一、Linux
查看当前登录所有在线用户
强制结束 PID 为 10086 的进程
递归删除当前目录下所有空目录
bash
who
kill -9 10086
find . -type d -empty -deletewho :查看服务器在线登录用户,运维安全巡检常用
kill -9 PID :强制杀死进程,卡死任务、僵尸进程收尾必备
find -type d -empty -delete:递归清理空目录,磁盘规整、数据归档常用
二、SQL
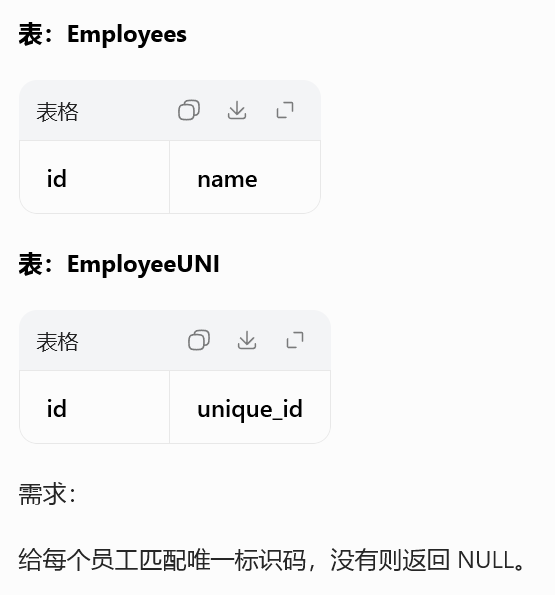
1378. 使用唯一标识码替换员工 ID
sql
SELECT
eu.unique_id,
e.name
FROM Employees e
LEFT JOIN EmployeeUNI eu
ON e.id = eu.id;标准左外连接匹配维度 ID
主表保留全部,匹配不到自动 NULL
数仓用户主表关联唯一标识通用模板
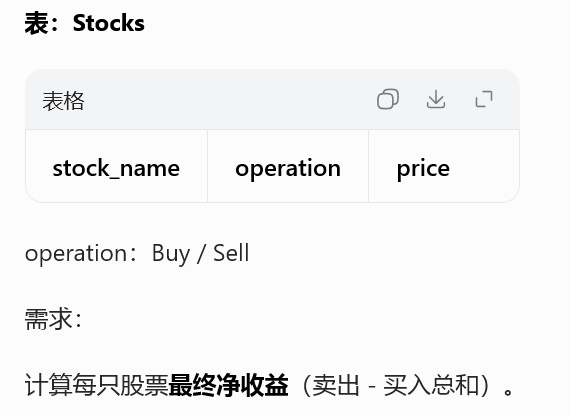
1393. 股票的资本损益
sql
SELECT
stock_name,
SUM(CASE operation
WHEN 'Sell' THEN price
WHEN 'Buy' THEN -price
END) AS capital_gain_loss
FROM Stocks
GROUP BY stock_name;CASE 给买入加负号、卖出正号
分组 SUM 直接算净盈亏
行为类型做正负折算,金融 / 交易类 SQL 经典写法
1407. 排名靠前的旅行者

sql
SELECT
u.name,
IFNULL(SUM(r.distance), 0) AS travelled_distance
FROM users u
LEFT JOIN rides r ON r.user_id = u.id
GROUP BY u.id, u.name
ORDER BY travelled_distance DESC, u.name ASC;左连接保证无行程用户也能出现(距离为 NULL)
分组聚合总里程
多字段排序:指标降序、名字字典序升序兜底
三、Pyspark
python
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, sum, when
spark = SparkSession.builder \
.master("local[*]") \
.appName("Day28") \
.getOrCreate()
# 1. 左连接匹配唯一ID
emp = spark.createDataFrame([(1,"Alice"),(2,"Bob")],["id","name"])
uni = spark.createDataFrame([(1,"U001")],["id","unique_id"])
emp.join(uni, on="id", how="left").show()
# 2. 股票盈亏计算
stock = spark.createDataFrame([
("AAPL","Buy",100),
("AAPL","Sell",120)
], ["stock_name","operation","price"])
stock.withColumn("gain",
when(col("operation")=="Sell", col("price"))
.when(col("operation")=="Buy", -col("price"))
).groupBy("stock_name").sum("gain").show()
spark.stop()Spark left 左外连接和 MySQL 逻辑完全一致
when 实现条件正负转换,对标 SQL CASE分组聚合 + 排序,直接复用数仓业务开发逻辑
四、算法
160. 相交链表
python
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
def getIntersectionNode(headA, headB):
a, b = headA, headB
while a != b:
a = a.next if a else headB
b = b.next if b else headA
return a双指针遍历,走完自己走对方
时间 O (n)、空间 O (1) 最优解
链表高频面试经典题型