一. 完整的函数实现
1.sigmoid函数
import numpy as np
def sigmoid(z):
"""
Compute the sigmoid of z
Args:
z (ndarray): A scalar, numpy array of any size.
Returns:
g (ndarray): sigmoid(z), with the same shape as z
"""
### START CODE HERE ###
g = 1 / (1 + np.exp(-z))
### END SOLUTION ###
return g(1) 代码解析与说明
(a)核心公式
根据定义,sigmoid 函数为:
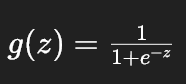
我们用 np.exp(-z) 来计算指数项,numpy 会自动对数组的每个元素进行计算,无需手动循环。
(b)功能特点
- 支持标量输入(如
sigmoid(0)) - 支持向量 / 矩阵输入(如
sigmoid(np.array([-1, 0, 1, 2]))) - 输出与输入的
shape完全一致
(2)测试代码与预期结果
# 测试标量输入
print("sigmoid(0) = " + str(sigmoid(0)))
# 预期输出: sigmoid(0) = 0.5
# 测试数组输入
print("sigmoid([-1, 0, 1, 2]) = " + str(sigmoid(np.array([-1, 0, 1, 2]))))
# 预期输出: sigmoid([-1, 0, 1, 2]) = [0.26894142 0.5 0.73105858 0.88079708]
# 单元测试(按题目要求)
from public_tests import *
sigmoid_test(sigmoid)(3)完整代码
# 1. 导入包
import numpy as np
import matplotlib.pyplot as plt
from utils import *
import copy
import math
%matplotlib inline
# 2. 加载数据
def load_data(filename):
# 这里假设 utils.py 已经实现了 load_data
data = np.loadtxt(filename, delimiter=',')
X = data[:, :2]
y = data[:, 2]
return X, y
X_train, y_train = load_data("data/ex2data1.txt")
# 查看数据
print("First five elements in X_train are:\n", X_train[:5])
print("Type of X_train:", type(X_train))
print("First five elements in y_train are:\n", y_train[:5])
print("Type of y_train:", type(y_train))
print('The shape of X_train is: ' + str(X_train.shape))
print('The shape of y_train is: ' + str(y_train.shape))
print('We have m = %d training examples' % (len(y_train)))
# 可视化数据
def plot_data(X, y, pos_label="Admitted", neg_label="Not admitted"):
# 这里假设 utils.py 已实现 plot_data,也可以自己实现
pos = y == 1
neg = y == 0
plt.scatter(X[pos, 0], X[pos, 1], marker='+', c='r', label=pos_label)
plt.scatter(X[neg, 0], X[neg, 1], marker='o', c='b', label=neg_label)
plot_data(X_train, y_train[:], pos_label="Admitted", neg_label="Not admitted")
plt.ylabel('Exam 2 score')
plt.xlabel('Exam 1 score')
plt.legend(loc="upper right")
plt.show()2. compute_gradient 函数
def compute_gradient(X, y, w, b, lambda_=None):
"""
Computes the gradient for logistic regression
Args:
X : (ndarray Shape (m,n)) variable such as house size
y : (array_like Shape (m,1)) actual value
w : (array_like Shape (n,1)) values of parameters of the model
b : (scalar) value of parameter of the model
lambda_: unused placeholder.
Returns:
dj_dw: (array_like Shape (n,1)) The gradient of the cost w.r.t. the parameters w.
dj_db: (scalar) The gradient of the cost w.r.t. the parameter b.
"""
m, n = X.shape
dj_dw = np.zeros(w.shape)
dj_db = 0.
### START CODE HERE ###
for i in range(m):
# 计算 z_wb = w·x + b
z_wb = 0
for j in range(n):
z_wb += X[i, j] * w[j]
z_wb += b
# 计算预测值 f_wb = sigmoid(z_wb)
f_wb = sigmoid(z_wb)
# 计算误差项
err = f_wb - y[i]
# 累加对 b 的梯度
dj_db += err
# 累加对 w_j 的梯度
for j in range(n):
dj_dw[j] += err * X[i, j]
# 取平均值
dj_dw = dj_dw / m
dj_db = dj_db / m
### END CODE HERE ###
return dj_db, dj_dw(1)代码解析与验证
(a)核心公式实现
根据题目给出的梯度公式:
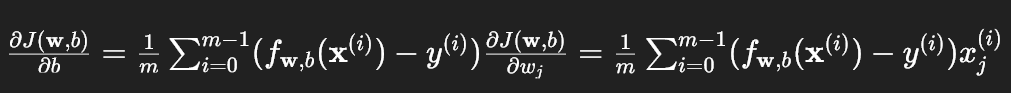
实现要点:
- 循环计算每个样本的预测值 :先计算线性部分
z_wb,再通过sigmoid函数得到概率预测f_wb - 计算误差项 :
err = f_wb - y[i] - 累加梯度 :对每个样本的误差进行累加,最后除以样本数
m取平均 - 与线性回归的区别 :虽然公式形式相似,但这里的
f_wb是 sigmoid 输出,而非线性回归的直接输出
(b)测试代码
# 测试1:w 初始化为 0
initial_w = np.zeros(n)
initial_b = 0.
