后端缓存中间件
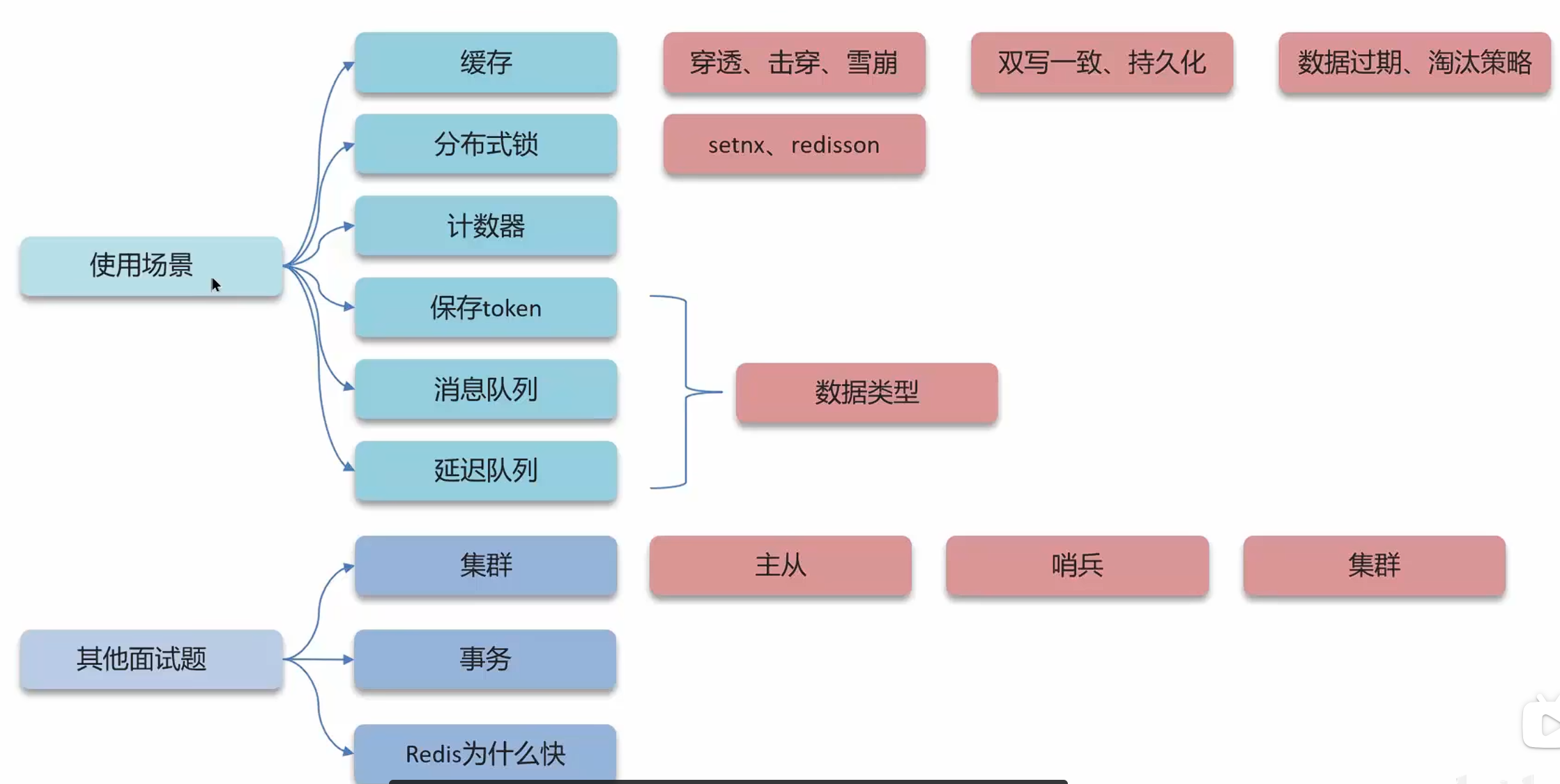

一、缓存
1.1缓存穿透(一堆假key访问)
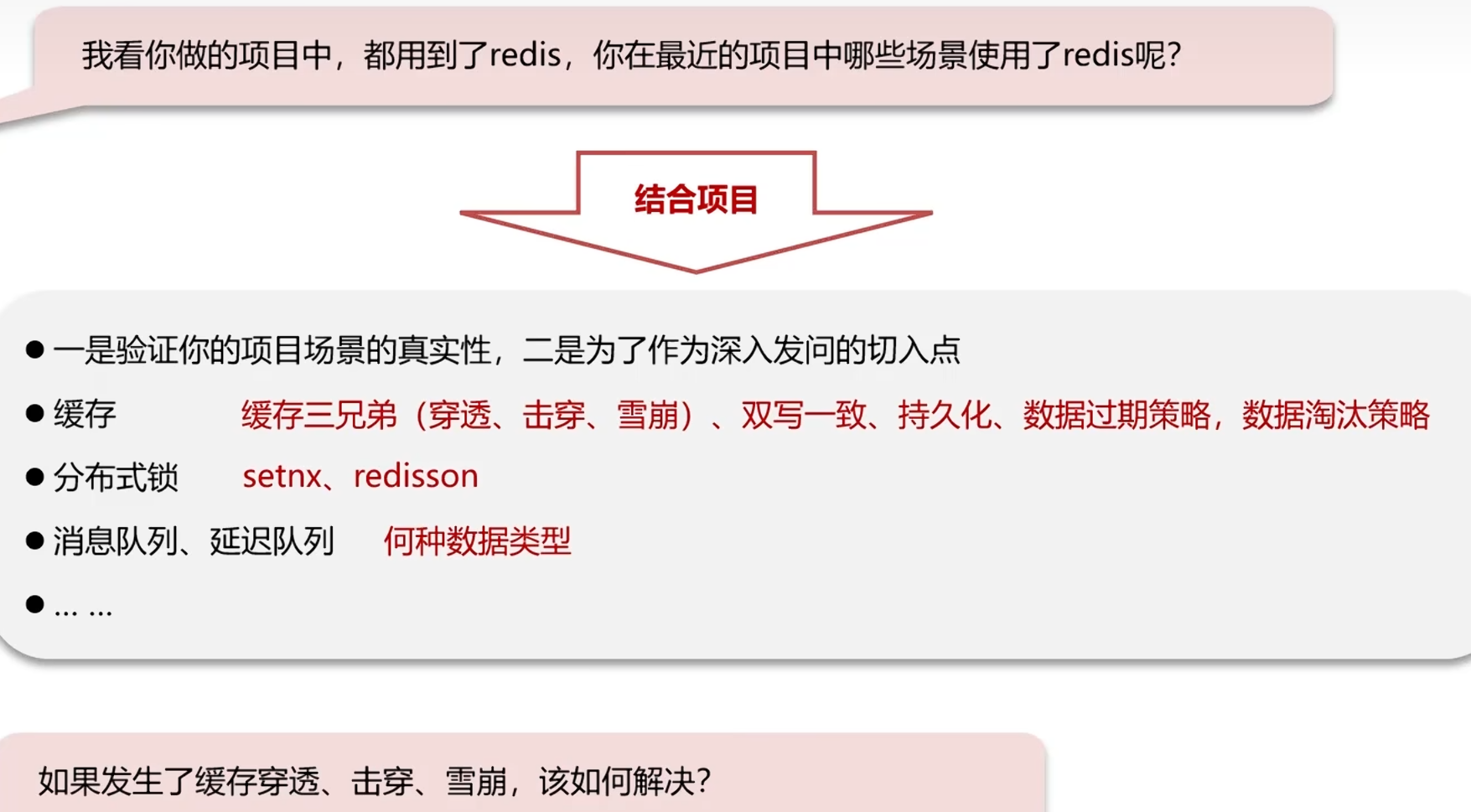
攻击数据库,知道你的请求路径在路径后面,造假id攻击,请求到一定量就会击垮数据库,导致宕机
2种方案
1.缓存空数据
就是将查询回来的空值也缓存
效果:简单,但可能导致数据不一致(比如:本来是空数据,但数据添加上了,但还是空)
原理:
当数据库返回空时,在Redis中缓存一个空值(如null),并设置较短过期时间(如1分钟),下次相同请求直接返回空,不再查DB。不涉及误判,100%有效,但会多占用少量内存。
2.布隆过滤器
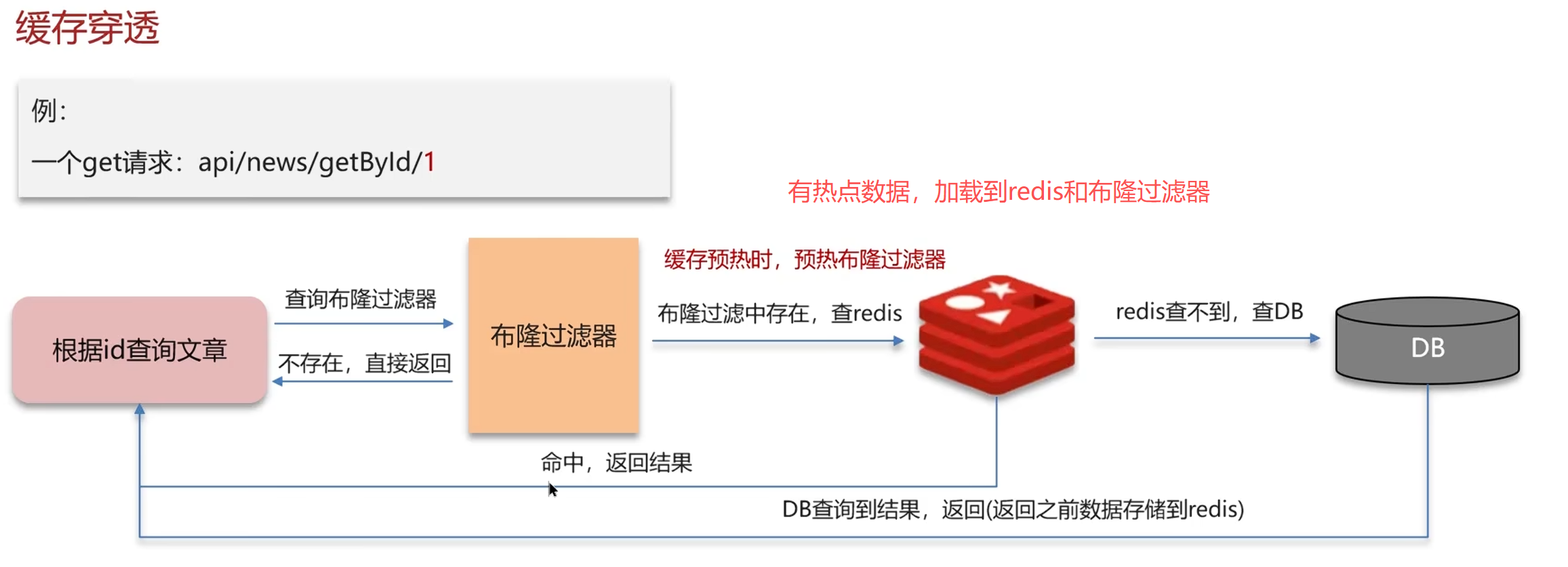
布隆过滤器

可能出现误判
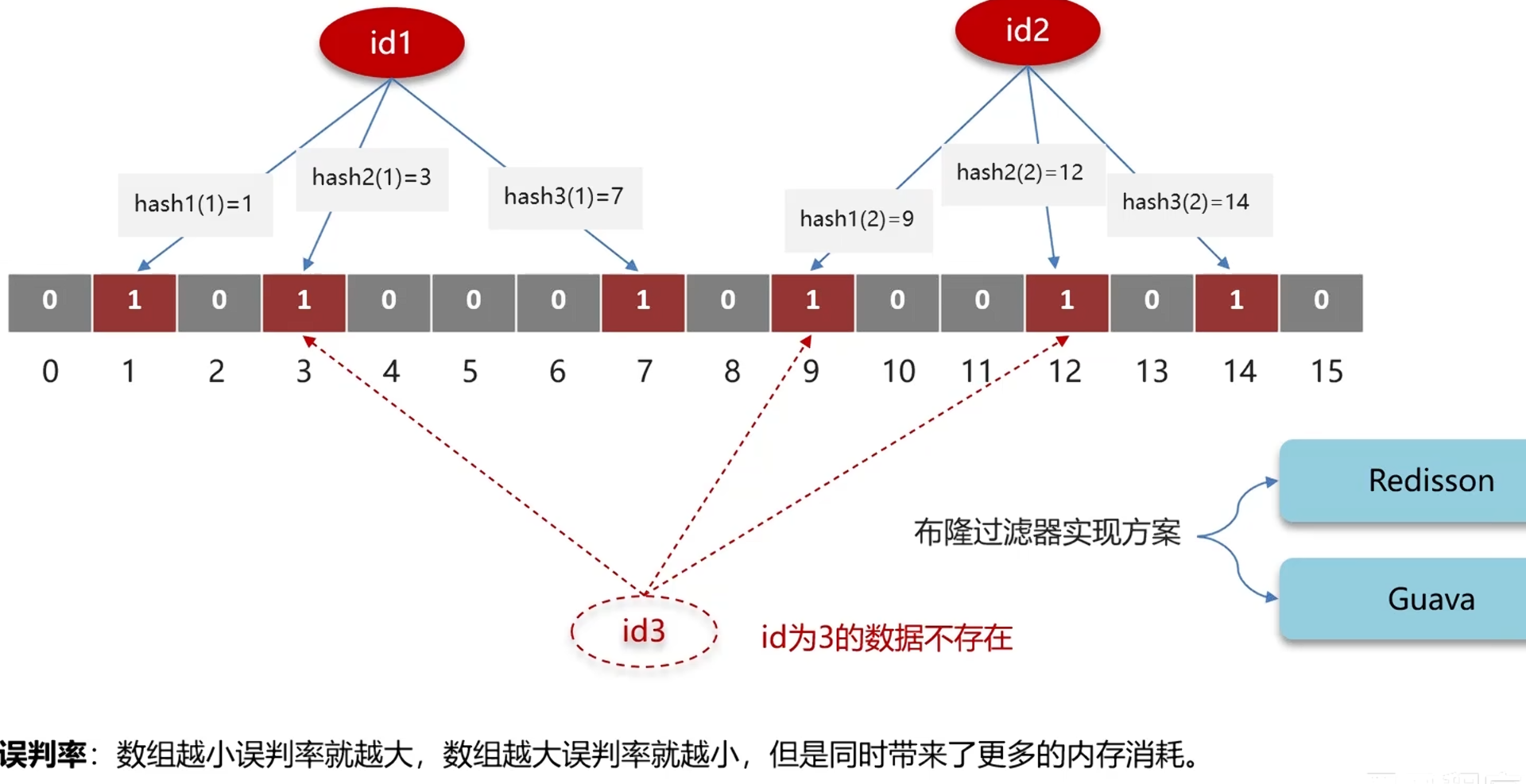
一般设置误判率为5%以内
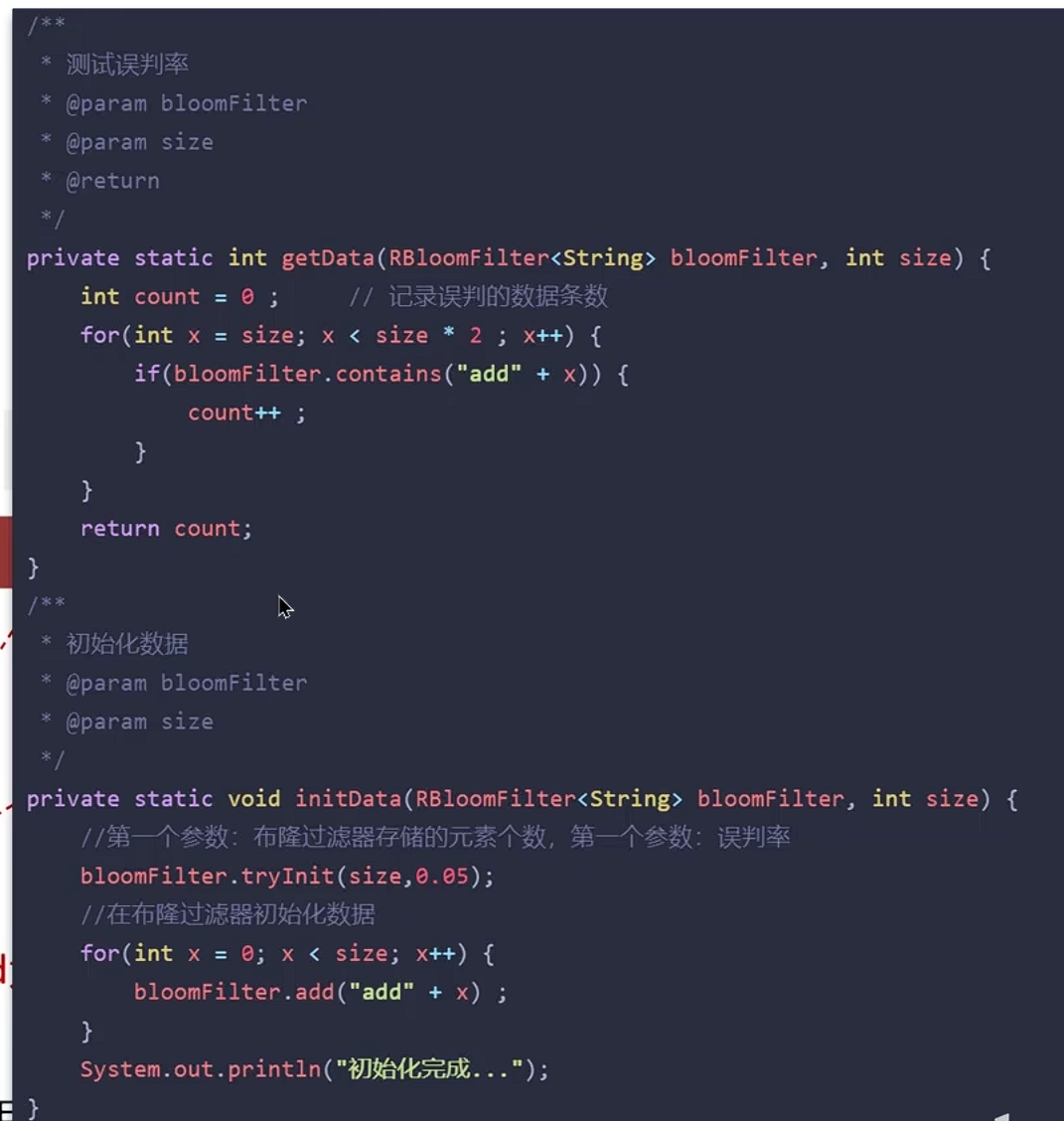
优点:内存占用少,没有多余的key
缺点:实现复杂,有误判,内存越大误判越低
原理:
将所有可能存在的数据的key(如所有合法user_id)预先放入布隆过滤器。请求来时先过布隆过滤器:
• 如果判断不存在 → 直接返回空,不查DB。
• 如果判断存在 → 才去查Redis/DB。

总结
如果你的数据key是有限且可枚举的(如用户ID、订单号),用布隆过滤器;如果你的key空间无限或难以预加载(如搜索词、动态参数),用缓存空值 + 短TTL + 限流
1.2缓存击穿(1个弱点key)
重新热缓存时间期间出现大量请求
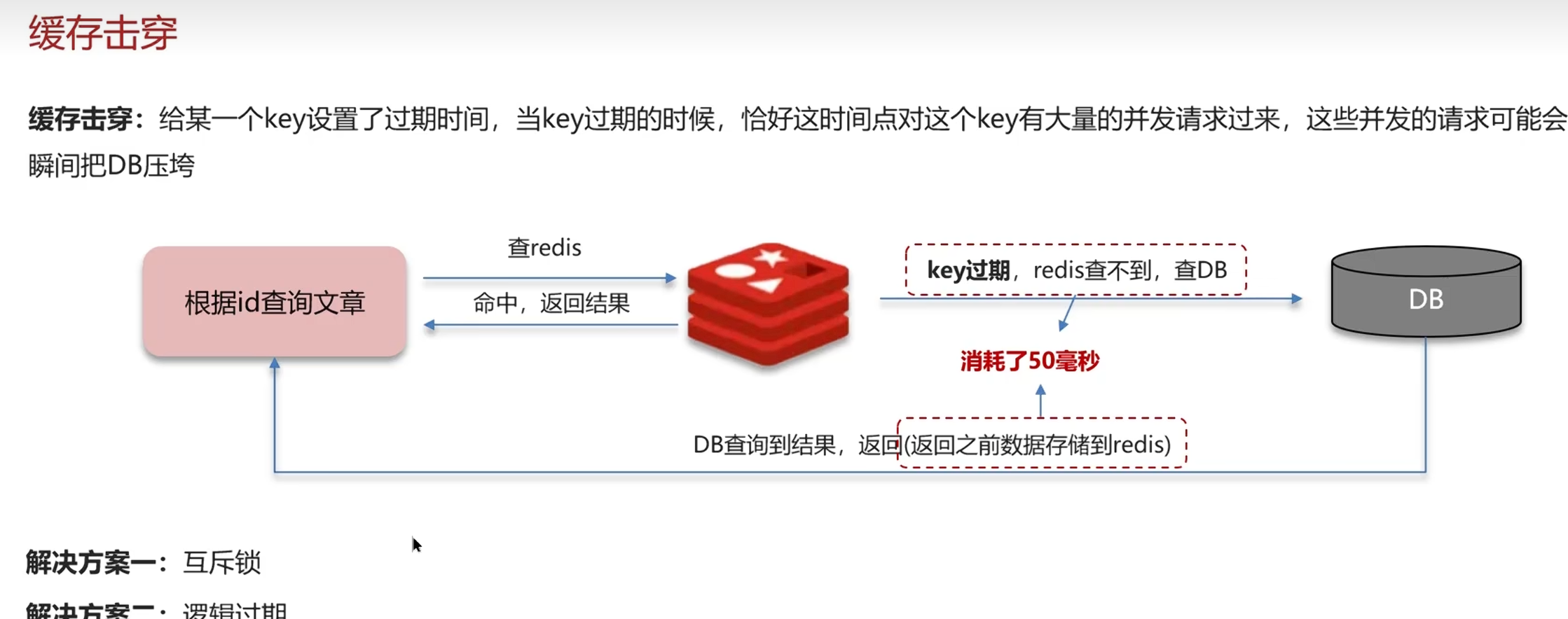
2种方案
1.互斥锁
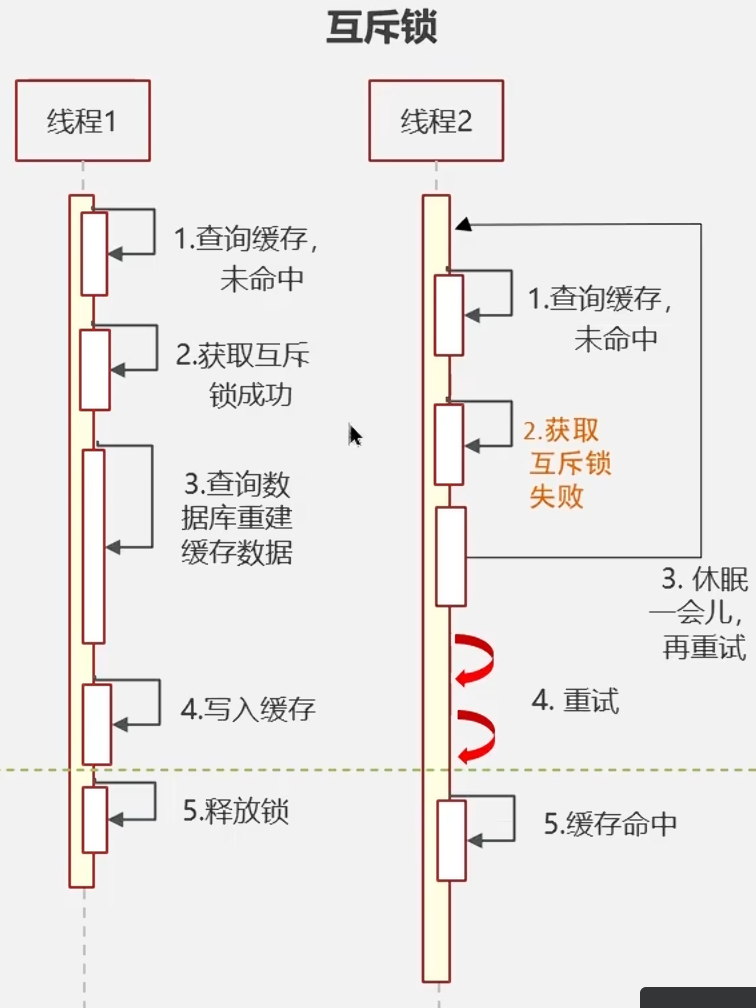
原理:
当缓存失效时,只允许一个线程去查询数据库并重建缓存,其他线程等待或快速失败。
强一致但性能差
2.逻辑过期
redis中不设置过期时间:
通过在存储数据的时候可以设置过期时间字段
原理:
缓存中不设置物理过期时间,而是存储一个"逻辑过期时间"。异步线程负责在数据快要逻辑过期时主动更新缓存
流程:
-
查询缓存,拿到数据及其逻辑过期时间。
-
如果未过期,直接返回。
-
如果已过期,立即返回旧数据(保证可用性),同时触发一个后台线程 去异步更新 缓存。
优点:不阻塞请求,高并发下性能好。
缺点:数据会短暂不一致(返回旧数据)
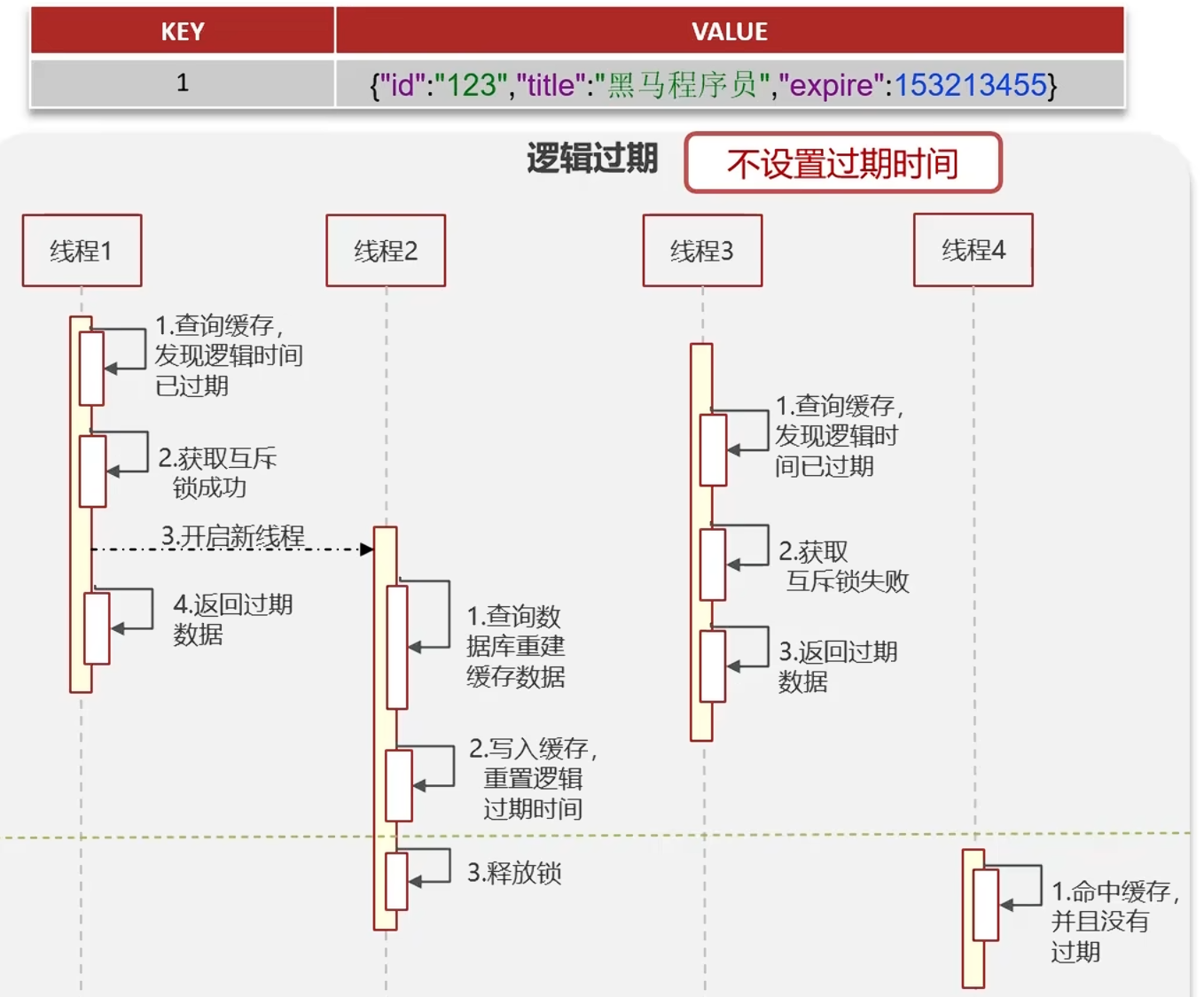
高可用,先返回旧数据,性能优
(核心目的)
如果用 Redis 自带的过期:key 一到时间就被删掉,所有请求都会直接打到数据库,就会出现缓存雪崩 / 击穿。
用逻辑过期的好处:key 永远不删,程序自己判断数据是否过期。过期后只让一个线程去更新数据,其他线程还能继续用旧数据,不会瞬间压垮数据库
「不设置过期时间」= 不让 Redis 自动删 key,key 永远留在内存里。
「加 expire 字段」= 程序自己存个过期标记,用来判断业务上的数据是否该更新了。
这俩是完全独立的,不冲突。3.永远不过期 + 定时刷新
原理:对热点key设置永不过期,由独立的后台任务定期(如每隔5分钟)从数据库拉取最新数据写入缓存。
优点:实现简单,完全避免击穿。
缺点:数据更新不及时,不适用于对实时性要求高的场景。
场景
-
对于超高热点(如秒杀商品) :采用 逻辑过期 或 永远不过期+异步刷新。
-
对于一般热点(如用户主页) :使用 互斥锁 (加锁时间短,影响不大)【互斥锁解决了击穿,但代价是增加了请求的等待延迟和锁竞争开销,可能耗尽线程资源,只适用于低并发、快速重建的热点场景】
总结
根据业务选择解决方案

1.3缓存雪崩(大量过期key)
缓存中大量的数据同时失效(或缓存服务整体宕机),导致海量请求直接穿透到数据库,数据库瞬间压力暴增甚至崩溃
两种常见成因
| 成因 | 示例 |
|---|---|
| 大量key设置了相同的过期时间 | 活动缓存设置 expire=3600,一小时后集体失效 |
| 缓存服务宕机 | Redis节点全部挂了,或网络断开 |
后果
-
数据库CPU飙升到100%,连接池爆满
-
服务响应变慢 → 上游请求超时 → 线程堆积 → 整个系统不可用

第四个解决方案就是给业务加多级缓存,使得redis作为2级缓存就可以预防
方案
| 图中 | 即 | 是否一致 |
|---|---|---|
| 给不同的Key的TTL添加随机值 | 过期时间打散(基础TTL + 随机偏移量) | ✅ 完全一致 |
| 利用Redis集群提高服务的可用性 | 缓存高可用(Redis Sentinel/Cluster) | ✅ 完全一致 |
| 给缓存业务添加降级限流策略 | 限流/熔断(Sentinel/Hystrix) | ✅ 完全一致 |
| 给业务添加多级缓存 | 降级返回(如本地缓存兜底) | ✅ 本质一致 |
-
"多级缓存" 你提到了具体实现(Guava/Caffeine),这是本地缓存的典型选型。"降级返回默认值或旧数据"包含了这一层,但没有明确点名 Guava/Caffeine。你的笔记更落地。
-
"哨兵模式、集群模式" 你单独列出,是 Redis 高可用的具体模式。即"Redis Sentinel/Cluster",完全一样。
-
"nginx或spring cloud gateway" 你指出限流降级的常见位置。我之前只说了组件(Sentinel/Hystrix),没提网关层,你的笔记更完整。
-
新的:"热点数据永不过期 + 异步刷新":这是一个专门针对极高并发场景的雪崩/击穿应对方案,你的笔记中没有列出。这个方案可以有效避免因"大量key同时过期"引起的雪崩,尤其适合缓存重建耗时长的情况。
-
"设置随机偏移量的具体范围":例如 1小时 ± 5分钟,你的笔记只写了"给不同的Key的TTL添加随机值",没给出量级建议
总结

1.4缓存-双写一致性

双写一致
原理:
双写一致性:当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致
删除顺序可能的问题
正常情况:
先删除缓存,再删除数据库,再查询,不影响
更改数据库,再删缓存,再查,不影响
非正常情况:
改第一个中突然有查,导致脏数据
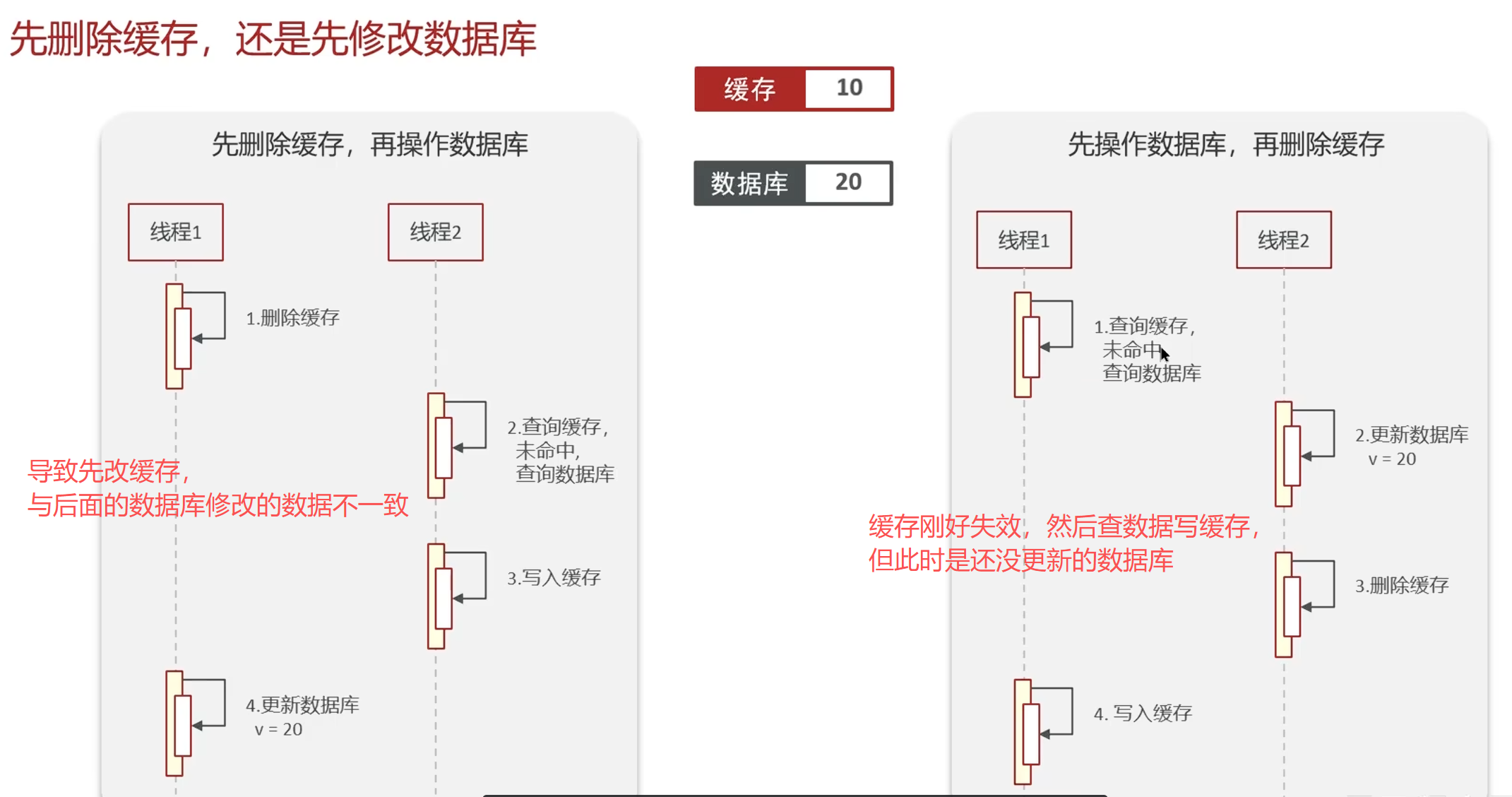
双删可以降低脏数据,延时是因为数据库是主从模式,读写分离的,需要等主节点把数据同步先
数据库主从模式存在复制延迟,导致"先删缓存后更新DB"的流程中,读请求可能从从库拿到旧数据并回填缓存,造成不一致;延时双删通过等待复制完成后再删一次缓存来消除这种污染
但这里延时也可能有问题,延时过程可能有脏数据,时间不好控制,做不到绝对的强一致。
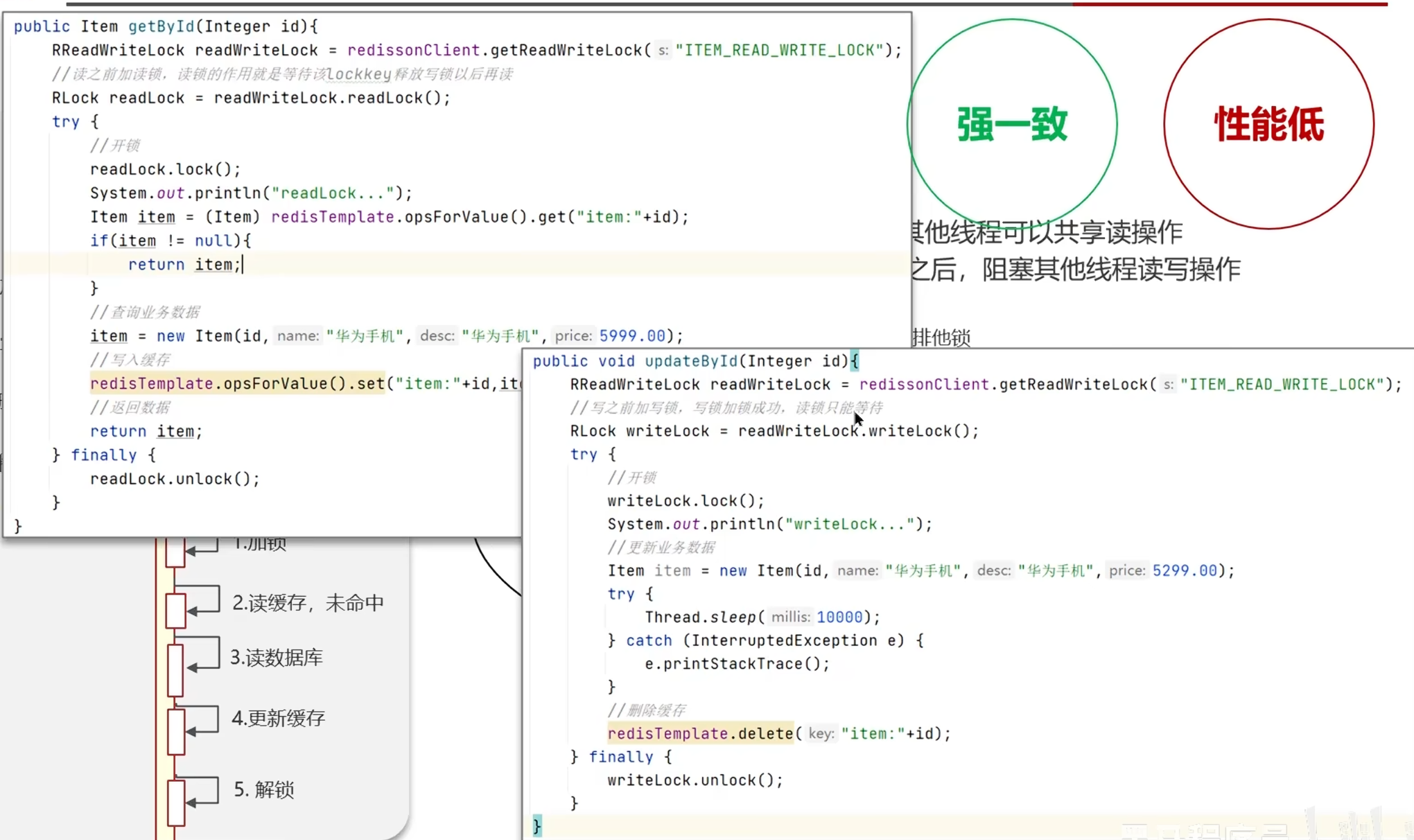
互斥锁(保证强一致)
但是性能差
优化:
思路:一般存入缓存都是读多写少,写多读少不应该写入缓存;
那么可以使用读写锁来限定,只影响写的时候的性能,然后就是一般业务要求严格的强一致才会使用读写锁。
异步通知(MQ)
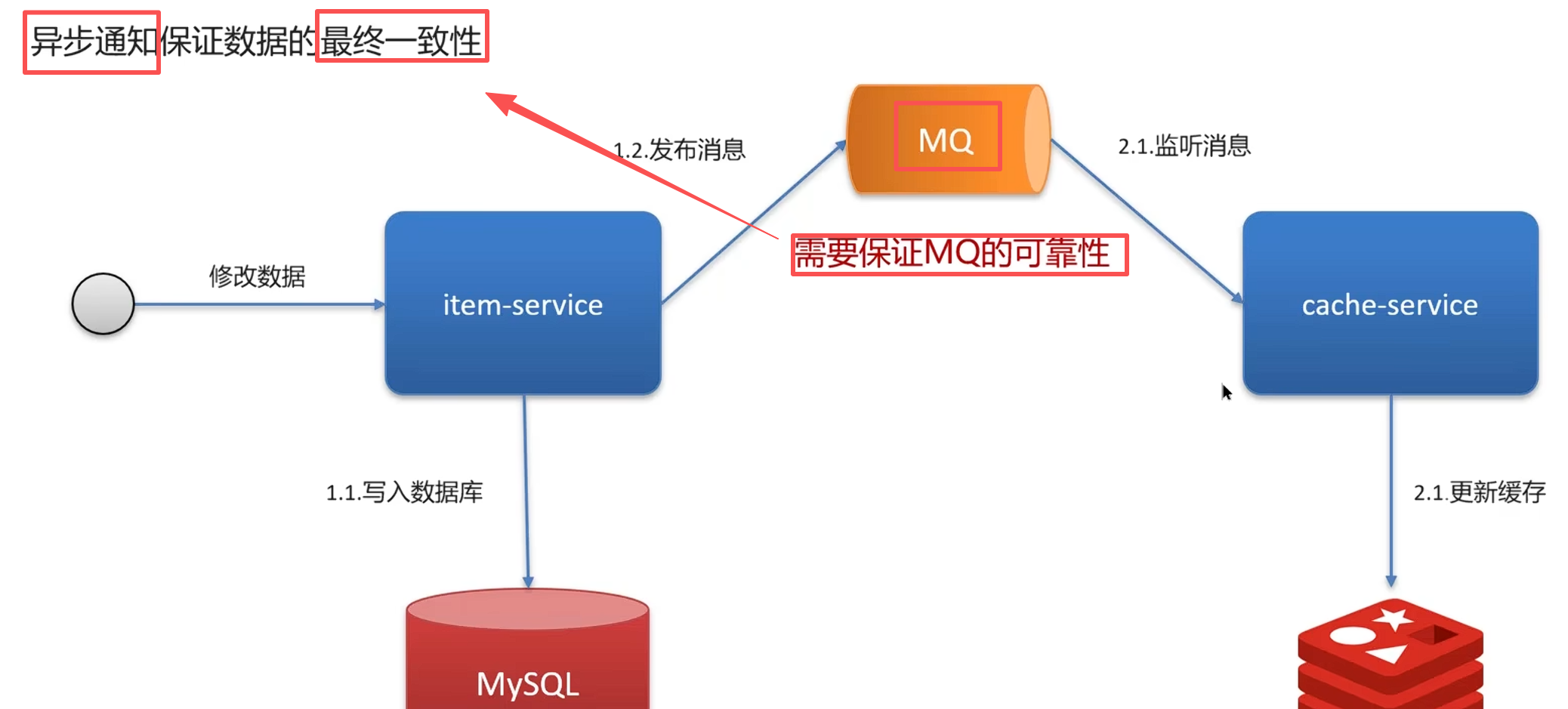
异步通知方案
写入数据库后,发一条消息到 MQ,消费者收到后更新缓存:
写请求 → 更新数据库 → 发送MQ消息 → 消费者更新缓存
为什么关系到 MQ 可靠性?
核心问题:MQ 丢消息怎么办?
如果消息丢失了:
数据库更新成功
但缓存没收到更新通知
缓存和数据库就不一致了
MQ 保证可靠性的手段
生产者端:
发送确认机制(如 RabbitMQ 的 confirm)
发送失败重试
Broker 端:
消息持久化到磁盘
镜像队列/副本
消费者端:
手动 ACK,处理完再确认
消费失败重试/死信队列
面试回答要点
"异步通知方案依赖 MQ 的可靠性,如果消息丢失会导致缓存不一致。所以需要从生产者、Broker、消费者三个层面保证消息不丢失,
比如生产者确认、消息持久化、消费者手动 ACK 等。"
异步通知(Canal)
阿里的中间件,基于数据库主从来实现同步的,就是把数据的修改(变化),自动记录到binlog,然后缓存服务是可以获取变化的,就更新到缓存
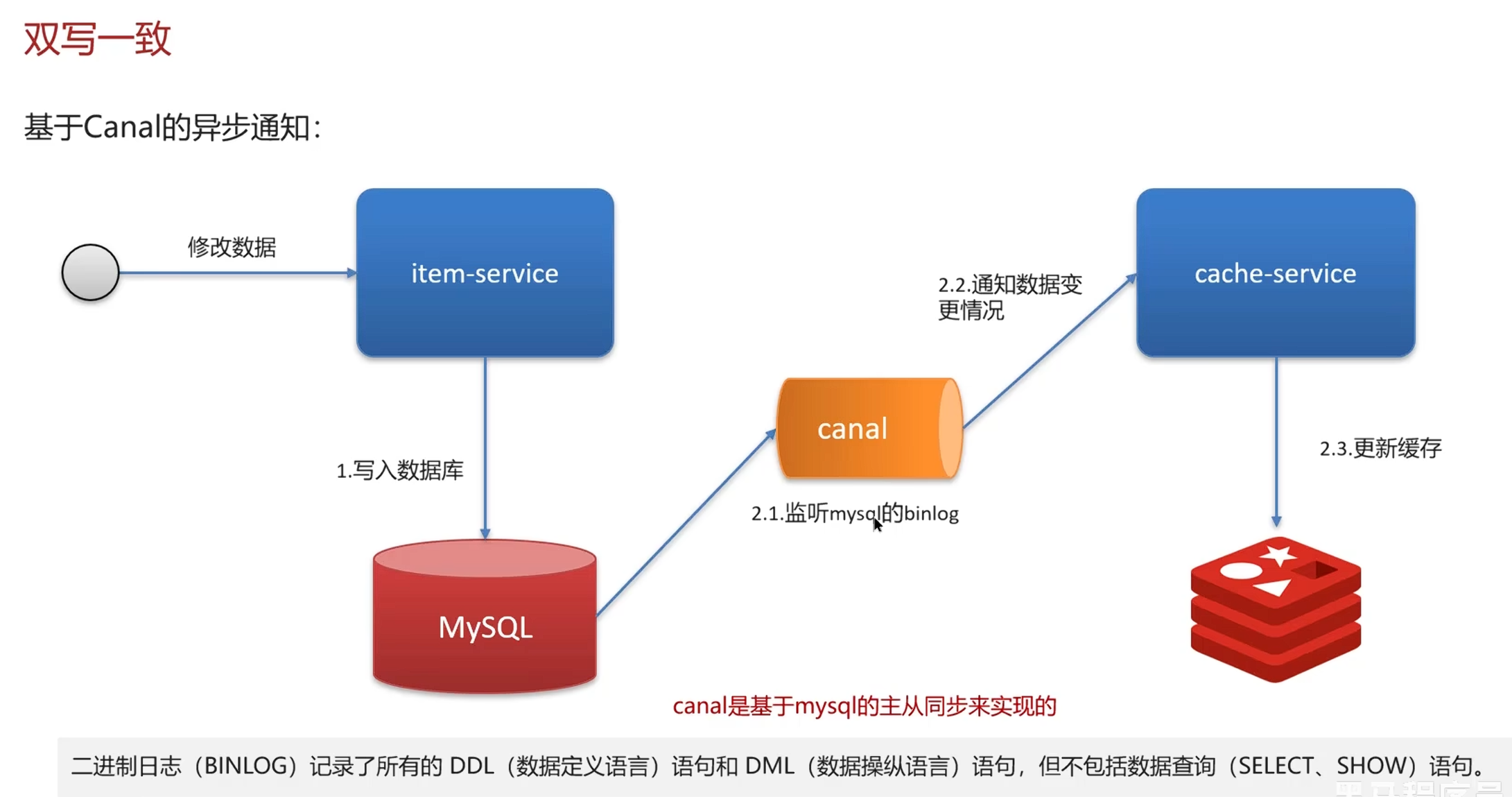
| 对比维度 | 普通 MQ | Canal |
|---|---|---|
| 谁发消息 | 业务代码 | Canal 自动发 |
| 侵入性 | 高,要改业务代码 | 零侵入,不用改代码 |
| 可靠性 | 依赖开发者记得发 | 自动监听,不容易漏 |
| 复杂度 | 低 | 需要部署 Canal |
延迟一致 = 允许短时间内不一致
总结


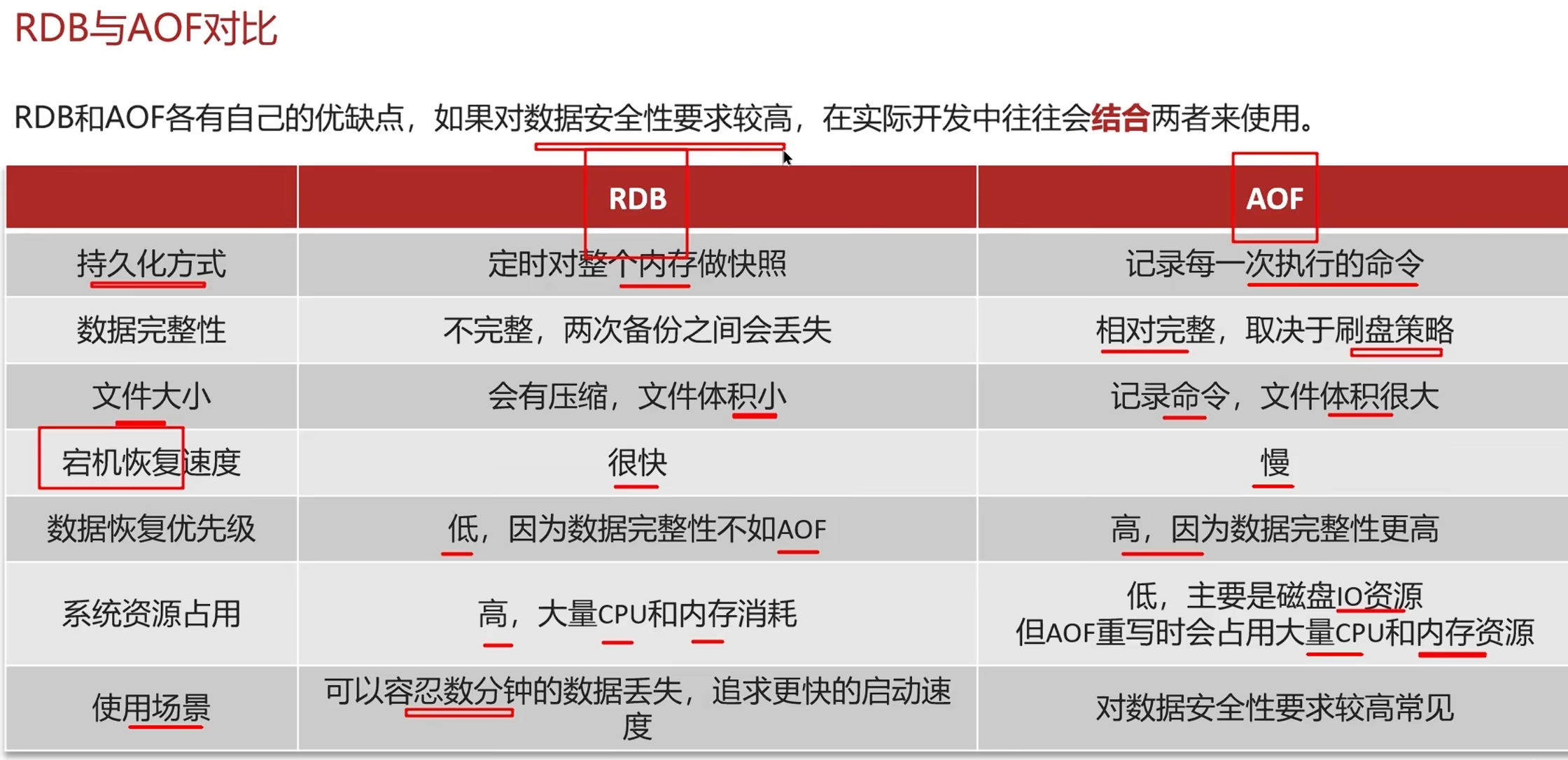
1.5redis持久化(存到磁盘)
RDB介绍:
建议bgsave,防止阻塞进程
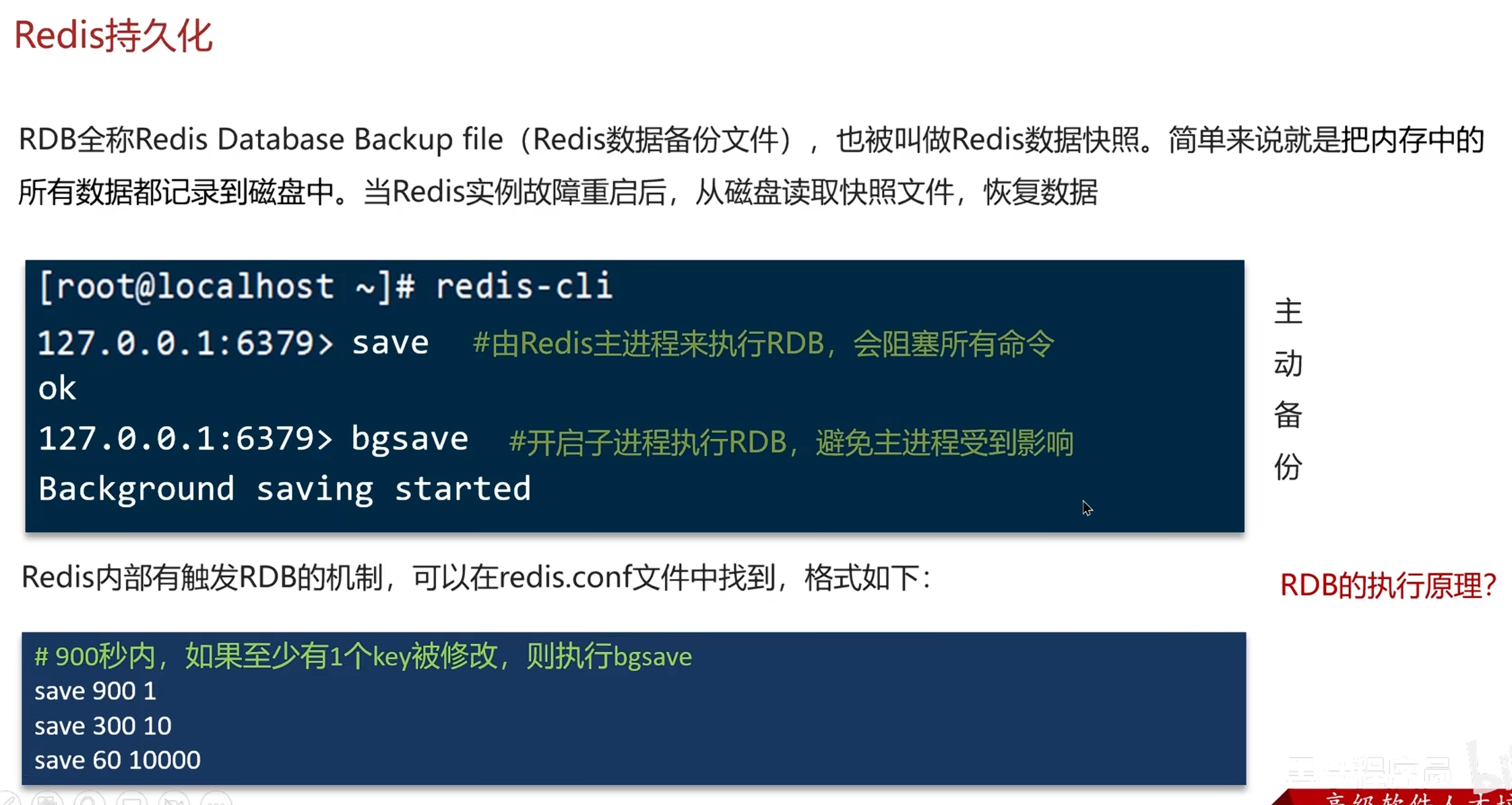
原理:
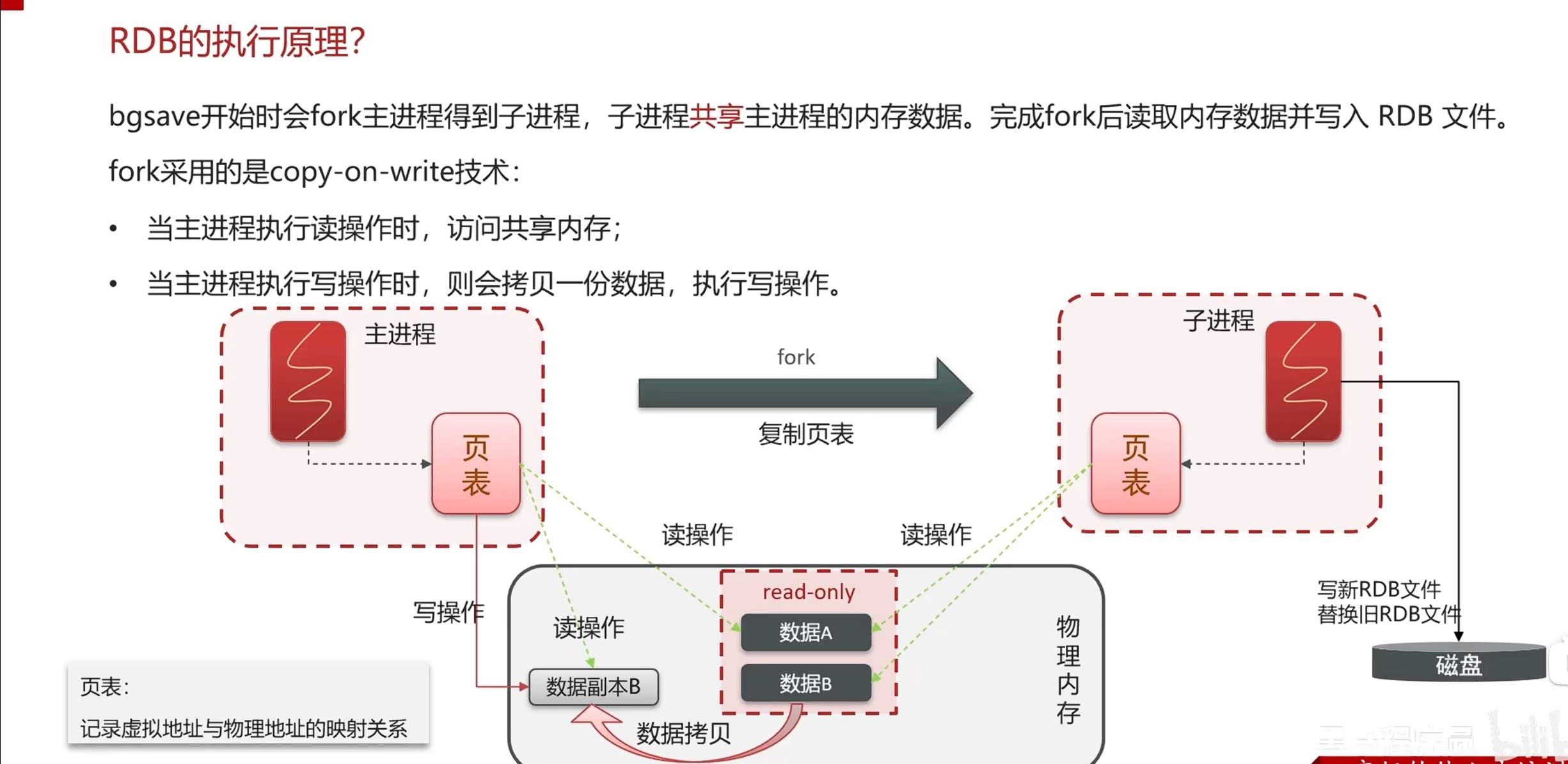
这里只是页表的复制,快
AOF介绍:
原理
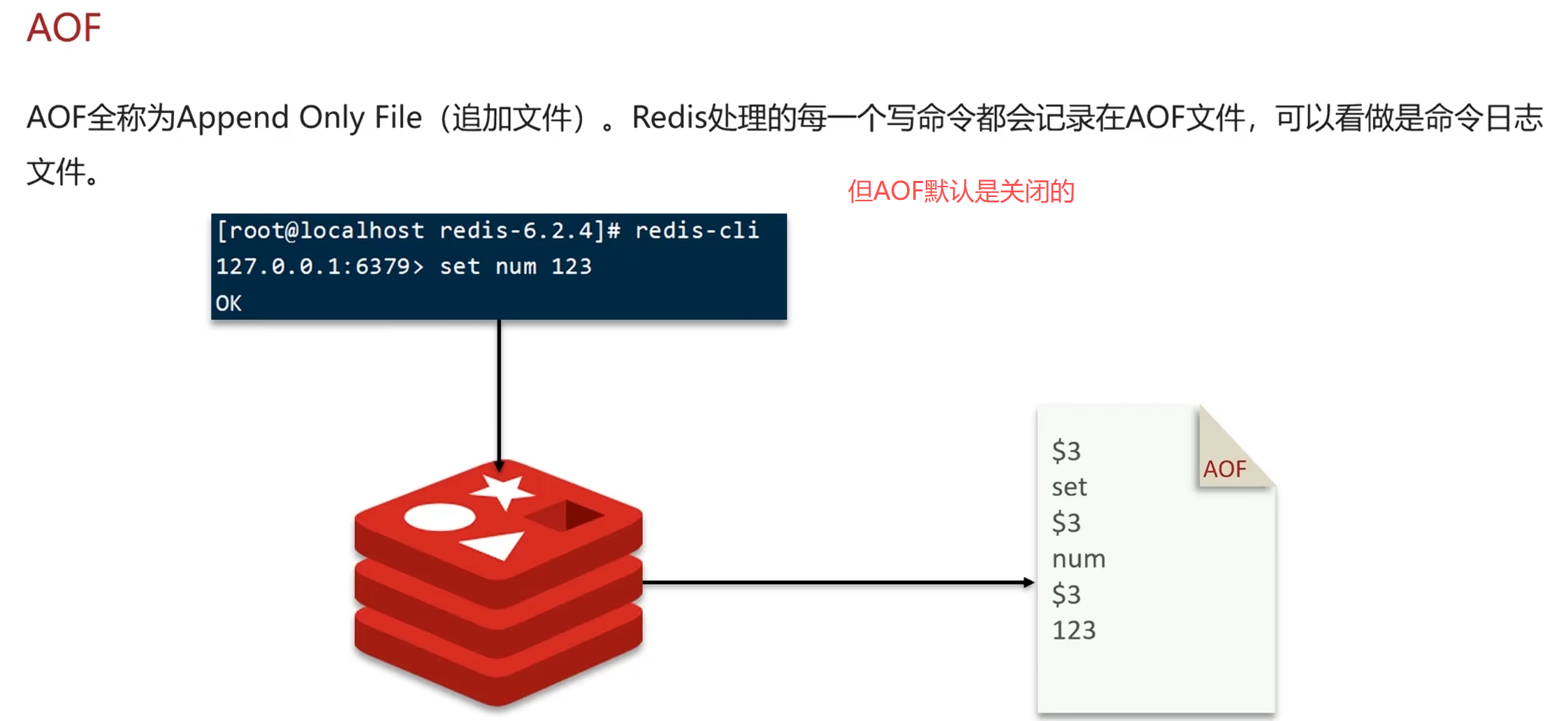



特点
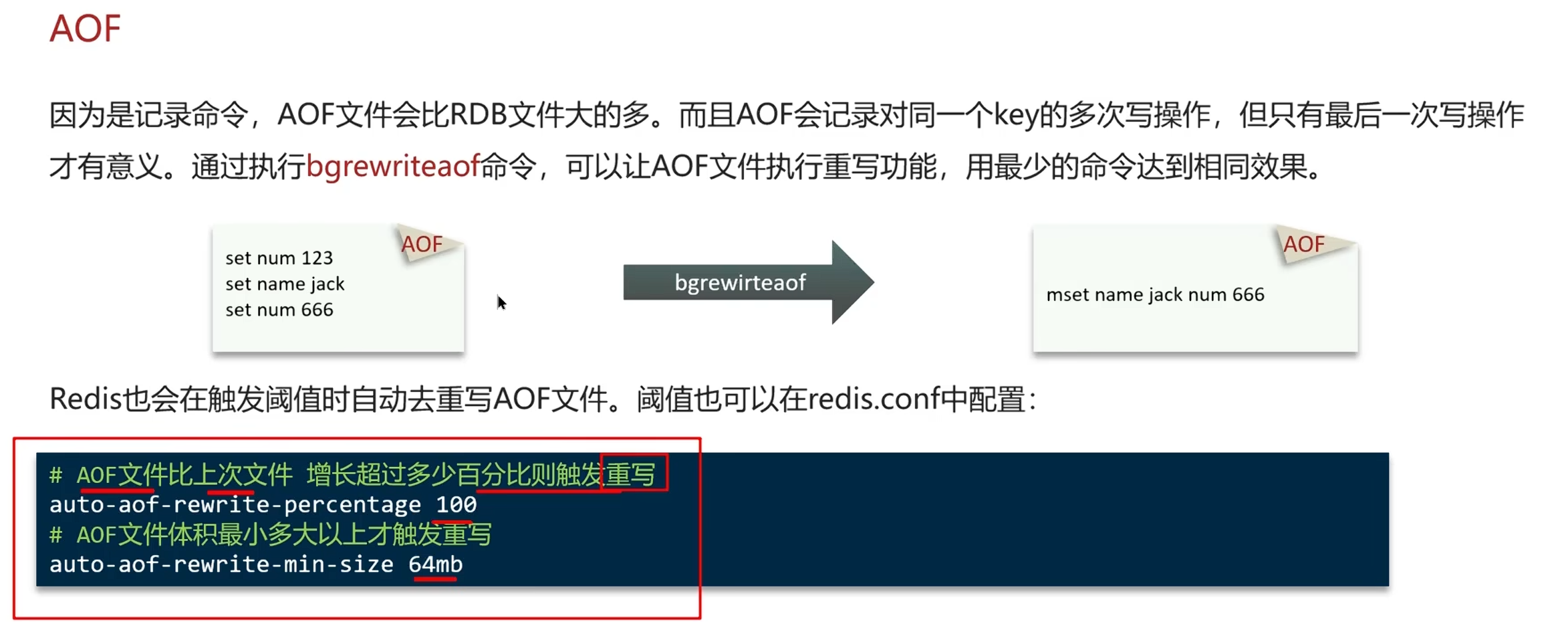
对比
|----------|-----------|----------|
| 性能影响 | fork时可能卡顿 | 持续写入,影响小 |
Redis 4.0+ 混合持久化
原理: AOF 重写时,将 RDB 快照写入 AOF 文件开头,之后的增量用 AOF 追加。
效果: 兼具 RDB 恢复快 + AOF 数据安全的优点。
aof-use-rdb-preamble yes # 默认开启流程:
AOF重写触发 → 写入RDB快照到AOF开头 → 后续增量用AOF追加生产环境建议
- 都开启:RDB 用于备份,AOF 用于数据安全
- 优先用 AOF 恢复:AOF 数据更完整
- 定期备份 RDB:上传到 S3 或其他存储
| 场景 | 推荐方案 |
|---|---|
| 普通业务 | 混合持久化(RDB+AOF) |
| 对数据安全要求极高 | 纯 AOF + everysec |
| 纯缓存(丢了无所谓) | 纯 RDB 或关闭持久化 |
| 备份/迁移 | 单独生成 RDB 文件 |
总结
"Redis 持久化有两种机制:
RDB 是定时生成快照,文件小恢复快,但可能丢数据
AOF 是记录每条写命令,数据更安全,但文件大恢复慢
生产环境通常两者都开启,Redis 4.0 之后支持混合持久化,兼顾两者优点"

1.6redis--数据过期策略
惰性删除
惰性删除:设置该key过期时间后,我们不去管它, 当需要该key时,我们再检查其是否过期,如果过期,我们就删掉它,反之返回该key

定期删除

总结


1.7redis-数据淘汰策略




总结


1.8分布式锁场景

真实场景:抢卷
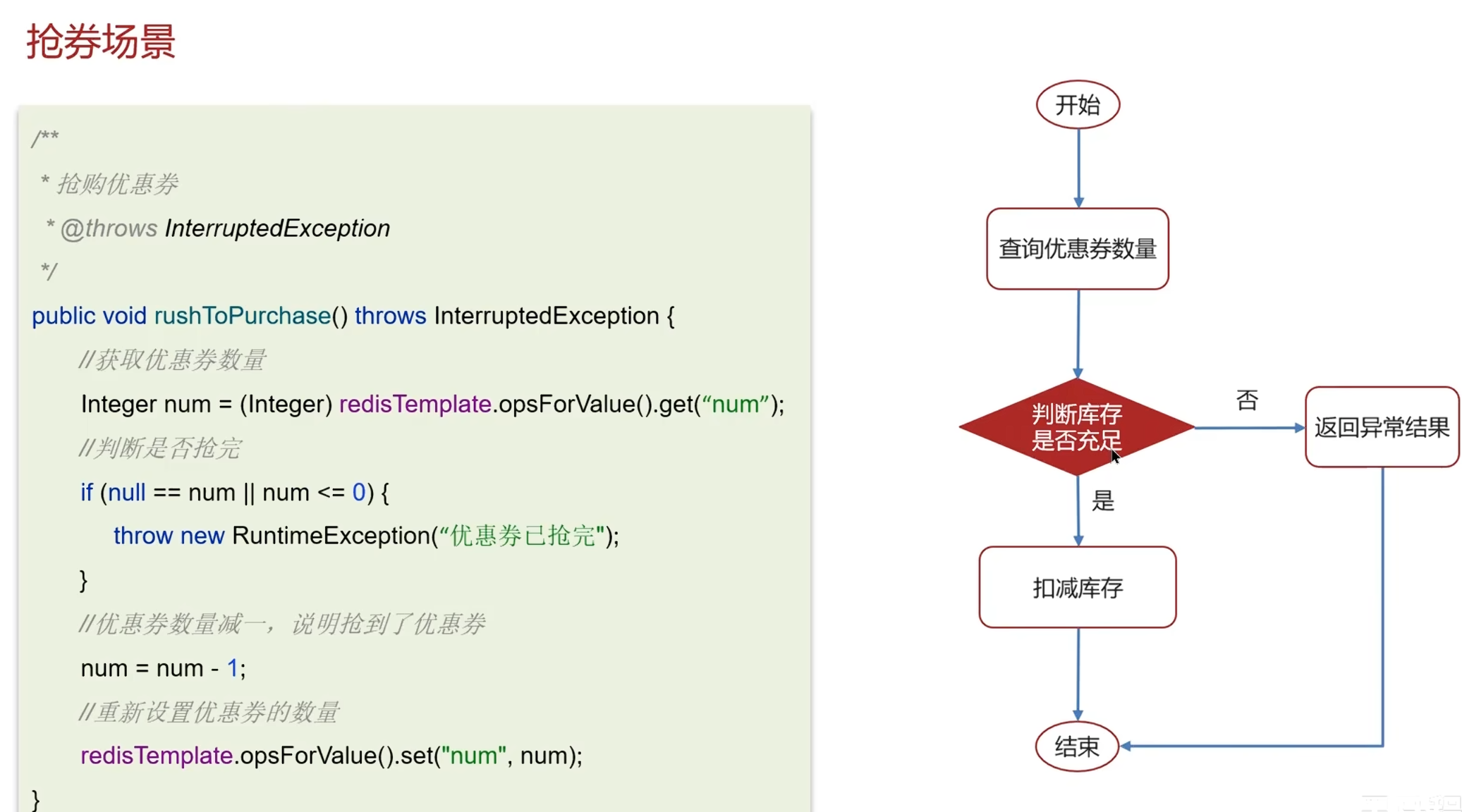
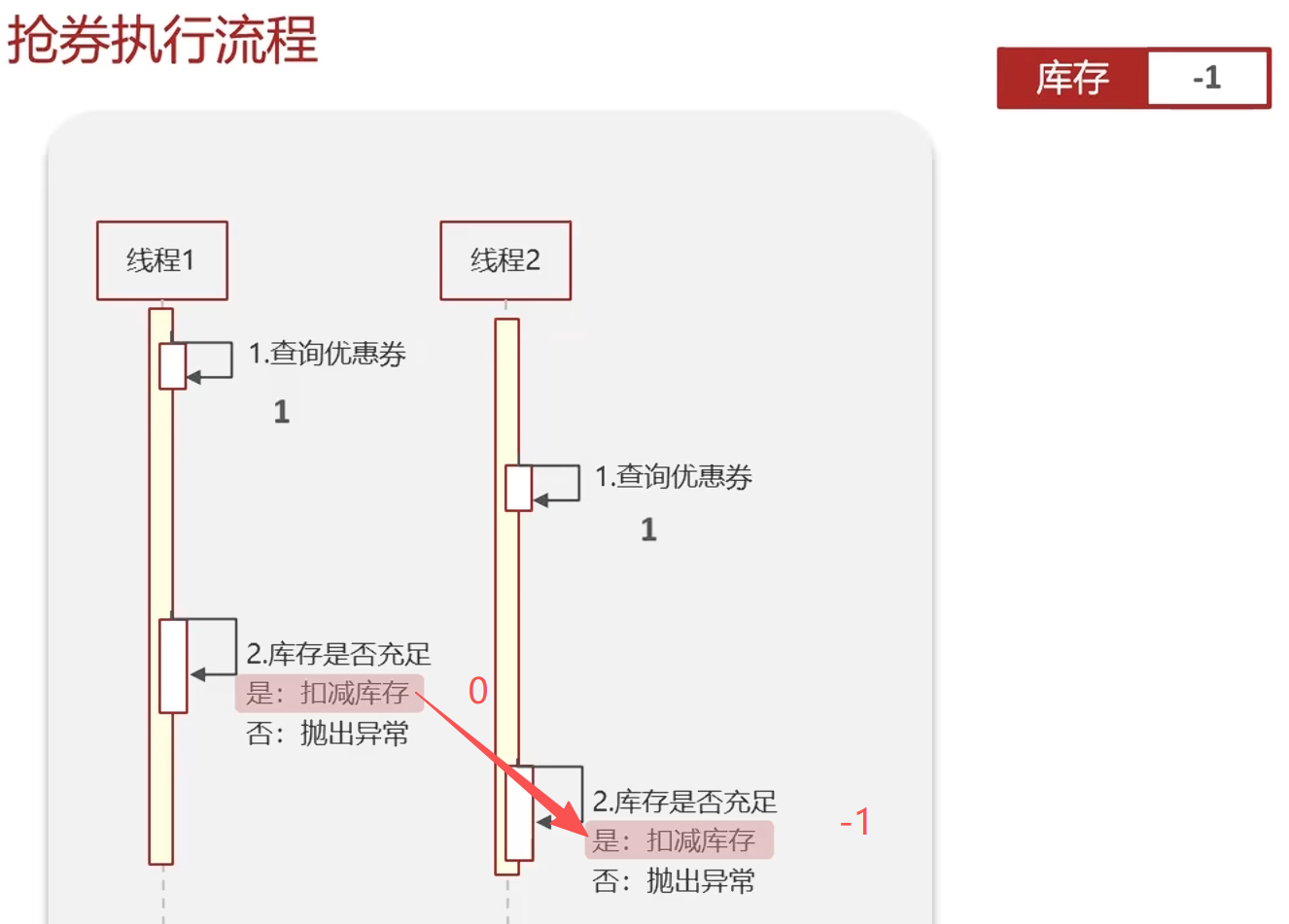
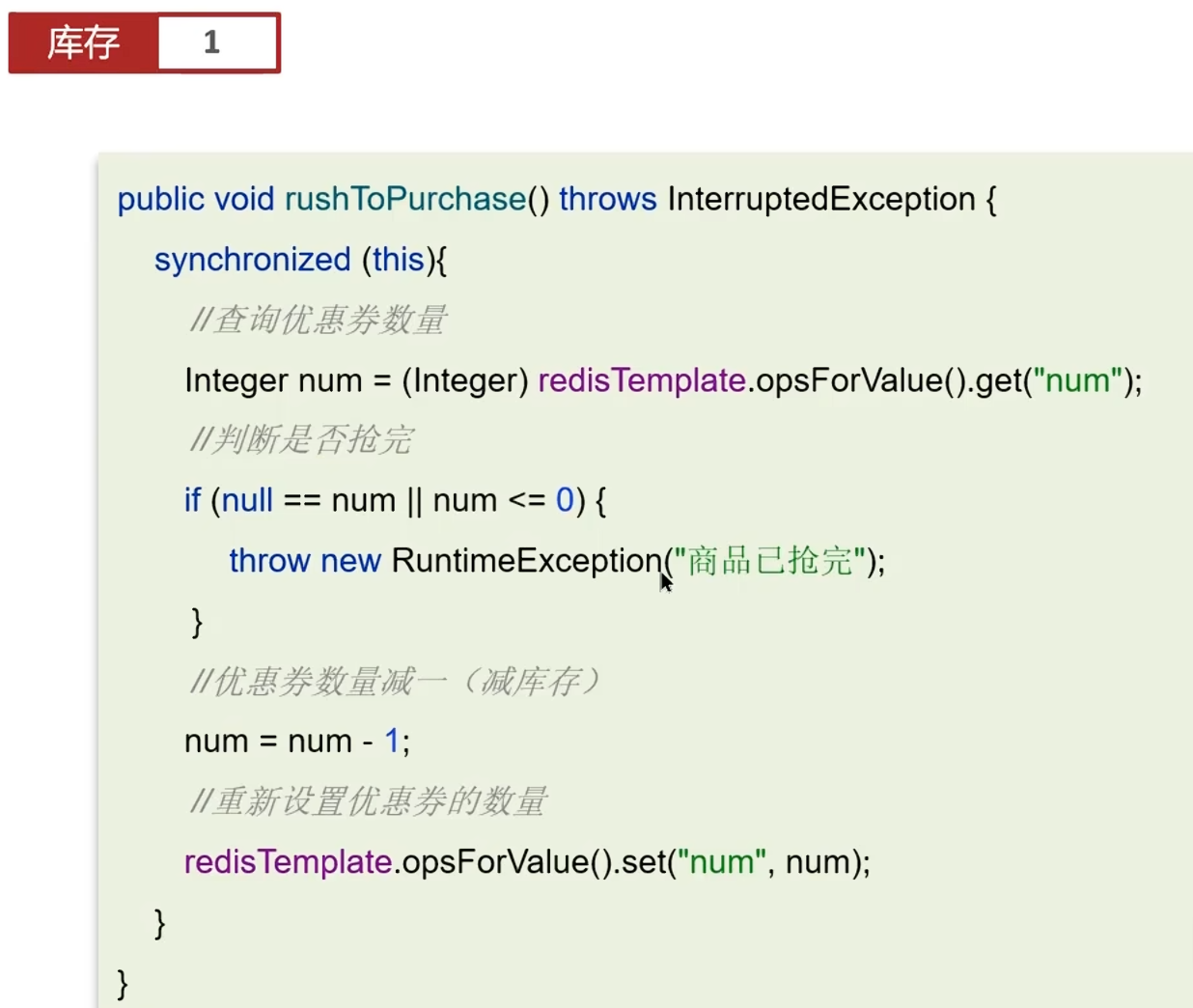
sync是本地锁,解决不了集群锁
分布式集群部署情况(为了支持更多并发请求)使用分布式锁(外部锁:比如redis)
即:单体就是本地锁,集群就是分布式锁代替本地锁
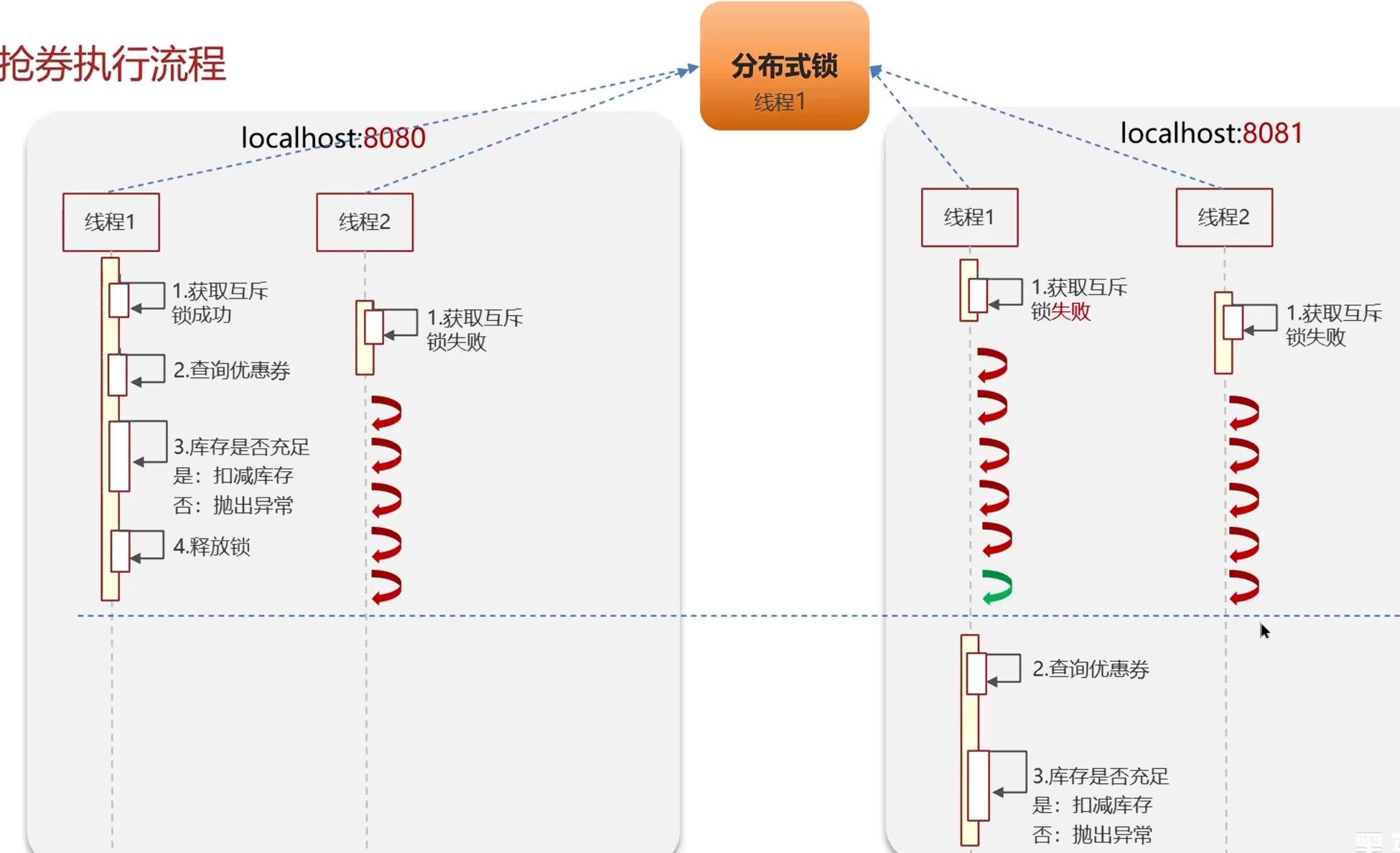
1.9redis分布式锁-实现原理(setnx,redission)
setnx
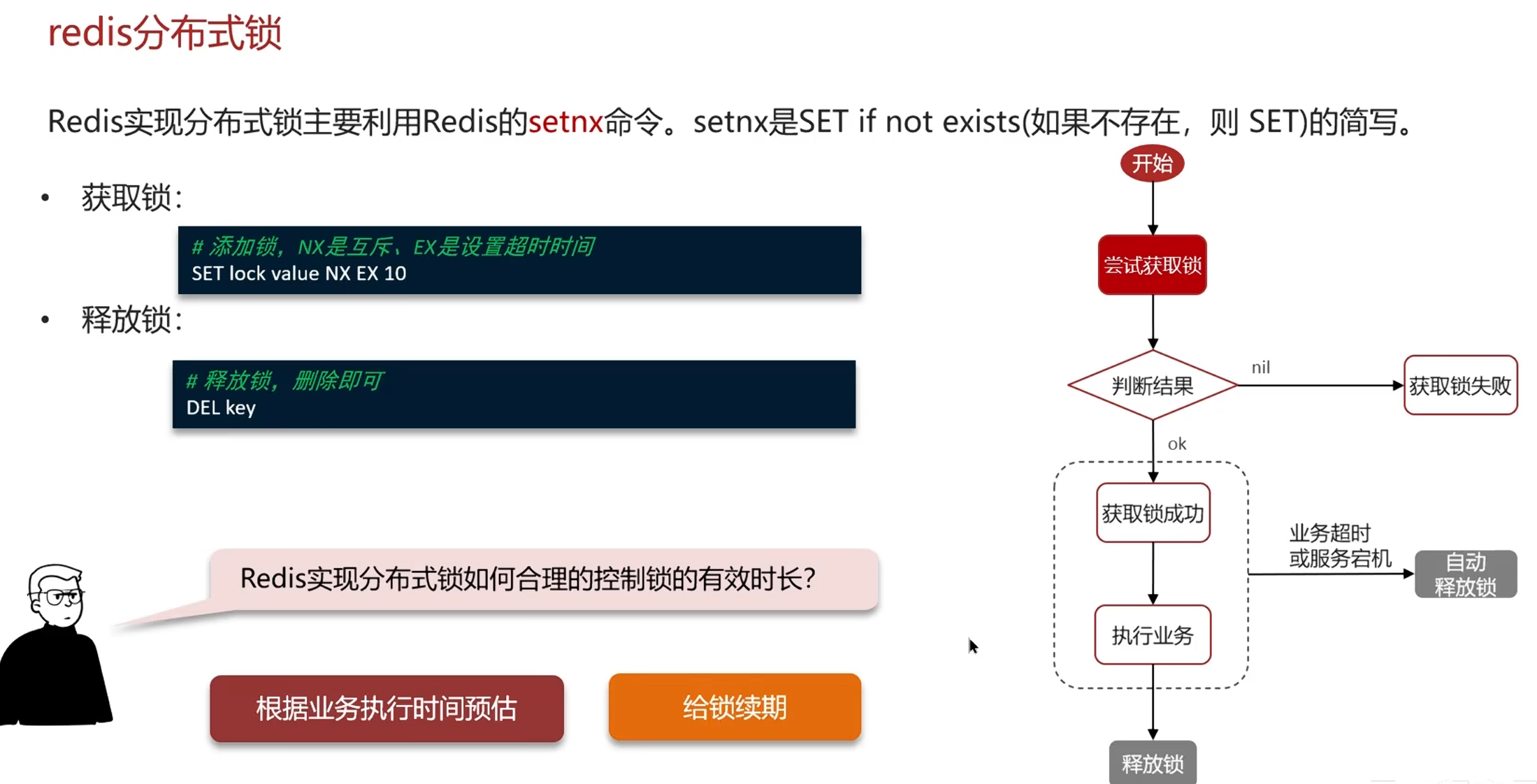
用另一个线程监听,如果时间过长,就增加 这个线程持有锁的时长
redission
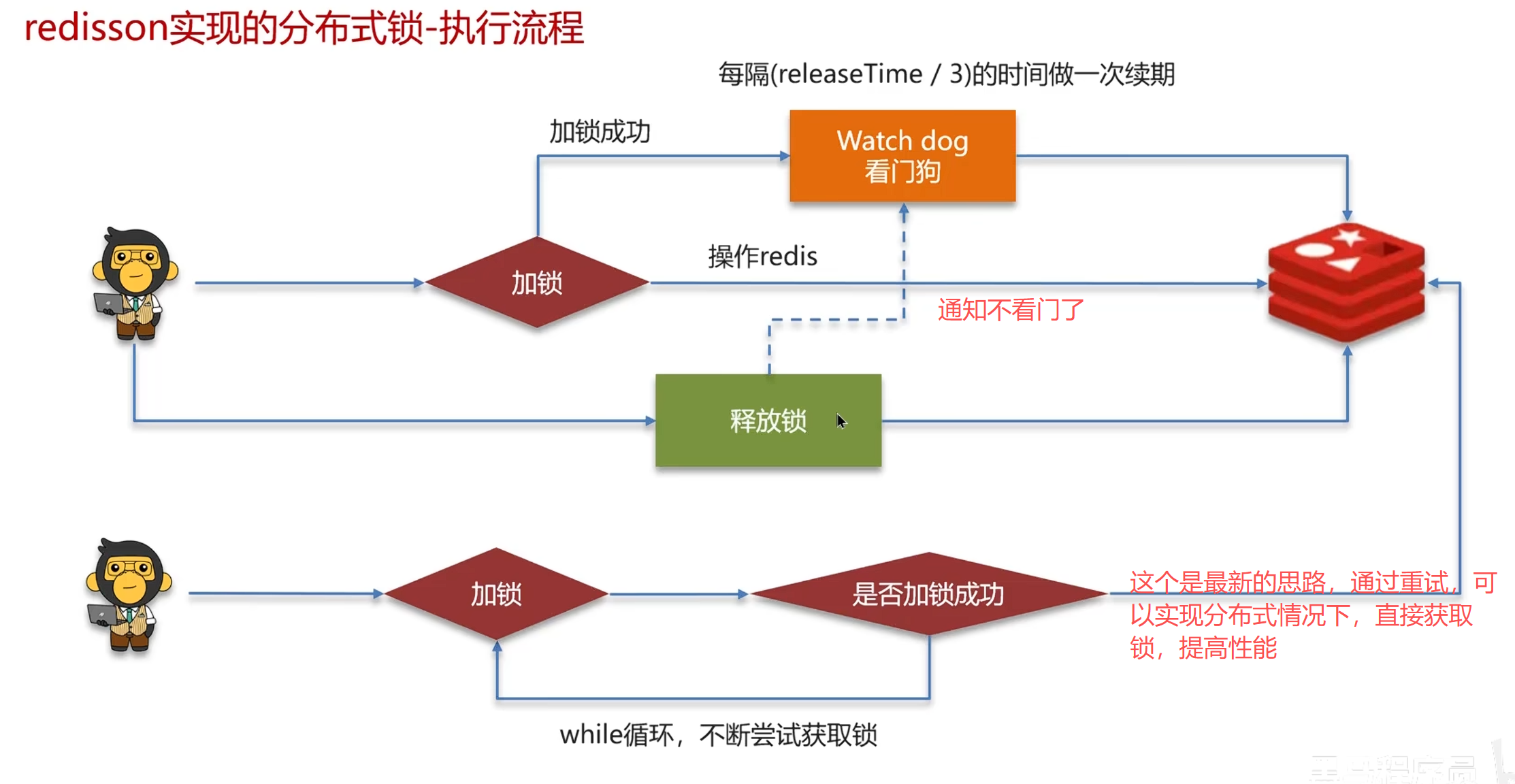
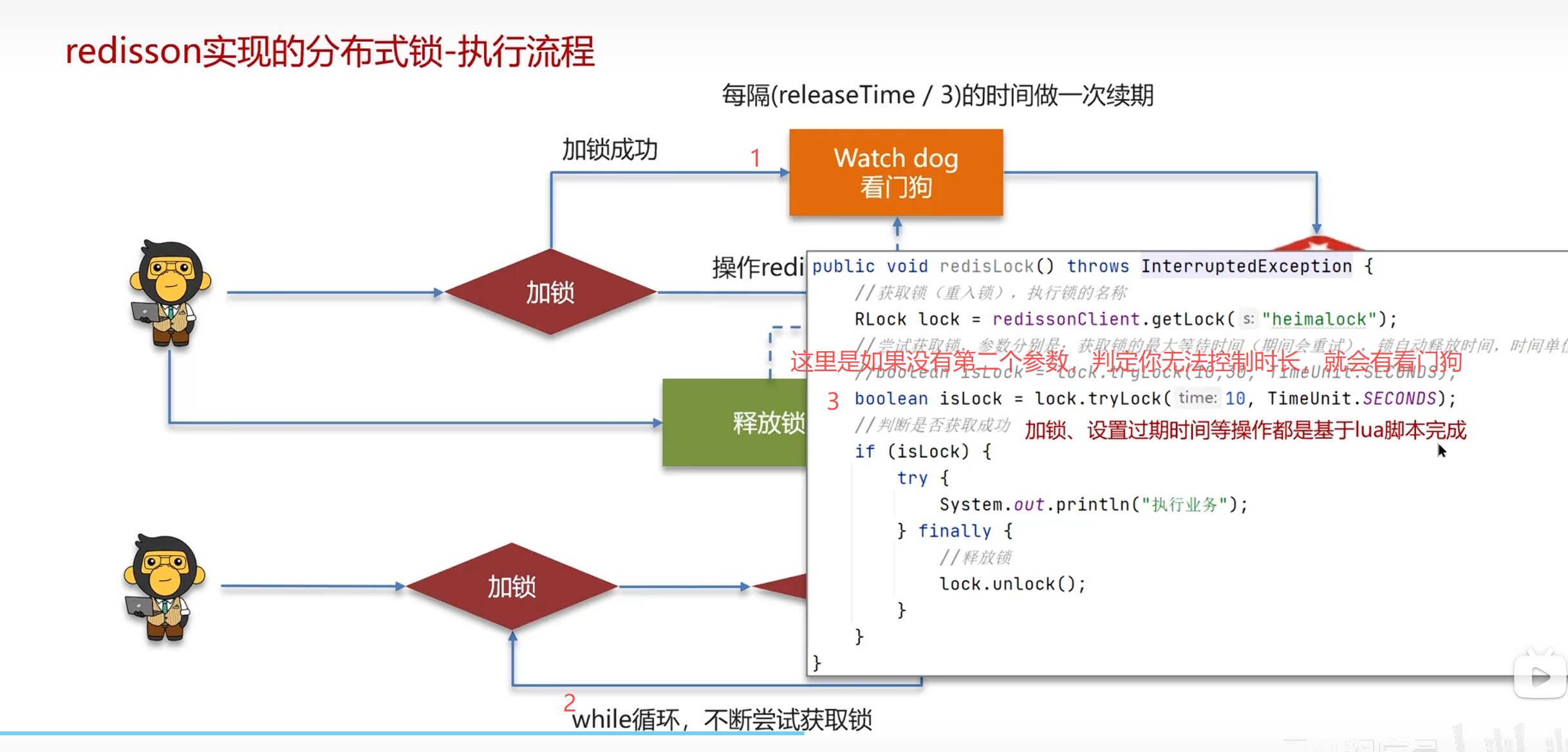
lua脚本是可以调用redis命令,同时调用多条redis命令,保证原子性
Redisson 主动把 Lua 脚本提交给 Redis 执行,借助 Lua 多命令原子性,实现分布式锁加锁、解锁无并发问题
Redis 执行 Lua 脚本有三条铁规则:
- 整个脚本从头到尾独占 Redis 主线程
- 脚本没跑完,其他客户端命令全部排队等着
- 不会被其他请求打断、不会中间切换任务
相当于:把多条 Redis 命令包成一条不可分割的大命令,天然原子性
Redis 是服务端中间件;Redisson 是 Java 客户端框架,用于操作 Redis,可向 Redis 提交 Lua 脚本。Lua 脚本内部由多条 Redis 原生命令组成,执行时会独占 Redis 主线程,全程不被打断,一口气执行完毕后再释放线程
可重入
注意
redis实现的分布式锁是不可重入的(同时获取锁)
redission实现的分布式锁是可重入的
**可重入:**同一个线程,已经拿到锁了,再去抢同一把锁,还能直接拿到,不会自己把自己堵死
过程:
- key 是锁名
- field 是线程 ID
- value 是重入次数 同一线程加锁时,次数 + 1;解锁时次数 - 1,减到 0 才真正释放锁,从而避免了自己阻塞自己的死锁问题
可重入的好处:
业务复杂,粒度要细的时候使用
可以避免多个锁间产生死锁的问题

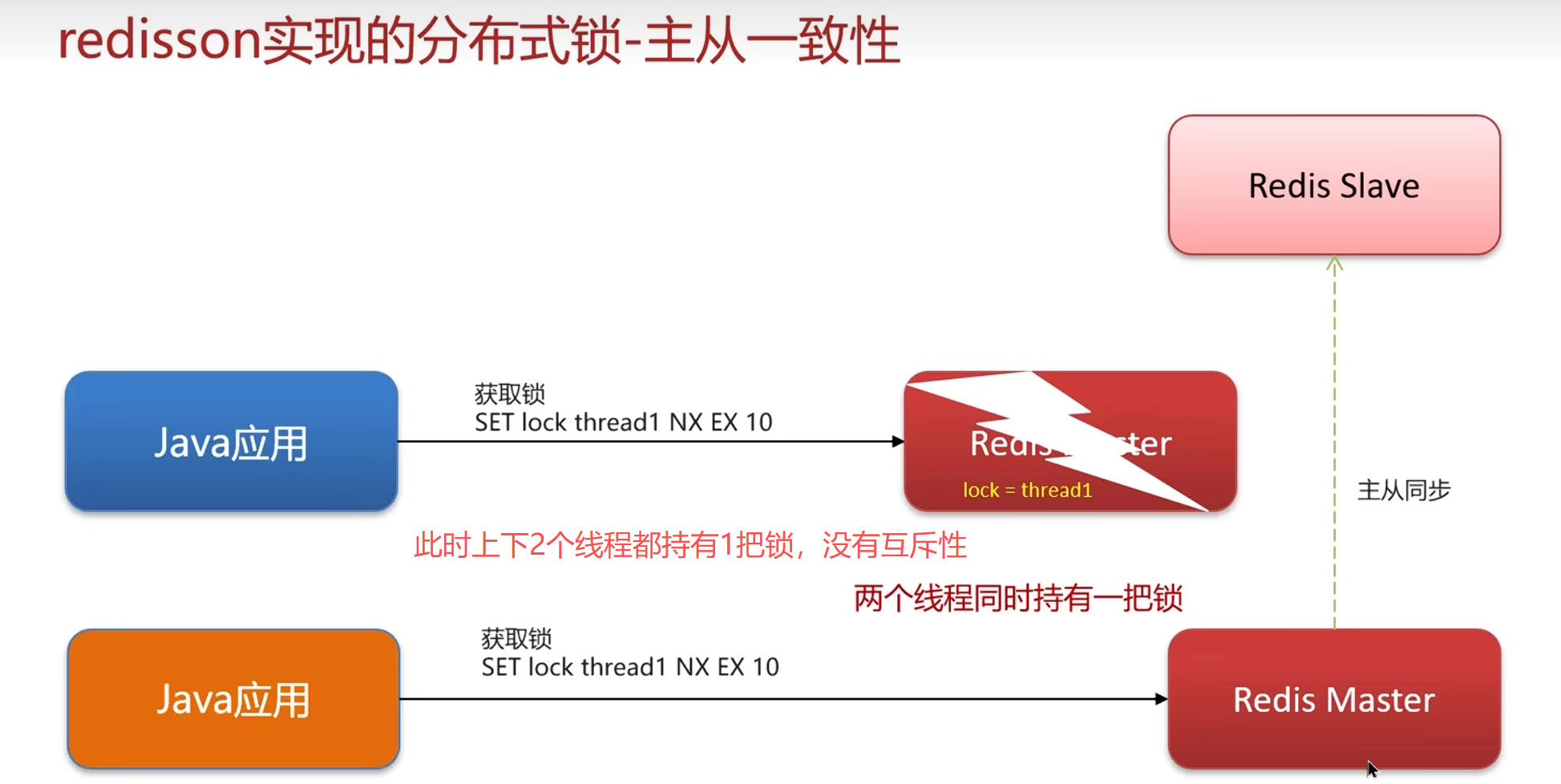
主从数据一致
主节点负责增删改,从节点负责查
当主节点改数据要同步给从节点,主节点宕机后就需要从节点变成主节点
红锁
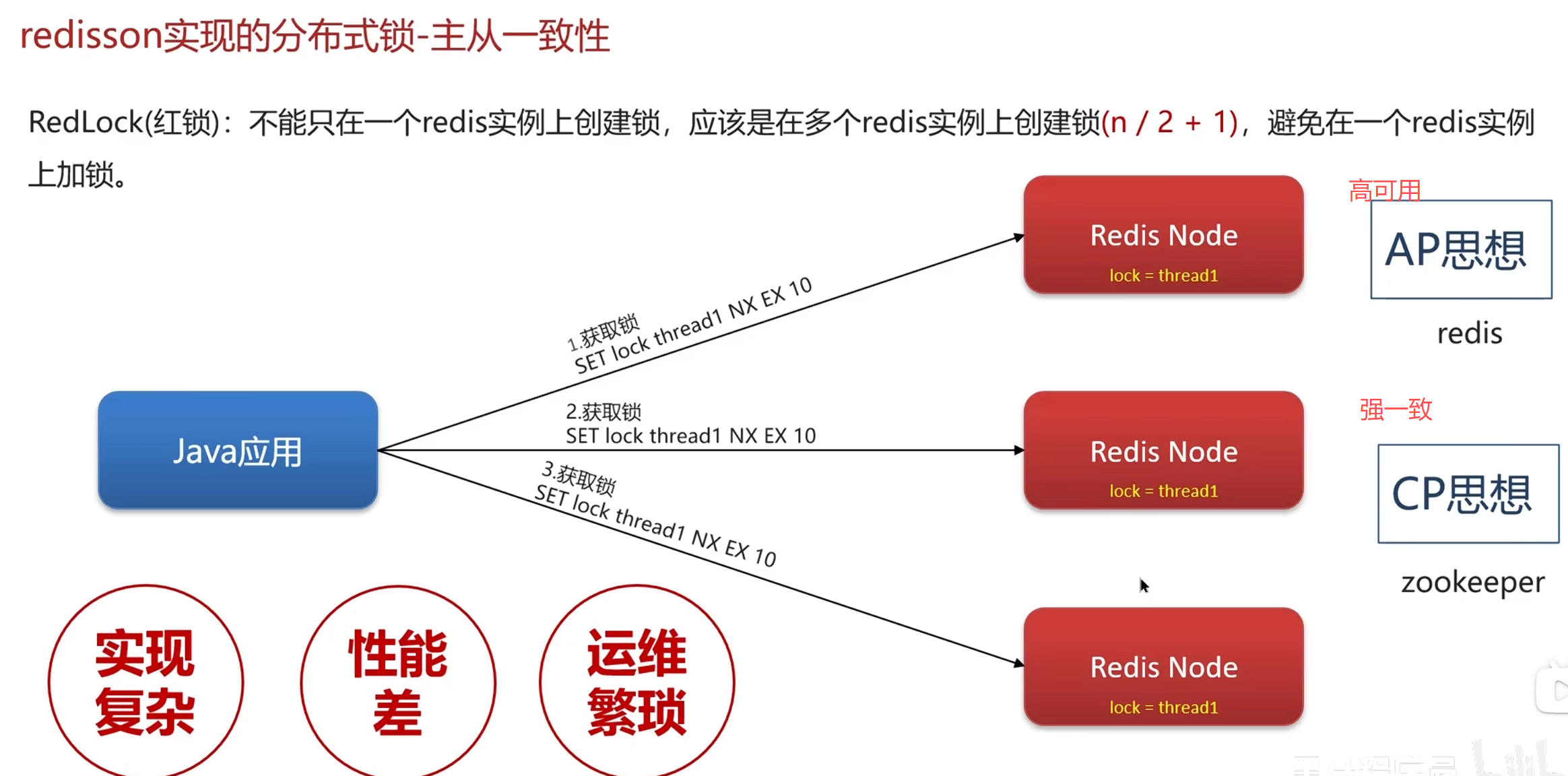
总结


其他面试问题
1.10 主从复制及主从同步流程

主从复制
特点:
读写分离
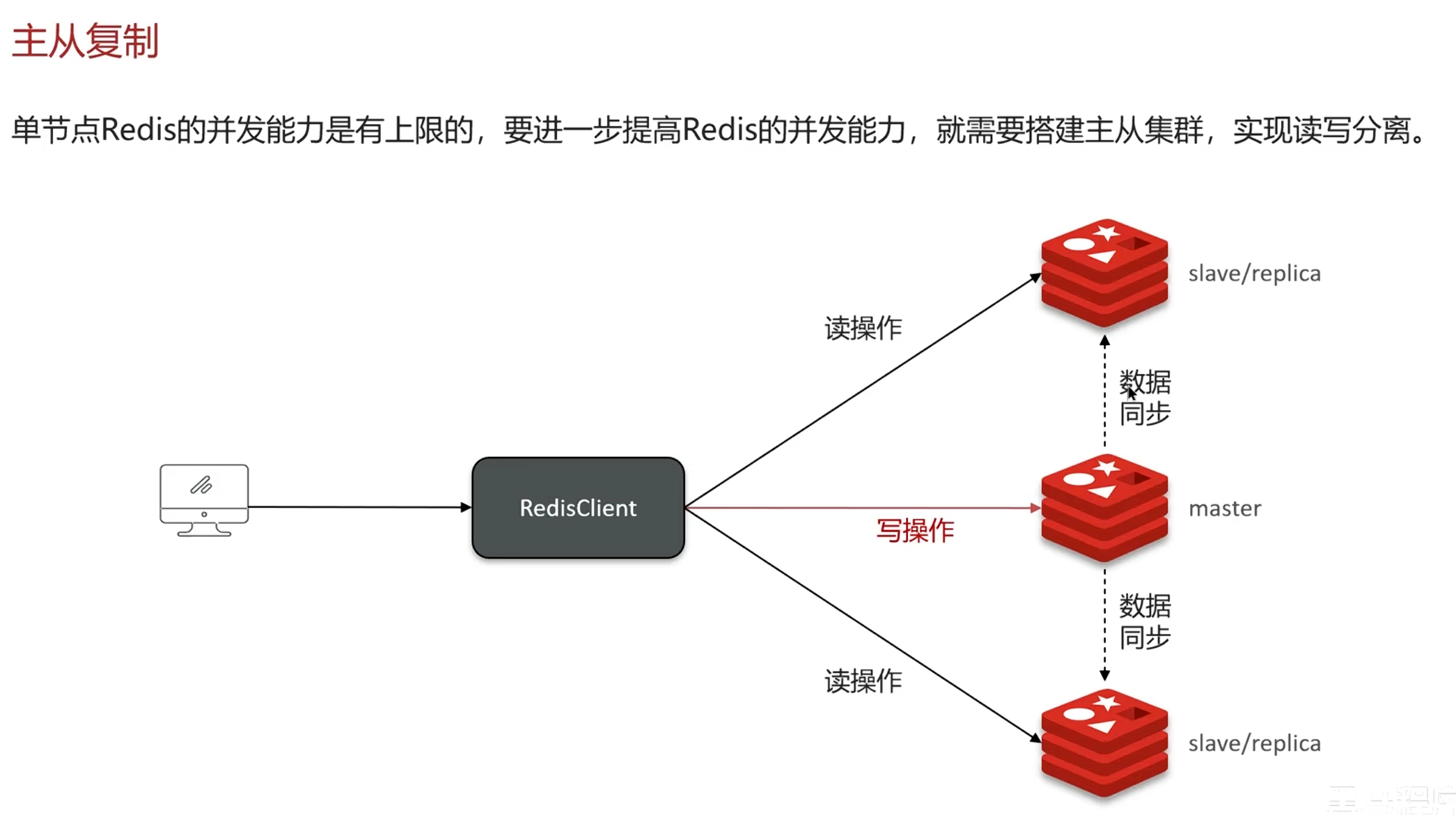
原理

总结步骤:
1.对比replid,然后主节点判断是否为第一次,是就全量
2.主节点执行bgsave,生成RDB给从节点执行
3.主节点执行期间RDB会生成日志文件给从节点执行,使得数据一致
增量同步
原理
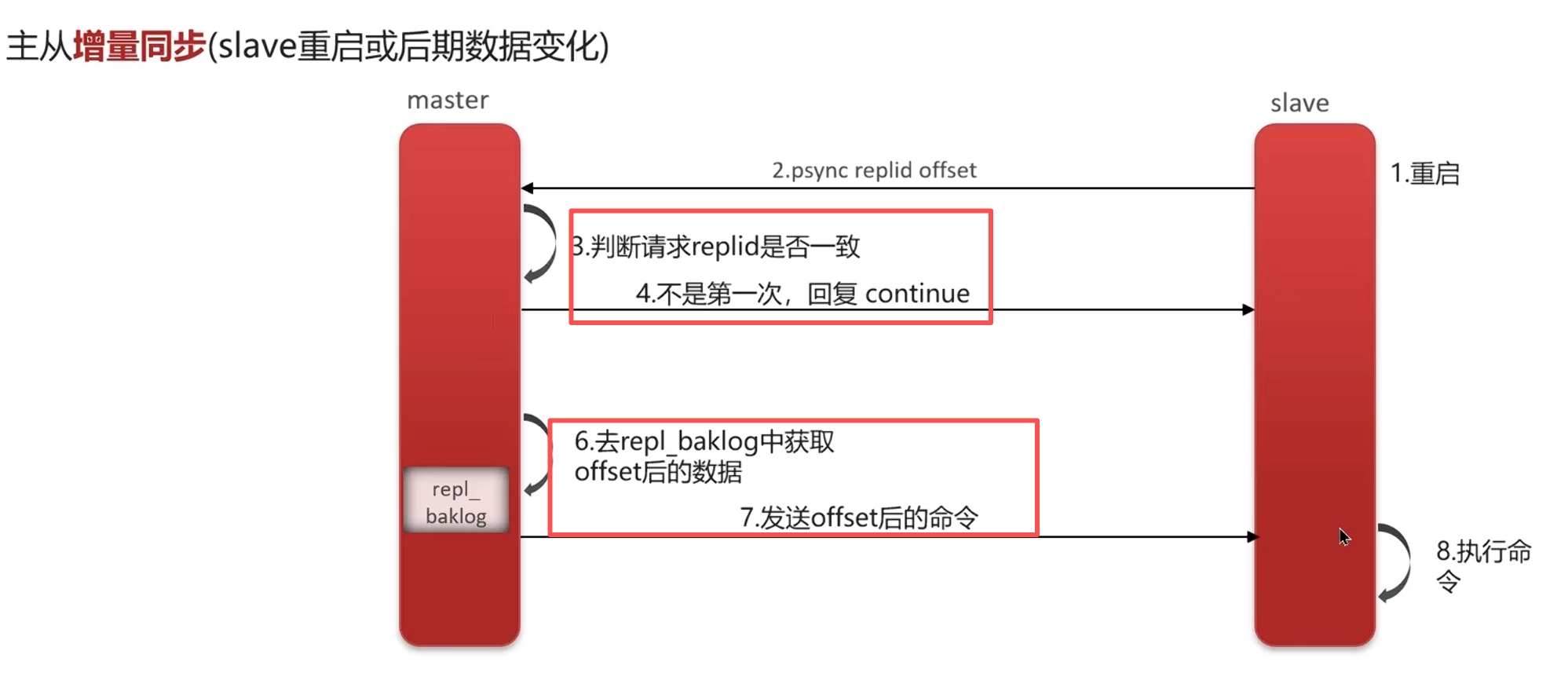
 总结
总结

1.11哨兵模式和集群脑裂
哨兵介绍
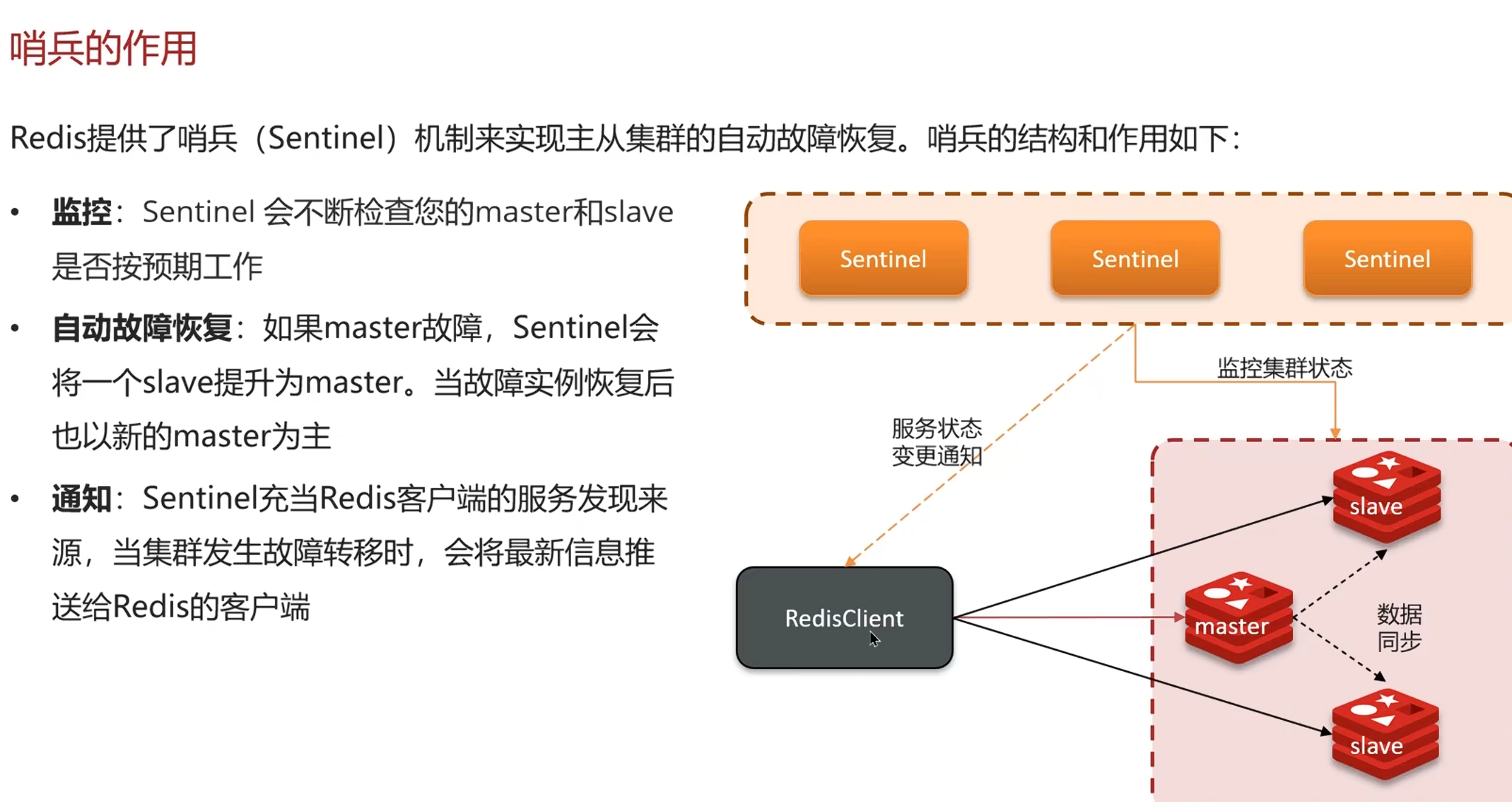
了解哨兵
