平台:阿里云百炼(Qwen)+ LangChain
本文从 API 申请出发,系统讲解 Chat Model、Prompt Template、Few-Shot、Output Parser 以及 LCEL Chain 五大核心模块,所有代码均来自实际运行案例。
注:由于langchain更新,会导致你有些代码用不了,这时可以去langchain官网看文档来解决。或者去问大模型解决。
目录
- [阿里云百炼 API Key 申请与配置](#阿里云百炼 API Key 申请与配置)
- 环境安装
- [Chat Model:模型调用基础](#Chat Model:模型调用基础)
- [Prompt Template:提示词模板化](#Prompt Template:提示词模板化)
- [Few-Shot Prompt:少样本提示](#Few-Shot Prompt:少样本提示)
- [Output Parser:结构化输出](#Output Parser:结构化输出)
- [LCEL Chain:链式调用](#LCEL Chain:链式调用)
- 综合实战案例
- 总结
一、阿里云百炼 API Key 申请与配置
1.1 进入模型广场,选择模型
访问 阿里云百炼控制台,在 模型广场 中可以浏览并选择模型。本文使用 qwen-plus 作为示例模型(性价比较高,支持 function calling、结构化输出、联网搜索等能力)。
💡 百炼的模型命名规则:
qwen-plus(均衡型)、qwen-turbo(轻量快速)、qwen-max(旗舰型)
1.2 创建 API Key
在左侧导航栏找到 API Key 菜单,点击右上角 「+ 创建 API Key」 按钮即可生成。
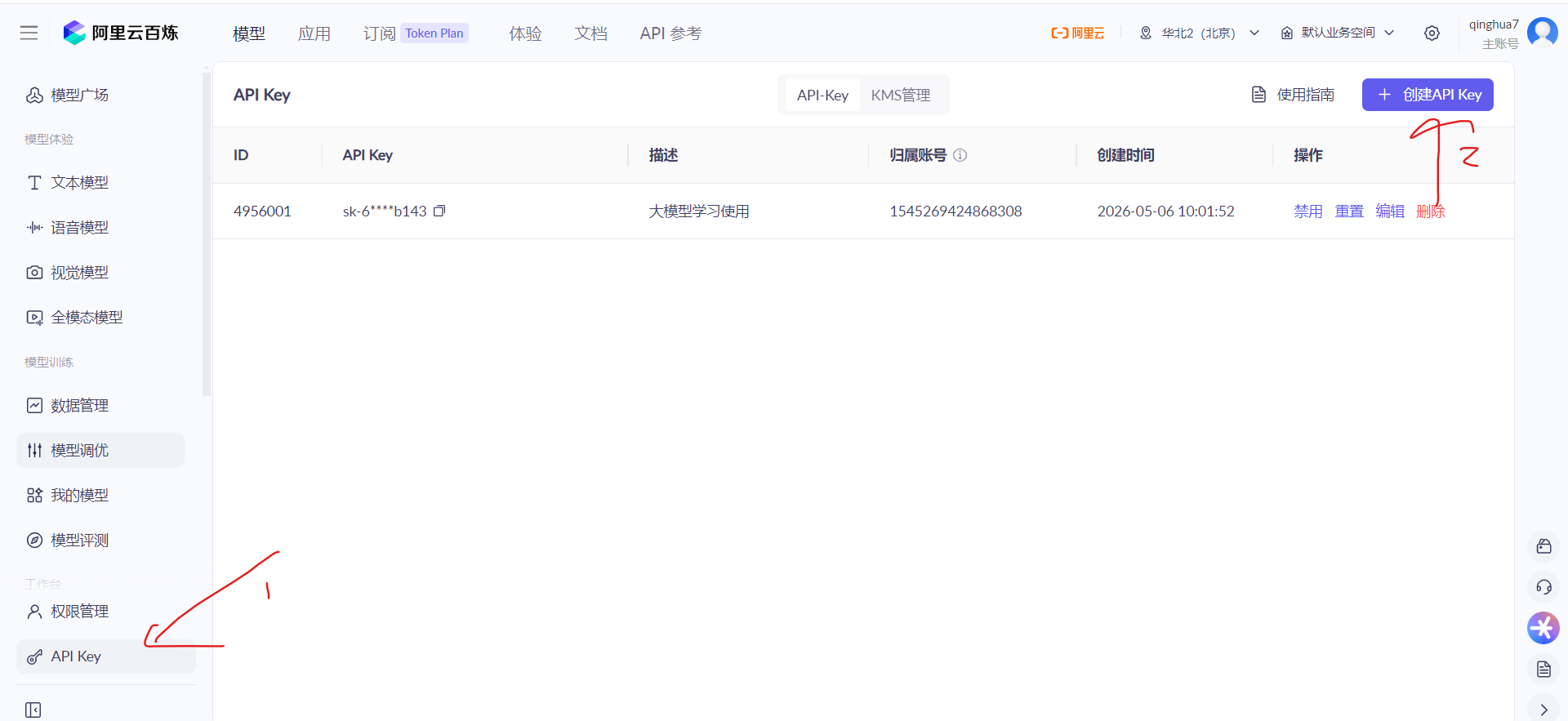
⚠️ 创建成功后请立即复制并妥善保存 Key 值(格式为
sk-xxxx),后续通过环境变量注入,切勿硬编码到代码中。
1.3 查看 API 代码示例
在模型详情页的 「API 代码示例」 区域可以直接获取 Python 调用示例,百炼兼容 OpenAI SDK,只需将 base_url 设置为:
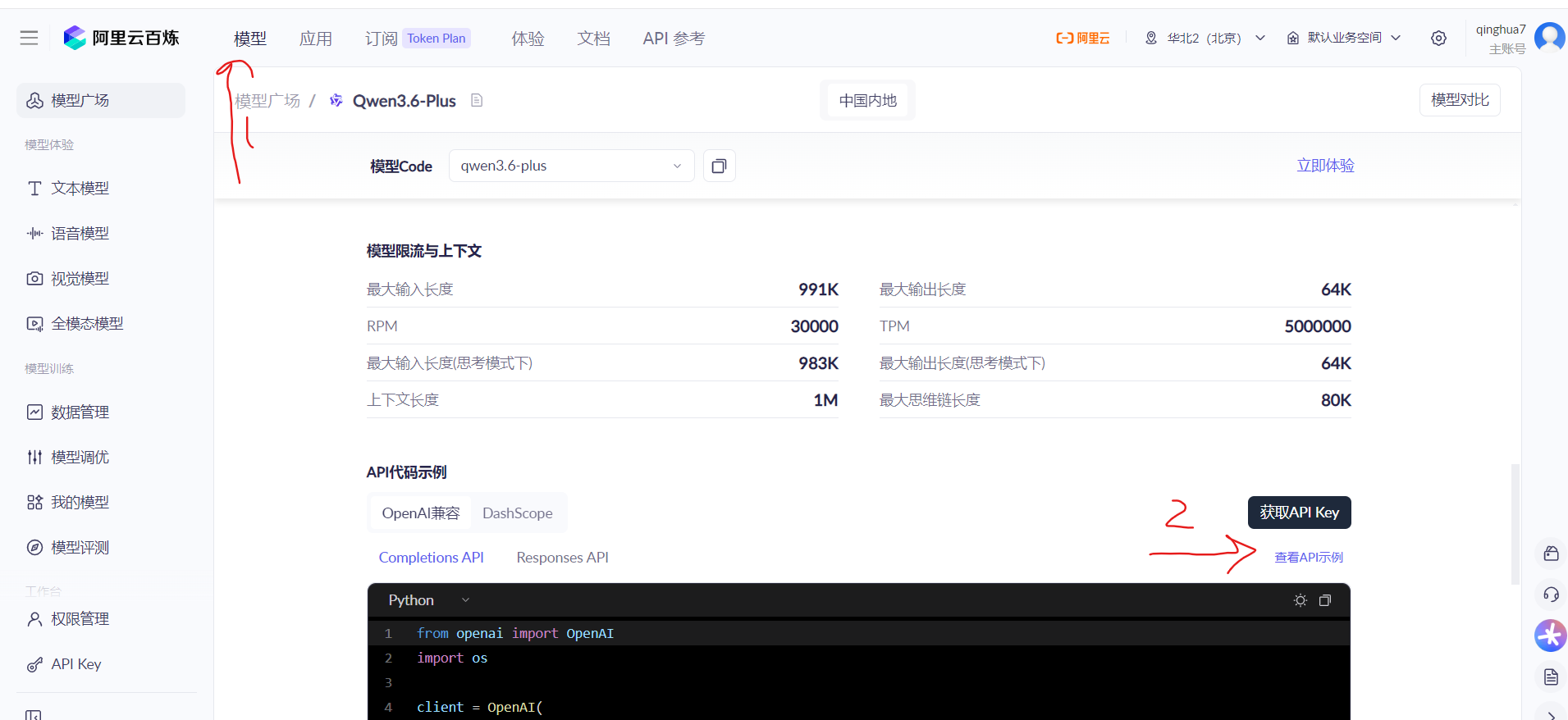
https://dashscope.aliyuncs.com/compatible-mode/v1即可无缝切换,无需修改其他代码。
1.4 配置环境变量
百炼标准接入流程:获取 API Key → 配置到环境变量 → 安装 SDK → 调用 。
Windows 临时配置(PowerShell):
