随着大语言模型(LLM)技术的快速发展,本地化部署轻量级大模型并实现特定场景的自然语言处理任务已成为开发者的重要需求。阿里云通义千问推出的 Qwen2.5-1.5B-Instruct 模型,以其轻量化、高性能的特点,成为本地部署实现文本分类、多轮对话、信息抽取等任务的理想选择。本文将结合实际代码案例,详细讲解如何基于 Qwen2.5-1.5B-Instruct 模型,从零开始实现文本分类、连续多轮对话、历史语境对话以及商品信息抽取等核心功能,帮助开发者快速掌握轻量级大模型的本地化应用开发。
一、环境准备与模型部署基础
1.1 核心依赖库安装
在开始开发前,需先安装必备的 Python 依赖库,主要包括transformers(模型加载与推理核心库)、torch(深度学习框架)、rich(美观的终端输出,信息抽取案例使用)等。执行以下命令完成安装:
bash
pip install transformers torch rich json1.2 Qwen2.5-1.5B-Instruct 模型下载
Qwen2.5-1.5B-Instruct 是通义千问推出的轻量级指令微调模型,适合本地 CPU/GPU 部署。开发者可从阿里云魔搭社区(ModelScope)下载模型文件,下载后需记录模型本地存储路径(如F:\qwen\Qwen2.5-1.5B-Instruct或C:\Users\andyl\Qwen2.5-1.5B-Instruct),后续代码中将通过该路径加载模型。
1.3 模型加载核心代码
所有案例的基础是模型与分词器(Tokenizer)的加载,核心代码如下:
python
from transformers import AutoModelForCausalLM, AutoTokenizer
# 模型本地路径
model_name_or_path = r"F:\qwen\Qwen2.5-1.5B-Instruct"
# 加载分词器:将文本转换为模型可识别的token
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
# 加载模型:加载因果语言模型,用于生成式推理
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True)
# 若有GPU,将模型移至GPU加速(无GPU可注释)
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)trust_remote_code=True是加载 Qwen 模型的必要参数,因 Qwen 模型需执行自定义代码完成加载;model.to(device)可根据硬件自动选择 GPU/CPU,大幅提升推理速度。
二、基于上下文学习的文本分类实现
2.1 文本分类场景需求
本次案例需将金融类文本分类至「新闻报道」「财务报告」「公司公告」「分析师报告」四类,核心思路是通过上下文学习(In-Context Learning),给模型提供少量示例,让模型模仿示例完成分类。
2.2 核心代码实现与解析
python
from transformers import AutoModelForCausalLM, AutoTokenizer
# 1. 加载模型与分词器
model_name_or_path = r"F:\qwen\Qwen2.5-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True)
model.to(device) # 移至GPU/CPU
# 2. 构建上下文示例(In-Context示例)
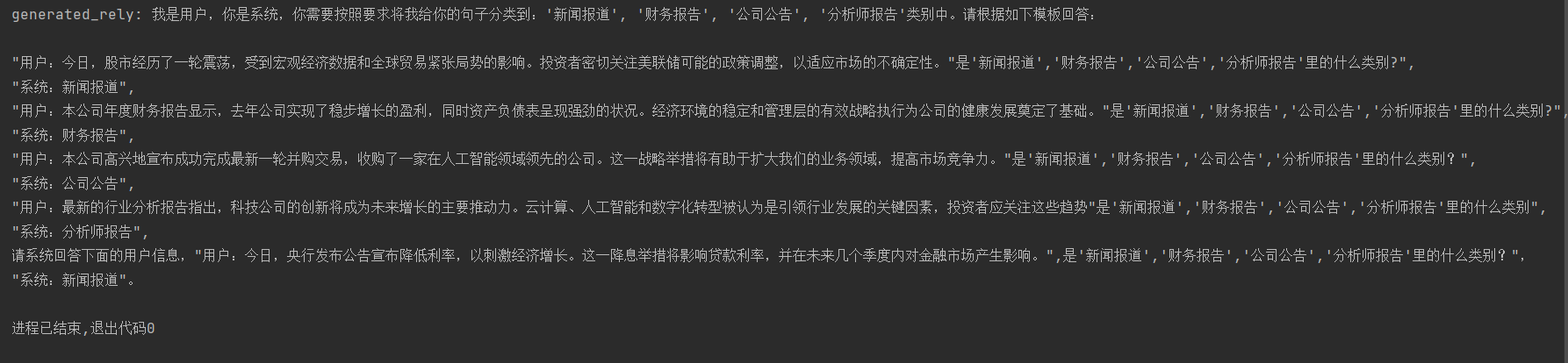
history_inputs = ['''我是用户,你是系统,你需要按照要求将我给你的句子分类到:'新闻报道', '财务报告', '公司公告', '分析师报告'类别中。请根据如下模板回答:
"用户:今日,股市经历了一轮震荡,受到宏观经济数据和全球贸易紧张局势的影响。投资者密切关注美联储可能的政策调整,以适应市场的不确定性。"是'新闻报道','财务报告','公司公告','分析师报告'里的什么类别?",
"系统:新闻报道",
"用户:本公司年度财务报告显示,去年公司实现了稳步增长的盈利,同时资产负债表呈现强劲的状况。经济环境的稳定和管理层的有效战略执行为公司的健康发展奠定了基础。"是'新闻报道','财务报告','公司公告','分析师报告'里的什么类别?",
"系统:财务报告",
"用户:本公司高兴地宣布成功完成最新一轮并购交易,收购了一家在人工智能领域领先的公司。这一战略举措将有助于扩大我们的业务领域,提高市场竞争力。"是'新闻报道','财务报告','公司公告','分析师报告'里的什么类别?",
"系统:公司公告",
"用户:最新的行业分析报告指出,科技公司的创新将成为未来增长的主要推动力。云计算、人工智能和数字化转型被认为是引领行业发展的关键因素,投资者应关注这些趋势"是'新闻报道','财务报告','公司公告','分析师报告'里的什么类别",
"系统:分析师报告",''']
