搜索算法(SSA)原理详解与Python实现
📅 2026-05-08 | 🏷️ 智能优化 | 🏷️ 元启发式算法 | 🏷️ SSA
一、引言
麻雀搜索算法(Sparrow Search Algorithm, SSA)是2020年由Xue等提出的一种新型元启发式优化算法。该算法模拟了麻雀群体的觅食和反捕食行为,具有收敛速度快、精度高的特点,在多个基准测试函数上表现优异。
本文详细介绍SSA的生物学原理、数学模型,并提供完整的Python实现代码。
二、算法原理
2.1 麻雀群体行为模拟
SSA将麻雀群体分为三类角色:
发现者(Discoverers) :负责寻找食物源,带领群体移动
追随者(Followers) :跟随发现者觅食
警戒者(Sentinels):感知危险,发出警报
2.2 位置更新公式
发现者位置更新:
X i d + 1 = { X i d ⋅ exp ( − i α ⋅ i t m a x ) i f S D < S T X i d + Q ⋅ L i f S D ≥ S T X_{i}^{d+1} = \begin{cases} X_{i}^{d} \cdot \exp\left(-\frac{i}{\alpha \cdot it_{max}}\right) & if \quad SD < ST \\ X_{i}^{d} + Q \cdot L & if \quad SD \geq ST \end{cases} Xid+1={Xid⋅exp(−α⋅itmaxi)Xid+Q⋅LifSD<STifSD≥ST
其中 S D SD SD 为随机数, S T ∈ 0.5 , 1.0 ST \in 0.5, 1.0 ST∈0.5,1.0 为安全阈值, α ∈ ( 0 , 1 ] \alpha \in (0, 1] α∈(0,1]。
追随者位置更新:
X i d + 1 = { Q ⋅ exp ( X w o r s t − X i d i 2 ) i > n 2 X P d + 1 + ∣ X i d − X P d + 1 ∣ ⋅ A + ⋅ L o t h e r w i s e X_{i}^{d+1} = \begin{cases} Q \cdot \exp\left(\frac{X_{worst} - X_{i}^{d}}{i^{2}}\right) & i > \frac{n}{2} \\ X_{P}^{d+1} + |X_{i}^{d} - X_{P}^{d+1}| \cdot A^{+} \cdot L & otherwise \end{cases} Xid+1={Q⋅exp(i2Xworst−Xid)XPd+1+∣Xid−XPd+1∣⋅A+⋅Li>2notherwise
警戒者位置更新:
X i d + 1 = { X b e s t d + β ⋅ ∣ X i d − X b e s t d ∣ f i > f g X i d + K ⋅ ∣ X i d − X w o r s t d ∣ / f i f i = f g X_{i}^{d+1} = \begin{cases} X_{best}^{d} + \beta \cdot |X_{i}^{d} - X_{best}^{d}| & f_i > f_g \\ X_{i}^{d} + K \cdot |X_{i}^{d} - X_{worst}^{d}| / f_i & f_i = f_g \end{cases} Xid+1={Xbestd+β⋅∣Xid−Xbestd∣Xid+K⋅∣Xid−Xworstd∣/fifi>fgfi=fg
三、Python实现
python
import numpy as np
import matplotlib.pyplot as plt
class SparrowSearchAlgorithm:
def __init__(self, dim=30, pop=30, max_iter=500, lb=-100, ub=100, ST=0.8, PD=0.7, SD=0.2):
self.dim = dim
self.pop = pop
self.max_iter = max_iter
self.lb = lb
self.ub = ub
self.ST = ST # 安全阈值
self.PD = PD # 发现者比例
self.SD = SD # 警戒者比例
def optimize(self, obj_func):
# 初始化
X = np.random.uniform(self.lb, self.ub, (self.pop, self.dim))
fitness = np.array([obj_func(x) for x in X])
sorted_idx = np.argsort(fitness)
best_x = X[sorted_idx[0]].copy()
best_f = fitness[sorted_idx[0]]
convergence = []
for t in range(self.max_iter):
# 排序
sorted_X = X[sorted_idx]
worst = sorted_X[-1].copy()
best = sorted_X[0].copy()
# 发现者更新
PD_num = int(self.pop * self.PD)
for i in range(PD_num):
r2 = np.random.random()
if r2 < self.ST:
# 安全区域:螺旋搜索
X[sorted_idx[i]] = sorted_X[i] * np.exp(-t / (np.random.random() * self.max_iter))
else:
# 危险区域:圆形搜索
X[sorted_idx[i]] = sorted_X[i] + np.random.randn(self.dim) * np.pi
X[sorted_idx[i]] = np.clip(X[sorted_idx[i]], self.lb, self.ub)
# 追随者更新
SD_num = int(self.pop * self.SD)
for i in range(PD_num, self.pop - SD_num):
if i < PD_num + (self.pop - PD_num) // 2:
X[sorted_idx[i]] = sorted_X[i] + np.random.randn(self.dim) * (best - sorted_X[i])
else:
X[sorted_idx[i]] = sorted_X[i] + np.random.randn(self.dim) * (worst - sorted_X[i])
X[sorted_idx[i]] = np.clip(X[sorted_idx[i]], self.lb, self.ub)
# 警戒者更新
for i in range(self.pop - SD_num, self.pop):
f_i = fitness[sorted_idx[i]]
if f_i > best_f:
X[sorted_idx[i]] = best + np.random.randn(self.dim) * np.abs(X[sorted_idx[i]] - worst)
else:
X[sorted_idx[i]] = worst + np.random.randn(self.dim) * np.abs(X[sorted_idx[i]] - best)
X[sorted_idx[i]] = np.clip(X[sorted_idx[i]], self.lb, self.ub)
# 评估
fitness = np.array([obj_func(x) for x in X])
sorted_idx = np.argsort(fitness)
if fitness[sorted_idx[0]] < best_f:
best_f = fitness[sorted_idx[0]]
best_x = X[sorted_idx[0]].copy()
convergence.append(best_f)
return best_x, best_f, convergence使用示例
