Kafka 调优与运维实战
🏠 返回 README | ⬅️ 01-基础与原理.md | ➡️ 03-设计与编码.md
包含章节 :Ch9 调优实战 / Ch10 监控运维 / Ch11 MQ 对比 / Ch12 真实故障案例 难度 :⭐⭐ 高频考点 建议 :本模块是与 简历项目 结合最紧密的部分,建议第 2 周配合自己实际经验复习。Ch12 故障案例按 STAR 模板背 3~5 个,可应付任何"讲讲你解决过的难题"。
📑 本模块目录
- [9. 生产环境调优实战(高频考点)](#9. 生产环境调优实战(高频考点) "#9-%E7%94%9F%E4%BA%A7%E7%8E%AF%E5%A2%83%E8%B0%83%E4%BC%98%E5%AE%9E%E6%88%98%E9%AB%98%E9%A2%91%E8%80%83%E7%82%B9") ⭐⭐
- [10. 监控、运维与容量规划](#10. 监控、运维与容量规划 "#10-%E7%9B%91%E6%8E%A7%E8%BF%90%E7%BB%B4%E4%B8%8E%E5%AE%B9%E9%87%8F%E8%A7%84%E5%88%92") ⭐⭐
- [11. Kafka 与同类 MQ 对比](#11. Kafka 与同类 MQ 对比 "#11-kafka-%E4%B8%8E%E5%90%8C%E7%B1%BB-mq-%E5%AF%B9%E6%AF%94") ⭐
- [12. 真实故障案例复盘(强烈建议背熟)](#12. 真实故障案例复盘(强烈建议背熟) "#12-%E7%9C%9F%E5%AE%9E%E6%95%85%E9%9A%9C%E6%A1%88%E4%BE%8B%E5%A4%8D%E7%9B%98%E5%BC%BA%E7%83%88%E5%BB%BA%E8%AE%AE%E8%83%8C%E7%86%9F") ⭐⭐⭐
🟡 模块二导引:调优与运维实战
目标 :把"原理"翻译成"参数"和"操作"。能针对一个真实场景(吞吐瓶颈、延迟抖动、ISR 频繁收缩)说出为什么调这个参数、调多少、调完看哪个指标验证。
检验标准:
- 能默写 Broker / OS / JVM / Producer / Consumer 5 段式调优清单
- 能讲清 G1 vs ZGC 在 Kafka 上的取舍
- 能根据"消息平均大小 + QPS + 副本数 + 保留天数"现场算出磁盘容量与网络带宽
- 能讲 3 个以上自己经历过的 Kafka 故障(按 STAR 模板)
本模块共 4 章 (Ch9~Ch12)。Ch9 调优 和 Ch12 故障案例是面试性价比最高的两章,建议背熟。
9. 生产环境调优实战(高频考点)
9.1 调优总原则
不要背参数,先讲清目标 → 瓶颈定位 → 调整 → 验证 的方法论。
markdown
1. 明确目标:吞吐?延迟?可用性?成本?通常需要权衡,不可能全要。
2. 找瓶颈:是 CPU / 网络 / 磁盘 IO / GC / 锁 / 网络往返?
3. 单变量调整:每次只改一类参数。
4. 压测验证:kafka-producer-perf-test.sh / kafka-consumer-perf-test.sh + 业务压测。
5. 灰度发布:从一个 broker 滚动调,避免一把梭翻车。9.2 Broker 端调优
properties
# 网络与 IO 线程
num.network.threads=6 # 一般 = CPU 核数 / 2
num.io.threads=16 # 一般 = 磁盘数 × 8
queued.max.requests=1000
# Socket buffer
socket.send.buffer.buffer.bytes=1048576
socket.receive.buffer.bytes=1048576
socket.request.max.bytes=104857600 # 100MB,需 ≥ 业务最大消息 × 攒批
# 副本拉取线程(关键!)
num.replica.fetchers=4 # 每个 Broker 的 Fetcher 线程数,3 个 broker 起码 4~8
# 日志保留
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
# 落盘策略(不要主动 fsync!)
log.flush.interval.messages=Long.MAX_VALUE
log.flush.interval.ms=Long.MAX_VALUE
# 压缩与 cleaner
log.cleaner.threads=2
log.cleaner.dedupe.buffer.size=134217728
# 副本可靠性
default.replication.factor=3
min.insync.replicas=2
unclean.leader.election.enable=false
auto.leader.rebalance.enable=true
leader.imbalance.check.interval.seconds=300
leader.imbalance.per.broker.percentage=10
# Topic 默认
num.partitions=12
message.max.bytes=10485760 # 10MB(按业务调整,过大会拖慢一切)9.3 OS 级调优
bash
# 文件描述符
ulimit -n 1000000
echo "* soft nofile 1000000" >> /etc/security/limits.conf
echo "* hard nofile 1000000" >> /etc/security/limits.conf
# 关闭/降低 swap
sysctl -w vm.swappiness=1
# 脏页(控制刷盘抖动)
sysctl -w vm.dirty_background_ratio=5
sysctl -w vm.dirty_ratio=60
sysctl -w vm.dirty_expire_centisecs=12000
# 网络
sysctl -w net.core.somaxconn=32768
sysctl -w net.core.netdev_max_backlog=16384
sysctl -w net.ipv4.tcp_max_syn_backlog=8192
# 磁盘文件系统
# 推荐 XFS > ext4;mount 加 noatime,nodiratime
# 单盘单分区不做 RAID,多盘走 JBOD(让 Kafka 自己平衡)9.4 JVM 调优(含 G1 vs ZGC vs Shenandoah 选型)
9.4.1 为什么 Kafka Broker 默认推 G1,而不是 ZGC?(高频追问)
这是 10 年开发被狠狠考的题:很多人无脑回答"ZGC 暂停 < 1ms 当然用 ZGC",但用在 Kafka Broker 上几乎没有收益,反而是负作用。要从 Kafka 的内存模型出发讲清楚。
核心结论一句话:
Kafka Broker 性能由 PageCache 决定,不由 JVM 堆决定。堆只用 4
8GB,G1 已经能把 P99 GC 控制在 1020ms 内;ZGC 的"超低延迟"优势体现不出来,反而要付出更高的 CPU、内存放大和读屏障开销。
具体拆解:
1)Kafka Broker 的内存模型决定了堆很小
markdown
机器 64GB 内存 → JVM 堆只占 6GB,剩下 ~58GB 全部留给 OS PageCache
↑
Producer/Consumer/副本同步全部走 PageCache + sendfile
消息字节流根本不在堆里停留Broker 堆里到底放了什么?
- 网络层 buffer(NIO 的 ByteBuffer 大多是 DirectBuffer,走堆外)。
- ProducerStateManager(PID → 序列号缓存)、Log 元数据、Index 缓存(mmap,走堆外)。
- Controller 元数据、Coordinator 缓存。
- 真正落到堆上的对象生命周期都很短,G1 的年轻代复制 + 区域回收就够用了。
2)ZGC 的优势场景与 Kafka 不匹配
| ZGC 优势场景 | Kafka Broker 现状 |
|---|---|
| 大堆(几十 GB ~ TB 级) | 堆只有 4~8 GB |
| 大对象、大量长寿对象(缓存系统) | 大多是短命对象 |
| GC pause 是瓶颈 | PageCache miss / 磁盘 IO / 网络才是瓶颈 |
| 业务对 P99.9 延迟极度敏感(< 5ms) | Kafka 业务普遍能容忍 P99 几十 ms |
3)ZGC 在小堆上的反向代价
- CPU 开销 :ZGC 是并发标记/转移 GC,需要读屏障(Load Barrier) 。每次对象引用读取都要走一次 colored pointer 检查,应用线程吞吐下降 5%~15%。Kafka 是吞吐型系统,这一刀很疼。
- 内存放大:早期 ZGC 用 colored pointer 后还需要保留多视图(multi-mapping),实际内存占用 > 堆大小。Generational ZGC(JDK 21+)改善了这点,但仍比 G1 多一些 footprint。
- GC 触发更频繁:堆小 + 吞吐高 → ZGC 并发周期跟不上分配速率,频繁触发并发 GC,CPU 反而打高。
- 暂停虽短但次数多,对系统总开销不一定更优。
4)什么时候 Kafka 才考虑 ZGC?
