C++--STL(标准模板库),主要有六大组件组成:容器,迭代器,算法,仿函数(函数对象),适配器,空间配置器,核心是实现泛型编程。
一.容器
对于接收内置类型的顺序容器与关联容器可以直接使用==判断是否相等,但对于容器适配器不行,对于接收自定义类型的容器,需要自定义类型中有==号的重载函数。
1.顺序容器
(1)vector
vector(向量容器),底层的数据结构是一个动态扩容的数组(内存连续),每次以原来大小的二倍进行扩容。
特点
由于内存连续,vector在进行扩容时,进行的操作是,先找到一块新的空间,将老的空间上的元素拷贝到新的空间上,然后再将老空间上的内容析构,这导致了其扩容效率较低。
常用操作
增加:push_back(val),末尾添加元素,O(1)
emplace_back(val),末尾添加元素,O(1)
insert(it,val),在it迭代器指定位置添加一个元素,O(n)(中间添加元素需要后面的元素移动)
删除:pop_back(),末尾删除元素O(1)
erase(it),删除it迭代器指向的元素O(n)
查询:operator \[\],下标随机访问,O(1)
迭代器查询
常用方法:
size(),empty(),reserve(val)(预留空间,不进行构造与初始化),resize()(改变元素个数,进行构造与初始化),swap(vec)(交换两个容器元素)
emplace_back与与push_back的区别
emplace_back底层是依赖于可变参模板实现的,不同于push_back对左值与右值的实现需要重载,emplace_back通过引用折叠,将左值与右值的实现合并
1.对于内置类型的添加,两者没有任何区别
2.对于对象的直接添加,无论是普通对象还是临时对象,两者都没有区别(对于临时对象,需要先构造临时对象,再调用移动构造函数)。
3.emplace_back,支持使用对象的构造函数直接在容器内部进行构造,push_back不支持
cpp
class Test
{
public:
Test(int a, int b) { cout << "Test(int a,int b)" << endl; }
Test(int a) { cout << "Test(int a)" << endl; }
~Test() { cout << "~Test()" << endl; }
Test(const Test& t) { cout << "Test(const Test&)" << endl; }
Test(const Test&& t) { cout << "Test(const Test&&)" << endl; }
};
int main()
{
vector<Test>vec;
Test t(10);
//两者相同
vec.push_back(t);
vec.emplace_back(t);
//两者相同
vec.emplace_back(Test(10));
vec.push_back(Test(10));
//支持调用构造函数直接在容器中构造
vec.emplace_back(10, 20);//push_back不支持这种写法
//两者相同
vector<int>vec;
vec.push_back(10);
vec.emplace_back(10);
}(2)deque
底层原理
deque(双端队列),底层的数据结构是一个动态开辟的二维数组,第一维的数组Map(中控器 )是一个指针数组(一般底层实现的大小是#define MAP_SIZE 2),并不存放具体的元素,中控器中的每一个元素都指向了第二维数组Buffer(缓冲区),这里才是真正存放元素的地方(底层实现的大小是#define QUE_SIZE 4096/sizeof(T)),定义的first与last分别指向缓冲区的元素的起始位置和末尾位置,最开始都指向中间位置,进行扩容时以一维数组的二倍进行扩容,将二维数组从一维数组个数/2的位置开始存放(上下都预留空间方便从deque首尾添加元素)。如图,假如我们还要添加元素,此时结构的变化:
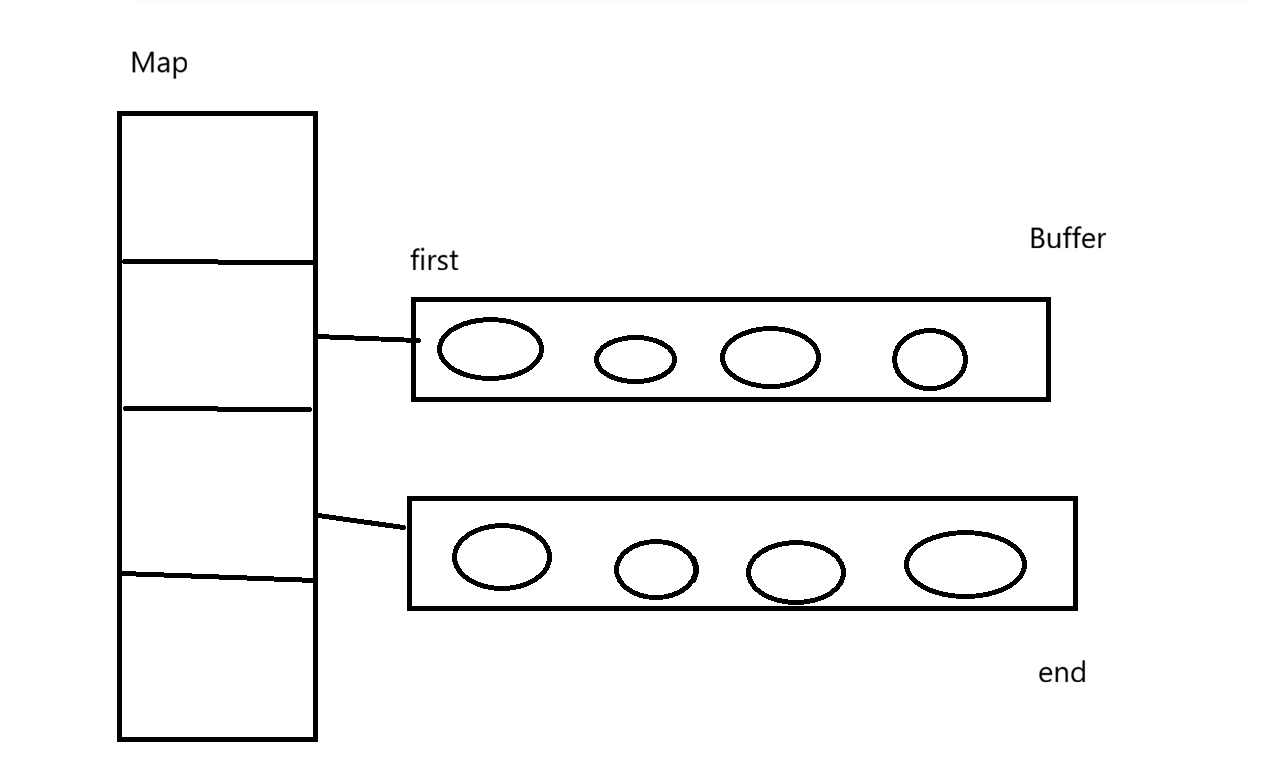
特点
动态开辟的二维数组空间,第二维是固定长度的数组空间,扩容的时候(第一维的数组进行2倍扩容),内存并不完全连续,分段连续,每一个一维间,每一个二维间是连续的,但是不同的二维间的地址并不连续,因为中控器(Map) 里的指针指向的内存块,可能是散落在内存条各个角落的。
常用操作
添加:
push_front(val)头插,O(1)
push_back(val)尾插,O(1)
insert(it,val)在it迭代器指定位置添加一个元素,O(n)
删除:
pop_back()头删
pop_front()尾删
erase(it)删除it迭代器指向的元素O(n)
查询:operator \[\],下标随机访问,O(1)
迭代器查询
(3)list
list链表容器,底层是一个双向循环链表。
常用操作
添加:
push_front(val)头插,O(1)
push_back(val)尾插,O(1)
insert(it,val)在it迭代器指定位置添加一个元素,O(1)
删除:
pop_back()头删,O(1)
pop_front()尾删,O(1)
erase(it)删除it迭代器指向的元素O(1)
查询:迭代器查询,链表的查询效率较低,通常需要遍历整个链表,O(n)
注意:链表单是使用insert或erase为O(1),但是通常需要与查询操作结合使用,导致实际为O(n)
vector与deque的区别
1.底层数据结构的区别
2.前中后插入删除元素的时间复杂度:中间和末尾 O(1) 前 deque O(1) vector O(n)
3.对于内存的使用效率:vector 需要的内存空间必须是连续的,deque 可以分块进行数据存储,不需要内存空间
4.在中间进行insert或者erase,vector和deque它们的效率区别:
虽然时间复杂度都是O(n),但由于deque的第二维内存空间不是连续的,所以在deque中间进行元素的insert或者erase,造成元素移动的时候比vector要慢
vector与list的区别
1.底层数据结构的区别
2.vector中间添加删除元素都是O(n),list不考虑查询时间中间删除,添加元素都是 O(1),链表的查询操作较慢O(n),vector可以使用下标随机访问 O(1)。
总结
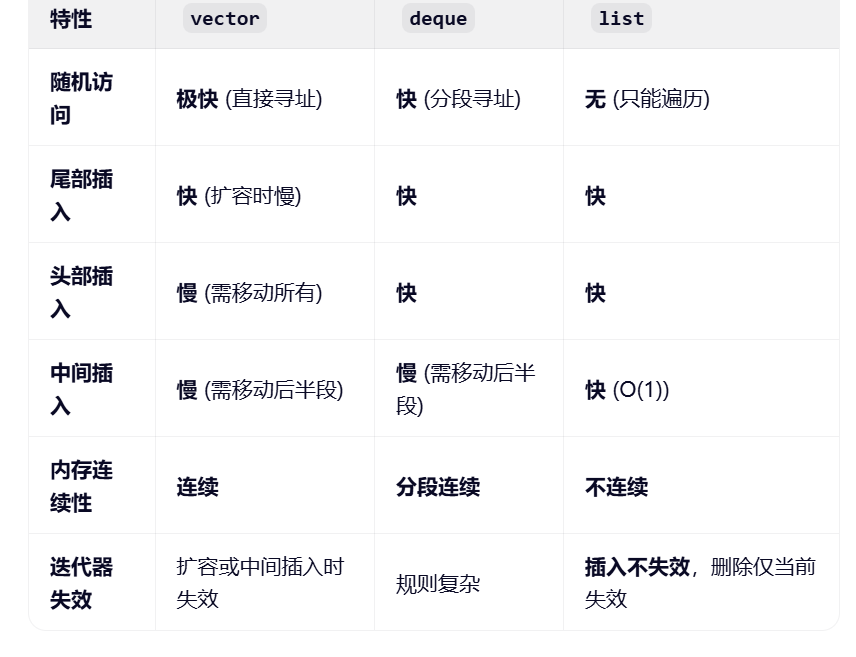
1.需要随机访问,只在尾部进行插入/删除,使用vector
2.需要随机访问,既需要在头部插入,也需要在尾部插入,使用deque
3.不关心随机访问,需要在容器的任意位置频繁插入/删除,使用list
(4)array
固定大小数组。性能与 C 风格数组相当,但更安全,提供了迭代器和大小查询。
**初始化:**fill(val),将整个数组的所有元素填充为同一个值。
访问:
operator \[\]:和 C 数组一样。
at():在调试或对安全性要求高的场景下使用,越界时会抛出 std::out_of_range 异常。
front() / back():分别获取首元素和尾元素的引用(注意:空数组调用会出错)。
(5)forward_list
forward_list,底层是一个单向链表,比list更节省空间,但只能只能从头到尾单向遍历,不支持反向迭代器。
常用操作
**添加:**push_front(val)与emplace_front(val),O(1)
insert_after(it) / emplace_after(it),在指定迭代器之后添加,O(1)
**删除:**pop_front()/erase(it),O(1)
访问:front(),O(1)
其他:empty(),sort()排序(nlog n),merge()(合并两个有序链表,O(n)),reserve()(反转链表,O(n))
