@TOC((AI升级篇)OpenGL渲染与几何内核那点事-(二-1-(14):你的3D查看器,是怎么一步步先试着造个数据工厂,向学会"教"机器人看世界的而努力)
背景:
试想一下,如果你是一个造机器人的工程师,想让机器人的 AI 视觉大模型学会精准抓取一个螺栓,你需要多少张照片来训练它? 答案是: 成千上万张不同角度、带有精准像素级标注的照片。【同时,真实世界中采集带标注的三维数据成本极高,我们称之为 Sim2Real(仿真到现实)的鸿沟。】
手工一张张拍?人工用鼠标去抠图?这得干到猴年马月! 为了解决这个痛点,我用 C++ 写了一个「AI 数据工厂」看这里。
代码仓库入口:
github源码地址(https://github.com/AIminminAI/Huhb3D-Viewer)。
gitee源码地址(https://gitee.com/aiminminai/Huhb3D-Viewer)。
解决方案:
- 只要丢给它一个工业 CAD 模型(比如 STL文件),它就能自动在虚拟空间中 360° 环绕拍照,瞬间吐出:
- 📸 RGB 真实渲染图:rgb/frame_XXXX.png
- 🏷️ 像素级语义分割 Mask (基于曲率算法,自动认出哪里是螺栓、孔洞、法兰):mask/mask_XXXX.png
- 📏 深度图(Depth) (告诉机器人距离多远),depth/depth_XXXX.png + .raw
- 📐 6DoF 相机位姿 (告诉机器人从哪个角度抓),camera_poses.json
- 📂 最后直接打包成 AI 训练最爱吃的 COCO/YOLO 格式。
- label_legend.txt【类别ID→名称→RGB颜色映射】、description.json【DeepSeek-V3 视觉API生成零件特征描述】
实际效果:
- 想看视频:
huhb_synthetic_data
- 不想看视频:也有图片:










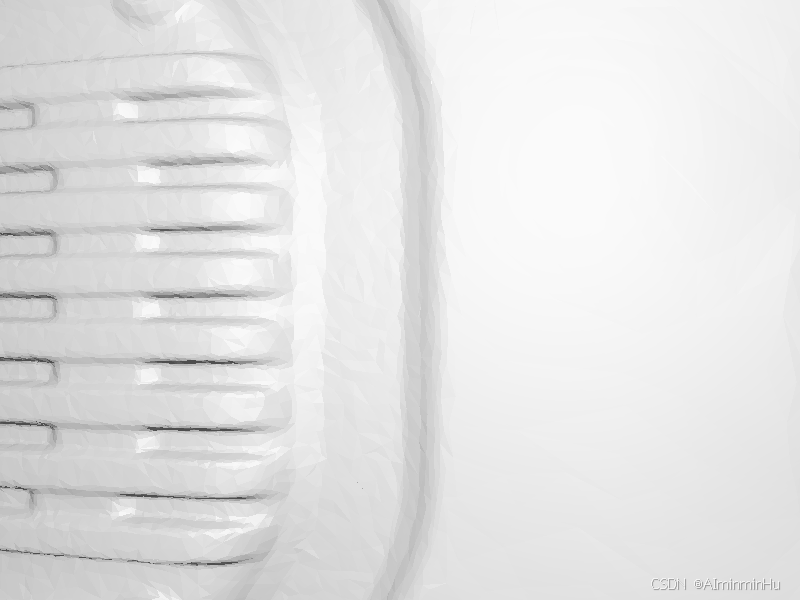

【还有附带的:camera_poses.json、label_legend.txt、manifest.json,具体内容见附录】
巨人的肩膀:
- OpenGL 4.6 Specification
- Vulkan 1.3 Specification
- Khronos Group SPIR-V Whitepaper
- 历代GPU架构白皮书(NVIDIA Fermi至Blackwell,AMD GCN至RDNA 4)
系列文章规划:
- OpenGL渲染与几何内核那点事-项目实践理论补充(一-1-(7)-番外篇:点击的瞬间,发生了什么?
