Python 多进程、多线程与锁的底层原理(超详细总结)
在 Python 并发编程中,多进程(fork、Process、进程池)、多线程以及锁的使用,是最基础也最容易混淆的知识点。很多初学者会疑惑:"为什么多进程底层都是 fork,行为却不一样?""线程共享变量,为什么还要用锁?" 本文将从底层原理出发,结合直观伪代码,把这些知识点彻底讲透,适合收藏备用、查漏补缺。
前置核心公理(必记)
在学习所有细节前,先记住4个核心前提,能帮你快速串联所有知识点:
-
Linux 环境下,Python 所有多进程的底层实现,本质都是
os\.fork\(\); -
fork\(\)调用瞬间,会完整复制父进程的所有资源(代码、内存、栈、程序计数器、文件描述符等); -
不同多进程方式(手动 fork、Process、进程池)的核心区别,只在于「子进程被 fork 出来后,下一步做什么」;
-
多线程与多进程完全不同,它不复制进程、不复制代码,所有线程共享同一份进程空间(代码、内存、变量等)。
一、多进程核心:3种方式的底层原理 + 伪代码
所有多进程的底层都是 os\.fork\(\),但上层封装不同,导致子进程的执行行为天差地别,我们分3种场景逐一拆解。
1. 手动 os.fork() 原生写法(危险、自由、易乱序)
这是最原生的多进程方式,没有任何封装,完全由开发者控制,也是最容易出问题的方式。
核心特点 :子进程被 fork 后,会和父进程一起,从 fork\(\) 调用的下一行开始,继续执行主程序的所有代码,没有任何管控。
底层伪代码:
python
# 父进程先执行到这里
pid = os.fork()
# 关键:fork 分裂后,父子进程同时从这一行开始执行
if pid > 0:
# 父进程逻辑(pid 是子进程的ID)
print("我是父进程,继续执行主流程")
else:
# 子进程逻辑(pid=0),直接继续跑主程序后续所有代码
print("我是子进程,跟着父进程一起执行主流程")
# 重点:父子进程都会执行到这行及后面的所有代码
print("父子进程都会执行这句话")注意:这种方式的风险在于,子进程会执行所有主程序代码(包括你不想让它执行的逻辑,比如重复创建子进程、重复读写文件),很容易导致逻辑混乱、数据错乱。
2. multiprocessing.Process 普通子进程(安全、受控)
Python 标准库封装的 Process,本质还是调用 fork\(\),但它帮我们做了"子进程管控",避免了手动 fork 的混乱。
核心特点 :子进程被 fork 后,会被库内部"劫持",不再执行主程序的后续代码,只执行开发者指定的 target 任务函数,执行完后直接退出。
底层伪代码:
python
# Process 库内部的封装逻辑(简化版)
pid = os.fork()
if pid > 0:
# 父进程:继续执行自己的主流程,不干扰子进程
pass
else:
# 子进程被库接管,不再执行原主程序的任何后续代码
run_target_func() # 只执行开发者传入的 target 函数
exit() # 任务执行完毕,子进程直接退出优势:开发者只需要关注任务函数本身,不用手动控制子进程的执行范围,安全性大大提升,也是日常开发中最常用的多进程方式。
3. multiprocessing.Pool 进程池(高效、复用、专注任务)
进程池是对多进程的进一步优化,它会提前创建一批子进程(进程池大小),避免频繁 fork 带来的性能开销,子进程专注于执行主进程派发的任务。
核心特点:子进程被 fork 后,不会执行主程序代码,也不会执行完任务就退出,而是进入一个"死循环待命"状态,持续接收主进程派发的任务,直到进程池关闭。
底层伪代码:
python
# 进程池内部创建工作进程的逻辑(简化版)
pid = os.fork()
if pid > 0:
# 父进程:负责管理任务队列、向子进程派发任务
pass
else:
# 子进程进入永久循环,卡死在库内部,不执行主程序代码
while True:
task = recv_task_from_parent() # 等待主进程派发任务
if task is None: # 收到退出信号
break
run_task_func(task) # 只执行派发的任务函数
exit() # 进程池关闭后,子进程退出优势:复用子进程,减少 fork 次数,提升并发效率;子进程只专注于任务执行,逻辑更可控,适合大量重复任务的场景(比如批量处理数据)。