- Broker 堆被迫调大(≥ 16GB):例如海量 ProducerStateManager(百万级 PID 的事务场景)、KRaft Controller 节点存超大元数据。
- JDK 21+ 的 Generational ZGC (
-XX:+UseZGC -XX:+ZGenerational):分代后年轻代走类似 G1 的快速 minor GC,CPU 开销大幅下降;这种情况下,对延迟敏感的金融场景可以考虑切 ZGC。 - Kafka Streams / 业务 Consumer (不是 Broker):业务 Consumer 通常堆很大(业务对象、缓存、聚合状态),且对端到端 P99 敏感 → ZGC / Shenandoah 收益明显。
9.4.2 G1 推荐配置(Broker,JDK 17+)
bash
KAFKA_HEAP_OPTS="-Xms6g -Xmx6g" # 堆固定大小,避免动态扩缩
KAFKA_JVM_PERFORMANCE_OPTS="
-server
-XX:+UseG1GC
-XX:MaxGCPauseMillis=20 # 目标暂停(G1 会尽量满足,非硬保证)
-XX:InitiatingHeapOccupancyPercent=35 # 占用率早点触发并发周期
-XX:G1HeapRegionSize=16m # 大 region 适配 batch 类大对象
-XX:G1ReservePercent=20 # 预留区抗 to-space 溢出
-XX:+ParallelRefProcEnabled # 引用并行处理
-XX:+ExplicitGCInvokesConcurrent # System.gc() 走并发,不全停
-XX:+AlwaysPreTouch # 启动期预触摸内存,避免运行期缺页
-XX:+UseStringDeduplication # G1 字符串去重,对 Topic/key 多的场景省内存
-XX:MaxMetaspaceSize=256m
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/var/log/kafka/
-Xlog:gc*,gc+heap=trace,safepoint:file=/var/log/kafka/gc.log:time,uptime:filecount=10,filesize=100M
"9.4.3 Generational ZGC 配置(JDK 21+,仅在确认堆 ≥ 16GB 或对延迟极度敏感时启用)
bash
KAFKA_HEAP_OPTS="-Xms16g -Xmx16g"
KAFKA_JVM_PERFORMANCE_OPTS="
-server
-XX:+UseZGC
-XX:+ZGenerational # JDK 21 GA
-XX:+AlwaysPreTouch
-XX:SoftMaxHeapSize=14g # 给 ZGC 留缓冲(约 80~85% Xmx)
-XX:ConcGCThreads=4 # 并发 GC 线程,CPU 充裕可调大
-XX:ParallelGCThreads=8 # STW 阶段并行线程
-XX:+HeapDumpOnOutOfMemoryError
-Xlog:gc*:file=/var/log/kafka/gc.log:time,uptime:filecount=10,filesize=100M
"生产经验 :我们曾在 KRaft Controller 节点试过 ZGC(堆 24GB,PID 表过亿),P99 GC 暂停从 G1 的 50ms 降到 < 5ms;但普通 Broker 切 ZGC 后 CPU 利用率上升 8%,吞吐下降 6%,最终回滚到 G1。结论:对症下药,不要无脑选最新 GC。
9.4.4 GC 排查命令清单
bash
# 看 GC 类型与运行参数
jcmd <pid> VM.flags | grep -E "UseG1GC|UseZGC|ConcGCThreads"
# 实时 GC
jstat -gcutil <pid> 1000 30
# GC 日志分析(推荐 GCEasy / GCViewer)
# 关注:YoungGC P99、MixedGC P99、Full GC 次数、Concurrent Cycle Failures
# 看暂停分布
grep "Pause" /var/log/kafka/gc.log | awk '{print $NF}' | sort -n | uniq -c
# 直接抓一次 heap dump(注意全停顿,慎用)
jmap -dump:format=b,file=/tmp/kafka.hprof <pid>9.4.5 Broker 堆调优红线
- 不要给 Broker 太大堆(普通 Broker ≤ 8GB)。Kafka 真正的快依赖 PageCache。
- 机器内存 64GB → 堆 6GB,剩下 58GB 给 PageCache。
- GC 暂停 超过
replica.lag.time.max.ms的 30%(即 ~9s)就会引发 ISR 抖动。所以 P99 GC 必须远低于这个阈值。 - 关闭
-XX:+DisableExplicitGC(不能关,Kafka 内部依赖System.gc()触发 DirectByteBuffer 回收,否则堆外内存泄漏直至 OOM)。这是个经典坑。 - 永远启用
+AlwaysPreTouch,避免上线后第一波流量打缺页风暴。
9.5 Producer 端调优
properties
# 高吞吐场景
acks=all
enable.idempotence=true
batch.size=131072 # 128KB
linger.ms=20
compression.type=lz4 # 或 zstd(更高压缩比,CPU 略高)
buffer.memory=134217728 # 128MB
max.in.flight.requests.per.connection=5
delivery.timeout.ms=120000
request.timeout.ms=30000调优心法:
- 看 Producer JMX:
record-queue-time-avg(等批耗时)↑ →linger.ms大了或 batch 大了;record-send-rate上不去 → 看是否 buffer.memory 满。 - 业务侧不要在 callback 里做重活(Sender 单线程会被拖慢)。
9.6 Consumer 端调优
properties
fetch.min.bytes=65536
fetch.max.wait.ms=100
max.partition.fetch.bytes=1048576
max.poll.records=200
max.poll.interval.ms=300000
session.timeout.ms=45000
heartbeat.interval.ms=15000
partition.assignment.strategy=org.apache.kafka.clients.consumer.CooperativeStickyAssignor
isolation.level=read_committed # 如果生产端用事务实战套路:
- 业务慢 → 不要无脑放大
max.poll.interval.ms,先做线程池异步化。 - 监控
records-lag-max(落后条数)+fetch-latency-avg,定位是消费慢还是拉得慢。
9.7 真实面试现场题(5 道带公司风格标记)
🟦 字节风格 Q1:你给生产 Broker 配 Xmx=8g,CPU 64 核,内存 256GB。线上 P99 写入毛刺到 200ms。怎么定位?
字节"性能压榨"经典题。考点:能不能从 GC / PageCache / 磁盘 / 锁四个维度系统排查。
参考答案:四步定位法。
- 看 GC :
jstat -gcutil <pid> 1000看 G1 暂停。如果 P99 GC > 50ms:- 检查 G1 region 大小,调到 16M
- 检查 InitiatingHeapOccupancyPercent,从默认 45% 降到 35%
- 关键:检查 Heap 是不是太大了,> 8GB 时 G1 暂停容易飙升
- 看 PageCache :
free -h看 buff/cache 是否被吃掉。vmstat 1看bi/bo:- 如果有大量 swap →
swappiness调到 1 - 如果 PageCache miss 率高 → 检查是否 Topic 太多导致命中率下降
- 如果有大量 swap →
- 看磁盘 :
iostat -x 1看await/util:- util > 80% → 磁盘瓶颈,检查是不是 compact / log clean 同步触发
vm.dirty_background_ratio从 10 → 5,让脏页提前后台刷
- 看锁 :JMX
RequestQueueTimeMsP99 是否飙:- 高 → Handler 线程不够,调大
num.io.threads - 低 → 锁竞争(
async-profiler -e lock抓一下)
- 高 → Handler 线程不够,调大
追问:你怎么区分是"GC 抖" vs "Page Cache miss" vs "磁盘抖"导致的写入毛刺?
