一、正则表达式
1.1 正则表达式概述
- 全称:Regular Express,简称 RegEX
- 作用:使用一串符号 描述具有共同属性的数据,实现模糊匹配
分为三种(仅作了解):
(工作中无需硬去区分)
- 基本正则(如grep。符号较为复杂,因而衍生出扩展正则)
- 扩展正则( 功能还不够强、不支持高级特性)
- Perl正则
1.2 egrep 过滤工具
文本处理顺序
- 以行为单位 ,逐行处理。
- 按整行匹配,默认只输出与表达式匹配 的文本行
- 相当于
grep -E,允许使用扩展正则表达式
基本用法
- 用法一:
egrep [选项] '正则表达式' 文件 - 用法二:
前置命令 | egrep [选项] '正则表达式'
正则表达式写在单引号之中
grep、egrep 既可以操作磁盘上的文本文件,也可以操作管道、标准输入传来的流式文本,不只是单纯读文件
常用选项
-i:忽略字母大小写-v:条件取反-c:统计匹配的行数-q:静默无输出 ,用于检测(看$?,0 表示匹配,非 0 不匹配)-n:显示匹配结果的行号--color:标红显示匹配字符串
(工作中常用:-v,-i,-q.其余作为了解)
1.3 行首及行尾匹配

代码示例
shell
[root@server ~]# egrep '^root' /etc/passwd #匹配以root关键字开头的行
[root@server ~]# egrep 'bash$' /etc/passwd #匹配以bash关键字结尾的行
[root@server ~]# cat /etc/default/useradd #查看文件内容
[root@server ~]# egrep '^$' /etc/default/useradd #匹配文件中的空行
[root@server ~]# egrep '.' /etc/default/useradd #匹配包括任意字符的行
[root@server ~]# egrep '..$'
/etc/default/useradd #匹配任意两个字符结尾的行1.4 不限定匹配次数