- OpenGL渲染与几何内核那点事-项目实践理论补充(一-1-(8)-番外篇:当你的 CAD 遇上"活"的零件)
- OpenGL渲染与几何内核那点事-项目实践理论补充(一-2-(1)-当你的CAD想"联网"时:从单机绘图到多人实时协作)
- OpenGL渲染与几何内核那点事-项目实践理论补充(一-2-(2)-当你的CAD需要处理"百万个螺栓"时:从内存爆炸到丝般顺滑)
- OpenGL渲染与几何内核那点事-项目实践理论补充(一-2-(3)-当你的协同CAD服务器面临"千人同屏"时:从单机优化到分布式高并发)
- OpenGL渲染与几何内核那点事-项目实践理论补充(二-1-(2):当你的CAD学会"听话":从鼠标点击到自然语言命令)
- OpenGL渲染与几何内核那点事-项目实践理论补充(二-1-(4)-当你的CAD学会"听话":从"按钮点击"到"自然语言诊断"的演进之路
- OpenGL渲染与几何内核那点事-项目实践理论补充(二-1-(4):在你的两个AI小宠物GEMINI与TRAE的交互下,帮你实现能听懂人话并诊断模型错误的小助手)
- OpenGL渲染与几何内核那点事-项目实践理论补充(二-1-(5):在你的GEMINI和TRAE 宠物帮助下,帮你实现能听懂人话并诊断模型错误的小助手-问题总结和解决篇)【重要提示:本文依旧按照之前的风格进行表达,如果你想看看具体如何通过你的电子宠物【gemini、trae等】相互之间的交互(包括提示词、反馈结果,如果根据结果继续向AI发起追问,直至拿到你想要的结果),完成你的需求和目标,可以看看如下的两篇:】
- (AI篇)OpenGL渲染与几何内核那点事-项目实践理论补充(二-1-(6):从"硬编码"到"AI语义",你的开源项目听懂人话了吗?------ 一个图形程序的自然语言进化史)
- (AI篇)OpenGL渲染与几何内核那点事-项目实践理论补充(二-1-(8):当你的CAD学会了"接单":(Agent的核心机制)AI函数调用从"鸡同鸭讲"到"心想事成"的进化史)
书接上回:隔壁AI部门找上门了
上次我们聊到,你的CAD软件终于能处理百万零件了,老板又把你叫进办公室。他说:"小C,现在AI这么火,隔壁AI部门想让我们帮忙生成一些训练数据。他们训练机器人抓零件,需要大量带标注的零件图片。"
你挠了挠头,心想:我的软件虽然能渲染3D模型,但那都是给人 看的,颜色好看就行。给AI看?AI需要什么?你当时的第一反应是:"不就是多截几张图吗?"
于是,就有了这个项目的 第一代。
🛠️ 第一代:单向可视化版本("能看就行")
最初的版本(我们叫它V1)非常单纯。它就是你现在看到的Huhb3D-Viewer的前身------一个基于 C++ 和 OpenGL 的简单3D模型加载器。
你最开始是怎么做的?
用户来找你,说想看看机械零件的3D样子。你翻开OpenGL入门教程,写了第一个文件加载器。
最初的需求极其简单------"我不需要改,能看就行。" 你自己一开始也是这么想的:写一个Demo,支持加载 STL、OBJ 这种最常见的网格文件。这两个格式是3D世界里最通用的"普通话",因为从30年前开始,各种CAD软件、3D扫描仪、3D打印切片软件就都能导出或识别它们了。
- STL :就像一个"三角形傻大个",因为它简单粗暴,只存三角形的三个顶点坐标和法向量,没有任何颜色、材质信息。早期3D打印只能认识它,因为它足够简单,不会出错。你的加载器读它最快,因为它就是一串
float数组。 - OBJ :比STL复杂一点,可以带纹理坐标和法线,但本质上还是离散的三角面片。你在代码里只解析了顶点位置(
v),没碰它的材质文件(mtl),因为你觉得反正后面要上高级材质,用不上它自带的。
你把模型读进来,塞进 顶点缓冲对象(VBO) ,写好最简单的 顶点着色器(Vertex Shader) 和 片元着色器(Fragment Shader),模型就显示在屏幕上了。你还顺手加了个简单的光照模型(Phong或Blinn-Phong),让模型看起来有个大概的立体感。
第一个人用了发现:这完全不够
你把V1版本发给AI部门的小李。小李是搞视觉的,拿到手跑了一遍,马上就来找你了:
"哥们,这不对啊!"
