分布式架构和微服务架构
-
分布式: 服务拆分 , 拆了就行
-
微服务: 指非常微小的服务 , 通常指不能再继续拆分的服务
微服务是 一种经过良好架构设计的分布式架构方案
SpringCloud
SpringCloud是 分布式微服务架构的一站式解决方案
前置依赖
apt install openjdk-17-jdk
微服务拆分原则
-
单一职责: 每个服务只负责自己的任务 , 每个服务的定义和边界都清晰,
-
服务自治: 服务自己能够独立治理; 每个服务能够独立开发, 构建, 部署 , 运行, 测试
-
单向依赖: 不能存在 循环依赖, 双向依赖
项目创建
父子工程项目
依赖
DependencyManagement: 只是声明依赖,并不实现Jar包的引入, 如果子项目需要用到相关依赖(这个依赖在父工程里声明了),同时这个没有指定具体版本, 那么就从父工程里读取 version ; 子项目指定了具体版本,就用子项目指定的
(此外父工程的打包方式是pom, 不是jar , 这里需要手动指定packaging 声明)
**Dependencies:**将所有依赖的jar包添加到项目中 , 子项目也会继承这个依赖 (直接引入依赖,并且被子项目继承)
<packaging>pom</packaging> // 父工程的 打包方式 应该是 pom , 而不是jar <properties> <maven.compiler.source>17</maven.compiler.source> <maven.compiler.target>17</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <java.version>17</java.version> <mybatis.version>3.0.3</mybatis.version> <mysql.version>8.0.33</mysql.version> <spring-cloud.version>2022.0.3</spring-cloud.version> </properties> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.1.6</version> <relativePath/> </parent> <dependencies> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> </dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>${mybatis.version}</version> </dependency> <dependency> <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> <version>${mysql.version}</version> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter-test</artifactId> <version>${mybatis.version}</version> <scope>test</scope> </dependency> </dependencies> </dependencyManagement>
实现
-
两个接口 , 一个获取 product的数据 , 一个 获取 order的数据
-
两个接口都从 url中获取数据: 如果url是: /product/1 , 那么 下面 productId 的值就是 1
@RestController @RequestMapping("/product") public class ProductController { @Autowired private ProductService productService ; // 根据 url来获取参数 @RequestMapping("/{productId}") // 指定从url获取参数赋值给 productId public ProductInfo getProductInfo(@PathVariable("productId") Integer productId){ return productService.getById(productId); } } @RestController @RequestMapping("/order") public class OrderController { @Autowired private OrderService orderService ; // 根据 url来获取参数 @RequestMapping("/{orderId}") public OrderInfo getProductInfo(@PathVariable("orderId") Integer orderId){ return orderService .getById(orderId); } }
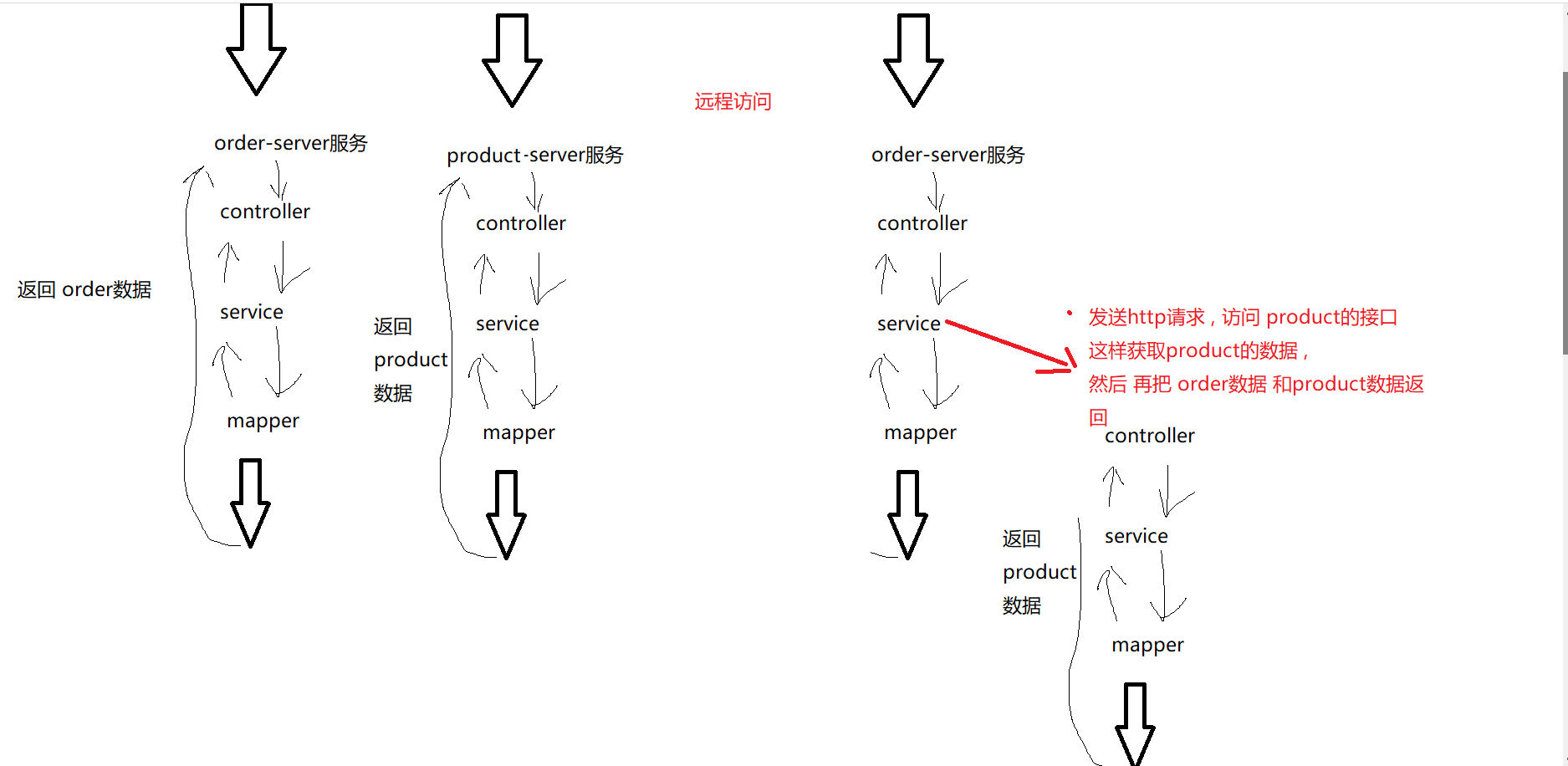
远程调用
-
当 访问 order 接口是 , order微服务 向 product服务 发送http请求 , 获取product的数据, 和order数据一同返回
-
(通过远程调用,将 order数据 和 product数据 一起返回)
RestTemplate
Representation State Transfer : 表现层资源状态转移
使用Spring提供的 RestTemplate , 实现远程调用
1. 先定义好一个ResTemplate 的Bean , 方便使用 @Configuration public class BeanConfig { @Bean public RestTemplate restTemplate(){ return new RestTemplate() ; } } 2. 在orderService 里使用 RestTemplate 来调用 product微服务的接口url , 来获取product数据 @Service public class OrderService { @Autowired private OrderMapper orderMapper ; @Autowired private RestTemplate restTemplate ; public OrderInfo getById(Integer orderId) { OrderInfo orderInfo = orderMapper.getById(orderId); // 构造url,就是获取 product数据是的地址 从 orderinfo里获取 productid String url = "http://localhost:9090/product/"+ orderInfo.getProductId() ; // 通过远程调用访问这个url , 来获取 productInfo对象 ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class); // 获取到 的product 给 orderinfo , 返回 orderInfo.setProductInfo(productInfo); return orderInfo; } }

-
当访问 url: localhost:9091/ order/1 ==> 先 根据 orderId=1 获取order数据
-
然后通过RestTemplate 访问 localhost:9090/product/ product的id , 来获取 product数据
-
最后合并两个数据返回
注册中心
1. 上面的使用 RestTemplate远程调用, 使用的url是固定的 , 如果 应用发生变更, 那么还要去修改上面的URL 2. 所以微服务有了注册中心 解决思路 1. 服务启动/变更 , 向 注册中心 报道, 注册中心记录 应用 和 IP 的关系 2. 调用方调用时, 先从注册中心 获取 服务方的IP, 再去服务方调用
注册中心
注册中心主要有三种角色:
1. 服务提供者(server):一次业务中 , 被其他微服务调用的服务 : 就是 提供接口 给其他微服务
2. 服务消费者(Client): 一次业务中 , 调用其他微服务的 服务 : 就是 调用其他微服务提供的接口
3.服务注册中心(Registry): 用来保存server(服务提供者)的消息 , 当server发生改变时, Registry 也会同步改变 ; (服务和注册中心通过 心跳监测 保持通信, 如果 注册中心 长时间无法和某个服务通信 , 那么删除掉这个服务的实例)
服务注册: 服务提供者 在启动时 , 向Registry注册自身服务 , 定期向 Registry 发送心跳
服务发现: 服务消费者中 注册中心查询服务提供者的 地址 , 并且通过这个 地址 调用 服务提供者 提供的 接口
CAP理论
CAP理论是 分布式系统设计中 最基础,核心的理论
CAP理论(重点)
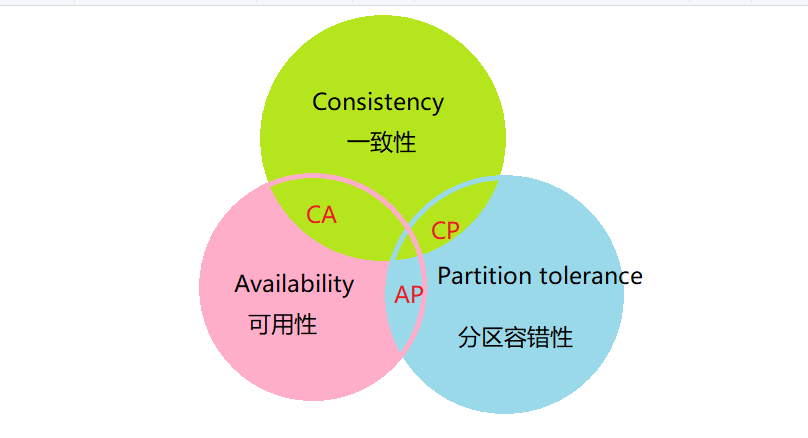
1. 一致性: CAP理论中的 一致性 是 强一致性 : 所有 节点 再同一时间 具有相同的数据
2.可用性: 保证名称请求都 有响应 (响应可能是旧的(不对的))
3. 分区容错性: 网络分区后 , 系统仍然能够对外提供服务
1. CAP理论表示 : 一个分布式系统中不可能 同时满足三个条件: 一致性,可用性,分区容错性 只能同时满足两个 2. 同时 Partition tolerance 分区容错性 是 必须要保证的一个条件 ;(因为分布式必须保证 , 某个节点挂了 ,系统仍然能够提供服务) 3. 所以只能是 : CP 或 AP 结构; CP(能保证 一致性,但无法保证 可用性) , AP(能保证可用性, 不能保证一致性)
一致性
强一致性 和 非强一致性 ,
1. 当 两个 数据库 a ,b == > 给a修改数据后 , a 会同步给 b , 这样来保证 a和b的数据一致 2. 他们之间是通过网络来连接的 , 如果当中网络 无法立刻传输 或 发生了问题 , a 无法 及时 同步给 b , 那么 此时 a 有新数据: s1 , b 有旧数据: s0 数据无法及时同步给b , 导致两个数据不同; 当有用户访问 b的 数据==> 1. 强一致性: 如果不同,那么就选择不返回 (因为要保证,同一时间,每个节点的数据 相同) 2. 非强一致性: 返回旧的数据/错的数据: s0 ;直到最后,我保证最后的数据,是相同的就可以了 (不保证, 同一时间, 每个节点的数据 相同)
服务可用性
可用性保证 每个请求 都有 结果返回 , 就算 返回的 数据是 错的
1. 当 两个 数据库 a ,b == > 给a修改数据后 , a 会同步给 b , 这样来保证 a和b的数据一致 2. 他们之间是通过网络来连接的 , 如果当中网络 无法立刻传输 或 发生了问题 , a 无法 及时 同步给 b , 那么 此时 a 有新数据: s1 , b 有旧数据: s0 数据无法及时同步给b , 导致两个数据不同; 当有用户访问 b的 数据==> 1. 可用性: 肯定要 有数据返回, 所以 及时 a 和 b的数据不同, 也不影响 我返回数据
分区容错性
分区容错性,是 最需要保证的 , 分区后 , 无论哪个节点出现了问题 , 都要保证系统 能够对外提供服务
1. 当 两个 数据库 a ,b == > 给a修改数据后 , a 会同步给 b , 这样来保证 a和b的数据一致 2. 如果 a 挂了 , 还有b可以提供服务 , 就访问b ,
Eureka
Eureka注册中心 是 SpringCloud 服务 注册/发现 的 默认实现
主要分为两个部分:
1 . Eureka Server : 注册中心的server端 , 向微服务提供 服务注册, 发现 , 健康检查 2. Eureka Client : 服务提供者, 服务启动时, 向 Eureka Server 注册自己的信息 (ip,端口 , 服务信息) Server会保存这些信心
Eureka Server
Eureka-Server 属于独立的微服务
1. 创建服务工程 2. 引入依赖 // server 注册中心使用 eureka-server , 那么服务 则是 eureka-client <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> </dependency> 3. 添加 eureka 服务的启动类 @EnableEurekaServer // 通过@EnableEurekaServer注解 声明使用 Eureka注册中心 @SpringBootApplication public class EurekaApplication { public static void main(String[] args) { SpringApplication.run(EurekaApplication.class,args); } } 4. 配置文件 server: port: 19090 spring: application: name: eureka-server # 服务名字 eureka: instance: hostname: localhost client: fetch-registry: false # 是否从eureka server中获取数据 (自己就是注册中心, 同时只有自己一个 eureka server ,没有其他的 server 所以不需要 register-with-eureka: false #是否将自己注册 到注册中心 , (自己就是注册中心,不需要 service-url: # 设置与Eureka Server的地址,查询服务和注册服务都需要依赖这个地址 defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/ #就是 localhost:10001/eureka/ ; 后面 服务要注册就通过这个地址 连接到 eureka 5. 启动服务
输入 地址端口号 , 进入到 Eureka 界面
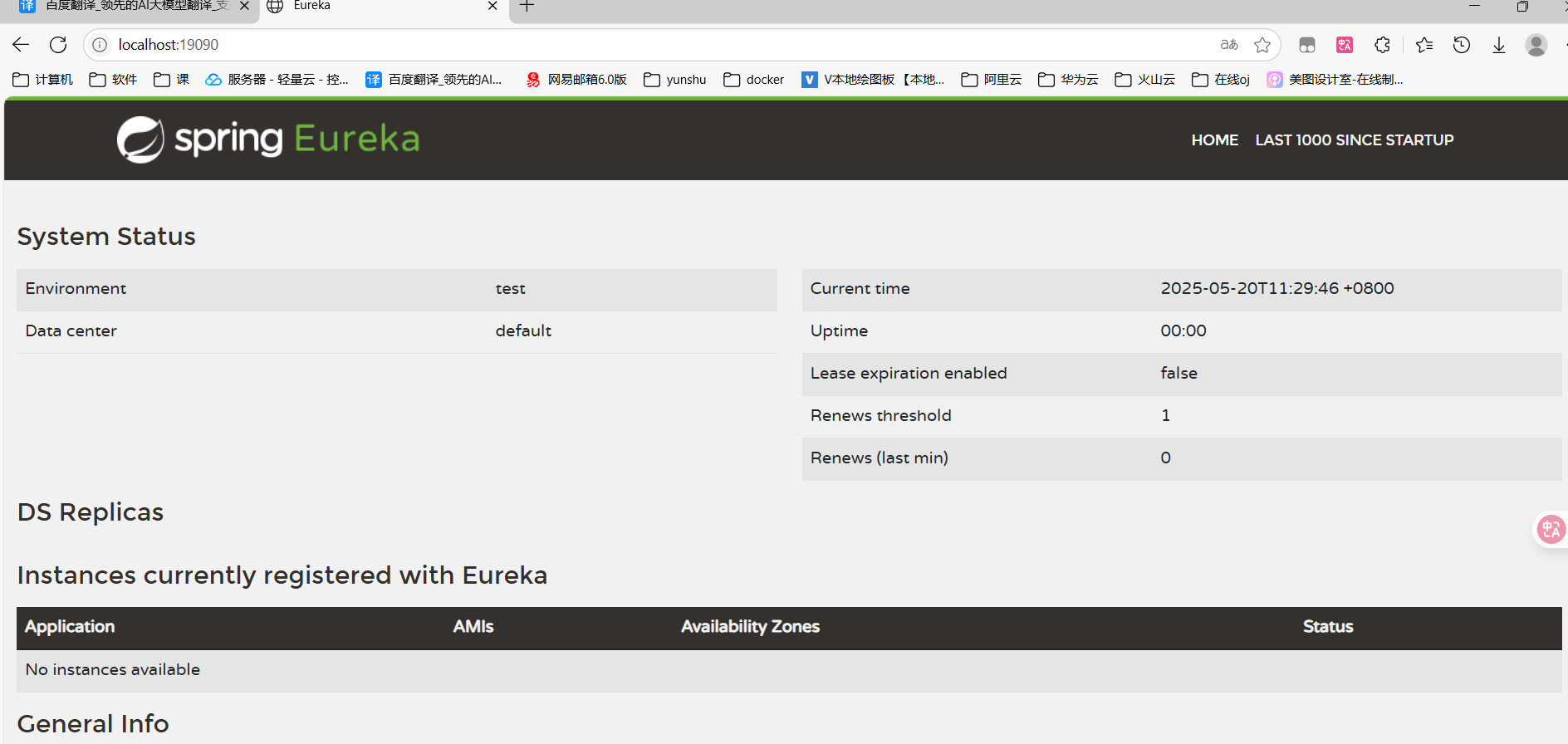
Eureka Client
1. 要使用 Eureka 注册中心注册的服务 添加依赖 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency> 2. 服务配置 添加 spring: datasource: driver-class-name: com.mysql.jdbc.Driver #新版为com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/cloud_order?characterEncoding=utf8&useSSL=false username: "root" password: "0118" //1. 微服务要有自己的 服务名称 application: name: product-server mybatis: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 配置打印 MyBatis⽇志 map-underscore-to-camel-case: true # 配置驼峰自动转换 server: port: 9090 // 2. Eureka 的 连接到 server的配置 eureka: client: service-url: defaultZone: http://127.0.0.1:19090/eureka // 连接地址是 上面 server 的配置

- 启动服务
刷新 Eureka Server 页面后 , 可以看到 注册的 服务 : 状态: 机器名字 : 服务名称 : 端口号

以此类推,将order-server也注册到 注册中心
Eureka 服务发现
- 原来OrderService使用RestTemplate 实现远程调用,url是写死了 , 如果 product-server服务 发生改变(例如: 端口号改了 )那么远程调用代码也要改变

通过Eureka 服务发现来 实现远程调用
- 注入DiscoveryClient 依赖 ,(是Spring 包底下的)

- order服务的service修改
// 1. 修改掉原来的远程调用 @Autowired private DiscoveryClient discoveryClient ; public OrderInfo getById(Integer orderId) { OrderInfo orderInfo = orderMapper.getById(orderId); // 从Eureka中 获取 注册服务的 实例列表 (一个服务可能有多个实例) List<ServiceInstance> instances = discoveryClient.getInstances("product-server"); // 服务可能有多个,但我们这里 product-server 里只有一个微服务, 所以获取 0下标的实例 EurekaServiceInstance serviceInstance = (EurekaServiceInstance) instances.get(0); // 拼接url : "http://localhost:9090" + productId String url =serviceInstance.getUri().toString()+ "/product/" + orderInfo.getProductId() ; // 通过远程调用访问这个url , 来获取 productInfo对象 ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class); orderInfo.setProductInfo(productInfo); return orderInfo; }

Eureka 和 Zookeeper 的区别
-
Eureka 和 Zookeeper 都是 用于 服务 注册 和 服务发现的 工具
-
Eureka 基于 AP原则 , 所以保证 高可用性
-
Zookeeper 基于 CP原则 , 所以保证 数据一致性
-
Eureka 所有节点都是 均等的 , Zookeeper 的节点分为 主从结构 , 所以当 主 发生故障时, 需要重新选举,(选举的过程中 ,集群是有一定时间不可用)
多机部署-负载均衡(LoadBalance)
负载均衡
-
负载: 可以看作是压力
-
均衡: 均衡不是平均, 是合理的分配压力
模拟实现
1. 上面的 order服务 和 product 服务 , 如果 product 服务有多个(实现群集) , 再发送请求 给 order 会发生上面
- 复制多个 product 服务启动
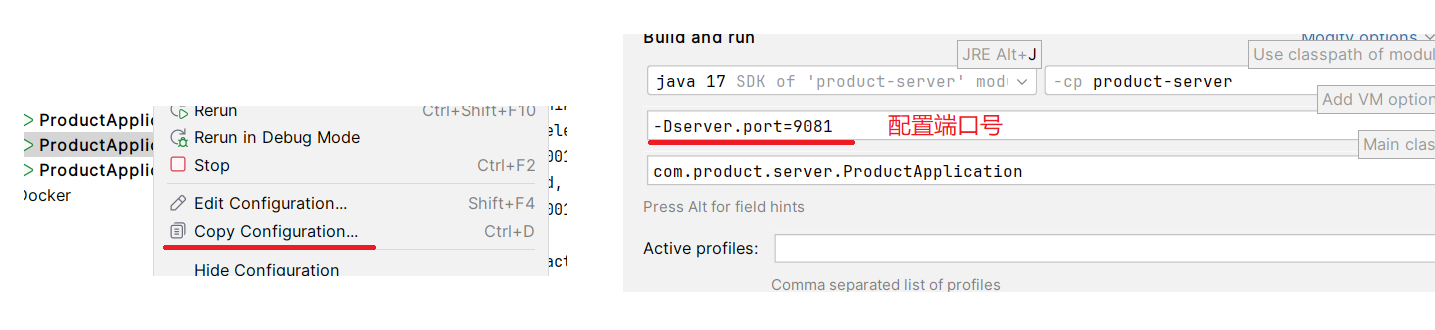
- 此时在 Eureka 里可以看到 product 服务有多个

- 多次调用 order 接口 , 查看 结果
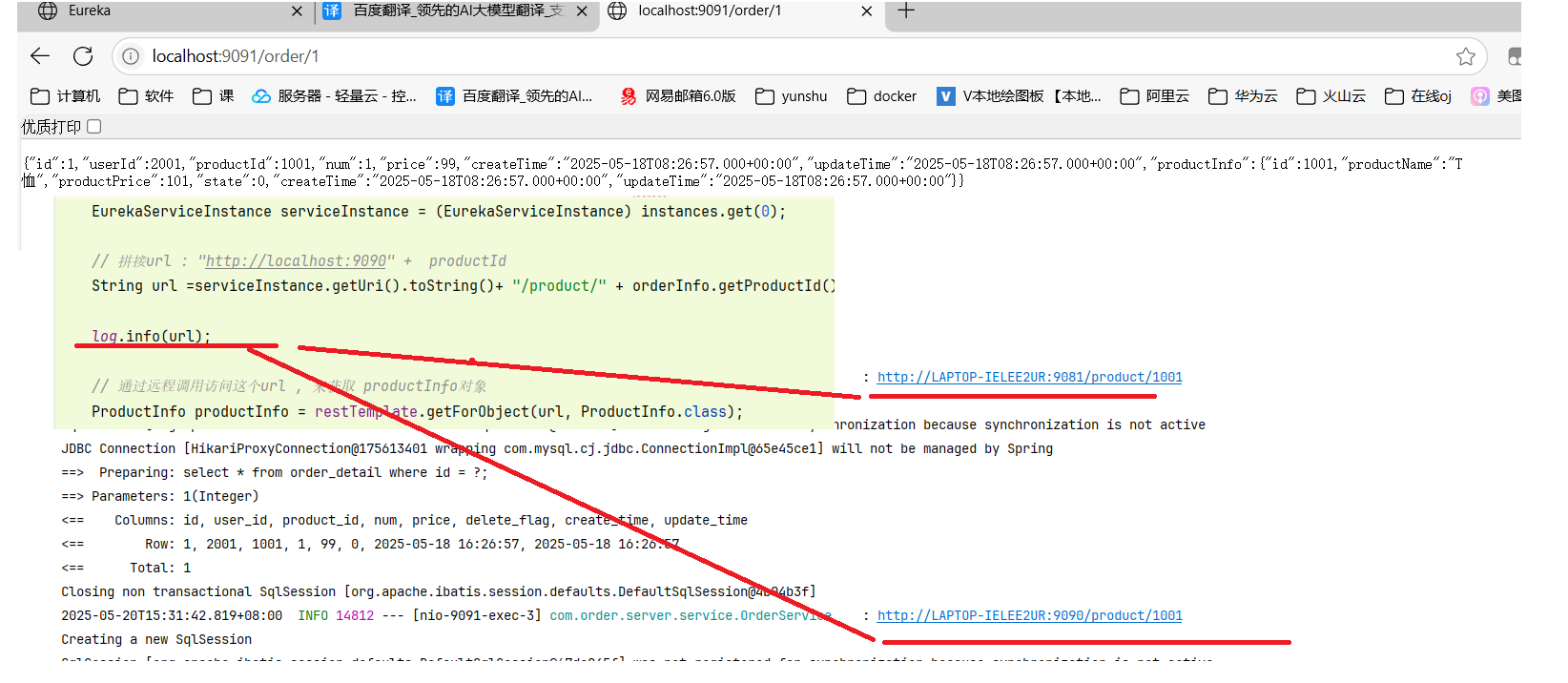
可以看到 虽然每次 get(0)下标的实例, 但实际上使用的服务都不一样
-
因为 getInstances 每次获取的结果都不一样
-
服务的顺序不是在 Eureka 上面看到的 ,
-
所以每次 拿到的 服务列表的顺序是可能 不同的


- 配置 一个模拟的均衡 , 让 order 服务 依次 从 product1服务 , product2服务 , product3服务 发送请求
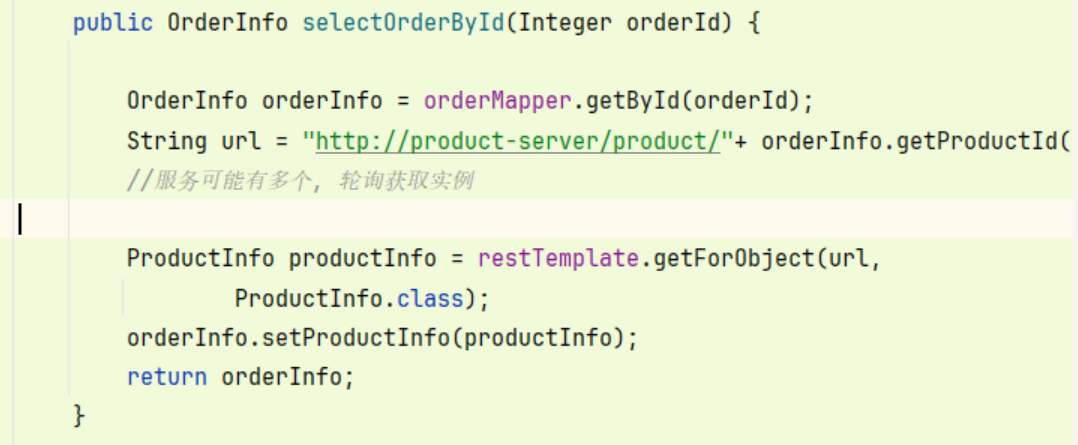
// 配置一个 线程安全的 计数器 (原子的int) private static AtomicInteger atomicInteger = new AtomicInteger(1); // 把 服务列表 提出来 private static List<ServiceInstance> instances ; // 提前初始化 @PostConstruct private void init(){ instances = discoveryClient.getInstances("product-server"); } public OrderInfo selectOrderById(Integer orderId) { OrderInfo orderInfo = orderMapper.getById(orderId); //String url = "http://127.0.0.1:9090/product/"+ orderInfo.getProductId(); //服务可能有多个, 轮询获取实例 // 通过原子计数器 来 , 每次获取当前计数器的值 后 ++ , int index = atomicInteger.getAndIncrement() % instances.size(); ServiceInstance instance =instances.get(index); log.info(instance.getInstanceId()); //拼接url String url = instance.getUri()+"/product/"+ orderInfo.getProductId(); ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class); orderInfo.setProductInfo(productInfo); return orderInfo; }
每次就轮流来使用 这 3 个product 服务
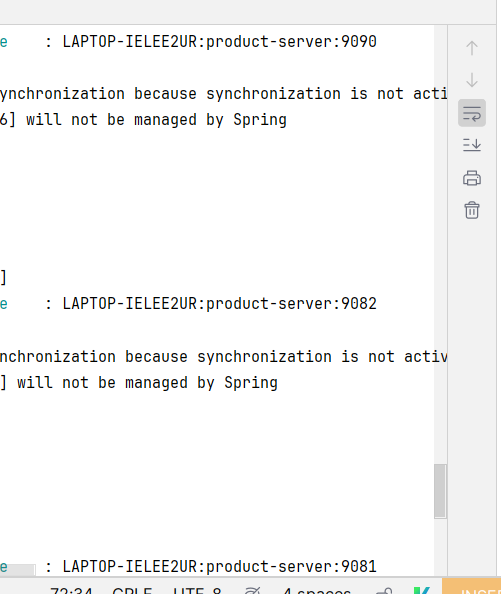
SpringCloudLoadBalance
SpringCloudLoadBalance 是 Spring官方 实现 负载均衡的 组件 ;
使用SpringCloud LoadBalance
- @LoadBalanced 注解
远程调用的 RestTemplate 的Bean 使用 @LoadBalance注解
- 远程调用的url 不指定ip 和端口号 , 而使用 服务名
远程调用 使用的 url 不指定 ip 和端口号 , 使用 要调用哪个服务 就 用 哪个服务的服务名
- 使用 远程调用的 RestTemplate 加上 @LoadBalance注解

2. 使用远程调用 的url 不在是 ip+端口号 , 而是 用 **服务名称**
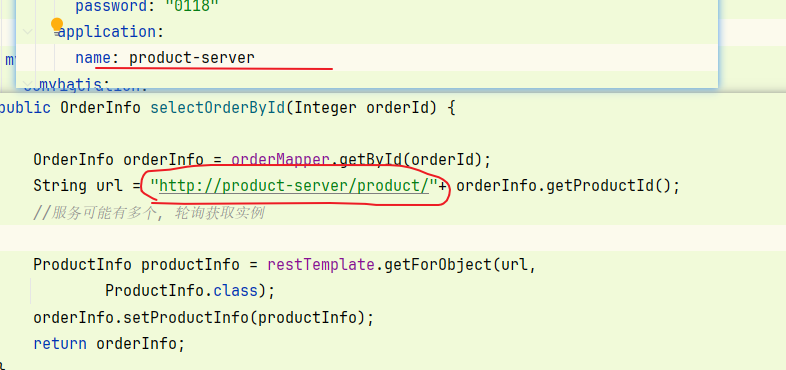
多次调用 order 接口 , 就可以看到 3个product服务 , 轮流使用
负载均衡策略
负载均衡策略 无论是 哪个负载均衡器 , 他们的负载均衡策略都是相同的 ;
SpringCloud LoadBalance 的负载均衡策略
SpringCloudLoadBalance只支持两种 负载均衡策略 默认是轮询
-
轮询 : 服务器轮流来处理请求 (例如: 上面的3个product服务 , 3个轮流使用)
-
随机选择: 随机选择有一个后端服务来处理请求 (例如: 上面3个product服务 , 随机选一个来使用)
自定义负载均衡策略
- 自定义均衡策略类 : 条件: 1. 不能用@Configuration注解 , 2. 类在 组件扫描范围内
// 随机选择的 负载均衡策略 类 , public class LoadBalancerConfig { @Bean ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment, LoadBalancerClientFactory loadBalancerClientFactory) { // 下面就是 负载均衡策略 String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME); System.out.println("==============" + name); return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name); } }
2. RestTemplate配置类使用 : @LoadBalanceClient 或 @LoadBalanceClients (适用于多个服务)
// @LoadBalanceClient : 目前只有 一个 product 服务 需要进行负载均衡 , 所以 不用 Clients // name : 是哪个服务需要使用 负载均衡策略 , Configuration 用哪个负载均衡策略 (就是上面定义的类) @LoadBalancerClient(name = "product-server" , configuration = LoadBalancerConfig.class) @Configuration public class BeanConfig { @LoadBalanced @Bean public RestTemplate restTemplate(){ return new RestTemplate() ; } }
- 远程调用继续保持使用 服务名代替ip和端口
- 此时 就是使用 随机选择的负载均衡策略 , 3 个product服务 , 随机选择 来用
LoadBalance原理
负载均衡主要实现在 LoadBalancerInterceptor
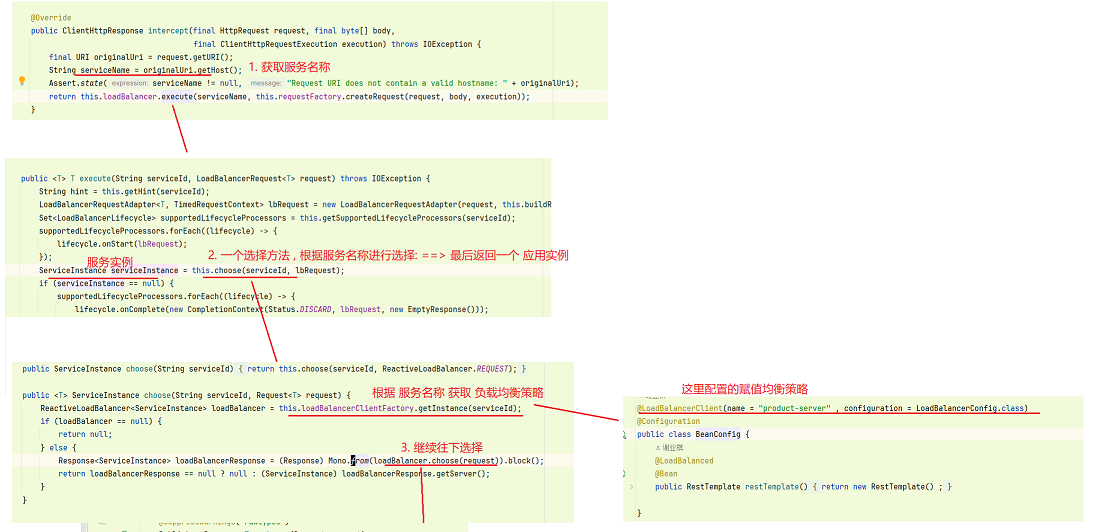
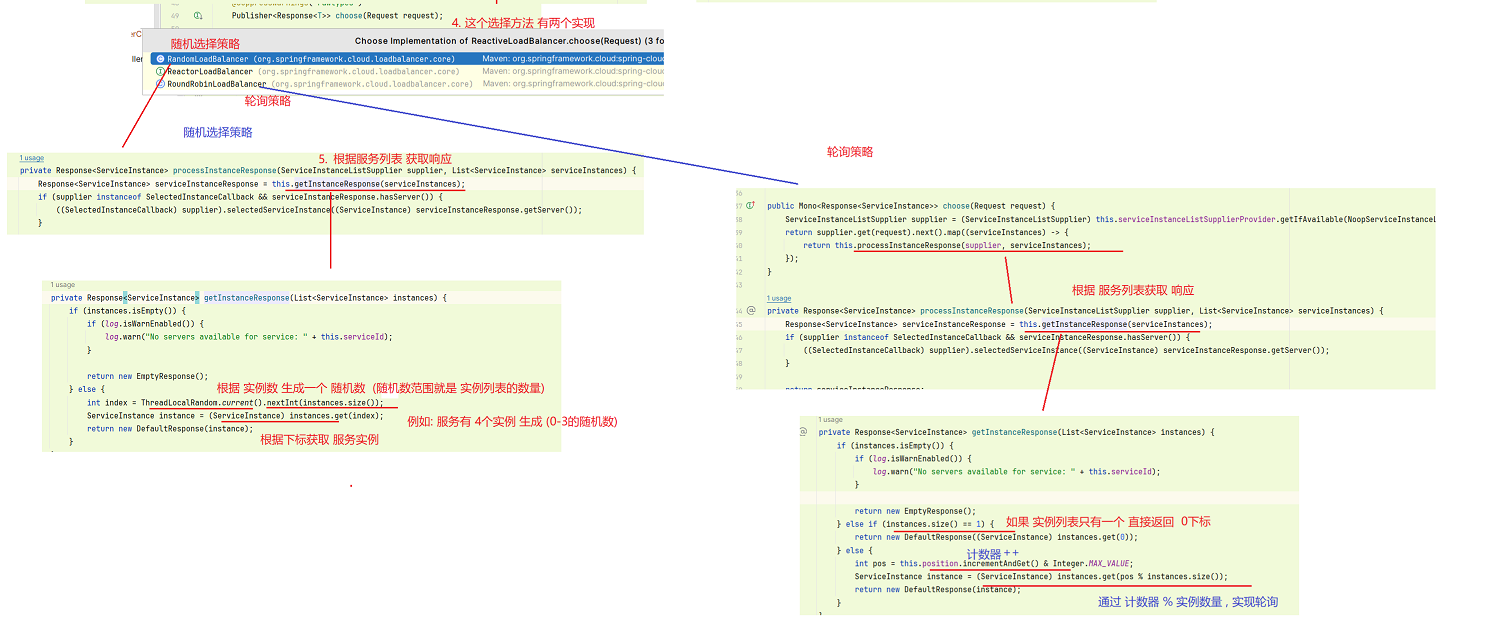
-
随机选择策略: 通过 实例数量生成 随机数 , 再通过 随机数 获取 实例
-
轮询策略: 和上面模拟实现的负载均衡类似 , 通过 计数器 % 实例数量 , 实现轮询
Nacos
Nacos 是一个更易于构建云原生的 动态服务发现, 配置管理和 服务管理平台 ; (不仅仅是一个 注册中心 组件)
- 修改 Nacos 集群服务 成 单机模式: model 的值 改成 standalone (修改startup.cmd的数据)
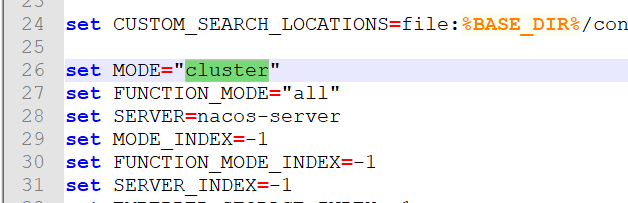
- 点击 startup.cmd 启动后 : 可以通过 8848 启动nacos
1. linux启动 : bash startup.sh -m standalone (-m standalone 单机模式启动)
使用Nacos
- 引入依赖
//springcloud alibaba 依赖 (一样要和springcloud版本对应) // 父工程引入 依赖 <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2022.0.0.0-RC2</version> <type>pom</type> <scope>import</scope> // 表示在父工程中直接引用 ,而不是 只声明不引用 </dependency> // 子工程引入依赖 // nacos 依赖 <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> // LoadBalance负载均衡依赖 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-loadbalancer</artifactId> </dependency>
2. 在子服务中配置Nacos地址
// 1. order 服务 , 配置服务名称 和 nacos地址 spring: application: name: order-server cloud: nacos: discovery: server-addr: nacos的ip 和端口
- RestTemplate远程调用的 url也要改成对应的服务名称
4. 查看nacos服务列表 , product启动了3个服务 , order有一个服务
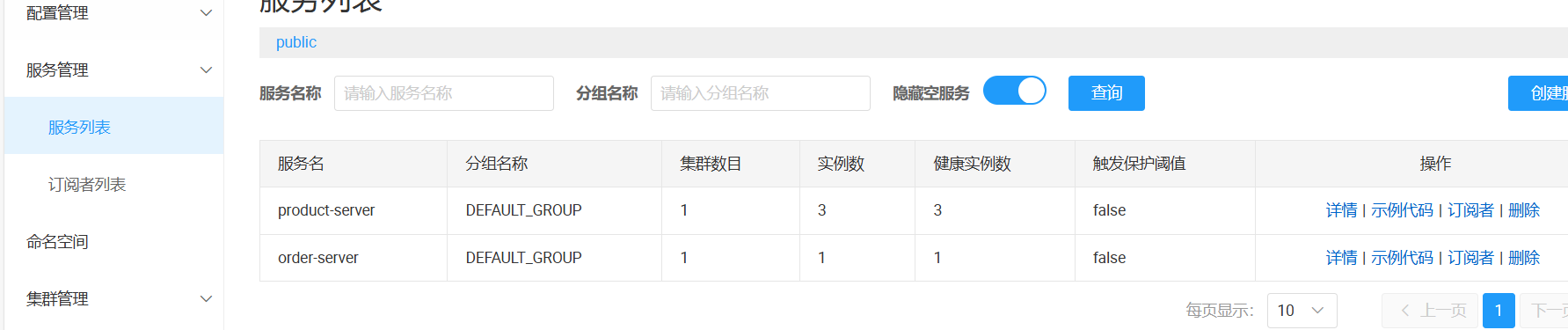
- 如果把product服务里的1个实例下线, 那么 远程调用 的请求 , 就不会 再让这个实例处理 (除非重新上线)

通过Nacos配置负载均衡
- 这里可以配置服务的权重 , (修改到 0.3) , 这样这个服务的权重为0.3 , 请求过来就更加优先 由权重大的服务处理
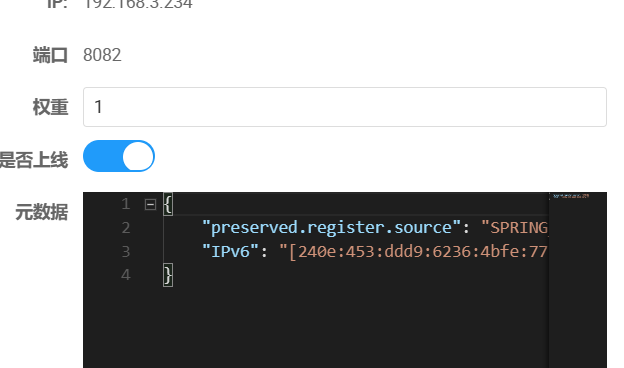
2. 开启Nacos负载均衡策略
// 这样 配置开启 后 , 才会使用 Nacos 的权重策略 spring: cloud: loadbalancer: nacos: enabled: true
Nacos同集群优先访问
-
product 1服务 在 机房1 , 同集群优先访问: order服务需要远程调用 product服务 , order服务在 机房1 , product 1服务 在 机房1 , product 3服务 在 机房2, 那么 order应该优先调用的是 在同一个机房的product服务 (一个机房可以看作是一个集群, 同一个集群里 , 的访问速度肯定更快)
-
修改配置
cloud: nacos: discovery: server-addr: localhost:8848 cluster-name: AD // 设置集群名字 loadbalancer: nacos: enabled: true // 使用集群要开启nacos负载均衡 // 设置 几个product服务为 BJ集群 -Dserver.port=9091 -Dspring.cloud.nacos.discovery.cluster-name=BJ- product服务里 : product8080 和 Order服务在 AD集群 , product 8081和 8082 在 BJ集群
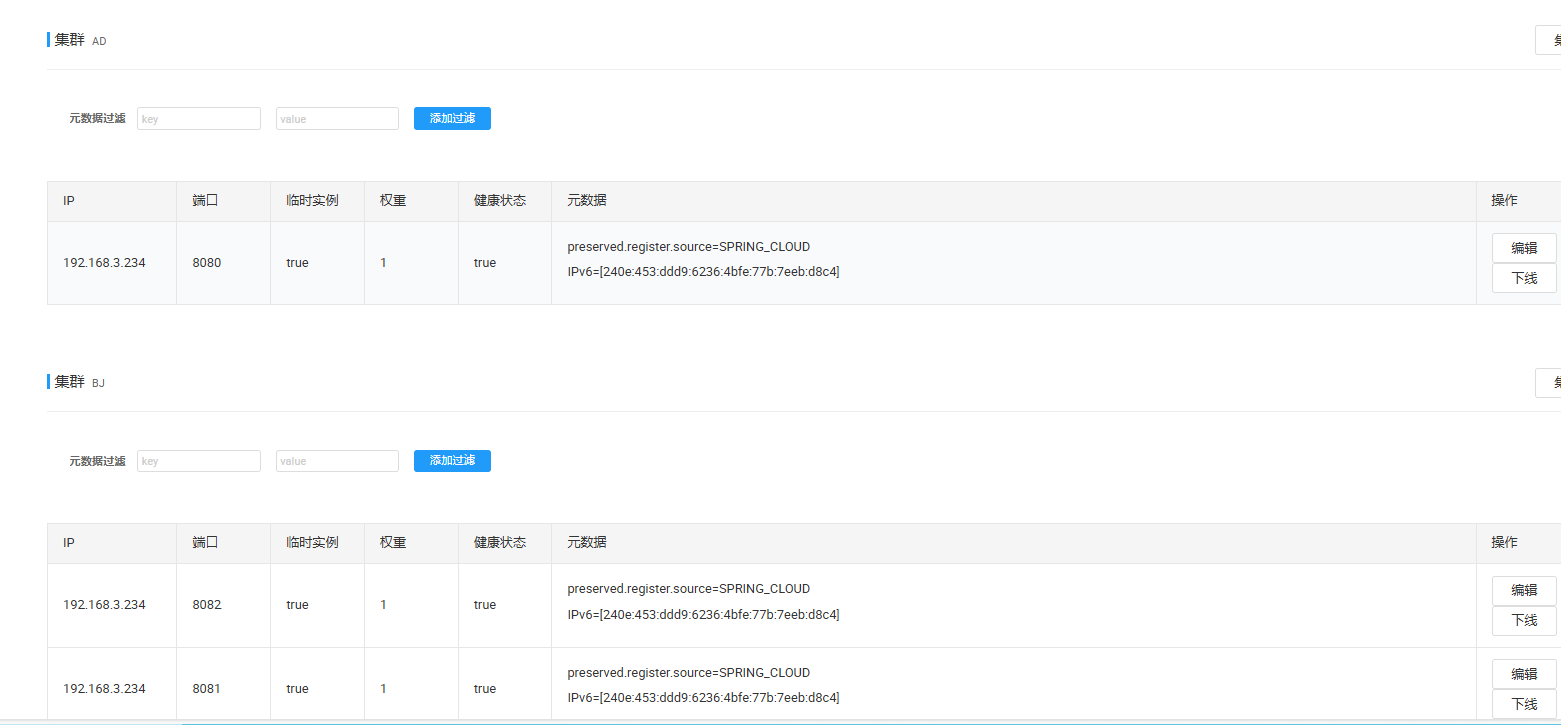
2. 此时在 处理请求 , order服务远程调用的 ,就都是使用 product8080服务 来进行处理
而 8081和8082 就不使用
3. 当 把和order服务同集群的 product8080服务 下线了 , 同集群里没有 product服务了 , 就开始使用其他集群的

Nacos健康检查
Nacos健康检查分为 两种
- 客户端主动上报机制
-
客户端通过心跳上报 机制 , 默认 每隔 5秒 像 服务端(Nacos注册中心) ,告知健康状态
-
nacos 如果在 15秒 没有收到 心跳 , 将实例设置为 不健康状态 , 超过30秒 将实例删除
- 服务器反向探测机制
-
Nacos 主动探测客户端健康状态, 默认 每隔 20秒 一次
-
Nacos 主动 健康检查 失败后 , 实例被标记为 不健康状态
Nacos服务实例类型
Nacos的健康检查机制不能主动设置, 因为 Nacos的健康检查机制和 服务实例类型强相关的
-
临时实例: 当实例超过一定时间宕机 , 服务会删除掉该实例 (默认类型) (使用第一种健康检查)
-
非临时实例(永久实例): 就算实例 宕机, 也不会被删除 (使用第二种健康检查)
// 通过配置设置 实例 类型 spring: cloud: nacos: discovery: ephemeral: false # 设置为⾮临时实例
(如果修改时效, 需要删除掉 缓存文件 , protocol 文件夹下的 rea...文件夹)
Nacos 环境隔离
- 通过给服务设置不同的 命名空间 , 这样不同命名空间的服务 就可以看作是在不同的环境下了
// 设置 服务命令空间 spring: cloud: nacos: discovery: namespace: 命名空间
2. 配置中心
设置好命名空间后, 可以给服务设置配置,
// 要使用 Nacos的配置中心 要引入依赖 <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!-- SpringCloud 2020.*之后版本需要引⼊bootstrap--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> </dependency>
3. 使用配置中心
// 通过Nacos , 使用Nacos的配置中心 // 这样 就可以在Nacos配置中心修改 服务的配置 spring: application: name: product-service 服务名称 (要和Nacos上的dataId一致) cloud: nacos: config: server-addr: nacos服务地址
配置的命名空间和 服务的命名空间不是同一个
-
注册中心是注册服务的
-
配置中心是设置服务配置的
1. 给 服务配置 热更新 @RefreshScope 注解 // 热更新注解, 服务不用重启也能随着 Nacos的设置实时更新配置
总结
-
Nacos 提供: 服务发现和注册 , 还提供配置中心,流量管理和DNS等功能
-
CAP原理:Eureka使用 AP原则 , Nacos 默认 AP ,但是可以切换成 CP模式
-
服务发现: Eureka基于 拉模式 , Eureka Client 会定期从Server 拉取信息 , 每30秒拉一次
-
Nacos基于 推送模式 , 服务列表实时推送给订阅者, 服务端和客户端保持心跳连接
OpenFeign
-
SpringCloud中 默认使用 HTTP 来进行微服务 的 通信 , 最常用的实现方式有2中
-
RestTemplate : 需要拼接URL ,
-
OpenFeign: 是声明式 Web Service客户端, (类似于Controller 调用Service, 只需要声明一个接口,添加注解就可以调用接口)
OpenFeign开发流程
-
引入依赖
-
通过注解 , 开启Feign 功能
-
编写客户端
-
使用OpenFeign 来实现远程调用
-
引入依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>
2. 添加注解,开启Feign功能
@EnableFeignClients // 给要使用Feign功能的服务的启动类加上这个注解 , 开启Feign功能
3. 编写客户端
@FeignClient (value = "product-server") // 指定FeignClient客户端 (name或value 指定 服务名称) public interface ProductApi { @RequestMapping("/product/{productId}") // 这里的方法就和 SpringMVC 一样 ProductInfo getProductInfo(@PathVariable("productId") Integer productId) ; }
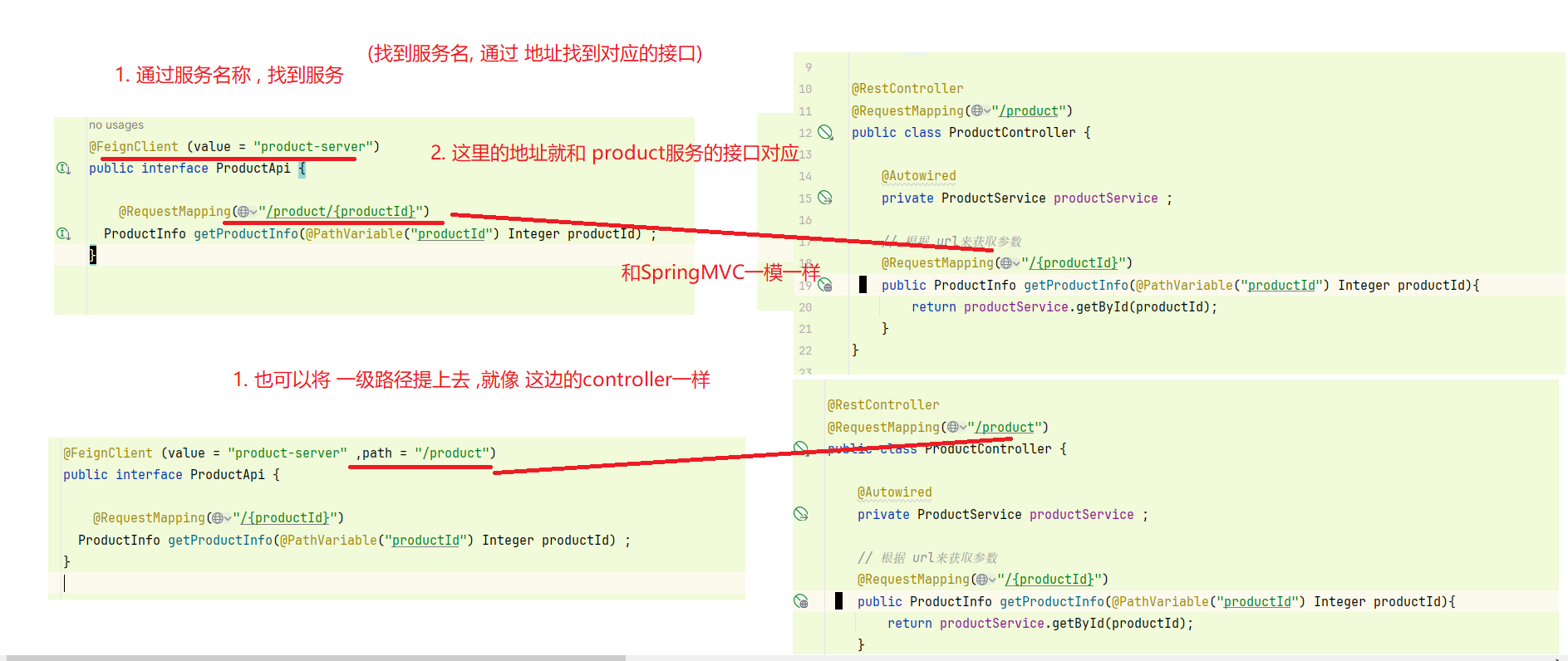
4. 通过Feign实现远程调用
@Service public class OrderService { @Autowired private OrderMapper orderMapper ; // 注入客户端 @Autowired private ProductApi productApi ; public OrderInfo getById(Integer orderId) { OrderInfo orderInfo = orderMapper.getById(orderId); // 通过Feign 实现远程调用 (通过客户端实现) ProductInfo productInfo = productApi.getProductInfo(orderInfo.getProductId()); orderInfo.setProductInfo(productInfo); return orderInfo; } }
5. 测试
成功通过Order服务,远程调用Product服务

OpenFeign 参数传递
-
传递单个参数
-
传递多个参数
-
传递对象
-
传递Json
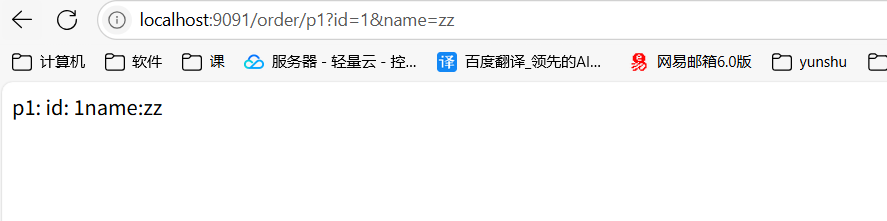
传递1个或多个参数
1. 首先服务要有对应的接口 // 传递一个或多个参数 @RequestMapping("/p1") public String p1(Integer id , String name){ return "p1: id: "+id + "name:"+name ; } 2. OpenFeign 客户端, 创建对应的 远程调用方法 // 这里用的是 Feign的格式 @RequestMapping("/p1") String p1(@RequestParam("id") Integer id , @RequestParam("name") String name); // @RequestParam 做参数绑定不能省略 // 是客户端接口类型, 所以方法的实现是 远程调用所调用的方法

3. 创建调用的接口 , 来使用 Feign客户端 来 远程调用 @RestController @RequestMapping("/order") public class OrderController { @Autowired private ProductApi productApi; @RequestMapping("/p1") public String p1( Integer id, String name) { // 通过 Feign 客户端 , 执行远程调用 return productApi.p1(id , name); } }
测试: 通过order服务,远程调用product服务的结果
传递对象
1. 创建出服务方的接口, // 传递对象 @RequestMapping("/p2") public String p2(ProductInfo productInfo){ return "p2: "+productInfo.toString(); } 2. 客户端创建出对应的 远程调用方法 // @SpringQueryMap 通过 这个注解 , 来实现 传输对象参数 @FeignClient (value = "product-server" ,path = "/product") public interface ProductApi { @RequestMapping("/{productId}") ProductInfo getProductInfo(@PathVariable("productId") Integer productId) ; @RequestMapping("/p2") // @SpringQueryMap 注解 String p2(@SpringQueryMap ProductInfo productInfo); } 3. 创建接口,调用 远程调用 @RequestMapping("/p2") public String p2(){ ProductInfo productInfo = new ProductInfo() ; productInfo.setId(11); productInfo.setProductName("zhangsan"); // 调用客户端p2方法 return productApi.p2(productInfo); }
测试: 通过order服务,远程调用product服务的结果

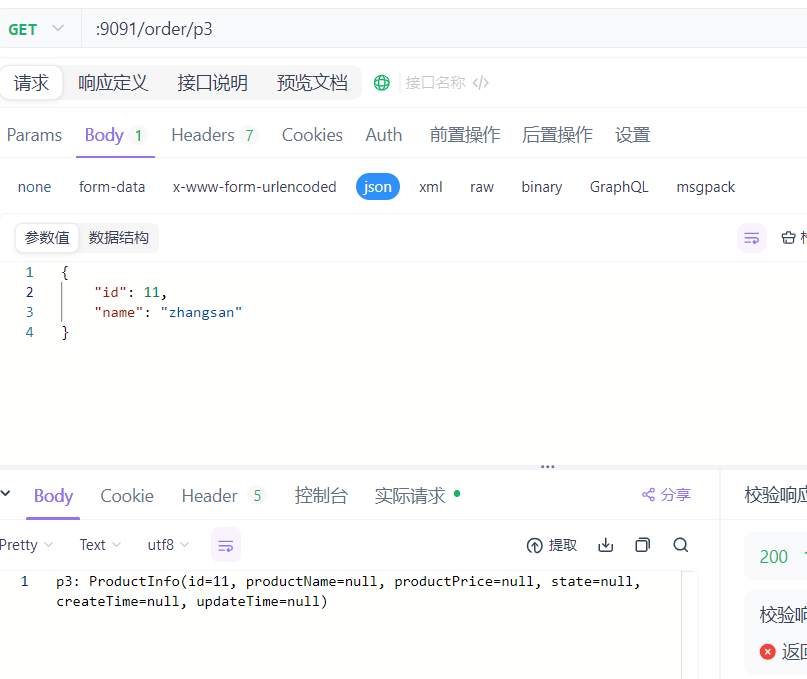
传递Json参数
1. 创建出服务方的接口, // 传递json @RequestMapping("/p3") public String p3(@RequestBody ProductInfo productInfo){ return "p3: "+ productInfo.toString() ; } 2. 创建 Feign客户端的远程调用方法 // 传递json @RequestMapping("/p3") // 和SpringMVc一样 , 传递json也用 @RequestBody String p3(@RequestBody ProductInfo productInfo) ; 3. 创建order服务 接口 , 调用Feign客户端 ,调用远程调用 // 传递json @RequestMapping("/p3") public String p3(@RequestBody ProductInfo productInfo) { return productApi.p3(productInfo); }
测试: order服务远程调用 product服务 接口 传递json数据
通过抽取的方式实现 Feign
-
完成抽取
-
打包install
-
启动服务端
-
服务调用方引用抽取出来的模块
-
给服务调用方 指定 扫描路径 ( 让 服务调用方 , 扫描 我们抽取出来的模块)
-
将OpenFeign服务抽取出来

删除掉原来使用的 OpenFeign客户端 和 远程调用用到的类 , (后面用抽取出来的模块来远程调用)
2. 打包install
将微服务 api 通过 maven 打成本地包
3. 启动服务端
启动提供服务的 product微服务

4. 服务调用方 引用打包 好的 模块
所有用原来的实体类和 feign 客户端的都删掉, 改用打包好的模块, (打包好的模块是jar包, 就相当于引入依赖)
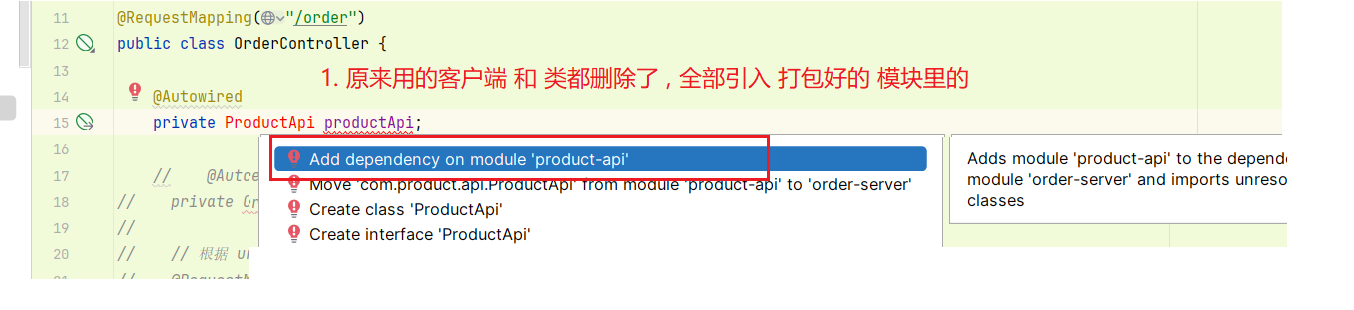
引入依赖后 可以看到 pom 里有 模块的依赖

原来使用的类和feign客户端都改成打包好的模块
5. 设置扫描路径
服务启动默认扫描路径就是启动类的包下路径 , 而现在 feign客户端 再 api 微服务里 , 所以要设置 服务扫描路径 , 来扫描到这个 feign客户端
通过设置 @EnableFeignClients 注解的 Clients的属性 , 把 openfeign 的客户端 添加进来