- 三者都可能让 LogFlushRateAndTimeMs P99 飙高,但RequestQueueTimeMs 同步飙高 = GC/锁;只 LogFlush 飙 = 磁盘;BytesIn 不变 + 命中率掉 = PageCache。
🟧 阿里风格 Q2:你们集群从 ZK 模式升级到 KRaft,怎么做?停机窗口给你 4 小时。
阿里"稳定性 + 平台演进"经典题。考点:升级路径 + 风险预案 + 监控验证。
参考答案:
markdown
阶段 1:评估(提前 2 周)
- 当前版本 ≥ 3.4?不到先升级到 3.4+
- 是否有元数据规模超出 KRaft 默认 quorum 容量
- 备份所有 Topic / ACL / Quota 配置
阶段 2:迁移(当天 4h 窗口)
- 步骤 1(30min):启动 3 个独立的 KRaft Controller
- 步骤 2(1h):执行 ZK → KRaft 元数据迁移工具
- 步骤 3(30min):各 Broker 重启切换为 KRaft 模式
- 步骤 4(30min):验证元数据正确性
- 步骤 5(1h):滚动把流量切回(先小流量、后大流量)
阶段 3:监控
- ActiveControllerCount = 1
- UnderReplicatedPartitions = 0
- Producer/Consumer 客户端无异常报错
- Controller 故障切换毫秒级
回滚预案:
- 任一步骤失败 → 全量回滚到 ZK 模式(保留 ZK 元数据快照)
- 时间窗口预留 1h buffer追问:生产风险点是什么?
- KRaft 模式下 Controller 故障切换更快但对 Quorum 网络更敏感,跨机房 RTT > 50ms 慎用。
- KRaft 早期版本(3.4/3.5)有过 metadata snapshot 大文件的 bug,3.6+ 才稳。
- 更推荐:新建 KRaft 集群 + MM2 数据迁移 + 业务侧切流量,零停机但成本高。
🟪 蚂蚁风格 Q3:金融场景,你怎么权衡 acks=all + min.insync.replicas=2 带来的可用性下降?
蚂蚁"金融可用性 vs 一致性"经典题。
参考答案:
ini
风险:
3 副本 + ISR=2 → 任一 broker 故障仍可写
但若 2 个 broker 同时故障(机架掉电、跨机架)→ 拒绝写入
→ 业务侧 Producer 阻塞 / 失败
应对(多层兜底):
1) 副本放置:Rack-Aware(broker.rack=zone-a/b/c),3 副本跨 3 机架
2) 故障演练:定期 chaos test 拉掉 1 个 broker,验证 ISR=2 仍可写
3) Producer 端降级:buffer.memory 满 + 短期失败 → 写本地 disk-based fallback
4) 业务侧补偿:依靠 Outbox 表 + Debezium 兜底(DB 一旦提交,最终消息一定送达)
5) 告警分级:UnderMinIsr → P0;UnderReplicated → P1
6) 降级开关:极端情况下临时把 min.insync.replicas 改 1(牺牲一致性保可用性)
→ 配合资损监控 + 事后对账修复追问:万一真的丢消息了,怎么发现?
- 不能只靠 Lag 监控(先消费后处理时 Lag=0 但消息已丢)
- 端到端时延埋点:消息生产时间戳 vs 业务落地时间
- 对账系统:DB 流水 vs Kafka 消息条数日终对账
- 业务关键链路:每条消息持久化到 Outbox + Audit log 双写
🟢 腾讯风格 Q4:日均 10 万亿消息的集群,你怎么把单 GB 消息成本从 0.5 元降到 0.3 元?
腾讯"海量 + 成本"经典题。考点:能从存储/网络/CPU 三个维度找出真正的成本大头。
参考答案:
markdown
1) 压缩升级(主战场,省最多)
- lz4 → zstd(压缩比 0.4 → 0.3)
- 预计节省存储 25% + 网络 25%
- CPU 上升 ~10%,可接受
2) Tiered Storage(KIP-405)
- 热数据 1 天本地 NVMe,> 1 天下沉 S3
- S3 单 GB 成本是本地 SSD 的 1/10
- 占总数据量 90%+ 的冷数据走 S3 → 整体磁盘成本降 60%
3) 副本数差异化
- 核心 Topic:副本 3
- 日志类 Topic:副本 2(容忍丢万分之一,业务可重试)
- 整体磁盘节省 17%
4) Quota 限流 + 业务收敛
- 监控异常突增的 Topic(流量翻倍)
- 强制 Topic owner 优化(拉黑必要时)
- 历史包袱清理(无人订阅的 Topic 直接 archive)
5) 跨 AZ 流量优化
- Follower Fetch(KIP-392)让 Consumer 就近读
- 跨 AZ 流量降 50%
合计:单 GB 成本从 0.5 → 0.3,年省约 X 千万。追问:zstd 压缩 CPU 涨多少?业务能接受吗?
- 实测:zstd level 3,CPU +10%;level 6,CPU +25% 但比例再降 5%。
- 业务侧权衡:CPU 成本 vs 存储/带宽成本。在腾讯这种"带宽 = 磁盘 3 倍"的体系下,zstd 一定划算。
🟡 美团/快手风格 Q5:实时推荐系统的 Kafka 集群 P99 延迟从 20ms 飙到 200ms,怎么排查?
美团/快手"实时性"经典题。考点:从客户端到 broker 全链路定位。
参考答案:
markdown
全链路打点排查:
1) Producer 端
- record-queue-time-avg:消息在 RecordAccumulator 等多久?
- request-latency-avg:请求发到 broker 多久?
→ 任一飙升 → 网络问题 / linger.ms 设置不合理
2) Broker 端
- RequestQueueTimeMs:进队列等待
- LocalTimeMs:本地写盘
- RemoteTimeMs:等 ISR 同步(acks=all 才有)
- ResponseQueueTimeMs:回包等待
→ 看哪段最长
3) Consumer 端
- fetch-latency-avg:fetch 请求 RTT
- records-consumed-rate:消费速率
- records-lag-max:消费 lag
定位场景:
- LocalTimeMs 飙 → 磁盘 / GC 抖
- RemoteTimeMs 飙 → 某个 ISR 副本掉队(GC / 网络)
- RequestQueueTimeMs 飙 → Handler 线程不够
- Producer record-queue-time 飙 → 客户端攒批太久(linger.ms)
修复(按场景):
- 副本掉队 → 该 broker GC 调优 / 磁盘升级
- Handler 不够 → num.io.threads 8 → 16
- 客户端攒批 → 实时场景 linger.ms 0~5(牺牲吞吐换延迟)追问:实时推荐场景,linger.ms=0 vs linger.ms=5,你选哪个?
