〔更多精彩AI内容,尽在 「魔方AI空间」 ,引领AIGC科技时代〕
本文作者:猫先生经典文章回顾:
- 万字综述 | 一文带你入门「具身智能」:从基础概念到大模型赋能
- 万字长文|一文详解具身智能:视觉-语言-动作模型(VLA)系统性综述
- 一文梳理主流大模型推理部署框架:vLLM、SGLang、TensorRT-LLM、ollama、XInference
- 一文梳理主流热门智能体框架:Dify、Coze、n8n、AutoGen、LangChain、CrewAI
- 一文详解AI大模型14个核心基础概念:Transformer、Token、MoE、RAG、对齐、预训练、微调、Agent
写在前面
【从零走向AGI】旨在深入了解通用人工智能(AGI)的发展路径,从最基础的概念起,逐步构建完整的知识体系。
项目地址🔗:https://ai-mzq.github.io/From-Zero-to-AGI/
主流大语言模型的演进,不只是参数量越来越大,更是架构、训练范式、注意力机制、长上下文、MoE和推理效率不断协同优化的过程。
在前面的几篇文章中,我们已经拆解了LLM 的基础组件、Transformer、Attention、位置编码、MoE等。
- 一文详解AI大模型14个核心基础概念:Transformer、Token、MoE、RAG、对齐、预训练、微调、Agent
- 一文搞懂大模型加速之Attention:从 FlashAttention 到 PagedAttention
- 一文详解『位置编码』技术演进:从 Transformer 到 DeepSeek 的创新之路
- 一文详解MoE模型(超全面)
本文将会介绍到:GPT、BERT、T5、LLaMA、Qwen、Mistral、DeepSeek、Gemma、Phi等。这些模型并不是完全不同的物种,而是在 Transformer 这条主干上做了不同取舍。
本文重点回答:
- 为什么现代聊天大模型大多采用 Decoder-only 架构?
- GPT、BERT、T5 三条早期路线有什么区别?
- LLaMA 为什么成为开源 LLM 架构的重要分水岭?
- Qwen、DeepSeek、Mistral、Gemma、Phi 各自代表什么设计取向?
- Dense 模型和 MoE 模型有什么差别?
- GQA、SwiGLU、RMSNorm、RoPE、MLA、长上下文这些技术如何进入主流架构?
- 读模型技术报告时,应该重点看哪些架构字段?
一条主线看懂架构演进
LLM 架构演进可以简化为下面这条线:
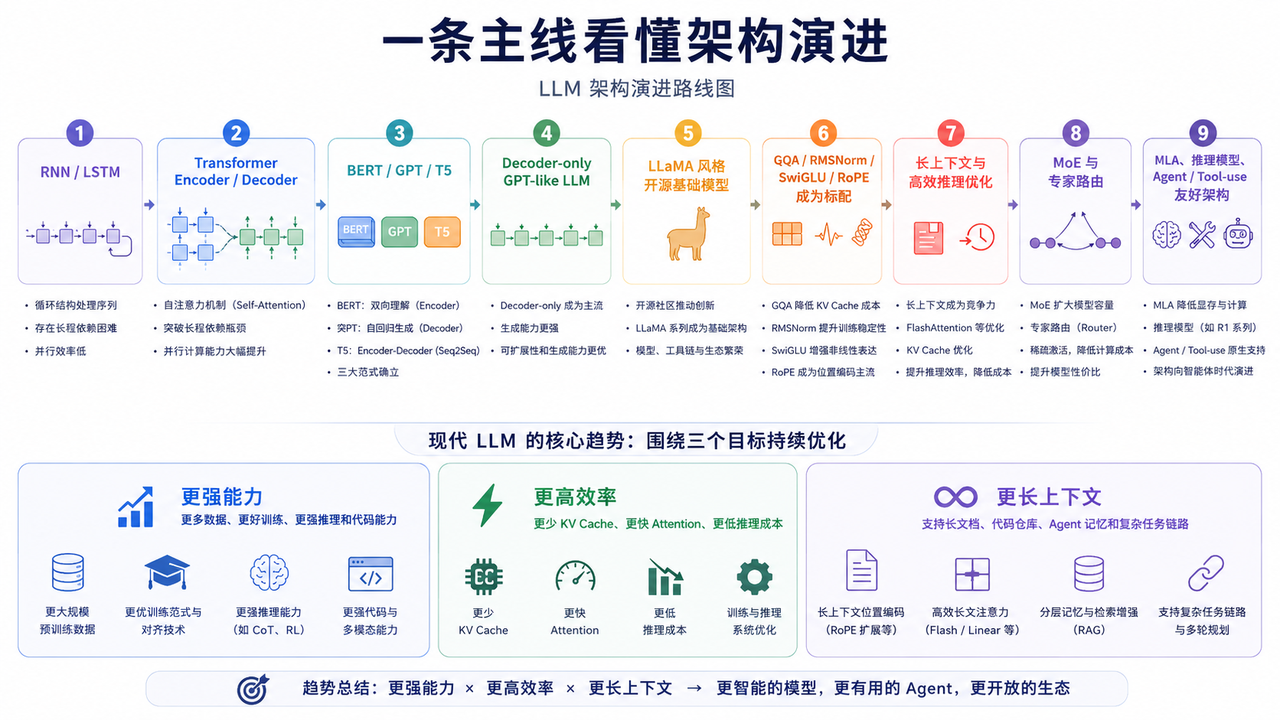
现代 LLM 的核心趋势不是单点创新,而是围绕三个目标持续优化:
- 更强能力:更多数据、更好训练、更强推理和代码能力。
- 更高效率:更少 KV Cache、更快 Attention、更低推理成本。
- 更长上下文:支持长文档、代码仓库、Agent 记忆和复杂任务链路。
早期三条经典路线
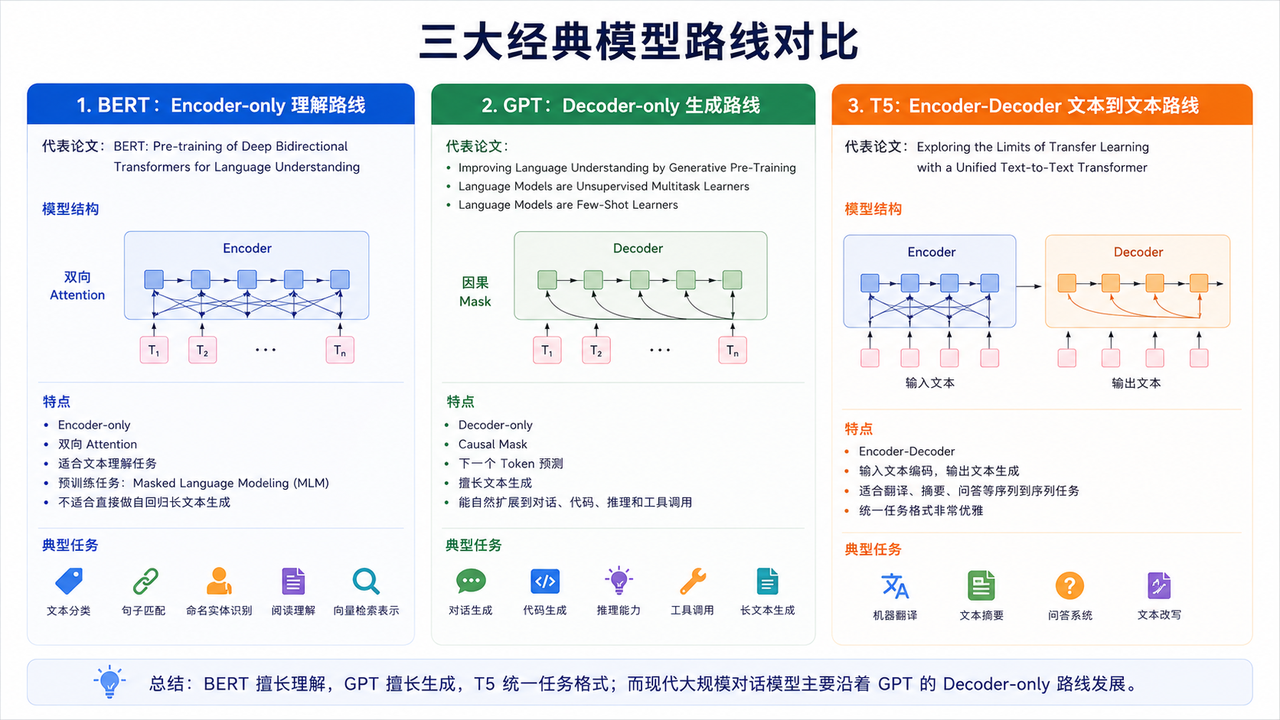
1. BERT:Encoder-only 理解路线
代表论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT 使用 Transformer Encoder,通过双向上下文建模理解文本。
特点:
- Encoder-only
- 双向 Attention
- 适合文本理解任务
- 预训练任务包含 Masked Language Modeling
- 不适合直接做自回归长文本生成
典型任务:
- 文本分类
- 句子匹配
- 命名实体识别
- 阅读理解
- 向量检索表示
2. GPT:Decoder-only 生成路线
代表论文:
- Improving Language Understanding by Generative Pre-Training
- Language Models are Unsupervised Multitask Learners
- Language Models are Few-Shot Learners
GPT 使用 Transformer Decoder,通过自回归方式预测下一个 Token。
特点:
- Decoder-only
- Causal Mask
- 下一个 Token 预测
- 擅长文本生成
- 能自然扩展到对话、代码、推理和工具调用
现代大多数 ChatGPT 类模型都沿着 GPT 的 Decoder-only 路线发展。
3. T5:Encoder-Decoder 文本到文本路线
代表论文:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
T5 把所有 NLP 任务都统一成 text-to-text 形式。
特点:
- Encoder-Decoder
- 输入文本编码,输出文本生成
- 适合翻译、摘要、问答等序列到序列任务
- 统一任务格式非常优雅
但在大规模通用对话模型时代,Decoder-only 路线凭借训练和推理上的简洁性成为主流。
为什么 Decoder-only 成为主流?