**注意:**因为是一个单向链表,所以没有push_back(val)、pop_back() 和 back()等操作,同时也没有size()操作。
2.容器适配器
适配器底层没有自己的数据结构,它是另外一个容器的封装,它的方法,全部由底层依赖的容器进行实现的,没有实现自己的迭代器,无法使用迭代器遍历。
(1)stack
stack,栈,底层是借助一个deque实现的。
常用操作
增加
push(val),入栈操作,O(1)
emplace(val),直接在栈顶构造元素(相较于push,少了拷贝,移动的开销,效率更高)
删除
pop(),出栈操作,O(1)
访问栈顶
top()访问栈顶元素的引用,O(1)
其他
empty(),size(),swap(stk)。
(2)queue
queue,队列,底层是借助一个deque实现的。
常用操作
增加
push(val),入队操作,O(1)
emplace(val),直接在队尾构造元素(相较于push,少了拷贝,移动的开销,效率更高)
删除
pop(),出队操作,O(1)
访问
front(),返回队头元素的引用
back(),返回队尾元素的引用
其他
empty(),size()。
(3)priority_queue
priority_queue,优先队列,底层借助一个vector封装,通过堆结构实现(默认是大根堆,最大值永远在堆顶)。
常用操作
增加
push(val),入队操作,入队结束后需要自动调整堆的结构,O(log n)
emplace(val),直接在队中构造元素(相较于push,少了拷贝,移动的开销,效率更高)
删除
pop(),移除堆顶元素,出队结束后需要自动调整堆的结构,O(log n)
访问
top(),返回堆顶元素(优先级最高的元素)的引用
其他
empty(),size()。
queue与stack为什么不依赖于vector
1.vector的初始内存使用效率太低了,没有deque好
2.对于queue来说,需要支持尾部插入,头部删除, 如果queue依赖vector,其出队效率很低
3.vector需要大片的连续内存,而deque只需要分段的内存,当存储大量数据时,显然deque对于内存的利用率更好一些
priority_queue为什么依赖于vector
大根堆与小根堆依赖于内存连续的数组实现,deque内存不连续
3.无序关联容器
无序关联容器:unordered_set(单重集合),unordered_multiset(多重集合),unordered_map(单重映射表),unordered_multimap(多重映射表),底层都是链式哈希表。元素无序排列
(1)unordered_set与unordered_multiset
常用操作
增加 :insert(val),对于unordered_set,如果集合中元素已经存在会自动忽略其操作(即可以自动去重),对于unordered_multiset直接添加,O(1)
emplace(val),直接在容器内部构造元素,相较于insert效率更高,O(1)。
删除:
erase(val),删除所有值为val的元素,O(1)。
erase(it),删除指定迭代器指向的元素,O(1)。
clear(),清空容器中所有元素,O(n)。
查询 :O(1),find(val),找到返回指向其的迭代器(如果unordered_multiset存在多个val,只返回第一个满足的),未找到返回end()迭代器。
count(val),统计值为 val 的元素个数。由于 unordered_set 不允许重复,结果只能是 0(不存在)或 1(存在)
contains(val)(C++20 起):返回 true 或 false。
其他:size(),empty(),swap(set)。
(2)unordered_map与unordered_multimap
常用操作
增加 :operator \[\](unordered_map),最常用的方式。如果键不存在,会自动插入一个默认值(如 int 为 0)并返回其引用;如果键已存在,则返回对应值的引用(可直接用于修改)。
