**摘要:**随着AI算力密度突破百千瓦级,传统风冷与单相液冷已逼近能力边界,温度波动导致GPU降频、算力虚标、PUE居高不下。新一代泵驱两相液冷方案通过相变控温与芯片级±1℃精准调节,结合背板换热与智能运维平台,实现热降频减少90%、PUE稳定低于1.1、TCO优化20%以上。模块化设计支持存量机房72小时在线改造,为未来功率翻倍预留余量。热管理正从辅助系统升级为决定算力兑现效率的核心基础设施。

一、行业正在经历一场静默的升级:算力密度飙升,传统冷却逼近极限
1**.AI算力爆发,机柜功率迈入****"百千瓦级"**已成为常态
近年来,AI训练集群和智算中心的部署速度远超预期。据DCD与Network World数据显示,2026年全球已有超过30%的新建AI机柜单柜功率突破120kW。这意味着,一台标准机柜产生的热量相当于数十台家用空调全负荷运行。在这样的热流密度下,传统的风冷和单相液冷系统正面临前所未有的压力。
2**.**单相液冷并非失效,但已逐渐触及能力边界
单相液冷在过去十年推动了数据中心能效的显著提升,PUE普遍降至1.3左右。然而,其本质仍是依靠液体显热吸热,换热效率受限于流体比热容。面对局部热峰频繁波动、芯片瞬时功耗剧烈变化的AI负载,单相系统往往需要大幅提升流量或依赖额外风冷补强,导致泵耗上升、系统冗余增加、温控响应滞后。
3**.行业焦点已从"能不能降温"转向"能不能稳住温度"**
今天的客户不再满足于"设备不烧毁",而是追求"算力持续满载释放"。真正制约高密度部署的,已不是电力或空间,而是热管理能否支撑长期稳定的运行质量。温度波动过大,会导致GPU频繁热降频,AI训练任务中断重算,推理延迟激增------这直接拉高了单位算力的TCO(总拥有成本)。
核心判断:液冷竞争的下半场,比的不是谁更"冷",而是谁更"稳"。
二、客户面临的五大真实困境,暴露了传统方案的深层短板
1**.温度波动导致算力"虚标"------**理论性能无法兑现
许多数据中心反映,尽管硬件规格支持高并发计算,但在实际运行中,因散热响应滞后,芯片频繁触发保护机制,实际利用率不足70%。这种"看得见、用不上"的算力浪费,成为项目ROI的最大黑洞。
2**.改造风险高------**停机一天,损失百万
对于大量已投入运营的数据中心而言,升级冷却系统意味着停机、搬迁、重构管网。传统液冷改造动辄需要数周,期间业务中断带来的经济损失远超设备投入。
3**.**冷却能耗占比攀升,PUE优化陷入瓶颈
即便采用单相液冷,冷却系统的泵组、风扇和制冷机组仍消耗大量电能。部分机房的CLF(Cooling Load Factor)高达0.2以上,严重拖累整体PUE表现,难以满足"双碳"考核要求。
4**.系统割裂------设备联网≠**智能运维
不少项目虽部署了监控平台,但仅实现数据采集,缺乏动态调控能力。温度异常仍需人工干预,故障预警滞后,无法实现预测性维护,运维效率并未实质性提升。
5**.**硬件升级快,冷却系统跟不上迭代节奏
AI芯片每18个月功率翻倍,而冷却基础设施建设周期长达2--3年。客户迫切需要一种既能适配当前密度、又能为未来扩容预留空间的热管理架构。
核心判断:客户真正购买的,不是一套冷却设备,而是一种"长期稳定释放算力"的能力。

三、系统级热管理方案浮现:以精准控温为核心的新一代基础设施
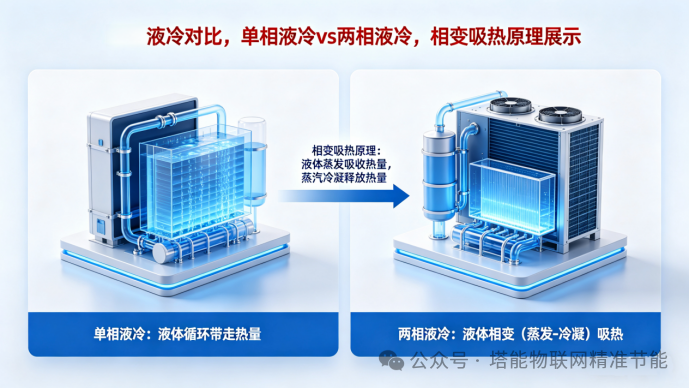
1**.技术跃迁:从"显热吸热"到"相变控温"**