二、多线程:与多进程的本质区别(不复制、全共享)
很多人会把多线程和多进程混淆,但两者的底层逻辑完全不同------多线程没有 fork 过程,也不复制任何资源,所有线程都在同一个进程内运行。
核心特点
-
不 fork、不复制进程、不复制代码;
-
只有一个进程、一份代码、一块全局内存;
-
多线程只是"同一个进程内的多条执行路径",所有线程共享所有变量、内存、文件描述符等资源;
-
新线程只执行开发者指定的任务函数,不会从头执行主程序。
底层伪代码(逻辑示意)
python
# 没有任何 fork 操作,不复制任何资源
def thread_run():
# 新线程只执行指定的任务函数
run_target_func()
# 主线程继续执行自己的主流程
# 所有线程共用同一份代码、同一块全局内存
create_thread(thread_run)三、多进程 vs 多线程 核心对比表
为了方便大家快速区分,整理了4种方式的核心差异,直接收藏即可:
| 方式 | 底层是否 fork | 是否复制代码/进程 | 子/线程执行行为 |
|---|---|---|---|
| 手动 os.fork() | 是 | 完整复制 | 父子一起执行主程序后续所有代码 |
| multiprocessing.Process | 是 | 完整复制 | 只执行 target 函数,不跑主程序后续 |
| 进程池 Pool | 是 | 完整复制 | 子进程循环待命,只执行派发任务 |
| 多线程 threading | 否 | 不复制、共享同一份 | 同进程内多执行流,共享代码内存 |
四、灵魂问题:线程共享变量,为什么还要学锁?
这是所有初学者都会问的问题,答案很简单:正因为线程共享变量,所以才必须用锁。共享意味着竞争,竞争会导致数据错乱,锁就是解决竞争的"利器"。
1. 不加锁的灾难:数据错乱
假设两个线程同时修改同一个全局变量 count,看似简单的 count \+= 1,底层其实分3步执行:
-
读取当前
count的值; -
计算
count \+ 1; -
把新值写回
count。
由于线程是交替执行的,中间可能被打断,导致数据错乱:
python
count = 0 # 所有线程共享的全局变量
def add():
global count
count += 1 # 底层3步,中间可能被打断错乱场景:
-
线程A 读取 count = 0,还没来得及计算,就被线程B打断;
-
线程B 也读取 count = 0,计算得 1,写回 count = 1;
-
线程A 继续执行,计算 0+1=1,写回 count = 1;
-
最终结果:本应是 2,实际是 1,数据错乱!
2. 锁的作用:强制"排队执行"
锁的核心作用,就是让"修改共享变量"的代码,同一时间只能被一个线程执行------相当于给这段代码加了一把"通行证",只有抢到通行证的线程才能执行,其他线程必须排队。
加锁后的伪代码(安全):
python
count = 0
lock = Lock() # 创建一把锁
def add():
lock.acquire() # 抢锁:抢到才能执行下面的代码
count += 1 # 同一时间只有一个线程能执行这行
lock.release() # 释放锁:让其他线程可以抢锁安全流程:
-
线程A 抢到锁,执行
count \+= 1,释放锁; -
线程B 抢到锁,执行
count \+= 1,释放锁; -
最终结果:count = 2,完全正确。
3. 核心总结:为什么需要锁?
-
线程共享所有变量,多线程同时修改共享变量,会产生"竞争";
-
一行 Python 代码对应多行 CPU 指令,执行过程中可能被其他线程打断,导致数据错乱;
-
锁的作用:强制同一时间只有一个线程修改共享数据,保证数据安全;
-
口诀:进程不共享,不用锁;线程全共享,必须锁。
五、终极背诵版(快速记忆)
整理了4句核心口诀,帮你快速记住所有重点:
-
手动 fork:复制进程,父子一起顺次跑主代码;
-
Process:fork 后被接管,只跑指定函数,不跑主代码;
-
进程池:fork 后常驻循环,只等任务、只干任务;
-
多线程:不 fork
(注:文档部分内容可能由 AI 生成)
注意点:
结论先说:
对!只读场景下,mmap 超级简单,而且完全不用加锁、不用管并发安全,多进程、多线程随便用。
我给你把原理、为什么不用锁、怎么用一次性讲透。
1. 为什么「只读」就不用锁?