"怎么了?这不挺好看的吗?" 你看着屏幕上光滑的齿轮模型。
"这只是个3D查看器。我需要的是训练AI的数据,光有图片没用。 " 小李跟你解释:"我们训练机器人去识别并抓取零件,需要告诉机器人'零件离你有多远'。你这截的图,背景全是纯黑色,零件材质像塑料玩具,光照死白死白的,完全不能模拟真实工厂的环境。"
"还有!" 小李补充道:"在真实工厂里,光照是不均匀的,金属零件会有高光和反射。你这些图训练出来的AI,拿到真摄像头面前就'瞎'了,它会以为世界上的东西都是黑背景的塑料。"
你一听,确实是自己想简单了。3D给人 看和给AI看,需求完全不同。人眼看到一张图就能自动脑补距离和材质,AI却需要精确的"数字"。
你的改进方向清晰了:需要增加数据的深度信息和物理真实感。
深度解析:从STL到渲染管线的起点
1. 网格文件格式的深度剖析
STL (Stereolithography)
- 起源:1987年由3D Systems公司为立体光刻(SLA)快速成型系统开发。
- 数据结构:极其简单,分为ASCII和二进制两种。二进制STL文件头80字节+4字节(面片数)+对每个三角形循环存储(法向量3个float + 三个顶点共9个float + 2字节属性)。
- 为何存在至今:因为格式简单到任何程序员都能在半小时内写一个解析器,保证了跨平台、跨软件的绝对兼容性(CAD、CAM、3D打印切片软件)。
- 致命缺陷:完全没有拓扑信息(不知道哪个三角形和哪个是邻居),数据冗余(一个顶点被多个三角形共享,要存多次),无单位,无颜色。
- 你的加载器实现细节 :解析时要注意STL的顶点存储顺序是右手定则(大拇指指向法向量方向,四指弯曲方向为顶点顺序),逆转会导致光照计算错误。
OBJ (Wavefront .obj)
- 起源:由Wavefront Technologies为它的Advanced Visualizer动画包开发。
- 数据结构 :行文本格式,核心关键字
v(顶点)、vt(纹理坐标)、vn(法向量)、f(面)。f行能定义三角形或四边形甚至更多边形。- 为什么你只解析了v :因为OBJ的核心是自由形态的多边形面,存储在它配套的
.mtl材质文件中,你需要多写一个解析器。早期为了快速出Demo,先不处理纹理和高级材质是合理的工程折衷。- 隐藏的坑 :OBJ文件的索引是从1开始的,不是C++习惯的0;面可以是
f v/vt/vn三部分索引,要正确处理缺失纹理或法线索引的情况。2. 固定管线的魅力与OpenGL V1.0时代的渲染
- 最早的OpenGL(1992年1.0版)只有固定渲染管线 ,你无需写着色器,而是通过
glLightfv、glMaterialfv、glBegin/glEnd来配置。你的V1虽然已经用了可编程管线,但写的着色器逻辑其实是"高配版的固定管线"------你只是实现了一个标准的Phong或Blinn-Phong光照模型。- Phong模型:环境光(Ambient)+ 漫反射(Diffuse)+ 镜面反射(Specular)。计算简单,速度快。
- Blinn-Phong模型:对Phong的改进,用半程向量(Halfway Vector)代替反射向量来计算镜面高光,计算上更高效且高光看起来更自然。
- 为什么它们现在不够用了:因为它们是经验模型,不遵守能量守恒。例如,金属粗糙时的镜面高光会扩散变暗,而Phong只是一个死白的高光斑,完全无法模拟。这引出了后文的PBR。
📸 第二代:多模态渲染版本("能训模型")
了解了小李的痛点后,你没急着改代码,而是先去做了些功课。你需要两样东西:物理真实感 和距离信息。
PBR着色器:让塑料玩具变成金属
针对"材质像塑料玩具"的问题,你找到了解决方案------PBR(基于物理的渲染)。这是近十年游戏和电影工业的核心技术,已经在现实世界被验证过无数次了。
你最早看到PBR这个词是在一些3A大作的技术分享文章里。他们为了吹嘘自己的画面多真实,会说:"我们使用了PBR管线!"你研究了一下,发现它背后的思想极其朴素:一切光照都必须遵守能量守恒定律(出射光的总量不能超过入射光的总量)。
一开始,大家实现PBR都用的是最经典的Cook-Torrance模型,它其实就是对现实世界光照的一个数学简化。你把它照搬进了你的片元着色器。
你给用户暴露了三个最关键的材质属性:
- Albedo(反照率/基础色):物体不包含任何光照信息的"本色"。非金属通常是较暗的颜色(因为会吸收光),金属通常没有漫反射,所以它的Albedo就是它的反射色。
- Metallic(金属度):一个0到1的滑动条。非0即1,要么是金属,要么是非金属(比如灰尘、铁锈被认为是非金属)。金属的反射色会染上Albedo的颜色,非金属的反射色永远是白色。
- Roughness(粗糙度):0是绝对光滑的镜子,1是完全粗糙的漫反射表面。你用它来控制镜面高光的大小和扩散程度。
你的片元着色器里,原来简单的Phong光照被替换成了长长的GGX、Schlick Fresnel、Smith函数调用。这些单词虽然唬人,但背后的逻辑就是反复用这几个粗糙度参数去算光线的反射和散射概率。
- GGX (Trowbridge-Reitz)分布函数:用来模拟微表面(物体表面肉眼不可见的凹凸)的法线分布,决定了高光的大小。
- Schlick's approximation(施利克近似):用来快速计算菲涅尔效应(视线越接近平行表面,反射越强),避免了计算昂贵的指数运算。
- Smith函数/几何衰减:模拟微表面自己遮挡自己(Shadowing/Masking),在极小角度下会急剧衰减反射。
你把这些搞定了,重新编译运行。在屏幕上看到的结果让你和小李都眼前一亮:铝金属的齿轮不再是一片死白高光,而是随着光源角度变化产生了锐利且带有轻微颜色倾向的反射;粗糙的铸铁件表面则均匀散射着柔和的环境光。
这就是PBR的"去参数化"魅力------以前调塑料质感要反复斟酌10个互相影响的参数(环境光、漫反射、镜面反射、高光指数等),现在你只需设定"金属度"和"粗糙度",光照结果就是物理正确的。
多图层导出:教AI"看"距离和材质
画面问题解决了,接下来要解决小李的另一个核心需求:"我需要知道零件离摄像头有多远。"
你的解决方案是帧缓冲对象(FBO)和多渲染目标(MRT)。OpenGL允许你创建一个自定义的FBO,然后同时把一张图的不同"零件"(RGB颜色、深度值、材质ID)写到不同的纹理附件上。
实现时就像搭积木:你新建了一个FBO,给它绑定了三张纹理------第一个是传统的RGBA(用于存RGB图),第二个存Float类型的深度图(GL_R32F),第三个存整型的物体ID图(GL_R32I)。在渲染的那一帧,你的像素着色器除了输出常规的fragColor之外,还额外用gl_FragDepth输出视空间下的线性深度值到第二张纹理,用整型Uniform变量输出当前零件的唯一ID到第三张纹理。
这样,每一帧渲染结束,你就同时拿到了三个结果。小李拿到的深度图是一张灰度图像,越黑代表离相机越近,越白越远。结合物体ID图,AI在训练时就知道了------"这个像素是螺栓-003,距离摄像头1.23米"。
第二个人用了发现:这数据太粗糙了
你把V2发给了AI组的另一个同事小张。小张是做语义分割的。他跑了一下午,又来找你了。
"图很棒,物理感很好。但我不知道图里哪个部分是'孔',哪个部分是'螺栓',手动标注太慢了! "
"还有,"他指着深度图的一个角落,"你看这里,你在球面上随机撒点拍照,结果拍了一堆差不多的角度,底部和顶部却几乎没有。我训练的抓取模型在某些角度效果很好,换到仰角30度就全错了。"
你明白过来:自动生成数据和科学采样,才是工业落地的瓶颈。
深度解析:PBR、多模态渲染与摄影测量学
1. PBR的理论完备性:从Cook-Torrance到迪士尼BSDF
- Cook-Torrance模型(1981年):这是现代PBR的起点。它将表面的反射描述为微面元的镜面反射,引入三项关键函数:法线分布函数D(你用Unity/Unreal常用GGX)、菲涅尔项F(用Schlick近似)、几何衰减项G(Smith GGX)。你的着色器就是这套经典物理模型的直接实现。
- 迪士尼BSDF原则(2012年) :SIGGRAPH 2012上迪士尼发布了一套设计给艺术家使用的"原则性"BRDF。它引入了一个设计友好的参数集 ,包括
subsurface(次表面)、metallic、specular、specularTint、roughness、anisotropic、sheen、sheenTint、clearcoat、clearcoatGloss。虽然你在项目中只暴露了Metallic-Roughness子集,但迪士尼BSDF奠定了现代材质模型"正交化、无冗余"的设计美学。一个艺术家不再需要凑Phong Index、Specular Color、Diffuse Color来调金属感,而只需拉一个Metallic滑动条------这正是你项目最终选择Metallic-Roughness工作流的原因。- 微面元理论的核心 :
