神经网络是模仿生物神经元层级结构的非线性计算模型,是深度学习的核心基础
核心能力是通过多层非线性变换,自动学习数据的层级化特征 ------ 从低级的边缘、纹理,到高级的语义、物体结构,无需人工设计特征
1.神经网络的基本构成部分
1.1 神经元
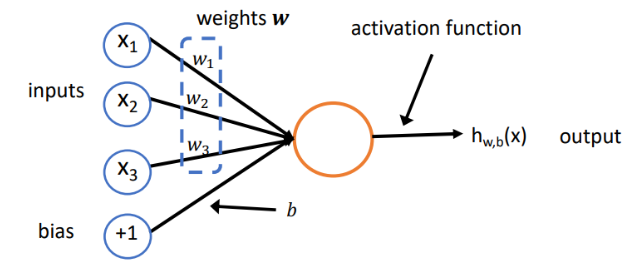
神经元在左边会接受 n 个数作为输入,然后在右边产生一个数的输出。这个神经元由参数 w 和 b 以及激活函数 f 构成。
神经元有三个输入,对应的三个权重分别为
。我们会计算一个乘积和
,然后将这个值与偏置
相加。这相当于输入有四个,其中第四个恒为1,而第四个输入对应的权重为
,这样偏置的计算可以统一到前面计算乘积和的步骤中。接着,这个乘积和会经过一个非线性的激活函数,然后就会得到这一个神经元的输出。
计算公式为:
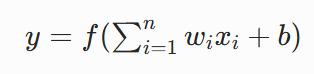
1.2 单层神经网络
利用多个这样的神经元联系在一起,可以构成一个只有一层的的神经网络
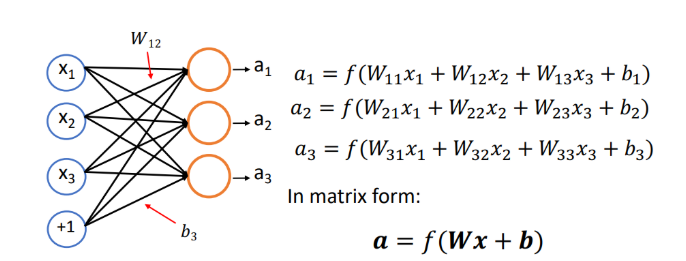
1.3 多层神经网络
单层神经网络可以继续叠加类似的层,变成一个多层的神经网络,其中每层都有若干个神经元。计算的时候从最左边的输入开始,依次计算每一层的结果,其中每一层的输出结果会作为下一层的输入,这就是前向计算
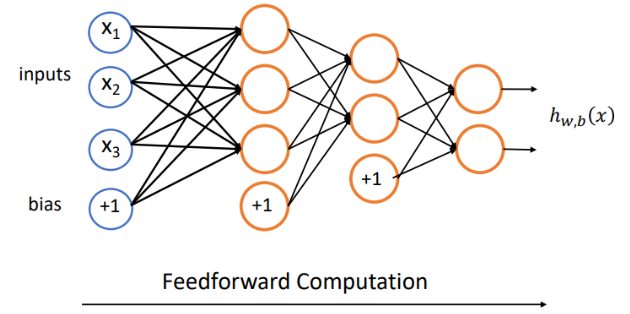
通常把在输入之上添加的多层网络称之为隐藏层 ,输入部分称之为输入层
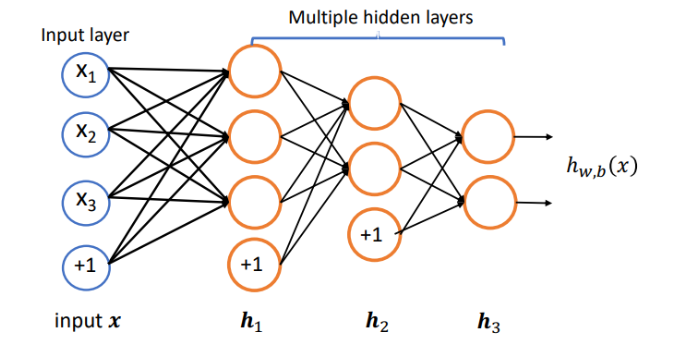
为了得到输出结果,我们需要在神经网络最右边再网络的最后一层,即输出层
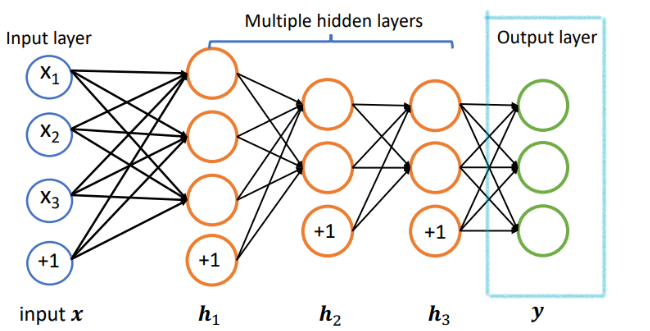
- 输入层:接收输入特征
- 隐藏层:进行数据处理和特征转换。隐藏层的神经元个数通常是一个超参数
- 输出层:输出结果,通常用于分类任务(如Softmax)或回归任务(如线性回归)
