目录
前言
在上篇文章 Learn-Claude-Code | 笔记 | Collaboration | s11 Autonomous Agents 中,我们介绍了开源项目 learn-claude-code 第十一个章节 s11 Autonomous Agents 的内容,这篇文章我们继续跟着教程文档来学习协作最后一个部分的内容,记录下个人学习笔记,和大家一起分享交流😄
Note:本篇文章主要学习记录教程第五部分 Collaboration 中 s12: Worktree + Task Isolation 章节的内容。
github :https://github.com/shareAI-lab/learn-claude-code
reference :https://chatgpt.com/
1. s12: Worktree + Task Isolation
如果说 s11 的 Autonomous Agents 解决的是 "多个 teammate 不再只是被动等待 lead 分配任务,而是能够在共享任务板上自己发现任务、自己认领任务,并逐渐涌现出分工",那么到了 s12,这一节继续沿着 Collaboration 这条主线往前推进,但它要回答的问题已经又比 s11 更进一步了:
即便任务已经能被多个 autonomous teammates 自己认领,如果这些任务最终还是都落在同一个工作目录里执行,那它们真的算被隔离了吗?
前面 s11 已经让我们看到一个非常漂亮的系统图景:任务板是共享真相源,多个 agent 通过 idle -> poll -> claim -> work 的本地循环自然把任务分散认领掉。从任务调度的角度看,这已经很像一个会自己运转的小团队了。但这里其实还埋着一个非常现实、也非常工程化的问题:任务的认领被分开了,不代表任务的执行环境也被分开了。
举一个特别直观的例子。假设当前任务板上有两个正在进行中的任务:
- Task 1:重构
auth/service.py - Task 2:优化
ui/Login.tsx
如果 Alice 和 Bob 都已经各自 claim 了自己的任务,但它们最后仍然在同一个工作目录里跑:
- 共享同一份源码树
- 共享同一组临时改动
- 共享同一套
git status - 共享同一块未提交的文件状态
那么从执行层面看,这两个任务其实还是会互相污染。哪怕它们改的是不同文件,也仍然可能碰到这些问题:
- 一个任务的临时改动影响另一个任务的测试结果
- 一个任务为了验证功能而安装 / 生成的文件污染另一个任务的工作区
- 两个 teammate 对同一目录进行读写时,很难再分清 "这是谁的执行痕迹"
- 任务板上虽然记录着 owner,但文件系统本身没有对应的 "lane ownership"
也就是说,到了 s12,问题已经不再是 "任务如何被分给谁",而是:
任务在被分给不同 agent 之后,能不能拥有各自独立的执行空间?
这其实是一个非常自然的推进。s07 解决的是任务如何被表达成外部事实;s09-s10 解决的是团队如何通过邮箱和协议协作;s11 解决的是任务如何被自治地认领;而到了 s12,系统终于开始回答另一个非常关键的问题:
认领之后,在哪里干活?
这也是为什么这一节叫 Worktree + Task Isolation 。它不是在调度层再加一个新技巧,而是在执行层第一次真正引入一种 "每个任务有自己的 lane" 的隔离观。前面 s11 已经让团队学会自己分工,而 s12 则进一步让这种分工开始拥有真正的物理边界:不仅任务归属不同,连工作空间也应该不同。
2. 问题
我们先来看一个很朴素的问题:为什么到了 s12,仅仅有任务板和 owner 字段还不够?🤔
从 s11 的角度看,系统已经很不错了。任务板里每条任务都有:
idsubjectstatusowner
多个 autonomous teammates 也已经会自己 claim task。于是从逻辑上看,好像分工已经清楚了:
- Task 1 归 Alice
- Task 2 归 Bob
那按理说,这不就已经解决冲突了吗?
问题就在于,任务板上的 "归属分离" 并不等于文件系统中的 "执行分离"。
任务板只是告诉我们 "谁负责什么",但如果 Alice 和 Bob 依然都在同一个根目录里执行:
- Alice 改了
auth/service.py - Bob 改了
ui/Login.tsx - 两个人都在根目录跑测试、写临时文件、更新依赖、查看状态
那么系统最终面对的依然是一块混在一起的工作区。这样一来,虽然任务板上记录了两个不同 owner,但执行层还是只有一条共享 lane。
这时会出现一个非常典型的问题:任务之间的冲突不再只是 "认领冲突",而变成了 "工作区冲突"。
比如:
- Task 1 正在修改 auth 逻辑
- Task 2 正在修改 UI 登录页
- 两个任务都需要跑验证命令
- 两个任务都可能产生中间文件或未提交改动
如果它们都在同一份工作树里进行,这些变化最后都会混在一起。于是你很难回答下面这些问题:
- 当前目录里的改动到底属于哪个任务?
- 某次测试失败,是因为当前任务没做好,还是因为另一个任务改乱了环境?
- 如果任务 1 做完了,任务 2 还在继续,能不能 "保留一个工作空间,关闭另一个工作空间"?
- 如果想审计某个任务到底做过什么,除了任务板状态以外,有没有更细的 side-channel 轨迹?
这时候就会发现,s11 虽然已经让任务分工开始自治,但执行层仍然缺一块非常关键的能力:
一个任务一旦开始工作,就应该拥有自己的隔离工作树,而不是继续把所有执行痕迹都压在同一个共享目录上。
所以 s12 真正想解决的问题,可以概括成一句话:
任务的所有权已经分离了,但执行环境还没有分离;而真正可靠的并行协作,必须把这两件事同时做对。
3. 解决方案
明确问题之后,s12 给出的解法,其实不是再去增强 lead 的调度能力,也不是继续给 autonomous teammate 加更多 "认领策略",而是第一次正式把系统拆成了两个平面:
shell
Control plane (.tasks/) Execution plane (.worktrees/)
+------------------+ +------------------------+
| task_1.json | | auth-refactor/ |
| status: in_progress <------> branch: wt/auth-refactor
| worktree: "auth-refactor" | task_id: 1 |
+------------------+ +------------------------+
| task_2.json | | ui-login/ |
| status: pending <------> branch: wt/ui-login
| worktree: "ui-login" | task_id: 2 |
+------------------+ +------------------------+
|
index.json (worktree registry)
events.jsonl (lifecycle log)
State machines:
Task: pending -> in_progress -> completed
Worktree: absent -> active -> removed | kept前面 s11 已经让我们看到,任务板上的任务可以被不同 teammate 自己认领,于是逻辑层的分工已经出现了;但到了 s12,项目开始进一步意识到:逻辑层的分工和执行层的隔离,其实是两件不同的事情。
任务板只负责回答 "谁在做什么",而 worktree 层要负责回答 "谁在哪里做"。也就是说,s12 的真正解决方案并不是单点能力增强,而是一次系统分层。
先看左边的 Control plane。
这一层还是 .tasks/,本质上延续的是 s07 和 s11 的任务板思想。这里每个 task_*.json 记录的仍然是任务本身的共享真相,比如:
- 任务主题是什么
- 当前状态是什么
- 谁在负责
- 以及现在绑定了哪条
worktree
所以 control plane 解决的问题,始终是 "任务协调"。
它让整个团队都能看到:Task1 现在 in_progress,并且它的执行 lane 叫 auth-refactor;Task2 当前是 pending,但未来会绑定到 ui-login。也就是说,任务板开始不只是记录逻辑状态,还第一次带上了 "任务执行空间的引用"。
