早上刷到马斯克xAI解散并入SpaceX的新闻,又看到他跟Anthropic搞合作了。AI圈一天没消停过。
但说实话,大厂的AI新闻离我太远。我今天想聊的,是一个我每天都在用的Prompt方案------处理香港那些中英混杂的文件。

一、先说说我为什么要写这个
来香港做FinTech第二年,最让我烦的不是代码,是文件。
MPF的英文条款、公司的中英混排合同、客户发来的繁体PDF合同......每份文件都得看两遍:一遍看内容,一遍看术语。
我试过各种工具。有些翻译完了把MPF(强积金)翻成"中央公积金"------虽然意思相近,但在香港语境下完全是两回事。
后来花了大概两周时间,反复调了一套Prompt出来,现在90%的文件丢进去直接出结果。
今天把方案摊开讲,应该能帮到有同样困扰的人。
二、核心思路
先说我踩过的坑。
一开始我直接写"请帮我翻译这份香港文件",结果Claude给出的译文很工整,但术语全废了。
比如"Mandatory Provident Fund"它翻译成"强制性公积金基金"------谁在香港工作都懂,正确的说法就是"MPF"或"强积金"。
后来我意识到,问题不是Claude能不能翻译,而是它不知道香港的语境。
所以我的Prompt做了三件事:
- 告诉它香港场景 ------ 不只是"翻译",是"处理香港职场文件"
- 给出术语规则 ------ 哪些保留英文,哪些用香港本地说法
- 控制输出格式 ------ 加术语对照表,方便我二次确认
三、完整代码实现
依赖
python
pip install anthropic python-dotenvPrompt模板
python
HONG_KONG_DOC_PROMPT = """你是一位熟悉香港职场环境的文件处理专家。
请按以下规则处理这份文件:
### 一、术语处理规则
1. 英文专业术语首次出现时保留原文,括号内标注简体中文
- 例:"MPF(强积金)" → 不要写"强制性公积金"
- 例:"IRD(税务局)" → 不要写"国内收入署"
2. 粤语口语表达 → 翻译为内地普通话对应说法
- 例:"听日交" → "明天提交"
3. 香港特有机构名 → 保留原文+中文名
- 例:"Hong Kong Monetary Authority(香港金融管理局)"
### 二、格式规则
1. 保持原文的表格结构和层级
2. 保持编号和项目符号
3. 输出正文 + 文档末尾附加术语对照表
### 三、输出格式
---
【译文正文】
(翻译后的内容)
---
【术语对照表】
| 原文 | 译文 | 说明 |
| --- | --- | --- |
| MPF | 强积金 | 香港强制性退休储蓄计划 |
| IRD | 税务局 | 香港税务局 |
待处理文件:
{document_content}"""
def process_hk_document(content: str, client) -> str:
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
messages=[{
"role": "user",
"content": HONG_KONG_DOC_PROMPT.format(
document_content=content
)
}]
)
return response.content[0].text批量处理脚本
python
import os
