凌晨三点的电话
"喂,系统慢得不行了,订单查询全在超时,你赶紧看看!"
凌晨三点,监控面板显示:CPU飙到85%,网络IO接近饱和,数据库连接数暴涨。翻开慢查询日志,一条报表SQL映入眼帘------
执行时长:247秒。扫描行数:2.3亿。网络传输:800MB。
这条SQL在单机上跑得好好的,迁到分布式集群后直接崩了。
元凶只有一个:跨分片JOIN。
如果你也踩过这个坑,或者正为分布式数据库的性能问题焦头烂额,这篇文章就是为你写的。我们从架构原理出发,彻底搞清楚跨分片JOIN为什么慢,以及如何快速定位问题。
📌 本文是系列开篇,后续5篇将逐一给出解决方案。
一、先认清三种主流架构
跨分片JOIN的慢,在不同架构下有不同的"病因"。读懂架构,才能读懂执行,才能读懂为什么慢。
架构一:分片中间件(Sharding Middleware)
代表产品:TDSQL MySQL版、Apache ShardingSphere、Vitess、MyCAT
在应用层和数据库之间插入一层"中间件",负责SQL解析、路由分发和结果聚合。底层是多个独立的MySQL/PostgreSQL实例,彼此互不感知。
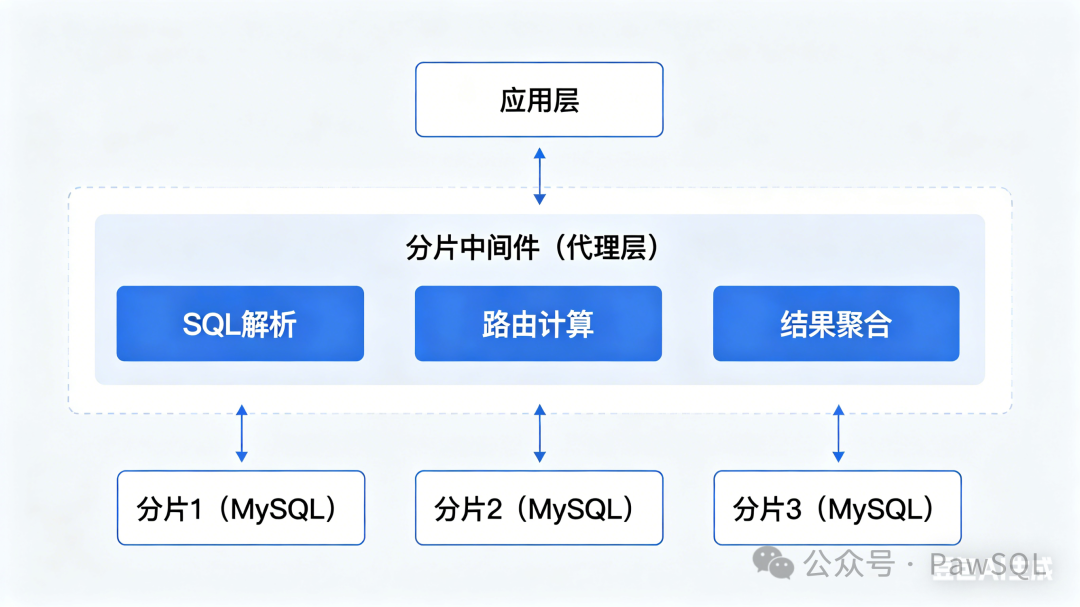