dj_db, dj_dw = compute_gradient(X_train, y_train, initial_w, initial_b)
print(f'dj_db at initial w (zeros): {dj_db}')
print(f'dj_dw at initial w (zeros): {dj_dw.tolist()}')
# 预期输出:
# dj_db at initial w (zeros): -0.1
# dj_dw at initial w (zeros): [-12.00921658929115, -11.262842205513591]
# 测试2:非零 w
test_w = np.array([0.2, -0.5])
test_b = -24
dj_db, dj_dw = compute_gradient(X_train, y_train, test_w, test_b)
print('dj_db at test_w:', dj_db)
print('dj_dw at test_w:', dj_dw.tolist())
# 预期输出:
# dj_db at test_w: -0.59999999999991071
# dj_dw at test_w: [-44.8313536178737957, -44.37384124953978](2)完整的梯度下降与训练流程:
# 定义损失函数(逻辑回归交叉熵损失)
def compute_cost(X, y, w, b, lambda_=None):
m = X.shape[0]
cost = 0.0
for i in range(m):
z_i = np.dot(X[i], w) + b
f_wb_i = sigmoid(z_i)
cost += -y[i] * np.log(f_wb_i) - (1 - y[i]) * np.log(1 - f_wb_i)
cost = cost / m
return cost
# 初始化参数
np.random.seed(1)
initial_w = 0.01 * (np.random.rand(2).reshape(-1,1) - 0.5)
initial_b = -8
# 梯度下降设置
iterations = 10000
alpha = 0.001
# 运行梯度下降
w, b, J_history, _ = gradient_descent(X_train, y_train, initial_w, initial_b,
compute_cost, compute_gradient,
alpha, iterations, 0)
# 查看最终成本
print(f"Final cost: {J_history[-1]:.2f}")
# 预期输出:Final cost: 0.30(3)额外优化:向量化实现
def compute_gradient_vectorized(X, y, w, b, lambda_=None):
m = X.shape[0]
# 向量化计算 z_wb = X@w + b
z = np.dot(X, w) + b
f_wb = sigmoid(z)
# 误差项
err = f_wb - y.reshape(-1,1)
# 梯度计算
dj_dw = (1/m) * np.dot(X.T, err)
dj_db = (1/m) * np.sum(err)
return dj_db, dj_dw3.正则化损失函数 compute_cost_reg 实现
根据题目给出的公式:
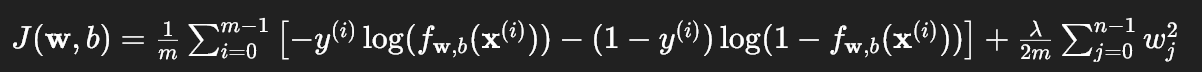
def compute_cost_reg(X, y, w, b, lambda_=1):
"""
Computes the cost over all examples for logistic regression with regularization
Args:
X : (ndarray Shape (m,n)) data, m examples by n features
y : (array_like Shape (m,)) target value
w : (array_like Shape (n,)) Values of parameters of the model
b : (scalar) Values of parameter of the model
lambda_ : (scalar, float) Controls amount of regularization
Returns:
total_cost: (scalar) cost
"""
m, n = X.shape
# 1. 计算基础交叉熵损失
cost = 0.0
for i in range(m):
z_i = np.dot(X[i], w) + b
f_wb_i = sigmoid(z_i)
cost += -y[i] * np.log(f_wb_i) - (1 - y[i]) * np.log(1 - f_wb_i)
cost = cost / m
# 2. 计算正则化项(不对b正则)
reg_cost = 0
for j in range(n):
reg_cost += w[j] ** 2
reg_cost = (lambda_ / (2 * m)) * reg_cost
# 3. 总损失
total_cost = cost + reg_cost
return total_cost4. 正则化梯度函数 compute_gradient_reg 实现
根据题目给出的公式:
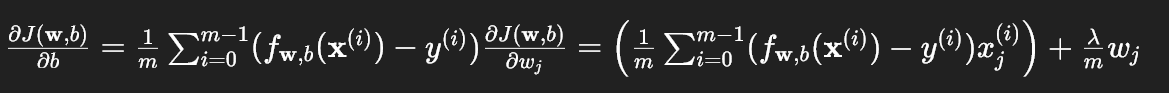
def compute_gradient_reg(X, y, w, b, lambda_=1):
"""
Computes the gradient for logistic regression with regularization
Args:
X : (ndarray Shape (m,n)) variable such as house size
y : (array_like Shape (m,)) actual value
w : (array_like Shape (n,)) values of parameters of the model
b : (scalar) value of parameter of the model
lambda_ : (scalar,float) regularization constant
Returns:
dj_db: (scalar) The gradient of the cost w.r.t. the parameter b.
dj_dw: (array_like Shape (n,)) The gradient of the cost w.r.t. the parameters w.
"""
m, n = X.shape
dj_dw = np.zeros(w.shape)
dj_db = 0.
# 1. 计算基础梯度(无正则)
for i in range(m):
z_wb = np.dot(X[i], w) + b
f_wb = sigmoid(z_wb)
err = f_wb - y[i]
dj_db += err
for j in range(n):
dj_dw[j] += err * X[i, j]
dj_dw = dj_dw / m
dj_db = dj_db / m
# 2. 添加正则化梯度项
for j in range(n):
dj_dw[j] += (lambda_ / m) * w[j]
return dj_db, dj_dw(1) 完整训练流程(含特征映射与模型训练)
# ----------------------
# 1. 加载与可视化数据
# ----------------------
X_train, y_train = load_data("data/ex2data2.txt")
print("X_train:", X_train[:5])
print("Type of X_train:", type(X_train))
print("y_train:", y_train[:5])
print("Type of y_train:", type(y_train))
print('The shape of X_train is: ' + str(X_train.shape))
print('The shape of y_train is: ' + str(y_train.shape))
print('We have m = %d training examples' % (len(y_train)))
# 可视化数据
plot_data(X_train, y_train[:], pos_label="Accepted", neg_label="Rejected")
plt.ylabel('Microchip Test 2')
plt.xlabel('Microchip Test 1')
plt.legend(loc="upper right")
plt.show()
# ----------------------
# 2. 特征映射(多项式特征)
# ----------------------
print("Original shape of data:", X_train.shape)
mapped_X = map_feature(X_train[:, 0], X_train[:, 1])
print("Shape after feature mapping:", mapped_X.shape)
print("X_train[0]:", X_train[0])
print("mapped X_train[0]:", mapped_X[0])
# ----------------------
# 3. 初始化参数并训练模型
# ----------------------
np.random.seed(1)
initial_w = np.random.rand(mapped_X.shape[1]) - 0.5
initial_b = 1.
