在 Android Clean Architecture 或常见分层设计中,很多人都会遇到一个问题:
每个 Repository 都需要配一个 DataSource 吗?
不少教程默认给出这样的结构:
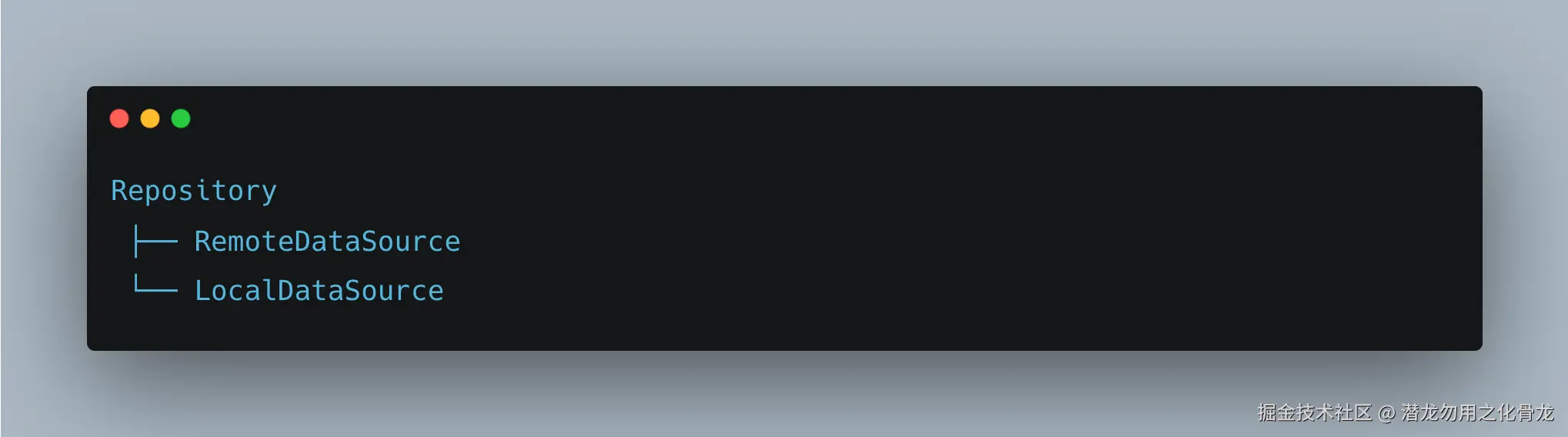
看起来很"标准",但在实际项目中,如果不加思考地套用,很容易导致过度设计。
这篇文章帮你彻底理清:什么时候需要 DataSource,什么时候不需要。
一、先搞清本质:Repository 和 DataSource 是什么关系?
Repository 的职责
Repository 本质上是:
数据的统一入口 + 数据调度中心
它解决的是:
- 上层不关心数据来源
- 多数据源的统一封装
- 数据获取策略(缓存 / 网络)
DataSource 的职责
DataSource 更纯粹:
只负责"拿数据"
它通常是:
- API 封装(RemoteDataSource)
- 数据库访问(LocalDataSource)
👉 不做决策,不做业务逻辑
核心区别一句话
- Repository:做决策
- DataSource:做执行
二、什么时候「需要 DataSource」?
当你的数据逻辑开始变复杂时,DataSource 才真正有价值。
✅ 场景 1:多数据源
例如:
- 网络(API)
- 本地数据库(Room)
- 内存缓存