统一服务入口Getaway
Api 网关
目前所有的微服务接口都是直接对外暴露的, 可以直接通过外部访问.为了保证对外服务的安全性,所以需要给每个服务都设置 校验机制 ,但是不同微服务就是不同应用, 每个微服务都要去重复的设置 校验机制 , 所以有了 ==> Api网关
API网关 : 网关也是 一个 服务 , 通畅是后端服务的唯一入口, 它类似于门面模式,就像微服务的门面, 所有的 外部访问都需要 通过网关 来进行调度和过滤
网关核心功能
-
权限控制: 作为微服务的入口, 对用户进行权限校验, 如果校验失败 , 就拦截 (身份验证)
-
动态路由: 一切请求先经过网关, 但是网关不处理业务 , 而是根据某种规则转发请求给 指定的服务(根据需求,送到指定的服务处理)
-
负载均衡: 可以给服务进行负载均衡 (当一个服务的有很多人时, 帮客户选择某个服务来处理)
-
限流: 请求流量过高时 , 进行限流 , 保证流量 是 微服务能够处理的了的 (当请求过多时, 进行流量限制)
常见的网关实现
-
Zuul : 是NetFlix 公司的api组件
-
SpringCloud Gateway : 是Springcloud的api网关组件
Spring Cloud Gateway
- 引入依赖
<!--⽹关--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <!--基于nacos实现服务发现依赖--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!--负载均衡--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency>
- 创建网关微服务添加配置
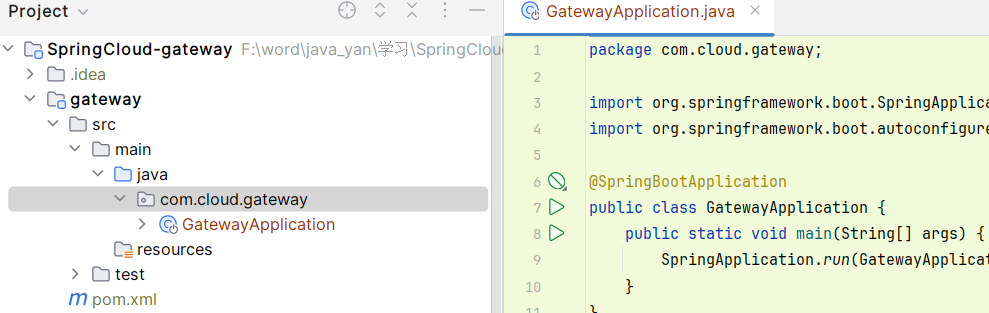
server: port: 10030 # ⽹关端⼝ spring: application: name: gateway # 服务名称 cloud: nacos: discovery: server-addr: localhost:8848 gateway: routes: # ⽹关路由配置 - id: product-server #路由ID, ⾃定义, 唯⼀即可 uri: lb://product-server #⽬标服务地址 predicates: #路由条件 - Path=/product/** // 后面请求路径 包含product网关转发给product服务 - id: order-server uri: lb://order-server predicates: - Path=/order/** // 这些- Path 都是 路径过滤 , 根据路径来过滤
3. 网关测试
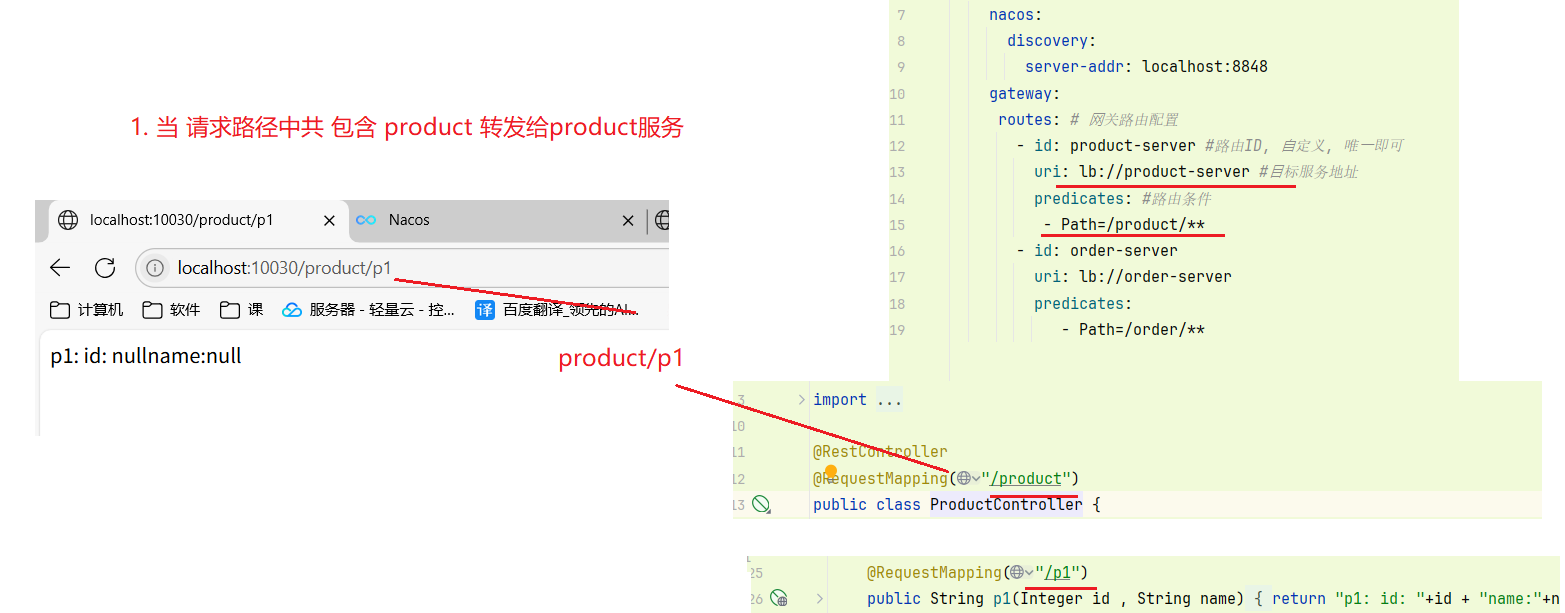
- 后面把服务的接口关闭掉不对外 , 这样 请求 都要通过网关来 进行访问 (上面的是根据地址来进行过滤的)
Route Predicate Factories
Predicate
predicate 是 Java8 提供的 函数式接口 , 他接口一个参数 (参数是泛型)返回 布尔值 , 用于条件过滤, 请求参数的校验
再java.util.function包下
-
通过继承实现
-
通过匿名内部类实现
-
通过Lambda实现
// 1. 通过继承实现 // 继承 predicate public class StringPredicate implements Predicate { // 重写test方法 @Override public boolean test(Object o) { return true ; } } public class TestPredicate { // 测试方法 @Test public void test1(){ Predicate predicate = new StringPredicate(); System.out.println(predicate.test(111)); } } // 2. 匿名内部类 @Test public void test2(){ Predicate predicate = new Predicate() { @Override public boolean test(Object o) { return true ; } }; System.out.println(predicate.test(11)); } // Lambda表达式 @Test public void test3(){ Predicate predicate = o -> true ; System.out.println(predicate.test(11)); }
引入Junit依赖实现测试类测试方法
Predicate方法
判断 与 或 非
- 非 negate()
@Test public void test4(){ Predicate o1 = o -> true ; System.out.println(o1.negate().test(11)); // 非, test返回true , 加上negate , 输出 false }
2. 与 and()
@Test public void test4(){ Predicate o1 = o -> true ; Predicate o2 = o -> false ; System.out.println(o1.and(o2).test(11)); // o1的test方法结果 与 o2的test方法结果 } // o1的test返回true , o2的test返回false , 那么 and的结果输出 false
3. 或 or()
@Test public void test4(){ Predicate o1 = o -> true ; Predicate o2 = o -> false ; System.out.println(o1.or(o2).test(11)); // 或结果 , 最后输出 true }
Route Predicate Factories
Route Predicate Factories : 路由断言工厂(或路由 谓词工厂) 在springcloud gateway 中 predicate 提供了路由规则的匹配机制
- 路由断言工厂 判断请求是否满足 条件, 满足了才会将请求转发给 指定的服务

// 其他断言条件 , 多个条件的判断结果 and 起来 (与) 1. After 这个⼯⼚需要⼀个⽇期时间(Java的 ZonedDateTime对象), 匹配指定⽇期之后的请求 predicates: - After=2017-01-20T17:42:47.789-07:00[America/Denver] 2. Before 匹配指定⽇期之前的请求 predicates: - Before=2017-01-20T17:42:47.789-07:00[America/Denver] 3. Between匹配两个指定时间之间的请求datetime2 的参数必须在datetime1 之后 predicates: - Between=2017-01-20T17:42:47.789-07:00[America/Denver], 2017-01-21T17:42:47.789-07:00[America/Denver] 3.Cookie 请求中包含指定Cookie, 且该Cookie值符合指定的正则表达式 predicates: - Cookie=chocolate, ch.p 4. Header 请求中包含指定Header, 且该Header值符合指定的正则表达式 predicates: - Header=X-Request-Id, \d+ 5. Host 请求必须是访问某个host(根据请求中的Host字段进⾏匹配) predicates: -Host=**.somehost.org,**.anotherhost.org 6. Method 匹配指定的请求⽅式 predicates: - Method=GET,POST 7. Path 匹配指定规则的路径 predicates: -Path=/red/{segment},/blue/{segment} 8.RemoteAddr 请求者的IP必须为指定范围 predicates: - RemoteAddr=192.168.1.1/24