本文深度解析 2026 年最新 SOTA 一步自回归视频生成方法 One-Forcing,从核心问题、架构设计到官方代码实战,一次性讲透如何用几乎零额外成本解决自回归视频生成的致命误差累积问题。
前言
视频生成技术正在经历从 "离线高质量" 到 "实时交互式" 的关键转型。以 Sora、Wan2.1 为代表的双向扩散模型虽然能生成惊艳的视频,但计算量随视频长度二次增长,无法满足游戏引擎、世界模拟等低延迟场景的需求。
自回归(因果)视频生成通过流式逐帧生成解决了延迟问题,但主流方法仍需 4 步采样,部署延迟依然较高。当我们试图将采样步数压缩到极限的 1 步时,所有现有方法都会遭遇灾难性的质量退化:
- 一致性蒸馏生成的视频动态性几乎消失
- 纯 DMD 方法生成的视频模糊不清,且会随着生成时长逐渐漂移
- 对抗自蒸馏方法的判别器会完全坍塌,无法提供有效监督
2026 年 5 月,清华大学与 UCLA 联合提出的One-Forcing 方法彻底解决了这一难题。它通过一个天才的 "零成本寄生式 GAN" 设计,在几乎不增加任何参数和计算量的情况下,让一步自回归视频生成的 VBench 总分达到83.76,仅比 50 步的 Wan2.1 教师模型低 0.5 分,同时训练成本仅为传统分块方法的 1/3。
一、核心问题:为什么一步自回归视频生成这么难?
在讲解 One-Forcing 之前,我们必须先搞清楚:为什么图像一步生成已经非常成熟,而视频一步生成却迟迟无法突破?
1. 一致性蒸馏的致命缺陷:高噪声曲率集中
轨迹式一致性蒸馏是目前最主流的少步生成方法,它的核心假设是教师模型的采样轨迹足够平滑,可以用一条直线近似。但 One-Forcing 论文通过严谨的几何分析发现:
视频教师模型(Wan2.1)的轨迹 92.5% 的曲率都集中在 t≥0.9 的高噪声区域
这意味着视频轨迹在最开始的阶段就有一个急剧的转弯,一步采样的直线近似会在最关键的初始阶段严重偏离真实轨迹,导致生成的视频丢失所有动态信息。而图像教师模型(EDM2)没有这个问题,因此图像一步生成可以轻松实现。
2. 纯 DMD 的致命缺陷:自回归误差累积
分布匹配蒸馏(DMD)绕过了轨迹弯曲的问题,通过匹配生成分布实现一步生成。但在自回归场景下,DMD 有一个天生的致命弱点:
DMD 是一个纯局部目标,它只关心当前这一帧的分布对不对,完全不关心这个帧作为上下文对未来的影响
在自回归生成中,每一个生成的帧都会被送入 KV 缓存,成为未来所有帧的上下文。一个微小的分布偏差会被递归放大,最终导致整个视频模糊、漂移、甚至完全崩坏。这就是为什么纯 DMD 的 Self-Forcing 在一步设置下 VBench 得分只有 77.18,比 4 步版本低了 6 分多。
3. 对抗自蒸馏的致命缺陷:判别器坍塌
为了解决 DMD 的模糊问题,ASD 等方法尝试加入对抗损失,但它们犯了一个根本性的错误:用模型输出作为判别器的 "真实" 样本。
当判别器需要区分 "差的模型输出" 和 "更差的模型输出" 时,它会很快发现两者没有本质区别,最终判别器的输出会完全一致,也就是所谓的 "判别器坍塌"
One-Forcing 论文的实验显示,ASD 的判别器 logit gap 在整个训练过程中都保持在 0.001 以下,几乎没有提供任何有效梯度。
二、One-Forcing 核心设计:零成本寄生式 GAN
One-Forcing 的核心洞察非常简单却极其深刻:
DMD 中的 fake-score 网络本身,已经在学习如何区分真实分布和生成分布了!
