1. 真正率TPR与假正率FPR
正样本中被预测为正样本的概率TPR (True Positive Rate);真正率 TPR = TP / (TP + FN)
负样本中被预测为正样本的概率FPR (False Positive Rate);假正率 FPR = FP / (FP + TN)
通过这两个指标可以描述模型对正/负样本的分辨能力;
2. ROCl线 (Receiver Operating Characteristic curve)
是一种常用于评估分类模型性能的可视化工具 。
ROC曲线以模型的真正率TPR为纵轴,假正率FPR为横轴 ,它将模型在不同阈值下的表现以曲线的形式展现出来。
3. AUC (Area Under the ROC Curve) 曲线下面积
ROC曲线的优劣可以通过曲线下的面积(AUC)来衡量,AUC越大表示分类器性能越好 。
当AUC=0.5 时,表示分类器的性能等同于随机猜测;
当AUC=1 时,表示分类器的性能完美,能够完全正确地将正负例分类。
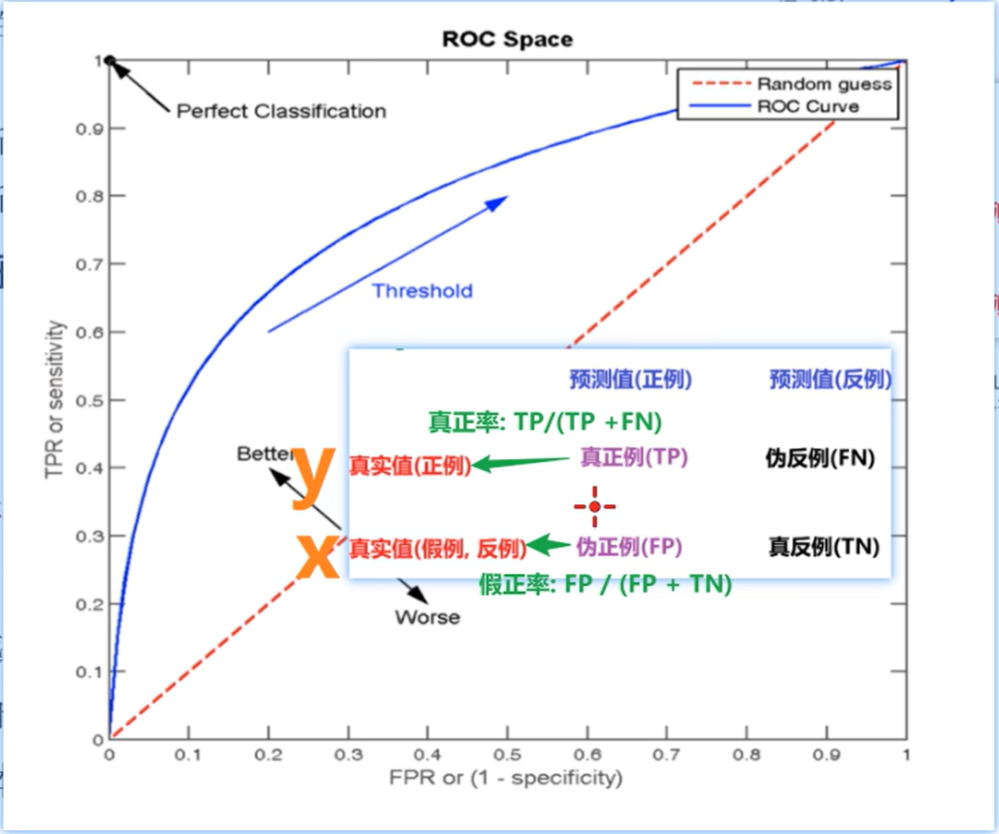
4. ROC曲线图像中,4个特殊点的含义
点坐标说明:图像x轴FPR/y轴TPR,任意一点坐标A(FPR值,TPR值) :
1️⃣ 点(0,0):所有的 负样本都预测正确 ,所有的正样本都预测为错误 。目当于点的(FPR值0,TPR值0) ;
2️⃣ 点(1,0):所有的负样本都预测错误,所有的正样本都预测错误。相当于点的(FPR值1,TPR值0) ;这是最不好的效果 ;
3️⃣ 点(1,1):所有的负样本都预测错误,表示所有的正样本都预测正确相当于点的(FPR值1,TPR值1) ;
4️⃣ 点(0,1):所有的负样本都预测正确,表示所有的正样本都预测正确。相当于点的(FPR值0,TPR值1) ;这是最好的效果 ;
ROC曲线上的每个点代表模型在不同阈值下的性能表现;
5. 从图像上看
1️⃣ 曲线越靠近(0,1)点则模型对 正负样本的辨别能力就越强 ;
2️⃣ AUC是ROC曲线下面的面积,该值越大,则模型的辨别能力就越强,AUC范围在0,1之间 ;
3️⃣ AUC=1时,该模型被认为是完美的分类器,但是几乎不存在完美分类器;
4️⃣ AUC<=0.5时,模型区分正负样本的就会变得模棱两可,近似于随机猜想;