再看右边的 Execution plane。
这一层是 s12 真正新增的内容:.worktrees/。它不再关心任务语义本身,而是关心执行空间的分配与运行,比如:
auth-refactor/对应wt/auth-refactorui-login/对应wt/ui-login
并且每条 lane 都带着明确的 task_id。
也就是说,执行平面真正做的,是把原来那个会让多个任务互相碰撞的单工作目录,拆成多条彼此隔离的执行 lane。这样一来,Task1 改 auth,Task2 改 ui,即便它们同时处于 in_progress,也不再默认落到同一个目录里打架了。
而中间的两个文件:
index.jsonevents.jsonl
又把这一层结构补完整了。
其中 index.json 很重要,因为它其实就是 worktree registry。如果没有它,系统就只有一些零散目录,根本无法稳定回答:
- 当前有哪些 worktree
- 每条 lane 叫什么
- 它对应哪个目录
- 绑定的是哪个 task
换句话说,index.json 的价值在于:它把执行平面中的 lane,从 "几个存在于文件系统里的目录",提升成了 "系统可追踪、可列举、可绑定的执行对象"。
而 events.jsonl 则是另一个很有工程味道的设计。它不负责当前状态本身,而负责记录生命周期轨迹,也就是:
- 某条 lane 是什么时候创建的
- 它是什么时候绑定到某个 task 的
- 什么时候运行过命令
- 什么时候被 keep
- 什么时候被 remove
这意味着 s12 并不满足于 "现在状态是对的" 就结束了,它还希望 lane 的演化过程是可审计的。也就是说,除了任务真相和执行空间之外,这一节还第一次显式补上了一层 side-channel trace。
所以,从整体方案上看,s12 做的其实不是 "给 task 多加一个 worktree 字段" 这么简单,而是把整个系统正式拆成了三层:
第一层是 任务协调层 ,也就是 .tasks/。它负责共享真相,回答 "任务现在是什么状态"。
第二层是 执行隔离层 ,也就是 .worktrees/ + index.json。它负责 lane 编排,回答 "任务现在在哪条工作树里执行"。
第三层是 生命周期审计层 ,也就是 events.jsonl。它负责记录轨迹,回答 "这条 lane 是怎么一步步走到现在这个状态的"。
而最下面那两条状态机,又把这三层结构进一步收束成了两个最小 FSM:
shell
Task: pending -> in_progress -> completed
Worktree: absent -> active -> removed | kept这两条状态机其实特别重要,因为它说明在 s12 里,任务和 worktree 虽然彼此关联,但并不是同一个对象。
任务有自己的逻辑生命周期:
- 还没做的时候是
pending - 真正开始推进时是
in_progress - 收尾后变成
completed
而 worktree 也有自己独立的执行生命周期:
- 还没分 lane 时是
absent - 创建并投入使用后是
active - 最后要么被
removed - 要么被
kept
也就是说,任务结束和 lane 收尾虽然经常相关,但并不是天然完全同步的。一个任务完成后,你可以顺手删除对应 lane;但你也可以选择保留这条 lane,方便后续 follow-up。这正是 s12 比前面章节更成熟的地方:它第一次把 "任务完成" 与 "执行空间怎么收尾" 区分开了。
所以从解法角度看,s12 真正做的事情可以概括成下面三点:
第一,把任务板和执行目录彻底分层。任务板继续做共享协调,worktree 开始做执行隔离。
第二,用显式 registry 把 lane 管理正规化 。不是随便开几个目录,而是通过 index.json 维护正式的 worktree 映射关系。
第三,让任务状态机和 worktree 状态机并行存在 。任务管逻辑完成度,lane 管执行空间生命周期,两者通过 task_id/worktree 互相绑定,但不彼此吞并。
这也就意味着,到了 s12,系统终于开始具备一种真正成熟的并行执行观:
任务可以共享一块控制平面来协调,但绝不能默认共享一块执行平面来动手。
4. Worktree Task Isolation 流程图分析
这一节教程配了 6 张 Worktree Task Isolation 的图。如果说 s11 的 Autonomous Agent Cycle 图是在说明 "多个 agent 如何通过本地规则自然涌现出分工",那么 s12 的这一组图,重点就在于说明:当多个任务已经同时活跃时,系统如何把它们从共享工作区中拆分到不同的执行 lane。
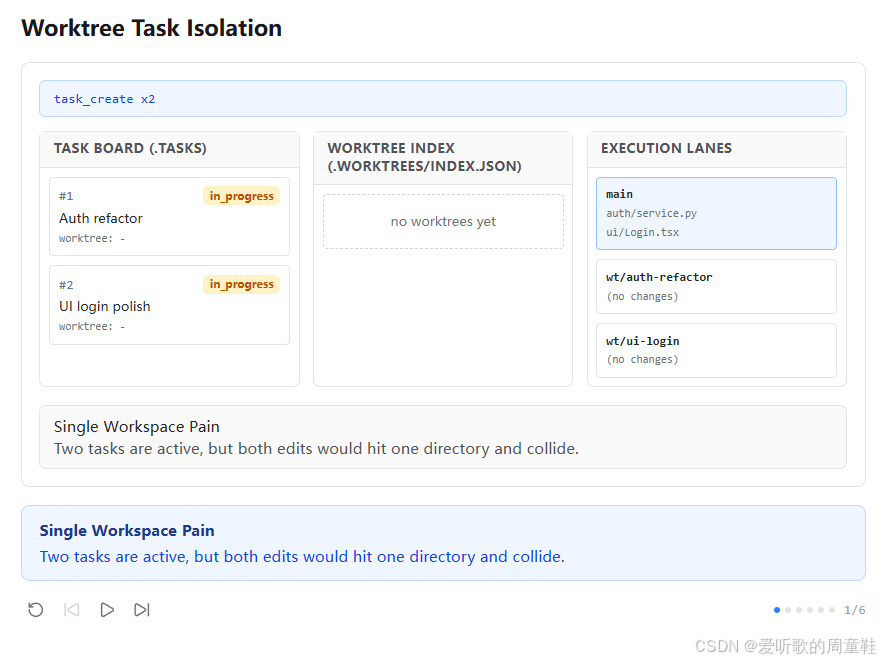
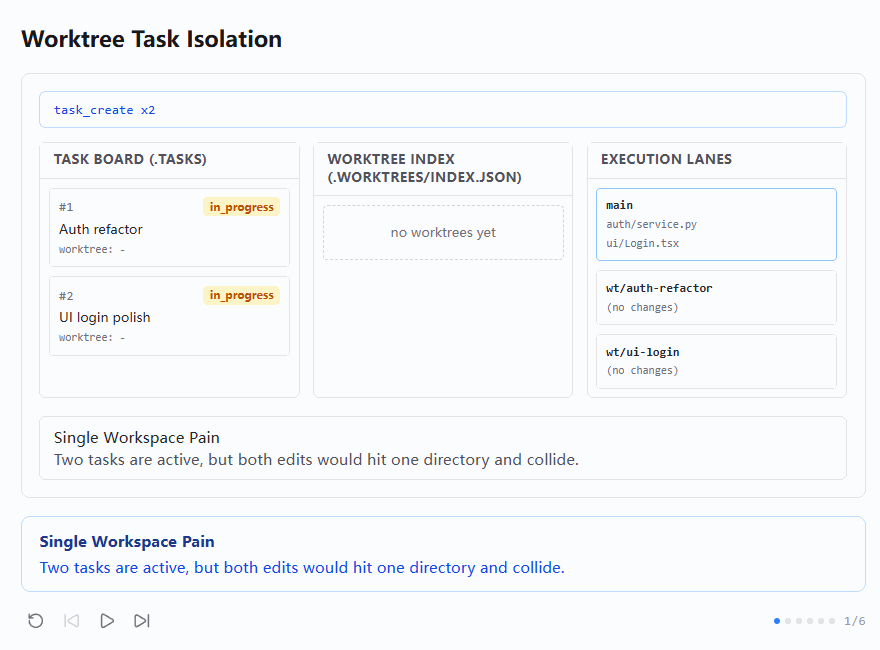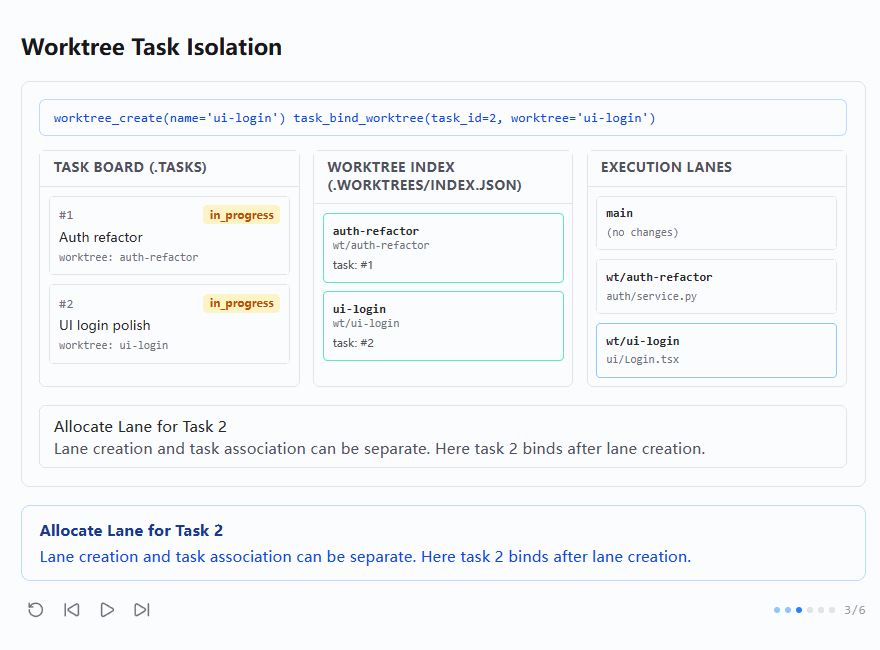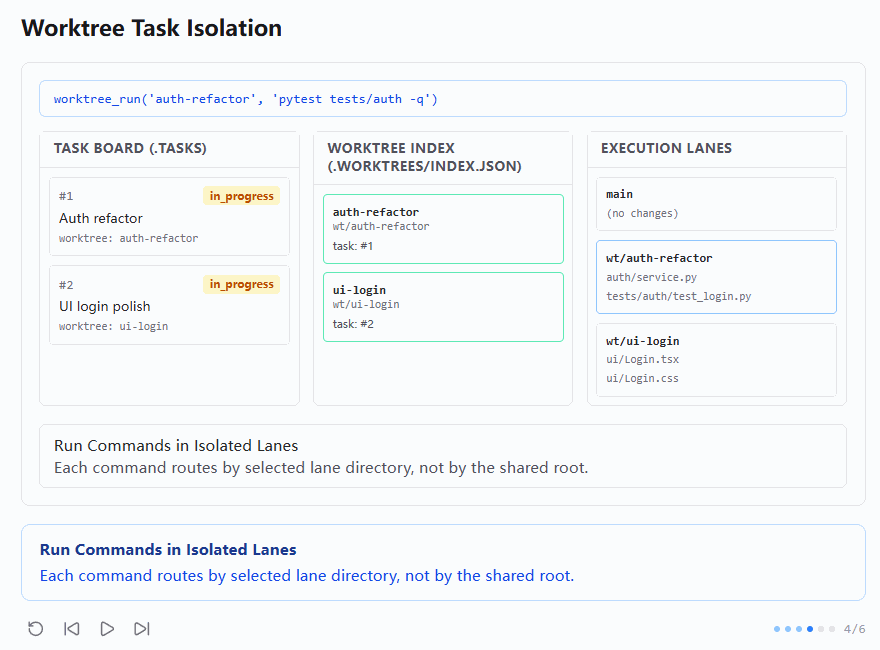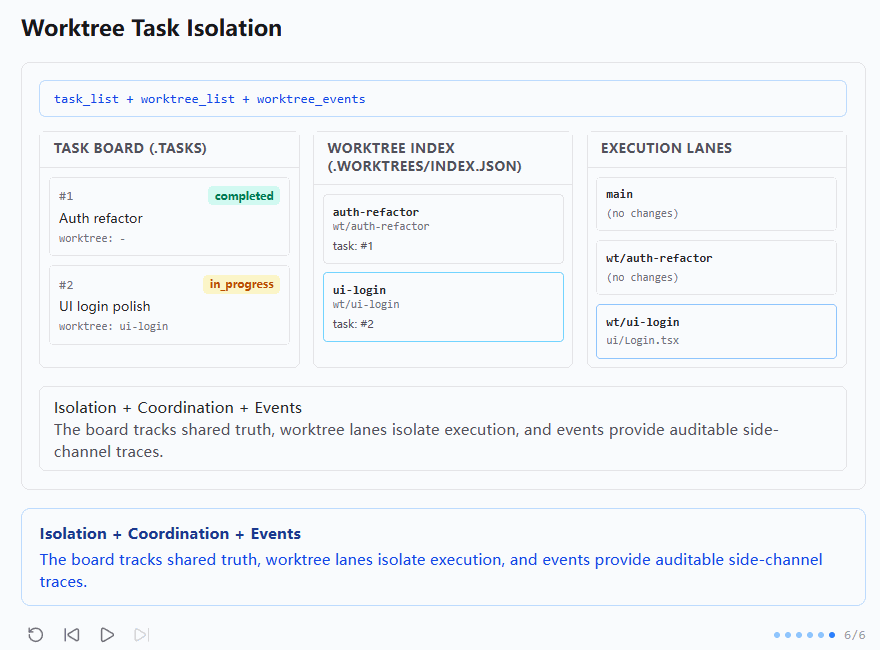
先看第一张图。图里同时出现了三个并列区域:
TASK BOARD (.TASKS)WORKTREE INDEX (.WORKTREES/INDEX.JSON)EXECUTION LANES
其中任务板上已经有两个任务:
#1 Auth refactor→in_progress#2 UI login polish→in_progress
但它们的 worktree 字段都是 -。与此同时,中间的 Worktree Index 区域还是空的,右侧 execution lanes 里只有一个 main 工作区带着文件痕迹,两个预留 lane 还是 (no changes)。
底部说明写的是:
shell
Single Workspace Pain
Two tasks are active, but both edits would hit one directory and collide.这张图的作用非常明确:先把问题摆出来。也就是说,任务级并行已经发生了,但执行级隔离还没有发生。
任务板上看起来一切都很好,两个任务都在进行中;可一旦落到文件系统,就会发现它们仍然在共享同一个根目录工作。这样一来,任务逻辑上是并行的,执行上却仍然是混杂的。
这其实就是 s12 整节课的出发点:s11 让任务分工涌现出来了,但还没有解决 "这些任务到底在哪里干活" 这个问题。
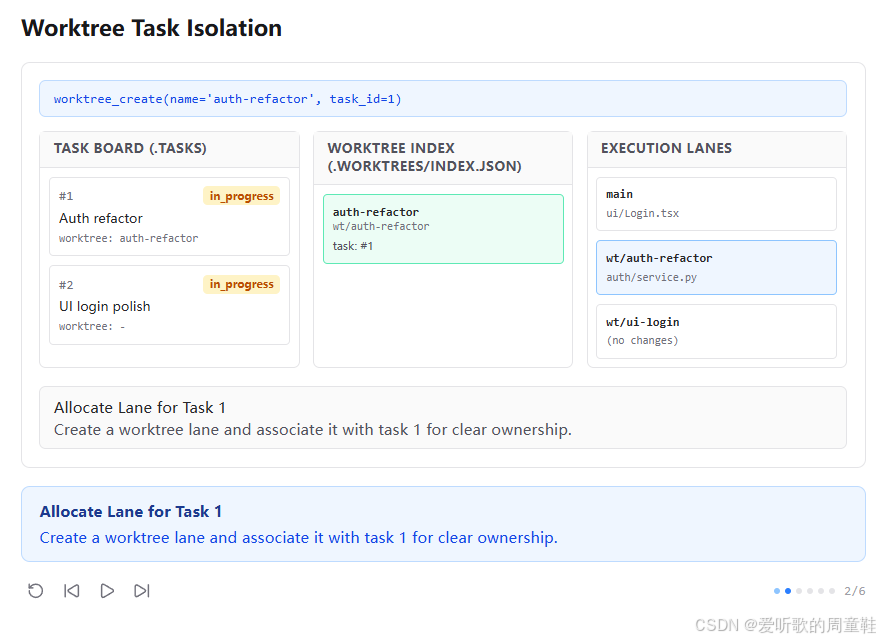
第二张图里,顶部命令栏显示:
shell
worktree_create(name='auth-refactor', task_id=1)这时任务板中的 #1 Auth refactor 卡片已经变成:
worktree: auth-refactor
中间的 Worktree Index 中也出现了一条新记录:
auth-refactorwt/auth-refactortask: #1
右侧 execution lanes 则显示:
main里还有别的痕迹wt/auth-refactor开始承载auth/service.pywt/ui-login还没动
底部说明写的是:
shell
Allocate Lane for Task 1
Create a worktree lane and associate it with task 1 for clear ownership.这一张图说明 s12 的第一步:先给任务分一条 lane。
这里最重要的其实不是 worktree_create 这个名字本身,而是它同时做了两件事情:
1. 创建了一个新的隔离执行空间
2. 把这个空间和 Task 1 显式绑定了起来
也就是说,从这里开始,任务板上的 "owner" 不再是唯一的归属字段,任务还第一次拥有了自己的 worktree 归属。
这一步让任务分工从 "谁负责" 扩展到了 "在哪个 lane 里执行"。
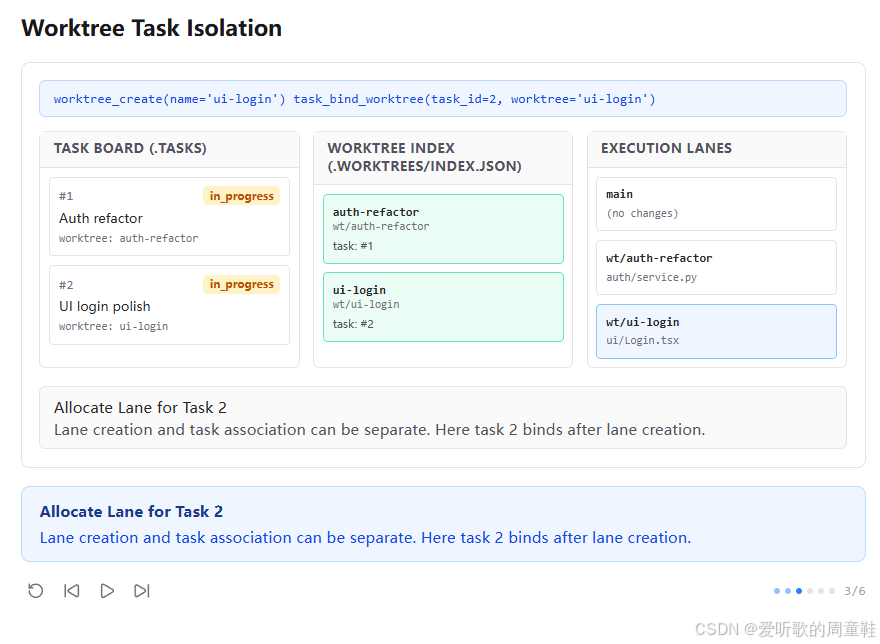
第三张图里,顶部命令变成:
shell
worktree_create(name='ui-login')
