目录
[重新认识 tuple](#重新认识 tuple)
[1. 为什么要有 tuple?](#1. 为什么要有 tuple?)
[2. tuple 的本质](#2. tuple 的本质)
[手写精简版 MyTuple](#手写精简版 MyTuple)
[1. 空基类特化](#1. 空基类特化)
[2. 递归主模板](#2. 递归主模板)
[3. 实现 get()](#3. 实现 get())
[1. tuple 的对齐与大小](#1. tuple 的对齐与大小)
[2. 布局分析](#2. 布局分析)
[操作 tuple 类型本身](#操作 tuple 类型本身)
[1. 类型查询与修改](#1. 类型查询与修改)
[2. 利用 index_sequence 实现万能访问](#2. 利用 index_sequence 实现万能访问)
[1. 多返回值与结构化绑定](#1. 多返回值与结构化绑定)
[2. 利用 std::apply 实现参数列表泛型编程](#2. 利用 std::apply 实现参数列表泛型编程)
[3. 类型列表与编译期算法](#3. 类型列表与编译期算法)
每当我们想从一个函数里返回三个值,却不得不在文件开头写一个只活五秒钟的 struct,还给它起了个名字叫 TempResult。
后来 std::tuple 来了,青天就来了。它允许我们随手写个 std::make_tuple(111, 3.33, "hello"),编译器就默默地帮我们把类型全推了。
重新认识 tuple
1. 为什么要有 tuple?
对于这个问题,我总会有那种明明有刀叉,却非要用筷子吃牛排的感觉。
C++ 的强类型是它骄傲的资本,但也因此干过无数反人类的事。假如我们写了个函数,美滋滋地算出了一组结果,想一把全部返回去,然后我们愣住了。
返回多个值这个在其他语言里像呼吸一样自然的操作,在 C++ 里却逼着我们先定义一个 struct,起个名字,写上四五个成员,可能还得配个构造函数。就为了临时传一组数据,我们得在代码里造一个一辈子只用一次的类型,荒唐,太荒唐了。
这时候 std::tuple 踩着七彩祥云......不,它没踩祥云,它是黑着脸来的。它是那种"既然你们这么懒,那只能我勤快点咯"。我们可以这样写:
cpp
auto get_info()
{
return std::make_tuple("老王", 18, 175.0, true); // 名字、年龄、身高、是否单身
}欸,连返回值类型都懒得写,auto 一推了事。
这在泛型编程里使用起来还蛮方便的:模板函数需要打包一堆不知道什么类型的玩意儿时,总不能让我们事先定义十几种结构体吧?tuple 让临时性异构数据聚合起来,终于不用再整那一堆结构体了。
还有一种情况就是我们写了个模板,想把一堆模板参数存起来稍后再用,或者逐个展开操作。没有 tuple,我们就得跟 std::integer_sequence 和某种诡异的递归模板玩命;有了 tuple 后,它就是那个现成的编译期容器,我们想在里面放什么类型和值就全凭心情。
所以,为什么需要 tuple?因为 C++ 的类型系统太...自行脑补,需要一个专门的容器来帮忙擦屁股。它解决了"我不想为一次性数据组合命名一个新类型"的麻烦,同时给模板元编程提供了一个能装下任意类型组合的盒子。
2. tuple 的本质
好了,现在让我们来瞅瞅它是由什么东西做成的。
很多人以为 tuple 内部就是个"动态数组,每个元素 void*"之类的玩意,那可就太小看 C++ 模板的倔强了。
tuple 的本质就一句话:它是一棵用递归继承构建的匿名结构体树,每一个叶子节点都是对真实数据的编译期布局,不浪费一个字节,不搞一丝运行时开销。
我们写 std::tuple<int, double, std::string>,编译器大致会给我们生出一个类似这样的玩意儿(简化版):
cpp
// 递归终点
template<size_t I, typename... Types>