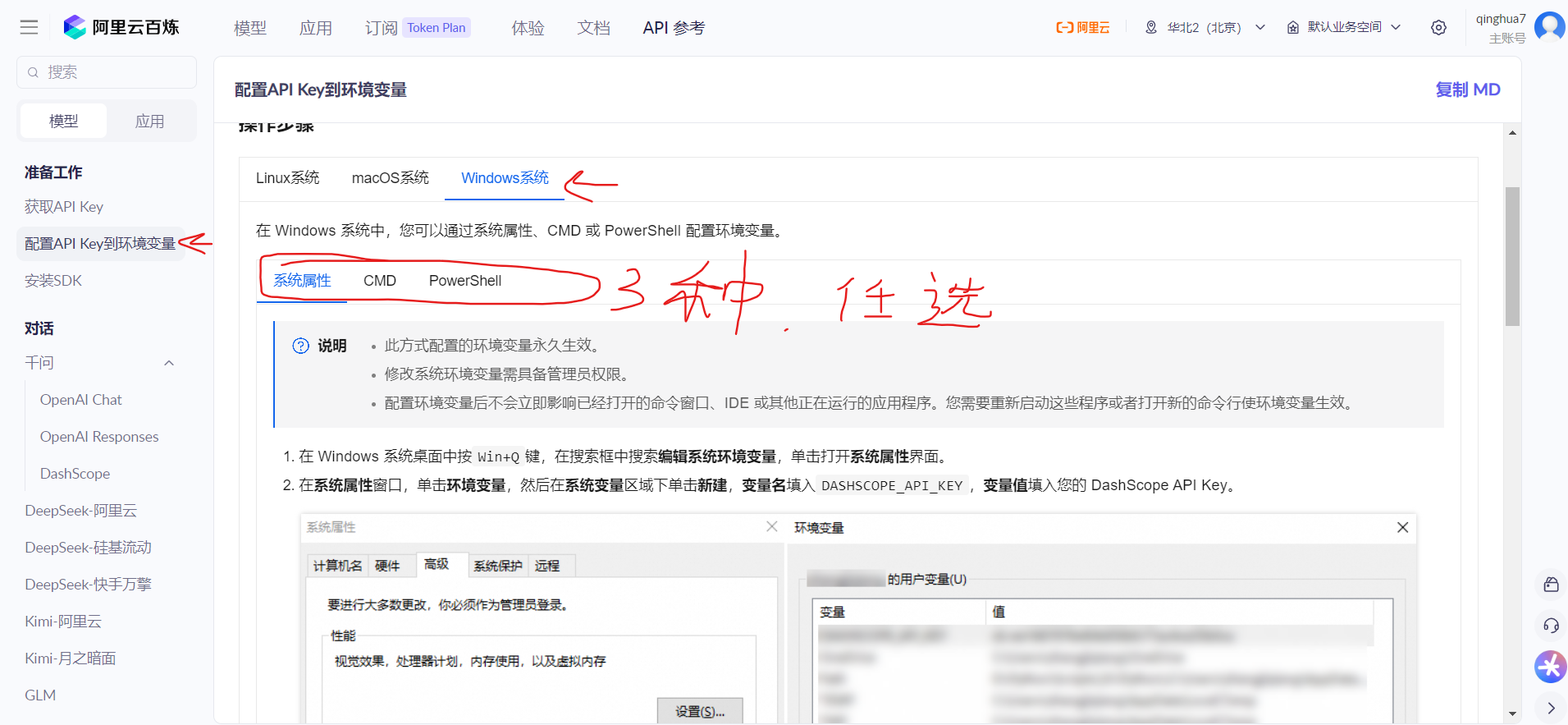
powershell
$env:DASHSCOPE_API_KEY = "sk-xxxxxxxxxxxxxxxx"Windows 永久配置(推荐,重启后生效):
powershell
[System.Environment]::SetEnvironmentVariable("DASHSCOPE_API_KEY", "sk-xxxxxxxxxxxxxxxx", "User")代码中读取环境变量:
python
import os
api_key = os.getenv("DASHSCOPE_API_KEY")二、环境安装
bash
pip install langchain langchain-openai langchain-core langchain-community openai| 包名 | 说明 |
|---|---|
langchain |
核心框架 |
langchain-openai |
OpenAI / 兼容接口集成 |
langchain-core |
基础抽象(Prompt、Message、Parser 等) |
openai |
OpenAI SDK(百炼兼容层) |
三、Chat Model:模型调用基础
3.1 原生 OpenAI SDK 调用(传统方式)
最直接的调用方式,使用 openai 包:
python
# Ch1-2.py 节选
from openai import OpenAI
import os
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": "你是谁?"}]
)
print(completion.choices[0].message.content)3.2 LangChain ChatOpenAI 调用(推荐)
LangChain 将模型封装为统一接口,推荐使用 ChatOpenAI,后续可以与 Prompt、Parser 无缝组合:
python
# 01 Model chat_model.ipynb
from langchain_openai import ChatOpenAI
import os
model = ChatOpenAI(
model="qwen-plus",
api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=1.2, # 温度:0~2,越大越随机
max_tokens=300 # 最大输出 token 数
)常用参数说明:
| 参数 | 说明 |
|---|---|
model |
模型名称,如 qwen-plus、qwen-turbo |
temperature |
控制生成随机性,0 最稳定,2 最发散 |
max_tokens |
最大输出 token 数,防止回复过长 |
api_key |
鉴权 Key,读取环境变量 |
openai_api_base |
百炼兼容接口地址 |
3.3 使用 Message 类型调用
LangChain 提供三种消息类型,对应不同对话角色:
| 消息类 | 对应角色 | 说明 |
|---|---|---|
SystemMessage |
system |
系统指令,定义模型角色和行为 |
HumanMessage |
user |
用户输入 |
AIMessage |
assistant |
模型历史回复(用于多轮对话) |
python
# 01 Model chat_model.ipynb
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="请你作为我的数学课助教,用通俗易懂且直接的语言帮我解释数学原理。"),
HumanMessage(content="什么是三角函数?"),
]
response = model.invoke(messages)
print(response.content)3.4 多轮对话------手动维护上下文
LangChain 不自动维护对话历史,需要手动将历史消息追加到列表:
python
# 01 Model chat_model.ipynb
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
messages = [SystemMessage(content="你是一个翻译助手。")]
# --------- 第一轮 ---------
messages.append(HumanMessage(content="把 '你好' 翻译成英文"))
response_1 = model.invoke(messages)
print(f"模型回答: {response_1.content}") # Hello
# ✅ 关键:将 AI 回答存入历史
messages.append(AIMessage(content=response_1.content))
# --------- 第二轮(模型能理解"那'谢谢'呢"的指代) ---------
messages.append(HumanMessage(content="那 '谢谢' 呢?"))
