HDFS伪分布式集群搭建
安装JDK
按照以下步骤在node1节点上安装JDK8。
- 在node1节点创建/software目录,上传并安装jdk8 rpm包**
rpm -ivh /software/jdk-8u181-linux-x64.rpm
以上命令执行完成后,会在每台节点的/user/java下安装jdk8。
**2) 配置jdk环境变量**
在node1节点上配置jdk的环境变量:
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64
export PATH=JAVA_HOME/bin:PATH
export CLASSPATH=.:JAVA_HOME/lib/dt.jar:JAVA_HOME/lib/tools.jar
以上配置完成后,最后执行"source /etc/profile"使配置生效。
HDFS伪分布式集群搭建
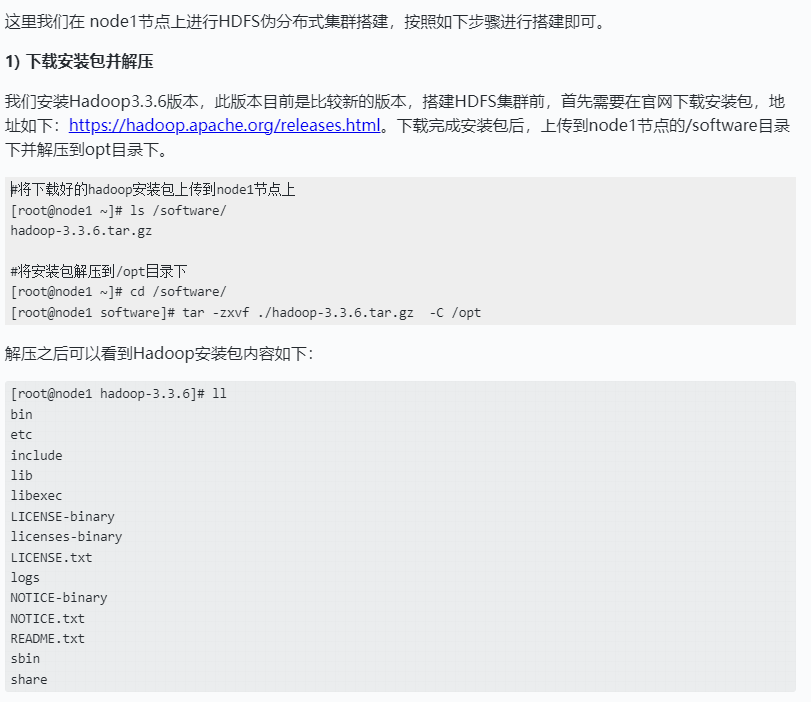
以上Hadoop解压文件重要目录解释如下:
bin目录:Hadoop最基本的管理脚本和使用脚本的目录,用户可以直接使用这些脚本管理和使用Hadoop。
etc目录:Hadoop配置文件所在的目录,包括core-site,xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、works等。