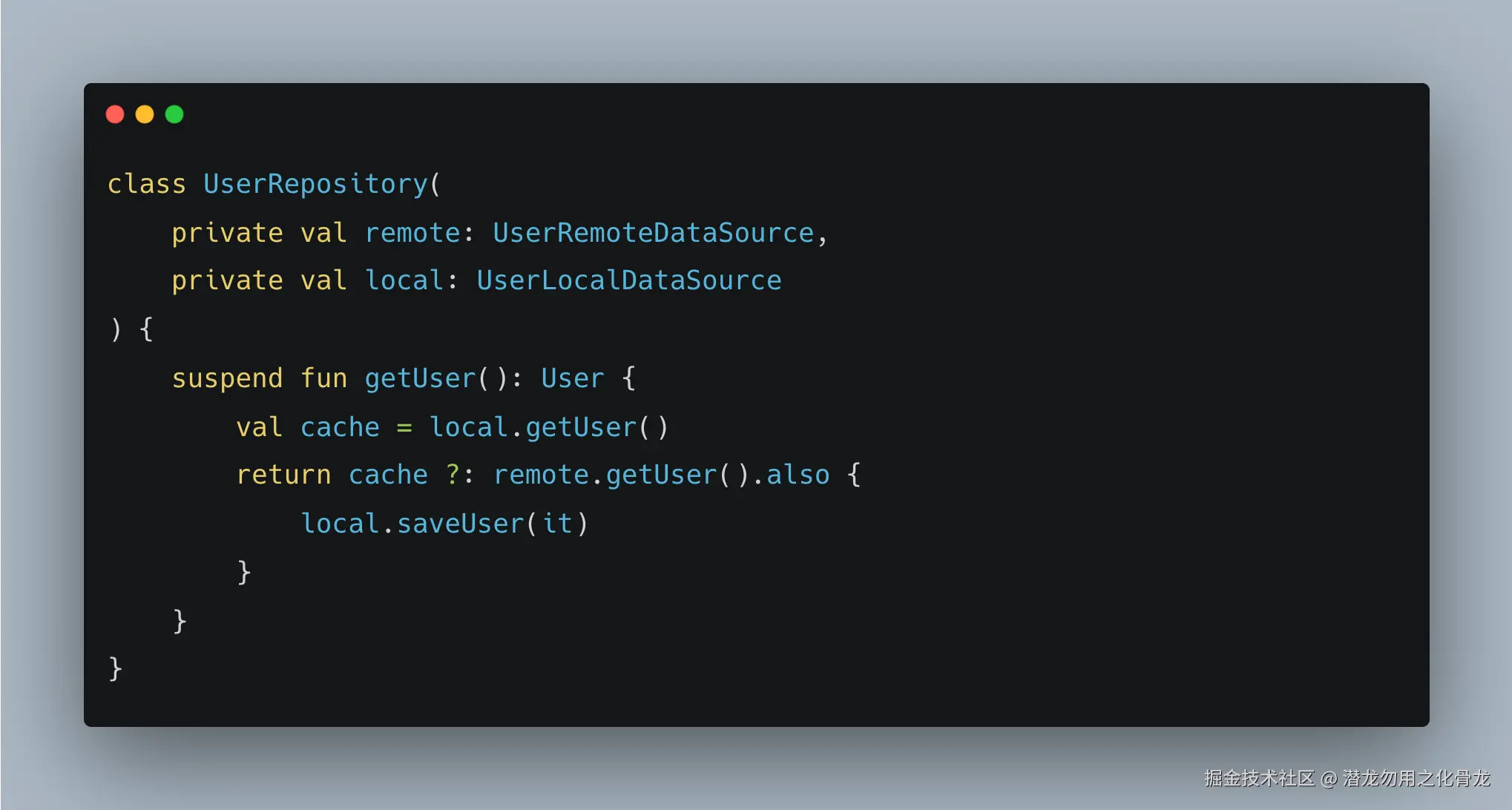
👉 这种情况下:
- DataSource 负责"取数据"
- Repository 负责"用哪个数据"
✅ 场景 2:复杂业务逻辑
例如:
- cache → network → fallback
- 多接口组合
- 数据合并
👉 如果全部写在 Repository:
很快就会变成"上百行大类"
👉 这时候拆 DataSource 是降低复杂度的手段
✅ 场景 3:数据逻辑复用
多个 Repository 共享:
- 同一个 API 封装
- 同一个缓存逻辑
👉 DataSource 可以复用,避免重复代码
三、什么时候「不需要 DataSource」?
这是很多人容易踩坑的地方。
❌ 场景 1:只有一个数据源
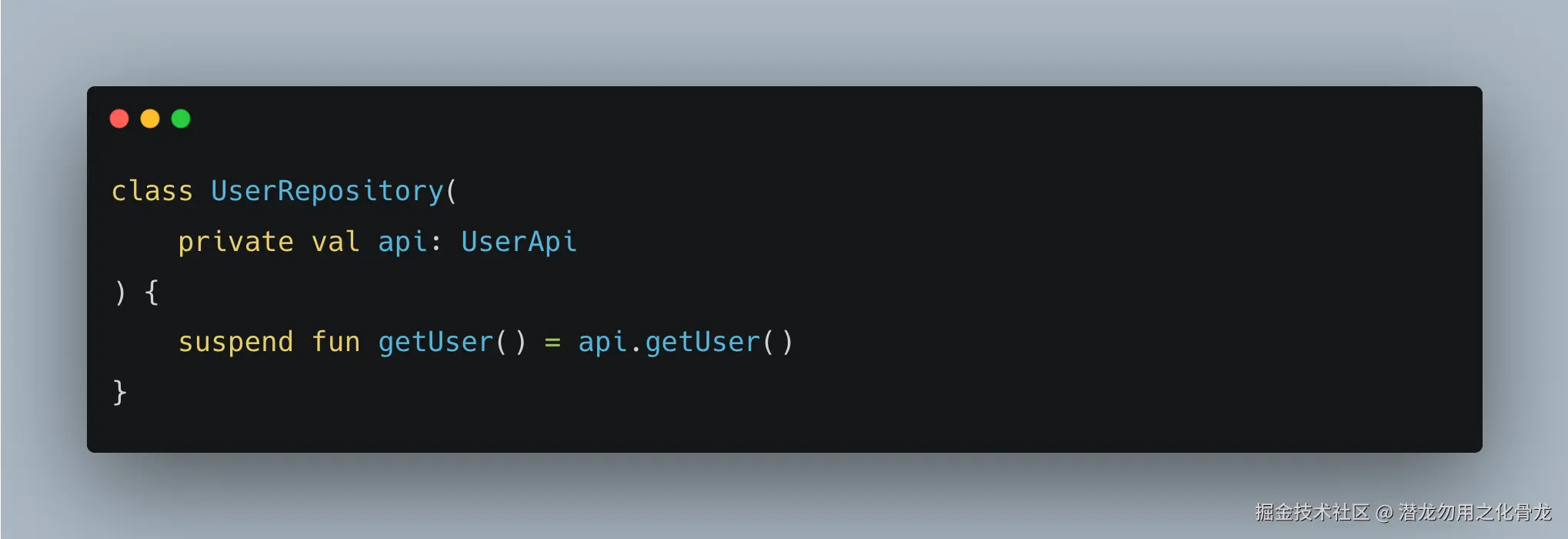
👉 这种情况下再加一层:
没有任何收益,只是增加复杂度。
❌ 场景 2:逻辑非常简单
- 没有缓存
- 没有策略
- 没有组合
👉 Repository 直接调用 API / DAO 即可
❌ 场景 3:为了"符合架构图"
很多人是这样写代码的:
"教程里有 DataSource,我也要有"
结果:
- 类数量翻倍
- 文件层级变深
- 可读性下降
👉 这是典型的过度设计
四、一个实用判断标准
当你在犹豫要不要引入 DataSource 时,问自己三个问题:
1️⃣ 数据来源是否 ≥ 2 个?