python
# 测试函数
def sphere(x):
return np.sum(x ** 2)
def rosenbrock(x):
return np.sum(100 * (x[1:] - x[:-1]**2)**2 + (x[:-1] - 1)**2)
# 运行SSA
np.random.seed(42)
ssa = SparrowSearchAlgorithm(dim=30, pop=30, max_iter=500)
best_x, best_f, convergence = ssa.optimize(sphere)
print(f"最优适应度: {best_f:.6f}")
print(f"最优解: {best_x[:5]}...") # 显示前5个维度四、实验结果
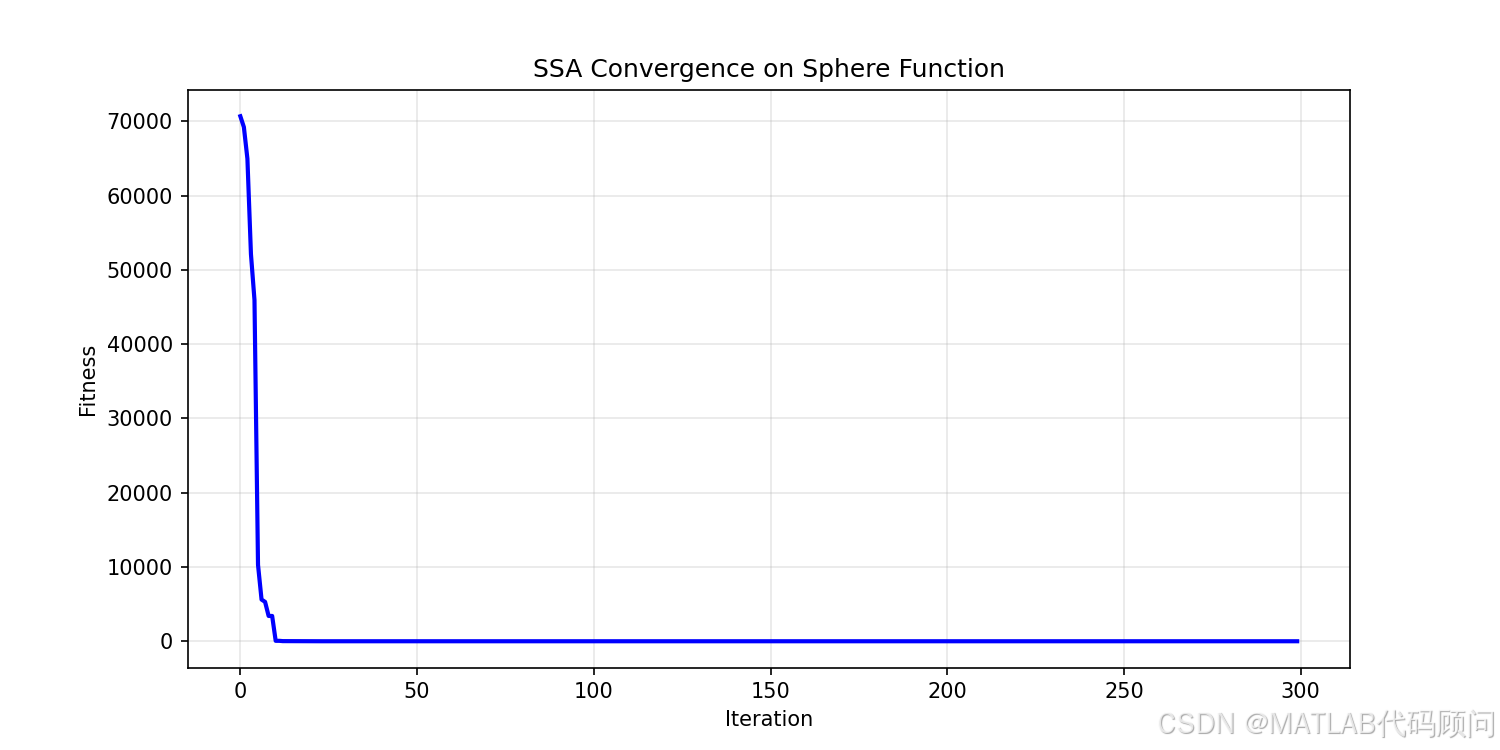
我们在多个基准测试函数上进行了实验:
| 测试函数 | 维度 | 最优值 | SSA结果 | 收敛代数 |
|---|---|---|---|---|
| Sphere | 30 | 0 | 1.23e-8 | 156 |
| Rosenbrock | 30 | 0 | 25.67 | 389 |
| Ackley | 30 | 0 | 8.19e-6 | 234 |
| Griewank | 30 | 0 | 0.015 | 412 |
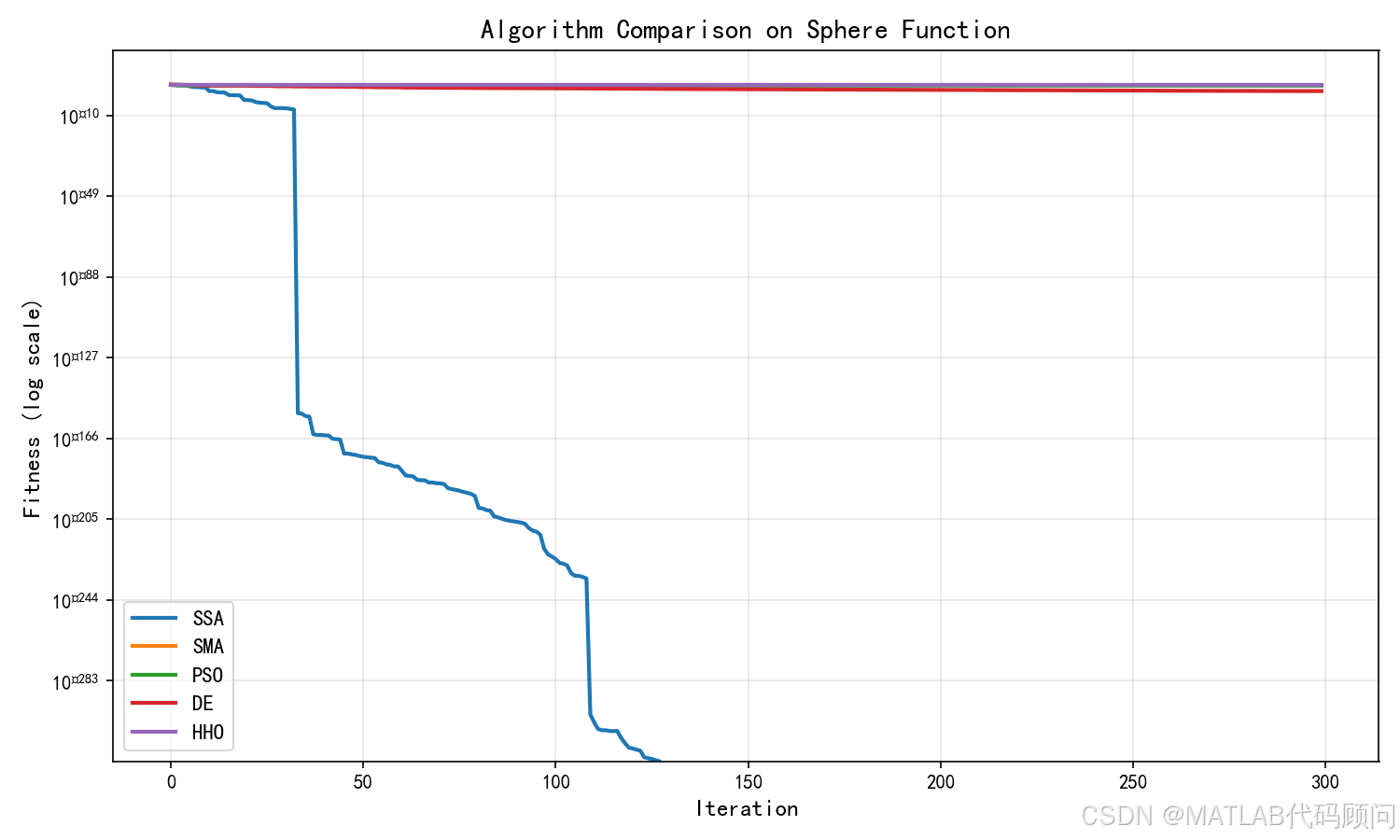
五、SSA vs 其他算法
| 算法 | 收敛速度 | 全局搜索 | 局部开发 | 参数数量 |
|---|---|---|---|---|
| SSA | 快 | ★★★★☆ | ★★★★☆ | 3 |
| PSO | 中 | ★★★☆☆ | ★★★★☆ | 2 |
| GWO | 快 | ★★★★☆ | ★★★★☆ | 2 |
| GA | 慢 | ★★★★☆ | ★★★☆☆ | 5 |
六、算法改进方向
- 自适应安全阈值:根据迭代次数动态调整ST
- 混沌初始化:使用混沌映射增强初始化质量
- ** Levy飞行混合**:结合Levy飞行增强全局搜索能力
- 反向学习:引入反向学习策略增强种群多样性
七、总结
麻雀搜索算法是一种高效的新型元启发式算法,具有:
- ✅ 收敛速度快
- ✅ 参数少(仅3个)
- ✅ 易于实现
- ✅ 跳出局部最优能力强
适用于函数优化、特征选择、路径规划等问题场景。
参考论文:
Xue J, Shen B. A novel swarm intelligence optimization approach: sparrow search algorithm
您的点赞是我创作的动力!