【AI大模型】Self-Attention:为什么它能取代 RNN 解决长距离依赖?
在 Transformer 一统 NLP 乃至多模态领域之前,序列建模几乎是 RNN 及其变体(LSTM、GRU)的天下。但随着文本长度增加、模型规模扩大,RNN 的瓶颈愈发明显。而 Self-Attention(自注意力机制) 的出现,不仅颠覆了序列建模范式,更凭借对长距离依赖的优秀建模能力,成为现代大模型的核心基石。
本文用通俗易懂的方式,讲清 RNN 是什么、Self-Attention 核心原理,以及为什么它能完美替代 RNN 处理长序列。
理解 Self-Attention,就是理解现代深度学习序列建模的第一步。
一、先搞清楚:RNN 是什么,它的局限在哪?
1、 RNN 基本概念
RNN,全称 Recurrent Neural Network(循环神经网络) ,是一类专门处理序列数据 的神经网络。
序列数据可以是:一句话、一段语音、一行时间序列。
它的核心设计思想很直观:
按顺序逐个处理输入,把前一个位置的信息通过"隐藏状态"传递给下一个位置。
结构可以简单理解为:
输入 x₁ → 隐藏状态 h₁
输入 x₂ → 隐藏状态 h₂(依赖 h₁)
输入 x₃ → 隐藏状态 h₃(依赖 h₂)
......为了缓解 RNN 的梯度消失问题,后来又出现了 LSTM、GRU,通过门控结构(遗忘门、输入门)保留部分历史信息,但底层串行的结构没有变。
2、RNN 无法绕开的致命缺陷
-
串行计算,无法并行
必须算完第 1 个词才能算第 2 个词,序列越长,训练越慢。
-
长距离依赖能力极差
信息像"传话游戏"一样一步步传递。
句子一长,前面的关键信息经过多层传递后会严重衰减,甚至出现梯度消失,后面的词完全"记不住"前面的内容。
比如句子:
小明在去年夏天去了欧洲,他在那里玩得很开心。
模型要知道"他""那里"指谁、指哪里,RNN 往往很难建立这种远距离关联。
二、Self-Attention 是什么?一句话抓住本质
Self-Attention,自注意力机制:
让序列里的每一个位置,都能直接"看到"所有位置,并自动计算彼此的关联程度,从而动态聚合全局信息。
不再按顺序接力,而是全局互联。
核心计算流程(简化版)
对序列中每个词,生成三个向量:
- Q(Query,查询向量):我要找什么信息
- K(Key,键向量):我能提供什么信息
- V(Value,值向量):我真正要传递的内容
然后做三步计算:
- 用 Q 和所有 K 计算相似度,得到注意力分数
- 对分数做 Softmax 归一化,权重和为 1
- 用权重对 V 加权求和,得到当前位置的注意力输出
经典公式:
\\text{Attention}(Q,K,V) = \\text{softmax}\\left(\\frac{QK\^T}{\\sqrt{d_k}}\\right)V
简单说:
每个词的输出,是句子中所有词根据相关性加权后的结果。
三、核心:为什么 Self-Attention 能替代 RNN 处理长距离依赖?