锁的作用是:防止同时写、读写冲突。
只要满足:
- 所有进程/线程 只读、不修改
- 底层映射的文件内容 不会变
就不存在数据争抢、脏数据、覆盖问题 → 完全不需要任何锁。
这就是 mmap 最舒服的使用场景:静态大文件只读共享。
2. mmap 只读有多香?
-
多进程共享同一份物理内存
几百个进程映射同一个大文件,物理内存只加载1份,不是每个进程拷一份,极度省内存。
-
不用自己读文件、不用管 IO
操作系统帮你把文件直接映射成内存地址,你像读数组一样读文件,比
open/read快得多。 -
代码极简,无并发坑
不用 Lock、不用 Manager、不用队列,打开映射直接读就行。
3. 线程 / 进程 都能只读 mmap 吗?
全都可以:
- 多线程:本来就共享内存,用 mmap 只读纯属锦上添花,适合超大静态配置、词表、模型权重。
- 多进程:完美适配,每个进程 mmap 同一个文件,只读,零拷贝、零内存冗余。
4. 极简人话总结
- 有写操作:mmap + 跨进程锁,复杂、容易翻车,业务不用。
- 纯只读静态文件 :mmap 无脑用,不用锁、简单、省内存、速度快。
5. 给你一段可直接运行的 Python 只读 mmap 示例
只读映射,多进程多线程随便读,不用任何锁:
6 适用场景(你以后工作大概率会碰到)
- 超大词典、词表、黑名单、配置表
- AI 推理里静态权重、常量数据表
- 多进程服务共用一份超大静态索引文件
全部都是:mmap 只读 完美场景,简单又高性能。
要不要我给你写一个多进程同时 mmap 只读同一份文件的例子,让你直观看到多个进程共用同一份内存、不用锁也完全安全?
注意点:
两个进程的包:

注意点:
pid什么时候才创建:
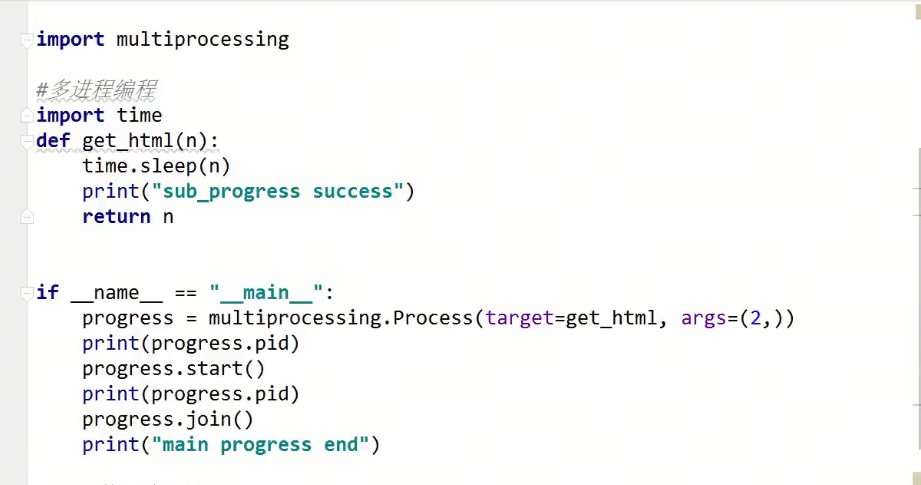
注意点:
如果不穿数量使用默认的就是cpu核心数:

注意点:
为什么join之前要调close就行不再接受什么东西:
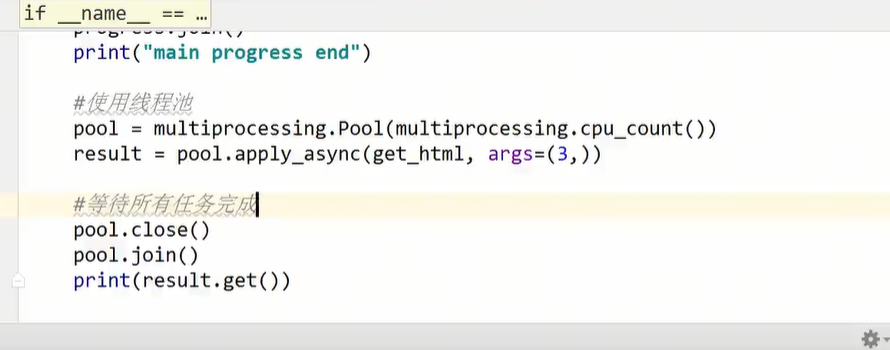
注意点:
进程间的通信:线程间同步的类与锁是不能用到多进程中的,下面的这个from queue import Queue就不能用,应该使用mutiprocessing中提供的Queue
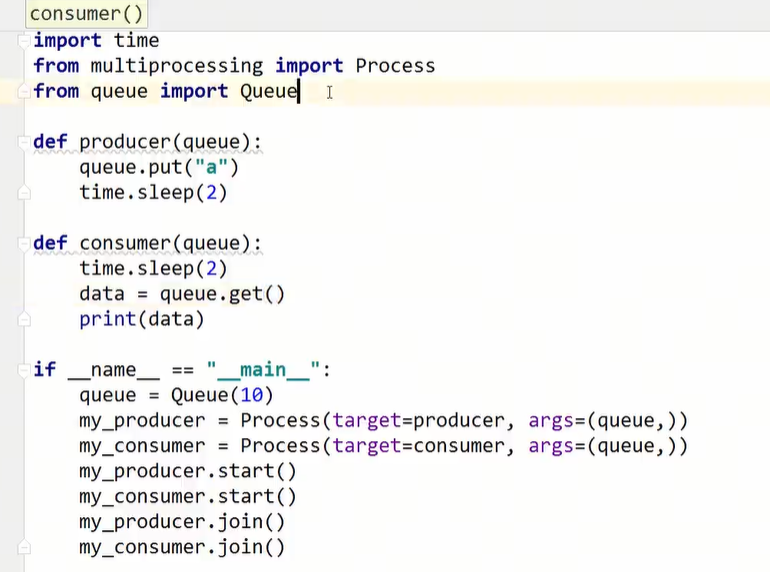

注意点:
核心结论:进程之间不能直接共享全局变量
这是多进程 和多线程最大的区别!我用最简单的话给你讲清楚👇
1. 一句话解释
- 线程 :共用同一个进程的内存,全局变量直接共享
- 进程 :有独立的内存空间 ,互相隔离,全局变量互不影响
os.fork() 创建的子进程,会复制父进程的全局变量 ,但复制完之后,父子进程的变量就是完全独立的了,改一个不会影响另一个。
2. 看代码你立刻就懂
python
import os
# 全局变量
num = 100
# 创建子进程
pid = os.fork()
if pid == 0:
# 子进程 修改全局变量
num += 1
print(f"子进程:num = {num}") # 输出 101
else:
# 父进程
print(f"父进程:num = {num}") # 输出 100运行结果
父进程:num = 100
子进程:num = 101✅ 关键现象 :
子进程把 num 改成了 101,父进程的 num 还是 100,完全没变 !
这就证明:进程之间不共享全局变量。
3. 为什么不能共享?(底层原理)
- 每个进程都有独立的内存空间
fork()只是复制了变量,不是共享- 父子进程修改的是自己内存里的副本,互不干扰
就像:
- 你复印了一份试卷
- 你在原件上写答案
- 复印件上不会有任何变化
进程 = 原件 / 复印件
线程 = 同一本试卷,多人一起写
4. 那进程之间想共享数据怎么办?
