昨天给 Agent 装了"记忆系统",它能记住你是谁、喜欢什么了。
但还有个问题:遇到复杂问题,它不会拆解。
比如你跟它说:
"帮我看看明天北京天气怎么样,如果下雨就提醒我带伞,如果天晴就推荐个公园。"
没有推理能力的 Agent 会怎样?它要么只做第一件事(查天气),要么干脆说"我不会"。
人遇到复杂问题怎么办?
先拆开看------查天气 → 判断天气 → 决定建议。这就是多步推理。
一、什么是多步推理?
说白了就是:遇到复杂问题,不急着回答,先想想要几步才能解决。
场景对比
| 没有推理能力 | 有推理能力 |
|---|---|
| "帮我比较猫和狗" → "猫和狗都是宠物" | "比较猫和狗" → 分析猫 → 分析狗 → 对比 → 得出结论 |
| "如果下雨提醒我带伞" → "好的" | "如果下雨提醒我带伞" → 提取条件"下雨" → 判断 → 给出建议 |
| "检查我的答案" → "看完了,不错" | "检查我的答案" → 看答案 → 对照规则 → 找错误 → 修正 |
核心思想
复杂问题 = 拆成小步骤 + 一步步解决就像你不会一口吞下一个汉堡,你会一口一口吃。Agent 也一样。
二、四种推理模式
我做了 4 种推理模式,基本覆盖了日常场景:
| 模式 | 适用场景 | 工作流 | 像什么 |
|---|---|---|---|
| 顺序推理 | 步骤明确的任务 | A → B → C → D | 做菜:洗→切→炒→装盘 |
| 条件推理 | 需要判断的决策 | if A then B else C | 编程的 if/else |
| 分支推理 | 多角度对比 | 分析A→分析B→对比 | 买车:比价格、比油耗 |
| 验证推理 | 质量控制 | 执行→检查→修正→确认 | 写代码:写完→review→改bug |
2.1 顺序推理(Sequential)
最简单的推理模式------按步骤走。
python
def _plan_sequential(self):
return [
Step("理解需求", "用户想要什么"),
Step("收集信息", "找相关资料"),
Step("分析处理", "分析信息"),
Step("生成回答", "给出结果"),
]运行效果:
ini
[阶段1] 分析问题类型 → 多步任务型
[阶段2] 制定计划 → 共 4 步
[阶段3] 逐步执行
Step 1: 分析用户真实需求 → 用户想「推荐单词」
Step 2: 查找相关信息 → 收集到 3 条信息
Step 3: 分析处理 → 推荐方案已确定
Step 4: 整合结果 → 回答已生成
[阶段4] 综合结果 → 已分析你的需求,推荐最适合的方案2.2 条件推理(Conditional)
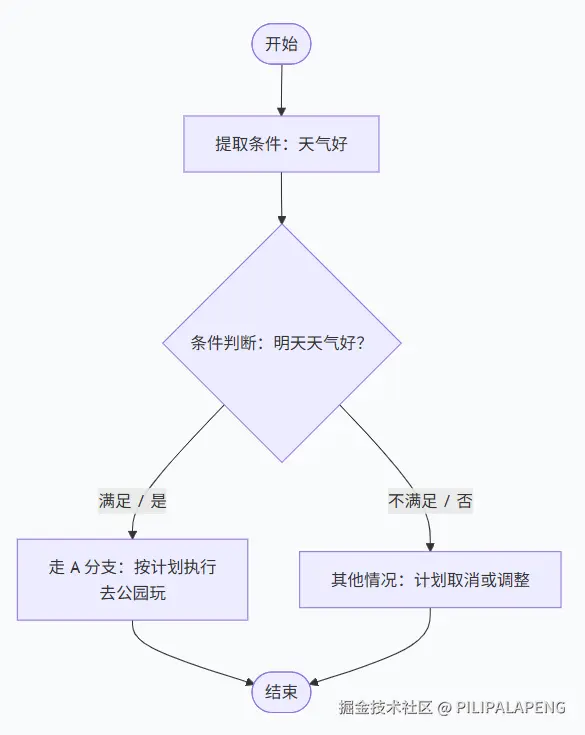
根据条件走不同分支------"如果 A 就 B,否则 C"。
python
def _plan_conditional(self):
return [
Step("提取条件", "从问题中找到判断条件"),
Step("条件判断", "判断满足还是不满足"),
Step("得出结论", "根据结果走分支"),
]两种情况对比:
ini
### 2.3 分支推理(Parallel)
同一件事从多个角度分别分析,最后汇总对比。
```python
def _plan_parallel(self):
# 动态生成步骤:有多少比较项就有多少分析步骤
items = ["猫", "狗"] # 从问题中提取
steps = [
Step("分析项1", "分析猫的特征"),
Step("分析项2", "分析狗的特征"),
Step("汇总对比", "整合对比"),
]运行效果:
vbnet
用户:比较猫和狗哪个更适合当宠物
Step 1: 分析「猫」→ 独立、安静、爱干净、适合室内
Step 2: 分析「狗」→ 忠诚、活泼、需要遛、适合户外
Step 3: 汇总对比 → 各有特点,看需求偏向哪边
→ 结论:没有绝对好坏,看你更看重安静还是活泼2.4 验证推理(Verification)
先执行,再检查,有错就改,最后确认。
python
def _plan_verification(self):
return [
Step("执行任务", "按要求操作"),
Step("检查结果", "验证是否正确"),