- 辅助理解:a+,最少匹配一个a,也就是每次匹配 最少匹配一个a,最多不限量个a;a?,每次匹配 最多1个最少0个a。*是二者的结合,a *是匹配任意个对应字符
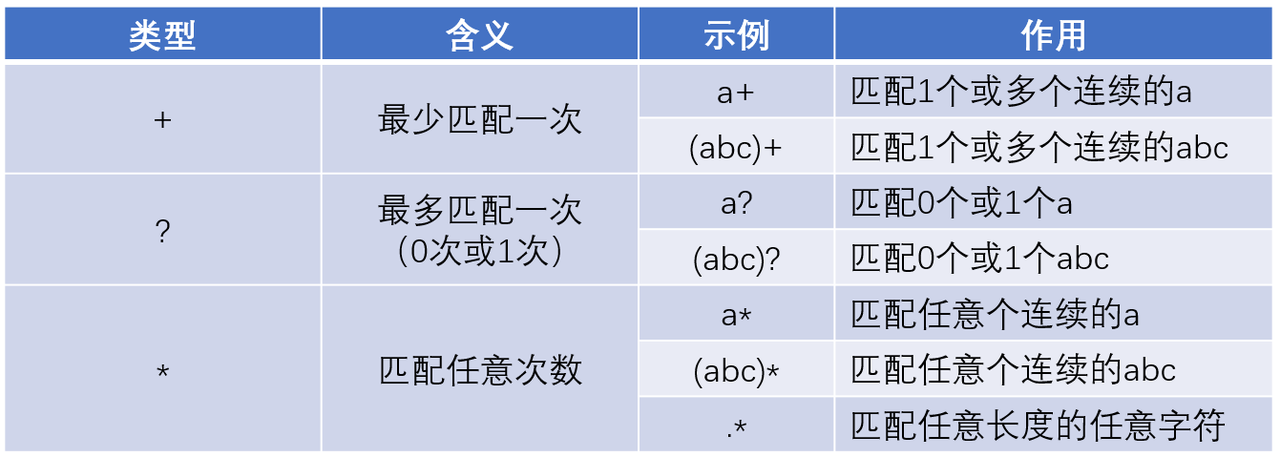
注意,+,?,*都不限定匹配次数
关于?:
着重关注匹配次数。
(abc)?:每一次 匹配只能匹配到0个或者1个abc
如果输出是连续的abcabc,相当于匹配了多次
如:(abc)+
匹配:abcabc
因为?每次只能匹配一个abc,所以算只匹配了两次。
关于+:
注意关键字:连续
(abc)+:每一次 匹配只能匹配到1个abc或者多个连续的abc
如果单行有多个不连续的(abc),算多次匹配
如果是连续的abcabc,相当于只匹配了一次
如:(abc)+
匹配:abcabc
因为是连续的两个abc,所以算只匹配了一次。
关于 . * :意思是匹配任意长度的任意字符,相当于只匹配一次。
但是'.'是有多少字符算匹配多少次
把()中的数据比作袋子中的苹果:
+相当于只要是连续成袋的,就把袋子里的苹果一次性倒出来 ?相当于整袋要么完全不拿(0 次),要么只拿 1 整袋(1 次),把苹果一个一个拿出来。
关于* :
任意次,包含0次
.* 每一行只匹配一次
代码示例
shell
egrep '(abc)+' /opt/reg.txt # 包含至少1次abc
egrep '(abc)?' /opt/reg.txt # 包含0或1次abc
egrep '(abc)*' /opt/reg.txt # 包含任意次abc(含0次)加了()意思是括号内的整体,如(abc)指代abc这个整体
1.5 限定匹配次数
- 辅助理解:粗略理解{n}的"次数n"其实是要查询的字符串的倍数。例:(a){n}意思是一次查询n个a
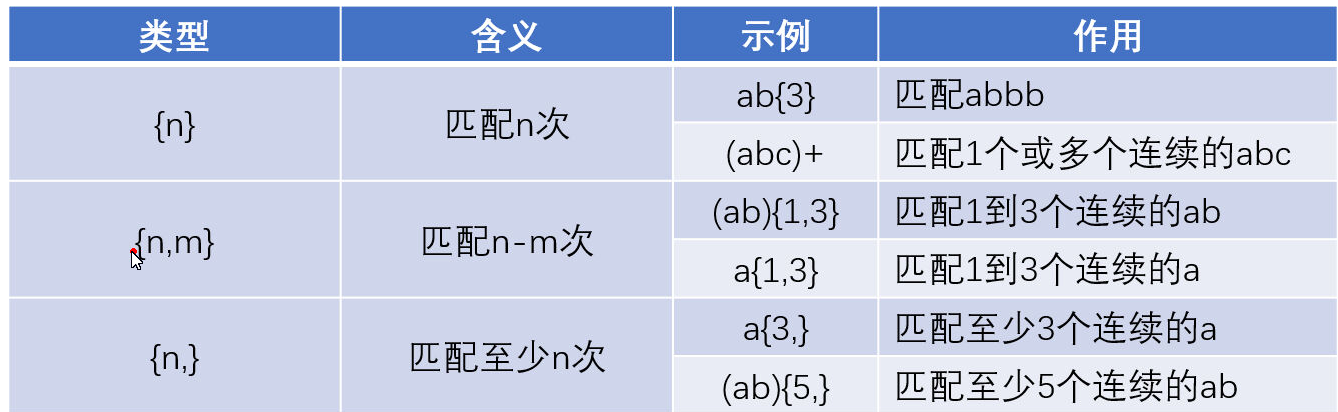
-
ab{3}:意思是匹配abbb(因为没加括号,ab不是一个整体,{3}只作用到b)
-
(ab){3}:意思是每一次都匹配3个连续的ab