- 取决于业务时延要求。如果 P99 < 50ms 必须命中,linger=0;如果 P99 < 200ms 可接受,linger=5 提升 5~10% 吞吐。
- 真正的优化是业务侧异步发送 + 框架层 fire-and-forget + 服务端 ack=1。
10. 监控、运维与容量规划
本章定位 :从"装上 Kafka 能跑"到"出问题前 5 分钟报警、出问题后 30 分钟止血"。 核心思想 :监控不是装一堆指标,是建立"故障 → 指标 → 处置预案"的链路。
10.1 监控体系总览
关键组件分工:
| 组件 | 作用 | 必要性 |
|---|---|---|
| JMX Exporter | 把 Kafka JMX MBean 暴露为 Prometheus metrics | 必备 |
| Node Exporter | 主机层指标(CPU / Disk / NIC) | 必备 |
| Prometheus | 时序数据库 + 告警规则引擎 | 必备 |
| Grafana | 可视化大盘 | 必备 |
| AlertManager | 告警路由、抑制、分级 | 必备 |
| Burrow | LinkedIn 出品的 Consumer Lag 监控(基于 offset 滑动窗口) | 推荐 |
| Cruise Control | LinkedIn 出品的自动副本均衡 + 异常检测 | 推荐 |
| Kafka UI / Kafdrop / AKHQ | Topic / Group 可视化管理 | 推荐 |
10.2 必看 JMX 指标(按层级 + 严重等级)
10.2.1 集群健康(P0 红线指标,触发立即告警)
| 指标 | 含义 | 告警阈值 | 含义解读 |
|---|---|---|---|
kafka.controller:type=KafkaController,name=OfflinePartitionsCount |
离线分区数 | > 0 立即告警 | 有 partition 没有 Leader → 直接不可用 |
kafka.controller:type=KafkaController,name=ActiveControllerCount |
当前 Controller 数量 | 不等于 1 告警 | 0 = 集群无主;> 1 = 脑裂 |
kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions |
副本未同步分区数 | > 0 持续 1 分钟 | 有副本掉队,可能丢数据风险 |
kafka.server:type=ReplicaManager,name=UnderMinIsrPartitionCount |
ISR 不足 min.insync.replicas 的分区数 | > 0 立即告警 | Producer acks=all 写入会失败 |
kafka.server:type=ReplicaManager,name=AtMinIsrPartitionCount |
ISR 刚好等于 min.insync 的分区数 | 持续增长 告警 | 距离 ISR 不足只差一台 |
10.2.2 性能与吞吐(P1 容量指标)
| 指标 | 含义 | 关注点 |
|---|---|---|
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec |
入流量 byte/s | 容量评估 + 限流 |
kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec |
出流量(含副本同步) | 网络带宽规划 |
kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec |
入消息条数 QPS | 业务量监控 |
kafka.server:type=BrokerTopicMetrics,name=BytesRejectedPerSec |
因配额/大小被拒绝的字节数 | > 0 必看,业务被限流 |
kafka.network:type=RequestMetrics,name=TotalTimeMs,request=Produce |
Produce 端到端耗时(含 Local + Remote + Response Queue) | P99 > 200ms 告警 |
kafka.network:type=RequestMetrics,name=TotalTimeMs,request=FetchConsumer |
Consumer Fetch 耗时 | P99 > 100ms |
kafka.network:type=RequestMetrics,name=TotalTimeMs,request=FetchFollower |
Follower 同步耗时 | 飙升 → ISR 风险 |
kafka.network:type=RequestMetrics,name=RequestQueueTimeMs |
请求在队列里等待时间 | 飙升 = Handler 线程不够 / 锁争用 |
kafka.network:type=RequestMetrics,name=ResponseQueueTimeMs |
响应队列等待时间 | 飙升 = Processor 不够 |
10.2.3 资源使用(P2 资源指标)
| 指标 | 含义 | 阈值 |
|---|---|---|
kafka.network:type=SocketServer,name=NetworkProcessorAvgIdlePercent |
Network 线程空闲率 | < 30% 告警(线程不够) |
kafka.server:type=KafkaRequestHandlerPool,name=RequestHandlerAvgIdlePercent |
Handler 线程空闲率 | < 30% 告警 |
kafka.log:type=LogFlushStats,name=LogFlushRateAndTimeMs |
刷盘耗时 | P99 飙升 → 怀疑磁盘 |
kafka.server:type=ReplicaFetcherManager,name=MaxLag |
Follower 落后 Leader 最大 offset | 持续 > 1000 告警 |
kafka.server:type=DelayedOperationPurgatory,name=PurgatorySize,delayedOperation=Produce |
DelayedProduce 等待数量 | 飙升 = HW 推不动(Follower 卡) |
10.2.4 客户端侧(Producer / Consumer)
Producer:
| 指标 | 含义 |
|---|---|
record-send-rate |
发送速率 |
record-error-rate |
发送失败率 |
record-retry-rate |
重试率(飙高说明 broker 在抖动) |
request-latency-avg / max |
单次 Produce 请求延迟 |
record-queue-time-avg |
消息在 RecordAccumulator 里等待时间 |
buffer-available-bytes |
缓冲池剩余(接近 0 = 即将阻塞 send) |
Consumer:
| 指标 | 含义 |
|---|---|
records-lag-max |
最大滞后条数(核心指标) |
records-consumed-rate |
消费速率 |
fetch-latency-avg |
Fetch 平均延迟 |
commit-latency-avg |
offset 提交延迟 |
rebalance-rate-per-hour |
rebalance 频率(> 1 次/小时 警告) |
last-rebalance-seconds-ago |
距上次 rebalance 时长 |
10.2.5 Lag 监控的正确姿势
⚠️ Burrow 的 Lag = 0 不代表业务零延迟(参考 Ch12 案例 5)。
正确的监控分层:
markdown
1. offset Lag → Burrow / Kafka Exporter
2. 端到端时延 → 消息时间戳 vs 业务落地时间(业务侧自埋点)
3. 业务正确性 → 对账 / 抽样回放10.3 关键告警规则示例(Prometheus)
yaml
groups:
- name: kafka-critical
rules:
- alert: KafkaOfflinePartitions
expr: kafka_controller_kafkacontroller_offlinepartitionscount > 0
for: 1m
labels:
severity: P0
annotations:
summary: "Kafka 集群有离线分区 ({{ $value }} 个)"
runbook: "https://wiki/runbook/kafka-offline-partition"
- alert: KafkaUnderReplicated
expr: kafka_server_replicamanager_underreplicatedpartitions > 0
for: 5m
labels:
severity: P1
annotations:
summary: "Kafka URP 持续 5 分钟 ({{ $value }})"
- alert: KafkaUnderMinIsr
expr: kafka_server_replicamanager_underminisrpartitioncount > 0
for: 1m
labels:
severity: P0
annotations:
summary: "Kafka 有分区 ISR 不足 min.insync.replicas,影响 Producer 写入"
- alert: KafkaProduceLatencyHigh
expr: histogram_quantile(0.99, rate(kafka_network_requestmetrics_totaltimems_request_produce_bucket[5m])) > 200
for: 10m
labels:
severity: P2
annotations:
summary: "Kafka Produce P99 > 200ms 持续 10 分钟"
- alert: KafkaConsumerLagHigh
expr: kafka_consumergroup_lag{consumergroup="order-service"} > 100000
for: 5m
labels:
severity: P1
annotations:
summary: "Consumer {{ $labels.consumergroup }} Lag={{ $value }}"
- alert: KafkaIsrShrinkRate
expr: rate(kafka_server_replicamanager_isrshrinkspersec[5m]) > 0.5
for: 5m
labels:
severity: P2
annotations:
summary: "ISR 收缩频繁,疑似 GC / 网络 / 磁盘抖动"10.4 容量规划详细方法
10.4.1 计算公式
scss
[输入参数]
单条消息平均大小 M (Byte)
峰值 QPS Q