基于这个洞察,One-Forcing 没有额外训练一个独立的判别器,而是直接复用 fake-score Transformer 的主干,只添加了一个极小的判别头,实现了几乎零成本的 GAN 损失。
1. 整体框架
One-Forcing 的整体框架如下图所示:
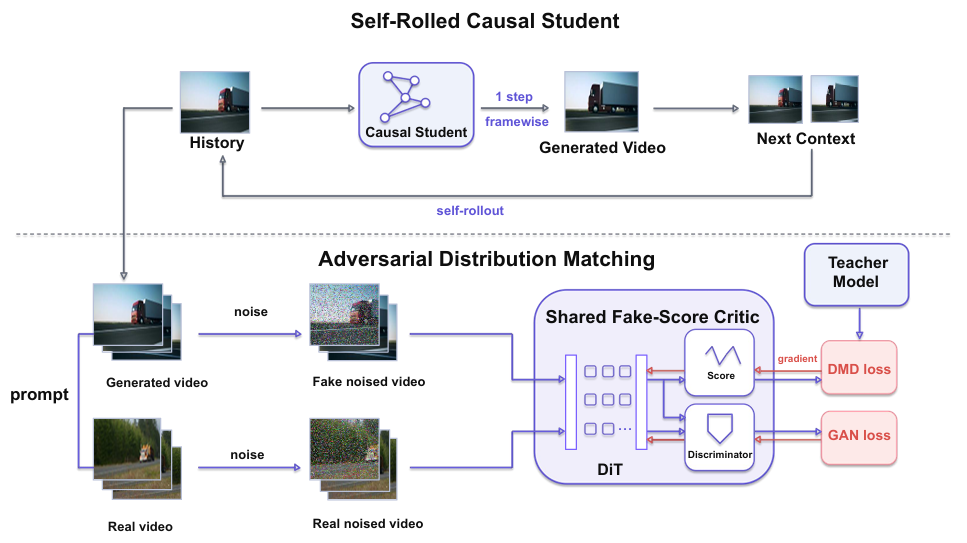
它由两个核心部分组成:
- 自滚动因果生成器:从历史帧生成下一帧,一步采样
- 对抗分布匹配模块:通过共享 fake-score 主干的判别器,同时提供 DMD 梯度和 GAN 梯度
2. 最核心创新:共享主干 + Register Token 判别头
这是 One-Forcing 最天才的设计,也是它能做到零成本的根本原因。
具体实现(完全对应官方代码)
-
插入 Register Token 探针 在 fake-score Transformer 的第 21 层和第 29 层(Wan2.1-1.3B 共 32 层)的输入序列前,各插入 2 个可学习的 register token。
# 官方代码 modeling_wan.py 中的实现 self.register_tokens = nn.Parameter(torch.randn(2, hidden_size))总共只新增了 4 个 1536 维的向量,参数量可以忽略不计。
-
共同前向传播 register token 和正常的视频时空 token 一起经过该层的自注意力和前馈网络:
x = torch.cat([self.register_tokens.expand(batch_size, -1, -1), x], dim=1) x = self.attn(x) x = self.ffn(x) -
轻量交叉注意力池化 该层计算完成后,取出前 2 个 register token 作为 query,对所有正常视频 token 做单头交叉注意力:
# 官方代码 register_attention.py 中的实现 register_tokens = x[:, :2] video_tokens = x[:, 2:] attn_output = F.scaled_dot_product_attention(register_tokens, video_tokens, video_tokens)这一步的本质是让 register token 主动扫描整个视频的所有时空位置,提取最能区分真假的特征。
-
判别头输出 拼接第 21 层和第 29 层提取的 4 个特征向量,经过一个 2 层 MLP 输出最终的真假 logit:
features = torch.cat([layer21_features, layer29_features], dim=-1) logit = self.disc_head(features)
为什么这个设计这么好?