-
其遵循贪婪匹配的原则,默认匹配最多次。如{1,3}与{3,},条件满足的情况下默认匹配3倍
示例与详解:
{n}示例详解
a{n}意思是每次匹配n个a

为什么这里两次输出一致?因为uu{2}:意思是每一次匹配都匹配u+2u,即uuu(因为没加括号,这两个u不是一个整体)匹配了6个u是匹配了两次。同理uu{5}:意思是每一次匹配都匹配u+5u,即uuuuuu,匹配了6个u是匹配了一次
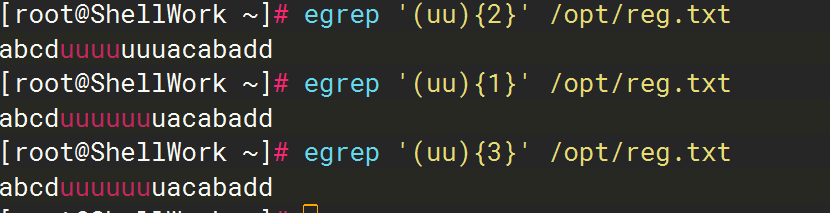
当我们加上括号,使uu成为一个整体之后,就能明显发现变化。(uu){2}意思是每一次 都匹配以uu为整体的字符的2倍,也就是uuuu;(uu){1}意思是每一次 都匹配以uu为整体的1倍,即uu;(uu){3}意思是每一次都匹配以uu为整体的3倍,即uuuuuu。
除了 {n} 这种 "精确指定次数(字符倍数)" 的以外, 所有其他正则量词,都会匹配【所有能匹配的对应元素】。
{n,m}示例详解
a{n,m}的意思是每一次匹配最少匹配n个a,最多匹配m个a。

看示例,已知字符串有7个u。u{3,6},每次最少匹配3个u,最多匹配6个u,因此会标亮6个,空余一个。
而u{3,7},每次最少匹配3个u,最多匹配7个u,最后七个全部标亮
{n,}示例详解
u{n,}意思是每次查询最少查询n个u,最多不限个u
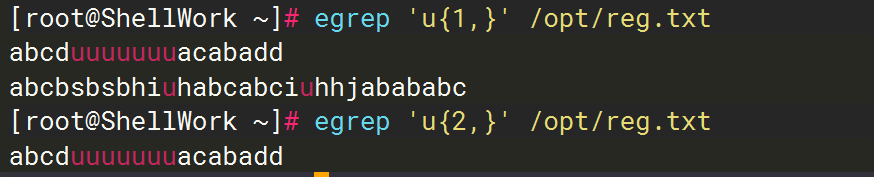
示例:u{1,},因为最少是一个u,所以包含单个不连续的u的行也会被过滤出来。而u{2,}时,每次查询最少是2个u,原先那个单个不连续的行就不会出现了
1.6 其他元字符
1.6.1 \[\] 内单字匹配
[]:匹配集合内任意一个字符[^]:取反,匹配不在集合内的字符
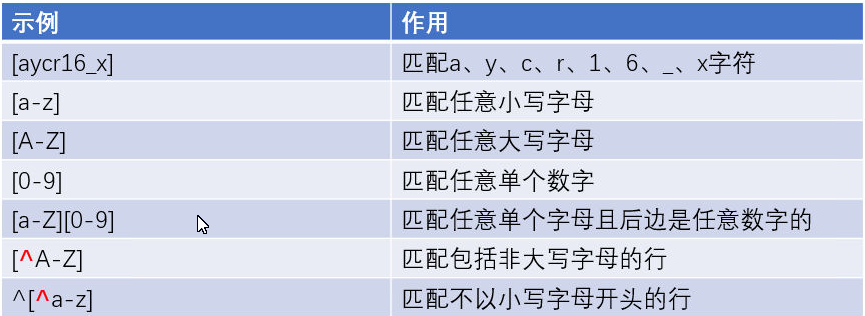
a-Z :所有大小写字母
注意: 中的每一个元素都是独立的,不会被视作整体进行匹配
代码示例
shell
[root@server ~]# cat /opt/reg.txt #编写测试文件
