一、介绍
pinecone - 松果
英式发音为/ˈpaɪnˌkəʊn/,美式发音为/ˈpɑɪnˌkoʊn/
AI 向量数据库服务
Pinecone 是一家 2019 年成立于美国纽约的人工智能公司,专注于开发向量数据库技术,其核心产品通过 API 服务帮助开发者将向量搜索功能集成到应用程序中。
1)什么是高维向量
1. 普通低维向量(你能理解的)
2 维:平面坐标 (x, y),比如 (3,5)
3 维:空间坐标 (x, y, z),比如 (1,2,3)
就是一组数字,有几个数字就叫几维。
2. 高维向量(AI 里的向量)
AI 把文字、图片、音频、视频,转换成一长串浮点数数组,这串数字就是高维向量。
举个例子:
一段文字:Java怎么学?
经过 Embedding 模型(OpenAI、BERT 等)处理后,变成:
plaintext
[0.12, 0.35, -0.22, 0.78, ... 一直有 1536 个数字]
一共 1536 个数字 → 就叫 1536 维高维向量
你之前报错 1536 vs 1024,就是两种长度的向量不匹配
核心特点
维度极高:常见 512、1024、1536、4096 维
含义抽象:单个数字没意义,整串数字代表语义 / 特征
相似内容 → 向量距离近
"猫" 和 "小猫" 向量距离很近
"猫" 和 "汽车" 向量距离很远
高维向量 = 把文字 / 图片变成AI 能看懂的数字指纹2)什么是向量数据库?
1. 传统数据库能干啥 MySQL/ES:存结构化数据,按关键词、条件查找比如:查姓名、年龄、订单号,精准匹配。
2. 向量数据库专门干啥 专门用来:存储 高维向量 + 快速做相似度搜索普通数据库存 1536 维向量也能存,但查不了:你要找 "语义最相似" 的内容,传统数据库遍历比对超级慢,上亿条直接卡死。
向量数据库做了两件核心事:
1. 专门存储成千上万、上亿条高维向量
2. 内置向量索引算法(HNSW、IVF 等),毫秒级找出最相似的 Top-K 向量
3. 通俗比喻
• 普通数据库:查字典,按字精准查找
• 向量数据库:凭感觉找人,找气质、长相最相似的人,不用精准匹配3)和你开发场景对应
- 你用 RAG 知识库:
◦ 文档 → 切分 → Embedding 转 1536 维高维向量
◦ 存入 Pinecone / 向量数据库 ◦ 用户提问 → 也转成向量
◦ 向量数据库帮你秒级找出语义最相似的文档片段 → 给大模型做上下文
- 为什么不能只用 MySQL?
MySQL 能存这 1536 个数字,但没法高效算相似度,数据一多直接崩。
二、安装 Pinecone 库
Pinecone 官方提供了 Python 客户端库,推荐使用最新的 3.x 版本(2.x 已逐步弃用),安装命令:
pip install pinecone-client
pip install pinecone
三、获取 Pinecone API Key
需要注册和登录
key: 如果需要选择什么内容,可以直接跳过 skip
复制自己的 key 值
pcsk_6XALja_3PKqXmUvFQupF1sFhNASJKHqfhVXW29rtE6TS4Ln2jURbdz346EqR9umqkAeFk2四、核心 API
在向量数据库中,索引相当于是数据库,向量相当于是一条条的数据
1 初始化 Pinecone 客户端
3.x 版本简化了客户端初始化方式,无需指定 environment,仅需 API Key:
import pinecone