lambda_ = 0.01 # 正则化参数
iterations = 10000
alpha = 0.01
# 运行梯度下降
w, b, J_history, _ = gradient_descent(mapped_X, y_train, initial_w, initial_b,
compute_cost_reg, compute_gradient_reg,
alpha, iterations, lambda_)
# ----------------------
# 4. 绘制决策边界
# ----------------------
plot_decision_boundary(w, b, mapped_X, y_train)
# ----------------------
# 5. 评估模型准确率
# ----------------------
def predict(X, w, b):
"""
Predict whether the label is 0 or 1 using learned logistic regression parameters w, b
Args:
X : (ndarray Shape (m,n)) data, m examples by n features
w : (array_like Shape (n,)) parameters
b : (scalar) parameter
Returns:
p : (array_like Shape (m,)) predictions (0 or 1)
"""
m = X.shape[0]
p = np.zeros(m)
for i in range(m):
z_wb = np.dot(X[i], w) + b
f_wb = sigmoid(z_wb)
p[i] = 1 if f_wb >= 0.5 else 0
return p
# 计算训练集准确率
p = predict(mapped_X, w, b)
print('Train Accuracy: %f' % (np.mean(p == y_train) * 100))
# 预期输出:训练准确率约 80%(2)关键代码解析
(a)正则化的作用
- 损失函数中的正则项 :
(lambda_ / (2*m)) * sum(w²)会惩罚过大的权重,防止模型过拟合。 - 梯度中的正则项 :
(lambda_ / m) * w[j]会让权重在更新时向 0 收缩,降低模型复杂度。
(b)超参数调优建议
lambda_控制正则强度:lambda_过大:模型会欠拟合(决策边界过于平滑)lambda_过小:模型会过拟合(决策边界过于复杂)
- 可以尝试
lambda_ = 0.1, 1, 10对比效果,通常lambda_=0.01~1在此数据集上效果较好。
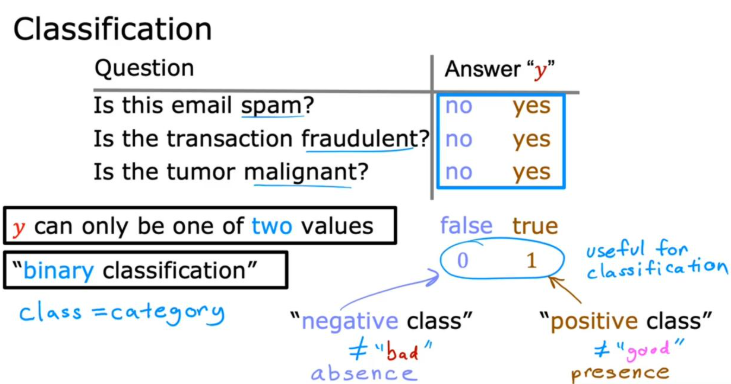
二.分类
1. 分类问题的本质
- 目标:预测离散类别 (比如肿瘤良性 / 恶性、邮件垃圾 / 非垃圾),典型的二分类问题 只有两种结果(用
y=0表示负类 / 良性,y=1表示正类 / 恶性)。 - 可视化习惯:用不同符号区分结果,比如实验里用
X表示正类(y=1)、O表示负类(y=0)。
2. 线性回归的局限
线性回归的核心是预测连续数值,输出可以是任意实数;但分类任务的输出必须是离散的(0 或 1),两者的本质目标存在冲突。
3、实验代码与可视化解析
(1)数据准备与绘图代码
import numpy as np
%matplotlib widget
import matplotlib.pyplot as plt
from lab_utils_common import dlc, plot_data
from plt_one_addpt_onclick import plt_one_addpt_onclick
# 全局样式
plt.style.use('./deeplearning.mplstyle')
# 单变量数据(肿瘤大小 vs 良恶性)
x_train = np.array([0., 1, 2, 3, 4, 5])
y_train = np.array([0, 0, 0, 1, 1, 1])
# 双变量数据(肿瘤的两个特征)
X_train2 = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]])
y_train2 = np.array([0, 0, 0, 1, 1, 1])
# 区分正负样本索引
pos = y_train == 1
neg = y_train == 0
# 创建双图布局:单变量 + 双变量
fig,ax = plt.subplots(1,2,figsize=(8,3))
# 图1:单变量数据可视化
ax[0].scatter(x_train[pos], y_train[pos], marker='x', s=80, c = 'red', label="y=1")
ax[0].scatter(x_train[neg], y_train[neg], marker='o', s=100, label="y=0",
facecolors='none', edgecolors=dlc["d1blue"],lw=3)
ax[0].set_ylim(-0.08,1.1)
ax[0].set_ylabel('y', fontsize=12)
ax[0].set_xlabel('x', fontsize=12)
ax[0].set_title('one variable plot')
ax[0].legend()
# 图2:双变量数据可视化
plot_data(X_train2, y_train2, ax[1])
ax[1].axis([0, 4, 0, 4])
ax[1].set_ylabel('$x_1$', fontsize=12)
ax[1].set_xlabel('$x_0$', fontsize=12)
ax[1].set_title('two variable plot')
ax[1].legend()
plt.tight_layout()
plt.show()运行后会得到两个关键图表:
- 左图(单变量):横轴是肿瘤大小,纵轴是标签(0/1),
O代表良性肿瘤,X代表恶性肿瘤。 - 右图(双变量):横轴和纵轴是肿瘤的两个特征,用符号直接区分良恶性,不再用纵轴表示标签。
(2) 线性回归在分类数据上的表现
实验核心步骤:
w_in = np.zeros((1))
b_in = 0
plt.close('all')
addpt = plt_one_addpt_onclick( x_train,y_train, w_in, b_in, logistic=False)运行后会得到交互式图表:
- 初始拟合:线性回归会拟合一条穿过数据的直线,对原始数据来说,用 0.5 作为阈值时,分类效果看似 "不错"。
- 加入极端数据点后 :当你在右侧添加更多 "大肿瘤恶性" 数据点时,线性回归的直线会被 "拉偏",导致原本正确的
x=3处的恶性肿瘤被错误预测为良性。 - 根本问题 :线性回归的输出会超出
[0,1]范围,无法天然适配二分类任务;且对极端数据非常敏感,无法保证分类的稳定性。
4.核心结论与后续方向
(1) 线性回归不适合分类任务的原因
| 维度 | 线性回归 | 分类任务 |
|---|---|---|
| 输出类型 | 连续数值(任意实数) | 离散类别(如 0/1) |
| 模型目标 | 拟合数据的连续趋势 | 学习决策边界,区分不同类别 |
| 稳定性 | 易受极端数据点影响 | 需要对异常值鲁棒 |
| 输出范围 | 无限制 | 需天然落在 [0,1] 区间(概率意义) |
(2)引出逻辑回归的必要性