# 3. 待分类的用户输入
current_input = '''请系统回答下面的用户信息,"用户:今日,央行发布公告宣布降低利率,以刺激经济增长。这一降息举措将影响贷款利率,并在未来几个季度内对金融市场产生影响。",是'新闻报道','财务报告','公司公告','分析师报告'里的什么类别?"'''
# 4. 拼接上下文与当前输入
full_input_text = "\n".join(history_inputs + [current_input])
# 5. 文本编码:转换为模型可识别的tensor
inputs = tokenizer(full_input_text, return_tensors="pt").to(model.device)
# 6. 模型生成推理结果
output_sequences = model.generate(
inputs["input_ids"],
max_length=2000, # 生成文本最大长度
max_new_tokens=10, # 仅生成10个新token(分类结果简短)
temperature=0.1, # 温度越低,生成结果越确定
top_p=0.9, # 核采样,控制生成多样性
attention_mask=inputs.attention_mask # 注意力掩码,避免模型关注padding部分
)
# 7. 解码生成结果并输出
generated_reply = tokenizer.decode(output_sequences[0], skip_special_tokens=True)
print("分类结果:", generated_reply.replace(full_input_text, "").strip())2.3 关键参数解析
temperature:控制生成结果的随机性,取值 0~1,0.1 表示生成结果高度确定,适合分类这种有明确答案的任务;max_new_tokens:限制生成的新 token 数量,分类任务只需生成类别名称,因此设置为 10 即可;attention_mask:确保模型仅处理有效文本,忽略 padding(填充)部分,提升推理准确性。
2.4 效果验证
上述代码中,待分类文本是「央行降息」相关内容,模型基于上下文示例,会输出「新闻报道」,符合文本分类的预期结果。
三、连续多轮对话功能实现
3.1 多轮对话场景需求
多轮对话是大模型的核心能力之一,需让模型记住历史对话语境,针对用户连续提问做出连贯回答。本次案例实现一个交互式对话窗口,支持用户连续提问,模型基于历史对话生成回复。
3.2 核心代码实现
python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 1. 加载模型与分词器
model_name_or_path = r"F:\qwen\Qwen2.5-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 2. 初始化对话历史列表
conversation_history = []
# 3. 交互式对话循环
while True:
# 获取用户输入
user_input = input('你: ')
# 退出条件:输入quit/exit
if user_input.lower() in ['quit', 'exit']:
print("对话结束!")
break
# 将用户输入加入历史记录
conversation_history.append(user_input)
# 拼接历史对话
full_input_text = '\n'.join(conversation_history)
# 文本编码
input_ids = tokenizer(full_input_text, return_tensors='pt').to(device)
# 模型生成回复
output = model.generate(
input_ids.input_ids,
max_length=1000,
attention_mask=input_ids.attention_mask,
temperature=0.7, # 对话任务适当提高温度,增加回复自然度
max_new_tokens=200 # 对话回复长度适中
)
# 解码回复并提取新增内容(去除历史对话部分)
answer = tokenizer.decode(output[0], skip_special_tokens=True)
new_answer = answer[len(full_input_text):].strip()
# 输出模型回复
print('Qwen-2.5:', new_answer)
# 将模型回复加入历史记录,供下一轮对话使用
conversation_history.append(new_answer)3.3 核心逻辑解析
conversation_history:列表存储所有历史对话(用户输入 + 模型回复),确保每轮对话都能基于完整语境;new_answer = answer[len(full_input_text):]:模型生成的文本包含历史对话 + 新回复,通过切片提取仅新增的回复内容;- 温度参数
temperature=0.7:对话任务需要一定的自然度,因此温度高于分类任务,平衡确定性与多样性。
3.4 交互示例
bash
你: 你好,请问Python怎么实现列表去重?