答案可以浓缩成一句话:
RNN 是"接力传递",Self-Attention 是"直接互联"。
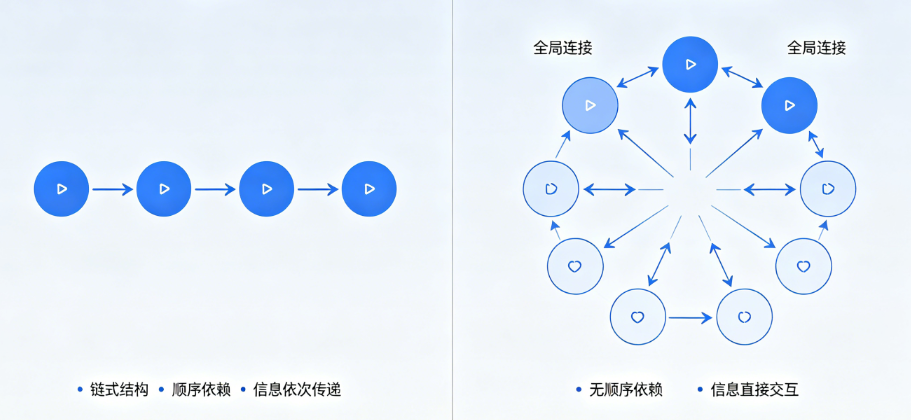
1、 信息传递路径完全不同
-
RNN:
位置 1 → 2 → 3 → ... → n
路径长度 = 序列长度
-
Self-Attention:
任意两个位置直接相连
路径长度恒等于 1
距离再远,也不会出现信息衰减。
2、不存在梯度消失问题
RNN 长距离依赖失效的根源是:
多次矩阵相乘导致梯度指数级消失。
Self-Attention 直接通过点积建模全局关系,没有连续的链式乘法,长距离依赖天然稳定。
3、自动学习语义关联,而非机械传递
Self-Attention 会自动学到:
- 代词对应哪个名词
- 动词对应哪个主语
- 修饰词对应哪个中心词
这种语义级的关联,RNN 很难学到。
4、 支持并行计算
所有位置的 Q、K、V 可以一次性算出,注意力矩阵也可并行求解,训练效率远超 RNN。
四、RNN vs Self-Attention 直观对比表
| 特性 | RNN / LSTM | Self-Attention |
|---|---|---|
| 计算方式 | 串行,依次计算 | 并行,全局计算 |
| 长距离依赖 | 弱,易梯度消失 | 强,直接关联 |
| 信息传递 | 链式传递,逐步衰减 | 全连接,无距离损耗 |
| 训练速度 | 慢 | 快 |
| 长文本效果 | 差 | 优秀 |
一句话总结差距:
RNN 只能记住附近的内容,而 Self-Attention 能读懂整段上下文。
- RNN 是传统序列建模方案,依靠隐藏状态串行传递信息,在长文本上表现拉胯,训练效率低。
- Self-Attention 通过 QKV 机制让每个词直接关注全局,动态计算语义权重,彻底解决了长距离依赖问题。
- 正是凭借这一点,Self-Attention 成为 Transformer 的核心,进而支撑起 BERT、GPT 等一系列大模型,彻底取代 RNN 成为主流。
五、PyTorch 手写极简 Self-Attention 实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleSelfAttention(nn.Module):
def __init__(self, embed_dim, dropout=0.1):
super().__init__()
# 词嵌入维度
self.embed_dim = embed_dim
# 线性层生成 Q、K、V
self.qkv_proj = nn.Linear(embed_dim, embed_dim * 3)
self.dropout = nn.Dropout(dropout)
# 输出线性层
self.out_proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
"""
x: 输入序列,形状 [batch_size, seq_len, embed_dim]
返回: 自注意力输出 [batch_size, seq_len, embed_dim]
"""
batch_size, seq_len, _ = x.shape
# 1. 线性映射得到 Q、K、V
qkv = self.qkv_proj(x) # [batch, seq_len, 3*embed_dim]
# 拆分 Q、K、V,每个形状 [batch, seq_len, embed_dim]
q, k, v = qkv.chunk(3, dim=-1)
# 2. 缩放点积注意力分数
# Q@K.T / sqrt(d)
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.embed_dim, dtype=torch.float32))
# Softmax 归一化得到注意力权重
attn_weights = F.softmax(attn_scores, dim=-1)
attn_weights = self.dropout(attn_weights)
# 3. 权重与 V 加权求和
output = torch.matmul(attn_weights, v)
# 4. 输出线性层
output = self.out_proj(output)
return output, attn_weights
# 测试代码
if __name__ == "__main__":
# 超参数
batch_size = 2
seq_len = 5
embed_dim = 16
# 随机生成输入序列
x = torch.randn(batch_size, seq_len, embed_dim)
# 初始化自注意力
self_attn = SimpleSelfAttention(embed_dim)
# 前向传播
out, weights = self_attn(x)
print("输入形状:", x.shape)
print("自注意力输出形状:", out.shape)
print("注意力权重形状:", weights.shape)