2026 年 4 月 24 日 DeepSeek V4 正式发布,拥有百万级长上下文。
目前 Nebula Lab 已上线 DeepSeek V4,欢迎前来使用。
此次 DeepSeek V4有几大核心升级点:
🔥 1. 百万级长上下文
本次更新的突破莫过于上下文窗口直接从 128k 飙升至1,000,000 Tokens,实现整整 8 倍以上的增长。
无论是完整的超长代码库、整本专业书籍,还是超长多轮复杂推理任务,DeepSeek V4 都能轻松精准拿捏,告别内容拆分、上下文丢失的痛点。
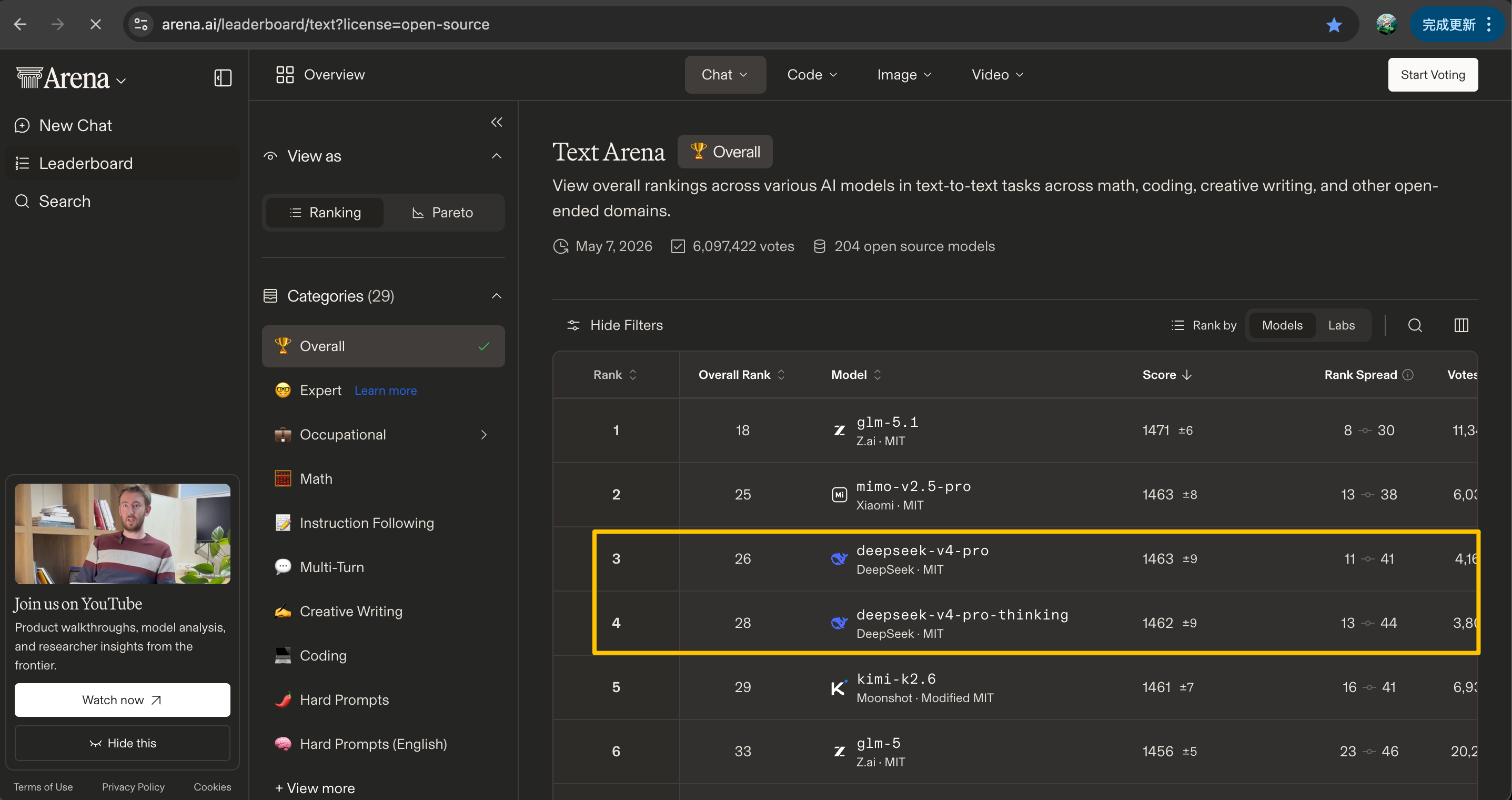
🧠 2. 推理能力跻身开源模型第一梯队
不止是 "会聊天",更能搞定硬核技术活。
DeepSeek V4 在数学、STEM 学科、竞赛级代码等硬核任务中表现优异,实测效果已接近 Gemini、Claude 等模型,打破开源模型 "重对话、轻推理" 的固有短板。
💻 3. Agent 能力全面增强
DeepSeek V4 进化为真正的 "AI 工程师",Agent 能力实现质的飞跃。
它可自主拆解复杂任务、自动生成代码、独立调试执行并完成全流程闭环,不再是被动应答的聊天机器人,真正成为能落地解决实际开发问题的生产力工具。
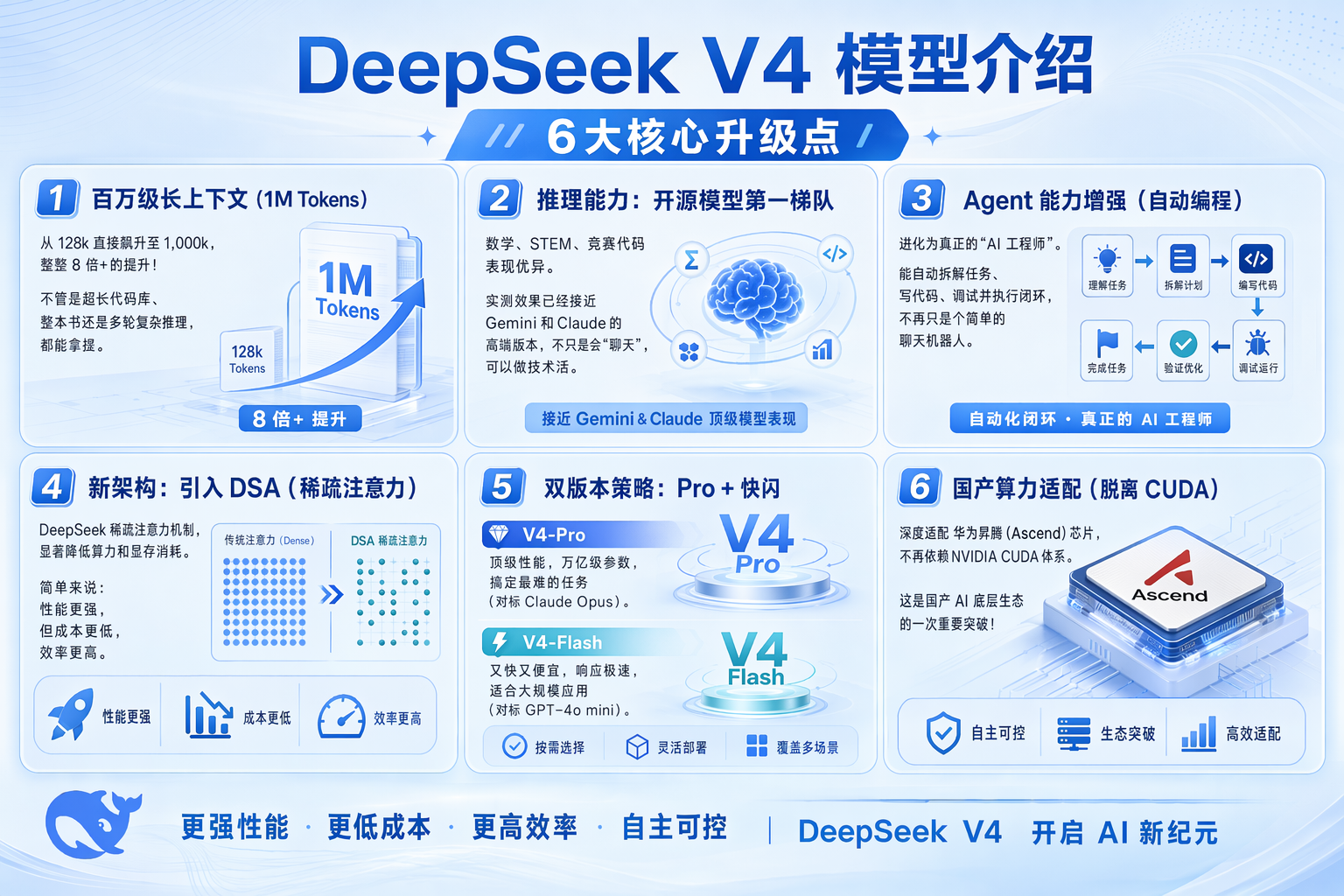