1.4 非线性激活函数
如果神经网络中并没有激活函数 ,神经网络中就只存在线性运算了,比如对于两层的神经网络,两层的运算其实可以被表示成单层的运算,也就是说在这样情况下,多层网络和单层网络的表达能力是相同的。因此我们需要引入非线性的激活函数,这样可以防止多层神经网络塌缩为一层的神经网络,我们也可以通过更加复杂的激活函数来加强多层网络的表达能力。
常见的激活函数:
1.Sigmoid
公式:
优点:输出有界,梯度计算简单(导数为),适合二分类任务的输出层。
缺点:输入绝对值 > 5 时导数趋近于 0,存在严重梯度消失 ;输出非零均值,权重收敛慢;指数运算计算成本高。
2.Tanh(双曲正切函数)
公式:
特点:零均值输出,解决了 Sigmoid 的非零均值缺陷,收敛速度显著快于 Sigmoid,早期广泛用于 RNN/LSTM。
缺点:仍存在梯度消失问题(输入绝对值 > 3 时导数趋近于 0);仍有指数运算成本。
3.Softmax 函数
公式:,n为类别总数
核心特点:将多维度输入转化为归一化的类别概率分布,是多分类任务的标准输出层激活函数,仅用于网络输出层,隐藏层几乎不使用。
1.5 输出形式
不使用激活函数,直接线性输出:
使用 sigmoid 激活函数:
使用 softmax 激活函数:
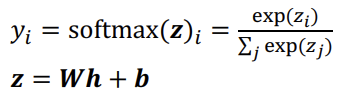
2.神经网络的训练方式
**训练流程:**数据准备 → 搭模型 → 选损失 / 优化器 → 前向算损失 → 反向算梯度 → 优化器更新参数 → 多轮迭代 + 验证 + 早停 → 测试评估
2.1 数据准备
收集数据:清洗(去脏数据、异常值、重复)
标注:分类 / 回归标签
划分:训练集 / 验证集 / 测试集(70%/20%/10%)
预处理:
- 归一化 / 标准化(比如缩到 0~1 或均值 0 方差 1)
- 编码(one-hot、词嵌入)
- 增强(图像翻转、裁剪;文本随机删词)
2.2 构建网络结构(定义模型)
选择网络类型:MLP、CNN、RNN、Transformer...