副本数 R (一般 3)
保留时长 T (天)
预留余量 F (1.3 ~ 1.5)
压缩比 C (lz4 ≈ 0.4,zstd ≈ 0.3)
Consumer 组数 G
[输出]
磁盘总需求 = M × Q × 86400 × T × R × F × C (压缩后实际占用)
磁盘单 broker = 总需求 / broker 数
入网带宽 = M × Q
出网带宽 = M × Q × (G + R - 1) ← R-1 是副本同步消耗
内存最少 = max(6GB 堆, 30% 机器内存留 PageCache)
CPU = QPS / 单核处理量(lz4 压缩约 2 万条/核/秒)10.4.2 实战示例:日均 100 亿消息系统
ini
输入:
日消息总量 = 100 亿
平均 QPS = 100亿 / 86400 ≈ 12 万
峰值 QPS(按 5 倍)= 60 万
M = 1 KB
T = 7 天
R = 3
F = 1.5
C = 0.4 (lz4)
G = 5 (5 个消费组)
输出:
磁盘 = 1024 × 60万 × 86400 × 7 × 3 × 1.5 × 0.4 ≈ 670 TB
→ 每 broker 24×7TB NVMe → 净 168 TB → 至少 5 台
→ 实际加 50% 余量 → 8 台
入网 = 1024 × 60万 = 600 MB/s ≈ 4.8 Gbps
出网 = 1024 × 60万 × (5 + 2) = 4.2 GB/s ≈ 33.6 Gbps
→ 25 Gbps 网卡 × 2 (bond)
内存 = 每 broker 256GB(堆 8GB + PageCache 248GB)
CPU = 60万 / 2万 = 30 核 (单 broker,含 SSL/压缩)
→ 64 核10.4.3 容量水位预警
erlang
磁盘水位 单 broker 使用率 < 70% (留 30% 给 segment roll + compact)
网卡水位 使用率 < 60% (留 40% 应对突发)
PageCache 命中率 ≥ 95%(用 vmstat 看 cache miss)
GC 时间占比 < 1%10.5 集群扩容流程(实战)
10.5.1 扩容步骤
10.5.2 关键命令
bash
# 1. 列出待迁移 topic
echo '{"topics":[{"topic":"order-event"}],"version":1}' > topics-to-move.json
# 2. 生成迁移计划(指定目标 broker 列表)
kafka-reassign-partitions.sh --bootstrap-server $BS \
--topics-to-move-json-file topics-to-move.json \
--broker-list "1,2,3,4,5,6" \
--generate > plan.json
# 3. 提取 Proposed partition reassignment 部分到 reassign.json
# 4. 执行(带限速!默认无限速会打挂集群)
kafka-reassign-partitions.sh --bootstrap-server $BS \
--reassignment-json-file reassign.json \
--execute \
--throttle 50000000 # 50 MB/s 单 broker 限速
# 5. 验证
kafka-reassign-partitions.sh --bootstrap-server $BS \
--reassignment-json-file reassign.json \
--verify
# 6. 移除限速(一定要做,否则会一直限制)
kafka-configs.sh --bootstrap-server $BS --alter \
--entity-type brokers --entity-name 1 \
--delete-config follower.replication.throttled.rate,leader.replication.throttled.rate10.5.3 扩容期监控重点
markdown
1. UnderReplicatedPartitions → 必然短暂飙升,不要紧张
2. 网卡使用率 → 限速时应该贴近 throttle 上限
3. Producer P99 → 受影响应 < 30%,否则 throttle 调小
4. Consumer Lag → 不应有显著增长10.6 缩容 / 下线流程
bash
# 1. 把目标 broker 的所有 partition 迁出去
echo '{"topics":[{"topic":"*"}],"version":1}' > all-topics.json
kafka-reassign-partitions.sh ... --topics-to-move-json-file all-topics.json \
--broker-list "1,2,3,4,5" # 不包含要下线的 broker 6
# 2. 等迁移完成
kafka-reassign-partitions.sh ... --verify
# 3. 确认目标 broker 上没有 partition
kafka-broker-api-versions.sh --bootstrap-server <broker6> ...
# 4. 优雅停机(kafka-server-stop.sh,发 SIGTERM)
# 5. 等待 controlled.shutdown 完成(看 server.log "Controlled shutdown completed")⚠️ 不能直接 kill -9,会让所有 partition Leader 在该 broker 上的瞬间不可用。
10.7 滚动升级流程
关键参数:
properties
# 升级期间临时设置:让新 broker 用旧协议与老 broker 通信
inter.broker.protocol.version=2.8
log.message.format.version=2.8
# 全部升级完后再统一切到 3.7
inter.broker.protocol.version=3.7
log.message.format.version=3.7避坑:
- 2.8 → 3.x 跨大版本:先从 2.8 升到 3.3,再升到目标版本(不能直接跨太多版本)。
- ZK → KRaft :3.4+ 提供 migration 工具(
kafka.tools.MetadataQuorumCommand),但生产慎用,建议新建 KRaft 集群 + MM2 迁移数据更安全。
10.8 Cruise Control 自动均衡
Cruise Control 是 LinkedIn 开源的 Kafka 自动运维利器。
能力:
- 检测异常:goal violation(如 broker CPU 不均衡、磁盘倾斜)。
- 自动均衡:生成 + 执行 reassignment 计划,带限速。
- 故障自愈:broker 挂了自动迁移 partition。
- 监控指标:Anomaly Detector + REST API。
部署架构:
arduino
Cruise Control Server
├── Metric Sampler(采集 broker JMX)
├── Goal Optimizer(多目标优化算法)
└── Executor(执行 reassignment)
↓
Kafka Cluster典型 goal:
RackAwareGoal- 副本跨机架分布ReplicaCapacityGoal- 单 broker 副本数上限DiskCapacityGoal- 磁盘水位NetworkInboundCapacityGoal- 入网带宽LeaderReplicaDistributionGoal- Leader 数量均衡
实战经验:
- 不要把所有 goal 都打开,按业务优先级选 5~7 个;
- 限速默认很激进(10MB/s),生产建议提到 50~100MB/s;
- 先用 dry-run 模式跑一周观察推荐再开自动执行;
- 监控 Cruise Control 自身的
anomalies接口。
10.9 备份与灾备
10.9.1 数据备份方案
| 方案 | 描述 | 适用 |
|---|---|---|
| 多副本 | 3 副本是基础保障 | 必备,应对单点故障 |
| MirrorMaker 2 | 跨集群异步复制 | 灾备机房 |
| Tiered Storage(KIP-405) | 冷数据下沉 S3 | 长期归档 |
| 数据湖双写 | 同时写 Kafka + Iceberg/Hudi | 数据可回放 |
10.9.2 配置与元数据备份
bash
# 备份所有 topic 配置
kafka-topics.sh --bootstrap-server $BS --describe > topics-backup.txt
# 备份所有 ACL
kafka-acls.sh --bootstrap-server $BS --list > acls-backup.txt
# 备份所有 quota
kafka-configs.sh --bootstrap-server $BS --describe \
--entity-type users --entity-default > quotas-backup.txt
# KRaft 模式:snapshot 自动持久化在 metadata log,无需手动备份10.10 高频追问
Q:UnderReplicatedPartitions = 0,但 ISR 持续抖动怎么排查?
A:看 IsrShrinksPerSec 与 IsrExpandsPerSec:
- 同时升高 → 副本反复进出 ISR(replica.lag.time.max.ms 设小了 / GC 抖 / 网络丢包)。
- 只升 Shrink → Follower 落后越来越多(broker 负载过高)。
- 工具:
kafka-leader-election.sh临时强制 prefer leader 选举,结合kafka-log-dirs.sh看磁盘倾斜。
Q:发现某 partition Lag 不下降,offset 也不前进?
A:可能场景:
- Consumer 进程挂了但 Group 没及时变化 →
kafka-consumer-groups.sh --describe看 LAG / CONSUMER-ID 是否为-。 - Consumer 卡在某条消息 → 看消费者 thread dump,常见 DB / Redis 阻塞。
- Poison message:单条消息反复抛异常 + 自动重试无限循环 → 写入 DLQ + skip。
Q:滚动升级时,业务侧 Producer/Consumer 会断连吗?
A:理论上不会。客户端有 metadata refresh + retry 机制,broker 短暂下线时客户端会自动重连其他 broker。但实际有几个坑:
request.timeout.ms设太短(< 30s)→ 升级期间个别请求超时。delivery.timeout.ms设太短(< 60s)→ batch 直接 expire 丢消息。- 老版本(< 2.8)滚动升级时 controller 切换可能有几秒抖动。 最佳实践 :升级前一周临时把
delivery.timeout.ms提到 5 分钟。
Q:你们 Kafka 集群 SLA 怎么定的?
