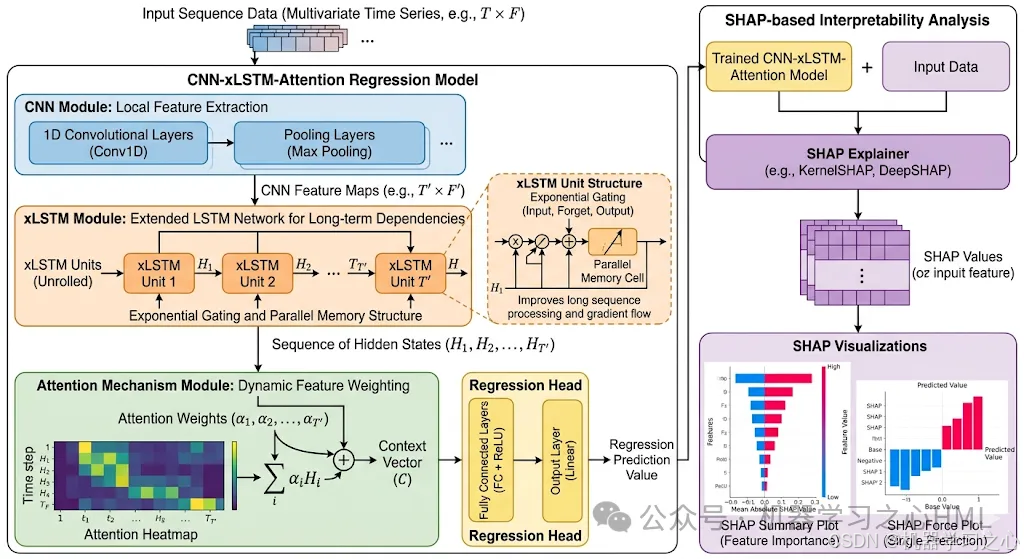
CNN-xLSTM-Attention 回归模型:从原理到 SHAP 可解释性全解析
融合卷积、长短期记忆与注意力机制,让时间序列预测同时做到高精度与高解释性。
在工业预测、故障诊断、能源负荷预测等任务中,我们经常需要处理结构复杂的表格型时间序列数据。今天,我们深入一种新颖的混合深度学习架构------CNN-xLSTM-Attention ,并配合 SHAP 可解释性分析,在实现高精度回归的同时,让模型决策过程一目了然。
一、模型原理:三大核心模块的协同设计
CNN-xLSTM-Attention 模型通过级联三个互补模块,分别解决特征提取、长时序建模和关键信息聚焦的问题。
1. CNN 前端:局部感受野捕捉时空纹理
一维卷积(Conv1D)沿时间轴滑动,提取多尺度的局部模式。例如在机械振动信号中,CNN 能自动学习冲击、周期性波动等短时特征,生成富含时空信息的高维特征图,供给下游序列模型。
2. xLSTM 核心:指数门控 + 并行记忆结构
传统 LSTM 受限于遗忘门的饱和效应和串行记忆更新。xLSTM(Extended LSTM) 做出两点革命性改进:
- 指数门控:利用指数激活函数实现更灵活的信息遗忘与保留,缓解长程梯度消失。
- 并行记忆结构:将记忆单元升级为矩阵形式,允许并行信息流动,显著提升对超长序列的建模能力和训练效率。