新一代解决方案采用泵驱两相液冷技术,利用液体在微通道冷板内发生相变(液态→气态)时吸收大量潜热的特性,实现超高换热效率。相比单相系统,同等热负荷下流量需求仅为1/5~1/9,大幅降低泵耗与管路负担。
更重要的是,两相换热过程中温度几乎恒定,天然具备±1℃以内的芯片级温控能力。无论负载如何跳变,都能将CPU/GPU维持在最佳工作区间,从根本上消除热降频现象。
2**.架构革新:芯片级+背板级+**站级三层协同
该方案并非单一产品堆砌,而是构建了一个从芯片到机房的完整热管理闭环:
芯片级:泵驱两相冷板直接贴合GPU/CPU,实现定点高效散热;
背板级:两相换热背板回收服务器排出的热空气,进一步降低机柜整体热负荷;
站级:集成冷站通过AI算法优化冷源运行策略,实现自然冷却最大化、制冷机补冷最小化。
三层能力贯通:确保从微观芯片到宏观机房的温区始终受控。
3**.**改造友好:模块化设计支持在线部署
针对存量机房,方案采用预制化模块与兼容性接口设计,可在不停机状态下完成冷板替换与管路接入。多个实际案例显示,改造周期可压缩至72小时内,最大程度保障业务连续性。
更关键的是,仅通过热管理升级,即可释放现有机房30%以上的潜在算力,无需新增电力或空间投入,显著提升资产利用率。
4**.平台赋能:物联网SaaS实现"可管、可控、可运营"**
所有硬件设备接入统一的物联网智能运维平台,实现:
实时监测:温度、流量、压力、能耗等参数秒级采集;
动态调控:根据负载自动调节泵速与沸点设定;
故障预警:AI模型识别早期泄漏、堵塞等隐患;
节能优化:基于气象数据与电价策略,自动切换运行模式。
平台不再只是"看数据",而是驱动整个热管理系统持续进化。
核心判断:未来的热管理,不是辅助系统,而是决定算力兑现效率的核心基础设施。
四、最终交付的不是产品,而是一套面向未来的系统能力
1**.算力更稳:热降频减少90%****,AI任务连续性提升**
实测数据显示,在采用该方案的AI训练集群中,GPU因高温触发的降频次数下降超过90%,单次训练任务平均耗时缩短15%以上,模型迭代效率显著提升。
2**.成本更低:PUE稳定在1.1以下,TCO优化达20%+**
通过高效换热与自然冷却最大化,多个项目年均PUE控制在1.1以内,局部pPUE低至1.05。结合泵耗降低与设备寿命延长,三年综合TCO下降超过20%。
3**.扩容无忧:为120kW+**机柜预留热管理余量
系统设计支持未来三年内机柜功率翻倍升级,避免因冷却能力不足而导致二次改造,真正实现"一次投入,长期受益"。
4**.运维更轻:从"被动抢修"走向"预测性运营"**
平台记录全生命周期运行数据,结合机器学习预测关键部件寿命,提前安排维护计划。某客户反馈,运维人力投入减少40%,故障平均响应时间从小时级降至分钟级。
5**.**双碳达标:支撑绿色数据中心建设与能效考核
低PUE+零水患(无水冷设计)+磁悬浮主机+可再生能源适配,全面契合东数西算、双碳政策对新型算力基础设施的要求。
核心判断:真正有竞争力的方案,从来不靠参数碾压,而是以系统思维解决客户的长期运营难题。
这场由AI驱动的算力革命,正在倒逼基础设施全面升级。面对高密度、高波动、高可靠的新要求,简单的"降温"已不足以应对挑战。唯有将航天级热控技术、模块化系统架构、物联网智能平台深度融合,才能构建起支撑未来十年算力发展的坚实底座。这不是一次技术修补,而是一场从"散热"到"控温"、从"设备"到"服务"的范式转移。