response_2 = model.invoke(messages)
print(f"模型回答: {response_2.content}") # Thank you关键点 :每轮调用后都要把
AIMessage追加到列表,模型才能"记住"上下文,否则每次都是独立对话。
3.5 参数实验:frequency_penalty(词频惩罚)
frequency_penalty 控制模型对高频词的惩罚力度,影响输出的多样性:
python
# Ch1-3.py
from openai import OpenAI
import os
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
prompt_text = "生成一个豆瓣高分电影清单,包含至少20部电影,每个电影名称打上书名号,每个物品之间用顿号进行分隔"
# frequency_penalty = -2:鼓励重复(输出更连贯,内容更多)
response_neg = client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": prompt_text}],
max_tokens=300,
frequency_penalty=-2
)
# frequency_penalty = 2:惩罚重复(词汇更多样,但可能更简短)
response_pos = client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": prompt_text}],
max_tokens=300,
frequency_penalty=2
)frequency_penalty |
效果 |
|---|---|
-2 |
鼓励重复高频词,内容更连贯,适合列表生成 |
0(默认) |
中性,平衡多样性与连贯性 |
2 |
强烈惩罚重复,词汇更丰富,但可能更简短 |
3.6 非 OpenAI 兼容模型:init_chat_model
对于不走 OpenAI 规范的模型(如 DeepSeek),使用 init_chat_model:
python
# Ch1-2.py
from langchain.chat_models import init_chat_model
# 参数1:model 模型名称
# 参数2:model_provider 模型提供者
client = init_chat_model("deepseek-chat", model_provider="deepseek")
response = client.invoke("你是谁?")
print(response.content)注意 :
langchain_community中的ChatTongyi因为社区更新滞后,新版 Qwen 模型名称可能报错,建议统一使用ChatOpenAI兼容方式。
四、Prompt Template:提示词模板化
手写 prompt 字符串难以复用。LangChain 的 Prompt Template 将变量占位符与提示词分离,实现模块化管理。
4.1 分角色模板(细粒度控制)
SystemMessagePromptTemplate + HumanMessagePromptTemplate 分别定义系统和用户提示:
python
# 02 Prompt Template.ipynb
from langchain_core.prompts import (
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
# System 模板:含 {input_language} 和 {output_language} 两个变量
system_template_text = (
"你是一位专业的翻译,能够将{input_language}翻译成{output_language},"
"并且输出文本会根据用户要求的任何语言风格进行调整。请只输出翻译后的文本,不要有任何其它内容。"
)
system_prompt_template = SystemMessagePromptTemplate.from_template(system_template_text)
# Human 模板:含 {text} 和 {style} 两个变量
human_template_text = "文本:{text}\n语言风格:{style}"
human_prompt_template = HumanMessagePromptTemplate.from_template(human_template_text)
# 查看变量列表
print(system_prompt_template.input_variables) # ['input_language', 'output_language']
print(human_prompt_template.input_variables) # ['style', 'text']填充变量并调用:
python
system_prompt = system_prompt_template.format(input_language="汉语", output_language="汉语")
human_prompt = human_prompt_template.format(text="勿以善小而不为,勿以恶小而为之", style="白话文")
response = model.invoke([system_prompt, human_prompt])
print(response.content)
# 不要因为善事很小就不去做,也不要因为恶事很小就去做。4.2 统一模板:ChatPromptTemplate(推荐写法)
ChatPromptTemplate.from_messages 一次性定义所有消息角色,代码更简洁:
python
# 02 Prompt Template.ipynb
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_messages(
[
("system",
"你是一位专业的翻译,能够将{input_language}翻译成{output_language},"
"并且输出文本会根据用户要求的任何语言风格进行调整。请只输出翻译后的文本,不要有任何其它内容。"),
("human", "文本:{text}\n语言风格:{style}"),
]
)
# 查看所有输入变量
print(prompt_template.input_variables)
# ['input_language', 'output_language', 'style', 'text']
# 填充变量,得到 ChatPromptValue
prompt_value = prompt_template.invoke({
"input_language": "汉语", "output_language": "汉语",
"text": "勿以善小而不为,勿以恶小而为之。", "style": "白话文"
})
response = model.invoke(prompt_value)
print(response.content)
# 不要因为善事很小就不去做,也不要因为恶事很小就去做。4.3 批量翻译实战
使用同一模板,批量处理多语言翻译任务:
python
# 02 Prompt Template.ipynb
input_variables = [
{"input_language": "汉语", "output_language": "汉语", "text": "勿以善小而不为,勿以恶小而为之。", "style": "白话文"},
{"input_language": "法语", "output_language": "英语", "text": "Je suis désolé pour ce que tu as fait", "style": "古英语"},
{"input_language": "俄语", "output_language": "意大利语", "text": "Сегодня отличная погода", "style": "网络用语"},
{"input_language": "韩语", "output_language": "日语", "text": "너 정말 짜증나", "style": "口语"},
]
for inp in input_variables:
response = model.invoke(prompt_template.invoke(inp))
print(response.content)输出:
不要因为善事很小就不去做,也不要因为恶事很小就去做。
I am sorry for that which thou hast done.
Oggi il tempo è fantastico! 🌞
あんた、本当にイライラするわ!五、Few-Shot Prompt:少样本提示
Few-Shot(少样本)通过在 Prompt 中内嵌若干「输入→输出」示例,引导模型按预期格式回复,无需微调模型。
5.1 对比:Zero-Shot vs Few-Shot
Zero-Shot(无示例): 模型自由发挥,格式不受控
python
# fewshot.py
response = client.chat.completions.create(
model="qwen-plus",
messages=[{
"role": "user",
"content": "格式化以下信息:\n姓名 -> 张三\n年龄 -> 27\n学号 -> 001"
}]
)
# 模型可能返回各种格式Few-Shot(有示例): 模型严格学习示例格式
python
# fewshot.py
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{"role": "user", "content": "格式化以下信息:\n姓名 -> 张三\n年龄 -> 17\n学号 -> 001"},
{"role": "assistant", "content": "##学生信息\n- 学生姓名:张三\n- 客户年龄:17岁\n- 学号:001"},
{"role": "user", "content": "格式化以下信息:\n姓名 -> 李四\n年龄 -> 12\n学号 -> 002"},
{"role": "assistant", "content": "##学生信息\n- 学生姓名:李四\n- 客户年龄:12岁\n- 学号:002"},
{"role": "user", "content": "格式化以下信息:\n姓名 -> 王五\n年龄 -> 13\n学号 -> 003"},
]
)
# 模型严格按照 Markdown 列表格式返回5.2 LangChain FewShotChatMessagePromptTemplate
LangChain 将 Few-Shot 示例管理结构化,避免手动拼接 messages 列表:
python
# 03 Few Shot Prompt Templates.ipynb
from langchain_openai import ChatOpenAI
from langchain_core.prompts import FewShotChatMessagePromptTemplate, ChatPromptTemplate
# Step 1:定义单个示例的格式模板(人机对话格式)
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "格式化以下客户信息:\n姓名 -> {customer_name}\n年龄 -> {customer_age}\n 城市 -> {customer_city}"),
("ai", "##客户信息\n- 客户姓名:{formatted_name}\n- 客户年龄:{formatted_age}\n- 客户所在地:{formatted_city}")
]
)
# Step 2:准备示例数据
examples = [
{
"customer_name": "张三", "customer_age": "27", "customer_city": "长沙",
"formatted_name": "张三", "formatted_age": "27岁", "formatted_city": "湖南省长沙市"
},
{
"customer_name": "李四", "customer_age": "42", "customer_city": "广州",
"formatted_name": "李四", "formatted_age": "42岁", "formatted_city": "广东省广州市"
},
]
# Step 3:创建 Few-Shot 模板
few_shot_template = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
# Step 4:组合最终 Prompt(Few-Shot 示例 + 真实问题)
final_prompt_template = ChatPromptTemplate.from_messages(
[
few_shot_template,
("human", "{input}"),
]
)调用验证:
python
final_prompt = final_prompt_template.invoke({
"input": "格式化以下客户信息:\n姓名 -> 王五\n年龄 -> 31\n 城市 -> 郑州"
})
response = model.invoke(final_prompt)
print(response.content)输出:
markdown
##客户信息
- 客户姓名:王五
- 客户年龄:31岁
- 客户所在地:河南省郑州市few_shot_template 自动展开为两轮 Human/AI 对话消息,模型精准习得格式规范。
5.3 Chain-of-Thought(思维链推理)
思维链是一种特殊 Few-Shot,通过提供带推理步骤的示例,引导模型逐步分析而非直接给结论:
python
# chain_of_thinking.py
# ❌ 错误示例(无推理步骤):示例答案不严谨,模型容易学错
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{"role": "user", "content": "该组中的奇数加起来为偶数:1、2、3、4、5、6、7,对吗?"},