⚡ 4. 全新 DSA 稀疏注意力架构
本次更新从底层架构实现突破,引入 DeepSeek 自研DSA 稀疏注意力机制,降低模型运行的算力与显存消耗。
简单来说,就是实现了「性能大幅升级,运行成本更低、处理效率更高」的表现,兼顾效果与性价比。
🎯 5. 双版本精准布局
DeepSeek V4 同步推出两大定制化版本, 精准匹配不同使用场景,覆盖全量需求:
-
V4-Pro:万亿级参数规模,主打顶级性能,专攻高难度复杂任务,综合能力对标 Claude Opus;
-
V4-Flash:主打极速响应与极致性价比,响应速度快、调用成本低,完美适配大规模商用场景,对标 GPT-4o mini。
🇨🇳 6. 深度适配国产算力
这是本次更新,DeepSeek V4 完成对华为昇腾(Ascend)芯片的深度适配,彻底摆脱对 NVIDIA CUDA 体系的依赖。
这不仅是模型本身的能力升级,更是国产 AI 底层生态的关键突破,为国产大模型的自主可控、规模化落地打下了坚实基础。
从底层架构创新,到上层能力突破,再到国产生态适配,DeepSeek V4 的 6 大升级,既是自身产品的跨越式迭代,更是国产大模型向国际顶尖水平看齐的重要迈步。
不过,此次 V4 发布,并未像此前 DeepSeek R1 面世时那样,引发英伟达股价的剧烈震荡 ------ 彼时 R1 发布后,英伟达股价最高跌幅接近 20%。