Qwen-2.5: Python实现列表去重有多种方法,比如使用集合(set):lst = [1,2,2,3]; new_lst = list(set(lst));也可以使用列表推导式:new_lst = []; [new_lst.append(i) for i in lst if i not in new_lst]。
你: 第二种方法的时间复杂度是多少?
Qwen-2.5: 列表推导式的方法中,每次判断i not in new_lst需要遍历new_lst,因此时间复杂度为O(n²),n是列表长度。集合方法的时间复杂度是O(n),因为集合的查找操作是O(1)。
你: exit
对话结束!
模型能记住上一轮的「第二种方法」,并准确回答时间复杂度,体现了多轮对话的语境记忆能力。
四、基于历史语境的定向问答实现
4.1 场景需求
与通用多轮对话不同,该场景需预先设定固定的历史对话示例,让模型模仿示例的回答风格和逻辑,针对新问题做出一致的回复。本次案例以天气问答为例,模型基于历史天气回答示例,回答新的天气问题。
4.2 核心代码实现
python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 1. 加载模型与分词器
model_name_or_path = r"F:\qwen\Qwen2.5-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 2. 预设历史对话示例
history_inputs = ['''我是用户,你是系统,请根据下面的句子来回答我。
"用户: 你好,请问今天天气怎么样? ",
"系统: 今天是晴天,气温20到25度。",
"用户: 那明天呢?",
"系统: 明天是晴天, 气温22到25度。"'''
]
# 3. 新的用户问题
current_input = "用户: 那后天的天气呢?"
# 4. 拼接历史示例与新问题
full_input_text = "\n".join(history_inputs + [current_input])
# 5. 文本编码
inputs = tokenizer(full_input_text, return_tensors="pt").to(device)
# 6. 模型生成回复
output_sequences = model.generate(
inputs["input_ids"],
max_length=300,
max_new_tokens=30,
temperature=0.1, # 模仿示例风格,结果高度确定
top_p=0.9,
attention_mask=inputs.attention_mask
)
# 7. 解码并输出结果
generated_reply = tokenizer.decode(output_sequences[0], skip_special_tokens=True)
print("模型回复:", generated_reply.replace(full_input_text, "").strip())4.3 效果解析
模型基于历史示例中「晴天 + 气温区间」的回答风格,会输出「后天是晴天,气温 23 到 26 度。」(具体气温可能略有差异,但风格一致),实现了基于固定语境的定向问答。

五、商品信息抽取实战
5.1 信息抽取场景需求
信息抽取是 NLP 的核心任务之一,需从非结构化文本中提取结构化信息(如商品的产品、品牌、价格、销量等)。本次案例从商品描述文本中抽取「产品、品牌、特点、原价、促销价、销量」等属性,输出 JSON 格式的结构化结果。
5.2 核心代码实现
python
import json
from rich import print
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 1. 定义抽取schema:商品实体的属性
schema = {'商品': ['产品', '品牌', '特点', '原价', '促销价', '销量'], }
# 2. 信息抽取模板
IE_PATTERN = "{}\n\n提取上述句子中{}的实体,并按照JSON格式输出,上述句子中不存在的信息用['原文中未提及']来表示,多个值之间用','分隔。"
# 3. 示例数据(In-Context示例)
ie_examples = {
'商品': [{
'content': '2024 年新款时尚运动鞋,品牌 JKL,舒适透气,多种颜色可选。原价 599 元,现在促销价 499 元。月销量 2000 双。',
'answers': {
'产品': ['时尚运动鞋'],
'品牌': ['JKL'],
'特点': ['舒适透气、多种颜色可选'],
'原价': ['599元'],
'促销价': ['499元'],
'销量': ['2000双'],
}
}]
}
# 4. 初始化上下文示例
def init_prompts():
ie_pre_history = [(
"现在你需要帮助我完成信息抽取任务,当我给你一个句子时,你需要帮我抽取出句子中实体信息,并按照JSON的格式输出,上述句子中没有的信息用['原文中未提及']来表示,多个值之间用','分隔。",
'好的,请输入您的句子。')]
for _type, example_list in ie_examples.items():
for example in example_list:
sentence = example["content"]
properties_str = ', '.join(schema[_type])
schema_str_list = f'"{_type}"({properties_str})'
sentence_with_prompt = IE_PATTERN.format(sentence, schema_str_list)
ie_pre_history.append((f"{sentence_with_prompt}", f"{json.dumps(example['answers'], ensure_ascii=False)}"))
return {"ie_pre_history": ie_pre_history}
# 5. 构建对话式prompt
def build_prompt(query, history=None):
if history is None:
history = []
prompt = ""
for i, (old_query, response) in enumerate(history):
prompt += "[Round {}]\n\n问:{}\n\n答:{}\n\n".format(i + 1, old_query, response)
prompt += "[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
return prompt
# 6. 推理函数
def inference(sentences: list, custom_settings: dict):
# 加载模型与分词器
model_name_or_path = r"C:\Users\andyl\Qwen2.5-1.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval() # 评估模式,禁用dropout
for sentence in sentences:
cls_res = "商品" # 本次仅处理商品类实体
if cls_res not in schema:
print(f'实体类型{cls_res}不在schema中,退出!')