insert(key),对于unordered_map,如果集合中元素已经存在会自动忽略其操作(即可以自动去重),对于unordered_multimap直接添加,O(1)
emplace(key),直接在容器内部构造元素,相较于insert效率更高,O(1)。
insert_or_assign(key) (C++17,unordered_map):如果键不存在则插入,如果存在则更新其值,O(1)。
删除:
erase(key),删除所有键为key的元素,O(1)。
erase(it),删除指定迭代器指向的元素,O(1)。
clear(),清空容器中所有元素,O(n)。
查询 :O(1),find(key),找到返回指向其的迭代器(如果unordered_multimap存在多个key,只返回第一个满足的),未找到返回end()迭代器。
count(key),统计键为key 的元素个数。由于 unordered_map 不允许重复,结果只能是 0(不存在)或 1(存在)
equal_range(key),返回一个迭代器对(pair),包含了所有等于 key 的元素的起始和结束范围,,O(k+1)
contains(val)(C++20 起):返回 true 或 false。
其他:size(),empty(),swap(map)。
4.有序关联容器
set,multiset,map,multimap,底层是红黑树,元素默认按照升序排列。
(1)set与multiset
常用操作
增加 :insert(val),对于unordered_set,如果集合中元素已经存在会自动忽略其操作(即可以自动去重),对于unordered_multiset直接添加,O(log n)
emplace(val),直接在容器内部构造元素,相较于insert效率更高,O(log n)。
删除:
erase(val),删除所有值为val的元素,O(log n)。
erase(it),删除指定迭代器指向的元素,O(log n)。
clear(),清空容器中所有元素,O(n)。
查询 :O(log n),find(val),找到返回指向其的迭代器(如果multiset存在多个val,只返回第一个满足的),未找到返回end()迭代器。
count(val),统计值为 val 的元素个数。由于 set 不允许重复,结果只能是 0(不存在)或 1(存在)
contains(val)(C++20 起):返回 true 或 false。
其他:size(),empty(),swap(set)。
(2)map与multimap
常用操作
增加 :operator \[\](map),最常用的方式。如果键不存在,会自动插入一个默认值(如 int 为 0)并返回其引用;如果键已存在,则返回对应值的引用(可直接用于修改)。
insert(key),对于map,如果集合中元素已经存在会自动忽略其操作(即可以自动去重),对于multimap直接添加,O(log n)
emplace(key),直接在容器内部构造元素,相较于insert效率更高,O(log n)。
insert_or_assign(key) (C++17,map):如果键不存在则插入,如果存在则更新其值,OO(log n)。
删除:
erase(key),删除所有键为key的元素,O(log n)。
erase(it),删除指定迭代器指向的元素,O(log n)。
clear(),清空容器中所有元素,O(n)。
查询 :O(log n),find(key),找到返回指向其的迭代器(如果unordered_multimap存在多个key,只返回第一个满足的),未找到返回end()迭代器。
count(key),统计键为key 的元素个数。由于 unordered_map 不允许重复,结果只能是 0(不存在)或 1(存在)
equal_range(key),返回一个迭代器对(pair),包含了所有等于 key 的元素的起始和结束范围,,O(k+log(n))