xLSTM 处理 CNN 输出的特征序列,捕获其间复杂的长期依赖关系,为后续注意力层提供高质量上下文表示。
3. 注意力机制:动态聚焦关键时间步
并非所有时间步对最终预测同等重要。注意力模块通过自动学习标量权重,加权聚合 xLSTM 各时刻的输出,强化高贡献时刻、抑制噪声干扰,最终生成固定长度的上下文向量送入回归器。
三者协同工作:CNN → 局部特征提取 → xLSTM → 长程依赖建模 → Attention → 自适应聚焦 → 回归输出,充分发挥各自优势。
二、代码全流程实现(Python)
我们设计了一套完整的端到端流程,支持 CSV/Excel 数据输入、模型训练、评估可视化及 SHAP 解释。以下为核心代码结构与功能解析。
2.1 数据加载与标准化
python
import pandas as pd
from sklearn.preprocessing import StandardScaler
def load_data(file_path, target_col):
df = pd.read_csv(file_path) # 也支持 .xlsx
X = df.drop(columns=[target_col]).values
y = df[target_col].values.reshape(-1, 1)
return X, y
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_scaled = scaler_X.fit_transform(X)
y_scaled = scaler_y.fit_transform(y)支持时序窗口切片,将表格数据转化为监督学习样本(滑动窗口法)。
2.2 模型构建(PyTorch)
python
class CNN_xLSTM_Attention(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super().__init__()
self.conv1 = nn.Conv1d(in_channels=input_size, out_channels=64, kernel_size=3, padding=1)
self.relu = nn.ReLU()
# xLSTM 可基于 mLSTM 或 sLSTM 实现,这里用自定义 xLSTM 单元
self.xlstm = xLSTM(input_size=64, hidden_size=hidden_size, num_layers=num_layers)
self.attention = Attention(hidden_size)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# x shape: (batch, seq_len, features) -> (batch, features, seq_len)
x = x.permute(0, 2, 1)
x = self.relu(self.conv1(x))