- 是 → 可以考虑 DataSource
- 否 → 不需要
2️⃣ Repository 是否变复杂?
是否出现:
- 多分支判断
- 数据拼装逻辑
- 缓存策略
👉 是 → 可以拆 DataSource
3️⃣ 是否有复用需求?
- 多个地方用同一套数据逻辑
👉 是 → 可以抽 DataSource
五、推荐的演进式架构
不要一开始就上"完整版架构",而是逐步演进。
🟢 简单项目

👉 简单直接,维护成本最低
🟡 中型项目
👉 开始有缓存、策略
🔴 复杂项目
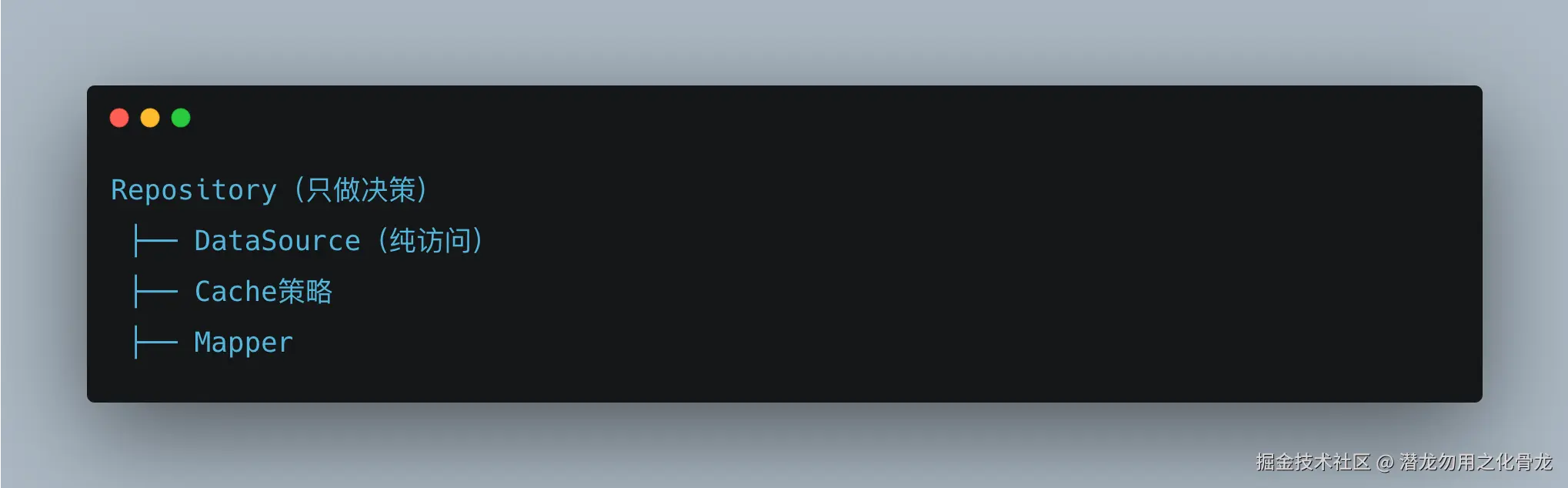
👉 高内聚、低耦合,但复杂度高
六、一个关键认知:架构是为复杂度服务的
很多人误以为:
架构越完整越好
但实际上:
架构的目标是控制复杂度,而不是制造复杂度
错误做法
- 每个 Repo 强行加 DataSource
- 每层都拆接口
- 模板化开发
👉 结果是:代码膨胀,但收益为 0
正确做法
- 从简单开始
- 复杂了再拆
- 按需引入结构
七、总结
一句话总结:
DataSource 是"解耦工具",不是"标配组件"
- ❌ 不是每个 Repository 都需要 DataSource
- ✅ 只有在"复杂度上升"时才引入
- 🎯 架构设计应当是"演进的",而不是"预设的"