进程不能直接用全局变量,但可以用专门的通信方式:
multiprocessing模块的Value/Array- 队列 Queue
- 管道 Pipe
- 共享内存
5. 超级重要的对比总结
| 特性 | 多线程 | 多进程 |
|---|---|---|
| 全局变量 | 直接共享 | 不能共享 |
| 内存 | 共用一块内存 | 独立内存,互相隔离 |
| 数据安全 | 需要加锁 | 天然安全,互不干扰 |
| 适用场景 | IO密集 | CPU密集 |
总结
- 进程之间绝对不能直接共享全局变量
fork只是复制变量,不是共享- 想在进程间传数据,必须用进程通信机制
需要我给你写一段进程之间真正共享变量的示例代码吗?
注意点:
我来帮你把这三个 Queue 彻底讲清楚,顺便讲明白为什么进程池里要用 Manager.Queue()。
一、三个 Queue 的本质区别
| 来源 | 模块 | 适用场景 | 底层原理 | 进程池(Pool)中能用吗? |
|---|---|---|---|---|
from queue import Queue |
queue(线程安全) |
多线程 间通信 | 基于线程锁的内存队列,只在同一个进程内有效 | ❌ 完全不能用(进程间不共享内存) |
from multiprocessing import Queue |
multiprocessing |
多进程 间通信 | 基于管道/信号量的IPC队列 | ❌ 不能用在 Pool 进程池里 |
Manager().Queue() |
multiprocessing.Manager |
进程池(Pool)中的进程间通信 | 由一个独立的管理进程维护的共享队列 | ✅ 完全支持 |
二、逐个拆解每个 Queue
1. from queue import Queue(线程专用)
- 本质 :线程安全的队列,只能在同一个进程内的多个线程之间使用。
- 为什么进程用不了?
进程之间默认是内存隔离的,这个队列的数据存在当前进程的内存里,别的进程根本看不到。 - 使用示例(仅线程):
python
import threading
from queue import Queue
def worker(q):
q.put("hello from thread")
q = Queue()
t = threading.Thread(target=worker, args=(q,))
t.start()
t.join()
print(q.get())2. from multiprocessing import Queue(多进程专用,但Pool不兼容)
- 本质:专门为多进程设计的IPC(进程间通信)队列,基于操作系统的管道和信号量实现。
- 为什么
Pool里不能用?
进程池里的进程是由Pool管理的,而multiprocessing.Queue会使用一个后台的"feeder线程"来管理数据传输,当Pool回收进程时,会和这个feeder线程产生冲突,导致数据丢失或程序挂死。 - 正确用法(普通多进程):
python
from multiprocessing import Process, Queue
def worker(q):
q.put("hello from process")
if __name__ == "__main__":
q = Queue()
p = Process(target=worker, args=(q,))
p.start()
p.join()
print(q.get())- 错误用法(Pool中会出问题):
python
from multiprocessing import Pool, Queue
def worker(q):
q.put("test")
if __name__ == "__main__":
q = Queue()
with Pool(2) as pool:
pool.apply(worker, args=(q,))
print(q.get()) # 可能卡死/拿不到数据3. Manager().Queue()(进程池专用,推荐)
- 本质 :由
multiprocessing.Manager启动一个独立的管理进程,这个进程负责维护队列数据,所有进程(包括进程池里的)都通过网络/IPC和这个管理进程通信,实现数据共享。 - 为什么
Pool里能用?
它的数据不是直接存在进程内存里,而是存在管理进程中,所有进程池里的worker进程都能访问到这个共享队列,不存在feeder线程冲突的问题。 - 正确用法(进程池通信):
python
from multiprocessing import Pool, Manager
def producer(q, i):
q.put(f"data_{i}")
def consumer(q):
while not q.empty():
print("consumed:", q.get())
if __name__ == "__main__":
# 创建Manager和共享队列
manager = Manager()
q = manager.Queue()
with Pool(4) as pool:
# 生产者往队列里写数据
pool.starmap(producer, [(q, i) for i in range(5)])
# 消费者从队列里读数据
pool.apply(consumer, args=(q,))三、核心问题:为什么 Pool 必须用 Manager().Queue()?