A:参考标准:
- 可用性:99.95% / 99.99%(金融)
- 数据持久性:99.9999%(六个 9)
- 写入 P99 延迟:< 100ms
- Consumer Lag:< 10s(核心 Topic)/ < 5min(离线日志)
- 故障恢复 RTO :< 5min;RPO:< 1min
11. Kafka 与同类 MQ 对比
本章定位 :选型题、设计题最常被追问。要能讲清楚"为什么这个场景选 Kafka 而不是 RocketMQ"。
11.1 全景对比
| 维度 | Kafka | RocketMQ | RabbitMQ | Pulsar |
|---|---|---|---|---|
| 核心模型 | 分区日志(Partitioned Log) | 主题 + 队列 + CommitLog | Exchange / Queue / Binding | 分层(Broker + BookKeeper) |
| 存储 | 多文件(每分区一目录) | 单 CommitLog + 多 ConsumeQueue 索引 | 内存 + 磁盘混合 | BookKeeper Ledger |
| 吞吐 | 极高(百万级 QPS) | 高(10w~50w QPS) | 中(万级) | 高(百万级) |
| 延迟 | ms 级 | ms 级 | μs 级(小消息) | ms 级 |
| 顺序 | 分区内有序(hash key) | 队列内有序(messageQueueSelector) | 单队列有序(FIFO) | 分区内 / Key 有序 |
| 事务 | 2PC + Control Records | 半消息 + 回查 | 弱(Channel 层 commit) | 2PC |
| 延迟消息 | ❌ 不原生(要业务自实现) | ✅ 18 个固定级 / 5.0 任意精度 | ✅ 插件 / TTL+DLX | ✅ 原生秒级 |
| 死信队列 | ❌ 业务自实现 | ✅ 原生(%DLQ%xxx) | ✅ 原生 DLX | ✅ 原生 |
| 消息回溯 | ✅ 强(offset reset) | ✅ 支持(按时间) | ❌ 弱(消息消费即删) | ✅ 强 |
| 重试机制 | ❌ 业务自实现 | ✅ 16 级阶梯重试 | 一般 | 一般 |
| 广播 / 集群消费 | 集群(Group) | 集群 + 广播双模式 | Topic / Direct / Fanout | Exclusive/Shared/Failover/KeyShared |
| 多租户 | 弱(仅 Quota) | 弱 | 一般 | 强(Tenant/Namespace/Topic 三层) |
| 存算分离 | 否(Tiered Storage 分层但不分离) | 否 | 否 | 是 |
| 协议 | 自研二进制 | 自研(兼容 Java/Push/Pull) | AMQP 0.9.1 / STOMP / MQTT | 自研 + 兼容 Kafka |
| 生态 | 极强(Connect、Streams、Schema Registry、Flink、Spark、Iceberg) | 阿里系 + 业务消息生态 | 中(运维成熟) | 一般(成长中) |
| 运维复杂度 | 中 | 中 | 低 | 高(Broker + BookKeeper + ZK) |
| 典型用法 | 日志、大数据、流处理 | 订单、交易、业务消息 | 低吞吐高可靠业务 | 多租户、跨地域 SaaS |
11.2 Kafka vs RocketMQ(最高频对比)
11.2.1 存储模型对比(关键差异)
| 特性 | Kafka | RocketMQ |
|---|---|---|
| 写入磁盘模式 | 每分区独立文件,多文件并行顺序写 | 单 CommitLog 全局顺序写 |
| Topic 数量上限 | 受单 broker 文件句柄限制(数千 Partition) | 支持数万 Topic(CommitLog 共享) |
| 单分区读取 | 直接读分区文件,sendfile 零拷贝 | 通过 ConsumeQueue 索引到 CommitLog 偏移,多一次随机读 |
| 顺序写优势 | 多文件聚合可能成随机写(高 Topic 数时) | 一个文件,永远顺序写 |
结论:
- 少 Topic 高吞吐(< 1000 Topic):Kafka 更快。
- 多 Topic(万级)业务消息:RocketMQ 单 CommitLog 设计更优。
11.2.2 顺序消息对比
| 维度 | Kafka | RocketMQ |
|---|---|---|
| API 易用性 | 用 key 哈希到分区,需理解 Partitioner | MessageQueueSelector 显式指定 Queue |
| 严格顺序 | 单分区单 Consumer,max.in.flight=1(或幂等≤5) | 单 Queue 顺序消费,自动加锁保证 |
| 顺序消费失败 | 业务自处理(重试/暂停) | 自动暂停 + 重试 16 次 + 进 DLQ |
| 顺序消费的 Rebalance 影响 | 重新分配后短暂乱序 | 锁机制保证不乱序 |
顺序场景下 RocketMQ 更省心,Kafka 需要业务方自实现严格顺序保证。
11.2.3 事务消息对比
| 维度 | Kafka | RocketMQ |
|---|---|---|
| 协议 | 真正的 2PC(Coordinator + Markers) | 半消息 + 反查(单阶段 + 异步检查) |
| 业务侵入 | 用 transactional.id 包装代码 |
实现 TransactionListener 接口 |
| 超时回查 | TC 超时 abort | 业务回调 checkLocalTransaction |
| 跨集群事务 | ❌ 不支持 | ❌ 不支持 |
| 典型场景 | Flink Sink 端到端 EOS | 订单创建 + 业务表写入原子性 |
RocketMQ 半消息流程 (面试要会画):
sql
