Http协议报头
-
请求报文报头
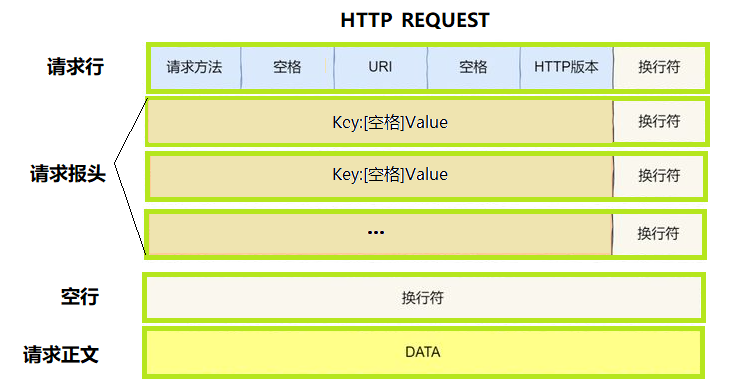

- 请求方法:如GET,POST等,且在代码编写过程中不区分大小写
- 空格:用于分割,控制报头各属性格式
- URI:即请求的资源路径,如/index.html,使用/作为路径时,通常建议返回/index.html,其余路径查找失败时可能会由浏览器返回404错误
- HTTP版本:如HTTP/1.1等
- 换行符:用于分割HTTP报头的各行信息
- 请求报头headers:由
key: value\r\n格式的键值对构成,key包括Host,Connection等字段,后续会对部分字段进行详细介绍 - 空行:用于分割报头与报文
- 请求正文:即HTTP报文的正文部分
- 请求方法:如GET,POST等,且在代码编写过程中不区分大小写
-
响应报文报头


- HTTP版本:如HTTP/1.1等,需要严格正确填写,因为不同版本之间可能会有不同的支持,也可能存在兼容性问题
- 空格:用于分割,控制报头各属性格式
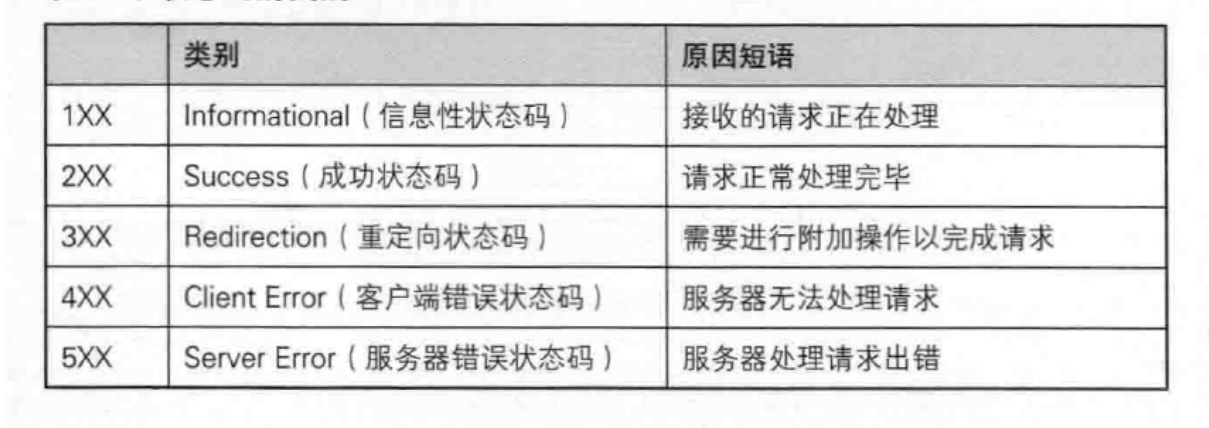
- 状态码:如200,404,500等,具体含义见下表
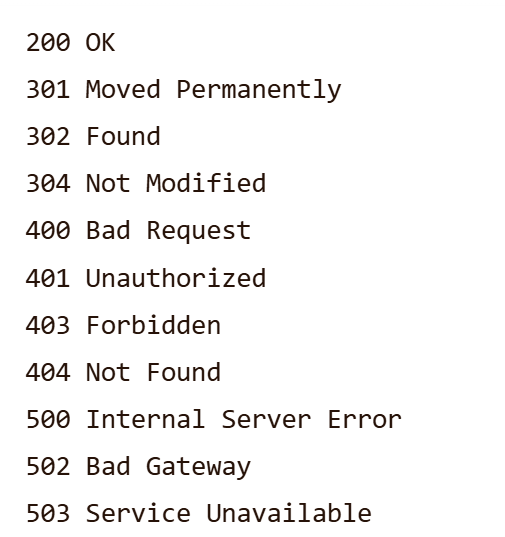
- 状态码描述:即描述状态码的含义,
需要注意,该字段不会被浏览器等解析,仅用于用户查看,常见设置如下(无官方标准,允许自定义,以下仅为参考):
- 响应报头headers:由
key: value\r\n格式的键值对构成,key包括Host,Connection等字段,后续会对部分字段进行详细介绍(注:Cookie也属于该字段,本身其实也可以看作是key: value结构) - 换行符:用于分割HTTP报头的各行信息