multiprocessing.Queue依赖主进程的后台feeder线程来传递数据,而Pool会接管worker进程的生命周期,导致feeder线程无法正常工作,数据可能丢失。Manager().Queue()是跨进程的"代理对象",所有进程都通过管理进程访问队列,和Pool的生命周期完全解耦,所以安全稳定。
四、三个场景的最佳实践
| 场景 | 推荐队列 | 说明 |
|---|---|---|
| 普通多线程 | queue.Queue |
轻量高效,线程安全 |
| 普通多进程(非Pool) | multiprocessing.Queue |
性能比Manager更高,无额外进程开销 |
| 进程池(Pool)多进程 | Manager().Queue() |
唯一稳定的选择 |
五、补充:完整的进程池生产者消费者示例
python
from multiprocessing import Pool, Manager
import time
def producer(q, n):
for i in range(n):
msg = f"task_{i}_{time.time()}"
q.put(msg)
print(f"produced: {msg}")
def consumer(q):
count = 0
while True:
if not q.empty():
msg = q.get()
print(f"consumed: {msg}")
count += 1
else:
break
print(f"consumer done, handled {count} tasks")
if __name__ == "__main__":
manager = Manager()
q = manager.Queue()
with Pool(4) as pool:
# 两个生产者进程,各生成3个任务
pool.starmap(producer, [(q, 3), (q, 3)])
# 两个消费者进程处理任务
pool.starmap(consumer, [(q,), (q,)])如果你愿意,我可以帮你写一个带错误处理和日志的进程池队列通信模板,你之后可以直接套用。需要吗?
注意点:
可直接发布博客完整版 Markdown(已强化 Pipe 核心定位)
Python 多进程间共享与通信全解:Manager / 共享内存 / Queue / Pipe 底层原理+选型对比
前言
Python 多进程内存完全隔离,每个进程拥有独立虚拟地址空间,默认无法直接共享变量。
日常开发常用四类进程间通信/共享方案:
multiprocessing.Manager、mmap/shared_memory 共享内存、Queue、Pipe。
本文做结构化对比、底层原理深度拆解,重点厘清:Queue、Pipe、Manager 底层是不是同一套,同时强化 Pipe 定位,附带工程选型建议,可直接复制发布博客。
一、两大内存共享方式核心对比
| 特性 | multiprocessing.Manager | mmap / multiprocessing.shared_memory |
|---|---|---|
| 数据存储位置 | 数据存独立 Manager 守护进程内存,非进程间直接物理内存共享 | 多进程映射同一块物理内存,直接访问物理内存地址 |
| 通信模式 | 工作进程 ↔ Manager 进程 中转 IPC 调用 | 进程直接读写共享内存,无中间转发进程 |
| 性能表现 | 偏低,每次操作伴随 IPC 通信 + 序列化/反序列化开销 | 极高,无中转、无多余序列化,接近原生内存读写 |
| 数据类型支持 | 支持复杂对象:list、dict、嵌套结构、自定义对象 | 仅支持连续字节流、基础数值数组,不支持复杂对象 |
| 并发安全 | 自带锁机制,开箱即用,无需手动加锁 | 无内置锁,必须手动配合 multiprocessing.Lock 做互斥控制 |
| 跨机器能力 | 支持绑定网络地址,可实现跨主机进程通信 | 仅限本机内核内存映射,不支持跨机器 |
| 使用成本 | 极低,语法贴近普通列表字典,上手快 | 偏高,需手动管理内存偏移、字节解析、并发锁 |
二、工程常用所有进程通信/共享方式汇总
除上述内存共享外,实际开发常用 5 类:
- Pipe 管道:仅两个进程点对点双工通信
- Queue 队列:多进程生产者-消费者任务分发
- Manager 托管共享:快速共享 list/dict 复杂对象
- mmap / shared_memory 共享内存:大数据、高频读写高性能场景
- 中间件/文件:Redis、SQLite、普通文件(跨进程、跨机器、跨语言、持久化)
三、核心底层原理:Queue、Pipe、Manager 是不是一套?