堆叠层:
- 线性层 / 卷积层
- 激活函数(ReLU/GELU)
- 池化、Dropout、BN(防止过拟合)
定义前向传播:输入 → 逐层计算 → 输出预测值
2.3 选择损失函数
回归:均方误差
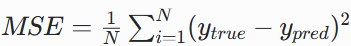
分类:交叉熵
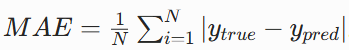
2.4 选择优化器(梯度下降法)
目标是最小化损失函数 ,核心思想是沿损失函数梯度的反方向迭代更新参数,逐步逼近损失函数的全局最小值
- 方向:损失函数上升最快的方向
- 大小:上升的速率(斜率)
- 公式:
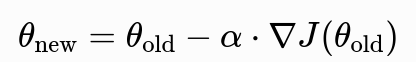 α是学习率,控制每一步走多远
α是学习率,控制每一步走多远
批量梯度下降(BGD)
- 更新规则 :用全部m个样本计算梯度,再更新参数(每轮迭代用所有数据);
- 公式:同上述线性回归示例;
- 优点 :梯度计算稳定、无噪声,收敛到全局最优(凸函数);
- 缺点 :超慢、内存开销大(大数据集无法一次性载入);
- 适用 :小数据集、凸损失函数(如简单线性回归)。
随机梯度下降(SGD)
- 更新规则 :每次只用 1 个随机样本计算梯度,立即更新参数(1 样本 = 1 次更新);
- 公式 :
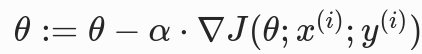
- 优点 :速度极快、适合大数据(逐样本更新,内存友好);可跳出局部最优;
- 缺点 :梯度噪声大、震荡严重(单样本梯度不准),收敛到最优附近后难收敛;
- 适用 :大数据集、在线学习、深度学习(标准 SGD)。
小批量梯度下降(Mini-Batch GD)
- 更新规则 :每次用 1 个小批量(batch,b个样本,1<b<m)计算梯度,更新参数;
- 公式 :
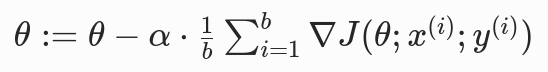
- 优点 :BGD+SGD 折中------速度快、梯度噪声小、收敛稳定;GPU 并行高效;
- 缺点 :需调batch size(常见 32/64/128);
- 适用 :几乎所有深度学习场景(CNN/Transformer),工业界默认首选。
| 算法 | 数据使用 | 速度 | 梯度噪声 | 收敛性 | 适用场景 |
|---|---|---|---|---|---|
| BGD | 全量样本 | 最慢 | 无 | 稳定到全局最优 | 小数据、凸函数 |
| SGD | 单样本 | 最快 | 极大 | 震荡、难精调 | 在线学习、大数据 |