Step("修正优化", "有问题则修正"),
Step("确认完成", "最终确认"),
]就像你写完一段代码:
- 写完 → 2. Review → 3. 改 Bug → 4. 上线确认
三、推理引擎设计
python
class ReasoningAgent:
"""
推理引擎核心流程:
分析 → 规划 → 执行 → 综合
"""
def solve(self, request):
# 1. 分析问题类型
problem_type = self._analyze(request)
# 2. 制定执行计划
plan = self._plan(problem_type)
# 3. 逐步执行计划
for step in plan:
step.execute(self.context)
# 4. 综合结果
answer = self._synthesize(request, self.context)
return answerStep 是什么?
python
class ReasoningStep:
def __init__(self, name, desc, action):
self.name = name # 步骤名
self.desc = desc # 描述(显示给用户)
self.action = action # 实际执行的函数
self.result = None
def execute(self, context):
self.result = self.action(context)
return self.result每个步骤其实就是三个东西:叫什么 + 干什么 + 怎么干。
Context 是什么?
一个字典,存推理过程中的中间结果。后面的步骤可以看前面步骤的结果:
python
# Step 1 存了条件
context["_condition"] = "下雨"
# Step 2 读 Step 1 的结果
condition = context.get("_condition", "")
if condition == "下雨":
# 走 B 分支四、常见疑问解答
看完上面的代码,你可能会问几个很实际的问题。
Q1:分步骤是模型自己去分的,还是代码写死的?
演示版里是代码写死的------我用规则判断问题类型,用硬编码决定步骤。好处是不用调 API 也能跑。
生产环境里,步骤是 LLM 自己分的。 给模型一个 prompt,让它分析问题、列出步骤、分配工具:
javascript
用户提问 → LLM 分析 → 输出执行计划(JSON)LLM 返回的"计划"大概长这样:
json
{
"problem_type": "conditional",
"steps": [
{"step": 1, "action": "查北京明天天气", "tool": "get_weather"},
{"step": 2, "action": "判断是否下雨", "condition": "天气包含'雨'"},
{"step": 3, "action": "根据判断结果给出建议"}
]
}这样步骤不是写死的,而是模型根据问题动态生成的。问"推荐个单词"可能只分 2 步,问"比较猫和狗"可能分 5 步。
Q2:那么会有"每步调一次模型"的循环吗?
对!这就是"推理循环"------每执行一步,调一次 LLM。
python
# 推理循环
context = {"request": user_input}
for step in plan:
prompt = f"""
用户问题:{context['request']}
当前步骤:{step.name}
到目前为止:{json.dumps(context)}
请执行当前步骤,输出结果。
"""
# 调一次 LLM
llm_result = call_llm(prompt)
context[step.name] = llm_result多次调用有什么利弊?
| 一次调用(全让模型想) | 多次调用(拆成步骤) | |
|---|---|---|
| prompt 长度 | 很长 | 短,每步聚焦一件事 |
| 准确度 | 容易丢信息 | 高,每步只做一件事 |
| 透明性 | 黑盒,看不到中间过程 | 能看到每一步结果 |
| token 总花费 | 较少 | 较多 |
| 调试 | 难 | 哪步错调哪步 |
Q3:分析问题类型和推理模式,真的只靠关键词去区分?