现代 LLM 大多采用 Decoder-only,不是偶然。
训练目标简单
Decoder-only 只需要做下一个 Token 预测:
Plain
给定历史 Token -> 预测下一个 Token这个目标可以直接利用海量无标注文本。
生成任务天然匹配
对话、写作、代码、总结、推理,本质上都可以转成"根据上下文继续生成"。
扩展规律清晰
增加参数、数据和计算量时,Decoder-only 模型的 Scaling Law 表现稳定,便于工程放大。
推理流程统一
无论是聊天、代码补全、RAG 还是工具调用,最终都可以落到自回归生成。
适合指令微调和对齐
SFT、RLHF、DPO、GRPO 等后训练方法都可以自然接在 Decoder-only 基础模型之后。
现代 Decoder-only LLM 的常见配置
虽然不同模型家族细节很多,但现代 Decoder-only LLM 通常有一组高频组件。
| 组件 | 主流选择 | 作用 |
|---|---|---|
| 主体架构 | Decoder-only Transformer | 自回归生成 |
| Attention | MHA / GQA / MQA / MLA | 上下文信息交互 |
| Mask | Causal Mask | 防止看到未来 Token |
| Position | RoPE 及其变体 | 注入位置信息 |
| Norm | RMSNorm | 稳定训练,降低计算 |
| FFN | SwiGLU / Gated FFN | 提升非线性表达 |
| 长上下文 | RoPE Scaling / YaRN / Sliding Window | 扩展上下文长度 |
| 推理优化 | KV Cache / FlashAttention / GQA | 降低延迟和显存 |
| 大容量路线 | Dense / MoE | 提升参数容量和效率 |
如果你读一个模型技术报告,优先看这些字段,基本就能把架构轮廓抓出来。
GPT 系列:Decoder-only 路线的开端
GPT 系列确立了"生成式预训练 + 自回归语言模型"的主线。
GPT-1
GPT-1 展示了生成式预训练加下游微调的潜力。
核心意义:
- 用 Decoder-only Transformer 做语言建模
- 先无监督预训练,再有监督微调
- 证明预训练语言模型可以迁移到多种 NLP 任务
GPT-2
GPT-2 强化了"无监督多任务学习"的观点。
核心意义:
- 扩大模型规模和训练数据
- 展示 zero-shot 生成能力
- 证明模型可以从自然文本中学习任务模式
GPT-3
GPT-3 是 LLM 时代的重要分水岭。
核心意义:
- 参数规模扩大到 175B
- Few-shot / in-context learning 能力显著增强
- Prompt 成为使用模型的重要接口
- 证明规模扩展可以带来通用能力提升
GPT 系列的架构方向,基本奠定了后续 ChatGPT 类模型的基础。
LLaMA 系列:开源 LLM 的关键分水岭
代表论文:
- LLaMA: Open and Efficient Foundation Language Models
- Llama 2: Open Foundation and Fine-Tuned Chat Models
- The Llama 3 Herd of Models
LLaMA 系列的重要意义在于:它用相对高效的训练和简洁架构,推动了开源 LLM 生态爆发。
LLaMA 风格架构特点
常见特点:
- Decoder-only Transformer
- Pre-Norm
- RMSNorm
- RoPE
- SwiGLU
- Causal Attention
- 高质量训练数据
这套组合后来几乎成为许多开源 LLM 的默认起点。
LLaMA 的影响
