LRU缓存设计
Go
type lruCache struct {
mu sync.RWMutex
list *list.List // 双向链表,用于维护 LRU 顺序
items map[string]*list.Element // 键到链表节点的映射
expires map[string]time.Time // 过期时间映射
maxBytes int64 // 最大允许字节数
usedBytes int64 // 当前使用的字节数
onEvicted func(key string, value Value)
cleanupInterval time.Duration
cleanupTicker *time.Ticker
closeCh chan struct{} // 用于优雅关闭清理协程
}list
维护LRU的顺序,头部是最久未使用的,尾部是最新的或最近使用的。
items
提供了O(1)的查找能力,映射键与节点,避免遍历寻找。
expires
过期时间管理,为需要过期的Key维护过期时间。过期后进行处理。
maxBytes/usedBytes
维护缓存最大的存储字节量,记录缓存已经使用的字节量。
OnEvicted
设计的回调监听,当输出元素后调用回调。
CleanUpInterval
清理时间间隔。用来实现过期管理机制。
过期淘汰机制
主动清理
Go
//开启过期淘汰协程
func newLRUCache(opts Options) *lruCache {
......
// 启动定期清理协程
c.cleanupTicker = time.NewTicker(c.cleanupInterval)
go c.cleanupLoop()
......
}
// cleanupLoop 定期清理过期缓存的协程
func (c *lruCache) cleanupLoop() {
for {
select {
case <-c.cleanupTicker.C:
c.mu.Lock()
c.evict() //evict是清理过期缓存和超出内存限制的缓存。
c.mu.Unlock()
case <-c.closeCh: //通过closeCh进行优雅的关闭
return
}
}
}被动清理
当调用Get时,首先对Key进行过期检查,如果过期,获取失败并删除Key。
Go
func (c *lruCache) Get(key string) (Value, bool) {
......
// 检查是否过期
if expTime, hasExp := c.expires[key]; hasExp && time.Now().After(expTime) {
c.mu.RUnlock()
// 异步删除过期项,避免在读锁内操作
go c.Delete(key)
return nil, false
}
......
}
func (c *lruCache) SetWithExpiration(key string, value Value, expiration time.Duration) error {
......
// 检查是否需要淘汰旧项
c.evict()
......
}内存管理机制
Set
更新过期时间->更新键(更新List,更新usedBytes)->map映射新键与List元素。
Go
SET -> GET/DELETE
//SET
func (c *lruCache) Set(key string, value Value) error {
return c.SetWithExpiration(key, value, 0)
}
// SetWithExpiration 添加或更新缓存项,并设置过期时间
func (c *lruCache) SetWithExpiration(key string, value Value, expiration time.Duration) error {
if value == nil {
c.Delete(key)
return nil
}
c.mu.Lock()
defer c.mu.Unlock()
// 计算过期时间
var expTime time.Time
if expiration > 0 {
expTime = time.Now().Add(expiration)
c.expires[key] = expTime
} else {
delete(c.expires, key)
}
// 如果键已存在,更新值
if elem, ok := c.items[key]; ok {
oldEntry := elem.Value.(*lruEntry)
c.usedBytes += int64(value.Len() - oldEntry.value.Len())
oldEntry.value = value
c.list.MoveToBack(elem)
return nil
}
// 添加新项
entry := &lruEntry{key: key, value: value}
elem := c.list.PushBack(entry)
c.items[key] = elem
c.usedBytes += int64(len(key) + value.Len())
// 检查是否需要淘汰旧项
c.evict()
return nil
}Get
并发安全:锁升级机制,Get先用读锁检查,需要更新List时升级写锁。
Go
func (c *lruCache) Get(key string) (Value, bool) {
c.mu.RLock()
elem, ok := c.items[key]
if !ok {
c.mu.RUnlock()
return nil, false
}
// 检查是否过期
if expTime, hasExp := c.expires[key]; hasExp && time.Now().After(expTime) {
c.mu.RUnlock()
// 异步删除过期项,避免在读锁内操作
go c.Delete(key)
return nil, false
}
// 获取值并释放读锁
entry := elem.Value.(*lruEntry)
value := entry.value
c.mu.RUnlock()
// 更新 LRU 位置需要写锁
c.mu.Lock()
// 再次检查元素是否仍然存在(可能在获取写锁期间被其他协程删除)
if _, ok := c.items[key]; ok {
c.list.MoveToBack(elem)
}
c.mu.Unlock()
return value, true
}Delete
删除List中元素,删除items与expires映射,更新使用的字节数字。
Go
func (c *lruCache) Delete(key string) bool {
c.mu.Lock()
defer c.mu.Unlock()
if elem, ok := c.items[key]; ok {
c.removeElement(elem)
return true
}
return false
}
func (c *lruCache) removeElement(elem *list.Element) {
entry := elem.Value.(*lruEntry)
c.list.Remove(elem)
delete(c.items, entry.key)
delete(c.expires, entry.key)
c.usedBytes -= int64(len(entry.key) + entry.value.Len())
if c.onEvicted != nil {
c.onEvicted(entry.key, entry.value)
}
}ConsHash一致性哈希设计
一致性哈希为了解决什么?