| Mini-Batch | 小批量(32/64) | 快 | 小 | 稳定、易收敛 | 深度学习、工业界 |
2.5 前向传播
- 输入一个 batch 数据
- 从第一层到最后一层逐层计算
- 得到预测值 y^
- 计算损失 J
2.6 反向传播
核心逻辑:先算输出层误差 ,再反向 逐层传递误差,最后用误差算出所有参数的梯度
和梯度下降是互补关系:BP 算梯度,梯度下降更新参数,二者配合完成神经网络训练
输出层误差方程(BP1)
作用:计算输出层的误差项δL,是反向传播的起点
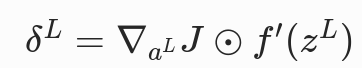
- 含义:输出层的误差 = 损失对输出层激活值的偏导 × 输出层激活函数的导数
- 分类任务最常用的组合(交叉熵损失 + Softmax 激活),这个公式会简化为:
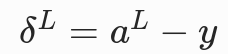 (预测值减真实值),无梯度衰减,完美规避梯度消失,是工程首选。
(预测值减真实值),无梯度衰减,完美规避梯度消失,是工程首选。
误差反向传播方程(BP2)
作用:将后一层的误差,传递到前一层,实现误差的反向流动,是 BP 的核心
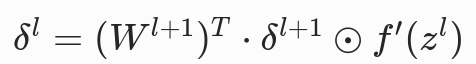
- 含义:当前层的误差 = 后一层权重的转置 × 后一层误差 × 当前层激活函数的导数
- 关键:误差从输出层往输入层逐层传递,每一层的误差仅依赖后一层的误差和当前层的激活导数,无需重复计算,极大提升了效率
偏置的梯度方程(BP3)
作用:用当前层的误差项,直接算出偏置bl的梯度
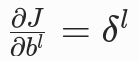
- 含义:偏置的梯度,完全等于当前层的误差项,无需额外计算
权重的梯度方程(BP4)
作用:用当前层的误差项和上一层的激活输出,算出权重Wl的梯度
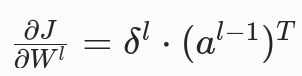
- 含义:权重的梯度 = 当前层误差 × 上一层激活输出的转置
- 关键:前向传播时已经保存了每一层的al−1,反向传播时直接复用,无需重复计算
2.7 参数更新
用反向传播算出的梯度 ,按优化器规则实际更新参数 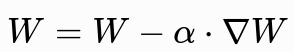
2.8 循环训练 + 验证 + 早停
对多个 Epoch 循环:
- 遍历所有 batch:前向 → 反向 → 更新
- 每轮结束用验证集算 loss/acc
- 监控:
- 训练集 loss:不断下降
- 验证集 loss:下降后平稳(上升 = 过拟合)
- 早停:验证集不涨了就停
