大家好,我是贺老师,嵌入式 AI工程师,《嵌入式AI:让单片机学会思考》主理人,专注AI在MCU上的落地实践。
文章简介
很多人第一次学习神经网络,最先接触的往往就是 Dense,也叫全连接层。
它看起来很简单:输入一组数字,输出另一组数字。但真正到了嵌入式 AI、TinyML、模型部署、Netron 看模型结构的时候,很多人又会卡住。
Dense 到底在算什么?为什么叫"全连接"?权重和偏置在哪里?Dense 的输入输出 shape 怎么看?为什么 Dense 层参数量很容易变大?为什么 MCU 上不能随便堆 Dense?
这篇文章站在嵌入式工程师能真正用起来的角度,把 Dense 和数组、矩阵、参数量、模型部署联系起来。
一、Dense 到底是什么?
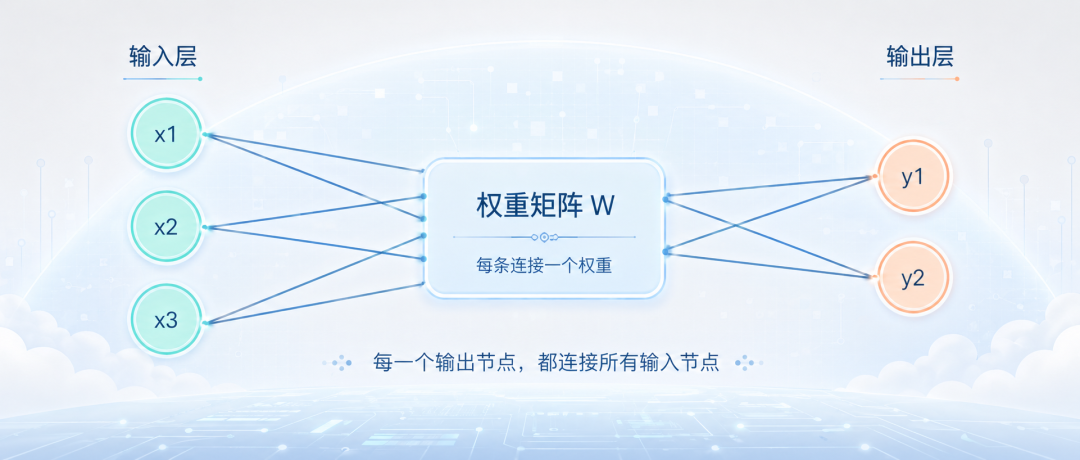
1. 什么叫全连接
Dense 的中文一般叫"全连接层"。所谓"全连接",意思是:上一层的每一个输入,都和下一层的每一个输出相连。
假设输入有 3 个数字:
x1, x2, x3Dense 层要输出 2 个数字:
y1, y2那么 y1 会同时使用 x1、x2、x3;y2 也会同时使用 x1、x2、x3。
y1 = x1 * w11 + x2 * w21 + x3 * w31 + b1
y2 = x1 * w12 + x2 * w22 + x3 * w32 + b2这里面的 w 是权重,b 是偏置。
2. Dense 的本质公式
可以先把 Dense 理解成一个"可训练的多输入多输出计算模块"。它不是人工写死规则,而是通过训练得到一组权重和偏置。
输出 = 输入 × 权重矩阵 + 偏置如果再加上激活函数,就变成:
输出 = 激活函数(输入 × 权重矩阵 + 偏置)比如最常见的 ReLU:
输出 = ReLU(输入 × 权重矩阵 + 偏置)ReLU 的作用很简单:小于 0 的值变成 0,大于 0 的值保持不变。
float relu(float x)
{
return x > 0 ? x : 0;
}3. 全连接结构示意
二、Dense 的输入、输出和参数量怎么看?