{"role": "assistant", "content": "所有奇数相加等于16。答案为是。"}, # 错误!1+3+5+7=16 ✓ 但推理过程漏写
{"role": "user", "content": "该组中的奇数加起来为偶数:15、12、5、3、72、17、1,对吗?"},
]
)
# ✅ 正确 CoT 示例(带完整推理步骤)
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{"role": "user", "content": "该组中的奇数加起来为偶数:4、8、9、15、12、2、1,对吗?"},
{"role": "assistant", "content": "所有奇数(9、15、1)相加,9 + 15 + 1 = 25。答案为否。"},
{"role": "user", "content": "该组中的奇数加起来为偶数:17、10、19、4、8、12、24,对吗?"},
{"role": "assistant", "content": "所有奇数(17、19)相加,17 + 19 = 36。答案为是。"},
{"role": "user", "content": "该组中的奇数加起来为偶数:15、12、5、3、72、17、1,对吗?"},
]
)
print(response.choices[0].message.content)
# 所有奇数(15、5、3、17、1)相加,15+5+3+17+1=41。答案为否。Zero-Shot CoT: 不提供示例,仅在 prompt 末尾加「让我们来分步骤思考」:
python
# chain_of_thinking.py
response = client.chat.completions.create(
model="qwen-plus",
messages=[{
"role": "user",
"content": "该组中的奇数加起来为偶数:15、12、5、3、72、17、1,对吗?让我们来分步骤思考。"
}]
)
print(response.choices[0].message.content)技巧:在 prompt 末尾追加「让我们来分步骤思考」,即可激活 Zero-Shot CoT。现代推理模型(如 Qwen3 的 thinking 模式)已内置该能力,无需手动触发。
六、Output Parser:结构化输出
模型默认返回纯文本字符串,Output Parser 负责将其解析为 Python 结构(列表、JSON 对象等),便于后续程序处理。
6.1 原始 JSON 输出(Prompt 约束法)
最简单的方式:在 Prompt 中直接要求 JSON 格式,再用 json.loads() 解析:
python
# Ch1-4.py
from openai import OpenAI
import json, os
client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
prompt = """
生成一个由三个学生考试分数信息所组成的列表,以JSON格式进行返回。
JSON列表里的每个元素包含以下信息:
student_number、student_name、student_marks、phone。
所有信息都是字符串。
除了JSON之外,不要输出任何额外的文本。
"""
response = client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": prompt}]
)
content = response.choices[0].message.content
print(content)
# 解析为 Python 列表
data = json.loads(content)
print(data[0]["phone"]) # 13800138000输出示例:
json
[
{"student_number": "001", "student_name": "张三", "student_marks": "85", "phone": "13800138000"},
{"student_number": "002", "student_name": "李四", "student_marks": "92", "phone": "13900139000"},
{"student_number": "003", "student_name": "王五", "student_marks": "78", "phone": "13700137000"}
]6.2 CommaSeparatedListOutputParser(逗号列表解析)
LangChain 内置的列表解析器,自动生成格式指令并解析:
python
# 04 Output Parser _List.ipynb
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import CommaSeparatedListOutputParser
from langchain_core.prompts import ChatPromptTemplate
# Step 1:创建 Parser,获取格式指令
output_parser = CommaSeparatedListOutputParser()
parser_instructions = output_parser.get_format_instructions()
print(parser_instructions)
# Your response should be a list of comma separated values,
# eg: `foo, bar, baz`
# Step 2:将格式指令注入 Prompt
prompt = ChatPromptTemplate.from_messages([
("system", "{parser_instructions}"),
("human", "列出5个{subject}国家的汽车品牌。")
])
model = ChatOpenAI(
model="qwen-plus",
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
final_prompt = prompt.invoke({"subject": "中国", "parser_instructions": parser_instructions})
response = model.invoke(final_prompt)
print(response.content) # 比亚迪, 吉利, 长城, 奇瑞, 红旗
# Step 3:解析字符串 → Python 列表
result = output_parser.invoke(response)
print(result) # ['比亚迪', '吉利', '长城', '奇瑞', '红旗']6.3 PydanticOutputParser(JSON 结构化输出)
对于复杂结构,使用 PydanticOutputParser + BaseModel 定义数据结构,实现强类型解析:
python
# 05 Output Parser _ JSON.ipynb
from typing import List