- 最后用测试集评估最终性能(从未见过的数据)
3.常见的神经网络结构
3.1 卷积神经网络CNN
定义
卷积神经网络是一种通过局部连接、权值共享 和池化操作,来高效、分层地提取输入数据空间特征的神经网络架构
结构组成
输入层:输入图像
卷积层:特征提取
激活层:引入非线性变换
池化层:降维、防止过拟合
输入层
在处理图像的CNN中,输入层一般代表了一张图片的像素矩阵 。可以用三维矩阵代表一张图片 。三维矩阵的长和宽代表了图像的大小,而三维矩阵的深度代表了图像的色彩通道。比如黑白图片的深度为1,而在RGB色彩模式下,图像的深度为3

在输入层进行输入时,便是将对应图片的三个通道的矩阵进行输入

卷积层
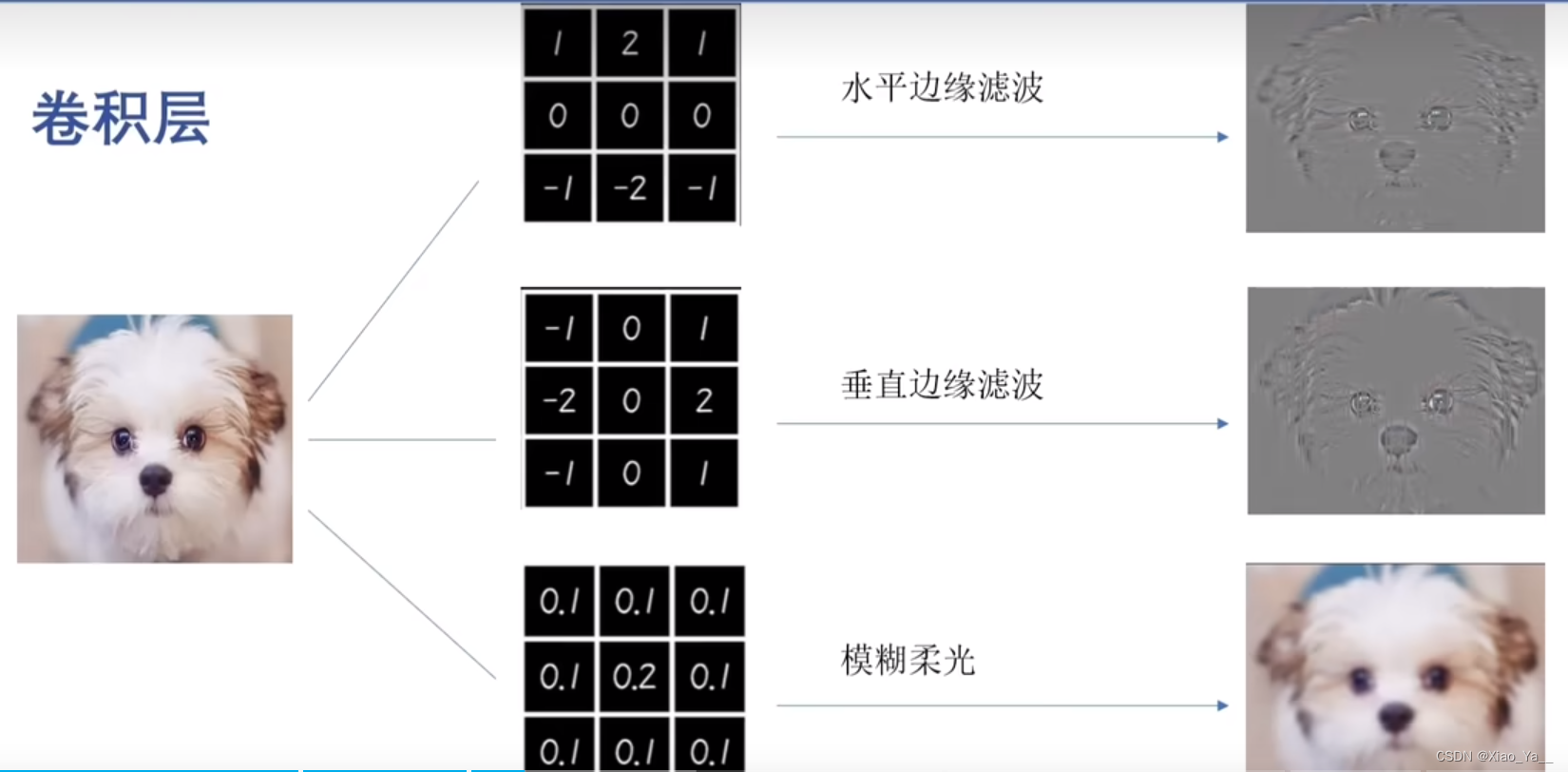
卷积操作的完整过程
- 卷积核在输入特征图上,按设定的步长滑动;
- 每滑动到一个位置,卷积核的权重和对应区域的像素值逐元素相乘再求和,加上偏置,得到输出特征图的一个像素值;
- 滑动完成后,生成一张新的特征图(输出通道数 = 卷积核的个数)。
单通道输入,单卷积核
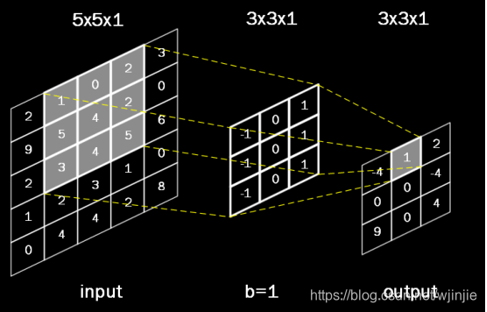
多通道输入,单卷积核
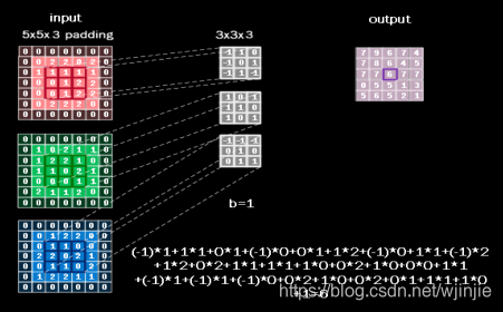
多通道输入,多卷积核
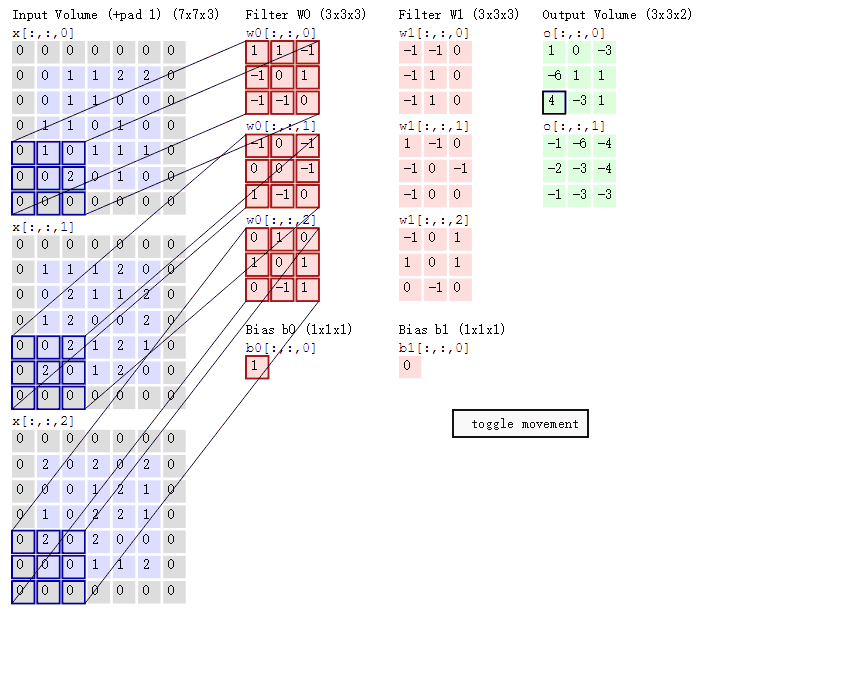
池化层
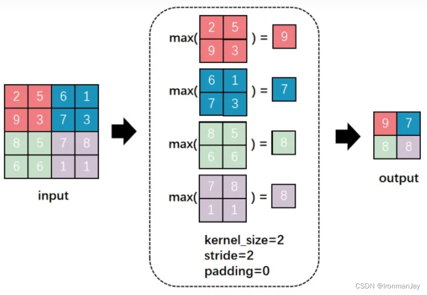
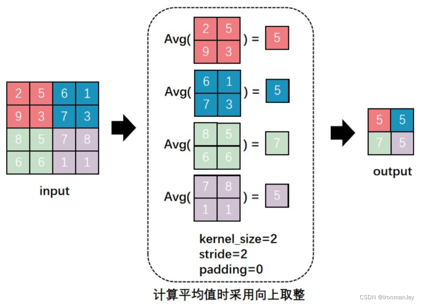
通过对特征图进行下采样来降低维度、增强模型鲁棒性
最大池化
平均池化
|-----------|----------|----------|---------|
| 输入特征图 | 最大池化 | 平均池化 | 说明 |
| 边缘检测图 | 保留边缘强 | 弱化边缘 | 最大池化更适合 |
| 背景均匀图 | 随机选点 | 保持均匀 | 平均池化更稳定 |
| 稀疏激活图 | 保留激活点 | 稀释信号 | 最大池化更有效 |
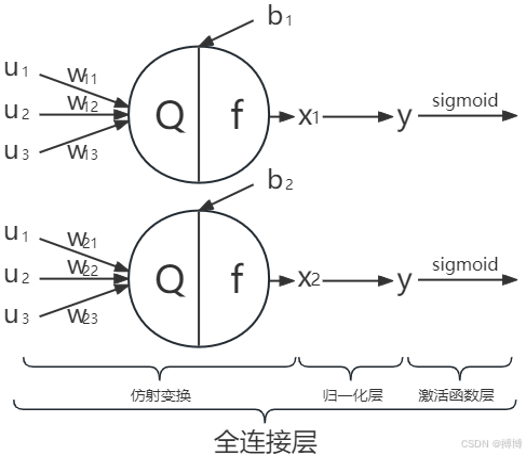
全连接层
将卷积 / 池化提取的特征映射到输出类别
数学表示:输出 = 输入 * 权重矩阵 + 偏置向量
作用
- 特征整合:将卷积/池化提取的局部特征整合为全局特征,输出固定大小向量,用于后续任务
- 分类决策:将学到的特征映射到具体类别或数值,完成分类/回归等最终决策
- 特征降维:将高维特征映射到低维空间,实现特征选择、减少计算量、防止过拟合
3.2Transformer