from pinecone import Pinecone, ServerlessSpec
# 初始化 Pinecone 客户端(3.x 推荐方式)
pc = Pinecone(api_key="YOUR_PINECONE_API_KEY")
# 兼容 2.x 版本(可选,不推荐)
# pinecone.init(api_key="YOUR_PINECONE_API_KEY", environment="YOUR_ENV")2、 索引管理(核心载体)
索引是 Pinecone 存储向量的核心单元,所有向量操作均基于索引完成,常用操作包括创建、列出、描述、缩放、删除。
2.1 创建索引
创建索引时需指定向量维度、相似度度量方式、云厂商/区域(Serverless 模式):
以下是手动创建:
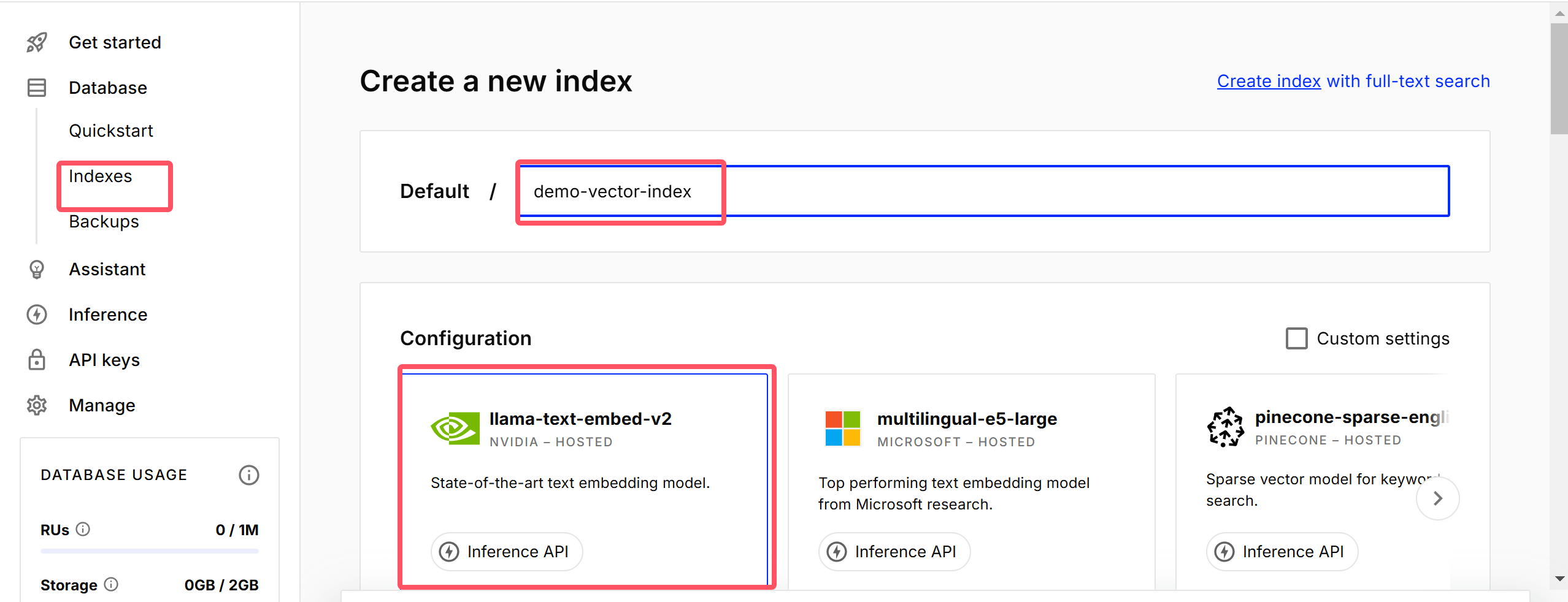

我手动创建的默认是 1024 维度的数据,而下面的代码中,维度使用的是1536,所以可能会报错,所以我们还是使用代码创建一个 1536 维度的数据为好
以下是代码创建:
# 定义索引名称(自定义)
index_name = "demo-vector-index2"
# 检查索引是否存在,避免重复创建
if index_name not in pc.list_indexes().names():
# 创建 Serverless 索引(3.x 推荐,无需管理服务器)
pc.create_index(
name=index_name,
dimension=1536, # 向量维度(如 OpenAI Embedding 为 1536)
metric="cosine", # 相似度度量:cosine(余弦)/euclidean(欧氏)/dotproduct(点积)
spec=ServerlessSpec(
cloud="aws", # 云厂商:aws/gcp
region="us-east-1" # 区域(需与账号一致)
)
)
# 等待索引创建完成(约 10 秒)
import time
while not pc.describe_index(index_name).status['ready']:
time.sleep(1)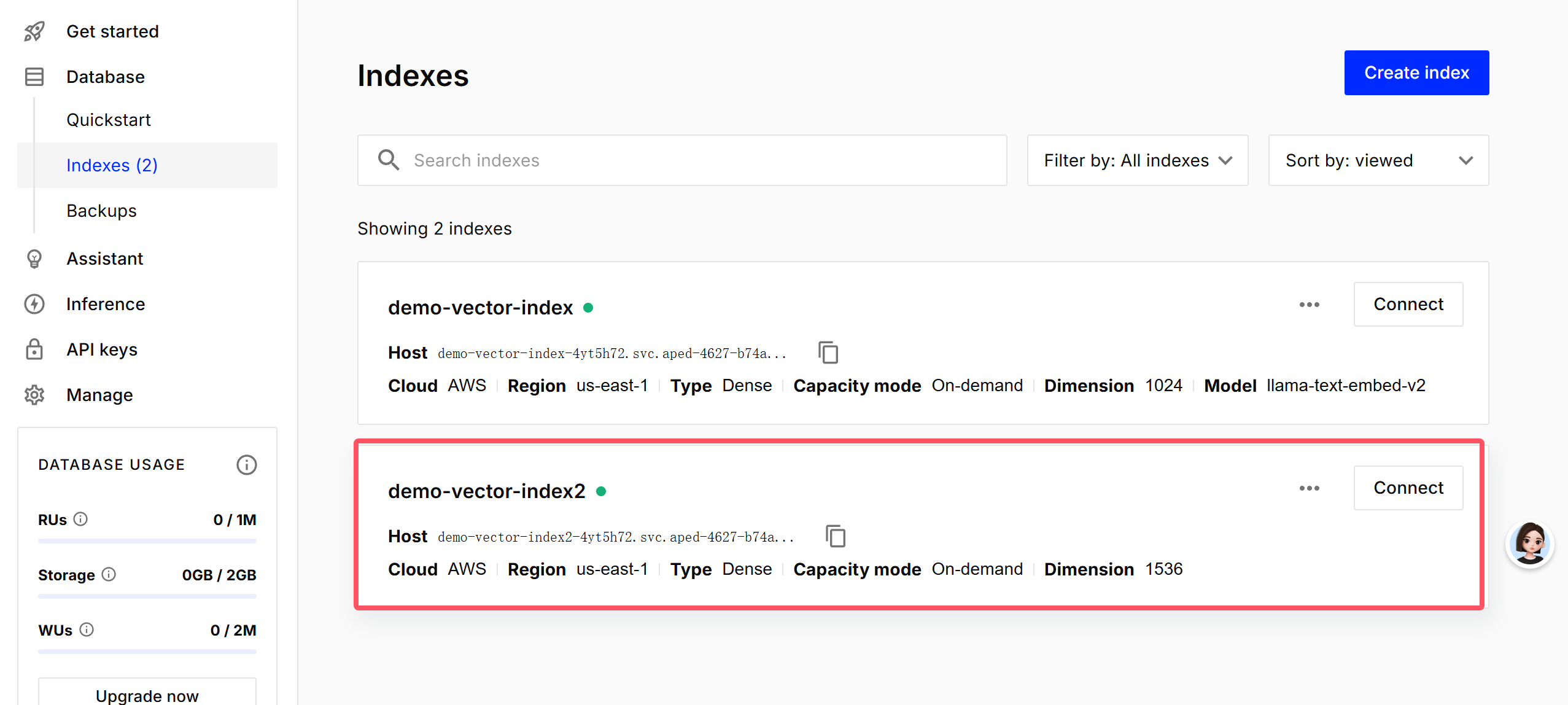
2.2 索引基础操作
# 列出所有索引
all_indexes = pc.list_indexes()
print("当前所有索引:", all_indexes.names())
# 描述索引详情(维度、度量方式、状态等)
index_desc = pc.describe_index(index_name)
print("索引详情:", index_desc)
# 缩放索引(仅 Pod 类型索引支持,Serverless 无需缩放)
# pc.scale_index(name=index_name, replicas=2, pods=1)
# 获取索引实例(后续向量操作的核心对象)
index = pc.Index(index_name)
2.3 向量操作(增删改查)
向量是 Pinecone 的核心数据单元,由 id(唯一标识)、values(向量值)、metadata(元数据,可选)组成,常用操作包括插入/更新、获取、删除。
2.3.1 插入/更新向量(upsert)
# 1. 单条向量插入
single_vec = {
"id": "vec-1",