1. 看 Dense,先看输入长度和输出长度
学习 Dense,最关键的是看懂三个东西:输入长度是多少,输出长度是多少,参数量是多少。
假设有这样一层:
Dense(4, input_shape=(3,))它表示输入是 3 个数字,输出是 4 个数字。
每个输出都要连接 3 个输入,所以一个输出需要 3 个权重。现在有 4 个输出,所以权重数量是:
3 × 4 = 12每个输出还需要一个偏置,所以偏置数量是:
4这一层总参数量就是:
3 × 4 + 4 = 162. Dense 参数量公式
Dense 层参数量的计算公式非常直接:
参数量 = 输入长度 × 输出长度 + 输出长度也可以写成:
参数量 = (输入长度 + 1) × 输出长度多出来的那个 1,本质上就是偏置。
**例子:**输入是长度为 128 的特征向量,Dense 输出 64 个节点:
Dense(64, input_shape=(128,))
参数量 = 128 × 64 + 64 = 82563. 为什么 Dense 层很容易变大
Dense 层的参数量增长非常直接。输入越长,输出节点越多,参数量就越大。
尤其是图像类任务,如果直接把图片拉平成一维再接 Dense,参数量会非常大。
**例子:**一张 96×96 的灰度图,如果直接 Flatten 后接 Dense(128):
输入长度 = 96 × 96 = 9216
输出长度 = 128
参数量 = 9216 × 128 + 128 = 1,179,776这一层就超过 117 万个参数。哪怕是 int8 量化,光权重就接近 1.18 MB。对于很多 MCU 来说,这已经不现实。
参数量对比表
| 输入长度 | 输出节点数 | 参数量计算 | 参数量 | int8 权重约占用 |
|---|---|---|---|---|
| 40 | 32 | 40 × 32 + 32 | 1,312 | 约 1.3 KB |
| 128 | 64 | 128 × 64 + 64 | 8,256 | 约 8.1 KB |
| 1024 | 128 | 1024 × 128 + 128 | 131,200 | 约 128 KB |
| 9216 | 128 | 9216 × 128 + 128 | 1,179,776 | 约 1.18 MB |
三、Dense 在神经网络里通常起什么作用?
1. 做特征组合
假设前面已经提取出一组特征,比如传感器信号经过预处理以后得到 40 个特征值:
feature[0] ~ feature[39]Dense 层可以把这 40 个特征重新组合成更有表达能力的中间表示:
Dense(32, activation='relu')这表示模型会从 40 个输入特征中学习出 32 个新的组合特征。每个输出节点都可以理解为"从所有输入特征中提取某种模式"。
2. 做分类输出
如果任务是三分类,比如:
0 = 静止
1 = 走路
2 = 跑步最后一层通常可以写成:
Dense(3, activation='softmax')输出是 3 个数字,分别代表三个类别的概率倾向。比如模型输出:
[0.05, 0.90, 0.05]就可以理解为模型认为第 1 类"走路"的可能性最大。
3. 做二分类或回归预测
如果是二分类,比如"正常 / 异常",也可以写成:
Dense(1, activation='sigmoid')输出一个 0 到 1 之间的值。比如:
0.87可以理解为更偏向"异常"这一类。实际项目中还会设定阈值,比如大于 0.7 才判定异常,而不是简单用 0.5。
如果模型不是输出类别,而是输出一个连续数值,比如温度预测、距离估计、剩余寿命估计,那么最后一层常常不加 softmax,也不加 sigmoid,而是直接:
Dense(1)Dense 输出层常见写法
| 任务类型 | 输出层写法 | 输出含义 | 后处理方式 |
|---|---|---|---|
| 二分类 | Dense(1, activation='sigmoid') | 0~1 的概率倾向 | 与阈值比较 |
| 多分类 | Dense(N, activation='softmax') | N 个类别概率 | 取最大概率类别 |
| 回归 | Dense(1) | 连续数值 | 直接读取或做物理量换算 |
四、从代码和部署角度理解 Dense
1. 一个简单 Dense 网络
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Input(shape=(40,)),
layers.Dense(32, activation='relu'),
layers.Dense(16, activation='relu'),