LLaMA 之后,大量模型都采用或借鉴了类似架构:
- Alpaca
- Vicuna
- Baichuan
- InternLM
- Qwen
- Yi
- DeepSeek
- Mistral
因此,理解 LLaMA 风格架构,是理解现代开源 LLM 的捷径。
Qwen 系列:中文和多语言能力的重要代表
代表技术报告:
Qwen 系列是中文、多语言、代码和工具调用生态中非常重要的模型家族。
常见架构特点:
- Decoder-only Transformer
- RoPE
- RMSNorm
- SwiGLU
- GQA
- 多语言 Tokenizer
- 长上下文扩展
- Base / Instruct / Coder / Math 等多分支模型
Qwen 的重点不只是架构本身,也包括:
- 中文和多语言数据覆盖
- 代码能力
- 数学能力
- 工具调用能力
- 开源生态和多尺寸模型矩阵
对于中文 LLM 学习者,Qwen 是非常值得重点跟踪的模型家族。
Mistral / Mixtral:滑动窗口与 MoE 的代表
代表论文:
Mistral 7B
Mistral 7B 的特点包括:
- Decoder-only
- GQA
- Sliding Window Attention
- 高效推理
- 小参数量下表现强
Sliding Window Attention 的直觉是:并不是每一层都必须让所有 Token 关注全局上下文,可以用局部窗口降低长序列开销。
Mixtral
Mixtral 是稀疏 MoE 路线的重要代表。
特点:
- Sparse Mixture of Experts
- 每个 Token 只激活部分专家
- 总参数量大,但每次前向计算只用一部分
- 在能力和推理成本之间做折中
Mixtral 之后,MoE 成为开源和工业界 LLM 架构中的重要方向。
DeepSeek 系列:MoE、MLA 与推理强化
代表技术报告:
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
- DeepSeek-V3 Technical Report
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek 系列的架构亮点非常鲜明。
DeepSeekMoE
DeepSeek 使用 MoE 扩展模型总参数量,同时控制每个 Token 的激活参数量。
核心直觉:
Plain
模型有很多专家
-> 每个 Token 只路由到少数专家
-> 总容量很大
-> 单次计算成本可控MLA
MLA(Multi-head Latent Attention)是 DeepSeek 高效推理的重要设计。
它的目标是压缩和优化 K/V 表示,降低 KV Cache 压力。
这对长上下文推理尤其重要,因为 KV Cache 会随着上下文长度、层数和头数增长而快速变大。
推理模型路线
DeepSeek-R1 则代表了另一条重要趋势:通过强化学习提升复杂推理能力。
这说明 LLM 架构演进已经不只是模型结构,还包括:
- 预训练架构
- 后训练算法
- 推理时行为
- 数据和奖励设计
Gemma 系列:Gemini 技术外溢的开放模型
代表论文:
- Gemma: Open Models Based on Gemini Research and Technology
- Gemma 2: Improving Open Language Models at a Practical Size
Gemma 是 Google 推出的开放模型家族,强调实用尺寸下的性能和部署友好性。
常见特点:
- Decoder-only
- 多尺寸模型
- 面向开发者生态
- 注重安全和负责发布
- 与 Gemini 研究技术路线有关
Gemma 的价值在于:它代表了大厂将旗舰模型经验下放到开放模型生态的一种路线。