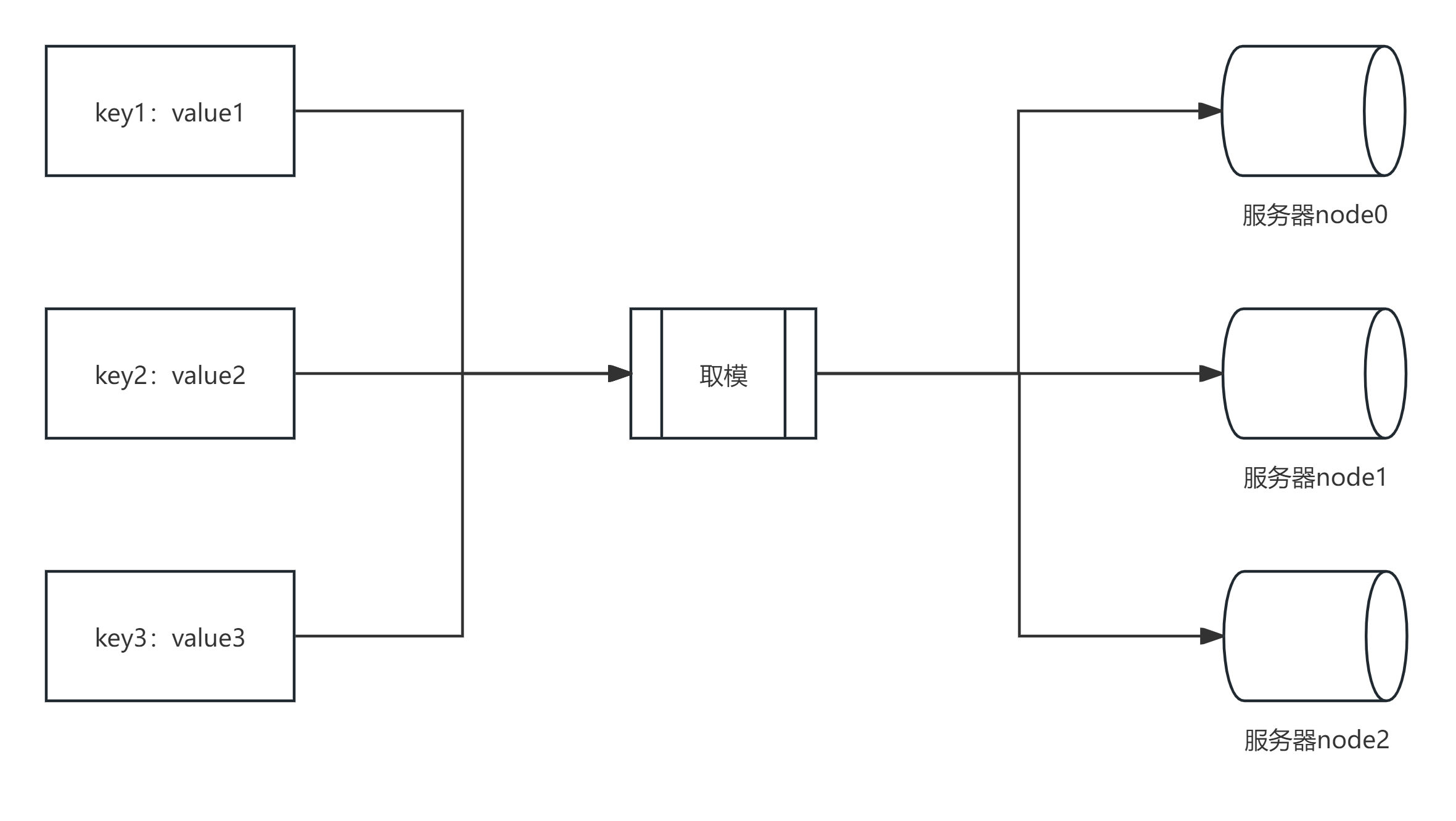
当我们有大量的数据需要缓存在服务器组成的集群时,可以使用hash(key)%N(N为机器数量)的方式进行缓存的均匀分配。
但是实际中如果服务器数量有调整,整个集群的缓存数据必须重新计算调整 。导致大量缓存雪崩进而使缓存系统不再可用。
一致性哈希为了解决这个问题。
一致性哈希简介
当分布式集群移除或者添加一个服务器时,必须尽可能小地改变 已存在的服务请求与处理请求服务器之间的映射关系。
一致性哈希原理
一致性哈希仍然是对取模,但并非对服务器数量取模,而是对固定值2^32取模。
算法工作原理:
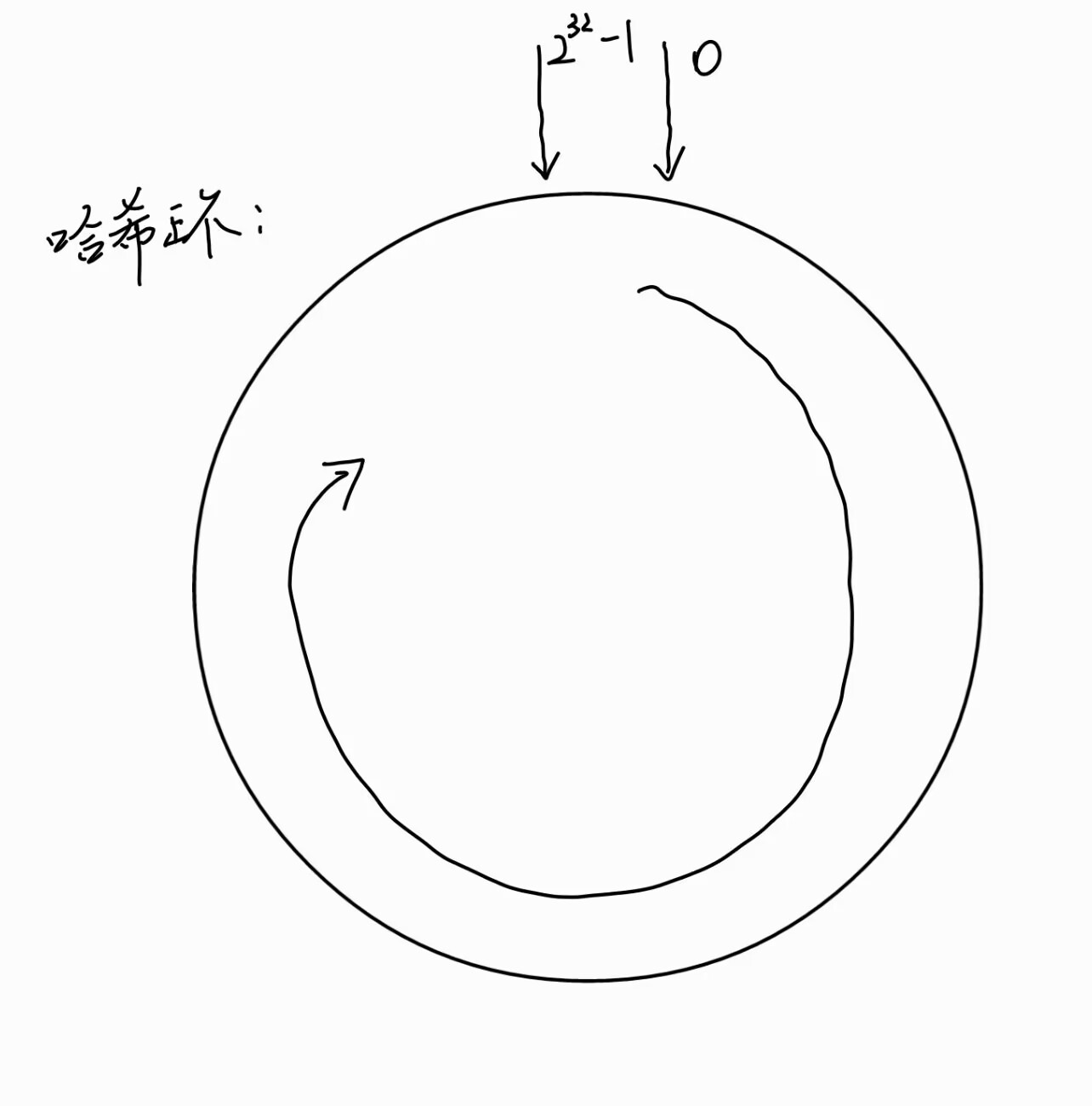
- 一致性算法将整个哈希值映射为一个圆环,哈希值的取值范围是0~2^32-1;
- 计算各个服务器节点的哈希值,映射到哈希环上;
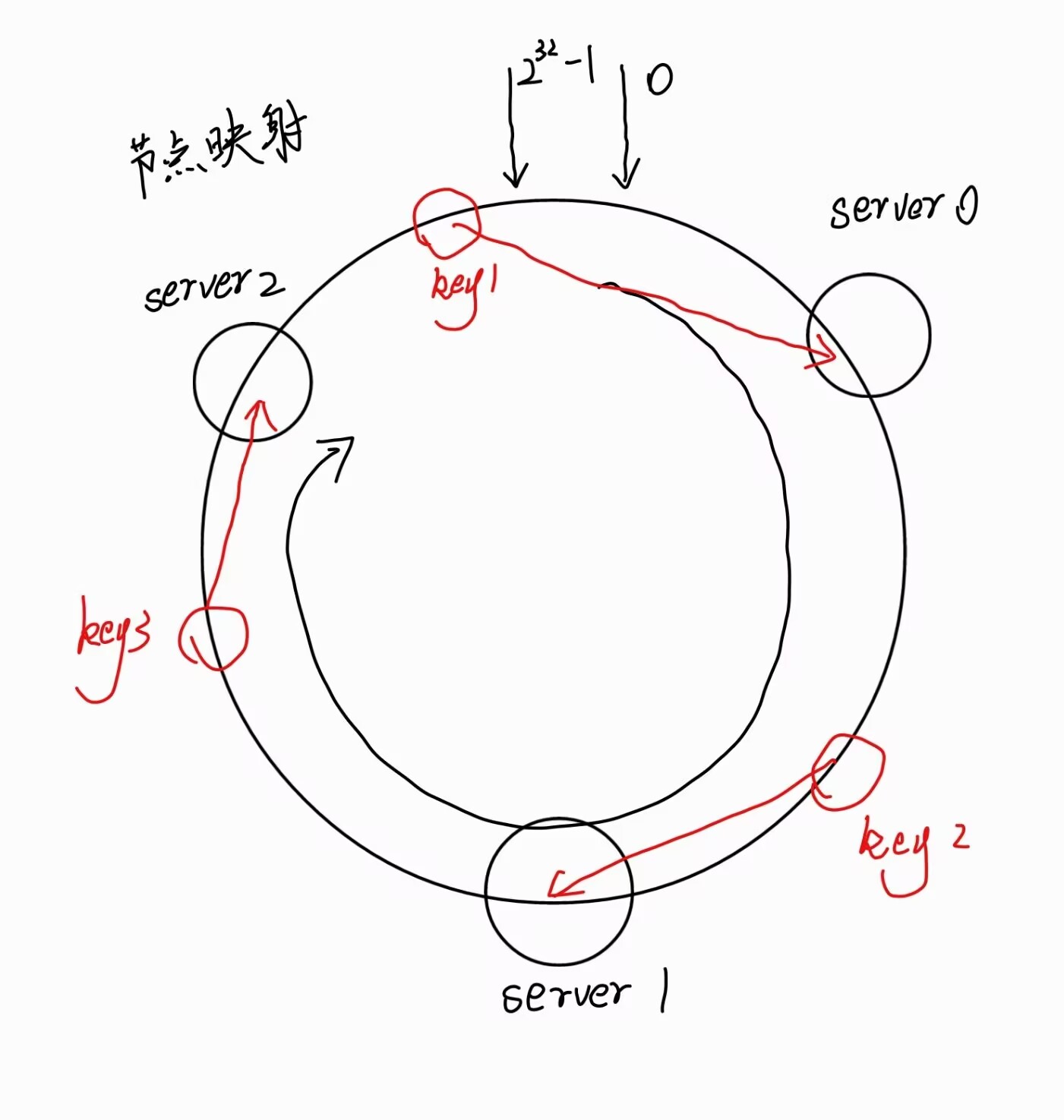
- 将服务发来的数据请求使用哈希算法算出对应的哈希值;