task_bind_worktree(task_id=2, worktree='ui-login')这次和第二张图不一样,它把 "创建 lane" 和 "绑定任务" 拆成了两个动作,结果是:
#2 UI login polish现在显示worktree: ui-login- Worktree Index 里多了一条
ui-login -> wt/ui-login -> task:#2 - 右侧
wt/ui-login中已经出现ui/Login.tsx
底部说明写的是:
shell
Allocate Lane for Task 2
Lane creation and task association can be separate. Here task 2 binds after lane creation.这张图说明:lane 和 task 的关系虽然紧密,但不是硬绑定在一个单一接口上的。
也就是说,系统支持两种使用方式:
- 创建时直接绑定
- 先创建 lane,再后绑定 task
这其实在工程实现中也很正常,因为现实里有时候你会先知道 "我要开一条临时工作 lane",但还没决定最终挂在哪个任务上;也有时候你已经明确知道这条 lane 就是给某个 task 用的,s12 的设计允许这两种节奏共存。
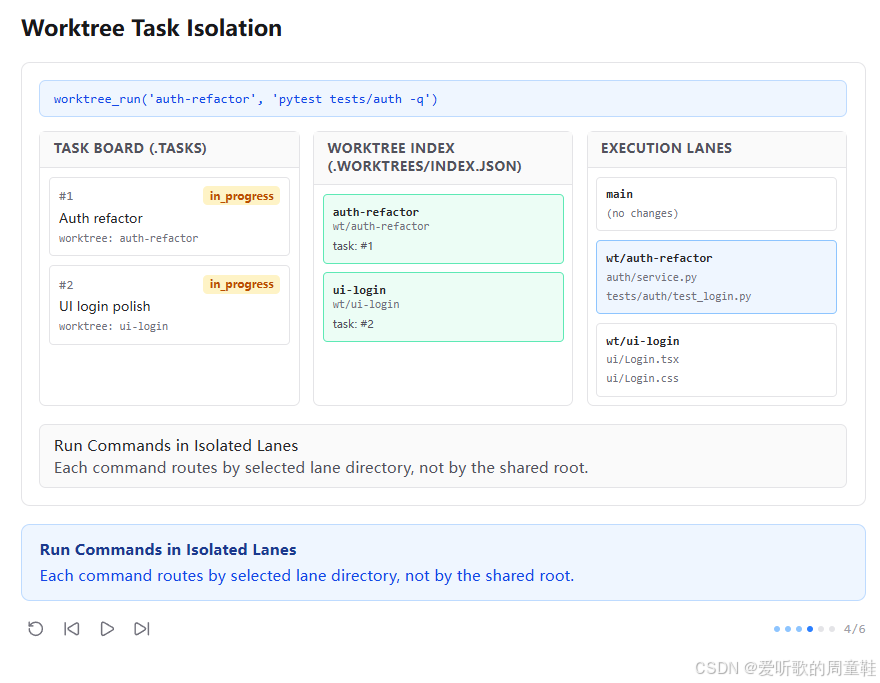
第四张图里,顶部命令栏显示:
shell
worktree_run('auth-refactor', 'pytest tests/auth -q')这时右侧 execution lanes 中的差异开始真正清晰起来:
wt/auth-refactor中出现了auth/service.py、tests/auth/test_login.pywt/ui-login中则是ui/Login.tsx、ui/Login.cssmain基本保持干净
底部说明写的是:
shell
Run Commands in Isolated Lanes
Each command routes by selected lane directory, not by the shared root.这一张图可以说是 s12 的灵魂。因为它第一次真正把 "隔离" 从任务板层面推进到了命令执行层面。前面第二、第三张图更多还是在建模 lane 和 task 的关系,而从这里开始,系统终于回答了一个最关键的问题:
既然 lane 已经分出来了,那命令到底怎么在 lane 里跑?
答案就是 worktree_run。它的意义不是简单地 "执行一条 bash",而是:
- 先选定 lane
- 再把命令路由到该 lane 对应的目录里执行
也就是说,从这一节开始,命令的 cwd 终于开始拥有任务上下文。
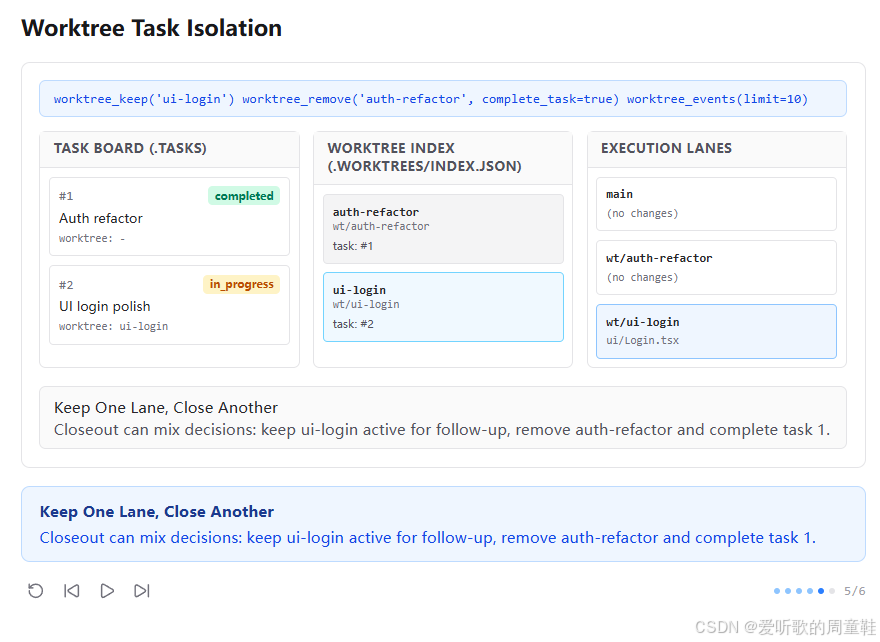
第五张图里,顶部命令组合非常有意思:
shell
worktree_keep('ui-login')
worktree_remove('auth-refactor', complete_task=true)
worktree_events(limit=10)此时任务板显示:
#1 Auth refactor→completed#2 UI login polish→in_progress, worktree: ui-login
Worktree Index 中:
auth-refactor变成灰掉的、相当于已关闭ui-login仍然保留并高亮
底部说明写的是:
shell
Keep One Lane, Close Another
Closeout can mix decisions: keep ui-login active for follow-up, remove auth-refactor and complete task 1.这一张图说明 s12 并不是把 worktree 当成一次性 disposable 目录,而是给了它完整的生命周期管理。
也就是说,任务 closeout 时不是只有一种 "全部删除" 策略,而是可以混合决策:
- 某条 lane 保留,方便继续跟进
- 某条 lane 删除,同时把任务状态正式推进到
completed
这一步特别重要,因为它把 "任务是否结束" 和 "工作空间是否保留" 这两件事解耦了。现实里这两者本来就不总是同步的:
- 有的任务做完了,空间也该清掉
- 有的任务虽然一轮目标做完了,但工作空间还值得保留用于 follow-up
s12 通过 keep/remove 这组动作,把这种真实工程中的收尾弹性正式表达出来了。
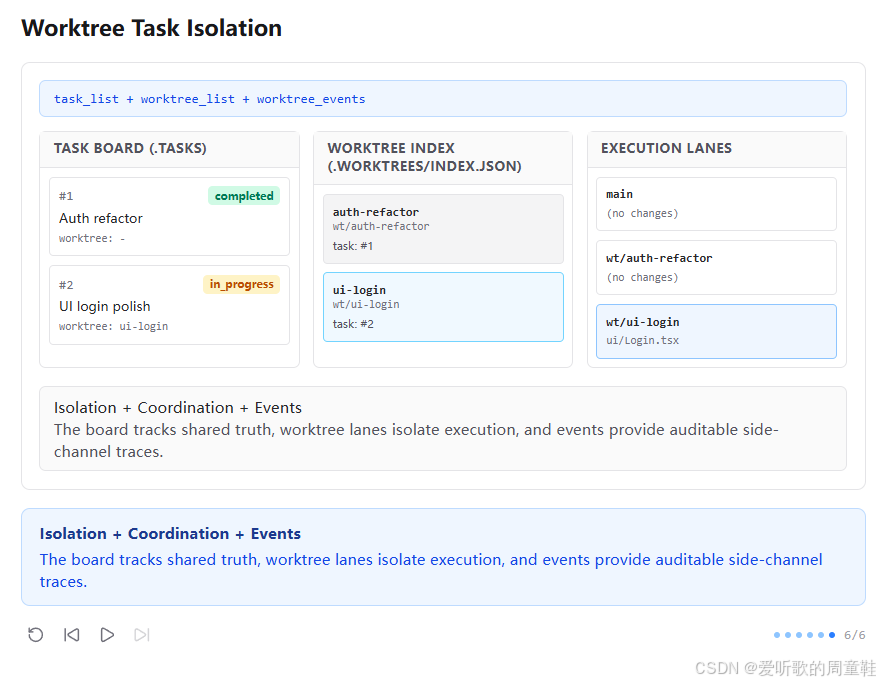
最后第六张图给出了总收束。顶部命令栏显示:
shell
task_list + worktree_list + worktree_events画面中三块区域的分工已经很清楚了:
- 任务板继续显示共享任务真相
- Worktree Index 显示 lane 与 task 的对应关系
- Execution Lanes 显示各 lane 中各自留下的执行痕迹
底部说明写的是:
shell
Isolation + Coordination + Events
The board tracks shared truth, worktree lanes isolate execution, and events provide auditable side-channel traces.这张图把这一节的三层结构总结得非常到位:
1. Task board:共享真相
2. Worktree lanes:执行隔离
3. Events:可审计侧信道轨迹
也就是说,到了 s12,协作系统已经不只是 "会分工、会协议、会自治",而开始具备一种真正成熟的工程结构:
- 任务层负责协调
- 执行层负责隔离
- 观察层负责留痕
完整动画演示如下图所示:
5. 工作原理(代码分析)
看完流程图之后,接下来我们正式进入 agents/s12_worktree_task_isolation.py。和前面几节一样,文件顶部先给出了这一节的设计意图说明:
python
#!/usr/bin/env python3
# Harness: directory isolation -- parallel execution lanes that never collide.
"""
s12_worktree_task_isolation.py - Worktree + Task Isolation
Directory-level isolation for parallel task execution.
Tasks are the control plane and worktrees are the execution plane.
...
Key insight: "Isolate by directory, coordinate by task ID."
"""这段注释其实已经把 s12 的主题说得非常清楚了。这里最重要的几个关键词是:
directory-level isolationparallel task executionTasks are the control planeworktrees are the execution plane
也就是说,s12 真正新增的,不只是 "task 多了一个 worktree 字段",也不只是 "多了几个 worktree 工具",而是一整套围绕 执行隔离 设计出来的机制:任务板继续负责协调,而真正的代码执行开始被分配到不同目录中进行 。文件头部也明确写了,这一节的核心洞察是 Isolate by directory, coordinate by task ID.
如果说 s11 的核心问题是 "任务如何被 autonomous teammates 自己发现和认领",那么到了 s12,问题已经进一步变成了:
即便任务已经被不同 agent 认领,如果它们最终还是都在同一个目录里执行,那并行协作真的成立了吗?
所以这一节并不是推翻 s11,而是在 s11 的任务自治之上,再加上一层真正的执行边界。
初始化部分和前面几节类似,依然有 .env、Anthropic client、WORKDIR 这些基础运行时准备逻辑,但这一节新增了几个非常关键的路径与环境常量:
python
WORKDIR = Path.cwd()
...
REPO_ROOT = detect_repo_root(WORKDIR) or WORKDIR
...