(假正率 FPR = FP / (FP + TN),真正率 TPR = TP / (TP + FN)即(如图): 假正率=伪正例 / 反例真实值,真正率=真正例/ 正例真实值;ROC曲线是红线或者蓝线,对于蓝色,下面的面积越大越好,红色的面积是下面的三角形;
AUC=1时是竖线。
有4个特殊点:①点(0,0)说明x,y都是0,x是0说明伪正例FP在真实值(假例,反例)中的占比是0,则真反例TN是1,说明所有的反例都找出来了;y是0说明真正例TP在真实值(正例)中的占比是0,则伪反例FN是1,即找出来的都是伪反例。说明所有的正例一个都没找出来,所有的反例都找出来了,即所有的负样本都预测正确,正样本都预测为错误;②点(1,0)x=1说明伪正例FP在真实值(假例,反例)中的占比是1,则真反例TN是0,所有的反例都没找出来;y=0说明真正例TP在真实值(正例)中的占比是0,则伪反例FN是1;③点(1,1)x=1说明伪正例FP在真实值(假例,反例)中的占比是100%,则真反例TN是0;y=1说明真正例TP在真实值(正例)中的占比是100%,则伪反例FN是0。说明所有的正都找出来了,所有的反都没找出来;④点(0,1),x=0说明伪正例FP在真实值(假例,反例)中的占比是0,则真反例TN是1,则所有的反例都找出来了;y=1说明真正例TP在真实值(正例)中的占比是100%,则伪反例FN是0,说明真正例都找出来了。因此所有的正反都找出来了,这是最好的情况。
ROC曲线上的每个点代表模型在不同阈值下的性能表现,从图像上看点(0,1)(即纵轴上)的效果最好,代表所有的东西都能完美分开,越靠近(0, 1)模型的分辨能力越强,曲线(蓝线和红线)下的面积越大,则模型的分类效果越好;若模型的大小约等于0.5(即红线),说明模型在划分时只能做到随机猜想;)
6. ROC曲线绘制
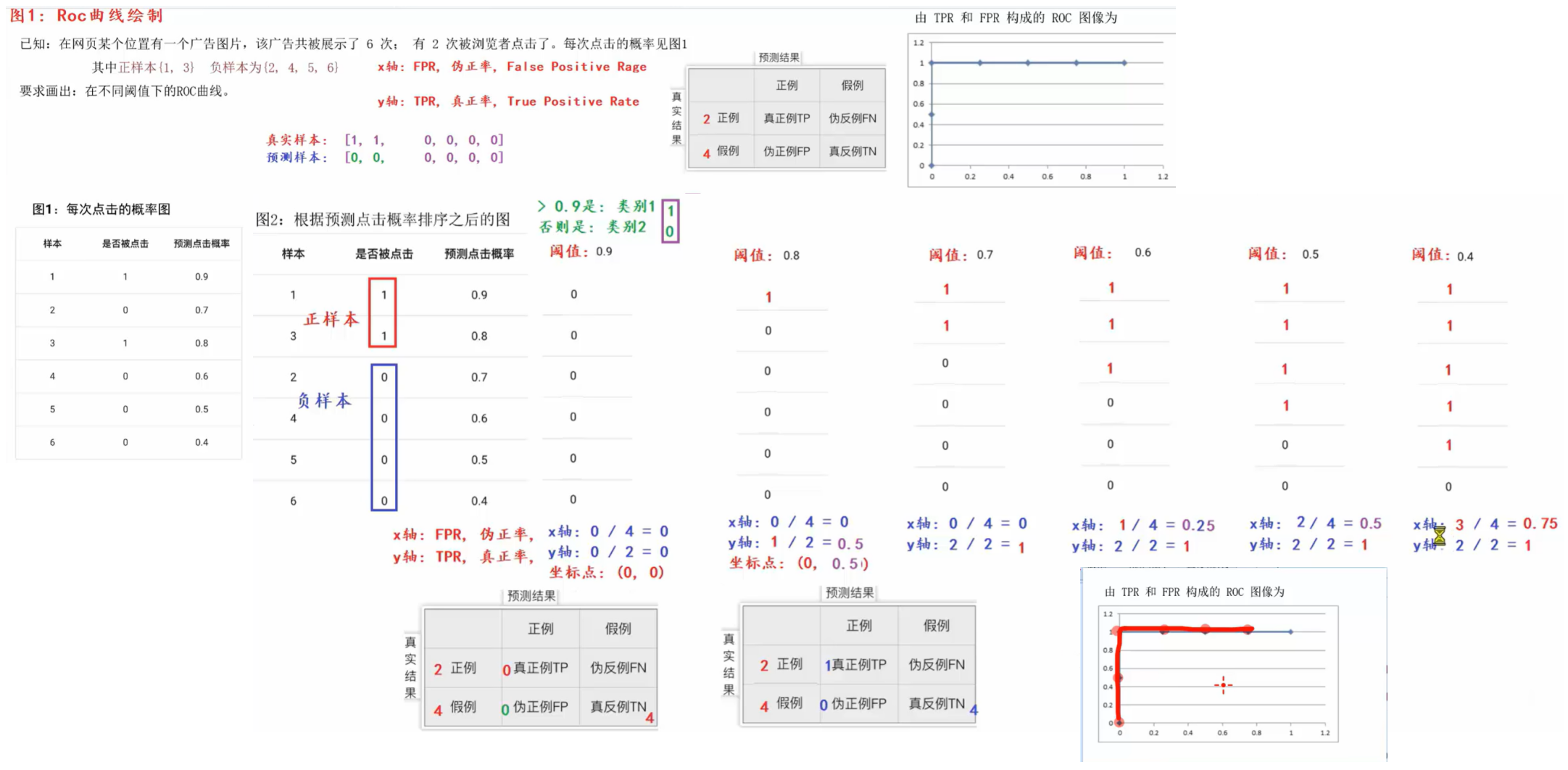
(已知:在网页某个位置有一个广告图片,该广告共被展示了6次;有2次被浏览者点击了。每次点击的概率见图1
其中正样本(1,3} 负样本为(2,4,5,6};要求画出:在不同阈值下的ROC曲线。
图1:每次点击的概率图。一共6个样本,是否被点击为1的有两个,即被点击了2次;图2是排完序的:预测点击概率是0.9,当以0.9作为阈值:>0.9的是类别1即1、否则是类别2即0;则阈值全都是0;
x轴:FPR,伪正率,False Positive Rate;
y轴:TPR,真正率,True Positive Rate;