- 零额外参数:新增参数量 < 0.1%,训练速度和纯 DMD 几乎一样
- 特征空间完全对齐:DMD 梯度和 GAN 梯度在同一特征空间工作,不会互相冲突
- 不干扰原任务:交叉注意力的梯度只会从 register token 流向视频 token,不会破坏 fake-score 的去噪能力
- 真实数据驱动:判别器的正样本来自真实视频数据,彻底避免了判别器坍塌
3. 联合损失函数
One-Forcing 使用 DMD 损失和 GAN 损失的加权和作为总损失:
- 生成器损失 :
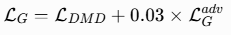
- 判别器损失 :
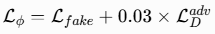
其中 GAN 损失使用标准的非饱和 softplus 损失,工作在加噪隐空间:
# 官方代码 one_forcing_trainer.py 中的实现
loss_d = F.softplus(-d_real).mean() + F.softplus(d_fake).mean()
loss_g_adv = F.softplus(-d_fake).mean()4. 训练流程
One-Forcing 采用双时间尺度更新策略:
- 每 1 次迭代:更新判别器(fake-score 主干 + 判别头)
- 每 5 次迭代:更新生成器
这种策略保证了判别器始终比生成器稍微强一点,能够提供稳定有效的梯度。
三、实验结果:一步生成媲美 50 步教师
One-Forcing 在 VBench 基准上取得了碾压性的结果:
| 模型 | 采样步数 | VBench 总分 | 画质分 | 语义分 |
|---|---|---|---|---|
| Wan2.1(教师) | 50 | 84.26 | 85.30 | 80.09 |
| One-Forcing(帧级) | 1 | 83.76 | 85.22 | 77.91 |
| One-Forcing(分块) | 1 | 81.60 | 83.65 | 73.41 |
| Self-Forcing(1 步) | 1 | 77.18 | 79.40 | 68.34 |
| ASD(1 步) | 1 | 79.12 | 81.35 | 70.19 |
关键结论:
- One-Forcing 的一步生成性能仅比 50 步的 Wan2.1 教师模型低 0.5 分,几乎追平
- 比所有其他一步方法高出 4-7 分,优势极其明显
- 帧级版本不仅质量更高,训练成本仅为分块版本的 1/3(200 步 vs 750 步)
人工偏好评测的结果更加惊人:
- 对比 1 步 Self-Forcing:胜率 88.4%
- 对比 1 步 ASD:胜率 92.7%
四、官方代码实战:从零开始跑通 One-Forcing
现在我们结合官方 GitHub 仓库https://github.com/Aurora-edu/One-Forcing,一步步教你如何跑通 One-Forcing 的推理和训练。
1. 环境搭建
# 创建conda环境
conda create -n one_forcing python=3.10 -y
conda activate one_forcing
# 安装依赖
git clone https://github.com/Aurora-edu/One-Forcing.git
cd One-Forcing
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
python setup.py develop2. 一键推理
官方已经提供了训练好的 One-Forcing 检查点,只需一行命令即可生成视频:
# 下载检查点
hf download JiaqiFeng/OneForcing checkpoints/one_forcing.pt --local-dir .
# 生成视频
bash scripts/infer.sh \
--checkpoint_path checkpoints/one_forcing.pt \
--prompt_path prompts/demos.txt \
--output_folder outputs \你可以编辑prompts/demos.txt文件,输入自己的文本提示。
3. 训练自己的 One-Forcing 模型
如果你想从头训练 One-Forcing,按照以下步骤操作:
步骤 1:下载数据集和基础模型
# 下载预处理好的真实视频隐变量数据集
hf download JiaqiFeng/OneForcing --include "clean_data/*" --local-dir .
# 下载ODE初始化检查点
hf download JiaqiFeng/OneForcing checkpoints/framewise/causal_ode.pt --local-dir .
# 下载Wan2.1基础模型
hf download Wan-AI/Wan2.1-T2V-1.3B --local-dir wan_models/Wan2.1-T2V-1.3B
hf download Wan-AI/Wan2.1-T2V-14B --local-dir wan_models/Wan2.1-T2V-14B步骤 2:开始训练
torchrun --nproc_per_node=8 train.py \
--config_path config.yaml \
--generator_ckpt checkpoints/framewise/causal_ode.pt \
--teacher_model_path wan_models/Wan2.1-T2V-14B \
--data_path mixkit_latents_lmdb \
--logdir runs \
--disable-wandb \
--no_visualize在 8×H100 GPU 上,帧级版本仅需 200 步即可收敛,训练时间不到 1 小时。
五、核心创新总结
One-Forcing 的成功不是偶然,它解决了自回归视频生成领域长期存在的三个根本性问题:
- 揭示了视频一步一致性蒸馏失效的几何原因:高噪声曲率集中
- 提出了零成本寄生式 GAN:共享 fake-score 主干,几乎无额外开销
- 实现了稳定的帧级一步自回归生成:训练成本降低 2/3,质量更高
六、总结与展望
One-Forcing 标志着实时交互式视频生成技术迈出了关键一步。它用一个极其优雅的设计,证明了一步自回归视频生成可以达到与多步方法相媲美的质量。
未来,One-Forcing 可以在以下方向进一步发展:
- 扩展到更高分辨率和更长时长的视频生成
- 结合更大的骨干模型(如 14B 参数)进一步提升质量
- 探索自适应步长调度,在复杂场景自动增加采样步数
- 拓展到动作条件视频生成,赋能交互式世界建模
参考资料
- 论文:One-Forcing: Towards Stable One-Step Autoregressive Video Generation
- 官方代码:https://github.com/Aurora-edu/One-Forcing
- 项目主页:https://aurora-edu.github.io/one-forcing/
如果你觉得这篇文章对你有帮助,欢迎点赞、收藏、转发。