TASKS = TaskManager(REPO_ROOT / ".tasks")
EVENTS = EventBus(REPO_ROOT / ".worktrees" / "events.jsonl")这里最值得注意的,其实是 REPO_ROOT。因为前面几节大多数时候,系统默认就是在当前 WORKDIR 下工作;而到了 s12,这一节第一次开始显式区分:
- 当前运行目录
WORKDIR - git 仓库根目录
REPO_ROOT
这一点特别重要,因为 worktree 本质上是 git 级别的能力,它必须围绕 repo root 来组织,而不能只是围绕当前 shell 所在目录来猜。代码里专门新增了:
python
def detect_repo_root(cwd: Path) -> Path | None:
"""Return git repo root if cwd is inside a repo, else None."""
try:
r = subprocess.run(
["git", "rev-parse", "--show-toplevel"],
cwd=cwd,
capture_output=True,
text=True,
timeout=10,
)
if r.returncode != 0:
return None
root = Path(r.stdout.strip())
return root if root.exists() else None
except Exception:
return None这一段代码说明 s12 不是简单地在本地新建几个目录就完事了,而是先要确认:当前这套 task isolation 到底依附的是哪个 git 仓库。
如果检测不到 repo root,就会退回 WORKDIR;而在主程序启动时也会专门提示:
python
if not WORKTREES.git_available:
print("Note: Not in a git repo. worktree_* tools will return errors.")这说明 s12 的执行隔离并不是抽象概念,而是明确建立在 git worktree 机制之上的。
接下来首先新增的,是 事件总线 EventBus。这一点和 s11 最大的不同之一就在这里:s11 里虽然有 task 状态、team 状态,但系统还没有一条专门面向 "执行空间生命周期" 的日志流;而到了 s12,这一节专门引入了:
python
class EventBus:
def __init__(self, event_log_path: Path):
self.path = event_log_path
self.path.parent.mkdir(parents=True, exist_ok=True)
if not self.path.exists():
self.path.write_text("")它底层对应的就是:
python
EVENTS_FILE = .worktrees/events.jsonl然后看 emit():
python
def emit(
self,
event: str,
task: dict | None = None,
worktree: dict | None = None,
error: str | None = None,
):
payload = {
"event": event,
"ts": time.time(),
"task": task or {},
"worktree": worktree or {},
}
if error:
payload["error"] = error
with self.path.open("a", encoding="utf-8") as f:
f.write(json.dumps(payload) + "\n")这个函数说明 s12 不只是想把当前状态维护对,还想把整个 lane 生命周期记录下来。也就是说,系统从这一节开始不只是有:
.tasks/task_*.json这样的静态状态文件.worktrees/index.json这样的映射注册表
还额外多了一条 append-only 的事件日志流。这意味着像下面这些动作:
worktree.create.beforeworktree.create.afterworktree.create.failedworktree.remove.beforeworktree.remove.afterworktree.keeptask.completed
都会被写进 events.jsonl。换句话说,执行平面从这一节开始不再只是 "当前状态可见",而是 "生命周期过程可追踪"。
然后我们看这一节的第一个核心状态对象:TaskManager。这一部分和 s11 之间既有延续,也有非常明确的新增。
先看 create():
python
def create(self, subject: str, description: str = "") -> str:
task = {
"id": self._next_id,
"subject": subject,
"description": description,
"status": "pending",
"owner": "",
"worktree": "",
"blockedBy": [],
"created_at": time.time(),
"updated_at": time.time(),
}
self._save(task)
self._next_id += 1
return json.dumps(task, indent=2)和 s07 相比,这里最值得注意的新字段就是:
python
"worktree": ""在 s07 中,task 主要只需要表达:
- 当前状态
- 当前 owner
- 是否被阻塞
也就是说,它更多是在描述 "任务协调状态"。而到了 s12,task 第一次开始明确引用一个执行空间,换句话说,task 不再只是 "被谁做",还开始描述 "在哪做"。
但要注意,这个 worktree 字段本身并不会创建 worktree,它只是一个引用关系。真正的 worktree 对象,是由后面的 WorktreeManager 管理的。这一点特别重要,因为它说明在代码结构上,s12 是明确把:
- task(控制平面对象)
- worktree(执行平面对象)
拆成了两个不同来源的状态,而不是简单地在 task json 里把所有东西一把塞完。
接着看 bind_worktree():
python
def bind_worktree(self, task_id: int, worktree: str, owner: str = "") -> str:
task = self._load(task_id)
task["worktree"] = worktree
if owner:
task["owner"] = owner
if task["status"] == "pending":
task["status"] = "in_progress"
task["updated_at"] = time.time()
self._save(task)
return json.dumps(task, indent=2)上述代码第一次把 "绑定执行空间" 这件事,正式写进了 task lifecycle 里。这里有两个关键点:
第一,绑定 worktree 会直接修改:
python
task["worktree"] = worktree也就是说,控制平面开始知道这个任务现在属于哪条 lane。
第二,如果原先还是 pending,那么绑定时会自动推进到:
python
task["status"] = "in_progress"这就说明,在 s12 的设计里,"任务被绑定到 worktree" 并不是一个无意义的元数据更新,而是意味着:这个任务已经正式拥有了执行空间,所以可以视为真正开始推进了。
同样地,unbind_worktree() 则负责把这种引用关系拆掉:
python
def unbind_worktree(self, task_id: int) -> str:
task = self._load(task_id)
task["worktree"] = ""
task["updated_at"] = time.time()
self._save(task)
return json.dumps(task, indent=2)这一点和后面的 lane closeout 是连在一起的:任务和执行空间虽然彼此绑定,但在生命周期上不是同一个对象,所以也必须允许解绑。
也就是说,s12 中 task 的状态机依然是 pending -> in_progress -> completed,但它开始和另一条 worktree 状态机并行存在。
接下来,我们就进入这一节真正新增的核心:WorktreeManager。
如果说前面的 TaskManager 主要还是 s07/s11 那一套 task board 逻辑的延续,那么 WorktreeManager 才是 s12 真正新长出来的那部分能力。
如果说前面的 TaskManager 主要还是 s07/s11 那一套 task board 逻辑的延续,那么 WorktreeManager 才是 s12 真正新长出来的那部分能力。
先看初始化:
python
class WorktreeManager:
def __init__(self, repo_root: Path, tasks: TaskManager, events: EventBus):
self.repo_root = repo_root
self.tasks = tasks
self.events = events
self.dir = repo_root / ".worktrees"
self.dir.mkdir(parents=True, exist_ok=True)
self.index_path = self.dir / "index.json"
if not self.index_path.exists():
self.index_path.write_text(json.dumps({"worktrees": []}, indent=2))
self.git_available = self._is_git_repo()初始化中充分体现了 s12 的 execution plane:
self.dir = repo_root / ".worktrees":执行空间根目录self.index_path = self.dir / "index.json":worktree 注册表self.git_available = self._is_git_repo():确认是否真的能使用 git worktree
这里最关键的是 index.json。因为从这一步开始,系统已经不只是 "在磁盘上新建几个目录",而是正式有了一份 worktree registry。这意味着:
- 当前有哪些 lane
- 每条 lane 的 path 是什么
- 对应 branch 是什么
- 服务哪个 task
- 当前状态是什么
这些信息不再靠 "扫目录猜出来",而是被显式保存在 index 中。也就是说,execution plane 已经从物理文件夹集合,变成了一个真正的系统状态面。
然后看 _find():
python
def _find(self, name: str) -> dict | None:
idx = self._load_index()
for wt in idx.get("worktrees", []):
if wt.get("name") == name:
return wt
return None这其实和 s09 的 teammate roster、s07 的 task board 是一个思路:系统里新增的重要对象,不会只靠路径存在,而会有一个稳定的名字和查找入口。
接下来先看 create(),这是这一节最核心的函数之一:
python
def create(self, name: str, task_id: int = None, base_ref: str = "HEAD") -> str:
self._validate_name(name)
if self._find(name):
raise ValueError(f"Worktree '{name}' already exists in index")
if task_id is not None and not self.tasks.exists(task_id):
raise ValueError(f"Task {task_id} not found")
path = self.dir / name
branch = f"wt/{name}"
self.events.emit(
"worktree.create.before",
task={"id": task_id} if task_id is not None else {},
worktree={"name": name, "base_ref": base_ref},
)
try:
self._run_git(["worktree", "add", "-b", branch, str(path), base_ref])
entry = {
"name": name,
"path": str(path),
"branch": branch,
"task_id": task_id,
"status": "active",
"created_at": time.time(),
}
idx = self._load_index()
idx["worktrees"].append(entry)
self._save_index(idx)
if task_id is not None:
self.tasks.bind_worktree(task_id, name)
self.events.emit(
"worktree.create.after",
...
)
return json.dumps(entry, indent=2)
except Exception as e:
self.events.emit(
"worktree.create.failed",
...
)
raise首先,它不是简单地 mkdir 一个目录,而是真正调用:
python
git worktree add -b wt/{name} ...也就是说,这一节所谓的 lane 并不只是普通目录,而是 git worktree 层面的隔离执行空间。
然后,它会构造一个 entry:
python
entry = {
"name": name,
"path": str(path),
"branch": branch,
"task_id": task_id,
"status": "active",
"created_at": time.time(),
}这里面最值得注意的是:
branchtask_idstatus = "active"
这说明 worktree 在这一节里已经有了自己独立的生命周期状态机。也就是说,它不是 task 的一个附属字符串,而是有名字、路径、分支、服务的 task、当前状态的完整对象。换句话说,execution plane 中新增的不是 "目录",而是 "带生命周期的 lane 对象"。
再往下看:
python
if task_id is not None:
self.tasks.bind_worktree(task_id, name)这一点特别关键,因为它说明 worktree_create(task_id=...) 并不只是创建 lane,还会把控制平面和执行平面接起来。
也就是说,一旦 create 成功,系统中会同时发生两件事:
1. index.json 中新增一条 active lane
2. 对应 task json 中写入 worktree=name
这也正好对应了我们前面解决方案里的双平面结构:
shell
.tasks/task_1.json <------> .worktrees/index.json再加上前后两个 events.emit(...),可以看出 s12 这一节并不满足于 "创建成功就行",它还希望把 create 的前后过程,以及失败情况,完整写进生命周期日志。也就是说,worktree create 不只是资源分配动作,还是一个可审计事件。
然后我们进入真正让执行语义变化的关键函数:run()。
python
def run(self, name: str, command: str) -> str:
dangerous = ["rm -rf /", "sudo", "shutdown", "reboot", "> /dev/"]
if any(d in command for d in dangerous):
return "Error: Dangerous command blocked"
wt = self._find(name)
if not wt:
return f"Error: Unknown worktree '{name}'"
path = Path(wt["path"])
if not path.exists():
return f"Error: Worktree path missing: {path}"
try:
r = subprocess.run(
command,
shell=True,
cwd=path,
capture_output=True,
text=True,
timeout=300,
)
out = (r.stdout + r.stderr).strip()
return out[:50000] if out else "(no output)"
except subprocess.TimeoutExpired:
return "Error: Timeout (300s)"这一段可以说是 s12 真正的灵魂。因为如果前面的 create() 和 bind() 还主要是在搭结构,那么 run() 才是真正让系统从 "共享工作区执行" 过渡到 "独立 lane 执行" 的地方。
关键其实只有一句:
python
cwd=path但就是这一个变化,把整个系统的执行语义彻底改掉了。
在 s11 里,不管 task 是谁认领的,最终命令大多还是在共享的 WORKDIR 下执行;而到了 s12,同样一条 shell 命令,如果通过:
python
worktree_run(name="auth-refactor", command="pytest tests/auth -q")调用,那它就不再在共享根目录运行,而是会被路由到:
python
path = wt["path"]也就是这条 lane 自己的 worktree 目录里执行。换句话说,从这一节开始,命令的执行位置第一次被正式纳入系统语义。
这一点特别重要,因为它意味着并行任务不再只是 "逻辑上各自负责不同的 task",而是开始真正拥有:
- 各自的目录
- 各自的分支
- 各自的执行上下文
所以如果用一句话来总结 worktree_run() 的价值,那就是:
它不是简单地又包了一层 bash,而是第一次把 "在哪执行" 变成了 agent 可以操作的显式维度。
接下来我们看 remove():
python
def remove(self, name: str, force: bool = False, complete_task: bool = False) -> str:
wt = self._find(name)
if not wt:
return f"Error: Unknown worktree '{name}'"
self.events.emit(
"worktree.remove.before",
...
)
try:
args = ["worktree", "remove"]
if force:
args.append("--force")
args.append(wt["path"])
self._run_git(args)
if complete_task and wt.get("task_id") is not None:
task_id = wt["task_id"]
before = json.loads(self.tasks.get(task_id))
self.tasks.update(task_id, status="completed")
self.tasks.unbind_worktree(task_id)
self.events.emit(
"task.completed",
...
)
idx = self._load_index()
for item in idx.get("worktrees", []):
if item.get("name") == name:
item["status"] = "removed"
item["removed_at"] = time.time()
self._save_index(idx)
self.events.emit(
"worktree.remove.after",
...