layers.Dense(3, activation='softmax')
])
model.summary()
这段模型的含义很清楚:输入是 40 个特征值;第一层 Dense 把 40 个输入变成 32 个中间特征;第二层 Dense 把 32 个中间特征变成 16 个中间特征;最后一层 Dense 输出 3 个类别结果。
2. 参数量估算
第一层:40 × 32 + 32 = 1312
第二层:32 × 16 + 16 = 528
第三层:16 × 3 + 3 = 51
总参数量:1891
如果是 float32,每个参数 4 字节,大约需要:
1891 × 4 = 7564 字节如果量化为 int8,每个参数 1 字节,大约是:
1891 × 1 = 1891 字节真实部署时还要算模型结构信息、中间张量、Tensor Arena 等运行时内存,但这个估算已经能让你判断模型大概是否适合 MCU。
3. 从 C/C++ 角度看 Dense 的计算
从 C/C++ 的角度看,Dense 层核心计算可以粗略理解成下面这样:
void dense_layer(const float* input,
const float* weights,
const float* bias,
float* output,
int input_size,
int output_size)
{
for (int j = 0; j < output_size; j++) {
float sum = bias[j];
for (int i = 0; i < input_size; i++) {
sum += input[i] * weights[i * output_size + j];
}
output[j] = sum;
}
}这段代码表达的就是 Dense 层最核心的逻辑:每个输出节点,都要把所有输入乘以对应权重,再加上偏置。
如果加 ReLU:
for (int j = 0; j < output_size; j++) {
if (output[j] < 0) {
output[j] = 0;
}
}
部署端最关键的判断: Dense 层在 MCU 上的性能主要受 输入长度 × 输出长度 影响。这个值越大,乘加次数越多,推理时间越长。
五、Dense 层在嵌入式 AI 中应该怎么用?
1. Dense 适合什么场景
Dense 非常适合小输入、小模型、结构清晰的任务。比如下面这些场景,Dense 很常见:
-
传感器特征分类:把温度、电流、振动 RMS、峰值、均值、方差等特征整理成几十维向量,然后用 Dense 做正常/异常判断。
-
简单回归任务:输入几个传感器特征,输出一个估计值。
-
小型动作识别任务:如果前面已经把一段 IMU 数据压缩成特征向量,Dense 可以作为分类器。
2. Dense 不适合直接处理很大的原始输入
如果输入很大,比如原始图像、长音频、长时序信号,直接用 Dense 往往不合适。因为它不利用局部结构,每个输入都连到每个输出,参数量会迅速变大。
这时候更常见的做法是:前面用卷积层或特征提取方法先压缩信息,再接 Dense 做最后分类。
图像任务通常不建议直接这样写:
Flatten()
Dense(128)
Dense(10)
如果图像尺寸比较大,这种结构参数量很容易失控。
更合理的是:
Conv2D(...)
MaxPooling2D(...)
Conv2D(...)
Flatten()
Dense(32)
Dense(num_classes)3. MCU 项目里 Dense 的使用建议
Dense 的正确使用思路是:
输入维度不要太大
中间节点不要盲目加宽
输出层要和任务类型匹配
部署前必须估算参数量和计算量如果是 MCU 项目,建议一开始就控制 Dense 的规模。比如输入几十维,隐藏层 16、32、64 都比较常见。不要一开始就上 256、512、1024 这种宽层,除非目标芯片资源足够,并且已经验证过推理时间和内存占用。
最后给一个非常实用的判断方式:
当你看到一层 Dense 时,马上问四个问题:
-
输入长度是多少?
-
输出节点是多少?
-
参数量是多少?
-
这一层在 MCU 上是否值得?
如果这四个问题回答不上来,就说明你还没有真正看懂这层。
总结
Dense 层看起来是神经网络里最基础的一层,但它并不简单。它连接着模型结构、参数量、计算量、输入输出 shape、量化部署和 MCU 资源预算。
把 Dense 真正搞明白,后面再看 CNN、RNN、Transformer,理解难度会下降很多。因为无论模型结构多复杂,最终都离不开一个核心:输入数据经过一系列可训练参数的计算,逐步变成我们需要的输出结果。
Dense,就是最直接、最基础、也最值得嵌入式工程师认真掌握的一层。