- DATA:报文正文部分(
对于非html正文,推荐使用json格式构建报文)
URI(URI可能也会被称作URL,但最精确说法其实是URI,URL是URI的子集)

即人们常说的"网址",具体构成如上图,也可直接简化为服务器域名:端口号或服务器ip:端口号在浏览器中进行访问,当端口号后不加文件路径时,请求报文中的路径会被设置为/目录,而对于/目录,常建议响应web根目录的index.html文件,否则/path则会以web目录为根目录进行数据请求,以下wwwroot即为设置的web根目录,目录结构也如下:
注:对于请求报文中路径的任何操作,都是由应用层(用户)自定义的,web根目录等叫法也只是规范建议,实际访问/filename,就算返回.../.../.../.../的文件都是合法的
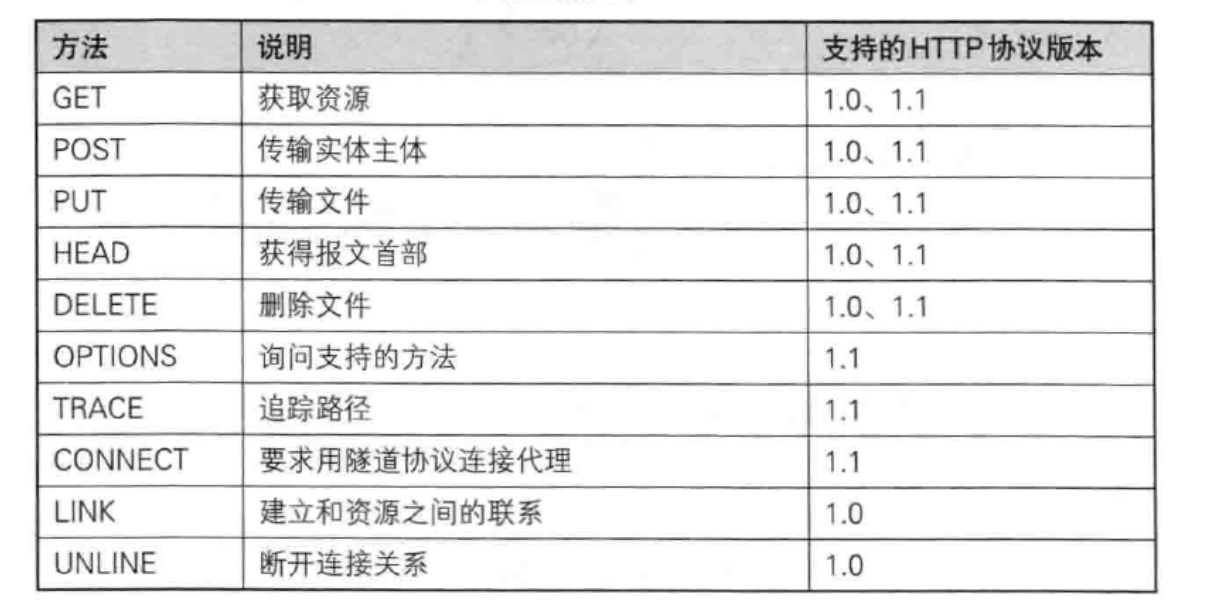
请求报文字段------请求方法(HTTP不对请求方法区分大小写,但建议使用全大写)
-
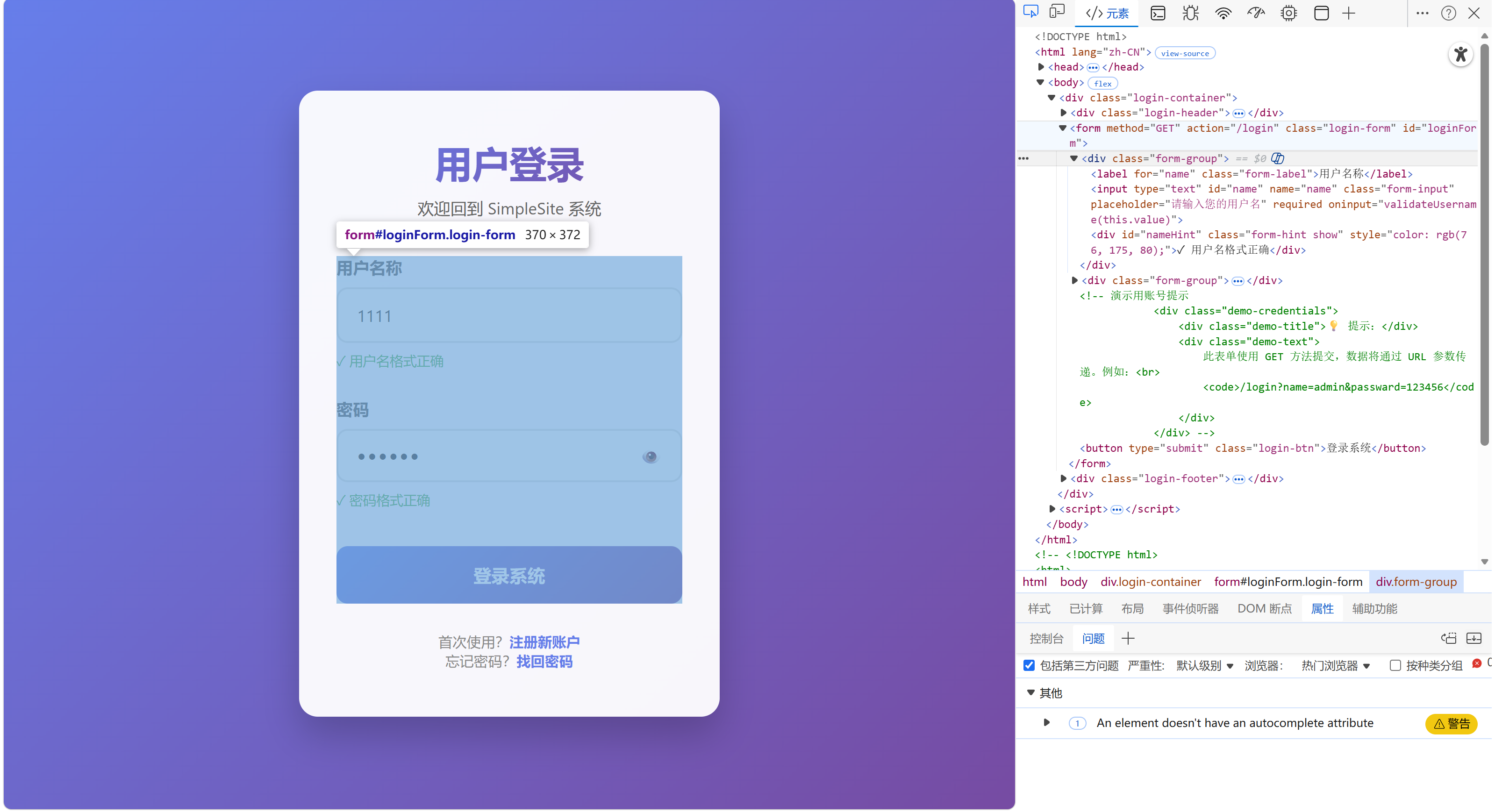
GET(重点):表示请求资源,该类型的请求报文一般不具备正文,且当html中使用GET获取资源时,会将资源添加到请求报文的URI中,如下图:

-
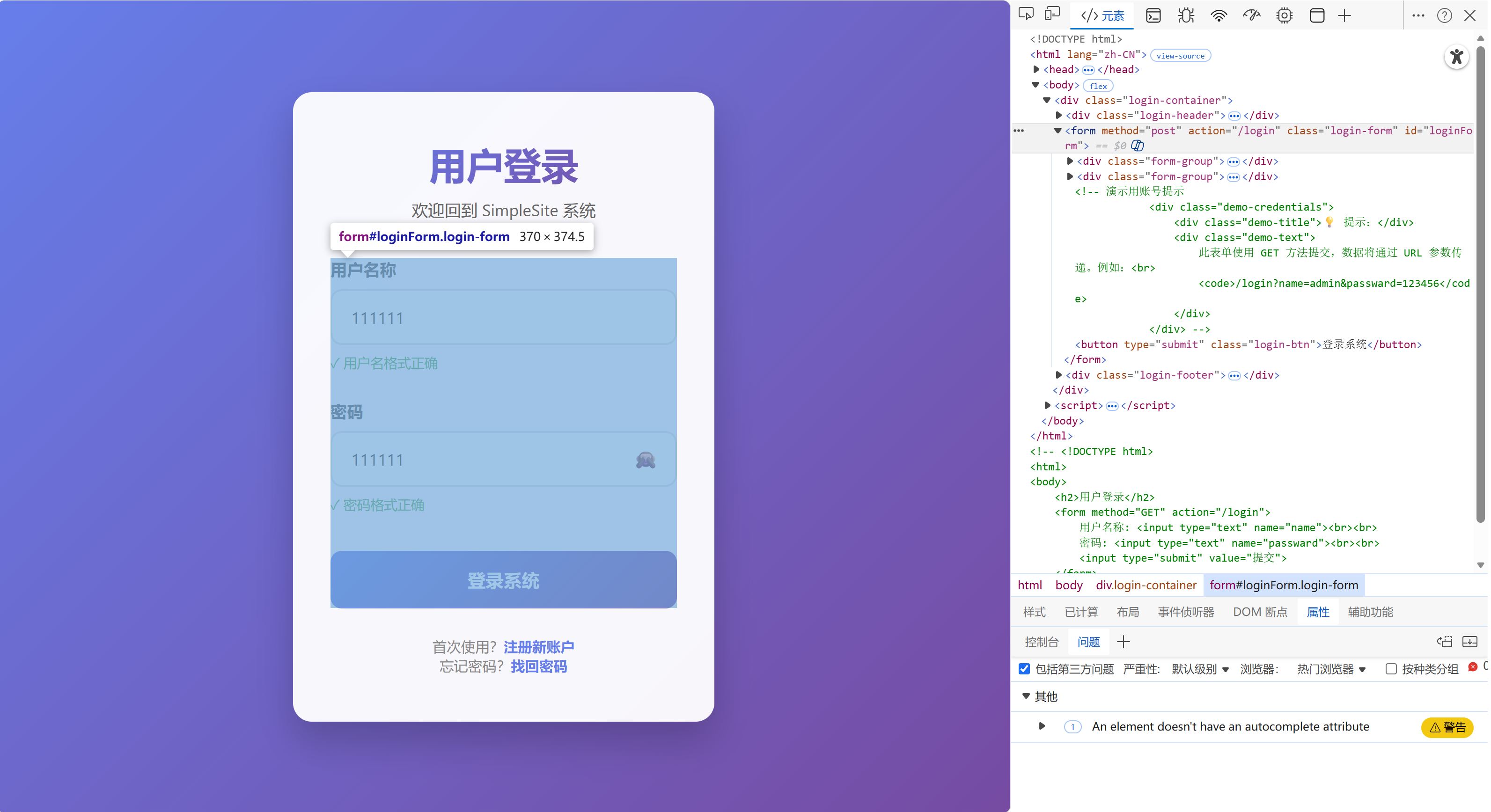
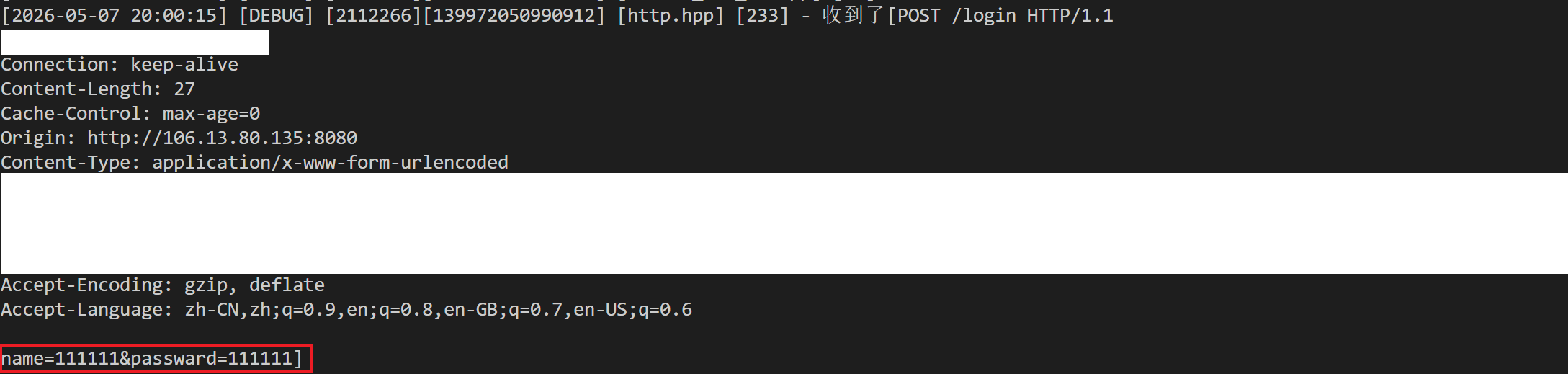
POST(重点):表示提交资源,该类型的请求报文一般有正文,且当html中使用POST提交资源时,会将资源添加到请求报文的正文部分,如下图:
-