)
return f"Removed worktree '{name}'"s12 中并没有把 worktree 当作一次性目录来粗暴处理,而是给它设计了一条明确的 closeout 路径。
这里最值得注意的是:
python
complete_task: bool = False这意味着 "移除 lane" 和 "完成任务" 是可以联动,但并不是写死在一起的。如果 complete_task=True,系统会同时:
- 把 task 状态推进到
completed - 执行
unbind_worktree() - 记录一个
task.completed事件
如果不传这个参数,那 remove 的就只是执行空间,而不会自动替任务完成收尾。也就是说,在 s12 中,task 生命周期和 worktree 生命周期是两条相关但独立的状态机。
这也正好对应前面总图里的那两条状态机:
shell
Task: pending -> in_progress -> completed
Worktree: absent -> active -> removed | kept到了这一节,系统第一次开始认真区分:
- 任务是不是完成了
- 执行空间是不是要保留
这两个问题。
接着再看 keep():
python
def keep(self, name: str) -> str:
wt = self._find(name)
if not wt:
return f"Error: Unknown worktree '{name}'"
idx = self._load_index()
kept = None
for item in idx.get("worktrees", []):
if item.get("name") == name:
item["status"] = "kept"
item["kept_at"] = time.time()
kept = item
self._save_index(idx)
self.events.emit(
"worktree.keep",
...
)
return json.dumps(kept, indent=2) if kept else f"Error: Unknown worktree '{name}'"这一段说明 worktree closeout 不只有 "删掉" 这一种路径,还可以进入:
python
status = "kept"也就是说,某个 lane 即便当前阶段工作结束了,也可以被显式保留下来,供后面继续 follow-up 或二次修改使用。
这一点非常像真实工程里的 feature branch:有的做完就删,有的虽然一轮目标结束了,但分支还值得留着。
所以 keep() 的存在进一步说明,s12 中 execution plane 已经不只是临时资源池,而是带着正式生命周期决策的执行系统。
除了这些 lifecycle 操作之外,这一节还新增了 status() 和 events() 这样的可观测接口。
先看 status():
python
def status(self, name: str) -> str:
wt = self._find(name)
if not wt:
return f"Error: Unknown worktree '{name}'"
path = Path(wt["path"])
if not path.exists():
return f"Error: Worktree path missing: {path}"
r = subprocess.run(
["git", "status", "--short", "--branch"],
cwd=path,
capture_output=True,
text=True,
timeout=60,
)
text = (r.stdout + r.stderr).strip()
return text or "Clean worktree"这说明从 s12 开始,系统不仅能知道 lane 存不存在,还能直接查看某条 lane 当前的 git 状态。也就是说,execution plane 里的 lane 不是黑盒子,还是可查询、可观察的。
再看 list_recent():
python
def list_recent(self, limit: int = 20) -> str:
...
return json.dumps(items, indent=2)这对应的就是 worktree_events(limit=...) 工具。
它的存在说明,s12 并不是只让状态文件静态存在,还要给出一条回放轨迹。换句话说,这章的新东西并不只是 "能隔离",还包括 "隔离过程可观测"。
最后再看工具空间本身,你会发现在 TOOL_HANDLERS 里,前面熟悉的那几类工具还在,真正新增的,是这一组明显围绕 worktree 平面组织起来的工具:
python
"task_bind_worktree"
"worktree_create"
"worktree_list"
"worktree_status"
"worktree_run"
"worktree_keep"
"worktree_remove"
"worktree_events"这说明从这一节开始,模型自己的工具空间里第一次正式出现了 "执行空间管理" 这一层能力。也就是说,agent 不再只是能:
- 创建任务
- 更新任务
- 读写文件
而是开始能:
- 创建 lane
- 绑定 lane
- 在 lane 中执行命令
- 查询 lane 状态
- 决定 lane 的 closeout 方式
- 查看 lane 生命周期日志
这其实就是 s12 和 s11 最大的代码层变化。s11 让 agent 学会了自己找任务;而 s12 则让 agent 第一次真正学会了 为任务分配独立执行空间,并在这个空间中动手。
所以从代码角度看,s12 真正的价值并不只是 "多了几个 worktree 相关函数",也不只是 "把 git worktree 接进来了",而是第一次让这个项目在执行层面长出了非常重要的一种工程能力:
任务仍然通过共享 task board 来协调,但实际命令与文件修改,开始被强制路由到独立目录中进行;控制平面继续共享,执行平面则正式隔离。