from pathlib import Path
from anthropic import Anthropic
client = Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
def batch_process(input_dir: str, output_dir: str):
input_path = Path(input_dir)
output_path = Path(output_dir)
output_path.mkdir(parents=True, exist_ok=True)
for file in input_path.glob("*.txt"):
content = file.read_text(encoding="utf-8")
result = process_hk_document(content, client)
output_file = output_path / f"{file.stem}_processed.md"
output_file.write_text(result, encoding="utf-8")
print(f"✅ 已处理:{file.name}")
if __name__ == "__main__":
batch_process("./input_docs", "./output_docs")四、实际效果对比
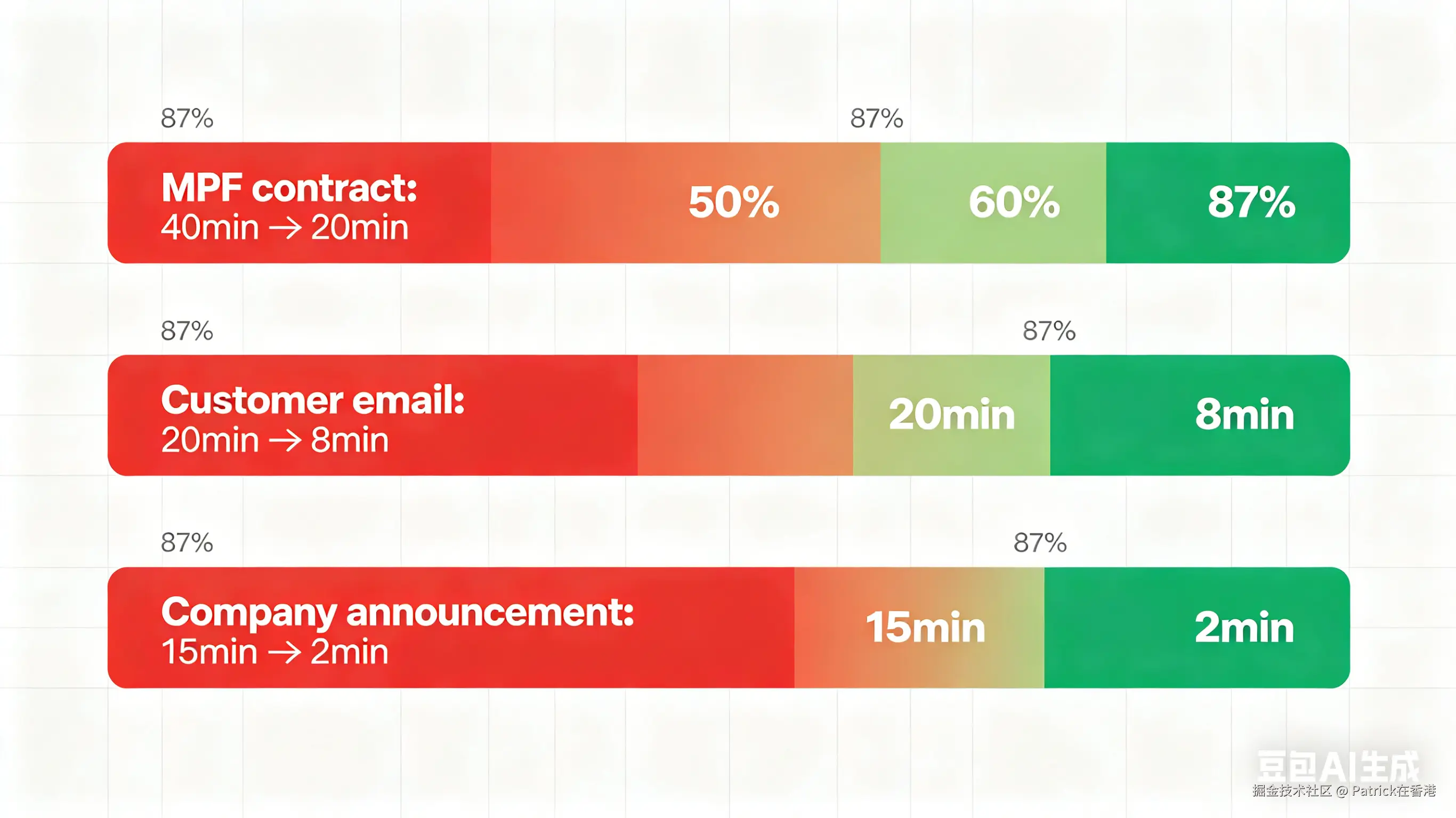
我拿三份不同类型的文件测了一下:
| 文件类型 | 处理前(人工) | 处理后(AI+Prompt) | 时间对比 |
|---|---|---|---|
| MPF合同(5页英文) | 约40分钟逐段翻译+查术语 | 5分钟AI出稿+15分钟复核 | 40min → 20min |
| 客户邮件(中英混排) | 20分钟理解+回复 | 3分钟AI整理+5分钟调整语气 | 20min → 8min |
| 公司内部通告(繁体) | 15分钟逐句改简体 | 2分钟自动转换 | 15min → 2min |
最明显的变化不是"快了多少倍",是我不用再花精力在"识别术语"这件事上。
五、踩坑记录
坑1:提示词太长被截断
一开始我把所有规则都塞到system prompt里,结果处理长文档经常被截断。
解决:把规则压缩到核心的3大类,不太重要的放user message里。
坑2:表格格式翻车
Claude输出的markdown表格有时候不对齐,导不到Notion里。
解决:加了"无嵌套表格"的要求,并且每次检查术语表格式。
坑3:粤语口语识别不稳定
"听日""俾我"这些词有时候能翻对,有时候直接保留原文。
解决:目前还没完全解决,我的做法是过一遍+手动标记,顺便积累了一个"粤语高频词库"辅助判断。
六、这玩意儿还能怎么用?
这套方案不只用于文件处理。稍微改改Prompt就能:
- 会议纪要:Whisper转录 → Claude结构化 → 中英双语版
- 合同审查:给Prompt加上"标注风险条款"的要求
- 客户邮件:Prompt加上"用更礼貌的商务语气重写"
本质上是在做一件事:把香港职场特有的"信息处理成本"降下来。
你现在在处理什么香港的文件?有没有遇到什么奇葩术语或者格式问题?评论区说说,我看看能不能优化一下Prompt帮你搞定。
#Claude #Prompt工程 #香港职场 #AI工具 #Python #金融科技