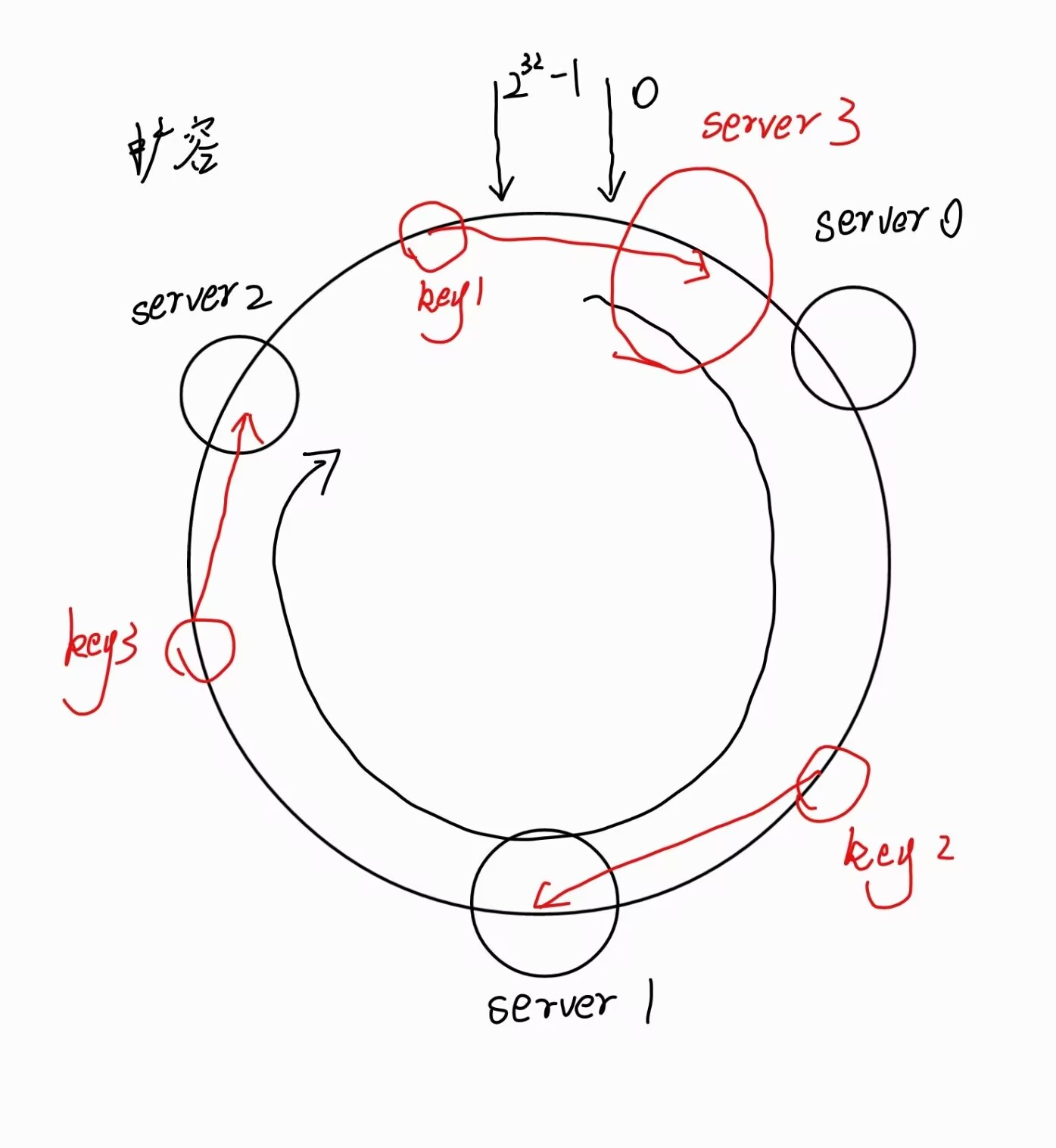
- 将服务发现的哈希值映射到哈希环上,同时沿圆环顺时针查找,遇到的第一个服务器就是对应的请求服务器。
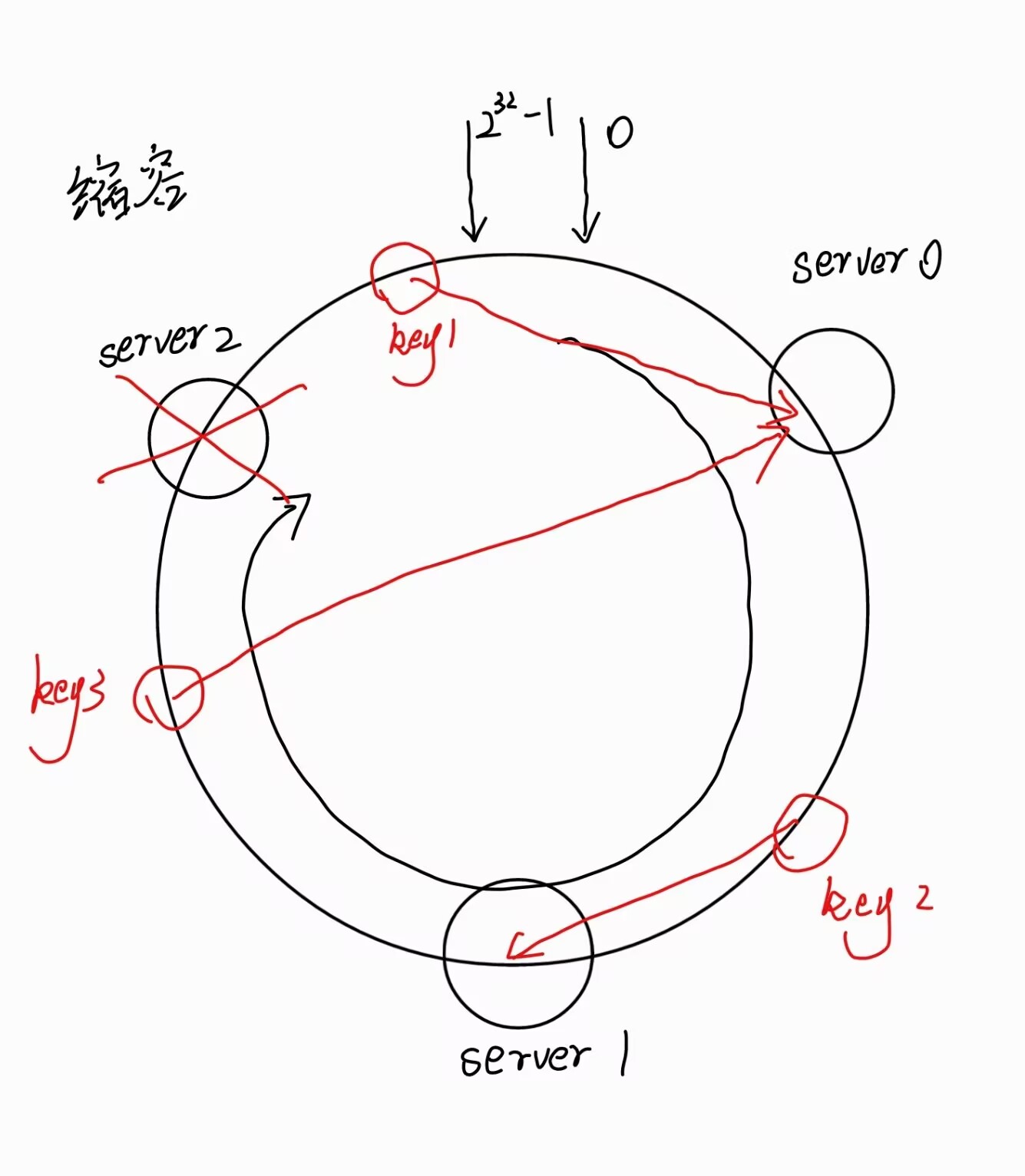
- 增加或者删除服务器时,受影响的数据只有新添加或者删除服务器到其环空间前一台服务器的数据,其他不影响。
优势:一致性哈希对于节点的增减只需要重定位环空间的一小部分数据,体现了容错性 和可扩展性。
内部剖析
哈希环
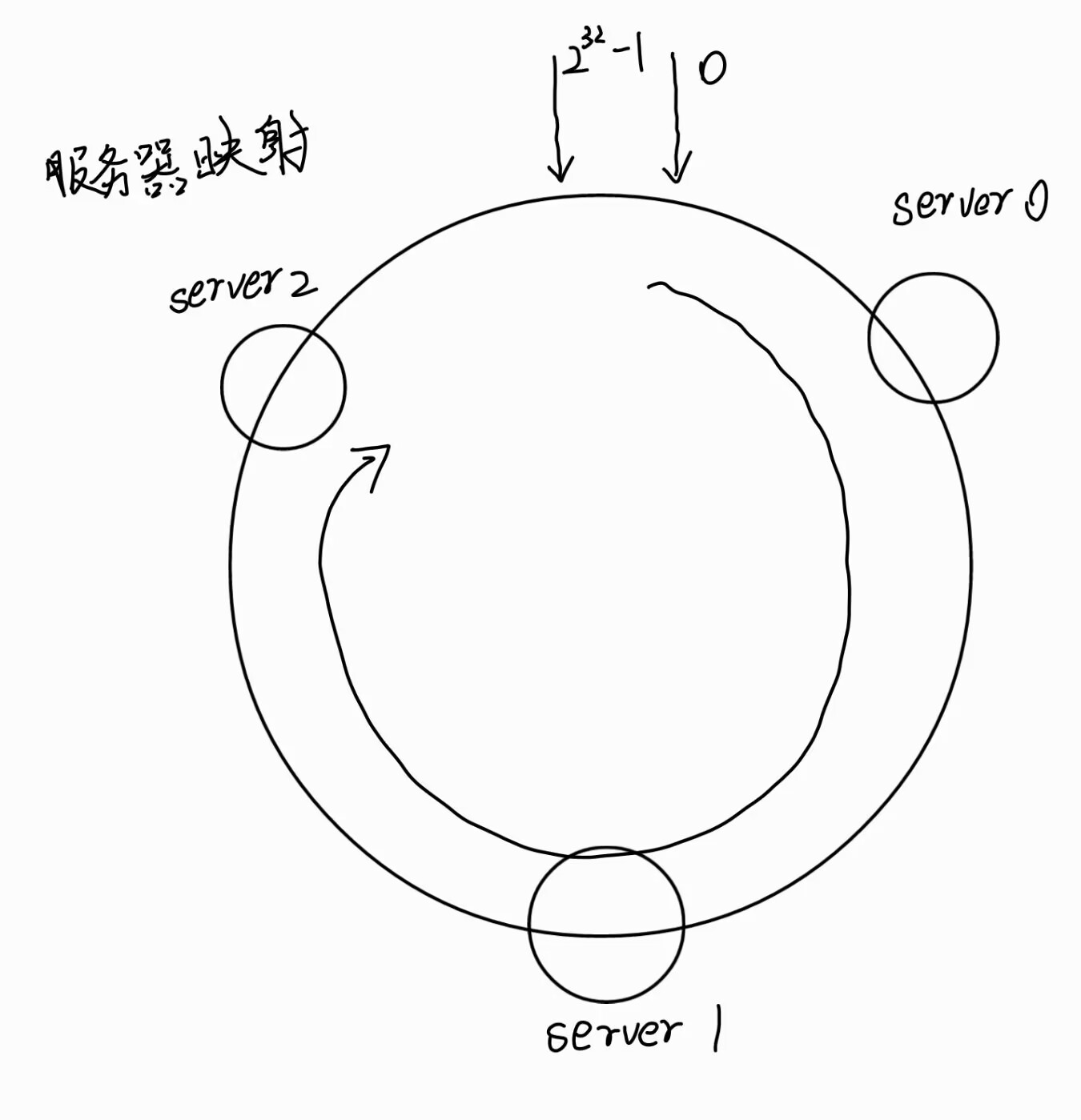
服务器映射
将服务器IP进行hash计算并映射到哈希环。
节点映射
将key进行hash计算并取模后映射到哈希环。
扩容
缩容
问题
因为哈希计算有随机性,当多个服务器节点映射到哈希环时,可能出现一部分节点映射区域较少,一部分节点映射较多,导致数据倾斜到几个服务器上。造成**"数据倾斜"**。