class TupleImpl {};
// 递归继承,剥洋葱一样
template<size_t I, typename Head, typename... Tail>
class TupleImpl<I, Head, Tail...>
: public TupleImpl<I+1, Tail...>
{
Head value; // 当前元素就嵌在这里
};看到了吗?它通过一层层继承,把自己的身子串了起来,tuple<int, double, string> 最终会变成:
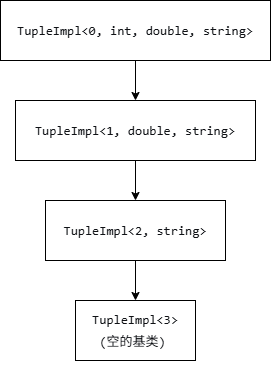
每个 TupleImpl 特化体里躺着它负责的那个元素(那个 Head value),因此内存布局上是紧凑的,没有额外指针,各个成员的内存位置通过 this 指针加上编译期计算的偏移自然可得。
这就是为什么 get<0>(t) 能零开销,它只是帮我们算好偏移,直接怼到我们想要的成员上,完全是一个被编译器藏起来的结构体成员访问。
这解释了另一个现象:tuple 的成员顺序和我们的声明顺序严格一致,且它是值语义的容器。它不像 Java 的元组那样需要装箱,所有东西都在栈上,或者随 tuple 对象整体分配在堆上,内聚性极高。拷贝、移动、销毁也都是靠每个成员的贡献,编译器自动递归生成,快得一匹。
但同时,这个实现也带来它最讨人厌的一面:编译慢、错误信息像天书。我们一旦用错 get<> 索引,编译器会沿着继承链一层层找,最后甩给我们一篇关于 tuple_element 小作文,恨不得连我们祖上三代代码都给标出来。
手写精简版 MyTuple
这玩意儿一旦拆开,其实也就那么回事。
1. 空基类特化
任何递归都得有个头,不然编译器就跟我们没完没了直到爆栈。我们的 MyTuple 是多继承的递归,所以终点就是一个啥也没有的空壳子。
cpp
template <typename... Types>
class MyTuple {};
template <>
class MyTuple<>
{
// 空空如也,连个屁都没有
// 但它的存在本身,是整个继承链的根
};为什么要搞个空的?因为想想我们的继承链:MyTuple<int, double> 要继承自 MyTuple<double>,而 MyTuple<double> 要继承自 MyTuple<>。到了 MyTuple<> 这里,如果再往下继承就成无底洞了,所以它必须站出来说:"就到这儿,我是终点站,都给我停!"
这玩意儿就叫递归基类特化 ,或者更亲切地,叫它躺平基类。它不存数据,不占内存,但却是整个 tuple 大厦能够盖起来的法定地基。
2. 递归主模板
好了,现在写那个真正干活的。
我们的设计很简单:每一层只存当前元素,然后把剩下的类型扔给父类去处理。
cpp
template <typename Head, typename... Tail>
class MyTuple<Head, Tail...>
: private MyTuple<Tail...>
{
Head value; // 这一层只负责头部元素
public:
// 构造函数
MyTuple() = default;
MyTuple(const Head& head, const Tail&... tail)
: MyTuple<Tail...>(tail...), // 先初始基类
value(head) // 然后是本层成员
{}
};晓得了波?MyTuple<int, double, std::string> 展开后是:
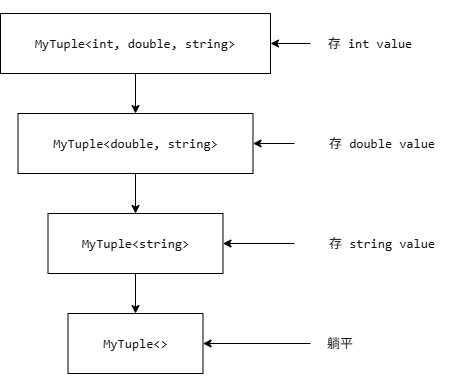
内存布局上,每个成员就嵌在自己那一层,顺序和我们声明的一模一样。我们也可以想象它就是编译器帮我们写了一个匿名的结构体,只不过这个结构体是通过继承关系串联起来的,而不是扁平地写在一层里。
3. 实现 get<N>()
现在有一个问题:我们怎么把元素取出来?