"values": [0.1, 0.2, 0.3] + [0.0]*1533, # 补全到 1536 维度
"metadata": { # 元数据(自定义键值对,用于过滤)
"category": "book",
"price": 29.99,
"title": "Python编程入门"
}
}
index.upsert(vectors=[single_vec], namespace="ns1") # namespace 用于隔离向量
# 2. 批量插入(推荐,提升效率)
batch_vecs = []
for i in range(2, 10):
batch_vecs.append({
"id": f"vec-{i}",
"values": [0.1*i, 0.2*i, 0.3*i] + [0.0]*1533,
"metadata": {
"category": "book" if i % 2 == 0 else "movie",
"price": 10.99 + i,
"title": f"Content {i}"
}
})
# 批量写入,支持指定命名空间
index.upsert(vectors=batch_vecs, namespace="ns1", batch_size=200) # 分块大小(默认 1000)点击索引,查看索引中的内容:
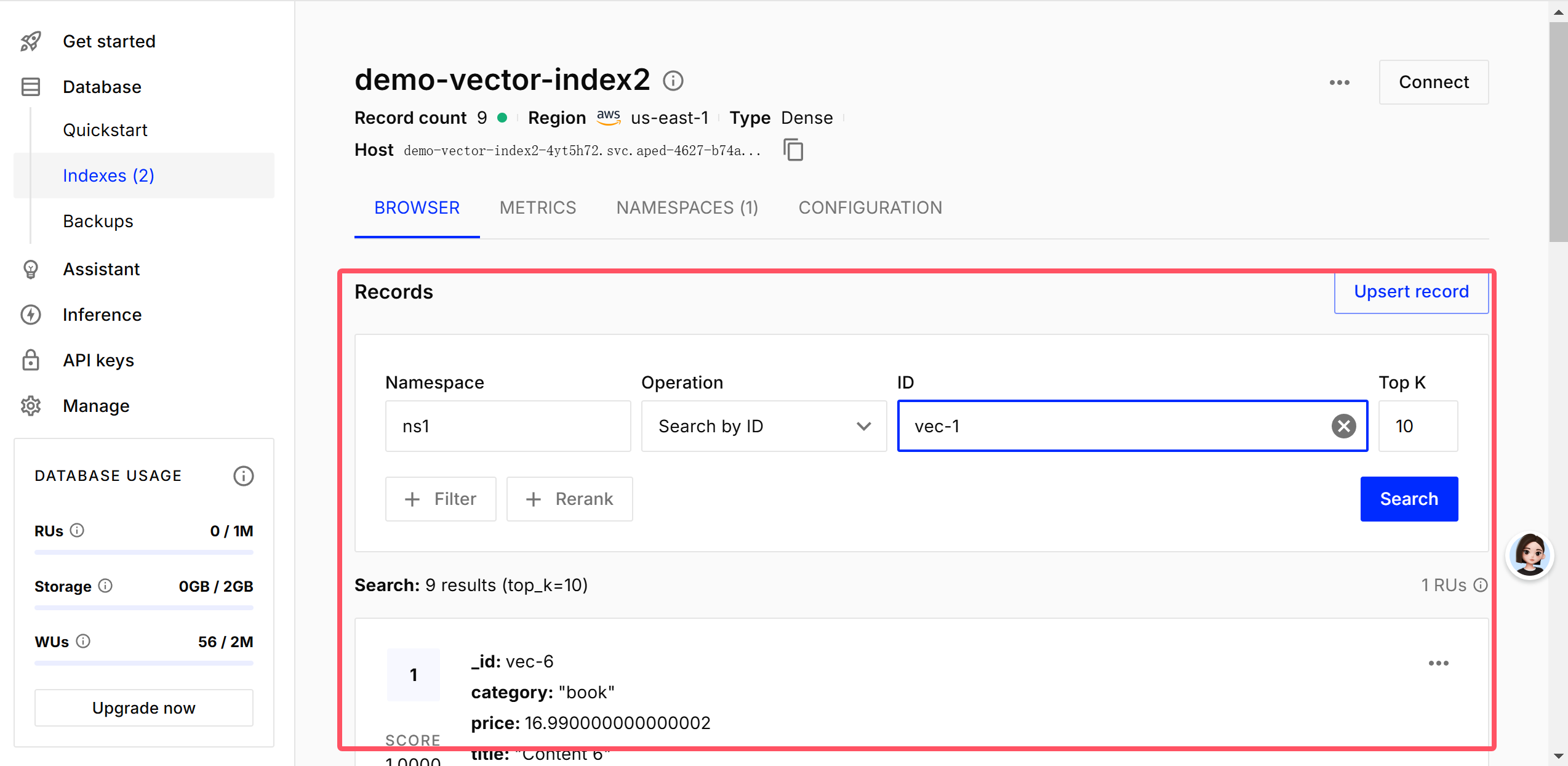
整体代码如下:
import pinecone
from pinecone import Pinecone, ServerlessSpec
# 初始化 Pinecone 客户端(3.x 推荐方式)
pc = Pinecone(api_key="pcsk_6XALja_3PKqXmUvFQupF1sFhNASJKHqfhVXW29rtE6TS4Ln2jURbdz346EqR9umqkAeFk2")
# 兼容 2.x 版本(可选,不推荐)
# pinecone.init(api_key="YOUR_PINECONE_API_KEY", environment="YOUR_ENV")
# 定义索引名称(自定义)
index_name = "demo-vector-index2"
# 检查索引是否存在,避免重复创建
if index_name not in pc.list_indexes().names():
# 创建 Serverless 索引(3.x 推荐,无需管理服务器)
pc.create_index(
name=index_name,
dimension=1536, # 向量维度(如 OpenAI Embedding 为 1536)
metric="cosine", # 相似度度量:cosine(余弦)/euclidean(欧氏)/dotproduct(点积)
spec=ServerlessSpec(
cloud="aws", # 云厂商:aws/gcp
region="us-east-1" # 区域(需与账号一致)
)
)
# 等待索引创建完成(约 10 秒)
import time
while not pc.describe_index(index_name).status['ready']:
time.sleep(1)
# 列出所有索引
all_indexes = pc.list_indexes()
print("当前所有索引:", all_indexes.names())
# 描述索引详情(维度、度量方式、状态等)
index_desc = pc.describe_index(index_name)