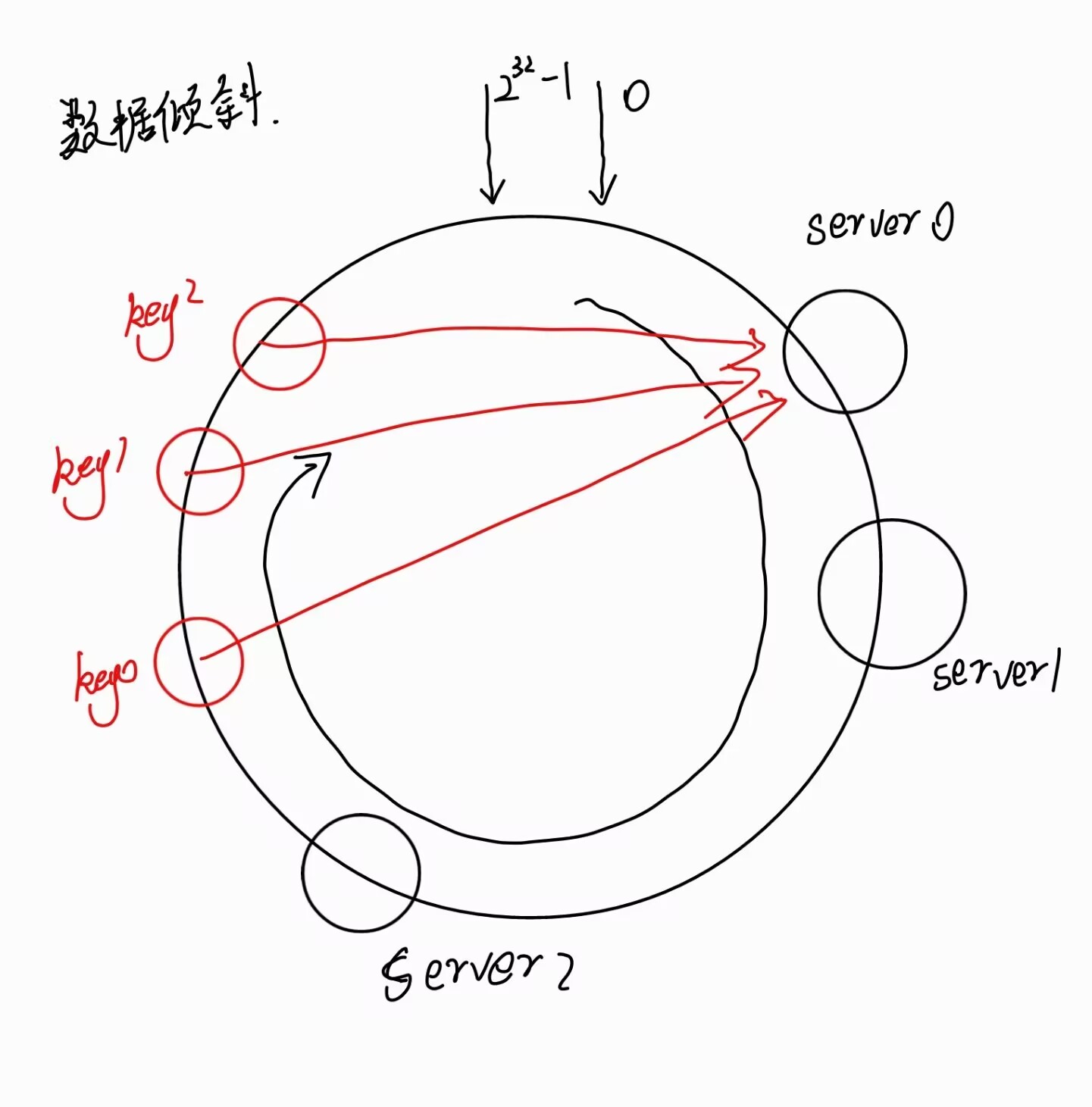
如何解决数据倾斜
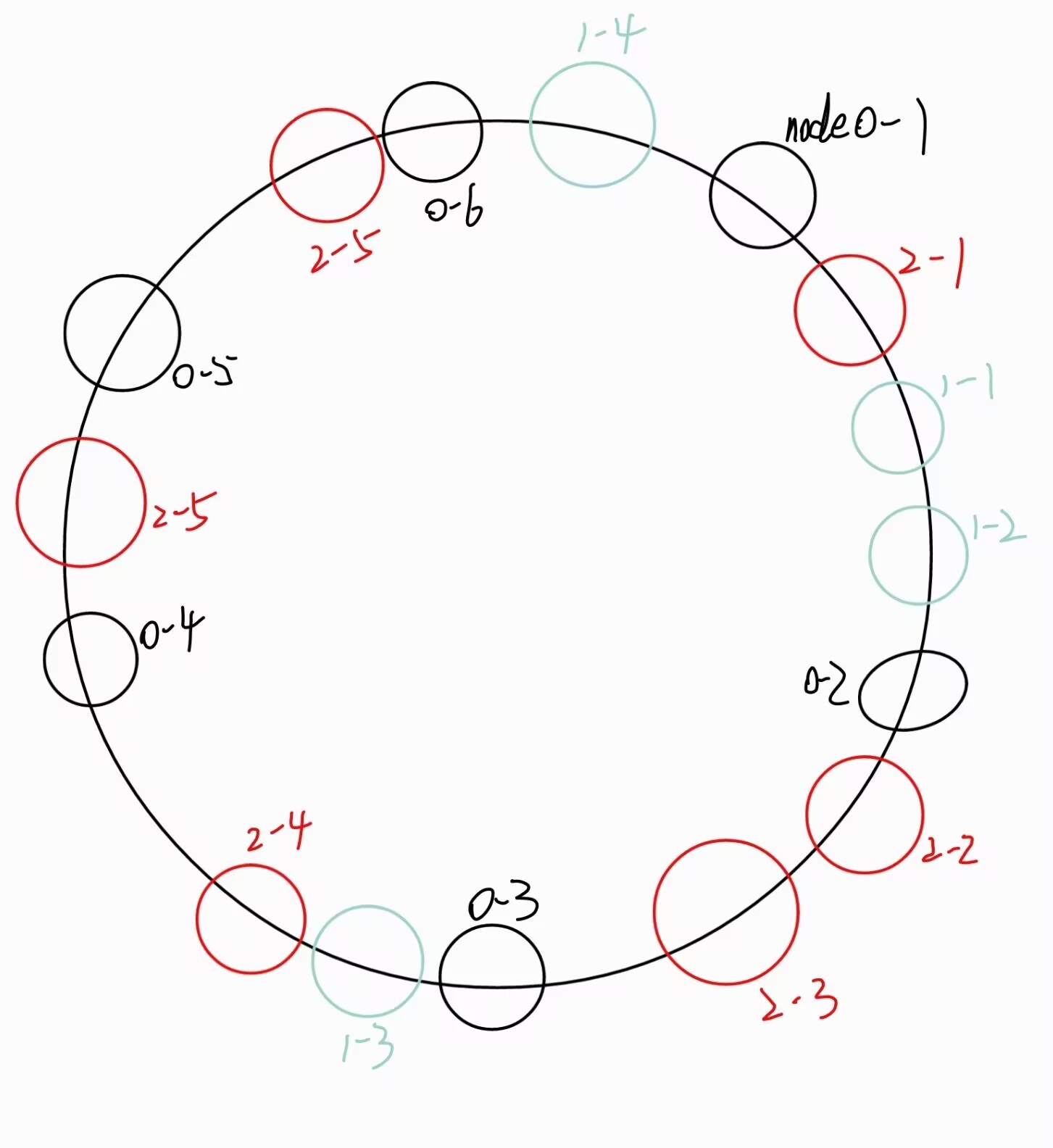
一致性哈希选择使用虚拟节点,同一个物理服务节点有多个虚拟节点,虚拟节点是计算哈希值并映射到哈希环上。虚拟节点越多,哈希环越均匀。避免了数据倾斜。
算法实现
Go
// Map 一致性哈希实现
type Map struct {
mu sync.RWMutex
// 配置信息
config *Config
// 哈希环
keys []int
// 哈希环到节点的映射
hashMap map[int]string
// 节点到虚拟节点数量的映射
nodeReplicas map[string]int
// 节点负载统计
nodeCounts map[string]int64
// 总请求数
totalRequests int64
}负载均衡设计
📌
- 统计周期内请求分布
- 计算出负载平均avgLoad = totalRequests / nodeCount