思路其实很简单:get<0> 就是要拿当前层(最顶层)的 value;get<1> 就往下剥一层父类,再拿那层的 value;get<2> 剥两层...... 翻译成代码,就是继续递归,直到下标为 0 时停手。
我们需要一个辅助模板,因为 get 函数模板不能偏特化,所以我们用一个静态工具类来做这个脏活。
cpp
// I 还没到 0,继续往下剥
template <size_t I, typename Tuple>
struct TupleGetter;
// I == 0,拿当前层的 value
template <typename Head, typename... Tail>
struct TupleGetter<0, MyTuple<Head, Tail...>>
{
static Head& get(MyTuple<Head, Tail...>& t)
{
return t.value; // 直接拿这一层的成员
}
static const Head& get(const MyTuple<Head, Tail...>& t)
{
return t.value;
}
};
// I > 0,把当前层剥掉,转嫁给父类,下标减一
template <size_t I, typename Head, typename... Tail>
struct TupleGetter<I, MyTuple<Head, Tail...>>
{
// 父类类型
using BaseType = MyTuple<Tail...>;
static auto& get(MyTuple<Head, Tail...>& t)
{
// 把当前对象强制转成父类引用,然后在父类上找 get<I-1>
return TupleGetter<I - 1, BaseType>::get(
static_cast<BaseType&>(t)
);
}
static const auto& get(const MyTuple<Head, Tail...>& t)
{
return TupleGetter<I - 1, BaseType>::get(
static_cast<const BaseType&>(t)
);
}
};现在还有一个小问题,回头看咱们写的递归主模板:
cpp
template <typename Head, typename... Tail>
class MyTuple<Head, Tail...>
: private MyTuple<Tail...>
{
...
};我们对于基类使用的是 private,但 TupleGetter 是一个外部工具类,它跟 MyTuple 没半毛钱血缘关系,没有权限去访问私有基类。
在我们这个精简版 MyTuple 里大可使用 public,但为了小小的封装可以使用友元把所有的特化都声明成朋友:
cpp
template <typename Head, typename... Tail>
class MyTuple<Head, Tail...>
: private MyTuple<Tail...>
{
template <size_t, typename>
friend struct TupleGetter;
...
};好吧,有时候封装性是好事,但封的太死连我们请的工具人都进不来,就不叫封装,改叫封闭得了。
最后我们再来个 get 函数整个漂亮的门面:
cpp
template <size_t I, typename... Types>
auto& get(MyTuple<Types...>& t)
{
return TupleGetter<I, MyTuple<Types...>>::get(t);
}
template <size_t I, typename... Types>
const auto& get(const MyTuple<Types...>& t)
{
return TupleGetter<I, MyTuple<Types...>>::get(t);
}然后我们就可以愉快的使用了:
cpp
MyTuple<int, double, std::string> t(111, 6.66, "Hello");
std::cout << get<0>(t) << std::endl; // 111
std::cout << get<1>(t) << std::endl; // 6.66
std::cout << get<2>(t) << std::endl; // Hello这里关键就在于那个 static_cast<BaseType&>(t),我们毫无心理负担地切掉当前层,把对象当成它父类去用,然后在父类上继续递归找。由于所有东西都在编译期算好,这个 static_cast 完全是零成本的指针偏移。
好了,现在我们手上有一个虽然简陋但五脏俱全的 MyTuple 了。它证明了 tuple 只是递归继承 + 编译期偏移计算这一套干净的组合。
内存布局与空基类优化
1. tuple 的对齐与大小
tuple 的大小,取决于它元素的类型、顺序,以及实现有多贼。
我们那个精简版 MyTuple,是直接用递归继承把每个元素嵌在各自那一层的 Head value 里。对于普通类型这没毛病,可一旦塞一个空类进去,比如 struct Empty {} 那恶心的玩意就来了:
cpp
sizeof(MyTuple<int, Empty, double>); // 24于是 MyTuple<int, Empty, double> 的大小大概会变成:int(4) + padding(4) + Empty(1) + padding(7) + double(8) = 24 字节。
对于这件事,还是'有空类占一字节'这条规矩惹的祸,明明是个空壳子,就因为要有独立地址硬生生啃掉我们 8 字节的布局,这是赤果果的浪费!