contains(val)(C++20 起):返回 true 或 false。
其他:size(),empty(),swap(map)。
5.string
虽然严格意义上来说string并不是容器,但是完全可以将其看成是容器,string的底层实际上是封装了C类型的字符串(const char*)。
常用操作
添加:push_back(str) / +=str/ append(str),尾插,一般是O(n),但是若容量不足触发扩容,单次可能为 O(n)
insert(pos,str),指定下标位置插入。
删除:erase(pos, len),从指定位置开始,删除len个字符。
clear()。
访问:operator \[\],at()
查找:find(str),用于查找子串第一次出现的位置,如果没找到会返回 string::npos
substr(pos, len) 可以从下标 pos 开始,截取长度为 len 的子串并返回(如果省略 len,则截取到字符串末尾,如果pos后面小于len,则截取到末尾)
replace(pos, len, str) 将从下标 pos 开始的 len 个字符替换为新的字符串 str
其他:size() / length() / empty(),(size与length相同),c_str()(返回一个以 \0 结尾的 C 风格字符串指针(const char*)),compare(),(字典序比较)。
容器的空间配置器(allocator)
allocator是容器底层底层管理内存的工具,容器的底层实现一般都不使用new与delete来管理空间,核心问题在于new与delete在内存的开辟于释放上的捆绑问题,即new与delete将内存开辟与调用构造函数,内存释放与调用析构函数捆绑在一起使用,由此导致了极大的性能浪费,例如:vector的底层实现如果只使用new与delete的话,new intSIZE时,C++ 会不仅开辟内存,还会强行把这 100 个 int 全部初始化(构造)一遍,但此时这里的 vector 里其实一个真实有效的元素都还没有,而在析构时又要将者所有的析构,由此造成了大量无意义的构造与析构调用。
为了解决这一问题,我们需要将内存开辟与对象构造,内存释放与对象析构这两组操作分离开来。而allocator就是来解决这个问题的。
空间配置器的标准工作流程:
1.空间开辟:allocate(n):只负责开辟 n 个对象大小的原始内存,不调用构造
2.对象构造:construct(ptr, val):在已分配的特定内存 ptr 上,调用构造函数生成对象
3.对象析构:destroy(ptr):显式调用 ptr 指向对象的析构函数,但不释放内存
4内存释放:.deallocate(ptr, n):将 ptr 指向的整块原始内存归还给系统
二.迭代器
(1)底层原理
迭代器的底层实际上是一个封装了对象元素指针的类,由于不同容器的元素的指针类型及其行为有所不同,对于每个容器,编译器都通过了它们自己的迭代器,如:vector的迭代器实际上是一个对T*类型的封装,并且实现了相关的行为的重载函数,string则是对char *的封装,list是Node*。
foeach遍历(基于范围的for循环):底层就是通过展开成一个标准的迭代器遍历来实现的,对于容器,编译器会直接调用其begin与end成员方法。特别的,对于没有begin与end的成员,如原生的C数组,编译器会直接调用全局的std::begin()与std::end()函数,对于容器适配器,由于没有实现迭代器,所以无法使用。
cpp
//实际代码
vector<int>vec{ 1,2,3 };
for (auto v : vec)
{
cout << v << endl;
}
//编译器展开
auto it_begin = vec.begin();
auto it_end = vec.end();
for (; it_begin < it_end; ++it_begin)