Phi 系列:小模型高质量数据路线
代表论文:
Phi 系列的重要启发是:模型能力不只由参数规模决定,高质量数据和训练配方同样关键。
特点:
- 参数规模相对较小
- 强调高质量合成数据和教科书式数据
- 面向端侧、低成本和高效率场景
- 在小模型能力上表现突出
Phi 路线提醒我们:LLM 架构演进不只是"大就是好",数据质量和任务定位同样重要。
Dense 模型与 MoE 模型
现代 LLM 可以粗略分成 Dense 和 MoE 两类。
Dense 模型
Dense 模型中,每个 Token 都会经过全部参数中的主要计算路径。
特点:
- 结构简单
- 训练和部署相对直接
- 性能稳定
- 推理时激活参数量接近总参数量
代表:
- GPT-3
- LLaMA
- Qwen dense 模型
- Mistral 7B
- Gemma
- Phi
MoE 模型
MoE 模型有多个专家,每个 Token 只激活其中一部分。
特点:
- 总参数量可以很大
- 每个 Token 激活参数量较小
- 训练和负载均衡更复杂
- 推理部署需要处理专家并行和路由
代表:
- Mixtral
- DeepSeek-V2 / V3
- 一些 Qwen MoE 模型
简单对比:
| 维度 | Dense | MoE |
|---|---|---|
| 结构复杂度 | 较低 | 较高 |
| 总参数量 | 相对直接 | 可以非常大 |
| 激活参数量 | 接近全模型 | 只激活部分专家 |
| 训练稳定性 | 更容易 | 更复杂 |
| 推理部署 | 更直接 | 需要专家路由和并行 |
| 代表模型 | LLaMA、Gemma、Phi | Mixtral、DeepSeek-V3 |
MoE 会在下一章 MoE 模型 中深入展开。
架构演进中的关键技术
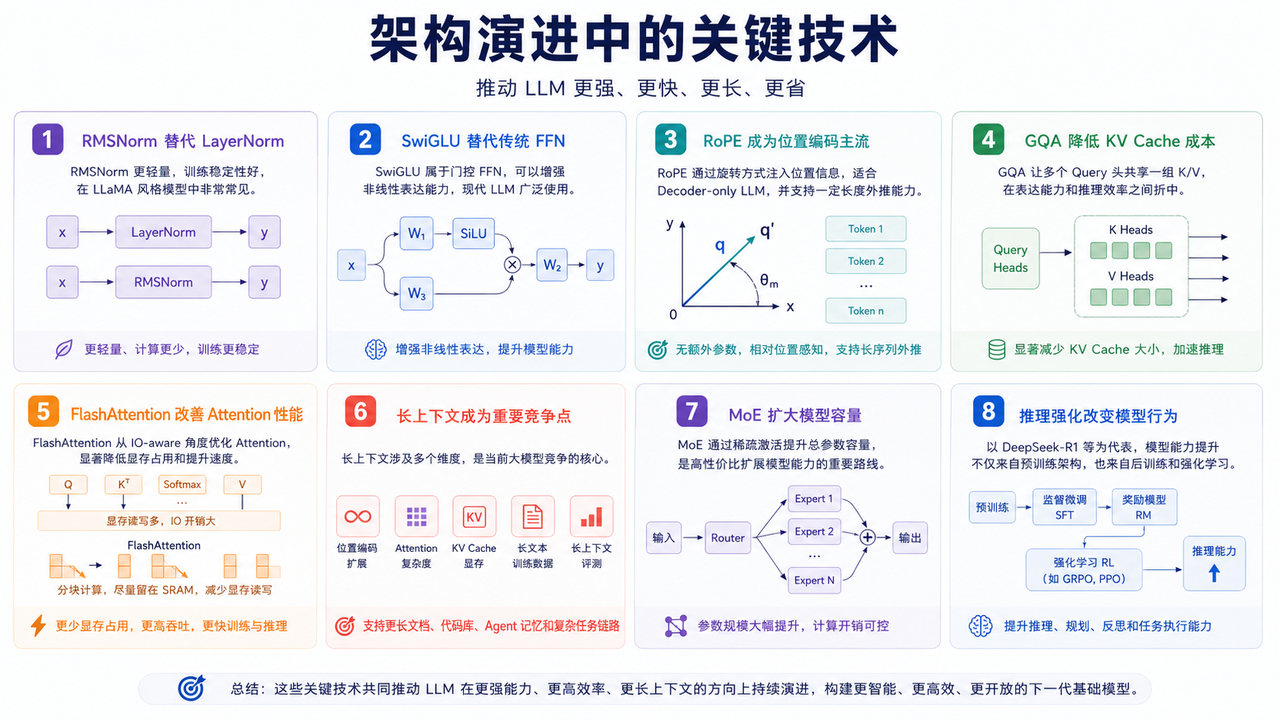
RMSNorm 替代 LayerNorm
RMSNorm 更轻量,训练稳定性好,在 LLaMA 风格模型中非常常见。
SwiGLU 替代传统 FFN
SwiGLU 属于门控 FFN,可以增强非线性表达能力,现代 LLM 广泛使用。
RoPE 成为位置编码主流
RoPE 通过旋转方式注入位置信息,适合 Decoder-only LLM,并支持一定长度外推能力。
GQA 降低 KV Cache 成本
GQA 让多个 Query 头共享一组 K/V,在表达能力和推理效率之间折中。
FlashAttention 改善 Attention 性能
FlashAttention 从 IO-aware 角度优化 Attention,显著降低显存占用和提升速度。
长上下文成为重要竞争点
长上下文涉及:位置编码扩展、Attention 复杂度、KV Cache 显存、长文本训练数据、长上下文评测。
MoE 扩大模型容量
MoE 通过稀疏激活提升总参数容量,是高性价比扩展模型能力的重要路线。
推理强化改变模型行为
以 DeepSeek-R1 等为代表,模型能力提升不只来自预训练架构,也来自后训练和强化学习。
主流模型架构速览
| 模型家族 | 主体架构 | 关键特征 | 适合关注点 |
|---|---|---|---|
| BERT | Encoder-only | 双向理解、MLM | 文本理解和向量表示 |
| GPT | Decoder-only | 自回归生成、Prompt | 生成式 LLM 主线 |
| T5 | Encoder-Decoder | Text-to-text | 翻译、摘要、Seq2Seq |
| LLaMA | Decoder-only | RoPE、RMSNorm、SwiGLU | 开源 LLM 基础架构 |
| Qwen | Decoder-only / MoE | 中文、多语言、代码、GQA | 中文与工具生态 |