x = x.permute(0, 2, 1) # (batch, seq_len, conv_out)
out, _ = self.xlstm(x) # out: (batch, seq_len, hidden_size)
context = self.attention(out)
return self.fc(context)其中 xLSTM 单元可采用开源实现(如 xlstm 库),注意力为缩放点积注意力或加性注意力。
2.3 训练与评估指标
- 损失函数:MSE Loss
- 优化器:Adam
- 评估指标:MAE、MSE、RMSE、R² Score
python
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
mae = mean_absolute_error(y_true, y_pred)
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
r2 = r2_score(y_true, y_pred)自动生成训练/测试集指标对比表格,并输出训练-测试损失曲线。
2.4 可视化分析
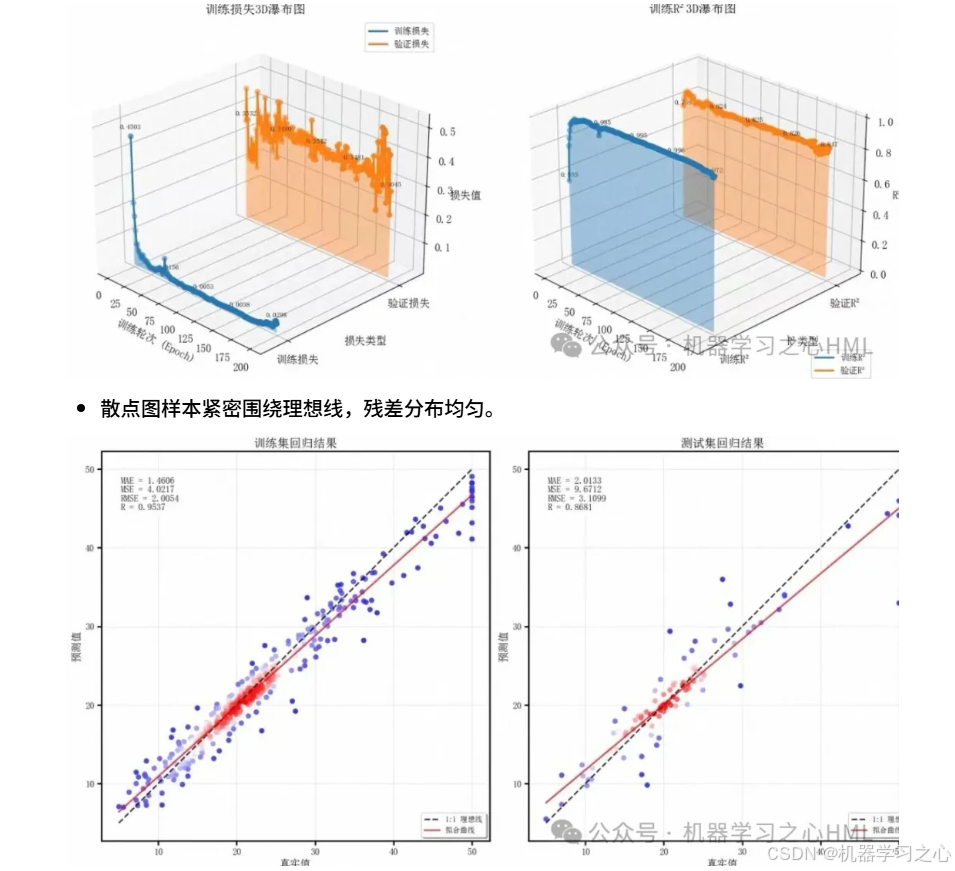
- 损失曲线对比:实时监控过拟合,判断训练是否充分。
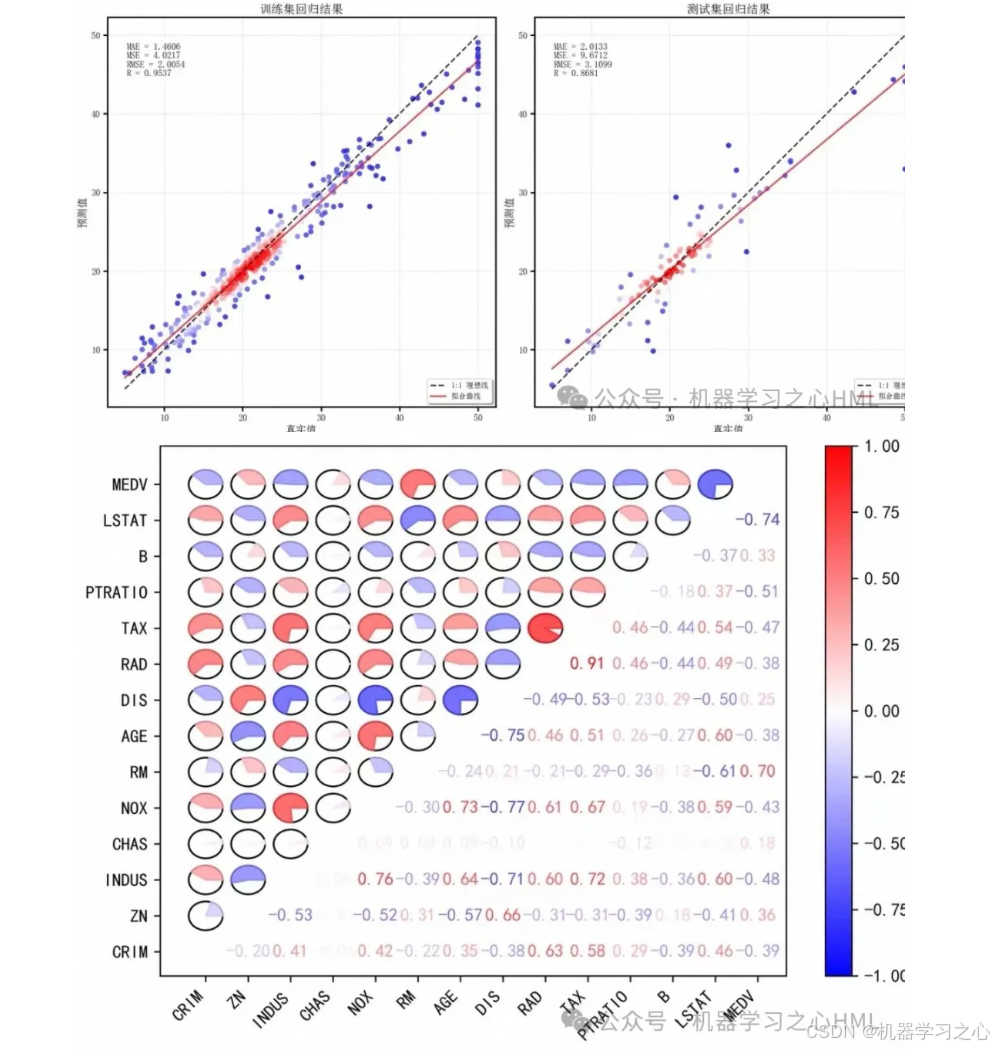