- 计算出最大负载偏差 maxDiff
- maxDiff > 阈值 重新平衡
- 调整虚拟节点数量
-负载高->减少虚拟节点
-负载低->增加虚拟节点
nodeCounts,每个节点请求数。
totalRequests,总的累计请求数字。
Go
//开启负载均衡
func New(opts ...Option) *Map { //一致性哈希构造函数
......
m.startBalancer() // 启动负载均衡器
......
}
//开启负载均衡器,进行检查和负载均衡
func (m *Map) startBalancer() {
go func() {
ticker := time.NewTicker(time.Second)
defer ticker.Stop()
for range ticker.C {
m.checkAndRebalance()
}
}()
}
func (m *Map) checkAndRebalance() {
if atomic.LoadInt64(&m.totalRequests) < 1000 {
return // 样本太少,不进行调整
}
// 计算负载情况
avgLoad := float64(m.totalRequests) / float64(len(m.nodeReplicas))
var maxDiff float64
for _, count := range m.nodeCounts {
diff := math.Abs(float64(count) - avgLoad)
if diff/avgLoad > maxDiff {
maxDiff = diff / avgLoad
}
}
// 如果负载不均衡度超过阈值,调整虚拟节点
if maxDiff > m.config.LoadBalanceThreshold {
m.rebalanceNodes()
}
}
// rebalanceNodes 重新平衡节点
func (m *Map) rebalanceNodes() {
m.mu.Lock()
defer m.mu.Unlock()
avgLoad := float64(m.totalRequests) / float64(len(m.nodeReplicas))
// 调整每个节点的虚拟节点数量
for node, count := range m.nodeCounts {
currentReplicas := m.nodeReplicas[node]
loadRatio := float64(count) / avgLoad
var newReplicas int
if loadRatio > 1 {
// 负载过高,减少虚拟节点
newReplicas = int(float64(currentReplicas) / loadRatio)
} else {
// 负载过低,增加虚拟节点
newReplicas = int(float64(currentReplicas) * (2 - loadRatio))
}
// 确保在限制范围内
if newReplicas < m.config.MinReplicas {
newReplicas = m.config.MinReplicas
}
if newReplicas > m.config.MaxReplicas {
newReplicas = m.config.MaxReplicas
}
if newReplicas != currentReplicas {
// 重新添加节点的虚拟节点
if err := m.Remove(node); err != nil {
continue // 如果移除失败,跳过这个节点
}
m.addNode(node, newReplicas)
}
}
// 重置计数器
for node := range m.nodeCounts {
m.nodeCounts[node] = 0
}
atomic.StoreInt64(&m.totalRequests, 0)
// 重新排序
sort.Ints(m.keys)
}哈希环设计
keys ->有序哈希环
储存所有虚拟节点的哈希值
hashMap->哈希值与实际节点名称的快速映射,O(1)获得目标