核心特征:跨分片操作完全依赖中间件的计算能力,JOIN通常采用"广播小表"或"拉取数据后合并"的方式处理。
架构二:存算分离MPP(Cloud-Native MPP)
代表产品:GaussDB DWS、Snowflake、Redshift、BigQuery
计算与存储彻底分离。数据统一存储在分布式文件系统(OBS/HDFS),计算节点按需启动,查询时动态分配资源。
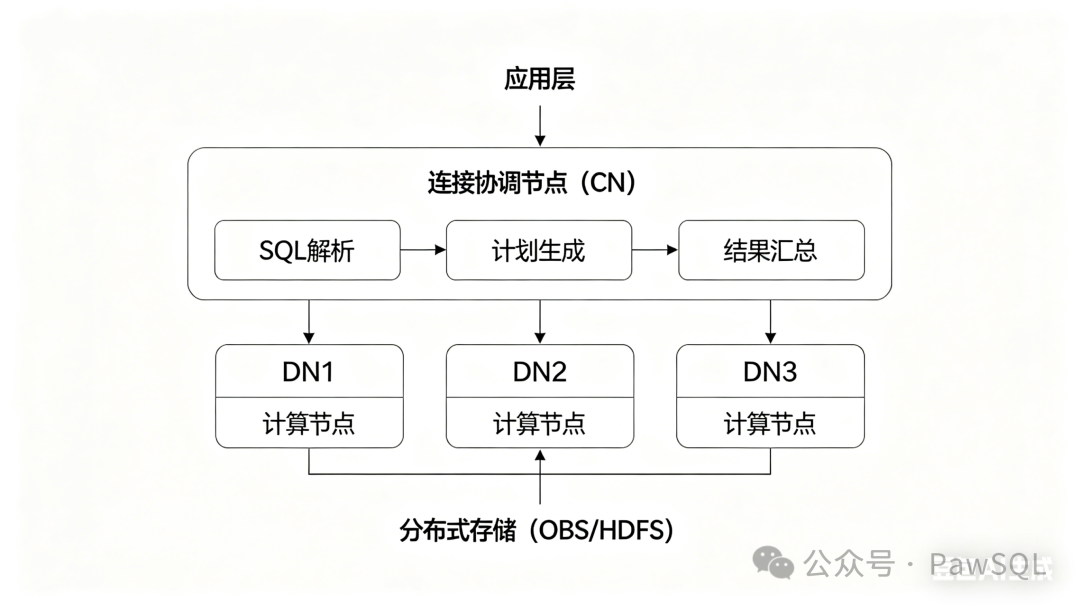
核心特征:利用列存储和数据剪枝压缩IO,JOIN优化高度依赖统计信息和CBO(代价优化器),支持重分布(Shuffle)和广播两种策略。
架构三:经典MPP(Shared-Nothing MPP)
代表产品:Teradata、Greenplum、Netezza
存算一体的经典设计。每个节点同时负责存储和计算,数据按分布键哈希散布到各节点,节点间通过高速专用网络互联。
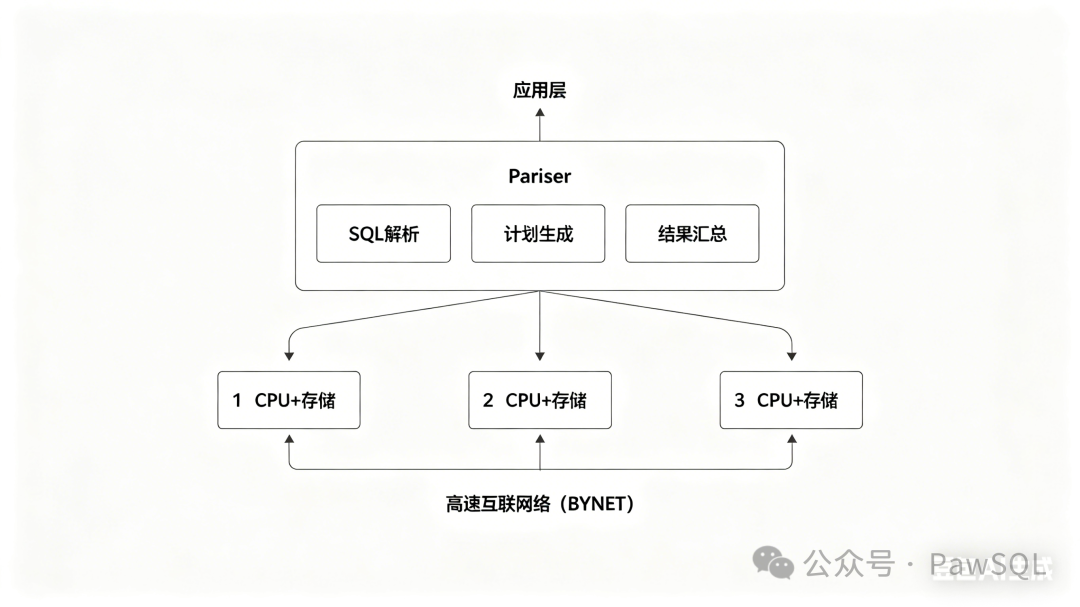
核心特征 :优化目标是最大化数据本地性,最小化数据移动。支持重分布、复制、本地JOIN三种执行策略。
二、同一条JOIN,三种架构怎么跑?