PUT(不常用):用于客户端向服务端传输文件,将请求报文主体中的文件保存到请求URL指定位置,示例如PUT /example.html HTTP/1.1 + 正文,表示将请求报文正文保存到/example.html文件中,需要注意的是,该方法常被浏览器禁用,以避免客户端对服务端的恶意攻击
-
HEAD:与GET类似,但使用该方法得到的响应报文,不会包含正文(类似GET得到的响应报文 + 删除正文部分),常用于检验服务器能否正常工作
-
DELETE(不常用):与PUT相反,该请求用于删除URI路径中的文件,因此该方法常被浏览器禁用,以避免客户端对服务端的恶意攻击
-
OPTIONS(不常用):将服务器支持的请求方法以header的Allow字段返回,如:
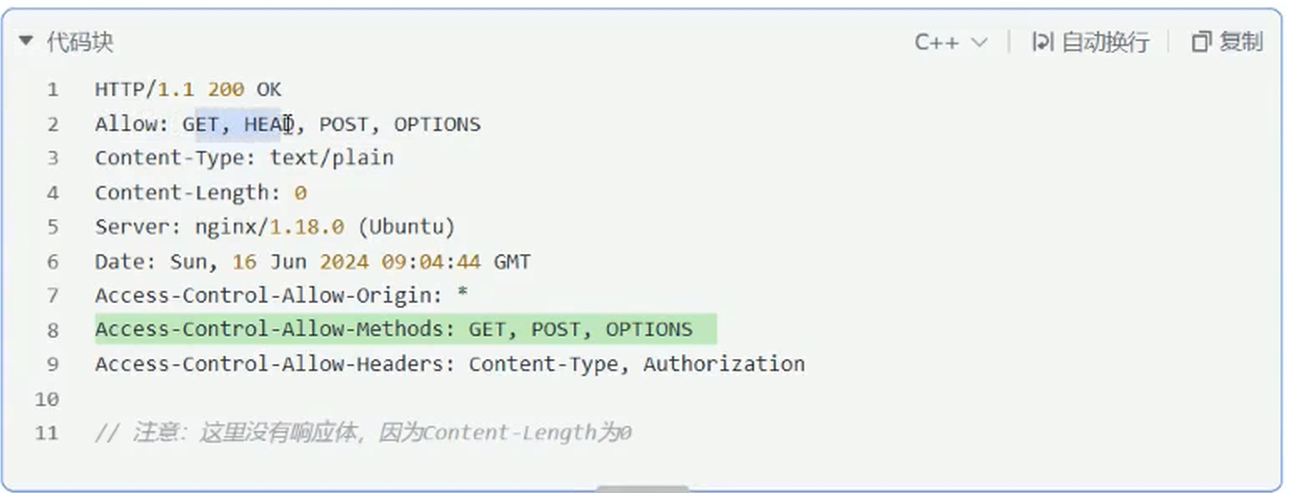
但为避免浏览器对服务端的恶意攻击,该方法常被禁用
-
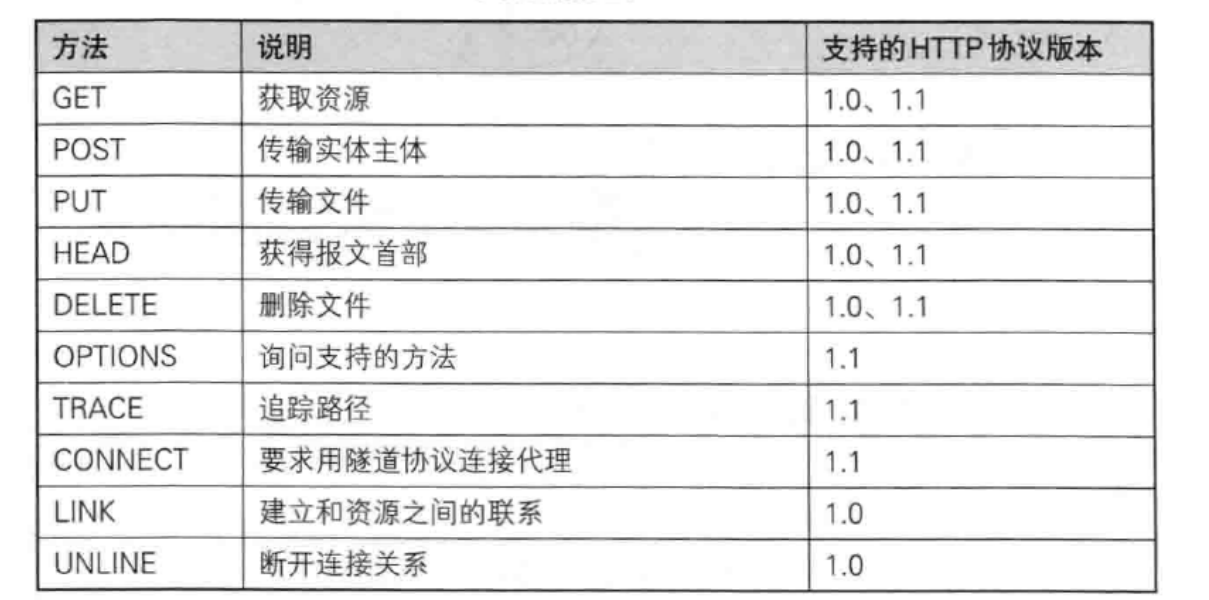
表格总结与其他:
响应报文字段------状态码200,301,302与404
- 状态码200:表示请求成功,浏览器一定会尝试正确解析响应报文
- 状态码301与302:分别表示永久重定向与临时重定向,两者区别在于:
浏览器访问a,发现永久重定向到b时,会记录一条a->b的映射,下次再尝试访问a时,会直接进行对b的访问,无需再次进行重定向操作;但当浏览器访问一个网址a遇到临时重定向时,会跳转到重定向的网址b,但不会对b做记录,也就是说,下次再次访问a时,仍会从a跳转到b,注:该状态码需搭配header字段Location进行设置:

- 状态码404:关于这点,
在代码编写时遇到了坑,在实践过程中发现服务端发送404响应报文,浏览器可能不对报文进行解析,会直接显示浏览器内置的404界面,此时,若想显示服务端自身的404界面,只能通过状态码设为3XX + 重定向或状态码设为200返回服务端自定义404界面 - 补充说明:
浏览器这个东西比较特殊,有些细节没有统一标准,就像这里的404状态码处理,各个浏览器就可能不同- 从第三点的解决方案也能看出,状态码虽表示不同的功能,但也不一定严格设置,这一点在同一类别的状态码中体现更甚,例如,现代编码过程中,可能不少程序员会把服务器无法处理请求全部设置为404
响应报文字段------常见headers
Content-Length:表示正文长度-》重点:协议处理粘包问题(请求与响应均有)- Content-Type:表示正文类型-》确保接收方能正确解析正文(请求与响应均有)
- Location:表示重定向的网址(上文介绍的3XX状态码重定位时所必带的header属性,更常见于响应报文)
- Allow:表示服务器支持的请求方法(少用,上述OPTIONS请求中有介绍,更常见于响应报文)
- Connection:这是HTTP/1.1开始支持的字段,功能是
表示是否支持长连接,该字段可填两种值,keep-alive表示当前报文发送端支持长连接,close表示当前报文发送端不支持长连接,若双方都支持,则相互就可提供长服务(服务端需自定义实现,客户端若为浏览器则无需手动实现)(请求与响应均有)-》为何使用长连接:从HTTP编码经历中体会到,若使用一个请求建立一个TCP连接的方式,对于现代网页,一个html中很可能包含几百张图片,那就会瞬间建立百条子进程/新线程,且创建新TCP连接也具备开销-》这些行为极有可能导致服务端直接崩溃,而采取长连接方案,可将这百次相关联的访问使用一条TCP连接交互,从而显著降低了服务端的压力 - Set-Cookie:一般常见于响应报文,较为复杂,下面会具体进行介绍