cout << *it_begin << endl;(2)迭代器分类
普通正向迭代器:iterator:
常量的正向迭代器:const_iterator:常用于遍历且不希望修改元素时(常与cbegin,cend结合使用)
反向迭代器:reverse_iterator:(常与rbegin,rend结合使用)
只读的反向迭代器:const_reverse_iterator:
(3)迭代器失效
对**内存连续的容器(vector与string)**进行连续插入或者删除操作(insert/erase),一定要更新迭代器,否则第一次insert或者erase完成,迭代器就失效了,迭代器的底层是指针,一次插入或删除后,其他元素发生移动,导致迭代器失效,
对于容器适配器,由于不提供迭代器,所以不存在迭代器失效,对于无序关联容器,
对于节点类型的容器(list,map,set等),由于内存不连续,所以只有在进行erase操作时,erase的对象的迭代器才会失效,
对于无序关联容器,由于底层是哈希表,所以对于insert只有在发生哈希冲突是才会迭代器全部失效。
为了应对迭代器失效问题,erase与insert方法都返回了一个迭代器,需要在调用时重新赋值更新(如it=vec.erase(val))。
三.仿函数(函数对象)
仿函数实际上是一个类,内部重载了函数调用操作符(),即opreator(),使其可以像普通函数一样被调用,所以称为仿函数,它的作用类似于C语言的函数指针,那么我们为什么需要使用到仿函数呢?我们举一个例子
如果我们要实现一个同时能够比较大于与小于的函数compare,假如我们直接使用函数指针来实现:
cpp
template<typename T>
bool mygreater(T a, T b)
{
return a > b;
}
template<typename T>
bool myless(T a, T b)
{
return a < b;
}
template<typename T, typename Compare>
bool compare(T a, T b, Compare comp)
{
return comp(a, b);
}
int main()
{
cout << compare(10, 20, mygreater<int>);
cout << compare(10, 20, myless<int>);
}这样的确能够实现我们的目标,但是使用函数指针有一个缺点,就是使用函数指针的函数无法设置为inline(内联函数)(即使这里为mygreater与myless前面加上inline也不行),原因在于内联函数是在编译阶段确定的,但是问题在于这里的调用是通过函数指针间接调用,在编译阶段编译器并不知道其将要调用那一个函数,只有运行时才能确定,这样就导致这段代码的效率较低。
而我们的函数对象就能够很好的解决这一问题:
cpp
template<typename T>
class mygreater
{
public:
bool operator()(T a, T b)
{
return a > b;
}
};
template<typename T>
class myless
{
public:
bool operator()(T a, T b)
{
return a < b;
}
};
template<typename T, typename Compare>
bool compare(T a, T b, Compare comp)
{
return comp(a, b);
}
int main()
{
cout << compare(10, 20, mygreater<int>());
cout << compare(10, 20, myless<int>());
}总节一下 :1.通过函数对象调用operator(),可以省略函数的调用开销,比通过函数指针
调用函数(不能够inline内联调用)效率高
2.因为函数对象是用类生成的,所以可以添加相关的成员变量,用来记录函数对象使用
