代码示例:
python
"""
案例:通过逻辑回归算法,针对于电信用户数据建模,进行流失预测分析;
"""
# 导包
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,classification_report # 准确率,精确率,召回率,F1值,分类评估报告
# 1.定义函数,演示:数据的预处理
def demo01_data_preprocessing():
# 1.读取csv文件,获取df对象
churn_df = pd.read_csv('./data/churn.csv')
# 2.查看(处理前的)数据集
# churn_df.info()
# print(churn_df.head(5))
# 3.因为Churn 和 gender列是字符串,所以需要进行one-hot编码(热编码处理)
churn_df = pd.get_dummies(churn_df, columns=['Churn', 'gender'])
# 4.查看(处理后的)数据集
# churn_df.info()
# print(churn_df.head(5))
# 5.删除one-hot处理后新增的,冗余的列
# 默认axis=0删除行,删除列axis=1。参1:要删除的列,参2:axis=1表示删除列,参3:inplace=True表示直接修改源数据,不返回新的数据集
churn_df.drop(['Churn_No', 'gender_Male'], axis=1, inplace=True)
# churn_df.info()
# print(churn_df.head(5))
# 6.修改列名,将Churn_Yes ------> flag,充当标签列
churn_df.rename(columns={'Churn_Yes': 'flag'}, inplace=True)
churn_df.info()
print(churn_df.head(5)) # False------>不流失,True------>流失
# 7.查看数据值的分布
print(churn_df['flag'].value_counts()) # False:5174,True:1869
# 2.定义函数,演示:数据的可视化
def demo02_data_visualization():
# 1.读取csv文件,获取df对象
churn_df = pd.read_csv('./data/churn.csv')
# 2.对object类型的列(数据)做 one-hot编码处理
churn_df = pd.get_dummies(churn_df, columns=['Churn', 'gender'])
# 3.删除one-hot处理后新增的,冗余的列
churn_df.drop(['Churn_No', 'gender_Male'], axis=1, inplace=True)
# 4.修改列名,将Churn_Yes ------> flag,充当标签列
churn_df.rename(columns={'Churn_Yes': 'flag'}, inplace=True)
# 5.查看数据值的分布
print(churn_df['flag'].value_counts()) # False:5174,True:1869