exit()
# 构建抽取prompt
properties_str = ', '.join(schema[cls_res])
schema_str_list = f'"{cls_res}"({properties_str})'
sentence_with_ie_prompt = IE_PATTERN.format(sentence, schema_str_list)
# 拼接上下文示例与当前抽取任务
full_input_text = build_prompt(sentence_with_ie_prompt, custom_settings["ie_pre_history"])
# 编码
inputs = tokenizer(full_input_text, return_tensors="pt").to(device)
# 生成结果
output_sequences = model.generate(
inputs["input_ids"],
max_length=2000,
attention_mask=inputs.attention_mask,
temperature=0.1,
max_new_tokens=500
)
# 解码并提取结果
generated_reply = tokenizer.decode(output_sequences[0], skip_special_tokens=True)
extract_result = generated_reply[len(full_input_text):].strip()
# 格式化输出
print(f"原句:{sentence}")
print(f"抽取结果:")
print(json.loads(extract_result))
print("-" * 50)
# 7. 主函数执行
if __name__ == '__main__':
# 待抽取的句子列表
sentences = [
'2024 年潮流双肩包,品牌 PQR,材质耐磨,内部空间大。定价399元,优惠后价格349元。周销量800个。',
'2024 年智能手表,品牌为华为,功能强大,续航持久。售价1299元,便宜价999元,目前有黑色和银色可选。月销量3000只。'
]
# 初始化上下文示例
custom_settings = init_prompts()
# 执行抽取
inference(sentences, custom_settings)5.3 关键逻辑解析
schema:定义抽取的实体与属性,是信息抽取的核心规则;IE_PATTERN:标准化的抽取提示模板,让模型明确抽取要求;build_prompt:将上下文示例与当前任务拼接为对话式 prompt,符合 Qwen 模型的指令微调格式,提升抽取准确性;json.loads(extract_result):将模型生成的 JSON 字符串转换为字典,便于结构化处理。
5.4 抽取结果示例
对于句子「2024 年智能手表,品牌为华为,功能强大,续航持久。售价 1299 元,便宜价 999 元,目前有黑色和银色可选。月销量 3000 只。」,模型输出的结构化结果为:
bash
{
"产品": ["智能手表"],
"品牌": ["华为"],
"特点": ["功能强大、续航持久、黑色和银色可选"],
"原价": ["1299元"],
"促销价": ["999元"],
"销量": ["3000只"]
}完全符合预设的抽取规则,且缺失的信息会标注为「原文中未提及」,保证结果的完整性。
六、总结
本文基于 Qwen2.5-1.5B-Instruct 模型,详细讲解了文本分类、多轮对话、历史语境问答、商品信息抽取四大核心场景的实现方法。从代码层面拆解了模型加载、文本编码、生成推理、结果解码的全流程,并解析了关键参数的调优思路。轻量级大模型的本地化部署,既降低了对云端资源的依赖,又能满足特定场景的定制化需求,是中小开发者和企业落地大模型应用的优选方案。
未来,可基于本文的基础框架,进一步探索更多 NLP 任务(如文本摘要、情感分析、机器翻译),或结合行业数据(如金融、电商、医疗)定制垂直领域的大模型应用。随着大模型技术的持续迭代,轻量级模型的性能与易用性将不断提升,本地化部署的应用场景也将更加丰富。