三种架构的实现机制不同,面对跨分片JOIN时的执行路径也截然不同------而执行路径,决定了性能上限。
用一个具体例子来对比:
SELECT o.order_id, u.user_name, u.user_phoneFROM orders oJOIN users u ON o.user_id= u.user_idWHERE o.order_date='2025-01-01';假设:orders 10亿行,users 1亿行,按不同字段分布在各节点。
架构一:中间件层合并
由于底层MySQL互不感知,中间件只能这样处理:
方式A:拉取到中间件后关联
1. 向所有分片发:SELECT * FROM orders WHERE order_date = '2025-01-01'2. 向对应分片发:SELECT * FROM users WHERE user_id IN (上一步结果)3. 在中间件内存中完成JOIN⚠️ 结果集稍大,中间件直接OOM。
方式B:广播小表
1. 拉取完整 users 表(1亿行)2. 广播到每个 orders 分片3. 各分片本地完成JOIN⚠️ 1亿行全量传输,网络流量爆炸。
根本缺陷:中间件不具备真正的分布式JOIN能力(如哈希重分布),天然是单点瓶颈。
架构二:优化器自动选择重分布
以GaussDB DWS为例,优化器会生成如下计划:
协调节点:
1. orders 和 users 都按 user_id 重哈希分布
2. 相同 user_id 的行被路由到同一个计算节点
3. 各节点独立完成本地 Hash Join
DN1:orders(user_id=1,4,7...) + users(user_id=1,4,7...)
DN2:orders(user_id=2,5,8...) + users(user_id=2,5,8...)
...优势 :充分利用所有节点的并行计算,支持PB级数据关联,列存储进一步压缩IO。代价:两张表都需要全量重分布,网络传输量仍然可观。
架构三:以最小数据移动为目标
以Teradata为例,优化器会按代价选择最优路径:
-
本地JOIN(最优) :若
orders和users都按user_id分布,无需移动任何数据,每个AMP直接本地JOIN。 -
重分布(次优):分布键不一致时,将一张表按JOIN字段重分布。
-
复制表:小表在每个节点保留完整副本,JOIN时零传输。
三种架构在跨分片JOIN上都面临数据移动的代价,只是严重程度和优化手段不同。接下来,我们来看具体的性能瓶颈在哪里。
三、三大性能杀手
杀手一:网络传输爆炸和结果膨胀