- 菲涅尔效应:Augustin-Jean Fresnel在19世纪发现的现象:光在介质界面会部分反射部分折射。Schlick近似是一个计算高效(由指数改为乘法)且视觉精确的工程妥协,替代了原生复杂的复数计算。
- 粗糙度/微表面 :不是把模型真的变粗糙,而是用统计方法模拟一个像素内成千上万个微小平面的法线分布------这是一个纯粹的统计学结论转成Shader代码的优雅工程实践。
2. 多模态数据------摄影测量学的数字化重现
- 深度图与RGB的对齐 :在OpenGL中,
gl_FragCoord.z是在裁剪空间 的非线性值。为了让AI直接使用,你需要在着色器里手动线性化深度 :linearDepth = (2.0 * near * far) / (far + near - z * (far - near))。这就是为什么工业级合成数据集(如NVIDIA DRIVE Sim)总是附带浮点深度图------非线性深度会引入极大的舍入误差,导致远处测距失败。- 物体ID图(Instance Segmentation) :V2时代你的FBO里只是存了一个
uint。在工业界,这对应**实例分割(Instance Segmentation)**任务。你给每个"零件实例"分配ID,为V3自动生成文本描述埋下伏笔------因为AI不仅想知道"这是螺栓",还想知道"这是第37号螺栓"。- OpenGL的FBO与Unity/Unreal的Render Texture对比 :在Unity中你拖一个
Render Texture到相机就是MRT;而在C++ OpenGL中你需要手写glFramebufferTexture2D绑定、指定GL_COLOR_ATTACHMENT0/1/2,以及调用glDrawBuffers指定着色器输出到哪几个缓冲区。这是引擎开发者必须迈过的底层坎,也是你代码里最关键的管线控制段之一。
📐 第三代:工程化闭环版本("标准化管线")
你针对小张提出的两个痛点,开始把项目从一个"渲染工具"升级为一个 "数据工厂" 。工厂最重要的就是标准化 和自动化。
斐波那契球面采样:给相机装个"科学罗盘"
第一个要解决的是相机分布不均匀的问题。之前你在球面上随机生成经纬度 (θ, φ) 来拍照,直觉上是均匀的,但实际上这种"经纬度采样"会在球的两极(θ=0或π附近)产生密集堆积。这是因为球面面积微元是 r² sinθ dθ dφ,经线在极点收缩成一个点,同样数量的经纬度跨度,在两极覆盖的实际面积远小于赤道。
你的解决方案是 球面斐波那契采样 。这背后的数学极其巧妙,利用了 黄金分割比例 的"最不理性"特性来生成均匀的点集。
生成第 i 个点的算法惊人的简洁,却达到了完美的视觉均匀性。你写了一个循环,对于给定的相机总数N,计算每个点的Y轴倾角(cos(θ) = 1 - (2i+1)/N,保证面积等分)和XY平面的方位角(φ = π * (1+√5) * i mod 2π,黄金比例螺旋展开)。有了方向向量,你只需让相机lookAt原点,配合上世界UP向量,就能生成一张张视角绝对无偏的数据。
12类语义分割:让AI直接"读懂"零件
第二个是语义标注问题。小张之前说手动标几千张图的"孔"、"螺栓"、"法兰"耗时巨大。你决定把这块知识硬编码进C++引擎里,自动生成语义Mask(语义分割掩码)。
你给每个三角面片设置了一个枚举类型:FaceType,可以根据法线方向和几何形状自动分类,整个分类逻辑称为 几何启发式规则:
- 根据法向量与Z轴的夹角分类 :
abs(normal.z) > 0.95归为水平面 ;abs(normal.z) < 0.05归为侧面 ;其余归为斜面。这三种面涵盖了零件的大部分外表面。 - 特征识别 :
- 孔洞:通过检测一组彼此相连的、法线朝向内侧(即朝向圆心)的圆柱面来识别通孔或盲孔。
- 螺栓:针对外螺纹标准件的几何特征(六边形头部+圆柱杆的组合)做模板匹配。
- 法兰:一个圆柱外壁上突出的环形平面或带螺栓孔的凸台平面。
- 退化面:面积极小(由超短边组成)的过渡面、倒角面。这类面在物理仿真中常引起问题,标记出来供算法过滤。