恰恰相反,这一次英伟达非但没有受到冲击,反而在时隔六个月后,市值再度突破 5 万亿美元大关。
这一反差也印证了市场的核心逻辑,大众与资本真正关注的,从来都是模型本身的硬实力,以及其是否真正实现了底层技术的降本突破。
而这也正契合了 DeepSeek 在此次发布时写下的那句宣言:"不诱于誉,不恐于诽。率道而行,端然正己。"
不被外界的赞誉裹挟本心、动摇节奏,不因他人的非议心生怯意、偏离正道,始终锚定技术本质行事,沉心打磨产品、端正自身操守 ------ 这既是 DeepSeek 的行事准则,也是它能持续实现技术突破的核心底气。


Nebula Data 星雲數據,总部位于新加坡,在雅加达、广州、上海、香港设有分支机构。公司自主研发 Nebula Lab 一站式 AI 内容生成与模型聚合平台,搭载企业级 AI Agent,聚合全球通用大模型与行业垂直模型;同步推出 Nebula AIoT 硬件生态体系(含智能交互终端、物联网网关等产品),形成 "云 - 边 - 端" 全链路智能解决方案,为电商、制造、零售等多领域客户提供从云端算力支撑、AI 智能决策到终端场景落地的一体化服务;同时提供全球 AIDC(AI 智算中心)+ 低延迟网络服务,以技术底座赋能企业拥抱 AI、链接物理世界,拓展全球业务。