- 预测值 vs 真实值散点图:理想情况应沿 y=x 线集中,偏离程度反映模型偏差。
python
plt.scatter(y_test, y_pred, alpha=0.5)
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'r--')三、SHAP 可解释性:揭开黑箱的利器
模型精度再高,若无法解释,在关键决策场景中依然难以落地。我们引入 SHAP (SHapley Additive exPlanations) 对训练好的 CNN-xLSTM-Attention 模型进行事后解释。
3.1 全局特征重要性
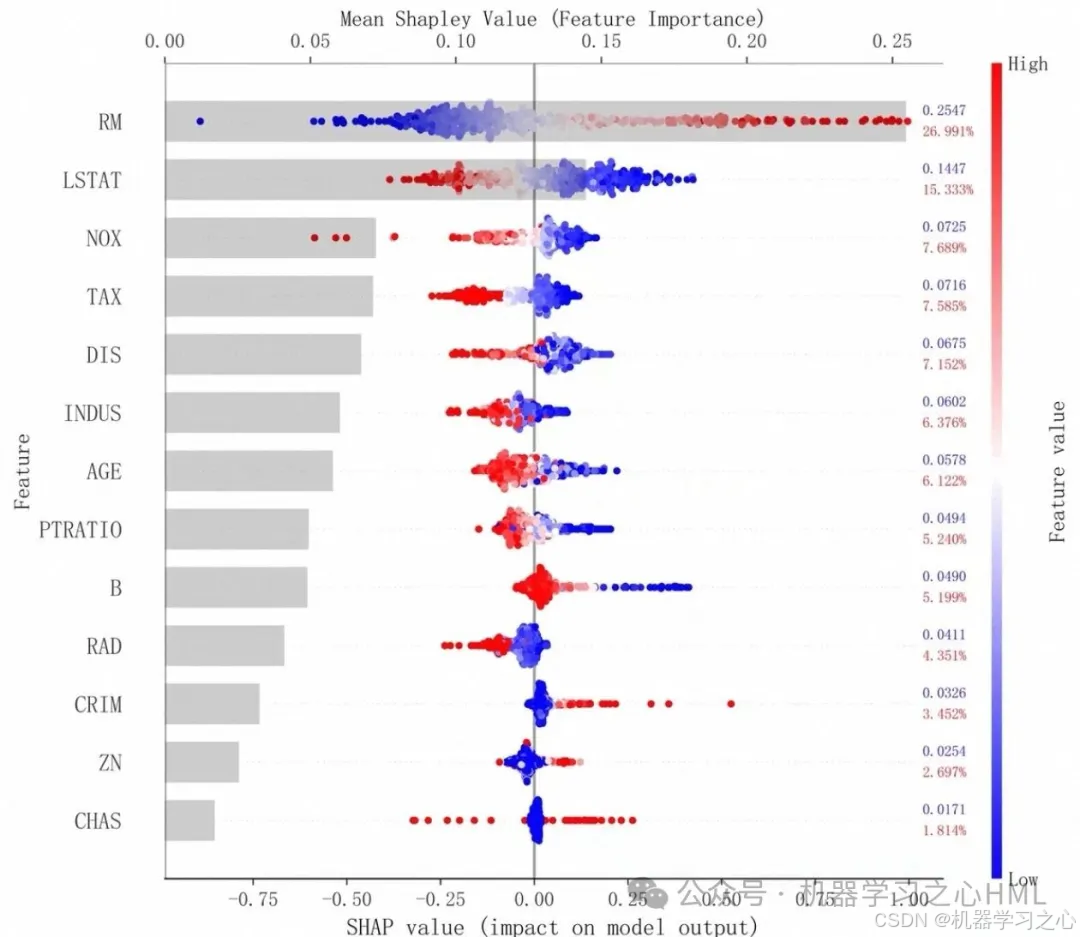
使用 shap.Explainer 计算各特征对输出的平均边际贡献,并以条形图展示。
python
explainer = shap.Explainer(model, X_train_sample)
shap_values = explainer(X_test_sample)
shap.summary_plot(shap_values, features=X_test_sample, feature_names=feature_names, plot_type="bar")条形图中,条形长度代表特征重要性,颜色表示正负向影响(需基于具体 SHAP 值)。
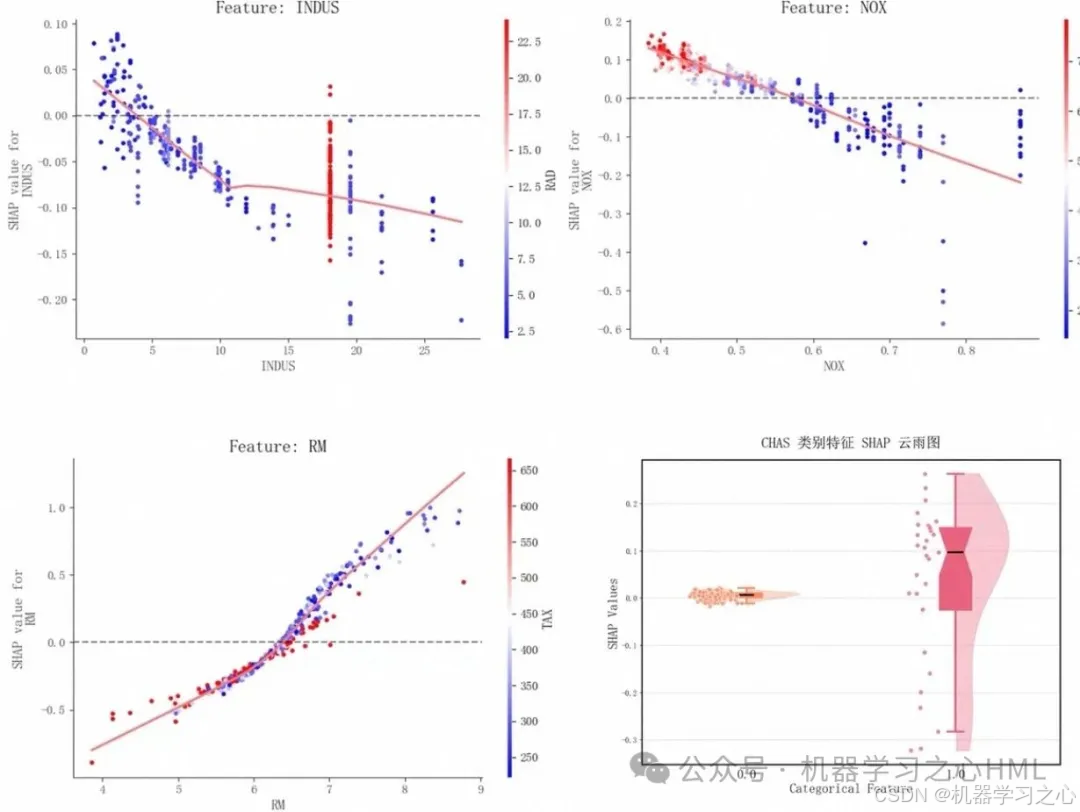