这是所有分布式架构最致命的问题。
以经典MPP的重分布JOIN为例,先算传输成本:

这还没算控制消息和中间结果的开销,实际往往超过10分钟。
更危险的是结果膨胀问题------一个容易被忽视的放大器:
-- orders 中每个 user_id 对应100条记录,users 中每个 user_id 只有1条
SELECT *
FROM orders o
JOIN users u
ON o.user_id = u.user_id重分布后每个节点处理的是 orders片段 + users片段,但JOIN结果可能远大于原始输入。极端情况下,JOIN条件写错导致笛卡尔积,网络传输量和计算量双双暴增,集群直接被打崩。
架构差异:分片中间件最糟糕,中间件吞吐量远低于MPP架构,是双重瓶颈;存算分离MPP通过列存储和数据剪枝能有效缓解,但涉及全表数据时同样无法幸免。
杀手二:协调节点 / 中间件单点瓶颈
分片中间件架构最为严重:
中间件需要:1. 汇总所有分片的返回结果2. 在内存中完成排序、聚合、JOIN3. 拼装并返回最终结果中间结果一旦超出内存上限,整个查询直接失败。
架构二和架构三通过让工作节点承担真正的JOIN计算,协调节点只做任务调度和轻量聚合,有效规避了这个问题。
杀手三:数据倾斜(三架构共性)
分布键选择不当,就会让某个节点成为全局瓶颈。以 province(省份)作为分布键为例:
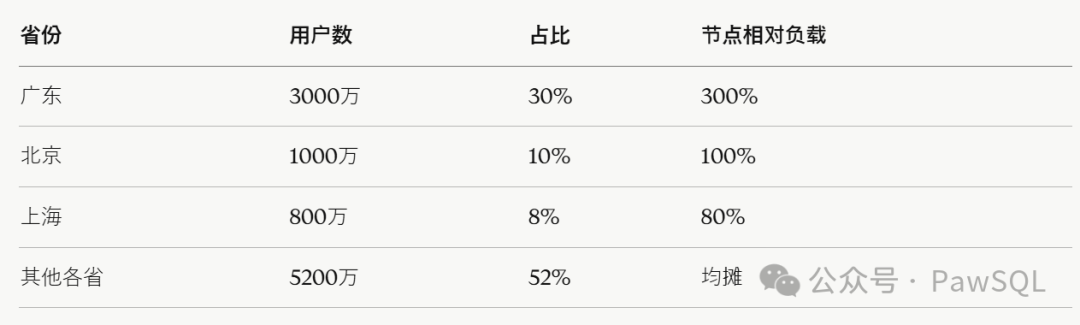
整个JOIN操作的完成时间,取决于广东所在节点------典型的木桶效应。
分片中间件对此最脆弱,没有自动均衡机制;存算分离MPP可以多级分区动态调整;经典MPP只能依靠分布键设计提前规避。
三种架构的暴露程度:
-
架构一:中间件统计信息往往不准,误判频率最高
-
架构二:依赖CBO,统计信息的准确性直接影响计划质量,需定期
ANALYZE -
架构三:优化器最成熟,但统计信息过期同样会导致计划退化
这也是为什么 SQL 的执行计划需要持续审查,而不是"跑通了就完事"。
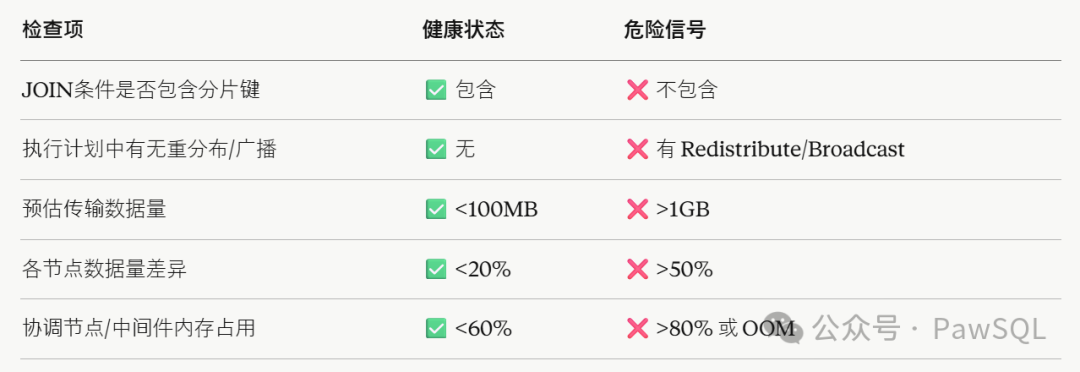
四、快速诊断:快速清单
遇到跨分片JOIN性能问题,建议先用快速清单做快速筛查,锁定方向后再进入架构专属诊断。
快速诊断清单
五、真实案例:一条报表SQL拖垮整个集群
业务背景
某电商平台需要统计"近30天每位用户的订单金额和登录次数":
SELECT
u.user_id,
u.user_name,
SUM(o.amount) AS total_amount,
COUNT(l.login_id) AS login_count
FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id
LEFT JOIN login_log l ON u.user_id = l.user_id
WHERE o.order_date >= DATE_SUB(CURDATE(), INTERVAL 30 DAY)
OR l.login_date >= DATE_SUB(CURDATE(), INTERVAL 30 DAY)
GROUP BY u.user_id, u.user_name
ORDER BY total_amount DESC
LIMIT 100;数据规模与分布

对照快速检查清单,第一条就命中了:JOIN条件(user_id)与分布键(order_id / login_log_id)不一致,必然触发大规模重分布。
执行过程拆解
-
架构一(分片中间件):
- 全表扫描 orders(2亿行)→ 拉取到中间件2. 全表扫描 login_log(5亿行)→ 拉取到中间件3. 中间件内存直接爆炸,查询失败
-
架构二 / 三(MPP):
- 扫描 orders 并过滤30天, 2亿 → 5000万行2. 扫描 login_log 并过滤30天, 5亿 → 5000万行3. orders 按 user_id 重分布, 5000万行跨节点4. login_log 按 user_id重分布,5000万行跨节点5. Hash Join(本地)6. Group By + Sort + Limit → 协调节点,结果集中
即使有30天的过滤条件,两张大表的双重重分布仍是核心瓶颈。
解决方案(剧透)
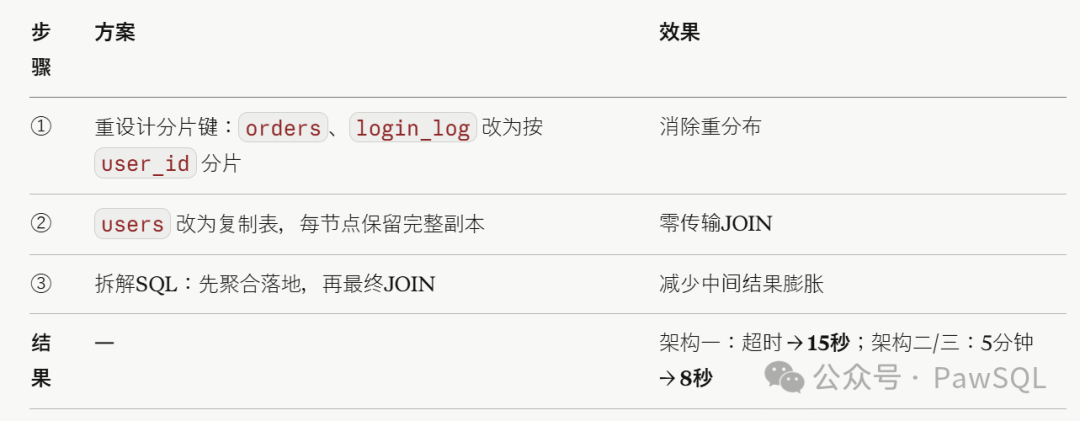
具体怎么做?系列后续文章逐一展开。
总结
跨分片JOIN慢,不是分布式数据库的"原罪",而是数据组织方式与查询模式不匹配 的结果。无论哪种架构,优化的终极目标都是同一个:减少数据移动,让JOIN回归本地。
下一步
你现在已经可以:
✅ 区分三种主流分布式架构的本质差异
✅ 识别跨分片JOIN的三大性能瓶颈
✅ 使用通用清单快速诊断问题
接下来的系列文章将逐一给出解决方案,并附带三种架构下的适用性分析:
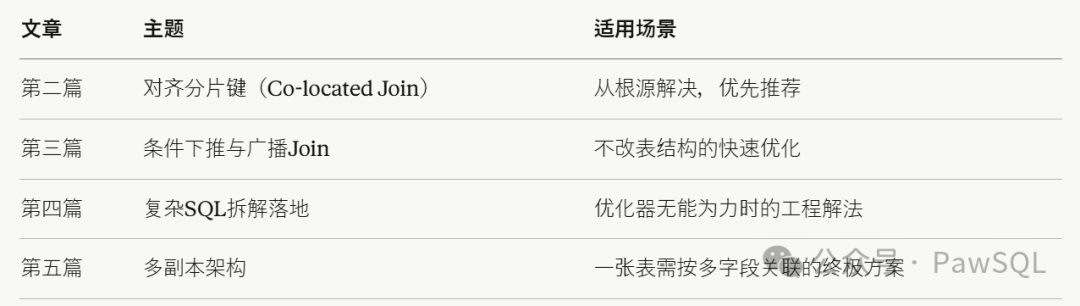
互动话题:你们公司用的是哪种架构?遇到过哪些跨分片JOIN引发的事故?欢迎评论区分享。
📌 下期预告:《分片键怎么选?一张表只有一次机会》。Co-located Join 不是万能解药,但用对了能让核心查询快 40 倍。