演示版是,生产版不是。
演示版用关键词是为了不用调 API 也能演示概念。生产环境会用 LLM 自己判断:
arduino
用户:帮我写一篇关于猫的文章,再对比一下狗
→ 关键词:同时有"写"和"对比" → 冲突了
→ LLM 能理解这是"先写文章,再对比"两个阶段
用户:如果我学完了初级单词,接下来学什么?
→ 关键词匹配:含有"如果" → 条件推理?
→ 但 LLM 能看出这是"规划"类问题生产环境推荐做法:混合策略
arduino
第一层:快速关键词匹配(不花钱)
→ 匹配上?直接走对应模式
→ 匹配不上?走第二层
第二层:LLM 分析(花一次调用钱)
→ 让 LLM 判断问题类型,返回推理计划
第三层:兜底
→ 默认走"顺序推理"(最通用的模式)
→ 或者反问用户:"你希望我怎么处理?"Q4:匹配不到的情况怎么办?
当前代码有兜底:匹配不上就默认走"顺序推理"。 这是最通用的模式,什么场景都能用。
生产环境的完整兜底策略:
| 层级 | 做法 | 成本 |
|---|---|---|
| 第1层 | 关键词匹配 → 命中直接用 | 免费 |
| 第2层 | LLM 分析 → 让模型判断类型 | 1 次调用 |
| 第3层 | 默认走顺序推理 | 免费 |
| 第4层 | 反问用户:"你希望我怎么处理?" | 免费 |
小结
markdown
演示版:规则 + 关键词(为了不用 API 也能跑)
生产版:LLM 分步 + LLM 判断类型(更灵活,但每次要调 API)
↓
混合策略最好:关键词兜底 + LLM 精准判断五、多步推理的价值
透明性
每一步都能看到,用户知道 Agent 在想什么:
没有推理:
AI:建议你带伞。
(用户心里:为什么啊?)
有推理:
AI:查了明天天气 → 会下雨 → 所以建议带伞。
(用户心里:明白了!)可调试
哪步出错了,一眼就能看到:
vbnet
用户:比较猫和狗
Step 1: 分析「猫」→ 独立、安静
Step 2: 分析「狗」→ ???没结果
→ 问题出在 Step 2,狗的数据没查到可优化
知道瓶颈在哪,就能针对性地优化:
- 如果"收集信息"太慢 → 优化数据源
- 如果"条件判断"总错 → 优化判断规则
- 如果"汇总"太啰嗦 → 优化综合逻辑
六、多步推理 vs 传统编程
| 传统编程 | Agent 多步推理 | |
|---|---|---|
| 步骤 | 写死的 | 动态规划(根据问题不同) |
| 流程 | 完全确定 | 可能走不同分支 |
| 可读性 | 只有程序员能看懂 | 用户也能看到推理过程 |
| 灵活性 | 改逻辑要改代码 | 改规则就行 |
| 适合 | 确定性任务 | 不确定性、复杂任务 |
七、四种推理模式的选用指南
| 当你需要 | 用这个模式 | 例子 |
|---|---|---|
| 按流程办事 | 顺序推理 | 查资料→分析→写报告 |
| 做决定 | 条件推理 | 如果打折就买,不然等双十一 |
| 做对比 | 分支推理 | 比较 iPhone 和 Android |
| 确保质量 | 验证推理 | 写完作业→检查→改错 |
八、今日总结
今天干了啥:
- 理解了什么是多步推理(问题拆解 + 逐步解决)
- 学会了 4 种推理模式:顺序、条件、分支、验证
- 掌握了推理引擎设计(分析→规划→执行→综合)
核心公式:
复杂问题 = 拆成小步骤 + 一步步解决明天预告:多 Agent 协作------多个 Agent 各司其职,分工合作完成复杂任务。
写于 2026-05-09,多步推理 Agent------让 Agent 学会"先想再干"