定义
一种用于自然语言处理(NLP)和其他序列到序列任务的深度学习模型架构神经网络
组成
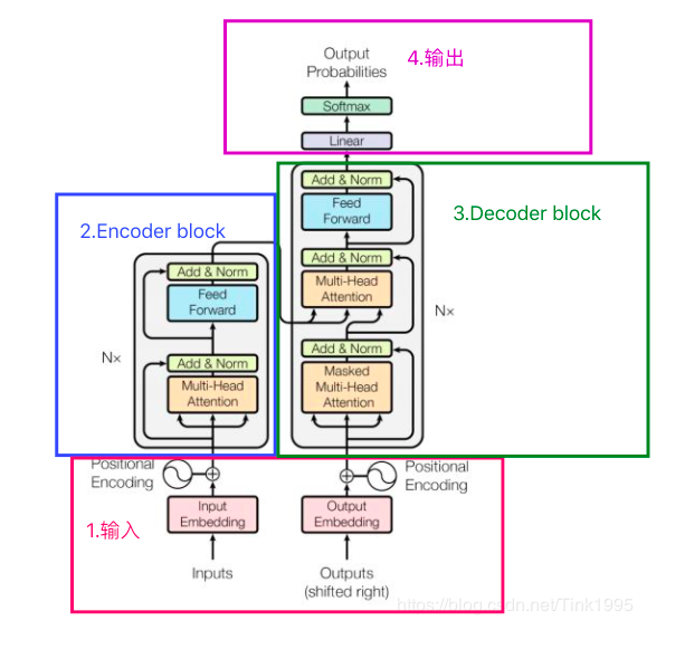
输入预处理模块
Transformer 的自注意力机制天然无法感知序列的顺序 / 位置信息,也无法直接处理离散文本,因此所有输入必须先经过两步预处理,才能送入编码器 / 解码器。
1.Token Embedding
核心作用:将离散的文本 Token(字 / 子词 / 单词)映射为固定维度的稠密向量,把人类可理解的文本转化为模型可计算的语义表示
2. Positional Encoding
核心作用 :为模型注入序列的位置 / 顺序信息,弥补自注意力机制无法区分 Token 先后顺序的核心缺陷。
编码器 Encoder 栈
编码器的核心目标是对输入序列进行全局语义编码,生成包含完整上下文信息的特征表示,是文本理解类任务的核心
1. 整体结构
标准为6层完全相同的 Encoder 层串行堆叠,前一层的输出直接作为后一层的输入,最终输出的编码特征会送入解码器的交叉注意力层
2. 单 Encoder 层的固定组成(严格顺序不可调换)
输入 → 多头自注意力层 → Add & LayerNorm → FFN 层 → Add & LayerNorm → 输出
① 多头自注意力层(Multi-Head Self-Attention)
负责建模输入序列中所有 Token 之间的全局依赖关系,让每个 Token 的特征都融合整句话的上下文语义
- 核心逻辑:将 Q(查询)、K(键)、V(值)三个向量拆分为
h个独立头,每个头独立计算自注意力,最终将所有头的输出拼接,再经过一次线性变换得到最终结果。 - 核心特点:双向注意力,每个 Token 都能关注序列中所有其他 Token(包括前文和后文),无信息屏蔽。
② 残差连接 + 层归一化(Add & LayerNorm)
- 残差连接:将子层的输入和输出直接相加,彻底解决深层网络的梯度消失问题,让超深层 Transformer 能够稳定训练。
- LayerNorm(层归一化):对每个样本的特征向量做归一化,稳定训练过程、加速模型收敛,是 Transformer 的标配。
- 规范说明:原始论文采用 Post-Norm,工业界主流模型(GPT、BERT)均采用 Pre-Norm,训练稳定性更强。
③ 前馈神经网络(FFN)
对每个 Token 的特征向量做独立的非线性变换,增强模型的表达能力,不做跨 Token 的信息交互。
- 标准结构:2 层全连接层 + 激活函数,公式为:
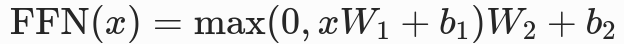