真实样本: 1, 1, 0, 0, 0, 0
预测样本: 0, 0, 0, 0, 0, 0
对于图:有2个正例(因为小的是正例),假例4个,真正例TP预测对了0所以为0;真实值是反例,又被预测为反例,所以真反例TN=4;因为TN=4,所以伪正例FP=0;所以
x轴FPR:伪正例FP / 假例 = 0 / 4 = 0;y轴TPR:真正例TP / 正例 = 0 / 2 = 0;所以坐标点(0,0);
对于第二个点,阈值0.8:对于第一个值概率=0.9>0.8,所以值是1,其他的都<阈值0.8,所以值都是0;对于图:正例2、假例4,真正例TP=1,因为只有一个为1即只有一个预测对了;则对角真反例TN=4;伪正例FP=0;x轴FPR:伪正例FP / 假例 = 0 / 4 = 0;y轴TPR:真正例TP / 正例 = 1 / 2 = 0.5;所以坐标点(0,0.5);
对于第三个点阈值=0.7时: 对于第一个值概率=0.9>0.7,第二个值概率=0.8>0.7,所以值都是1,其他的都<阈值0.7,所以值都是0;对于图:正例2、假例4,预测对了2个,所以真正例TP=2;则对角真反例TN=4;伪正例FP=0;x轴FPR:伪正例FP / 假例 = 0 / 4 = 0;y轴TPR:真正例TP / 正例 = 2 / 2 = 1;所以坐标点(0,1);
以此类推,阈值=0.6时,真正例TP表示正样本中(2个)被预测为正样本的:有2个;真反例TN表示负样本中被预测为负样本的概率:3个;所以伪正例FP=1;x轴FPR:伪正例FP / 假例 = 1 / 4 = 0.25;y轴TPR:真正例TP / 正例 = 2 / 2 = 1;所以坐标点(0.25,1);
阈值=0.5时,真正例TP表示正样本中(2个)被预测为正样本的:有2个;真反例TN表示负样本中被预测为负样本的概率:2个;所以伪正例FP=2;x轴FPR:伪正例FP / 假例 = 2 / 4 = 0.5;y轴TPR:真正例TP / 正例 = 2 / 2 = 1;所以坐标点(0.5,1);
阈值=0.4时,真正例TP表示正样本中(2个)被预测为正样本的:有2个;真反例TN表示负样本中被预测为负样本的概率:1个;所以伪正例FP=3;x轴FPR:伪正例FP / 假例 = 3 / 4 = 0.75;y轴TPR:真正例TP / 正例 = 2 / 2 = 1;所以坐标点(0.75,1);)


7. 总结:
