有直接映射,2路组相联映射(或是n路),全相联映射三种
下面从操作系统视角梳理一下相关内容
1 操作系统存储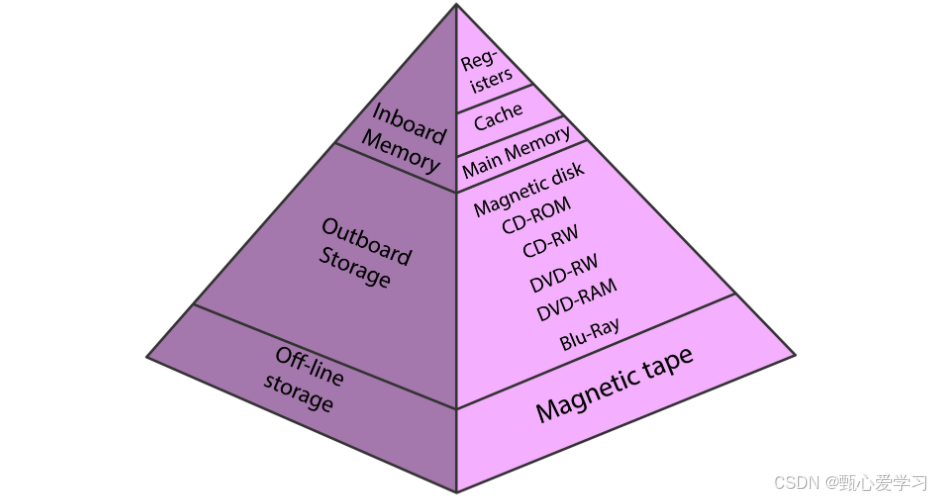

有寄存器、缓存、主存、硬盘等,上述缓存映射机制发生在主存与缓存之间
寄存器:直接集成在 CPU 的运算核心内部;与 CPU 的时钟频率同步,访问寄存器几乎不需要时间(通常在半个到三个时钟周期内),比 L1 缓存还要快;用于存放正在参与运算的数据、指令地址或中间计算结果。CPU 的数学运算单元(ALU)通常只能直接对寄存器里的数据进行操作
缓存:CPU芯片内部
主存:RAM,插在主板上的**独立内存条,**CPU 需要通过主板上的总线才能访问
硬盘
寄存器与缓存的区别
在运算时,CPU 的工作逻辑通常是这样的:
-
搬运 :硬件自动把主存里的数据块搬到缓存里(预防性准备)。
-
加载 :程序发出指令,把缓存里具体的某个数字加载到寄存器中。
-
计算:ALU 拿起寄存器里的数字进行加减乘除。
-
存回:计算结果先回存到寄存器,再由指令写回到缓存或内存。
| 特性 | 寄存器 (Register) | 缓存 (Cache, 如 L1/L2/L3) |
|---|---|---|
| 存放位置 | 紧挨着运算单元(ALU),是核心的最深处 | 位于核心附近或核心之间,作为内存的缓冲 |
| 容量大小 | 极小(通常只有几十个,总共几百字节) | 较大(从几 KB 到 几十 MB 不等) |
| 访问速度 | 最快(通常 1 个时钟周期内完成) | 快(L1 需要几个周期,L3 可能需要几十个) |
| 管理方式 | 由编译器或程序员决定(指令直接操作) | 由硬件自动管理(对程序员几乎透明) |
| 数据单位 | 字(Word,如 64 位系统就是 8 字节) | 缓存行(Cache Line,通常是 64 字节) |
缓存与主存的区别
电信号传输是有速度限制的。缓存就在 CPU 核心旁边,而访问主存需要穿过主板电路,这中间的物理距离导致了明显的延迟
-
缓存采用 SRAM (静态随机存取存储器):它利用 6 个晶体管来存储 1 位数据,速度极快但电路复杂、体积大且价格昂贵。
-
主存采用 DRAM (动态随机存取存储器):它利用 1 个晶体管和 1 个电容来存储,结构简单、密度高且便宜,但电容会漏电,需要不断刷新电量,这限制了它的速度。
刷新是什么意思?