- 关键细节:原始论文使用 ReLU 激活,当前主流大模型均采用 GELU 激活;中间层维度通常为
d_model的 4 倍(标准 d_model=512,中间层维度 2048)。
④ 第二组残差连接 + 层归一化
与前一组完全一致,将 FFN 层的输入和输出相加后做层归一化,结果输出到下一层 Encoder。
解码器 Decoder 栈
解码器的核心目标是基于编码器的输入语义,自回归地逐 Token 生成输出序列,是文本生成类任务的核心
- 整体结构
标准为6 层完全相同的 Decoder 层串行堆叠,前一层的输出作为后一层的输入,最终输出送入预测模块。
- 核心约束:自回归生成要求模型只能关注已经生成的 Token,不能看到未来的 Token,因此比 Encoder 多了掩码机制和交叉注意力层。
- 单 Decoder 层的固定组成(严格顺序不可调换)
输入 → 掩码多头自注意力层 → Add & LayerNorm → 交叉注意力层 → Add & LayerNorm → FFN 层 → Add & LayerNorm → 输出
① 掩码多头自注意力层(Masked Multi-Head Self-Attention)
与 Encoder 自注意力的核心区别是加入了下三角因果掩码(Causal Mask)。
- 核心作用:强制模型在生成第 i 个 Token 时,只能关注第 i 个之前的 Token(已生成的内容),完全屏蔽 i 之后的未来 Token,防止信息泄露。
- 其他计算逻辑与多头自注意力完全一致。
② 交叉注意力层(Encoder-Decoder Attention / Cross-Attention)
连接编码器和解码器的核心层,负责将编码器生成的输入语义信息,融合到解码器的生成过程中,让输出内容与输入精准对齐(如机器翻译中,让译文和原文语义对应)。
- 核心逻辑:Q(查询)来自上一层 Decoder 的输出,K(键)和 V(值)来自 Encoder 栈的最终输出,其余计算逻辑与多头注意力一致。
输出预测模块
位于 Transformer 的最末端,负责将解码器输出的特征转化为最终的预测结果。
- 线性全连接层 :将解码器最终输出的
d_model维特征向量,映射到与词表大小一致的维度,得到每个 Token 的 logits 分数。 - Softmax 激活层:将 logits 分数转化为归一化的概率分布,概率最高的 Token 即为模型预测的下一个输出 Token。
- 自回归生成逻辑 :将预测出的 Token 拼接到输入序列末尾,再次送入解码器,循环往复,直到生成结束符
<EOS>或达到最大长度。