C语言数据在内存中的存储:整型与浮点型的秘密
数据在内存中以二进制形式存储,但整型和浮点型的存储方式截然不同。本文将深入讲解整型的原码、反码、补码,揭示大小端字节序的本质,并通过大量练习帮助理解截断与提升,最后解析浮点数遵循的IEEE754标准,带你彻底搞懂数据在内存中的真实面貌。
目录
一、整数在内存中的存储
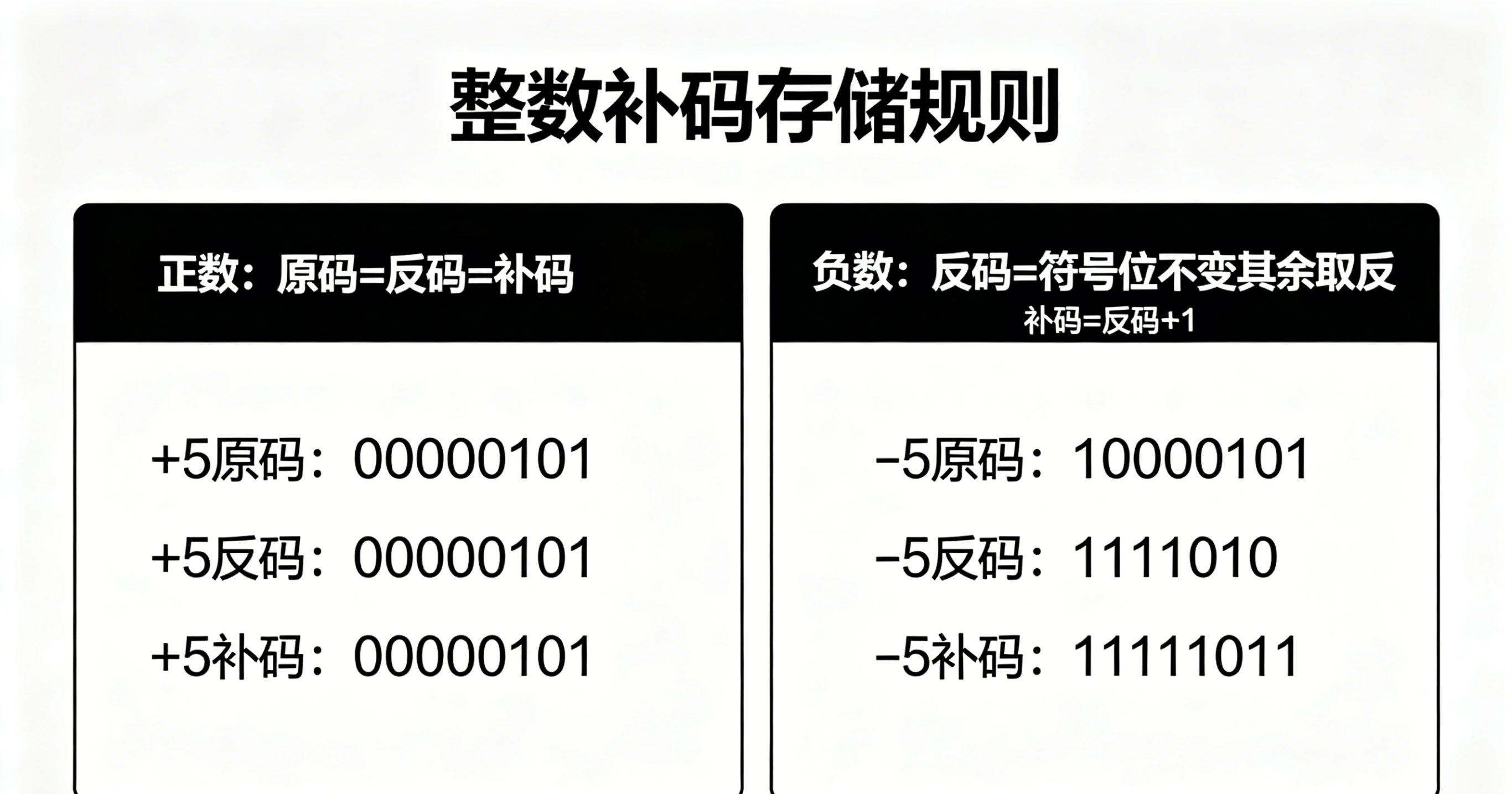
整数的二进制表示有原码 、反码 、补码三种形式:
- 正数:原码、反码、补码相同。
- 负数:原码符号位为1,数值位为绝对值的二进制;反码符号位不变,其余取反;补码为反码+1。
计算机中整数一律使用补码存储。原因:
- 符号位和数值域统一处理。
- 加减法统一为加法运算(CPU只有加法器)。
- 补码与原码转换过程相同,无需额外硬件。
示例:int a = 0x11223344; 在内存中调试发现字节顺序是倒着存储的(如 44 33 22 11),这就涉及大小端问题。
二、大小端字节序和字节序判断

2.1 什么是大小端?