你在渲染这帧语义图时,不再输出RGB颜色,而是让片元着色器根据FaceType枚举直接输出一个固定颜色(比如:(0,0,255) 蓝色代表孔洞,(255,0,0) 红色代表螺栓),生成一张彩色语义标签图。AI模型拿到这张图,就相当于有人类专家用不同颜色提前标出了每个结构。
6DoF位姿导出:不止"看到",还要"知道怎么看"
最后,你加入了 6DoF(自由度)相机位姿 的记录。对于机器人视觉来说,模型不仅要"看"这个零件,更要学"从哪个角度看"。
6DoF代表 **平移(位置)**和 旋转(姿态) 各三个自由度。你选取了相机在世界坐标系下的世界矩阵 View Inverse(即从相机原点看向零件的变换)并记录投影参数,组合成一个 模型视图投影矩阵 。每一帧图片对应的这个矩阵,你存成一个标准的4x4浮点数组写入配套的JSON或NPY文件。有了准确的6DoF真值,AI才能学会做 位姿估计------看到一个零件图片,直接推算出它在世界中的位置和角度。
第三个人用了发现:接入标准不统一
你把V3发给合作实验室后,实验室里的几个研究生反应很积极:"数据质量完全够发论文了!但格式太乱。我用YOLO训练,他用Detectron2,每次都要写脚本把语义图转来转去。"
你顿时理解了:工程上,数据格式必须"说人话"。
深度解析:采样策略、几何分类、位姿真值
1. 采样策略的数学本质:在SO(3)上做均匀随机旋转
- 球面斐波那契采样的最优性 :它本质上是一个在二维圆盘上生成低差异序列(Low-discrepancy Sequence) 的方法,投影映射到半球面上效果依然优异。对比完全随机采样(蒙特卡洛)收敛速度是
O(1/√N),而低差异序列能接近O(1/N)。这意味着同样的数据量,你的数据分布能更好地覆盖整个视角域,AI训练收敛更快。- 四元数与欧拉角的避坑 :你导出的是4×4矩阵,不是欧拉角。因为欧拉角存在万向节死锁(Gimbal Lock):当中间旋转轴(如Pitch)转到±90°,第一和第三轴重合,失去了一个旋转自由度,此时任何沿着这两个轴的旋转结果都相同。工业界和所有现代SLAM/VO系统(如ORB-SLAM)都使用四元数或旋转矩阵来存储位姿。你的4×4矩阵恰好是一个包含平移+旋转的齐次变换矩阵,对此会心一笑的AI研究员可以直接送入网络。
2. 几何启发式面分类算法(Classic Computational Geometry)
- 你实现的法线分区 是CAD/CAM软件的特征识别最原始但最稳健的形态。商业几何内核(如Parasolid, ACIS)拥有更复杂的图同构、图匹配方法来自动识别槽、沉头孔、加强筋等制造特征。你的方法虽然朴素,但对于标准化零件(Piping、Flange)有奇效,因为标准的工业设计本来就遵循"顶面平行基座、侧面垂直基座"的原则。
- 更深一步是 局部几何特征描述子 (如PFH, FPFH, SHOT)。如果零件更自由曲面(NURBS),你无法简单用
法线.z > 0.95分类。就需要计算每个点的FPFH特征(基于点对之间的角度和距离直方图),然后聚类。这是3D点云语义分割的经典方法。- 你的实现等于在渲染管线中进行了一次轻量级的计算几何预处理,实现了实时的实例/语义分割。
3. 6DoF Pose真值的物理意义------PnP问题的另一面
- 所有基于RGB的6DoF位姿估计算法(从经典的EPnP 到现代的PoseCNN )都在解同一个方程:给定一组3D点(你的零件模型)和它们在图像上的2D投影(你渲染的图片),求相机位姿。你做的其实是PnP的逆过程:给定相机位姿,算出2D投影来生成训练数据。
- 你存储的4×4投影矩阵,包含了
内参矩阵(K) × 外参矩阵(R|t)的组合。在工业实践中,通常分开存储内参(f_x, f_y, c_x, c_y)和外参(R, t),更便于AI框架处理。你存整矩阵,对方可以轻松分解(用SVD或直接取左上3×3的旋转部分),无损传输信息。
🚀 第四代:产品化与智能化版本("开箱即用的数据工厂")
面对第三阶段格式不统一的最后痛点,你开始了最后一轮冲刺,把项目变成一个非技术人员也能用的产品。
全格式兼容:一键生成COCO和YOLO格式
你写了一个Python脚本 mask_to_coco.py,内部自动将彩色语义标签图(红=螺栓,蓝=孔洞)解析为COCO JSON 和YOLO 格式。
- COCO JSON 采用标准的目标检测/实例分割字典结构,包括
"images","annotations","categories",每个分割区域被表示为轮廓点串(segmentation)和包围盒(bbox)。它是MS COCO比赛的官方格式,Detectron2、MMDetection等框架零代码加载。 - YOLO 格式 则极其轻量,每个图片对应一个
.txt文件,每行是class_id cx cy w h(归一化的包围盒中心及宽高)。这直接适配YOLOv5/v8等追求极简配置和速度的检测器。
你还在脚本里自动做了数据检查:剔除面积<50像素的噪声区域、处理遮挡关系(前景物体Mask覆盖背景物体)、划分训练集/验证集。脚本跑完,研究生的数据管线从"半天写转换脚本"变成了"双击运行,自动出数据集"。
AI智能描述:让大模型看图说话
最科幻的一步,你接入了 DeepSeek-V3 的多模态视觉API。你实现的逻辑是:在RGB图、深度图和语义图都生成完毕之后,将RGB截图(可选地叠加语义Mask热力图)编码为Base64,通过HTTP请求发送给DeepSeek-V3模型。提示词工程(Prompt)被设计为:"你是一个顶级工业视觉质检专家。请详细描述此机械零件的几何特征、表面处理工艺、存在的制造缺陷以及功能性结构..." 模型返回的自然语言文本被存储为 description.json。这意味着用户拿到数据集时,不仅有图、有标签,还有一段AI生成的详细文档。
Web UI产品化:告别命令行
最终的临门一脚,你用 Streamlit 写了一个极简的网页界面。用户可以通过浏览器上传STEP/STL/OBJ,在滑条上选择生成图片数量(如1000张),勾选输出格式(COCO? YOLO?),点击"开始生成"按钮。后台C++引擎在子进程中运行,Python Streamlit负责编排、进度条、以及最后的一键打包下载ZIP(包含所有子目录:rgb/, depth/, mask_vis/, coco.json, description.json)。
此刻,你的项目变成了一个真正的 MVP产品 ------一个对外部非技术用户友好的、标准化、自动化的具身智能合成数据生成器。
最终的数据矩阵:你交付的"黄金"
现在,面对小李、小张和那个实验室研究生,你终于可以自信地展示你的最终数据矩阵了:
| 数据 | 状态 | 价值 |
|---|---|---|
| RGB + PBR | ✅ 完整 | 提供从金属哑光到镜面抛光的视觉特征 |
| 12类语义 Mask | ✅ 完整 | 像素级精准标注,直接可训练语义分割网络 |
| Float 深度图 | ✅ 完整 | 为机器人距离感知、抓取避障提供真值 |
| 6DoF 相机位姿 | ✅ 完整 | 为所有需要空间推理的任务(如位姿估计、SLAM)提供精确监督信号 |
| COCO / YOLO 格式 | ✅ 完整 | 主流框架开箱即用,零代码开始训练 |
| AI 智能描述 | ✅ 完整 | 附带零件特征的自然语言文本描述,可用于训练视觉-语言多模态模型 |
深度解析:数据集标准化与多模态大模型
1. 数据集的终极形态:从COCO到Token
- COCO格式的计算机视觉垄断地位 :COCO(Common Objects in Context)不仅是数据集,更是一套数据标注的标准协议。定义了5种任务(目标检测、关键点检测、Stuff分割、全景分割、图像字幕)的统一JSON Schema。你实现的
mask_to_coco.py本质是把连续像素值转为多边形轮廓的矢量化算法 (通常用OpenCV的findContours或Ramer-Douglas-Peucker算法简化)。这个转换是数据管线中最容易出错的一环:像素级Mask和轮廓不能完美互逆,边界像素点的归属处理(如孔洞内壁属于孔还是侧面),都需要根据AI模型的训练策略(如是否做边缘忽略)精细调参。- YOLO格式与边缘端部署 :YOLO格式的简洁让它极端适配边缘端(NVIDIA Jetson, Raspberry Pi等)。归一化坐标能让不同分辨率的图片共用同一个标签文件。COCO转YOLO时,包围盒从
[x_min, y_min, width, height]转为[cx, cy, w, h]且归一化,你脚本里的除法cx/img_w等必须用float,且小心精度损失。2. 多模态大模型 (LVLM, Large Vision-Language Model) 与合成数据