到了这一节,这个项目已经不再只是一个 lead + teammates + protocols + autonomous task board 的协作系统了,它开始真正拥有一种更接近真实工程团队的执行观:任务分工可以共享同一个控制平面,但代码执行必须进入不同的执行平面;系统不仅要知道 "谁在做什么",还要知道 "谁在哪个 lane 里做什么"。
博主在给定下面的提示词情况下:
shell
Create tasks for backend auth and frontend login page, then list tasks.想通过调试看看任务创建过程有什么不同,我们来具体分析下:
Note:由于整个调试过程较长,因此下面我们只展示其中的关键部分。
key 1: 任务创建的差异
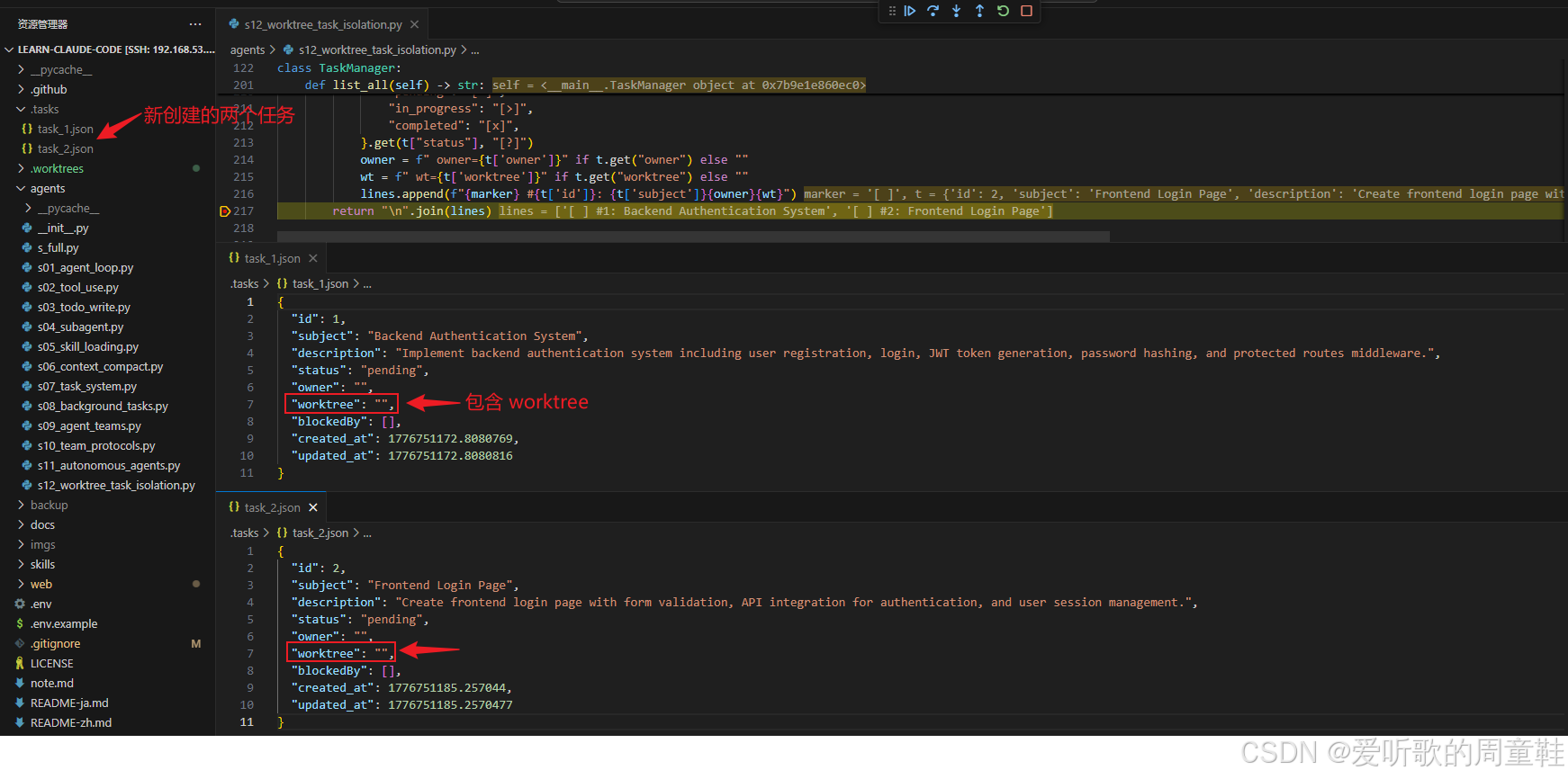
任务创建工具执行
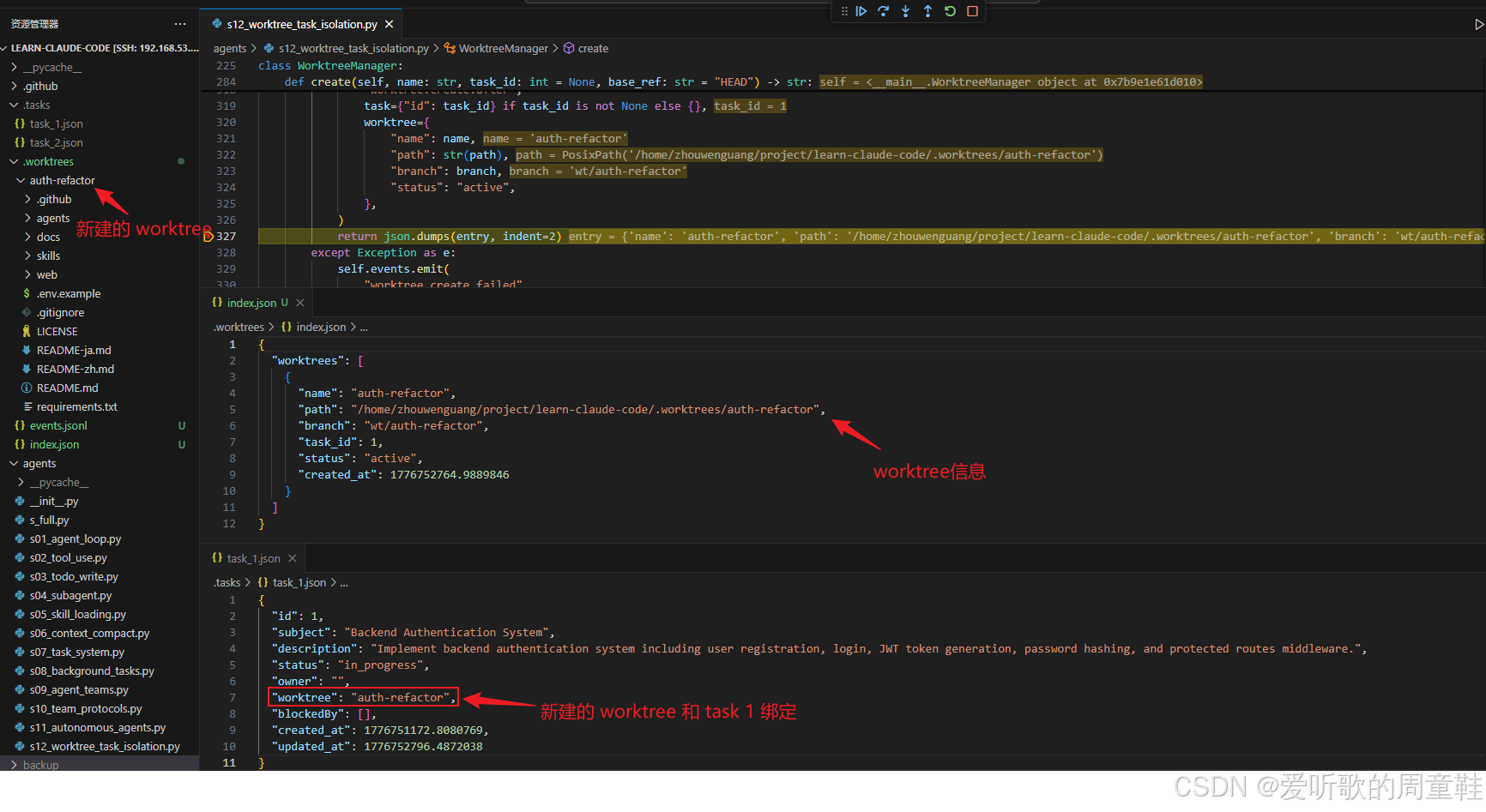
这里最值得注意的,不是一下子创建了两个任务,而是 task 的数据结构从一开始就已经为 worktree 做好了预留 。从调试图里可以直接看到,新创建出来的 task_1.json、task_2.json 中,除了前面 s11 已经有的 id、subject、status、owner 之外,现在还多了一个明确的:
json
"worktree": ""这其实就是 s12 和 s07/s11 最根本的分水岭,在 s12 中 task record 一创建出来就已经开始承担另一层语义:这个任务未来要绑定到哪条执行 lane 上。
接着我们在给定下面的提示词看看 worktree 工作树的创建:
shell
Create worktree "auth-refactor" for task 1, then bind task 2 to a new worktree "ui-login".key 2: worktree 的创建
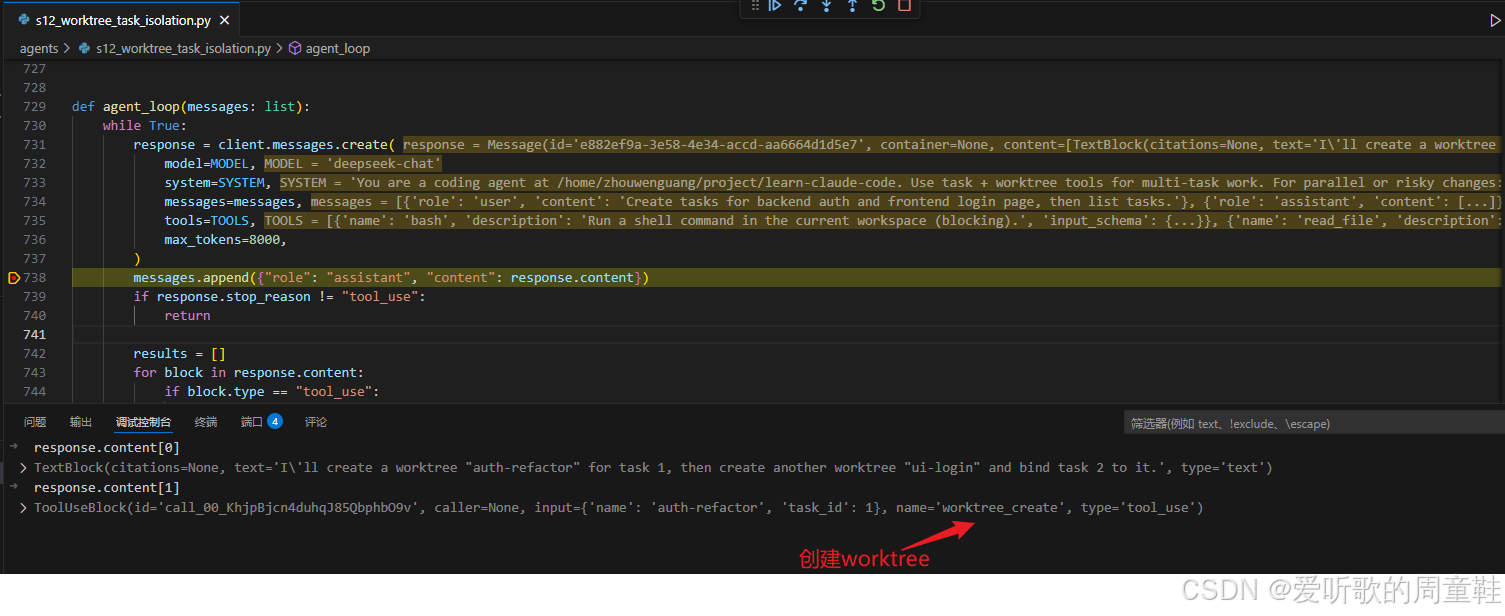
worktree 创建模型响应
worktree_create 工具调用执行

worktree_create 工具调用结果
上面这一组调试图把 s12 的核心新能力看得非常清楚。在 worktree_create() 执行过程的调试图中有三个关键点:
第一,它不是简单地新建目录,而是先生成:
python
path = self.dir / name
branch = f"wt/{name}"然后调用真正的 git worktree 命令:
python
self._run_git(["worktree", "add", "-b", branch, str(path), base_ref])也就是说,s12 的 lane 并不是随便建个文件夹,而是一个正式的 git worktree 分支工作树。
第二,它会构造一条完整的 entry,包括 name、path、branch、task_id、status = "active"、created_at,然后 append 到 index.json 中。
第三,如果传入了 task_id,它还会立刻调用:
python
self.tasks.bind_worktree(task_id, name)把 task 1 和新建的 auth-refactor 绑定起来。
这也正好对应了调试图里标出来的两个变化:一方面 .worktrees/auth-refactor/ 真的被创建出来了;另一方面 index.json 里写入了相关内容,同时 task_1.json 里的:
json
"worktree": "auth-refactor"也已经同步出现。也就是说,这一步真正做成的事情并不是 "多了个目录",而是 控制平面和执行平面第一次被显式连起来了:task 1 不只是逻辑上存在,而且已经拥有了一个正式的执行空间。
接着我们在给定下面的提示词看看在不同 worktree 下执行指令:
shell
Run "git status --short" in worktree "auth-refactor".key 3: 在 worktree 目录下执行指令
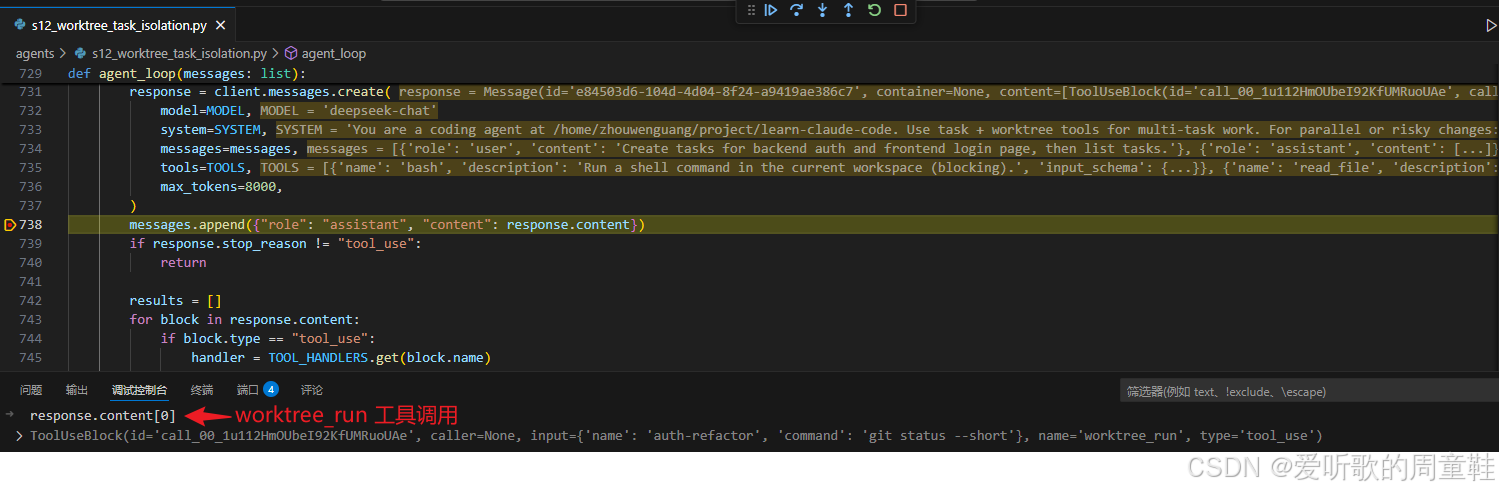
worktree_run 模型响应
worktree_run 工具调用
这一组图真正展示的,是 s12 相对于 s11 最本质的执行语义变化。因为在 s11 里,即便 task 已经被不同 teammate 认领,命令本质上还是在共享目录里运行;而到了 s12,模型已经会明确调用:
python
worktree_run(name="auth-refactor", command="git status --short")而不是普通的 bash(command=...)。也就是说,从模型视角看,"在哪个目录里执行" 第一次变成了一个显式决策。
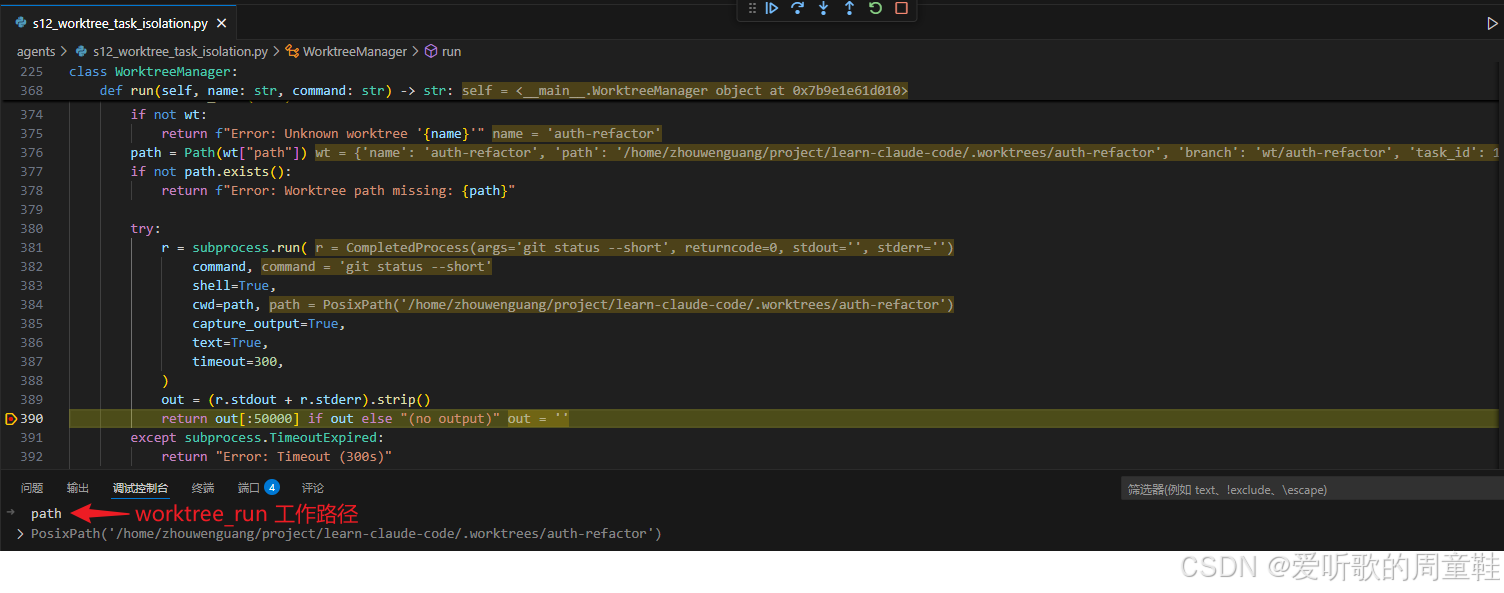
从调试图来看,path 的实际值是:
python
PosixPath('/home/.../.worktrees/auth-refactor')这意味着这次 git status --short 根本不是在共享根目录下运行,而是在 auth-refactor 这条 lane 自己的 worktree 中运行。
这一点特别关键,因为它说明 s12 真正解决的问题不是 "如何更聪明地调度命令",而是:
如何让不同任务的命令真正落在不同的执行目录里,从而把并行执行从逻辑分工推进到物理隔离。
接着我们在给定下面的提示词看看在 worktree 下 keep、list 等工具的调用:
shell
Keep worktree "ui-login", then list worktrees and inspect events.key 4: worktree keep、list、events 工具的调用
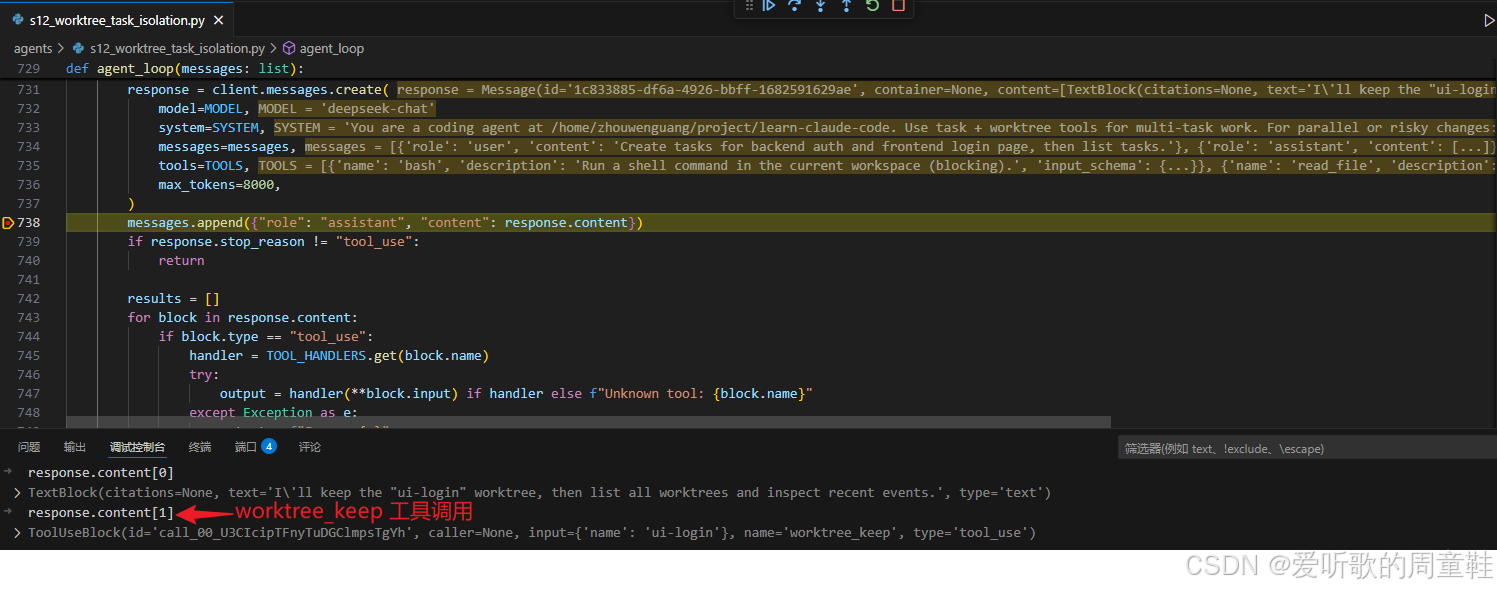
worktree_keep 模型响应
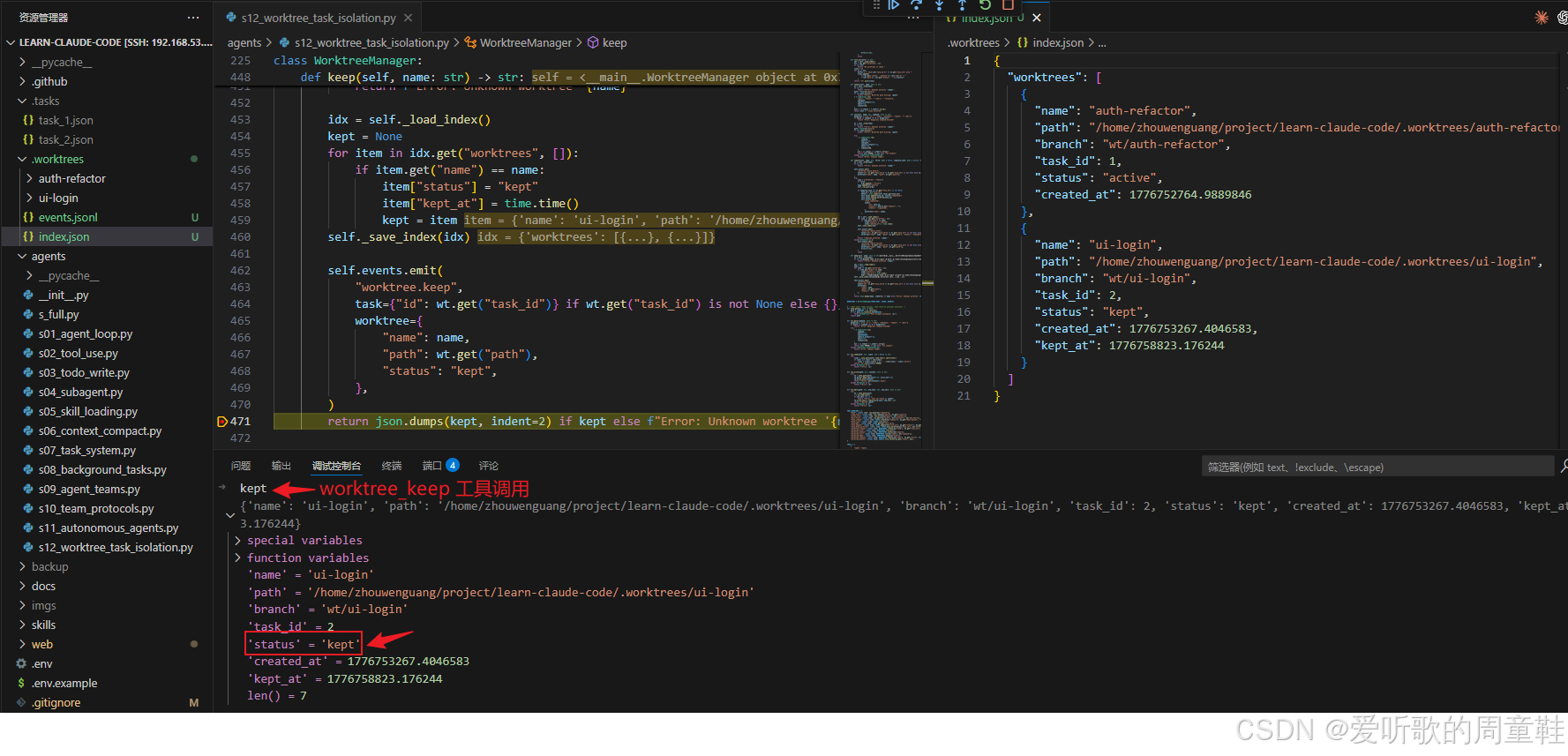
worktree_keep 工具执行
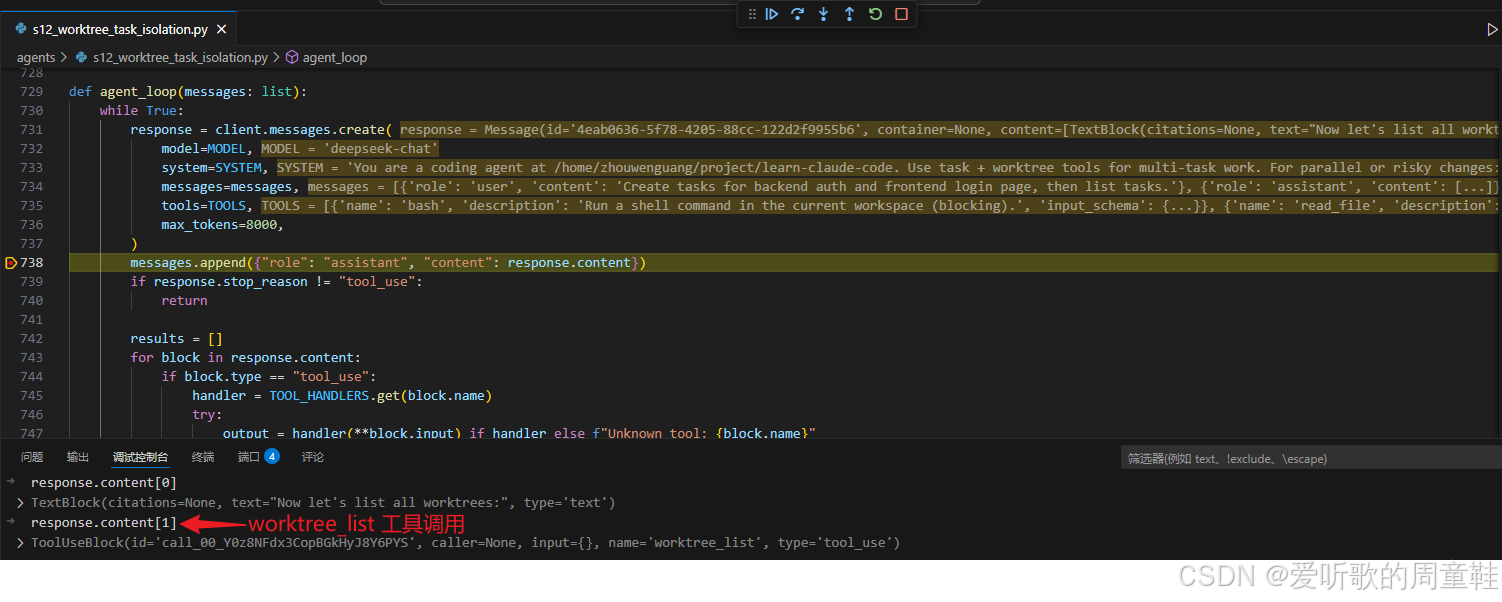