1. Producer 发送 半消息(Half Message)→ Broker 存储但不投递
2. Producer 执行本地事务(DB update)
3. Producer 提交 Commit / Rollback
├─ Commit → Broker 让消息可见
└─ Rollback → Broker 删除半消息
4. 如果 Producer 没确认 → Broker 主动回查 Producer 的状态
→ checkLocalTransaction() → COMMIT / ROLLBACK / UNKNOWN11.2.4 延迟消息对比
| 维度 | Kafka | RocketMQ |
|---|---|---|
| 原生支持 | ❌ | ✅ |
| 精度 | 业务自实现,分桶或时间轮 | 4.x:18 个固定级(1s/5s/10s/...);5.0+:任意精度 |
| 实现 | 多 Topic 分桶 / 自研时间轮服务 | 内置时间轮 + 18 个 SCHEDULE_TOPIC_xxxx |
| 业务复杂度 | 高 | 低 |
结论:业务延迟消息一定选 RocketMQ。
11.2.5 选型决策矩阵
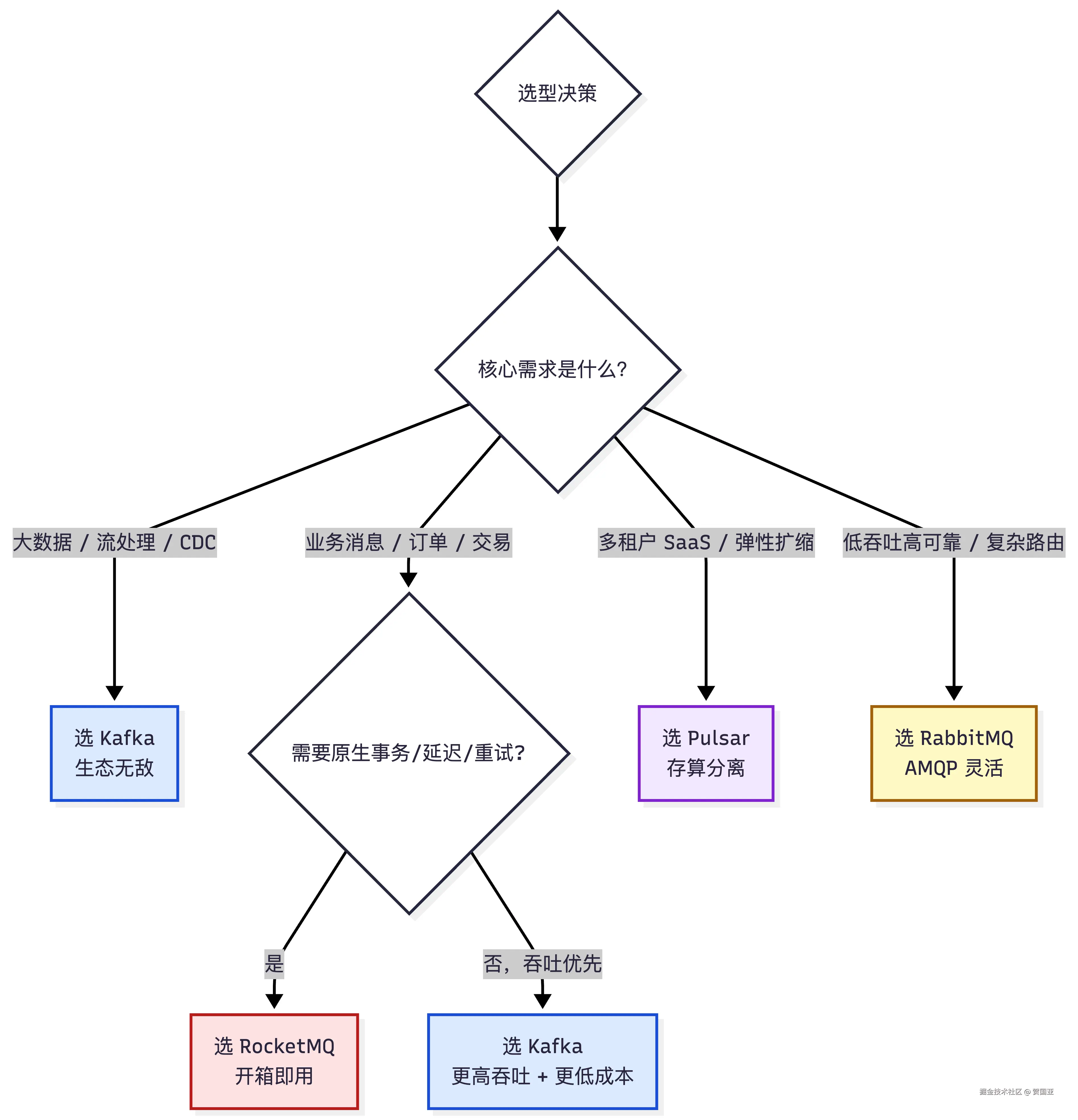
11.3 Kafka vs RabbitMQ
11.3.1 模型差异
| 维度 | RabbitMQ | Kafka |
|---|---|---|
| 路由模型 | Exchange + Binding 灵活路由 | Partition 哈希(key) |
| 消息删除 | 消费成功即删 | 按时间 / 大小保留 |
| 消息回溯 | ❌(消费即删) | ✅ 支持 |
| 吞吐量 | 万级 | 百万级 |
| 延迟 | μs 级(小消息) | ms 级 |
| 协议 | AMQP / STOMP / MQTT | 自研二进制 |
| 典型场景 | 银行间、低吞吐金融、复杂路由 | 大数据、日志、流处理 |
11.3.2 何时还会选 RabbitMQ?
- 复杂路由:headers exchange、按多 header 字段灵活分发;
- 低吞吐高一致性:传统业务异步、< 万级 QPS;
- 协议要求:与 STOMP / MQTT 互通;
- 小消息低延迟:μs 级延迟(金融报价转发)。
11.4 Kafka vs Pulsar
详细架构对比见 Ch17.6,这里给精简版选型。
| 何时选 Pulsar | 何时坚守 Kafka |
|---|---|
| 需要超大 Topic 数(10w~100w) | 大数据生态主导(Flink/Spark/Iceberg) |
| 多租户 SaaS(强隔离) | 团队对 Kafka 经验丰富 |
| 真正的存算分离 / 弹性扩缩 | 简单运维需求 |
| 异地多活、跨地域复制 | 日均 PB 级流处理 |
| 需要 Function Mesh 一站式 | 运维资源有限(Pulsar 三组件复杂) |
11.5 业内厂商选型实例
| 公司 | 主流选型 | 原因 |
|---|---|---|
| Kafka(自研 + 主导社区) | 大数据日志主场景 | |
| Uber | Kafka + Pulsar 混合 | Kafka 流处理,Pulsar 多租户业务 |
| 腾讯 | Kafka + Pulsar + TDMQ | 业务多样,按场景选 |
| 阿里 | RocketMQ(自研主推) | 业务消息为主,RocketMQ 体感更佳 |
| 字节 | Kafka 为主 + RocketMQ 业务侧 | 大数据 Kafka,订单/抖音电商 RocketMQ |
| 美团 | Mafka(Kafka 自研版) | 兼容 Kafka 协议 |
| 滴滴 | DDMQ(基于 RocketMQ + Kafka 自研) | 业务隔离 + 流处理双需求 |
| B站 | RocketMQ + Kafka | 弹幕用 RocketMQ,日志/视频流用 Kafka |
| Netflix | Kafka + Keystone | 大数据流处理 |
| PayPal | Kafka 主流 + 部分场景 RabbitMQ | 金融可靠性 |
11.6 高频追问
Q:为什么阿里自研 RocketMQ 不直接用 Kafka?
A:Kafka 0.8 时代分区数超千就严重退化,RocketMQ(基于 Notify/MetaQ 演进)面向阿里百万级 Topic + 万级 IO 队列 + 业务消息场景设计:
- 单 CommitLog 解决多 Topic 写放大;
- 内置事务消息、延迟消息、重试机制(业务直接用,省去自研);
- 主从同步 + 选主独立设计,避免 ZK 依赖(早期 Kafka 强依赖 ZK);
- 双写双活 / NameServer 简化部署。
Q:Kafka 没有原生延迟消息怎么办?
A:方案优先级:
- 业务允许延迟近似:多 Topic 分桶(5s/30s/5m/30m/1h)+ 桶级消费 + sleep 到时刻 → 重投目标 Topic(精度低但简单)。
- 业务要求高精度:自研 KafkaDelayService → 消费 delay-topic → 写本地时间轮 → 到点重投目标 Topic(参考 Ch16.1 时间轮实现)。
- 能换技术栈:直接用 RocketMQ 5.0 任意精度延迟消息。
- 混合架构:业务消息走 RocketMQ,大数据流走 Kafka。
Q:消息精确一次(EOS)每个 MQ 怎么实现?
A:
| MQ | EOS 实现 |
|---|---|
| Kafka | Producer 幂等 + 事务 + Consumer read_committed + Flink 2PC Sink |
| RocketMQ | 不支持严格 EOS,但事务消息 + 业务幂等可达成 |
| RabbitMQ | 不支持 |
| Pulsar | 类似 Kafka 的事务模型 |
Q:消息中间件的"丢消息"和"重复消费",本质是哪些参数决定的?