为了解决线性回归的缺陷,我们需要一种输出天然在 [0,1] 之间、表示概率 的模型,这就是逻辑回归(Logistic Regression):
- 用
sigmoid函数将线性回归的输出压缩到(0,1)区间,解释为 "属于正类的概率"; - 用交叉熵损失替代均方误差,适配分类任务的优化目标;
- 对极端数据点的鲁棒性更强,更适合二分类场景。
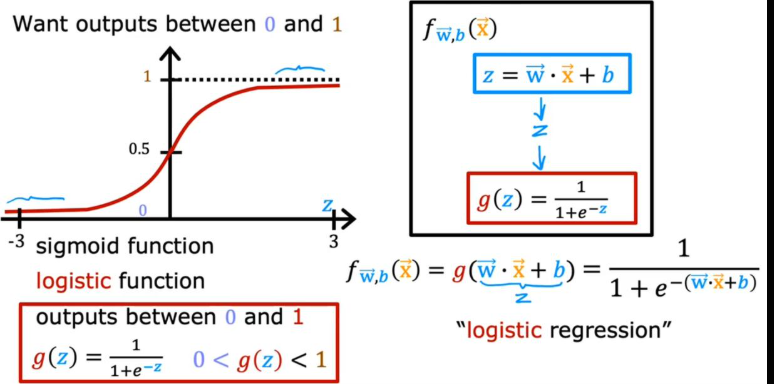
三.Sigmoid 函数
1. 函数定义与作用
Sigmoid 函数的公式:
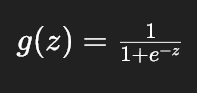
- 核心作用:将任意实数输入 z 映射到区间 \((0,1)\) 内,输出天然可以解释为 "概率"。
- 关键特性:

2. Python 实现与测试
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(z):
"""
计算sigmoid函数值
Args:
z (ndarray): 标量或任意形状的numpy数组
Returns:
g (ndarray): sigmoid(z),与z形状相同
"""
g = 1 / (1 + np.exp(-z))
return g
# 测试标量和数组输入
input_val = 1
exp_val = sigmoid(input_val)
print(f"Input: {input_val}, Sigmoid Output: {exp_val:.4f}")
input_array = np.array([-10, -5, 0, 5, 10])
output_array = sigmoid(input_array)
print(f"Input: {input_array}, Sigmoid Output: {output_array.round(4)}")3. 函数可视化
# 生成-10到10的测试数据
z_tmp = np.arange(-10, 11)
y = sigmoid(z_tmp)
# 绘制sigmoid曲线
fig, ax = plt.subplots(1, 1, figsize=(5, 3))
ax.plot(z_tmp, y, c="b")
ax.set_title("Sigmoid function")
ax.set_ylabel("sigmoid(z)")
ax.set_xlabel("z")
ax.axvline(x=0, color='gray', linestyle='--')
plt.show()4.逻辑回归模型结构
逻辑回归本质上是线性回归 + Sigmoid 激活的组合,模型公式:\(f_{\mathbf{w},b}(\mathbf{x}) = g(\mathbf{w} \cdot \mathbf{x} + b) = \frac{1}{1+e^{-(\mathbf{w} \cdot \mathbf{x} + b)}}\)
- 输入:线性回归的输出 \(z = \mathbf{w} \cdot \mathbf{x} + b\)(可以是任意实数)。
- 输出:经过 Sigmoid 函数压缩后的概率值,范围 \((0,1)\),表示样本属于正类(如恶性肿瘤)的概率。
- 分类规则:通常以 0.5 为阈值,若 \(f_{\mathbf{w},b}(\mathbf{x}) \ge 0.5\),预测为正类(\(y=1\));否则预测为负类(\(y=0\))。
5.逻辑回归 vs 线性回归
(1)实验数据与代码
# 肿瘤大小与良恶性数据
x_train = np.array([0., 1, 2, 3, 4, 5])
y_train = np.array([0, 0, 0, 1, 1, 1])
# 初始化参数
w_in = np.zeros((1))
b_in = 0
# 交互式逻辑回归实验
plt.close('all')
addpt = plt_one_addpt_onclick(x_train, y_train, w_in, b_in, logistic=True)(2) 核心对比结论
| 场景 | 线性回归表现 | 逻辑回归表现 |
|---|---|---|
| 原始数据拟合 | 看似有效,但输出无界 | 输出天然在 (0,1) 区间,拟合效果好 |
| 添加极端数据点 | 直线被 "拉偏",分类边界错误 | 不受极端值影响,分类边界稳定 |
| 输出含义 | 无概率解释 | 直接表示属于正类的概率 |
| 优化目标 | 均方误差(适合连续值) | 交叉熵损失(适合分类任务) |
6.关键知识点总结
- Sigmoid 函数是逻辑回归的 "灵魂":它解决了线性回归输出无界的问题,让模型可以输出可解释的概率值。
- 逻辑回归不是回归,而是分类算法:它的目标是学习一个线性决策边界,将不同类别的样本分开。
- 鲁棒性优势:相比线性回归,逻辑回归对极端数据点的敏感度更低,更适合分类任务。
四.决策边界
逻辑回归模型的核心公式是:fw,ь(x)=g(w . x+b)
其中 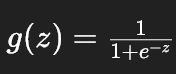 是 Sigmoid 函数。
是 Sigmoid 函数。
- 当fw,b(x) ≥0.5时,模型预测y=1(正类);
- 当 fw,b(x) <0.5 时,模型预测 y=0(负类)。
而 g(z) ≥ 0.5 的条件等价于z ≥ 0,因此决策边界就是满足 w . x+b=0的点集。这个实验就是要帮你可视化这个边界,理解它如何划分样本空间。
1. 数据集
实验用的是一个二特征的二分类数据集:
import numpy as np
import matplotlib.pyplot as plt
from lab_utils_common import plot_data, sigmoid
# 训练数据:6个样本,每个样本2个特征
X = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]])
y = np.array([0, 0, 0, 1, 1, 1]).reshape(-1,1)
# 可视化数据
fig, ax = plt.subplots(1,1, figsize=(4,4))
plot_data(X, y, ax)
ax.axis([0, 4, 0, 3.5])
ax.set_ylabel('$x_1$')
ax.set_xlabel('$x_0$')
plt.show()- 蓝色圆圈:y=0(负类)样本;
- 红色叉号:y=1(正类)样本。
2. 训练好的模型参数
实验中假设模型已经训练完成,参数为:
- b = -3,w_0 = 1,w_1 = 1
- 因此模型公式为:f(x) = g(x_0 + x_1 - 3)
3.决策边界的推导与绘制
(1)决策边界的数学推导
根据逻辑回归的分类规则:
- 当 x_0 + x_1 - 3 ≥ 0 时,模型预测 y=1;
- 当 x_0 + x_1 - 3 < 0 时,模型预测 y=0。
因此决策边界就是方程 \(x_0 + x_1 - 3 = 0\),整理得:\(x_1 = 3 - x_0\)这是一条直线,它将二维平面分成了两个区域。
(2)决策边界的可视化代码
# 生成x0的取值范围
x0 = np.arange(0, 6)
# 根据决策边界方程计算对应的x1
x1 = 3 - x0
# 绘制决策边界和数据
fig, ax = plt.subplots(1,1, figsize=(5,4))
ax.plot(x0, x1, c="b") # 绘制决策边界直线
ax.fill_between(x0, x1, alpha=0.2) # 填充负类区域
plot_data(X, y, ax) # 绘制原始数据点
ax.axis([0, 4, 0, 3.5])
ax.set_ylabel('$x_1$')