- Cookie:一般常见于请求报文,对应上述第6点中的Set-Cookie,用于保存用户信息,下面进行介绍
- Referer(标准中就是如此拼写,是历史遗留拼写错误):常见于请求报文,用于记录用户从哪个页面跳转到当前界面
响应报文字段------cookie(也属于headers)与session技术
cookie构成
由于http是无状态且无连接的,所以,其不会保存用户信息,记录用户是否在上个页面已经登录过,按这个说法,登录一个网站,访问其中每个需要登录的网页,都需要重新登陆
一个完整的Set-Cookie示例为Set-Cookie: username=peter; expires=Thu, 18 Dec 2024 12:00:00 UTC; path=/; domain=.example.com; secure; HttpOnly,其中,每个属性都以; 作为分隔符,除第一个属性外的其他属性为这条Cookie的属性,之后B端发送Cookie时不会再将这些属性重新发给S端:
第一个属性是一个键值对,即未来B,S之间传送的属性第二个属性是该条Cookie的过期时间,为保证时间的正确性,建议采取标准时间(UTC时间),标准时间格式如上,同时,如果设置了该属性,则Cookie为持久Cookie(即文件Cookie,直到过期时间才会失效),而若未设置该属性,则默认为会话Cookie(即临时Cookie,当浏览器关闭时才会失效)第三个属性为B端访问到哪个web目录时向S端发送该条Cookie;- domain属性功能是指定哪些主机可以接受该Cookie,默认为设置它的主机;
- secure属性表示仅当使用HTTPS协议时才发送Cookie,这有助于防止Cookie在不安全的HTTP连接中被截获;