但是真正的 std::tuple 没这么傻,标准库的实现者早就恨透了这点,所以他们掏出了 **EBO(Empty Base Optimization,空基类优化)**这件马甲。
原理其实很鸡贼:如果我们从空类继承,而不是把它当成员,编译器就可以让基类子对象不占空间(标准允许基类子对象和派生类共用地址,只要类型不同即可)。
所以真正厚重的 tuple 会把每个元素包装一下:遇到空类型,就让它当基类;遇到非空类型,就老老实实当成员。这样一来,空元素就彻底隐身了。
这也顺便点拨了对齐逻辑:tuple 的对齐值,通常等于各元素对齐要求的最大值,因为每个元素要么嵌在成员里,要么嵌在 EBO 基类里,都一样受对齐约束,整个对象的大小会在此基础上补齐到该对齐值的倍数。
2. 布局分析
现在我们拿这个具体的例子开刀:
cpp
struct Empty {}; // sizeof(Empty) == 1,但作为基类可以为 0
std::tuple<int, Empty, double> t;在一些主流编译器下,这个小东西的大小极可能是 16 字节,而不是刚才那版的 24。省哪儿了?省的就是 Empty 被 EBO 压没的那些填充。
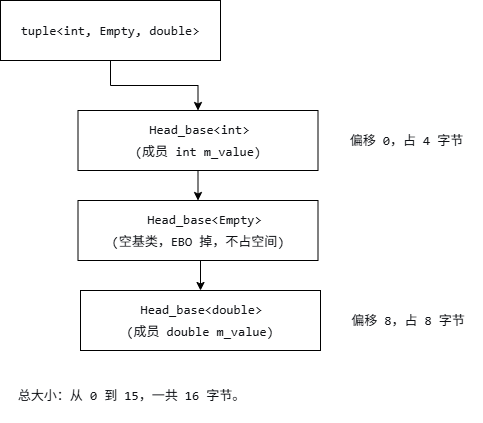
那偏移 4 到 8 之间那 4 个字节被 int 后的对齐填充 吃掉了,因为后面紧跟着要求 8 字节对齐的 double,所以 int 后面得塞 4 字节 padding,让 double 老实呆在 8 的倍数上。
那 Empty 呢?它就像个幽灵,贴在 int 后面,但由于 EBO 的存在它不占实实在在的字节,没有把布局撑大,填充仍然是 4 字节,整体大小 16。
如果顺序换一下呢?比如 std::tuple<Empty, int, double>,很多实现可能还是 16(Empty 在最前面完全不占空间,int 偏移 0,再加填充,double 偏移 8)。
不过这是实现细节,有些实现会把空基类永远塞在最前面,有些则可能调整。标准只保证元素顺序和构造/析构顺序一致,没规定物理布局,但有 EBO 后空类型通常就白送我们了。
操作 tuple 类型本身
1. 类型查询与修改
标准库其实已经给了我们两件趁手的小工具,专门用来偷窥 tuple 的类型底裤。
查询
cpp
using T = std::tuple<int, double, std::string>;
size_t sz = std::tuple_size_v<T>; // 3,有几个元素
using second_t = std::tuple_element_t<1, T>; // double,第二个元素类型没有运行时开销,全是 sizeof... 和类型萃取那套东西。
tuple_size 就是一个个数包里的参数个数,tuple_element 就是递归剥到第 N 个拿出来。
修改
如果我们想在 tuple 类型前面加一个新类型,拼成新 tuple,标准里没有现成的 push_front,但我们可以用 std::tuple_cat 整点活:
cpp
template <typename T, typename Tuple>
struct push_front;
template <typename T, typename... Ts>
struct push_front<T, std::tuple<Ts...>>
{
using type = decltype(std::tuple_cat(std::declval<std::tuple<T>>(),
std::declval<std::tuple<Ts...>>()));
};
using new_tuple = push_front<int, std::tuple<double, char>>::type;
// new_tuple 就是 std::tuple<int, double, char>这本质上就是让编译器帮我们做一次类型推导,根本不运行,纯在编译期干活。我们也可以完全不依赖 tuple_cat,自己用参数包拼接:
cpp
template <typename T, typename Tuple>
struct push_front;
template <typename T, typename... Ts>
struct push_front<T, std::tuple<Ts...>>
{
using type = std::tuple<T, Ts...>;
};有了这些,我们就掌握了在编译期对 tuple 类型做增删改查的基本功,后面写任何复杂的元函数,底子都是这玩意。
2. 利用 index_sequence 实现万能访问
一个很具体的问题:我们想对一个 tuple 的所有元素逐个执行一个操作,打印也好,传给函数也好,但 get<I> 的 I 必须是编译期常量,没法用运行时的 for 循环。
怎么办?我们得在编译期生成一串从 0 到 N-1 的索引,然后用一种语言支持的方式把它们展开。
std::index_sequence<0,1,2,...,N-1> 就是这个索引串,它是类型,承载着一包编译期整数。我们可以通过 std::make_index_sequence<N> 创造一个。
cpp
template <typename Tuple, typename Func, size_t... Is>
void for_each_impl(Tuple&& t, Func&& f, std::index_sequence<Is...>)
{
// 把 f 作用于每个 get<Is> 上,逗号运算符保证顺序