| Mistral | Decoder-only | GQA、滑动窗口 | 小模型高效率 |
| Mixtral | Sparse MoE | 专家路由、稀疏激活 | MoE 架构 |
| DeepSeek | MoE + MLA | DeepSeekMoE、MLA、推理强化 | 高效大模型和推理模型 |
| Gemma | Decoder-only | 开放模型、实用尺寸 | 轻量开放生态 |
| Phi | Decoder-only | 高质量数据、小模型 | 端侧和低成本场景 |
读模型技术报告应该看什么?
建议重点关注下面这些字段:

把这些字段读懂,就能快速判断一个模型的设计取向。
常见误区
参数量越大一定越好
模型能力还取决于数据质量、训练配方、架构效率、后训练和推理策略。
开源模型架构都差不多
很多模型都基于 Decoder-only,但在 Tokenizer、数据、GQA、RoPE Scaling、MoE、后训练上差异很大。
MoE 一定比 Dense 更省
MoE 每个 Token 激活参数少,但训练、部署、通信和负载均衡更复杂。
长上下文只靠 RoPE 扩展
长上下文需要位置编码、训练数据、Attention 优化、KV Cache 管理和评测共同支撑。
架构决定一切
同样架构下,数据和训练策略可能造成巨大差异。很多模型真正的壁垒在数据和工程细节。
学习建议
建议按下面顺序理解主流 LLM 架构:
- 先理解 GPT 的 Decoder-only 自回归生成路线。
- 再理解 LLaMA 风格架构:RMSNorm、RoPE、SwiGLU、Pre-Norm。
- 接着学习 GQA / MQA / KV Cache,理解推理效率优化。
- 然后学习 Mistral / Mixtral,理解滑动窗口和 MoE。
- 再学习 DeepSeek,理解 MoE、MLA 和推理强化。
- 最后横向比较 Qwen、Gemma、Phi,看中文、多语言、小模型和生态化路线。
推荐阅读
- Attention Is All You Need
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Language Models are Few-Shot Learners
- LLaMA: Open and Efficient Foundation Language Models
- The Llama 3 Herd of Models
- Qwen2 Technical Report
- Mistral 7B
- Mixtral of Experts
- DeepSeek-V3 Technical Report
- DeepSeek-R1
- Gemma 2
- Phi-3 Technical Report
小结
主流 LLM 架构演进可以概括为:
Plain
BERT / GPT / T5 确立 Transformer 三条路线
-> GPT 式 Decoder-only 成为生成式 LLM 主线
-> LLaMA 风格架构推动开源生态
-> RoPE / RMSNorm / SwiGLU / GQA 成为常见组件
-> Mistral / Mixtral 推动高效与 MoE 路线
-> DeepSeek 将 MoE、MLA 和推理强化推向前台
-> Qwen / Gemma / Phi 等模型围绕语言、生态、效率和小模型持续分化理解这些架构演进,你就能更快读懂新的模型技术报告,也能判断一个模型到底是在结构、数据、训练还是推理侧做了创新。
推荐阅读
► 技术资讯: 魔方 AI 新视界
► 项目应用:开源视界
► 技术专栏: 多模态大模型最新技术解读专栏 | AI 视频最新技术解读专栏 | 大模型基础入门系列专栏 | 视频内容理解技术专栏