- HttpOnly表示标记Cookie为HttpOnly,意味着该Cookie不能被客户端脚本(如JavaScript)访问,这有助于防止跨站脚本攻击(XSS)
注:如果Cookie的名称或值包含特殊字符(如空格、分号、逗号等),则需要进行URL编码
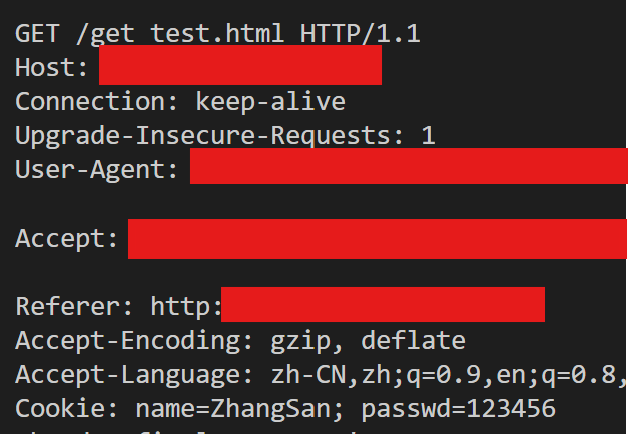
在实验中的体现为:
S端发送Cookie至B端:

B端接收Cookie:
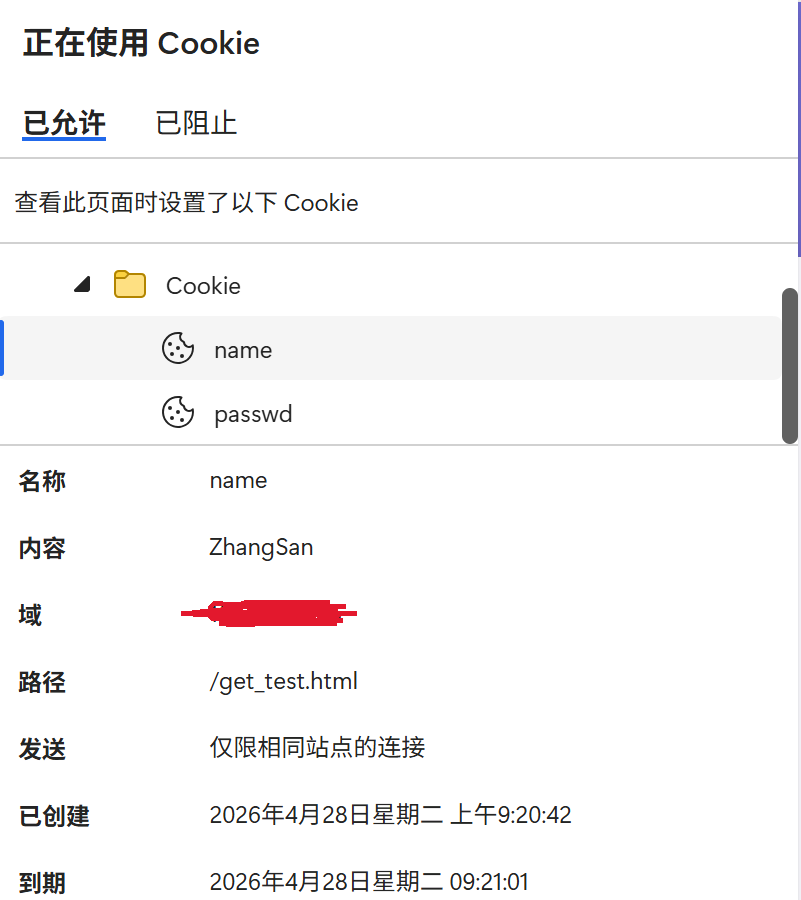
B端访问S端Set-Cookie设置的回复界面时:
session
Cookie中包含能够自动登录网页的信息,而古早的木马病毒(网络蠕虫病毒)就是通过获取Cookie中的信息,实现的自动登录,并且Cookie中获取的信息还会包含用户名甚至身份证号等重要信息,所以,仅用Cookie就会存在两层风险,一是网页会被别人登录,二是,密码,个人信息会泄露,为了解决这两个问题,session以及其衍生技术技术诞生了,session技术的原理很简单,就是将原本保存在Cookie中的个人信息(包括登录用信息)保存到服务端,由服务端管理的同时,服务端会将一个代表该管理信息的字符串(可以简单想象成服务端通过hash管理,返回的就类似key + 特殊处理后的值)返回给客户端,如此,客户端中的Cookie存储的就是该特殊字符串,当客户端尝试通过该Cookie访问服务端时,服务端会通过该Cookie(key)获取数据结构中存储的用户信息,若相匹配,则可成功登录-》如此,便解决了病毒通过Cookie获取用户信息的问题,而对于假冒登录的问题,则需要其他手段来解决,简单来说,若登录设备,ip等发生变化这个Cookie就可能会失效,或者,当用户行为异常,Cookie也可能会失效......