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# Step 1:定义数据模型(相当于 JSON Schema)
class FilmInfo(BaseModel):
film_name: str = Field(description="电影的名字", example="拯救大兵瑞恩")
author_name: str = Field(description="电影的导演", example="斯皮尔伯格")
genres: List[str] = Field(description="电影的题材", example=["历史", "战争"])
# BaseModel 用于创建数据模式,Field 为属性提供描述和验证条件
# Step 2:创建 Parser(自动从 FilmInfo 生成 JSON Schema)
output_parser = PydanticOutputParser(pydantic_object=FilmInfo)
# Step 3:构建 Prompt,将格式指令注入 system
prompt = ChatPromptTemplate.from_messages([
("system", "{parser_instructions} 你输出的结果请使用中文。"),
("human", "请你帮我从电影概述中,提取电影名、导演,以及电影的体裁。电影概述会被三个#符号包围。\n###{film_introduction}###")
])
film_introduction = """
《唐人街探案》是由陈思诚执导,王宝强、刘昊然领衔主演的喜剧电影。
该片于2015年12月31日在中国上映。
"""
final_prompt = prompt.invoke({
"film_introduction": film_introduction,
"parser_instructions": output_parser.get_format_instructions()
})
model = ChatOpenAI(
model="qwen-plus",
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
response = model.invoke(final_prompt)
# Step 4:解析为 Pydantic 对象(强类型)
result = output_parser.invoke(response)
print(result) # film_name='唐人街探案' author_name='陈思诚' genres=['喜剧']
print(result.film_name) # 唐人街探案
print(result.genres) # ['喜剧']三种输出方式对比:
| 方式 | 优点 | 缺点 |
|---|---|---|
Prompt 约束 + json.loads() |
简单直接 | 无类型校验,解析错误难定位 |
CommaSeparatedListOutputParser |
自动生成指令,解析列表方便 | 仅支持扁平列表 |
PydanticOutputParser |
强类型、自动校验、可访问属性 | 需要预定义数据模型 |
七、LCEL Chain:链式调用
LCEL(LangChain Expression Language)使用管道符 | 将各组件串联,构建可复用的处理流水线。
7.1 核心语法
python
chain = prompt | model | output_parser
result = chain.invoke(input_dict)等价于逐步调用:
python
prompt_value = prompt.invoke(input_dict)
model_response = model.invoke(prompt_value)
result = output_parser.invoke(model_response)7.2 实例:列表解析链
python
# 06 Chain.ipynb
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import CommaSeparatedListOutputParser
from langchain_core.prompts import ChatPromptTemplate
output_parser = CommaSeparatedListOutputParser()
parser_instructions = output_parser.get_format_instructions()
prompt = ChatPromptTemplate.from_messages([
("system", "{parser_instructions}"),
("human", "列出5个{subject}生产的汽车的品牌。")
])
model = ChatOpenAI(
model="qwen-plus",
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# ✅ 构建 Chain(管道符串联)
chat_model_chain = prompt | model | output_parser
# 单次调用
result = chat_model_chain.invoke({
"subject": "中国",
"parser_instructions": parser_instructions
})
print(result)
# ['比亚迪', '吉利', '长城', '奇瑞', '长安']7.3 LCEL 数据流示意
输入 dict
│
▼
ChatPromptTemplate ──→ ChatPromptValue(SystemMessage + HumanMessage)
│
▼
ChatOpenAI ──→ AIMessage(原始文本响应)
│
▼
OutputParser ──→ Python 列表 / Pydantic 对象 / 字符串
│
▼
最终结果LCEL 优势 :链中每个组件都实现
Runnable接口,支持.invoke()(单次)、.batch()(批量)、.stream()(流式)三种调用方式,极大提升代码可读性与可维护性。
八、综合实战案例
8.1 产品评价摘要生成
将用户评价自动拆分为优缺点 Markdown 列表(ex1_concluding_review.py):
python
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
def get_openai_response(client, prompt, model="qwen-plus"):
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
)
return response.choices[0].message.content
product_review1 = """
刚刚在迪卡侬入手了一件基础款运动T恤,性价比确实很高------不到百元的价格,面料透气速干,
缝线工整,版型宽松适合运动,细节也很实用,比如反光条和无感印刷标签。
不过实物颜色比官网稍暗,速干效果比高端品牌略慢,而且领口螺纹偏薄,长期机洗可能会先松垮。
"""