ax.set_xlabel('$x_0$')
plt.show()- 蓝色直线:决策边界 x_1 = 3 - x_0;
- 蓝色阴影区域:满足 x_0 + x_1 - 3 < 0的区域,模型会预测 y=0;
- 直线上方区域:满足 x_0 + x_1 - 3 > 0的区域,模型会预测 y=1。
4.关键知识点总结
(1)决策边界的本质
决策边界是模型预测结果发生变化的 "分界线",它是由模型参数 w和 b 决定的。对于线性逻辑回归,决策边界一定是线性的(直线 / 超平面)。
2. 线性 vs 非线性决策边界
- 线性逻辑回归:决策边界是直线(或超平面),只能处理线性可分的数据;
- 多项式逻辑回归:通过引入高阶项(如 x_0^2, x_1^2,可以生成非线性的决策边界,处理更复杂的数据分布。
3. 决策边界与模型参数的关系
决策边界的位置和方向由参数 \(\mathbf{w}\) 和 b 决定:
- w决定了决策边界的法向量方向,也就是分类的方向;
- b 决定了决策边界的位置,相当于直线的截距。
五.损失函数(交叉熵损失)
1. 单样本损失函数定义
为了解决平方误差损失的问题,逻辑回归使用专门的损失函数,针对单个样本的损失定义为:
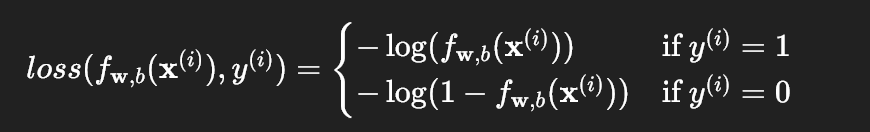
- 当 y=1 时,损失函数是 -log(f):预测值 f 越接近 1,损失越小;越接近 0,损失越大。
- 当 y=0 时,损失函数是 -log(1-f):预测值 f 越接近 0,损失越小;越接近 1,损失越大。
实验中绘制了两种情况下的损失曲线:
2. 统一形式的损失函数
上面的分段函数可以合并成一个统一的表达式: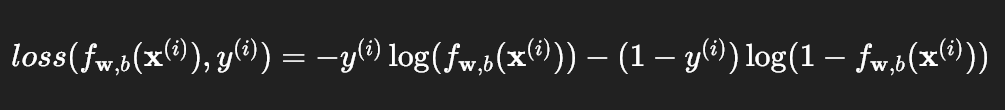

3. 成本函数(全训练集平均损失)
将所有样本的损失取平均,得到逻辑回归的成本函数:
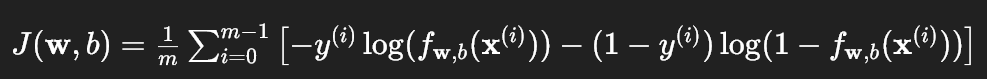
这个成本函数是凸函数,通过梯度下降可以稳定地找到全局最小值。实验中绘制了这个成本函数的曲面:
4.Python 实现逻辑损失函数
下面是逻辑损失函数的完整实现,以及在实验数据上的应用:
import numpy as np
import matplotlib.pyplot as plt
from lab_utils_common import sigmoid
def compute_cost_logistic(X, y, w, b):
"""
计算逻辑回归的成本函数(交叉熵损失)
Args:
X (ndarray): (m, n) 特征矩阵
y (ndarray): (m,) 标签向量
w (ndarray): (n,) 模型参数
b (scalar): 模型偏置项
Returns:
cost (scalar): 成本值
"""
m = X.shape[0]
cost = 0.0
for i in range(m):
z_i = np.dot(X[i], w) + b
f_wb_i = sigmoid(z_i)
cost += -y[i] * np.log(f_wb_i) - (1 - y[i]) * np.log(1 - f_wb_i)
cost /= m
return cost
# 实验数据
x_train = np.array([0., 1, 2, 3, 4, 5], dtype=np.longdouble)
y_train = np.array([0, 0, 0, 1, 1, 1], dtype=np.longdouble)
# 示例参数
w = np.array([1.0])
b = -3.0
# 计算成本
X_train = x_train.reshape(-1, 1)
cost = compute_cost_logistic(X_train, y_train, w, b)
print(f"Cost at (w={w}, b={b}): {cost:.4f}")5.知识点总结
| 损失函数 | 适用场景 | 函数性质 | 优化效果 |
|---|---|---|---|
| 平方误差损失 | 线性回归(连续值预测) | 凸函数 | 梯度下降易收敛到全局最优 |
| 平方误差损失(+Sigmoid) | 逻辑回归(分类任务) | 非凸函数 | 易陷入局部最优,无法收敛 |
| 交叉熵损失 | 逻辑回归(分类任务) | 凸函数 | 梯度下降可稳定收敛到全局最优 |
六.成本函数
1.准备
(1)数据集
实验使用和「决策边界」实验相同的二特征二分类数据集:
import numpy as np
%matplotlib widget
import matplotlib.pyplot as plt
from lab_utils_common import plot_data, sigmoid, dlc
plt.style.use('./deeplearning.mplstyle')
# 训练数据:6个样本,每个样本2个特征
X_train = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]])
y_train = np.array([0, 0, 0, 1, 1, 1])(2)数据可视化
fig, ax = plt.subplots(1,1, figsize=(4,4))
plot_data(X_train, y_train, ax)
ax.axis([0, 4, 0, 3.5])
ax.set_ylabel('$x_1$', fontsize=12)
ax.set_xlabel('$x_0$', fontsize=12)
plt.show()- 蓝色圆圈:y=0(负类)样本;
- 红色叉号:y=1(正类)样本。
2.逻辑回归成本函数实现
(1) 成本函数公式回顾
逻辑回归的成本函数是所有样本交叉熵损失的平均值:
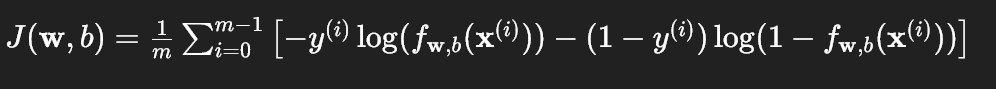
其中:
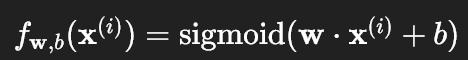
- m 是训练样本数量
(2) Python 实现
def compute_cost_logistic(X, y, w, b):
"""
计算逻辑回归的成本函数
Args:
X (ndarray (m,n)): 特征矩阵,m个样本,n个特征
y (ndarray (m,)): 标签向量
w (ndarray (n,)): 模型权重参数
b (scalar): 模型偏置项
Returns:
cost (scalar): 交叉熵成本值
"""
m = X.shape[0]
cost = 0.0
for i in range(m):
# 计算线性输出 z = w·x + b
z_i = np.dot(X[i], w) + b
# 计算模型预测值 f = sigmoid(z)
f_wb_i = sigmoid(z_i)
# 累加单个样本的交叉熵损失
cost += -y[i] * np.log(f_wb_i) - (1 - y[i]) * np.log(1 - f_wb_i)
# 取所有样本的平均损失
cost /= m
return cost(3)成本函数验证
使用已知参数 w = [1,1]、b = -3 验证成本函数的正确性:
w_tmp = np.array([1,1])
b_tmp = -3
print(compute_cost_logistic(X_train, y_train, w_tmp, b_tmp))
# 输出:0.36686678640551745(与预期结果一致)3.成本函数与模型拟合效果的关系
(1)两个模型的决策边界对比
实验中对比了两组参数的决策边界:
-
模型 1:
w = [1,1],b = -3,决策边界为 x_0 + x_1 - 3 = 0(即 x_1 = 3 - x_0) -
模型 2:
w = [1,1],b = -4,决策边界为 x_0 + x_1 - 4 = 0(即 x_1 = 4 - x_0)绘制两个决策边界
x0 = np.arange(0,6)
x1 = 3 - x0 # b=-3的决策边界
x1_other = 4 - x0 # b=-4的决策边界fig, ax = plt.subplots(1,1, figsize=(4,4))
ax.plot(x0, x1, c=dlc["dlblue"], label="b=-3")
ax.plot(x0, x1_other, c=dlc["dlmagenta"], label="b=-4")
ax.axis([0, 4, 0, 4])
plot_data(X_train, y_train, ax)
ax.set_ylabel('x_1', fontsize=12)
ax.set_xlabel('x_0', fontsize=12)
plt.legend(loc="upper right")
plt.title("Decision Boundary")
plt.show()
(2)成本值对比
计算两个模型的成本值:
w_array1 = np.array([1,1])
b_1 = -3
w_array2 = np.array([1,1])
b_2 = -4
print("Cost for b = -3 : ", compute_cost_logistic(X_train, y_train, w_array1, b_1))
print("Cost for b = -4 : ", compute_cost_logistic(X_train, y_train, w_array2, b_2))输出结果:
b=-3时,成本值为0.36686678640551745b=-4时,成本值为0.5036808636748461
可以看到,模型拟合效果越好,成本值越低,成本函数成功反映了模型的优劣。
4.关键知识点总结
- 成本函数的意义:逻辑回归的成本函数(交叉熵损失)是模型拟合效果的量化指标,成本越低,模型预测结果与真实标签的偏差越小。
- 决策边界与成本的关系:决策边界越能正确划分正负样本,成本值越低;反之,成本值越高。
- 成本函数的凸性:交叉熵成本函数是凸函数,通过梯度下降可以稳定地找到全局最小值,这也是逻辑回归选择交叉熵损失的核心原因。
七.逻辑回归梯度下降法
1.关键公式

2.代码实现
(1)导入依赖与初始化
import copy, math
import numpy as np
%matplotlib widget
import matplotlib.pyplot as plt
from lab_utils_common import dlc, plot_data, plt_tumor_data, sigmoid, compute_cost_logistic
from plt_quad_logistic import plt_quad_logistic, plt_prob
plt.style.use('./deeplearning.mplstyle')(2)数据集准备
# 双特征数据集
X_train = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]])
y_train = np.array([0, 0, 0, 1, 1, 1])
# 单特征数据集(后续使用)
x_train = np.array([0., 1, 2, 3, 4, 5])
y_train_single = np.array([0, 0, 0, 1, 1, 1])(3)核心函数:计算梯度 compute_gradient_logistic
这是你需要重点实现的部分,和公式一一对应:
def compute_gradient_logistic(X, y, w, b):
"""
计算逻辑回归的梯度
参数:
X (ndarray (m,n)): 数据,m个样本n个特征
y (ndarray (m,)): 目标值
w (ndarray (n,)): 模型参数
b (scalar) : 模型参数
返回:
dj_dw (ndarray (n,)): 成本对w的梯度
dj_db (scalar) : 成本对b的梯度
"""
m,n = X.shape
dj_dw = np.zeros((n,))
dj_db = 0.
for i in range(m):
# 1. 计算模型预测值
f_wb_i = sigmoid(np.dot(X[i],w) + b)
# 2. 计算误差
err_i = f_wb_i - y[i]
# 3. 累加对每个w_j的梯度
for j in range(n):
dj_dw[j] = dj_dw[j] + err_i * X[i,j]
# 4. 累加对b的梯度
dj_db = dj_db + err_i
# 5. 除以样本数m,得到平均梯度
dj_dw = dj_dw/m
dj_db = dj_db/m
return dj_db, dj_dw单元测试验证:
X_tmp = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]])
y_tmp = np.array([0, 0, 0, 1, 1, 1])
w_tmp = np.array([2.,3.])
b_tmp = 1.
dj_db_tmp, dj_dw_tmp = compute_gradient_logistic(X_tmp, y_tmp, w_tmp, b_tmp)
print(f"dj_db: {dj_db_tmp}")
print(f"dj_dw: {dj_dw_tmp.tolist()}")输出应和题目给出的一致:
dj_db: 0.49861806546328574
dj_dw: [0.498333393278696, 0.49883942983996693](4)梯度下降主函数 gradient_descent
def gradient_descent(X, y, w_in, b_in, alpha, num_iters):
"""
执行批量梯度下降
参数:
X (ndarray (m,n)) : 数据
y (ndarray (m,)) : 目标值
w_in (ndarray (n,)): 初始w
b_in (scalar) : 初始b
alpha (float) : 学习率
num_iters (int) : 迭代次数
返回:
w (ndarray (n,)): 训练后的w
b (scalar) : 训练后的b
J_history (list): 每次迭代的成本值
"""
J_history = []
w = copy.deepcopy(w_in)
b = b_in
for i in range(num_iters):
# 1. 计算当前梯度
dj_db, dj_dw = compute_gradient_logistic(X, y, w, b)
# 2. 更新参数
w = w - alpha * dj_dw
b = b - alpha * dj_db
# 3. 保存成本值(用于可视化)
if i<100000:
J_history.append(compute_cost_logistic(X, y, w, b))
# 4. 每隔一定次数打印成本
if i% math.ceil(num_iters / 10) == 0:
print(f"Iteration {i:4d}: Cost {J_history[-1]}")
return w, b, J_history(5)运行梯度下降并可视化
# 初始化参数
w_tmp = np.zeros_like(X_train[0])
b_tmp = 0.
alph = 0.1
iters = 10000
# 训练模型
w_out, b_out, _ = gradient_descent(X_train, y_train, w_tmp, b_tmp, alph, iters)
print(f"\nupdated parameters: w:{w_out}, b:{b_out}")
# 绘制结果
fig,ax = plt.subplots(1,1,figsize=(5,4))
# 绘制概率热力图
plt_prob(ax, w_out, b_out)
# 绘制原始数据
ax.set_ylabel(r'$x_1$')
ax.set_xlabel(r'$x_0$')
ax.axis([0, 4, 0, 3.5])
plot_data(X_train,y_train,ax)
# 绘制决策边界(概率=0.5的直线)
x0 = -b_out/w_out[0]
x1 = -b_out/w_out[1]
ax.plot([0,x0],[x1,0], c=dlc["dlblue"], lw=1)
plt.show()运行后会得到和题目中一致的结果:
- 成本随迭代不断下降,最终趋近于 0
- 决策边界能完美区分正负样本
3.代码关键细节说明
- 梯度计算的同步更新 :在梯度下降中,
w和b必须使用同一轮迭代计算出的梯度更新,不能边计算边更新,否则会破坏同步性。 - 学习率选择 :逻辑回归的梯度下降对学习率比较敏感,本实验中使用
alpha=0.1效果稳定。如果学习率太大,成本可能会震荡甚至发散;太小则收敛过慢。 - 决策边界推导 :当预测概率为 0.5 时,
sigmoid(z)=0.5对应z=0,即w·x + b = 0,整理后得到直线方程x1 = -(w0/w1)x0 - b/w1,也就是代码中绘制的那条线。
八.Scikit-Learn 实现逻辑回归
1.完整代码与步骤解析
(1)导入依赖与数据集准备
和之前手动实现梯度下降的数据集完全一致:
import numpy as np
# 双特征数据集
X = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]])
y = np.array([0, 0, 0, 1, 1, 1])(2)导入并训练 LogisticRegression 模型
from sklearn.linear_model import LogisticRegression
# 初始化模型(默认参数)
lr_model = LogisticRegression()
# 拟合训练数据
lr_model.fit(X, y)LogisticRegression默认使用 L2 正则化 ,优化器为lbfgs,适用于中小型数据集,收敛速度比手动实现的批量梯度下降更快。
(3) 模型预测
# 对训练集进行预测
y_pred = lr_model.predict(X)
print("Prediction on training set:", y_pred)输出:
Prediction on training set: [0 0 0 1 1 1]- 预测结果和真实标签完全一致,说明模型在训练集上实现了 100% 分类正确。
(4)计算模型精度
# 计算准确率(正确预测的样本数 / 总样本数)
print("Accuracy on training set:", lr_model.score(X, y))输出:
Accuracy on training set: 1.0score()函数直接返回分类准确率,这里1.0表示模型在训练集上零错误分类。
2.拓展知识点:模型参数查看与决策边界
查看模型学到的参数,并绘制决策边界,和之前手动实现的结果对比:
# 查看模型参数
print("系数w:", lr_model.coef_)
print("截距b:", lr_model.intercept_)
# 绘制决策边界
import matplotlib.pyplot as plt
from lab_utils_common import plot_data, dlc
fig, ax = plt.subplots(1,1,figsize=(5,4))
plot_data(X, y, ax)
# 决策边界:w0*x0 + w1*x1 + b = 0 → x1 = -(w0/w1)*x0 - b/w1
w = lr_model.coef_[0]
b = lr_model.intercept_[0]
x0 = np.arange(0, 4, 0.1)
x1 = -(w[0] * x0 + b) / w[1]
ax.plot(x0, x1, c=dlc["dlblue"], lw=1)
ax.set_ylabel(r'$x_1$')
ax.set_xlabel(r'$x_0$')
ax.axis([0, 4, 0, 3.5])
plt.show()- 你会发现
scikit-learn训练出的决策边界和手动梯度下降的结果基本一致,只是参数略有差异(因为优化算法不同)。
关键区别:手动实现 vs Scikit-Learn
| 对比项 | 手动实现梯度下降 | Scikit-Learn LogisticRegression |
|---|---|---|
| 优化算法 | 批量梯度下降(BGD) | 默认 lbfgs(拟牛顿法),可选 saga 等 |
| 正则化 | 无(可手动添加) | 默认 L2 正则化,可通过 penalty 调整 |
| 收敛速度 | 较慢,需手动调学习率 | 快,自动选择步长,无需手动调参 |
| 适用场景 | 教学、理解算法原理 | 工业界、快速原型开发 |
九.过拟合实验
1.核心概念:欠拟合 vs 过拟合 vs 合适拟合
| 类型 | 表现 | 原因 |
|---|---|---|
| 欠拟合(Underfitting) | 模型在训练集和测试集上误差都很高 | 模型太简单(如 1 阶线性模型),无法捕捉数据的真实规律 |
| 合适拟合(Just Right) | 训练误差低,测试误差也低,两者差距小 | 模型复杂度与数据真实分布匹配 |
| 过拟合(Overfitting) | 训练误差极低,测试误差很高,两者差距大 | 模型太复杂(如 6 阶多项式),过度学习了训练集的噪声和异常值 |
从实验的交互界面可以清晰看到:
- 选 Degree=1:模型是一条直线,无法拟合数据的二次趋势,属于欠拟合。
- 选 Degree=6:模型曲线会极力穿过每一个训练样本点,甚至学习了噪声,对新数据的泛化能力差,属于典型的过拟合。
- 选 Degree=2/3:模型曲线和 "理想曲线" 最接近,泛化能力最好。
2.缓解过拟合的 4 种经典方法
(1)增加训练数据
- 原理:更多的样本可以让模型学习到更真实的分布,减少对噪声的依赖。
- 实验体现:添加更多 "正常样本" 可以降低过拟合;但添加异常值 / 极端点反而会加剧过拟合。
(2)正则化(Regularization)
- 原理:在损失函数中加入对模型参数的惩罚项,限制参数的大小,避免模型过度复杂。

- 常见类型:L1 正则化(Lasso)、L2 正则化(Ridge)。逻辑回归中默认的 L2 正则化就是为了防止过拟合。
(3)特征选择 / 降维
- 原理:去掉无关或冗余的特征,减少模型的复杂度,避免学习到噪声特征。
- 实验体现:选择部分特征(而非所有特征)训练模型,往往能得到更好的泛化效果。
(4)降低模型复杂度
- 原理:使用更简单的模型(如降低多项式阶数、减少神经网络层数 / 神经元数),减少模型的表达能力,使其无法过度拟合噪声。
3.实验交互操作指南
根据实验说明,你可以这样操作来观察现象:
- 切换模式 :在
Regression(回归)和Categorical(分类)之间切换,观察过拟合在两种任务中的表现。 - 调整模型阶数 :
- 选
Degree=1:观察欠拟合,模型无法捕捉数据趋势。 - 选
Degree=6:观察过拟合,模型曲线剧烈波动,紧贴每个训练点。 - 选
Degree=2/3:观察合适拟合,曲线和理想曲线最接近。
- 选
- 添加数据点 :
- 正常数据点:增加样本量,过拟合现象会缓解。
- 异常值 / 极端点:会让模型为了拟合这些点而变得复杂,加剧过拟合。
十.正则化成本与梯度
1.正则化的核心原理
L2 正则化(岭回归)的核心是在成本函数中加入参数平方和的惩罚项,迫使模型参数变小,降低模型复杂度,从而减少过拟合。
- 正则化强度由超参数
控制:
- 注意:偏置项 b 通常不做正则化,因为它只是平移整个模型,不会影响模型复杂度。
2.正则化线性回归
(1)成本函数
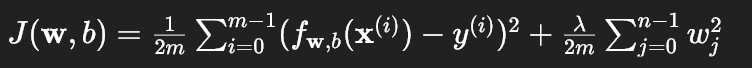
其中:
- 第一项是均方误差(原始成本)
- 第二项是 L2 正则化项,惩罚参数的平方和
(2) 代码实现 compute_cost_linear_reg
def compute_cost_linear_reg(X, y, w, b, lambda_ = 1):
"""
计算带L2正则化的线性回归成本
Args:
X (ndarray (m,n)): 数据,m个样本n个特征
y (ndarray (m,)): 目标值
w (ndarray (n,)): 模型参数
b (scalar) : 模型参数
lambda_ (scalar): 正则化强度
Returns:
total_cost (scalar): 总成本
"""
m = X.shape[0]
n = len(w)
cost = 0.
# 计算原始均方误差成本
for i in range(m):
f_wb_i = np.dot(X[i], w) + b
cost += (f_wb_i - y[i])**2
cost = cost / (2 * m)
# 计算正则化项
reg_cost = 0
for j in range(n):
reg_cost += (w[j]**2)
reg_cost = (lambda_/(2*m)) * reg_cost
total_cost = cost + reg_cost
return total_cost(3) 梯度函数与代码实现
梯度下降的更新公式:
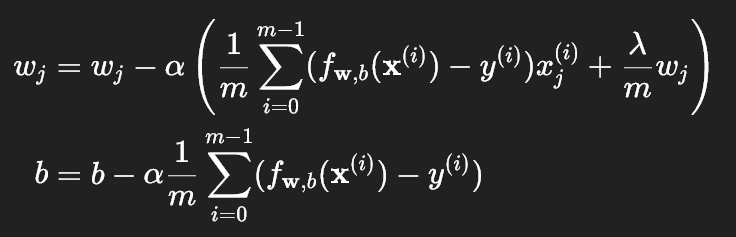
代码实现 compute_gradient_linear_reg:
def compute_gradient_linear_reg(X, y, w, b, lambda_):
"""
计算带L2正则化的线性回归梯度
Returns:
dj_dw (ndarray (n,)): 成本对w的梯度
dj_db (scalar) : 成本对b的梯度
"""
m,n = X.shape
dj_dw = np.zeros((n,))
dj_db = 0.
for i in range(m):
err = (np.dot(X[i], w) + b) - y[i]
for j in range(n):
dj_dw[j] = dj_dw[j] + err * X[i, j]
dj_db = dj_db + err
dj_dw = dj_dw / m
dj_db = dj_db / m
# 添加正则化项的梯度
for j in range(n):
dj_dw[j] = dj_dw[j] + (lambda_/m) * w[j]
return dj_db, dj_dw3.正则化逻辑回归
1. 成本函数
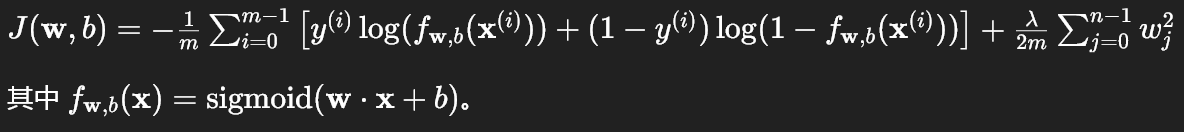
2. 代码实现 compute_cost_logistic_reg
def compute_cost_logistic_reg(X, y, w, b, lambda_ = 1):
"""
计算带L2正则化的逻辑回归成本
"""
m,n = X.shape
cost = 0.
# 计算原始交叉熵成本
for i in range(m):
z_i = np.dot(X[i], w) + b
f_wb_i = sigmoid(z_i)
cost += -y[i]*np.log(f_wb_i) - (1-y[i])*np.log(1-f_wb_i)
cost = cost / m
# 计算正则化项
reg_cost = 0
for j in range(n):
reg_cost += (w[j]**2)
reg_cost = (lambda_/(2*m)) * reg_cost
total_cost = cost + reg_cost
return total_cost3. 梯度函数与代码实现
逻辑回归的梯度公式和线性回归形式几乎完全一致,仅 fw,b的计算方式不同:
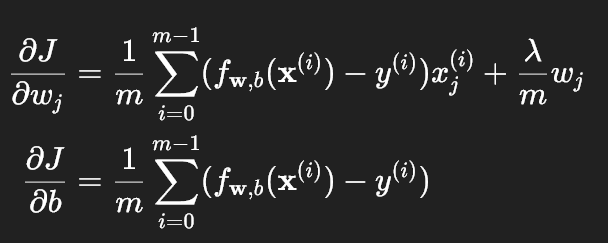
代码实现 compute_gradient_logistic_reg:
def compute_gradient_logistic_reg(X, y, w, b, lambda_):
"""
计算带L2正则化的逻辑回归梯度
"""
m,n = X.shape
dj_dw = np.zeros((n,))
dj_db = 0.0
for i in range(m):
f_wb_i = sigmoid(np.dot(X[i],w) + b)
err_i = f_wb_i - y[i]
for j in range(n):
dj_dw[j] = dj_dw[j] + err_i * X[i,j]
dj_db = dj_db + err_i
dj_dw = dj_dw/m
dj_db = dj_db/m
# 添加正则化项的梯度
for j in range(n):
dj_dw[j] = dj_dw[j] + (lambda_/m) * w[j]
return dj_db, dj_dw五、关键细节说明
- 正则化项的位置:正则化项只作用在参数w上,不作用在偏置 b 上,这是行业标准做法。
- 梯度更新的差异:线性回归和逻辑回归的梯度更新公式几乎完全相同,区别仅在于误差项 f{w,b} - y的计算方式:
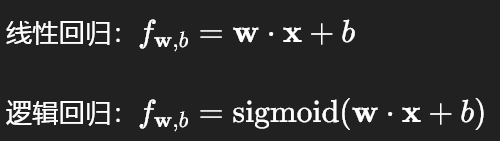
- 正则化的效果:在过拟合实验中,添加正则化后,高次多项式的曲线会变得更平滑,不再过度贴合训练数据中的噪声,泛化能力显著提升。