关于HTTP编程实例
HTTP仅具备协议,并没有C++官方推出的相关库,若尝试自定义实现,可参考以下链接:
https://gitee.com/xiao-dongs-code-repository/gitee_dmk/blob/master/Linux/2026_4_21/http.hpp
而在简单的项目开发中,常会使用第三方库httplib,其使用可参考以下链接:
https://gitee.com/xiao-dongs-code-repository/gitee_dmk/tree/master/Linux/2026_5_7
HTTP编程补充说明
当请求的URI的地址对应的是html文件,若其中包含图片等n个文件,会先请求一次html文件,然后再发送n个请求获取n个html中的文件HTTP协议对"请求URI中的路径"和"返回的响应报文"之间,没有任何硬性规定,一切都是应用层(程序员)自定义的,绝不存在什么请求/目录就一定返回/index的硬性规定- URI中路径部分可以添加多个/,如/a等价于//,浏览器均可正确识别
- urlencode和urldecode:URI中会使用如'?'的特殊字符,因此,若原始数据中需要进入URI且包含特殊字符,浏览器会将其转换为特殊格式,转换规则为:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式,如下图示例:
HTTPS
相关概念
首先说明,http在传输过程中是明文传输的,这就导致信息很容易被别有用心者获取,因此,就有了需要加密传输的需求,由此,就诞生了https:
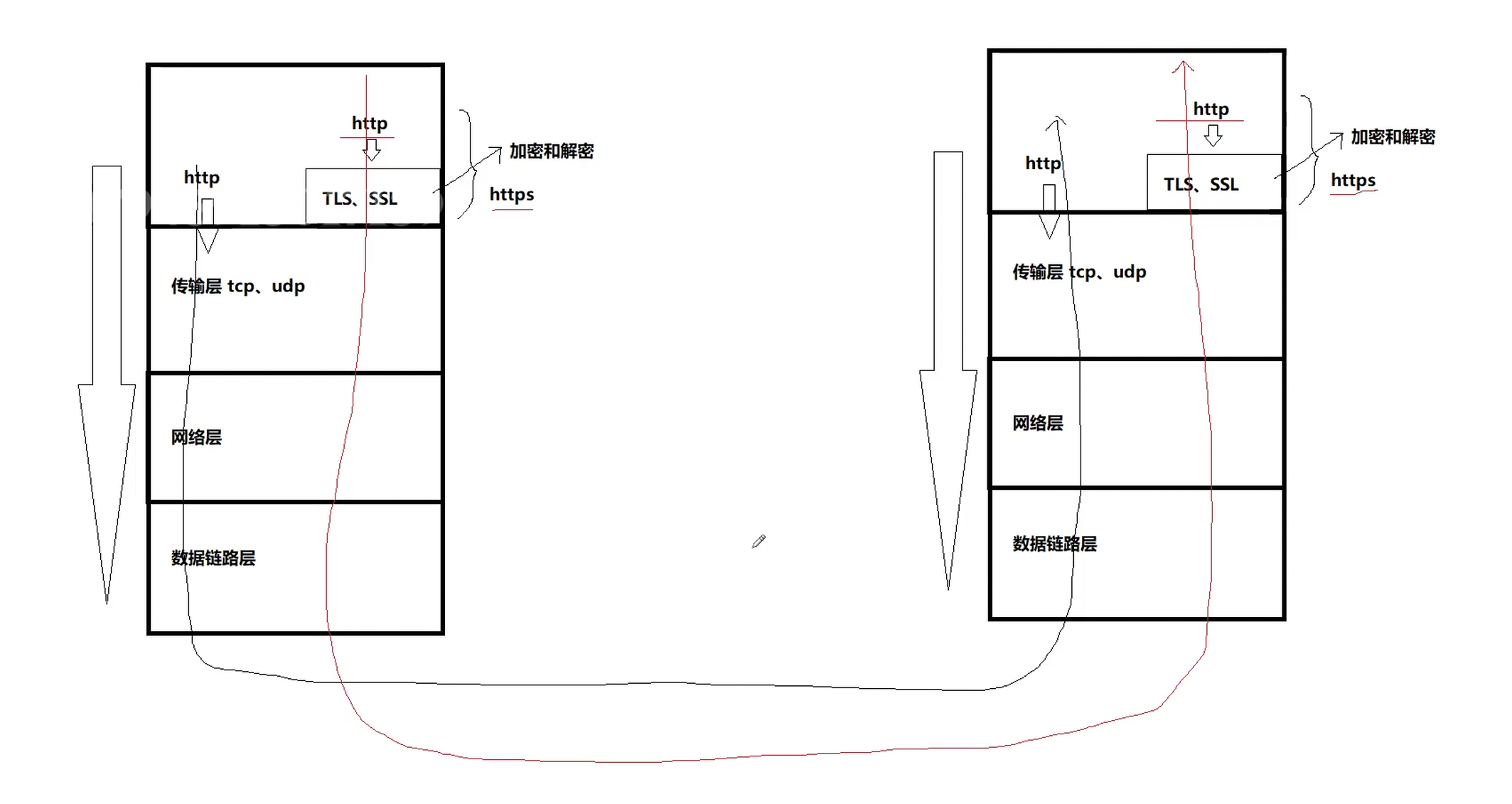
如上图,https即经过TLS、SSL软件层加密的http,也就是说,若不加密,则为http,而关于https是如何实现加密的,要先了解到下面的名词:
数据摘要/数据指纹:摘要是数据或消息的短文本,通常用于验证数据或消息的完整性,简单来说,对于一份数据,无论其大小,均可通过hash函数计算出一个大小仅几十个字节的摘要,且可确保很难(极难)产生hash冲突,原因是,比如现在用到的摘要,一般为32/64字节,拿32字节举例,若想通过鸽巢原理产生hash冲突,则需要2 ^ 32 * 8 + 1 ≈ 1.1579×10 ^ 77种数据,而这显然是个天文数字,只需保证hash函数足够优秀,基本完全可避免hash冲突,而值得一提的是,hash函数普遍仅能保证val获取key,但无法逆向从key获取val,因此,数据摘要的作用不是加密/解密数据,而是验证数据是否被篡改过密钥:用于加密/解密数据的工具,简单来说,比如传输的数据是10,密钥是5,则加密后的数据为10 ^ 5,而使用密钥解密就可得到10 ^ 5 ^ 5 = 10对称密钥:密钥的类型之一,一般指的是两把(一对)钥匙,对称指的是两把密钥是相同的,类似上述介绍密钥时举例的5,不过真正使用肯定要复杂很多非对称密钥:密钥的类型之一,指的也是两把(一对)钥匙,非对称指的是两把密钥是不同的,且其中一把是私有,另一把是可被公开的,加密/解密时,使用其中一把加密,就必须使用另一把解密,即加密解密不能使用同一把,值得一提的是,非对称密钥的加密解密效率要远低于对称密钥
HTTPS保密方案(注:以下流程不是TLS/SSL协议规范的逐条解读,而是通过逐步推演,理解为什么HTTPS最终采用"证书 + 非对称 + 对称加密"的方案)
-
方案一:其中一方创建一对对称密钥,且双方不泄露,即对称密钥均私密,则发送的消息在传输过程中便不会泄露,问题:一方构建对称密钥后,要如何传递给另一方,且保证该密钥在传输过程中不被第三方获取?答案是无法做到,因此,该方案由于无法保证密钥私密,成为废案 -