include:对外提供的编程库头文件,这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。
lib目录:lib目录包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。
sbin目录:Hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动/关闭脚本。
share目录:存放Hadoop的依赖jar包、文档、和官方案例,对HDFS 操作依赖的jar包都在这里。


格式化并启动HDFS集群
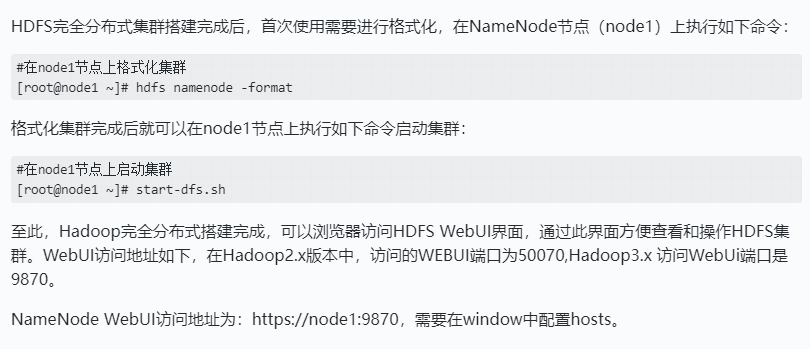
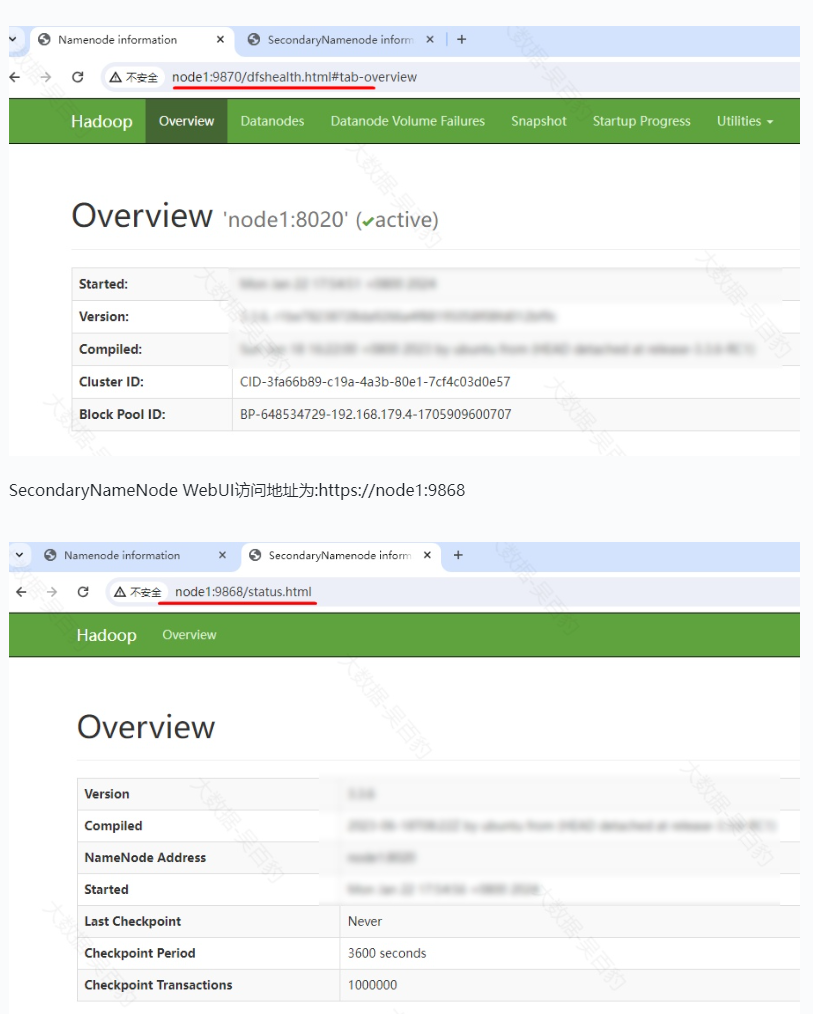
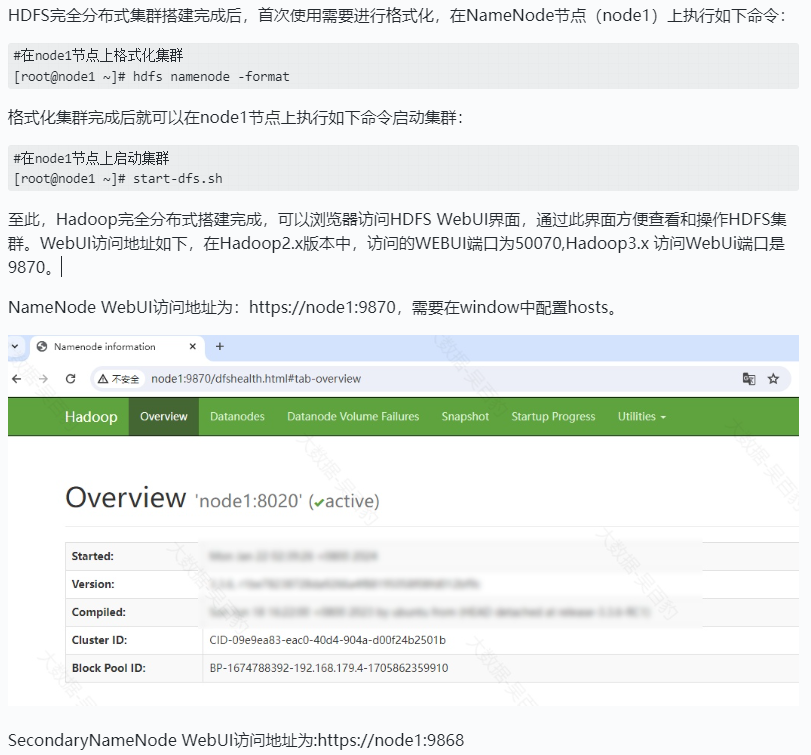
停止集群时只需要在NameNode节点上执行stop-dfs.sh命令即可。后续再次启动HDFS集群只需要在NameNode节点执行start-dfs.sh命令,不需要再次格式化集群。
查看集群目录


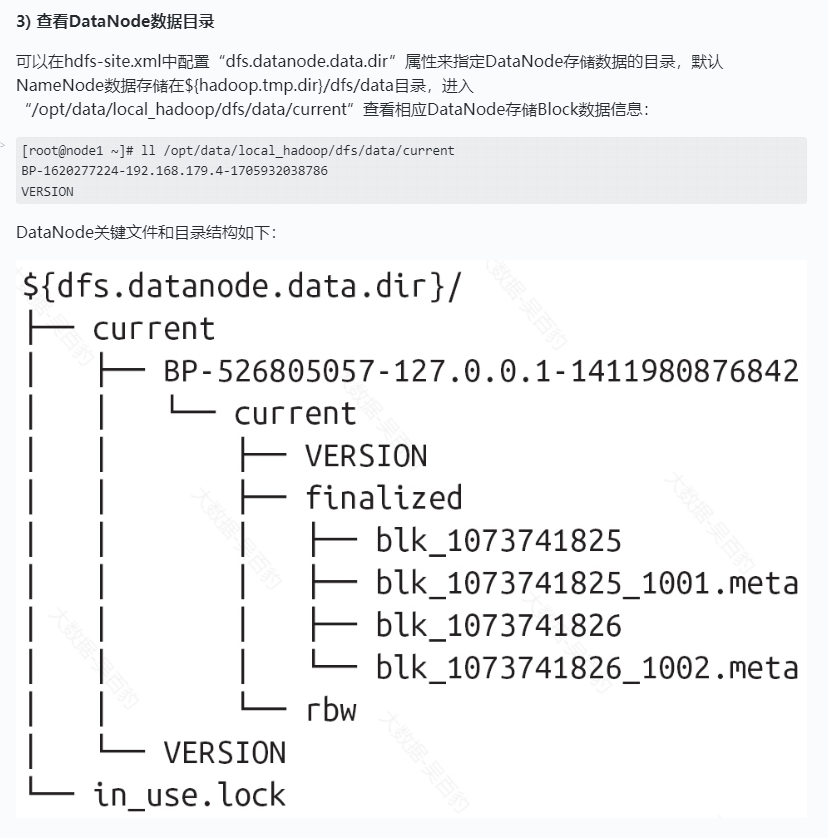