- DeepSeek-V3的视觉管道:它接收Base64图片和文本提示,内部经ViT(Vision Transformer)提取视觉特征,由LLM主干融合理解。你抓取它用来生成零件描述,其实复用了海量互联网预训练中的工业常识。
- 更激进的未来:用LVLM做质检 :你的数据管线组合了确定性合成数据(几何精确的RGB+Depth+Mask) 与生成式AI(VLM描述) 。在一线大厂,这种"合成数据N,通过VLM筛选高质量子集,然后SFT一个专用小模型"的范式正成为主流。你不需要雇100个QC,而是用VLM做第一次粗筛,这正是你为它留下
description.json接口的长远眼光。
故事还在继续...
从"一个简单的STL查看器"到"具身智能合成数据生成器",你带着这个项目走过的每一步,都不是一步到位的技术堆砌 ,而是一个真实的问题引发一个具体的技术决策。
现在,你,准备好继续这个故事了吗?
- 如果想像唠嗑一样,去了解一些小知识,快去看看视频吧:
- 认准一个头像,保你不迷路:
- 抖音:搜索"GodWarrior"
- 快手:搜索"AIYWminmin"
- B站:搜索"宇宙第一AIYWM"
您要是也想站在文章开头的巨人的肩膀啦,可以动动您发财的小指头,然后把您的想要展现的名称和公开信息发我,这些信息会跟随每篇文章,屹立在文章的顶部哦
附录:
camera_poses.json
bash
[
{
"frame_id": 0,
"position": [0.0, 0.0, 5.0],
"rotation_euler": [0.0, 0.0, 0.0],
"fov_degrees": 45.0,
"view_matrix": [
[1.0, 0.0, 0.0, 0.0],
[0.0, 1.0, 0.0, 0.0],
[0.0, 0.0, 1.0, -5.0],
[0.0, 0.0, 0.0, 1.0]
],
"projection_matrix": [
[2.414, 0.0, 0.0, 0.0],
[0.0, 2.414, 0.0, 0.0],
[0.0, 0.0, -1.002, -0.200],
[0.0, 0.0, -1.0, 0.0]
]
},
{
"frame_id": 1,
"position": [1.18, 0.0, 4.86],
"rotation_euler": [0.0, -13.6, 0.0],
"fov_degrees": 45.0,
"view_matrix": [
[0.972, 0.0, 0.236, -0.0],
[0.0, 1.0, 0.0, 0.0],
[-0.236, 0.0, 0.972, -5.0],
[0.0, 0.0, 0.0, 1.0]
],
"projection_matrix": [
[2.414, 0.0, 0.0, 0.0],
[0.0, 2.414, 0.0, 0.0],
[0.0, 0.0, -1.002, -0.200],
[0.0, 0.0, -1.0, 0.0]
]
}
]label_legend.txt
bash
# Semantic Label Color Legend
# Category -> (R, G, B) in 0-255 range
0 FreeSurface 127 127 127
1 HorizontalPlane 0 0 255
2 LateralPlane_X 0 255 0
3 LateralPlane_Z 255 0 0
4 NearHorizontal 255 255 0
5 NearLateral_X 255 0 255
6 NearLateral_Z 0 255 255
7 Degenerate 255 127 0
8 Reserved1 127 0 255
9 Reserved2 0 127 255manifest.json
bash
{
"version": "2.0",
"generator": "Huhb3D-SyntheticDataPipeline",
"rgb_count": 100,
"mask_count": 100,
"depth_count": 0,
"has_legend": true,
"has_ai_description": false,
"has_camera_poses": false
}