A:以 Kafka 为例(其他 MQ 类比):
- 丢 :
acks/min.insync.replicas/unclean.leader.election/ Consumer 提交时机; - 重:Producer 重试 + 是否启用幂等 / Consumer 处理后才提交。
金句 :所有 MQ 的底层语义都是 "at-least-once + 业务幂等 = exactly-once"。
Q:你们公司为什么选 X 而不是 Y?(自我介绍中常被问)
A:模板:
- 业务匹配度:举一个具体业务场景说明 X 比 Y 更适合;
- 生态成熟度:举团队工具链的依赖;
- 历史包袱:诚实说"团队已熟悉 X";
- 未来演进:能讲对 Y 的认知,不是不懂只是不选。
面试金句:
"Kafka 是为吞吐而生,RocketMQ 是为业务消息而生,RabbitMQ 是为路由而生,Pulsar 是为多租户而生。订单履约用 RocketMQ 更省心;用户行为日志、CDC、Flink 流计算上游一定选 Kafka;银行间路由复杂用 RabbitMQ;SaaS 多租户用 Pulsar。"
12. 真实故障案例复盘(强烈建议背熟)
这是面试官最爱听的部分,建议每条都准备成 STAR(Situation-Task-Action-Result)讲法。
案例 1:消费积压百万,业务大盘 5 分钟数据延迟 1 小时
- 现象 :监控告警
records-lag-max飙升到 200w,业务大盘指标不更新。 - 排查 :
- 看消费者机器负载,CPU/内存正常。
- 看消费者日志,发现频繁
CommitFailedException+ Rebalance。 - 进一步发现
max.poll.interval.ms默认 5 分钟,业务在 poll 后做了一次大批量 DB 写入,超时被踢出 Group。
- 解决 :
- 临时:调大
max.poll.interval.ms到 10 分钟;调小max.poll.records到 100,先止血。 - 长期:把消息处理改造为拉取线程 + 业务线程池模式,poll 线程只负责拉,业务线程池并行处理;引入手动提交 + 内存中按 partition 维护 offset 提交策略(避免乱序提交)。
- 顺手把分配策略从 RangeAssignor 改成 CooperativeStickyAssignor,减少 rebalance 影响。
- 临时:调大
- 结果:积压 30 分钟内消化完,rebalance 次数从每天 50+ 降到 1 以内。
案例 2:Producer 发送毛刺,P99 从 20ms 飙到 2s
- 现象:每天某几个时段 Producer P99 飙升,下游 RT 抖动。
- 排查 :
- Broker 端
RequestQueueTimeMsP99 抖动同步飙高。 - 进一步看
LogFlushRateAndTimeMs抖动 → 怀疑磁盘 IO。 - iostat 看磁盘
await在抖动时段 > 1s,定位到同机的日志清理任务 和 Topic compact 任务叠加触发。
- Broker 端
- 解决 :
- 把 compact 类 Topic 单独迁到独立 Broker。
- 调整
log.cleaner.threads与log.cleaner.io.max.bytes.per.second限速。 - OS 层面
vm.dirty_background_ratio从默认 10 调到 5,让脏页提前后台刷,避免突发集中刷盘。
- 结果:P99 稳定在 30ms 内。
案例 3:消息丢失(ISR=1 时挂掉了)
- 现象:财务对账发现 30 条订单消息丢失。
- 排查 :
- Broker 日志显示前一晚 broker-2 宕机,broker-3 之前因 GC 超长被踢出 ISR。
- 此时 ISR 只剩 broker-1(Leader),且
min.insync.replicas=1,broker-1 写入返回 ack=all 仍认为成功。 - broker-1 也短时间宕机后,未同步到的消息永久丢失。
- 解决 :
min.insync.replicas从 1 改成 2,ISR 不足时 Producer 拒绝写入(业务侧降级到 fallback)。- 副本数从 2 提到 3。
- 监控
UnderReplicatedPartitions的告警阈值从 5 分钟降到 1 分钟。 - 关闭
unclean.leader.election.enable。
- 结果:之后再无丢失,可用性下降 < 万分之一。
案例 4:Rebalance 风暴
- 现象:消费组 200+ 实例,每天发生几十次全员 Rebalance,每次中断 30s+。
- 排查 :
- 部分实例 GC 超 session timeout → 心跳超时被剔除 → Rebalance;
- 老的 Eager 协议下一个掉队就全员 STW。
- 解决 :
- 升级到 Cooperative Sticky Assignor。
- 调小
heartbeat.interval.ms(3s)+ 调大session.timeout.ms(30s)。 - JVM 调优解决 GC 抖动。
- 配置
group.instance.id(Static Membership),实例重启不触发 rebalance。
- 结果:日均 rebalance 从 50+ 降到 < 5。
案例 5:Lag 监控失真
- 现象:Burrow 显示 Lag = 0,但下游用户反映数据延迟 30 分钟。
- 排查 :业务消费者只 commit 了 offset 没真正处理(先提交后处理的反模式),Lag 自然为 0。
- 解决:先处理后提交;同时在业务侧增加端到端时延埋点(消息时间戳 vs 业务落地时间),不依赖 Lag 一个指标。
案例 6:跨机房同步延迟(MirrorMaker 2)
- 现象:MM2 同步上海→北京延迟 10 分钟。
- 排查:MM2 任务并发不够 + 跨机房 RTT 高 + acks=all 导致 RT 放大。
- 解决 :
- 增加 MM2 task 数量到 = 源 Topic Partition 数。
- Producer 端
compression.type=zstd节省带宽 50%+。 - 关键 Topic 升级专线。
- Lag 报警分级:核心 Topic 30s,离线日志 5min。
12.7 按公司风格分组复盘(必背)
不同公司喜欢的故障案例方向有明显倾向,针对性背 1~2 个比泛泛而谈 6 个更高效。
| 公司风格 | 偏好案例 | 主要追问点 |
|---|---|---|
| 🟦 字节 | 案例 2(Producer 毛刺)、案例 4(Rebalance 风暴) | "怎么定位是 GC / 磁盘 / 网络 / 锁?""有没有用 async-profiler?" |
| 🟧 阿里 | 案例 1(消费积压)、案例 4(Rebalance 风暴) | "你们 SLA 怎么定的?""故障演练如何?""降级方案?" |
| 🟪 蚂蚁 | 案例 3(消息丢失)、案例 5(Lag 失真) | "资损口径?""对账机制?""跨单元如何兜底?" |
| 🟢 腾讯 | 案例 6(MM2 跨机房)、案例 1(积压) | "百亿级 QPS 怎么撑?""带宽磁盘哪个先到顶?""成本优化空间?" |
| 🟡 美团/快手 | 案例 4(Rebalance)、案例 5(Lag 失真) | "外卖履约延迟?""实时计算反压?""灰度发布隔离?" |
12.8 讲故障案例的"金牌口诀"
yaml
S - Situation: 数据规模 + 业务影响 + 时间窗口
T - Trigger: 告警是什么 / 谁先发现的
A - Approach: 排查路径(不是直接抛结论,要展示方法论)
R - Resolution: 临时止血 + 长期根治分两步
M - Metrics: 具体数字(多少分钟修复 / 提升多少 / 节省多少)
P - Prevention: 复盘 + 监控加强 + 流程改进SatRMP 一气呵成,比"我修了一个 bug"高 10 个段位。
例如案例 1 升级版讲法:
"S :我们订单消费组日均处理 5 亿消息、200+ 实例。某个周二上午 9 点,T :告警
records-lag-max飙到 200 万,业务大盘指标 5 分钟数据延迟到 1 小时。A :先看消费者 CPU/内存正常排除资源瓶颈;看消费日志发现CommitFailedException频繁;继续查发现max.poll.interval.ms超时被 LeaveGroup → 触发 Rebalance → 处理被打断 → 进一步堆积。R :临时把max.poll.interval.ms从 5min 调到 10min +max.poll.records从 500 降到 100 先止血;30 分钟内消化完积压。长期把消息处理改造为'拉取线程 + 业务线程池'模式,引入 CooperativeStickyAssignor。M :积压消化时间从 1h+ → 30min;日均 Rebalance 从 50+ 降到 < 5;消费 P99 从 8s 降到 800ms。P :补充NumGroupsPreparingRebalance监控;推动其他 200+ Group 平滑迁移到新模式;写了内部规范《Consumer 处理慢消息的 5 种正确姿势》。"
🧭 章节导航
⬅️ 上一模块:01-基础与原理.md | ➡️ 下一模块:03-设计与编码.md
| 模块 | 文件 |
|---|---|
| 🔵 模块一·基础原理 | 01-基础与原理.md |
| 🟢 模块二·调优运维(当前) | 02-调优与运维.md |
| 🟡 模块三·设计编码 | 03-设计与编码.md |
| 🔴 模块四·源码 OS | 04-源码与OS底层.md |
| 🟣 模块五·分布式理论 | 05-分布式理论与大厂设计.md |
| 📎 附录 | 99-附录.md |