# 6.查看列名,方便我们一会儿抽取特征
# 列名为:['Partner_att', 'Dependents_att', 'landline', 'internet_att','internet_other', 'StreamingTV', 'StreamingMovies', 'Contract_Month',
# 'Contract_1YR', 'PaymentBank', 'PaymentCreditcard', 'PaymentElectronic','MonthlyCharges', 'TotalCharges', 'flag', 'gender_Female']
print(churn_df.columns)
# 7.数据的可视化,绘制 计数柱状图
# 参1:数据集,参2:x轴的列名(月度会员),参3:hue表示分组,根据分组进行绘制,这里是:是否流失(False:不流失,True:流失)
sns.countplot(data=churn_df, x='Contract_Month', hue='flag')
plt.show()
# 3.定义函数,演示:逻辑回归算法的模型训练,预测,评估
def demo03_logistic_regression_model():
# 1.加载数据集
churn_df = pd.read_csv('./data/churn.csv')
# 2.数据的预处理
# 2.1 对object类型的列(数据)做 one-hot编码处理
churn_df = pd.get_dummies(churn_df, columns=['Churn', 'gender'])
# 2.2 删除one-hot处理后新增的,冗余的列
churn_df.drop(['Churn_No', 'gender_Male'], axis=1, inplace=True)
# 2.3 修改列名,将Churn_Yes ------> flag,充当标签列
churn_df.rename(columns={'Churn_Yes': 'flag'}, inplace=True)
# 2.4 提取特征列 和 标签列
# x的特征列:月度会员,是否有互联网服务,是否是电子支付
x=churn_df[['Contract_Month', 'internet_other', 'PaymentElectronic']]
y=churn_df['flag'] # False------>不流失,True------>流失
# 2.5 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=23)
# 3.特征工程(如:特征提取,特征预处理:归一化、标准化,特征降维,特征选择,特征组合),暂不处理
# 4.模型训练
# 4.1 创建(逻辑回归)模型对象
estimator = LogisticRegression()
# 4.2 模型训练
estimator.fit(x_train, y_train)
# 5.模型预测
y_predict = estimator.predict(x_test)
print(f'预测结果:{y_predict}') #预测结果:[False False True ... False True False]
# 6.模型评估
print(f'准确率:{estimator.score(x_test, y_test)}') # (预测前)准确率:0.7679205110007097
print(f'准确率:{accuracy_score(y_test, y_predict)}') # (预测后)准确率:0.7679205110007097