时更多的信息
同时函数对象还有许多应用:例如:定义一个小根堆的priority_queue时(我们知道默认是大根堆,使用的是less<int>):priority_queue<int,vector<int>,greater<int>>que
这里的greater<int>就是一个仿函数类型,而上面我们写的greater<int>()就是一个仿函数对象。
四.泛型算法与绑定器
泛型算法是 STL 提供的一组通用函数(都包含在algorithm头文件中),所谓泛型,就是指:这里的函数不依赖于特定的容器类型,具有通用性,只要提供对应的迭代器就能进行操作。
泛型算法的特点
1:泛型算法的参数接收的都是迭代器
2.泛型算法的参数还可以接收函数对象(c函数指针)
常见的泛型算法
sort:(排序)
1.sort接收一组迭代器,指向排序的起始位置于结束位置,默认是升序sort(vec.begin(),vec.end())。
2.接收第三个参数,第三个参数可以是仿函数,普通函数,lambda表达式,可以自定义排序方式。
3.对于自定义类型的比较需要重载<(>)。
注意:sort并不是完全通用,它要求传入的迭代器必须支持随机访问,如:list就无法使用(list需要使用自己的成员方法)。
find:(查询)
1.接收一组迭代器和一个目标值,指向查询的起始位置与结束位置,如果找到了,返回指向该元素的迭代器,如果没找到,返回范围的结束迭代器(即 end())。
2.查找自定义类型,需要重载==号。
注意:所以查找传入的迭代器,实际上是查找范围都是左闭右开区间 [first, last)
find_if:(条件查询)
1.接收三个参数,一组迭代器,指向查询的起始位置与结束位置,第三个参数是一个可调用对象(称为谓词),包括:Lambda 表达式、普通函数或仿函数,它接受一个元素作为参数,并返回 bool 值。,如果找到了,返回第一个满足条件的元素的迭代器,如果没找到,返回范围的结束迭代器(即 end())。
binary_search:(二分查找)
1.接收三个参数:查找范围的起始迭代器、结束迭代器,以及要查找的目标值。
2.支持传入第四个参数(谓词),用于自定义比较规则
注意:
1.在使用 binary_search 之前,必须确保容器内的元素已经排好序
2.binary_search返回值是一个bool值,只能知道有没有。
如果想找到具体的位置,可以使用如下算法:
lower_bound:返回第一个 大于等于 目标值的元素的迭代器。
upper_bound:返回第一个 大于 目标值的元素的迭代器。
绑定器
这bind1st和bind2nd在 C++11 标准中已被弃用(deprecated),并在 C++17 中被彻底移除。现代 C++ 开发中,强烈建议使用更强大、更灵活的 std::bind
bind,位于<functional> 头文件中,可用于固定函数的某一个参数,避免重新实现一个新的函数。
举个例子:假如我们要找一个vector容器中第一个大于30的元素,我们可以使用find_if,但是find_if的第三参数只接收一个一元谓词,而如果我们使用库里的greater仿函数,接收的是两个参数,如果我们自己实现一个,就比较不方便,所以我们这里就可以使用bind绑定器。
cpp
int main()
{
using namespace std::placeholders;
vector<int>vec{ 12,23,34,45,56 };
auto it=find_if(vec.begin(), vec.end(), bind(greater<int>(), _1,30));
cout << *it << endl;
}如上:我们简单总结一下bind的使用方法:
1.包含finctional头文件,引入占位符using namespace std::placeholders
2.bind(greater<int>(), _1,30),占位1,参数2改成30,返回绑定的函数的仿函数对象。