1. 核心结论
- Pipe 是简化轻量版 Queue ,仅限两个进程通信;
- Queue 是加强版 Pipe ,在 Pipe 基础上叠加多层锁、队列逻辑、多进程调度,性能比 Pipe 低;
- Manager 和 Pipe/Queue 底层完全不同 :不走管道,基于独立进程 + Socket IPC 实现。
2. Pipe 管道重点强化说明
Pipe是极简轻量化通信组件 ,可以理解为:阉割简化版的 Queue;- 硬性限制:只能固定用于两个进程之间点对点通信,不支持多进程同时收发;
- 底层只是封装系统原生匿名管道,没有多余锁竞争、没有队列调度逻辑;
- 开销极低、逻辑极简,纯性能优于 Queue。
3. Queue 队列
- 底层基于 Pipe 做二次封装;
- 额外增加:多层互斥锁、条件变量、队列缓冲、阻塞等待、多进程并发调度;
- 为了兼容多进程安全生产消费,加了大量控制逻辑和锁竞争,额外开销大,性能弱于 Pipe。
4. Manager 托管共享
- 单独启动一个独立 Manager 服务进程;
- 底层不走管道,走本地 Socket IPC 通信;
- 所有子进程对 list/dict 的增删改查,都通过 Socket 发给 Manager 进程,由它真正操作内存再返回结果;
- 多了进程中转 + Socket 通信 + 序列化,是三者中性能最差的。
5 一句话精炼区分
- Pipe:极简版 Queue,只给两个进程用,无多余锁,性能最强;
- Queue:完整版 Pipe,加锁+队列+多进程调度,通用但性能更低;
- Manager:独立进程 Socket 托管,和管道体系无关,只为共享复杂对象。
四、四种主流进程通信方式横向总对比
| 方式 | 底层依赖 | 进程数量限制 | 性能 | 并发安全 | 复杂对象支持 | 核心定位 |
|---|---|---|---|---|---|---|
| Pipe | 系统匿名管道 | 仅限2个进程 | 最高 | 需自行控制 | 需手动序列化 | 两进程点对点轻量高速通信 |
| Queue | Pipe + 多层锁 + 队列封装 | 支持多进程 | 中等 | 自带进程安全 | 支持可序列化对象 | 多进程生产消费、任务队列 |
| Manager | 独立进程 + Socket IPC | 无限制 | 最低 | 自带安全 | 完美支持 | 快速共享 list/dict 复杂对象 |
| shared_memory/mmap | 内核物理内存映射 | 无限制 | 极高 | 需手动加锁 | 仅字节/基础数组 | 大数据、高频数值读写高性能共享 |
五、开发选型最佳实践
- 只有两个进程点对点交互、追求高性能 → 优先用
Pipe,极简无多余锁,速度比 Queue 快; - 多进程任务分发、生产消费模型 → 无脑用
Queue,牺牲部分性能换开箱即用的并发安全; - 需要共享字典、列表、自定义复杂对象 → 用
Manager,牺牲性能换开发效率; - 超大数组、AI 特征数据、高频数值读写 → 用
shared_memory原生共享内存; - 跨机器、跨语言、需要持久化落地 → 放弃进程内共享,改用 Redis / 数据库 / 本地文件。
六、全文核心总结
- 进程共享分两类:托管式共享(Manager) 、原生物理内存共享(mmap/shared_memory);
- Pipe = 简化轻量版 Queue ,仅限双进程通信,无多余锁逻辑,性能高于 Queue;
- Queue 基于 Pipe 封装,叠加大量锁和调度逻辑,适配多进程但增加性能开销;
- Manager 底层是独立进程+Socket IPC,和 Pipe/Queue 管道体系完全不是一套;
- 双进程高速通信选 Pipe,多进程任务队列选 Queue,复杂对象共享选 Manager,大数据高性能选共享内存。
直接全选复制就能发公众号/掘金/知乎专栏,结构完整、重点加粗、逻辑闭环。