product_review2 = "刚刚在nike入手了一件基础款运动T恤,垃圾。"
for product_review in [product_review1, product_review2]:
prompt = f"""
你的任务是为用户对产品的评价生成简要总结。
请把总结主要分为两个方面,产品的优点,以及产品的缺点,并以Markdown列表形式展示。
用户的评价内容会以三个#符号进行包围。
###
{product_review}
###
"""
print(get_openai_response(client, prompt))
print("-" * 60)输出示例(评价1):
markdown
**优点:**
- 性价比高,不到百元
- 面料透气速干,缝线工整
- 版型宽松,细节实用(反光条、无感标签)
**缺点:**
- 实物颜色比官网稍暗
- 速干效果不如高端品牌
- 领口螺纹偏薄,耐洗性存疑8.2 用户问题智能分类
基于 Prompt 模板的文本分类,将客服问题自动归类(ex3_textclassify.py):
python
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
def get_openai_response(client, prompt, model="qwen-plus"):
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
)
return response.choices[0].message.content
category_list = ["产品规格", "使用咨询", "功能比较", "用户反馈", "价格查询", "故障问题", "其它"]
classify_prompt_template = """
你的任务是为用户对产品的疑问进行分类。
请仔细阅读用户的问题内容,给出所属类别。类别应该是这些里面的其中一个:{categories}。
直接输出所属类别,不要有任何额外的描述或补充内容。
用户的问题内容会以三个#符号进行包围。
###
{question}
###
"""
q_list = [
"我刚买的智能手表无法同步我的日历,我应该怎么办?",
"手表的电池可以持续多久?",
"品牌的手表和ABC品牌的手表相比,有什么特别的功能吗?",
"安装智能手表的软件更新后,手表变得很慢,这是啥原因?",
"智能手表防水不?我可以用它来记录我的游泳数据吗?",
"我想知道手表的屏幕是什么材质,容不容易刮花?",
"请问手表标准版和豪华版的售价分别是多少?还有没有进行中的促销活动?",
]
for q in q_list:
formatted_prompt = classify_prompt_template.format(
categories=",".join(category_list),
question=q
)
print(f"问题:{q}\n分类:{get_openai_response(client, formatted_prompt)}\n")输出:
问题:我刚买的智能手表无法同步我的日历,我应该怎么办?
分类:故障问题
问题:手表的电池可以持续多久?
分类:产品规格
问题:品牌的手表和ABC品牌的手表相比,有什么特别的功能吗?
分类:功能比较
问题:安装智能手表的软件更新后,手表变得很慢,这是啥原因?
分类:故障问题
问题:智能手表防水不?我可以用它来记录我的游泳数据吗?
分类:使用咨询
问题:我想知道手表的屏幕是什么材质,容不容易刮花?
分类:产品规格
问题:请问手表标准版和豪华版的售价分别是多少?还有没有进行中的促销活动?
分类:价格查询8.3 小红书测评文案生成(System Prompt 工程)
通过精细化 System Prompt 控制输出风格与结构(ex2_rednotewritting.py):
python
from openai import OpenAI
import os
client = OpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
def get_response(client, system_prompt, user_prompt, model="qwen-plus"):
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
)
return response.choices[0].message.content
xiaohongshu_system_prompt = """
作为小红书平台上的科技产品测评专家,请撰写一篇关于最新款智能手表的专业测评文案,
平台为小红书,形式为口播视频。
目标读者是30到45岁之间的商务人士,比较关注健康监测和工作效率提升功能。
测评应包含以下部分:
1. 引人入胜的开场(介绍产品背景和测评目的)
2. 外观设计评价(材质、舒适度、屏幕表现)
3. 核心功能测试(健康监测、通知管理、运动追踪)
4. 电池续航表现(不同使用场景下的实测结果)
5. 性价比分析(与同价位竞品对比)
6. 明确的适用人群推荐和购买建议
语气应该专业且平易近人,使用第一人称叙述,穿插个人使用体验。
避免过度使用技术术语,但应包含必要的参数数据以支持观点。
特别注意:
1. 确保评价有理有据,避免无实际依据的夸张表述。
2. 客观指出产品的不足之处,不回避缺点。
3. 在结论部分提供清晰的使用场景建议,而不是简单的推荐与不推荐。
"""
print(get_response(client, xiaohongshu_system_prompt, "介绍Apple Watch 9"))System Prompt 工程要点:角色定义 + 目标受众 + 输出结构 + 语气风格 + 注意事项,五要素缺一不可。
九、总结
本文从阿里云百炼 API 申请出发,系统覆盖了 LangChain 的五大核心模块:
| 模块 | 核心类 | 作用 |
|---|---|---|
| Chat Model | ChatOpenAI |
统一封装大模型调用接口 |
| Message 类型 | SystemMessage / HumanMessage / AIMessage |
结构化对话消息,支持多轮上下文 |
| Prompt Template | ChatPromptTemplate |
模板化 Prompt,支持变量注入与批量处理 |
| Few-Shot / CoT | FewShotChatMessagePromptTemplate |
少样本示例引导模型输出格式 |
| Output Parser | CommaSeparatedListOutputParser / PydanticOutputParser |
结构化解析模型输出 |
| LCEL Chain | `prompt | model |
LangChain 的核心价值在于标准化与可组合性 ------无论使用 Qwen、GPT 还是 DeepSeek,只需修改 model 和 base_url 参数,其余代码完全不变。这为大模型应用的快速迭代和多模型切换提供了极大便利。
传统调用:OpenAI client → 手写 messages → json.loads()
LangChain:prompt | model | parser ← 三步完成,可复用,可组合参考资源