worktree_list 模型响应

worktree_list 工具执行结果
worktree_events 模型响应
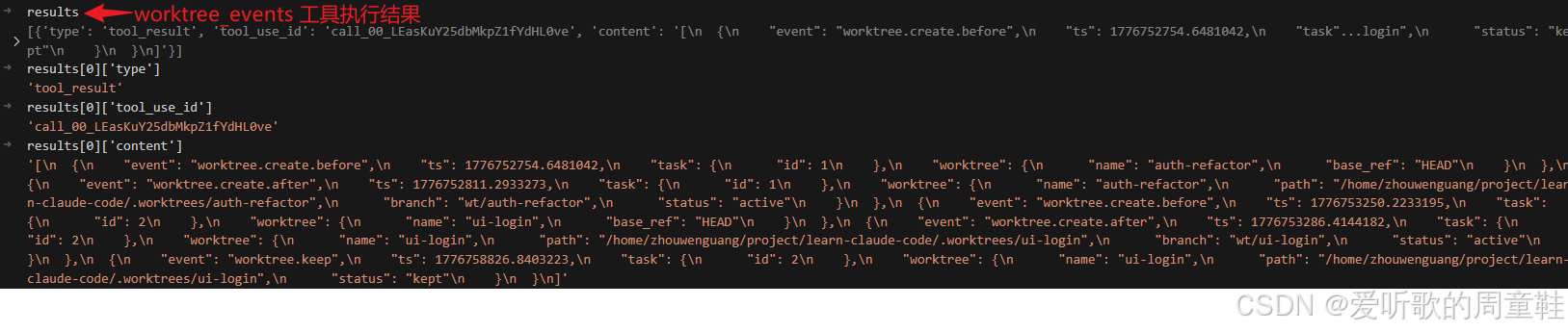
worktree_events 工具执行结果
这一组图说明 s12 新增的并不只是 "创建 lane" 和 "在 lane 中执行命令",而是一整套围绕 lane 生命周期的管理能力。
先看 worktree_keep,模型在响应里已经明确表示要 keep ui-login,随后调用:
python
worktree_keep(name="ui-login")对应代码里,WorktreeManager.keep() 做的事情并不是保留目录这么简单,而是会在 index.json 中找到这条 worktree entry,然后把:
python
item["status"] = "kept"
item["kept_at"] = time.time()写回去,同时还会发出:
python
self.events.emit("worktree.keep", ...)这也就解释了调试图里标出来的变化:ui-login 在 index.json 中已经从原先的 active 变成了 kept。也就是说,worktree 在 s12 中已经有了自己独立的生命周期状态机,而不是简单的 "存在 / 不存在"。
再看 worktree_list。模型调用这个工具之后,返回的结果里已经非常清楚地展示出两条 lane 当前的状态:
[active] auth-refactor -> ... task=1[kept] ui-login -> ... task=2
到了 s12,系统终于可以把 "当前有哪些执行 lane、它们各自处于什么状态、服务哪个任务" 清楚地列出来了。
最后再看 worktree_events,返回结果里已经不只是静态状态,而是一整串生命周期日志,比如:
worktree.create.beforeworktree.create.afterworktree.keep
等等。也就是说,s12 不只是给你当前状态,还给你这条 lane 是怎么一步步变成现在这样的。
最后我们在给定下面的提示词看看在 worktree 下 remove 的功能:
shell
Remove worktree "auth-refactor" with complete_task=true, then list tasks/worktrees/events.key 5: worktree remove 工具的调用
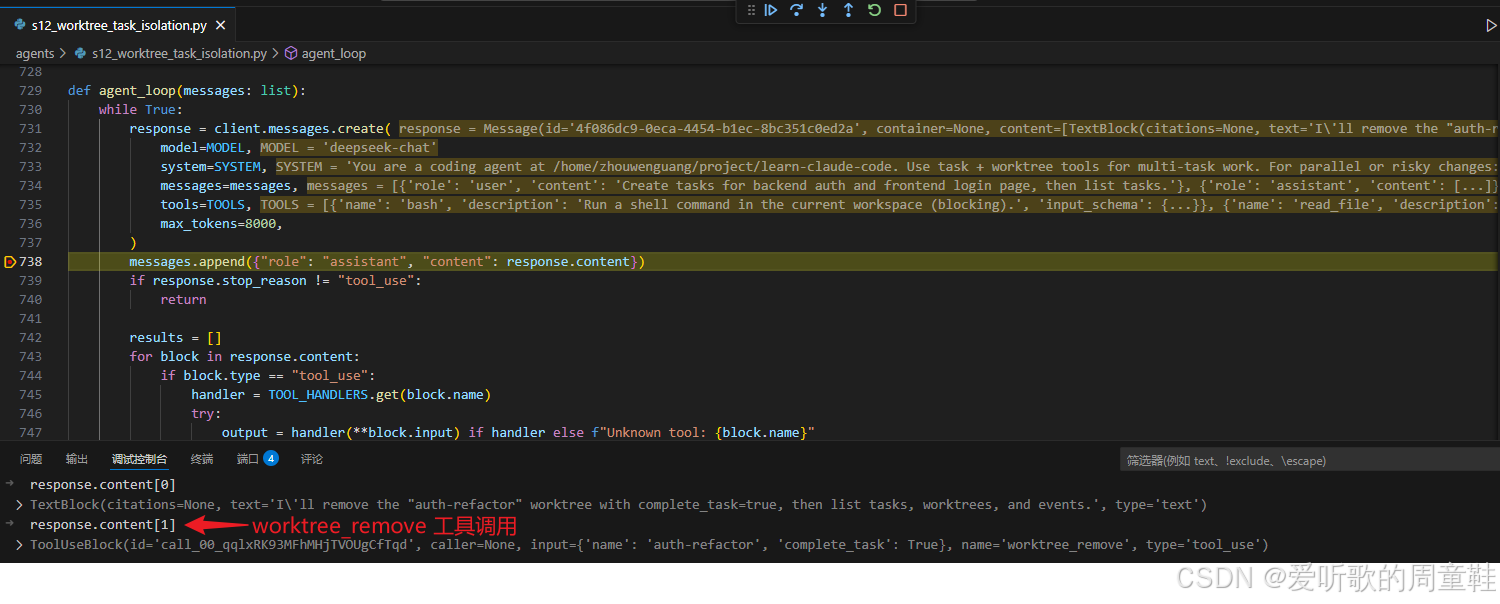
worktree_remove 模型响应
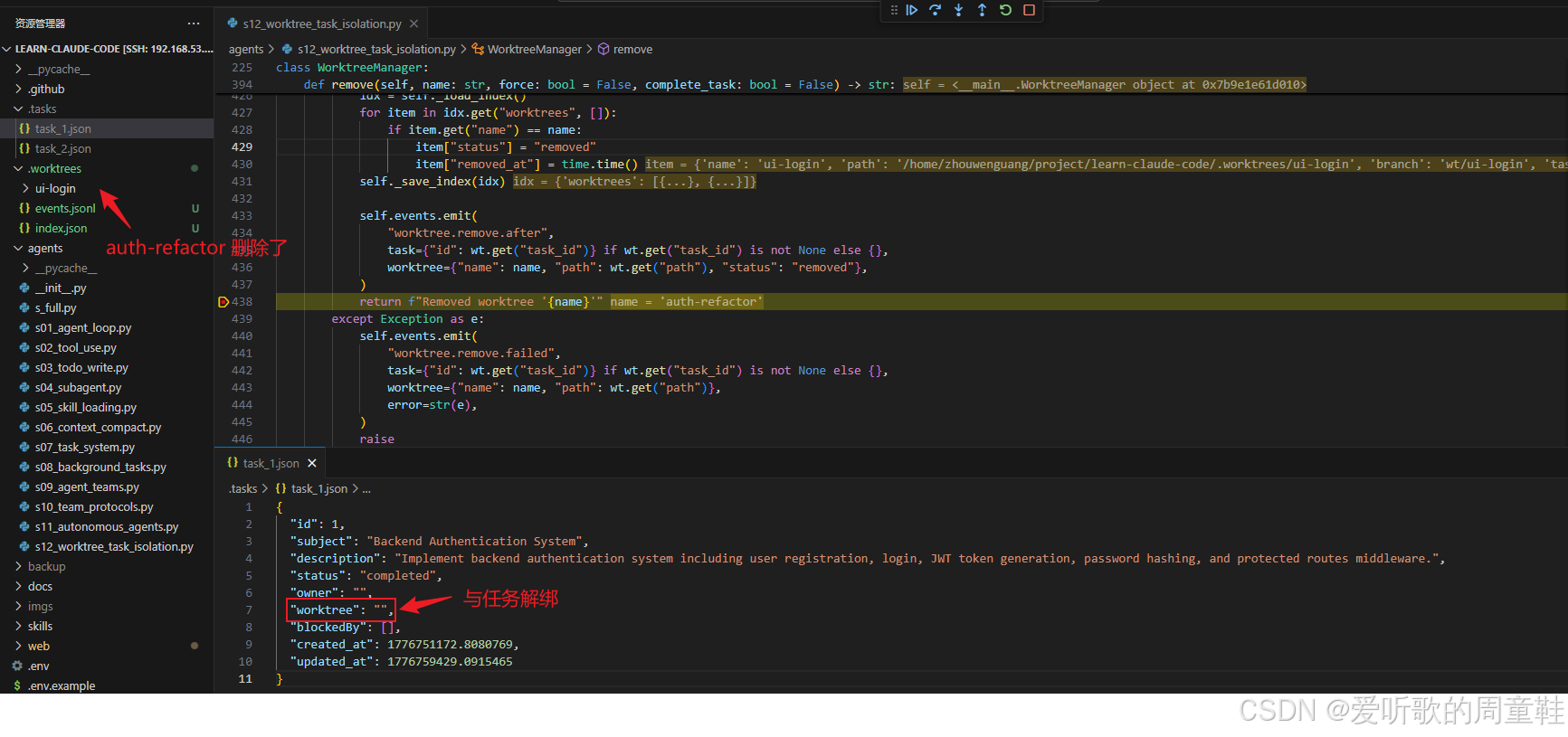
worktree_remove 工具执行结果
这一组图把 s12 的 closeout 逻辑展示得非常完整。先看模型响应,模型已经不只是说 "删除某条 worktree",而是明确决定调用:
python
worktree_remove(name="auth-refactor", complete_task=True)这里最关键的其实就是这个参数:
python
complete_task=True因为它说明在 s12 里,"移除执行空间" 和 "把任务正式收尾" 是可以联动的,但不是写死在一起的。也就是说,worktree 生命周期和 task 生命周期虽然相关,但并不是同一个状态机。
再看真正的 remove() 代码。它的执行顺序其实非常有代表性:先发出一个:
python
worktree.remove.before事件;然后调用真正的 git 命令:
python
git worktree remove <path>把物理 worktree 删除掉;如果 complete_task=True 且绑定了 task,就进一步执行:
python
self.tasks.update(task_id, status="completed")
self.tasks.unbind_worktree(task_id)
self.events.emit("task.completed", ...)也就是说,它会同时做三件事:
1. 把 task 状态推进到 completed
2. 把 task 中的 worktree 字段清空
3. 记录一个 task.completed 生命周期事件
最后,它还会在 index.json 中把对应 lane 的状态改成:
python
item["status"] = "removed"
item["removed_at"] = time.time()并再发出一个:
python
worktree.remove.after事件。
这也正好对应了你调试图里展示出来的结果:一方面,.worktrees/auth-refactor/ 这个目录已经消失了;另一方面,task_1.json 中的:
json
"status": "completed",
"worktree": ""也已经同步出现。也就是说,这一步并不是单纯 "删目录",而是一次完整的 双平面收尾动作:控制平面里的 task 被收尾,执行平面里的 lane 被关闭,生命周期日志里还会留下 before/after 轨迹。
这也是 s12 和前面所有章节最不一样的地方:系统第一次开始认真处理 "任务完成之后,执行空间怎么收尾" 这个问题。
所以,从这组调试结果回过头再看 s12 的代码,其实就会发现这一节真正新增的东西非常集中,而且都围绕一个问题展开:前面章节已经解决了任务如何创建、如何认领、如何自治推进,但如果这些任务最终还在同一个目录里执行,那整个并行协作系统就仍然不够工程化。
于是 s12 的代码给出的答案非常明确:
- 在
TaskManager.create()里,task 从一开始就预留worktree字段; - 在
WorktreeManager.create()里,系统把 lane 真正建成 git worktree,并写入index.json; - 在
worktree_run()里,命令的cwd第一次被路由到对应 lane 目录; - 在
keep()/remove()里,lane 拥有了自己的 closeout 生命周期; - 在