对于超过一个字节的数据,存在存储顺序问题:
- 大端模式 :数据的低字节 保存在高地址 ,高字节 保存在低地址。
- 小端模式 :数据的低字节 保存在低地址 ,高字节 保存在高地址。
(图示:0x11223344 在小端中存储为 44 33 22 11,在大端中为 11 22 33 44)
2.2 为什么有大小端?
因为寄存器宽度大于一个字节时,需要安排多字节存储顺序。不同架构选择不同:X86为小端模式,KEIL C51为大端,ARM可配置。
2.3 经典练习
练习1:判断当前机器字节序(百度笔试题)
c
int check_sys() {
int i = 1;
return *(char*)&i; // 取第一个字节,1为小端,0为大端
}练习2:char类型截断与提升
c
char a = -1; // 补码 11111111
signed char b = -1; // 同a
unsigned char c = -1; // 11111111,作为无符号,值为255
printf("%d,%d,%d", a, b, c); // -1,-1,255练习3:char范围与%u打印
c
char a = -128; // 补码 10000000
printf("%u\n", a); // 整型提升为 11111111111111111111111110000000 → 4294967168
char b = 128; // 128超出char范围(-128~127),存为 -128
printf("%u\n", b); // 同样输出 4294967168练习4:字符数组与strlen
c
char a[1000];
for(i=0; i<1000; i++) a[i] = -1-i;
printf("%d", strlen(a)); // 遇到第一个0停止,数组从-1,-2,...到-128,127,126...0,共255个非0练习5:无符号循环陷阱
c
unsigned char i = 0;
for(i=0; i<=255; i++) // 无符号char永远≤255,死循环
printf("hello\n");
unsigned int i;
for(i=9; i>=0; i--) // i>=0永远为真,死循环
printf("%u\n", i);注意:无符号整数永远非负,循环条件需谨慎。
练习6:指针与字节偏移
c
int a[4] = {1,2,3,4};
int *ptr1 = (int*)(&a + 1);
int *ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);&a+1跳过整个数组,ptr1[-1]指向最后一个元素 →4(int)a + 1将数组首地址转为整数后+1字节,再转为int*,指向从第二个字节开始的内存,在小端 环境下,取出的整数为0x02000000,即2000000(输出小端机器上为2000000,实际依赖环境)。
三、浮点数在内存中的存储
3.1 一个令人困惑的例子
c
int n = 9;
float *pFloat = (float*)&n;
printf("%d\n", n); // 9
printf("%f\n", *pFloat); // 0.000000
*pFloat = 9.0;
printf("%d\n", n); // 1091567616
printf("%f\n", *pFloat); // 9.000000为什么同样的内存,整型和浮点型解读结果完全不同?因为浮点数遵循IEEE754标准。
3.2 IEEE754浮点数表示
任意二进制浮点数V可表示为:
V = (-1)\^S \\times M \\times 2\^E
S:符号位,0正1负。M:有效数字,范围1 ≤ M < 2。E:指数。
对于32位float :1位S,8位E,23位M。
对于64位double:1位S,11位E,52位M。
特殊规则
- M的存储 :因为
1 ≤ M < 2,默认第一位总是1,可以舍去,只保存小数部分,读取时再补回。这样多了一位精度。 - E的存储 :E为无符号整数,但实际可正可负,所以存时加上中间值(float加127,double加1023)。
- E全0 :表示非常接近0的数字,此时M不再加1,还原为0.xxxxx,指数为
1-127(或1-1023)。 - E全1:若M全0,表示±无穷大。
3.3 题目解析
为什么9变成浮点数是0.000000?
9的二进制补码:0000 0000 0000 0000 0000 0000 0000 1001
按float拆解:S=0,E=00000000(全0),M=000...1001。
由于E全0,浮点数为 (-1)^0 × 0.000...1001 × 2^(-126),极小的正数 → 0.000000。
为什么9.0变成整数是1091567616?
9.0的二进制:1001.0 → 1.001 × 2^3
S=0,E=3+127=130(二进制10000010),M=001后面补20个0。
二进制序列:0 10000010 00100000000000000000000
按整数解析(补码)即为1091567616。
总结:整型数据在内存中以补码存储,大小端影响多字节顺序;char类型参与运算需注意截断与整型提升,无符号循环易死循环。浮点数遵循IEEE754标准,其存储与整型完全不同,解读方式取决于类型。掌握这些知识,能帮助我们理解指针类型转换、数据溢出、字节序等底层行为,写出更健壮的代码。