print("索引详情:", index_desc)
# 缩放索引(仅 Pod 类型索引支持,Serverless 无需缩放)
# pc.scale_index(name=index_name, replicas=2, pods=1)
# 获取索引实例(后续向量操作的核心对象)
index = pc.Index(index_name)
# 1. 单条向量插入
single_vec = {
"id": "vec-1",
"values": [0.1, 0.2, 0.3] + [0.0]*1533, # 补全到 1536 维度
"metadata": { # 元数据(自定义键值对,用于过滤)
"category": "book",
"price": 29.99,
"title": "Python编程入门"
}
}
index.upsert(vectors=[single_vec], namespace="ns1") # namespace 用于隔离向量
# 2. 批量插入(推荐,提升效率)
batch_vecs = []
for i in range(2, 10):
batch_vecs.append({
"id": f"vec-{i}",
"values": [0.1*i, 0.2*i, 0.3*i] + [0.0]*1533,
"metadata": {
"category": "book" if i % 2 == 0 else "movie",
"price": 10.99 + i,
"title": f"Content {i}"
}
})
# 批量写入,支持指定命名空间
index.upsert(vectors=batch_vecs, namespace="ns1", batch_size=200) # 分块大小(默认 1000)2.3.2 获取向量(fetch)
# 1. 获取单个向量
single_fetch = index.fetch(ids=["vec-1"], namespace="ns1")
print("单个向量:", single_fetch)
# 2. 批量获取向量
batch_fetch = index.fetch(ids=["vec-2", "vec-3", "vec-4"], namespace="ns1")
print("批量向量:", batch_fetch)2.3.3 更新向量
通过 upsert 实现更新(仅修改元数据时,向量值可传空列表):
# 全量更新(向量值 + 元数据)
update_vec = {
"id": "vec-1",
"values": [0.4, 0.5, 0.6] + [0.0]*1533,
"metadata": {"category": "book", "price": 39.99, "discount": True}
}
index.upsert(vectors=[update_vec], namespace="ns1")
# 仅更新元数据(向量值不变)
meta_only_update = {
"id": "vec-1",
"values": [], # 空列表表示不修改向量值
"metadata": {"sales": 1000} # 新增/修改元数据字段
}
index.upsert(vectors=[meta_only_update], namespace="ns1")2.3.4 删除向量