HDFS块数据存储于blk_前缀的文件中,包含了被存储文件原始字节数据的一部分。
每个block文件都有一个.meta后缀的元数据文件关联。该文件包含了一个版本和类型信息的头部,后接该block中每个部分的校验和。
每个block属于一个block池,每个block池有自己的存储目录,该目录名称就是该池子的ID(跟NameNode的VERSION文件中记录的block池ID一样)。
当一个目录中的block达到64个(通过dfs.datanode.numblocks配置)的时候,DataNode会创建一个新的子目录来存放新的block和它们的元数据。这样即使当系统中有大量的block的时候,目录树也不会太深。同时也保证了在每个目录中文件的数量是可管理的,避免了多数操作系统都会碰到的单个目录中的文件个数限制(几十几百上千个)。
如果dfs.datanode.data.dir指定了位于在不同的硬盘驱动器上的多个不同的目录,则会通过轮询的方式向目录中写block数据。需要注意的是block的副本不会在同一个DataNode上复制,而是在不同的DataNode节点之间复制。
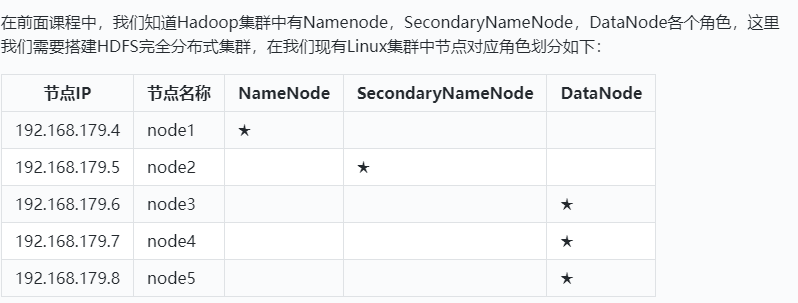
HDFS完全分布式集群搭建
节点规划
安装JDK
HDFS完全分布式集群搭建



格式化并启动HDFS集群
查看集群目录



HDFS集群搭建注意点