方案二:其中一方创建一对非对称密钥,自身保留私钥,另一方获取公钥,之后双方使用该非对称密钥通信,问题:公钥在首次发送时也能被他人获取,因此,虽可确保公钥方向私钥方传输的数据安全,但不能保证私钥方向公钥方传输的数据安全,因此,该方案也是废案 -
方案三:收到方案二的启发,既然一对非对称密钥可以保证公钥方向私钥方的通信安全,那,使用两对非对称密钥不就可以保证两方通信安全吗?但该方案会产生两个问题,首先,双方均使用非对称密钥,效率过低(相对于使用对称密钥),其次,其实该方案也不是安全的,试想,存在一个中间方负责两方的通信传输,当其中一端(这里假设C端)先创建一对非对称密钥A,私A, 公A,然后将公钥A发给另一端(即S端),则中间放就会先得到公钥,然后中间方便可以创建一对非对称密钥私B, 公B,将公B发给S端并拦截下A公钥,于是,S端会收到中间人创建的公钥B,接着,S端会创建一对非对称密钥私C, 公C,将公C发给C端,此时,还会经过中间人,则中间人便可获取公C,并拦截公C,向C端发送公B,于是,接下来,若C端向B端发送私钥A加密过的消息,则中间人便可通过获取的公钥A进行解密,得到数据后,篡改并用私钥B加密,发送至S端,则C-》S的数据便不在安全,与此同时,若S发C私钥加密的数据给C端,则经过中间人时,中间人可以使用公钥C进行解密,将数据篡改后用私钥B加密,并返回给C端,则S-》C的数据便也不再安全,因此,成为废案(注:该泄密过程被称为中间人攻击) -
方案四:该方案来解决方案三的第一个问题,即,可使用一对对称密钥 + 一对非对称密钥进行双方通信,流程是,其中一方(假设C端)先建立一对非对称密钥公A, 私A,然后将公A发送给另一端(即S端),接着,S端创建一对对称密钥B,并用公A加密,发送给C端,于是,S,C两端便获得了看似对其他人保密的一对对称密钥,之后废弃非对称密钥A,使用对称密钥通信即可,但问题是,方案三中的第二个问题(中间人攻击问题)仍然存在,也就是说,该方案仍是废案 -
方案五:这是https所使用的方案,也是最终方案,按方案四所言,现在需要解决的问题就仅有中间人攻击了,解决方案是,创建权威机构(即CA机构),具体来说,S端先创建一对非对称密钥公A,私A(现实中的流程一般均为S端创建非对称),然后将公A以及申请信息发送给CA机构,向其申请证书,申请通过后,CA机构会为S端颁发证书,其中内容中包括S端创建的公钥A,之后,若有C端尝试与S端通信,则S端会直接将得到的证书发送给C端,而C端有能力验证该证书是否合法,若合法,则获取证书上的公钥A,并创建一对对称密钥钥B,使用公A加密B后将其发送给S端,则此时,中间人由于无法伪造证书,也没有私钥A来解密,就无能为力了,而S端得到对称密钥B,双方便可以使用对称密钥B进行通信,至此,问题被解决,该方案为最终方案- 证书:其内容物包含S端创建的公钥A,S端的ip地址,以及证书的过期时间等,同时,证书中还包含一个由上述内容物形成的数据摘要,该摘要被称为签名,获得证书者可通过CA机构公开的哈希函数对证书的内容物以及签名做对比,确保证书有效
- CA机构:是大家公认的权威机构,具备一对非对称密钥,工作就是使用私钥加密,并颁发证书
p地址,以及证书的过期时间等,同时,证书中还包含一个由上述内容物形成的数据摘要,该摘要被称为签名,获得证书者可通过CA机构公开的哈希函数对证书的内容物以及签名做对比,确保证书有效 - CA机构:是大家公认的权威机构,具备一对非对称密钥,工作就是使用私钥加密,并颁发证书
- 关于中间人为何无法伪造,发起中间人攻击:最开始,C端申请与S端通信,S端会向C端发送证书,该证书经过中间人时,中间人是无法伪造的(因为没有CA机构的私钥),同时,虽然中间人也可以向CA机构申请证书,但由于证书上存在ip地址信息,所以中间人无法伪造为S端与C端进行通信,之后,当C端向S端传送使用公钥A加密的对称密钥B时,由于中间人没有私钥A,也就无法获得对称密钥B,至此,中间人便无法展开中间人攻击了