# 1. 删除单个向量
index.delete(ids=["vec-1"], namespace="ns1")
# 2. 批量删除向量
index.delete(ids=["vec-2", "vec-3"], namespace="ns1")
# 3. 删除命名空间下所有向量
index.delete(delete_all=True, namespace="ns1")2.4 向量查询(核心功能)
Pinecone 的核心价值是相似性检索,支持基础查询、元数据过滤、多向量查询、分页等能力。
2.4.1 基础相似性查询
# 构造查询向量(模拟 1536 维向量)
query_vec = [0.5, 0.6, 0.7] + [0.0]*1533
# 基础查询:返回最相似的 5 个向量
basic_query = index.query(
vector=query_vec,
top_k=5, # 返回数量
namespace="ns1",
include_metadata=True, # 是否返回元数据
include_values=False # 是否返回向量值
)
print("基础查询结果:", basic_query)2.4.2 元数据过滤查询(高频用法)
支持丰富的过滤操作符(eq/ne/gt/gte/lt/lte/in/nin),以及 and/or/$not 组合条件:
# 示例 1:筛选 category=book 且 price>20 的向量
filtered_query = index.query(
vector=query_vec,
top_k=3,
namespace="ns1",
include_metadata=True,
filter={
"category": {"$eq": "book"},
"price": {"$gt": 20}
}
)
print("过滤查询结果:", filtered_query)
# 示例 2:复杂条件(category=movie 或 price<15)
complex_filter = index.query(
vector=query_vec,
top_k=3,
namespace="ns1",
include_metadata=True,
filter={
"$or": [
{"category": {"$eq": "movie"}},
{"price": {"$lt": 15}}
]
}
)
print("复杂过滤结果:", complex_filter)2.4.3 多向量查询
支持传入多个查询向量,通过聚合(均值/求和/最大值)生成最终检索结果:
# 多查询向量(如多个文本片段的嵌入向量)
multi_query_vecs = [
[0.5, 0.6, 0.7] + [0.0]*1533,
[0.8, 0.9, 1.0] + [0.0]*1533
]
multi_vec_query = index.query(
vector=multi_query_vecs,
top_k=5,
namespace="ns1",
include_metadata=True,
multi_vector_query_config={"aggregate": "mean"} # 聚合方式:mean/sum/max
)
print("多向量查询结果:", multi_vec_query)2.4.4 分页查询
通过 pagination_token 实现分页,适用于结果量较大的场景:
# 第一页
first_page = index.query(