(f(std::get<Is>(std::forward<Tuple>(t))), ...);
}
template <typename Tuple, typename Func>
void for_each(Tuple&& t, Func&& f)
{
for_each_impl(
std::forward<Tuple>(t),
std::forward<Func>(f),
std::make_index_sequence<std::tuple_size_v<std::decay_t<Tuple>>>{}
);
}用起来:
cpp
auto t = std::make_tuple(1, 3.14, "hello");
for_each(t, [](const auto& x) { std::cout << x << std::endl; });那个 (f(get<Is>...), ...) 折叠表达式在编译期瞬间展开成一个用逗号串联的调用序列,编译器老老实实帮我们把循环展开了,零开销,每个元素都享受类型安全。
但是为了这么个展开,我们又得去理解一大堆东西,只能说不愧是 C++。
应用与小巧思
这些东西可能不是天天用,但需要用的时候能想到就行。
1. 多返回值与结构化绑定
多返回值这事,就不啰嗦了,直接上代码:
cpp
auto get_info()
{
return std::make_tuple("老王", 18, 175.0);
}
auto [name, age, height] = get_info(); // C++17 结构化绑定结构化绑定是 C++ 为了tuple 量身定做的语法糖,它让我们拆包的时候不用声明 std::tuple_element,直接靠 auto 推。
如果我们需要引用原 tuple 内部的东西,就用 auto& ...,不会产生意外的拷贝。这一点比 std::tie 安全,因为 tie 不小心就会引到临时对象上。
2. 利用 std::apply 实现参数列表泛型编程
std::apply 把 tuple 炸开喂给函数,瞬间就让函数拥有了运行时决定的参数列表。
但如果反过来想,我们可以写一个函数,接受任意参数的 tuple,然后把它转成调用某个具体函数,这不就是一种参数列表的泛型编程吗?
实现一个通用的延迟调用
比如我们有一堆不同类型的参数,想一会再用它们调用某个函数,但又不想写一堆重载。
cpp
template <typename Func, typename... Args>
class deferred_call
{
Func f;
std::tuple<Args...> args;
public:
deferred_call(Func f, Args... args) : f(std::move(f)), args(std::move(args)...) {}
auto execute()
{
return std::apply(f, args);
}
};这样我们就可以把参数打包,execute() 时再展开。
3. 类型列表与编译期算法
tuple 不仅能装值,它在元编程里的另一半灵魂,是类型列表。
我们可以把 std::tuple<int, double, string> 完全当成一个编译期的类型容器,值只是附加的。标准库里有 tuple_element、tuple_size 这些原始工具,但我们完全可以基于 tuple 实现一套编译期算法。
查找类型在 tuple 里的位置
cpp
template <typename T, typename Tuple>
struct index_of;
template <typename T, typename... Ts>
struct index_of<T, std::tuple<T, Ts...>>
: std::integral_constant<size_t, 0> {};
template <typename T, typename U, typename... Ts>
struct index_of<T, std::tuple<U, Ts...>>
: std::integral_constant<size_t, 1 + index_of<T, std::tuple<Ts...>>::value> {};如果找不到,别忘记兜底处理,比如给个 -1 啥的。
把每个类型套上一个外壳
假设我们要为 tuple 里的每个类型生成对应的 unique_ptr:
cpp
template <template <typename> class F, typename Tuple>
struct transform_tuple;
template <template <typename> class F, typename... Ts>
struct transform_tuple<F, std::tuple<Ts...>>
{
using type = std::tuple<F<Ts>...>;
};
using ptr_tuple = transform_tuple<std::unique_ptr, std::tuple<int, double>>::type;这种纯类型体操,和容器里实际的值一点关系没有,但是能帮我们生成对应的容器类型。
结尾
tuple 是好工具,但别把它当 struct 用。
如果我们的数据成员有清晰的名字和语义,别手懒,写个结构体比什么都强。tuple 适合那些临时的、泛型的、不需要名字的场合,或者模板深处我们实在没法提前知道类型的地方。
用对了,爽歪歪;用歪了,那就一起崩溃吧( ◜◡‾)。