EventBus里,worktree 的演化过程开始被系统性记录。
也就是说,到了这一节,这个项目已经不再只是一个会创建任务、会让队友认领任务的协作系统了,它开始真正拥有一种更接近真实工程团队的执行观:
任务板仍然负责共享真相,但代码执行必须进入独立的 worktree lane;系统不仅要知道 "谁在做什么",还要知道 "谁在哪个目录里做什么、这个目录后来是被保留还是被移除"。
这其实正是 s12 相对于 s11 最关键的一步升级。
OK,以上就是 Worktree + Task Isolation 工作原理的完整分析了。
大家也可以试试文档里给出的这些 prompt,感受一下引入 Worktree之后,这个 Agent 团队在协作方式上会有什么变化:
1. Create tasks for backend auth and frontend login page, then list tasks.
2. Create worktree "auth-refactor" for task 1, then bind task 2 to a new worktree "ui-login".
3. Run "git status --short" in worktree "auth-refactor".
4. Keep worktree "ui-login", then list worktrees and inspect events.
5. Remove worktree "auth-refactor" with complete_task=true, then list tasks/worktrees/events.
6. 相对 s11 的变更
| 组件 | 之前 (s11) | 之后 (s12) |
|---|---|---|
| 协调 | 任务板 (owner/status) | 任务板 + worktree 显式绑定 |
| 执行范围 | 共享目录 | 每个任务独立目录 |
| 可恢复性 | 仅任务状态 | 任务状态 + worktree 索引 |
| 收尾 | 任务完成 | 任务完成 + 显式 keep/remove |
| 生命周期可见性 | 隐式日志 | .worktrees/events.jsonl 显式事件流 |
7. 小结
如果说 s11 最大的贡献,是让多 agent 团队第一次从 "需要中心持续派活" 升级成 "多个 teammate 能在共享任务板上自组织认领任务" 的自治系统;那么 s12 的贡献就是让我们进一步意识到:真正可靠的并行协作,不应该只在任务逻辑层分工,还必须在文件系统和命令执行层分 lane。
前面 s11 里,任务已经能被 Alice、Bob 这样的 autonomous teammates 自己发现、自己认领、自己推进,但从执行环境的角度看,它们仍然可能全部压在同一个共享工作区里;到了 s12,系统第一次正式引入了 worktree lane、.worktrees/index.json、task_bind_worktree、worktree_run、worktree_keep/remove 和 worktree_events 这一整套执行隔离机制。也就是说,任务板继续负责共享真相,worktree 开始负责执行空间映射,而 events 则把这些 lane 的生命周期变化变成可审计轨迹。
所以,s12 真正的价值并不只是 "让任务多了个 worktree 字段",也不只是 "多了几个新的工具名",而是第一次把这个项目从一个 已经会自治分工的协作团队 ,推进成了一个开始具备 执行级任务隔离能力的协作团队。从这一节开始,系统终于不只是知道 "谁在做什么",还开始知道 "谁在哪个 lane 里做什么"。而一旦这层边界被建立起来,多个并行任务之间的碰撞、污染和收尾混乱,才真正有了被系统性解决的可能。
这一步其实非常关键,因为它也为整个 Learn-Claude-Code 的 Collaboration 部分做了一个很漂亮的收束:团队不仅要能存在、能通信、能协议化、能自治找活,还必须能在真正动手执行时各走各的 lane。只有当逻辑分工和执行隔离同时成立时,多 agent 协作才真正像一个可扩展的工程系统。
OK,以上就是本期想要分享的全部内容了。
结语
本篇文章我们围绕 s12 Worktree + Task Isolation 这一节,从问题出发,结合流程图与代码实现,完整梳理了多 Agent 系统在执行层如何从 "共享工作区" 演进为 "多 lane 隔离执行"的工程形态。
如果说 s11 让我们第一次看到一个团队可以在没有持续中心调度的情况下,通过 idle → poll → claim → work 的循环自然完成任务分工,那么 s12 则进一步回答了一个更加现实的问题:即便分工已经发生,如果执行仍然混在一起,这种并行是否真正成立?
这一节给出的答案非常直接 --- 任务可以共享控制平面,但执行必须被显式隔离。通过 .tasks/、.worktrees/、index.json 与 events.jsonl 这三层结构,系统第一次将 "任务协调" "执行空间" "生命周期轨迹" 彻底拆分开来:任务板继续维护共享真相,worktree 负责承载独立执行环境,而事件流则记录整个执行过程的演化路径。至此,多 Agent 协作不再只是逻辑上的分工,而是落到了真实的工程边界上。
如果把 learn-claude-code 整个演进过程串起来,其实可以看到一条非常清晰的主线:从最初的单 Agent loop,到工具调用,再到任务建模、上下文管理、团队协作、协议约束、自主调度,直到最后的执行隔离,每一步都在做同一件事情 --- 把复杂系统拆解为局部可控的简单规则,并通过这些规则的组合,逐步构建出一个可扩展的多 Agent 工程系统。
通过 learn-claude-code 项目博主了解了构建 Agent 的一些知识,也知道了一个最小 Agent kernel 其实就是一个 while loop + one tool,后续的内容就是在这个上面的一些扩展,让 Harness 更加完善,同时也让整个 Agent 更加强大。
值得注意的是,该仓库在 4 月 8 日其实有一波大更新,之前的 s12 章节内容扩展到了 s19 节内容,包括 MCP 等内容,不过由于某些原因回撤了,等再次上线的时候有时间再看看吧,完结撒花🤗