vector=query_vec,
top_k=2, # 每页 2 条
namespace="ns1",
include_metadata=True,
pagination_token=None
)
print("第一页:", first_page)
# 第二页(通过第一页的 token 继续查询)
if "pagination_token" in first_page:
second_page = index.query(
vector=query_vec,
top_k=2,
namespace="ns1",
include_metadata=True,
pagination_token=first_page["pagination_token"]
)
print("第二页:", second_page)2.5 高级操作
2.5.1 命名空间(Namespace)
命名空间用于隔离向量(如按用户/场景分库),不同命名空间的向量相互独立:
# 向不同命名空间插入向量
index.upsert(vectors=[single_vec], namespace="ns2")
# 查询指定命名空间的向量
ns2_query = index.query(
vector=query_vec,
top_k=1,
namespace="ns2",
include_metadata=True
)
print("ns2 命名空间查询:", ns2_query)2.5.2 索引统计信息
查看索引的向量数量、命名空间分布等:
stats = index.describe_index_stats()
print("索引统计信息:", stats)2.5.3 批量操作最佳实践
单次 upsert 建议控制在 1000 条以内,避免超时,可封装分块函数:
def batch_upsert(index, vectors, batch_size=200):
"""批量分块插入向量"""
for i in range(0, len(vectors), batch_size):
batch = vectors[i:i+batch_size]
index.upsert(vectors=batch)
print(f"插入第 {i//batch_size + 1} 批,共 {len(batch)} 条")
# 示例:插入 1000 条向量
large_batch = [
{
"id": f"vec-{i}",
"values": [0.1*i, 0.2*i, 0.3*i] + [0.0]*1533,
"metadata": {"category": "article", "views": i*10}
}
for i in range(10, 1010)
]
batch_upsert(index, large_batch)2.6 清理资源
使用完成后删除索引,避免不必要的计费:
pc.delete_index(index_name)
print(f"索引 {index_name} 已删除")五、综合实战:文本语义检索
结合 OpenAI Embedding 将文本转为向量,实现语义检索(需安装 openai 库:pip install openai):
import openai
# 配置 OpenAI API Key
openai.api_key = "YOUR_OPENAI_API_KEY"