print(f'精确率:{precision_score(y_test, y_predict)}') # 精确率:0.5807692307692308
print(f'召回率:{recall_score(y_test, y_predict)}') # 召回率:0.4092140921409214
print(f'F1值:{f1_score(y_test, y_predict)}') # F1值:0.48012718600953896
# macro avg 宏平均: 不考虑样本权重,直接求平均;适用于 数据均衡 的情况
# weighted avg 样本权重平均:即 考虑样本权重,求平均;适用于数据不均衡 的情况
print(f'分类评估报告:\n{classification_report(y_test, y_predict)}')
# 4.测试
if __name__ == '__main__':
# demo01_data_preprocessing()
# demo02_data_visualization()
demo03_logistic_regression_model()(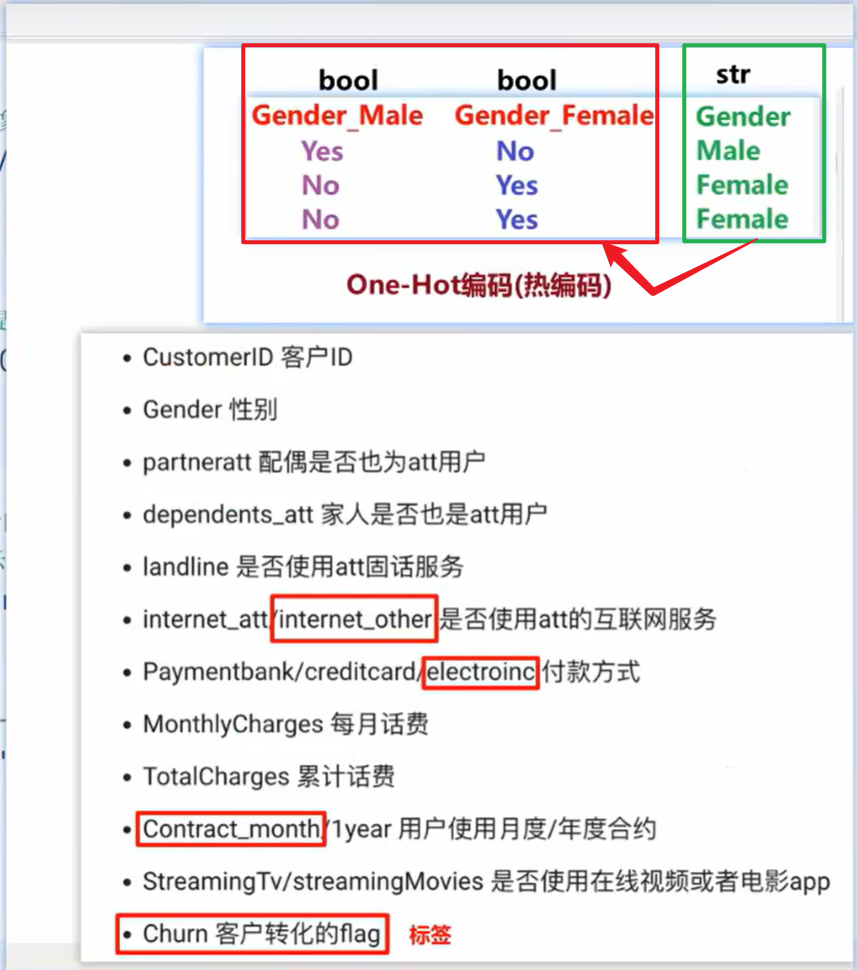
1. 定义函数,演示:数据的预处理
def demo01_data_preprocessing():
One-Hot热编码处理即将String类型的Gender字段 拆分成 左侧bool类型的Gender_Male、Gender_Female两个字段。
简述步骤:读取csv文件、热编码处理 、删列、改列名、查看;
2. 定义函数,演示:数据的可视化
def demo02_data_visualization():
前1~ 5步与上一个函数相同。sns.countplot(data=churn_df, x='Contract_Month') 中x='Contract_Month'表示根据月度会员做分析,x轴是月度会员;想看看流不流失hue='flag',flag='false'表示数据不流失: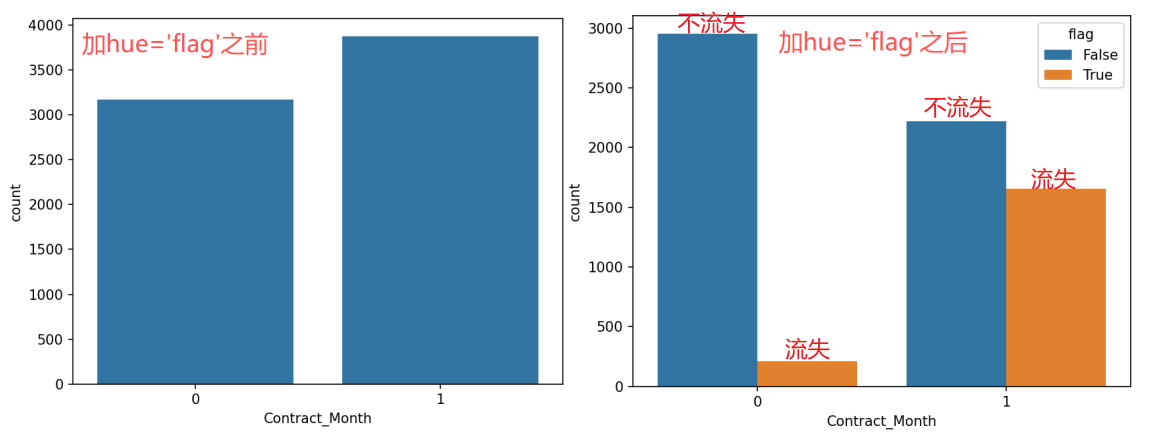
3. 定义函数,演示:逻辑回归算法的模型训练,预测,评估
def demo03_logistic_regression_model(): 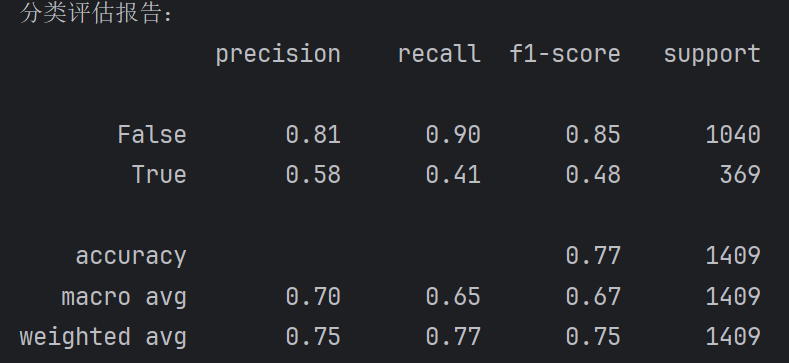 ①对于分类评估报告:False不流失、True流失,即流失与不流失中的:precision精确率 、recall召回率、f1-scoreF1值、support数据集的个数 ,accuracy准确率、macro avg 宏平均、weighted avg 权重平均 。
①对于分类评估报告:False不流失、True流失,即流失与不流失中的:precision精确率 、recall召回率、f1-scoreF1值、support数据集的个数 ,accuracy准确率、macro avg 宏平均、weighted avg 权重平均 。
②macro avg 宏平均 :逐个计算每个类的精确率,再求平均 即 不考虑样本权重,直接求平均;适用于数据均衡 的情况。
③weighted avg 样本权重平均 :即 考虑样本权重,求平均;适用于数据不均衡的情况。当数据非常多,值如果不均衡,增大某个权重、降低对方权重,两者即使量纲不同,差异也会变小;)