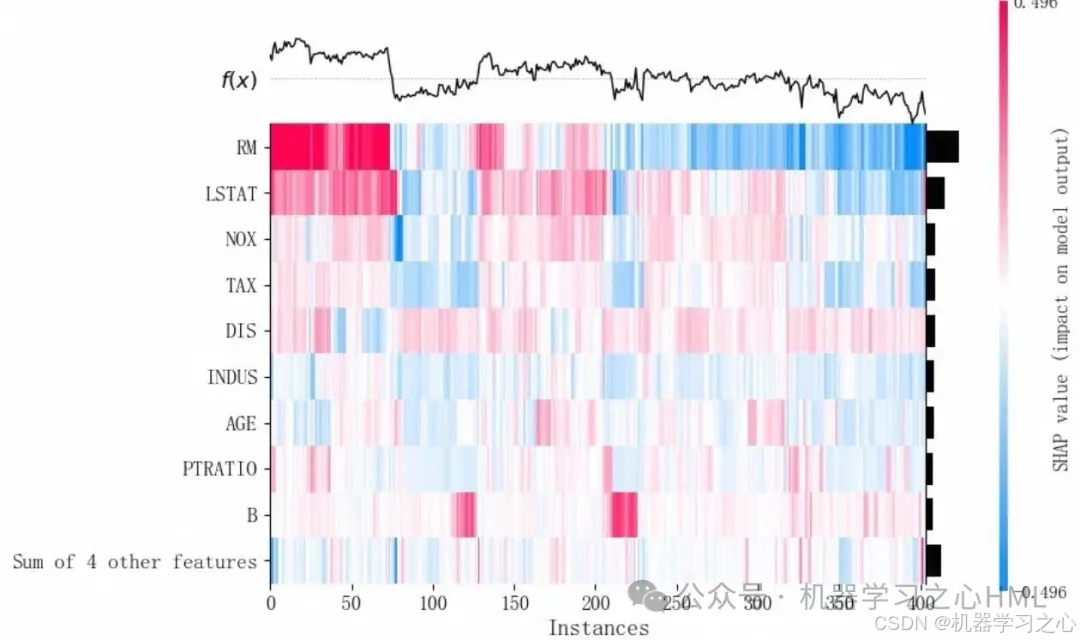
3.2 蜂巢图(Beeswarm)
蜂巢图将每个样本的每个特征 SHAP 值散点分布展示,颜色代表特征值大小:
- 可观察特征值与 SHAP 的非线性关系,例如某一特征取值高时产生正向贡献,低时负向贡献,揭示边际效应。
python
shap.plots.beeswarm(shap_values)3.3 单样本局部解释
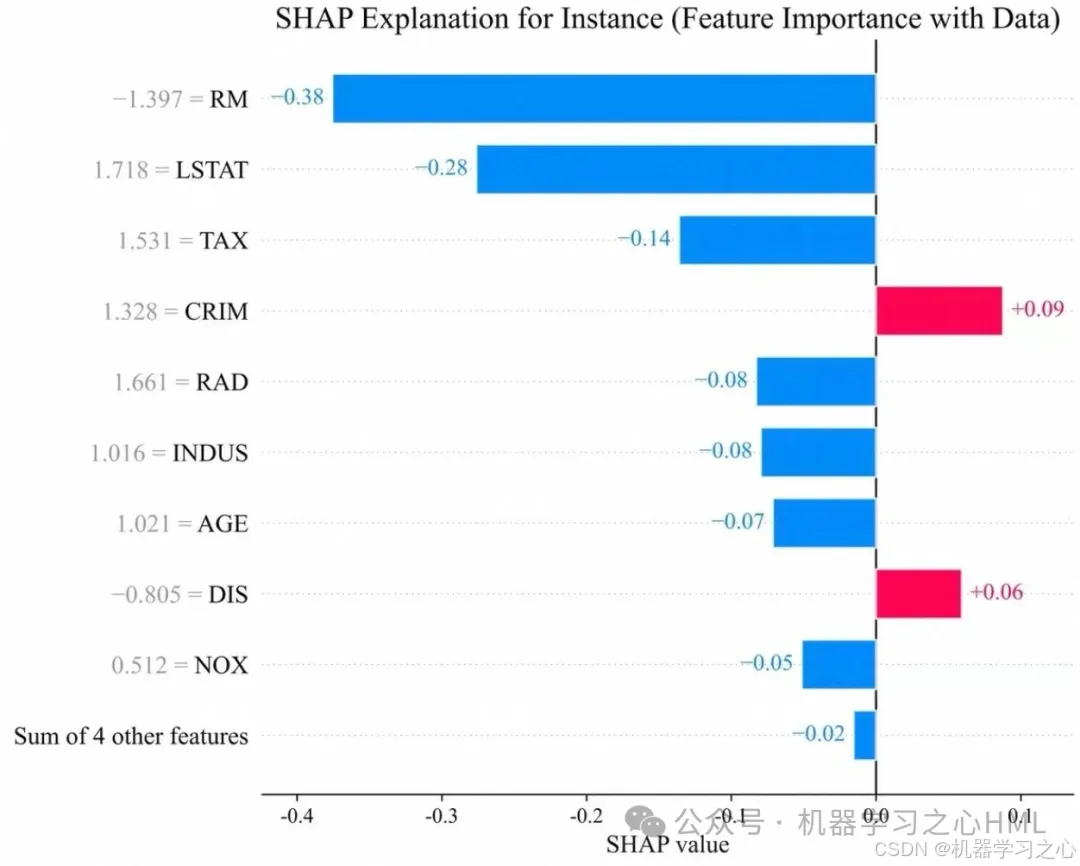
对于任意一个预测样本,瀑布图或力图(Waterfall)逐特征分解预测值偏离基值的贡献,让每一个预测都有据可依。
python
shap.plots.waterfall(shap_values[0])四、实践效果展示(样例)
我们在某回归数据集上训练,得到以下结果:
-
损失曲线显示训练与测试曲线紧贴下降,无严重过拟合。
-
散点图样本紧密围绕理想线,残差分布均匀。
-
SHAP 条形图揭示驱动因子;蜂巢图显示当特征 >XXX 时,对预测有持续正向拉升效果。
五、总结
CNN-xLSTM-Attention 模型通过局部卷积 → 改良记忆结构 → 动态聚焦的流水线,在回归任务中展现出优异的拟合与泛化能力。配合 SHAP 解释性分析,我们不仅能得到准确的预测值,还能清晰回答"模型为何做出这样的预测",为模型调试和业务决策提供强有力的支撑。
全部代码已结构化、注释清晰,仅供个人学习使用。欢迎交流优化思路,共同进步!