# 1. 初始化 Pinecone 并创建索引
pc = Pinecone(api_key="YOUR_PINECONE_API_KEY")
index_name = "text-semantic-search"
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=1536,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
index = pc.Index(index_name)
# 2. 文本转向量(OpenAI Embedding)
def get_text_embedding(text, model="text-embedding-3-small"):
"""获取文本的 Embedding 向量"""
return openai.embeddings.create(
input=[text.replace("\n", " ")],
model=model
).data[0].embedding
# 3. 准备文本数据并插入 Pinecone
texts = [
{"id": "t1", "content": "Python是一种解释型、面向对象的高级编程语言", "category": "编程"},
{"id": "t2", "content": "Pinecone是一款专为向量检索优化的托管式向量数据库", "category": "数据库"},
{"id": "t3", "content": "OpenAI的Embedding API可以将文本转换为高维向量", "category": "AI"},
{"id": "t4", "content": "语义搜索通过向量相似度匹配实现精准的文本检索", "category": "搜索"},
{"id": "t5", "content": "向量数据库广泛应用于推荐系统、问答机器人等AI场景", "category": "AI"}
]
# 批量转换并插入
vectors = []
for item in texts:
embedding = get_text_embedding(item["content"])
vectors.append({
"id": item["id"],
"values": embedding,
"metadata": {"content": item["content"], "category": item["category"]}
})
index.upsert(vectors=vectors)
# 4. 语义检索
query_text = "向量数据库在AI中的应用"
query_embedding = get_text_embedding(query_text)
# 检索 AI 分类的文本
results = index.query(
vector=query_embedding,
top_k=3,
include_metadata=True,
filter={"category": {"$eq": "AI"}}
)
# 输出结果
print(f"\n查询文本:{query_text}")
print("检索结果(按相似度排序):")
for match in results["matches"]:
print(f"相似度:{match['score']:.4f} | 内容:{match['metadata']['content']}")
# 5. 清理资源
pc.delete_index(index_name)