主存(DRAM)的基本存储单元是 1T1C 结构:即一个晶体管(Transistor)充当开关,一个微型电容(Capacitor)储存电荷。
-
原理:电容里充满电代表逻辑"1",没电代表逻辑"0"。
-
漏电难题:电容非常微小,而且物理上并不完美。即使开关断开,电荷也会通过电介质或晶体管缓慢地泄露出去。如果不干预,原本存储的"1"很快就会流失殆尽变成"0",导致数据损坏。
-
刷新操作 :为了维持数据,内存控制器必须在电荷流失到无法识别之前,周期性地(通常每 64 毫秒)读取每一行的数据。如果发现是"1",就重新给该电容充满电。这个"读取并重新充电"的过程就是刷新。
-
性能代价:刷新时,内存处于"忙碌"状态,CPU 的访问请求必须等待,这就是主存延迟的一部分来源。
主存与硬盘的区别
主存是易失的,只存放当前运行的程序片段
硬盘不易失,断电后仍存储
2 缓存映射
由于主存速度比较慢,所以用缓存存储一些常用的数据
这里有3个问题:
1.主存这个位置的数据要映射到缓存的哪个位置?这就是最开始的缓存映射问题
2.需要的数据是否在缓存中?即缓存是否命中的问题
3.如果缓存不命中,需要把新的数据加入缓存,由于容量有限,缓存中也需要数据出去,怎么选择替换数据?也就是替换策略
缓存映射方法
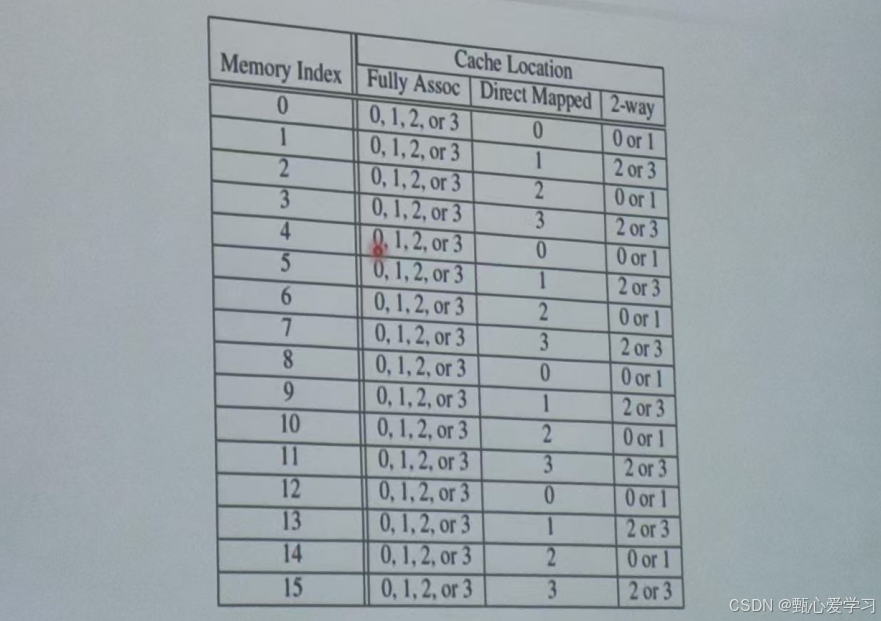
1.直接映射
-
规则 :通过取模运算确定位置。例如:
缓存位置 = 主存索引 % 缓存行数。 -
图中表现:缓存有 4 行,所以主存索引 0, 4, 8, 12 都会映射到缓存位置 0。
-
特点:查找极快,但容易产生冲突,即两个主存块不停地在同一个缓存位置互相踢走对方。
2.全相连映射
-
规则:只要缓存里有空位,数据就能进去。
-
图中表现 :主存索引 0-15 的缓存位置都是
0, 1, 2, or 3。 -
特点:缓存空间利用率最高,命中率高,但硬件查找(需要同时扫描所有行)非常昂贵且耗能。
3.2路组相连映射
这是前两者的折中方案,也是现代 CPU 最常用的方式。缓存被分成若干"组"。
-
规则:数据首先根据取模运算找到对应的"组",然后在组内的两个位置中任选其一。
-
图中表现:缓存被分为两组(组 0 包含位置 0 和 1;组 1 包含位置 2 和 3)。主存索引 0 映射到组 0(即位置 0 或 1)。
-
特点:兼顾了直接映射的查找速度和全相联的灵活性,有效降低了冲突。
替换策略
-
LRU (Least Recently Used) 最近最少使用 : 这是最聪明也最常用的策略。它会踢走那个最长时间没有被访问过的数据块。逻辑是:如果你很久没用它了,那么你接下来大概率也不会用它。
-
FIFO (First-In, First-Out) 先进先出 : 就像排队一样,最先进入缓存的数据块最先被踢走。
-
LFU (Least Frequently Used) 最不经常使用 : 它会记录每个数据块被访问的次数,踢走那个访问次数最少的数据。
-
Random 随机替换 : 完全随机选一个踢走。虽然听起来很草率,但在某些复杂的并行运算场景下,它的表现甚至不比 LRU 差,而且硬件实现非常简单。
策略选不好,可能导致缓存失效,也就是本来想利用缓存加速,但是缓存一直在替换数据,反而没有了速度优势
3 缓存
缓存分级系统
CPU 内部的分级是为了在速度、容量和成本之间取得平衡,形成一个"金字塔"结构。
-
L1 (一级缓存):离核心最近,速度极快(通常 1ns 左右),但容量最小(几十 KB)。它分为指令缓存和数据缓存,专门服务于单个核心。
-
L2 (二级缓存):容量稍大(几百 KB 到几 MB),速度稍慢。在很多现代设计中,它也是每个核心独占的。
-
L3 (三级缓存) :容量最大(几十 MB),但速度最慢。它通常是所有核心共享的,负责核心之间的数据交换和减少对主存的访问。
缓存分级 (L1, L2, L3) 的包含策略
-
Inclusive(包含式):L1 的所有数据必须也存在于 L2 中。优点是当核心 A 寻找核心 B 的数据时,只需查 B 的 L2,不需要打扰 B 的 L1(降低核心间通信压力)。
-
Exclusive(排他式):L1 和 L2 存储完全不同的内容。优点是总容量更大(L1+L2),但管理逻辑更复杂。
-
时延差异 :在现代 CPU 中,访问 L1 约需 4 个时钟周期 ,L2 约 12 周期 ,L3 则跃升至 40-60 周期。
多核并行的缓存一致性
在并行计算中,如果核心 A 修改了 L1 中的变量 x,而核心 B 的 L1 中也存有旧的 x,就会导致计算结果错误。
为了解决这个问题,CPU 使用了缓存一致性协议 (如 MESI 协议)。这些协议就像一套监听系统,当一个核心修改了数据,它会通知其他核心:你手里的那个副本已经失效了,请去主存或我的缓存里拿最新的。
在多核并行时,每个缓存行(Cache Line)都有一个状态位:
-
M (Modified):数据被修改,且只存在于当前核心缓存,与主存不一致。
-
E (Exclusive):数据与主存一致,且只存在于当前核心。
-
S (Shared):数据与主存一致,且多个核心都有副本。
-
I (Invalid):数据已失效,必须重新从主存或其它核心读取。