ab xx
abc xx
abcd xx
abcabc xx
[root@server ~]# egrep '^[a-z]' /opt/reg.txt #匹配小写字母开头的行
[root@server ~]# egrep '[acx]' /opt/reg.txt #匹配包含a、c、x字符的行
[root@server ~]# egrep '[^acx]' /opt/reg.txt #匹配不包含a、c、x字符的行集合内^为取反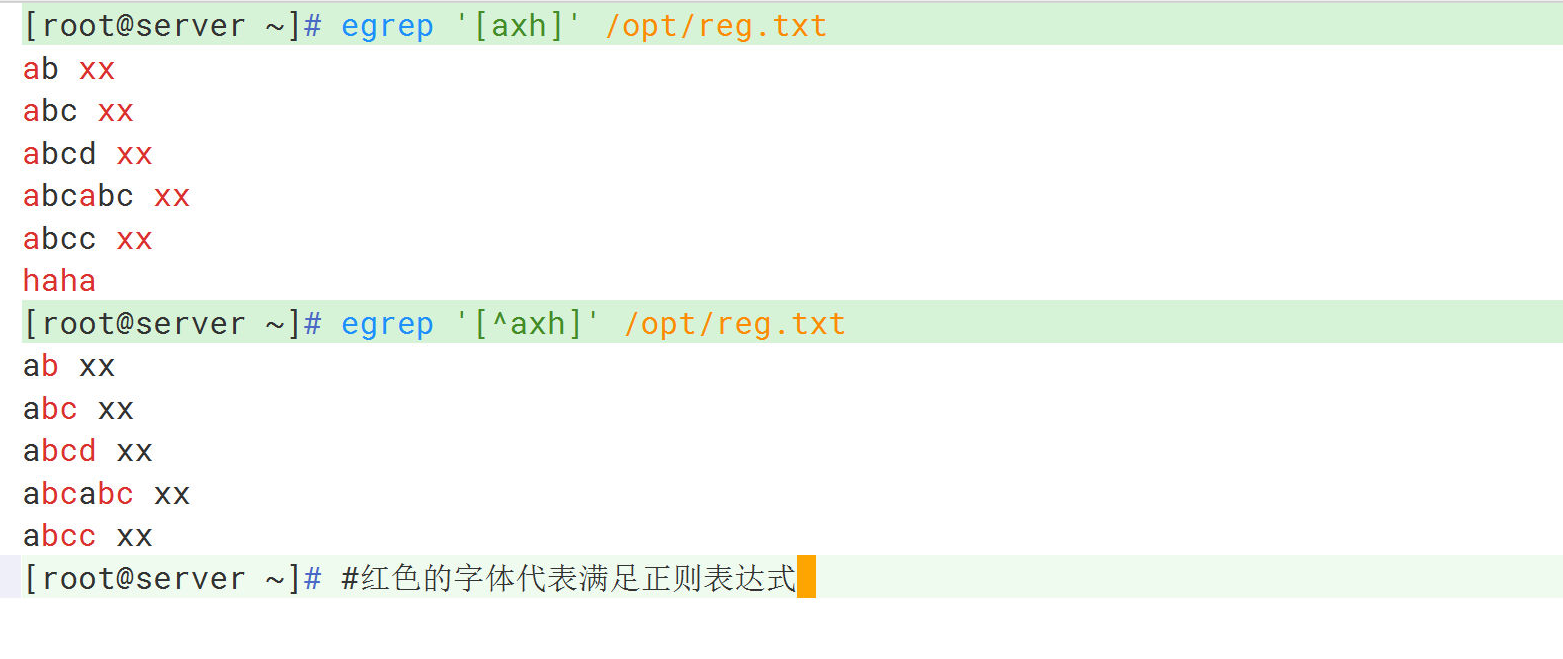
1.6.2 整体及边界匹配

代码示例
shell
[root@server ~]# egrep '(ab){1}' /opt/reg.txt #匹配ab连续出现1次的行
[root@server ~]# egrep 'root|tom' /etc/passwd #匹配包含root或者tom的行
[root@server ~]# egrep 'bin' /etc/passwd #匹配包含bin的行
[root@server ~]# egrep '\bbin\b' /etc/passwd #严格匹配包含bin的行二、sed 基本用法
2.1 sed 命令概述及解析
- 全称:Stream Editor(流式编辑器)
- 特点:非交互式逐行处理文本,并默认将结果输出到屏幕
- 支持:增、删、改、查(支持正则)
(逐行处理)
格式
- 格式一:
前置命令 | sed [选项] '条件指令' - 格式二:
sed [选项] '条件指令' 文件
常用选项
-n:屏蔽默认输出 (配合 p 使用)
(sed本身自带默认输出,当配合-p使用时会使目标输出两次。所以搭配-p使用尽量使用-n屏蔽默认输出)-i:直接修改文件内容
(命令只有加了-i才会真正修改对应文件)-r:支持扩展正则表达式
注意:-n不要和-i选项混用
条件写法
- 行号:
2、3,5、2p;4p - 正则:
/正则/ - 无条件:默认处理所有行
2.2 基本处理动作
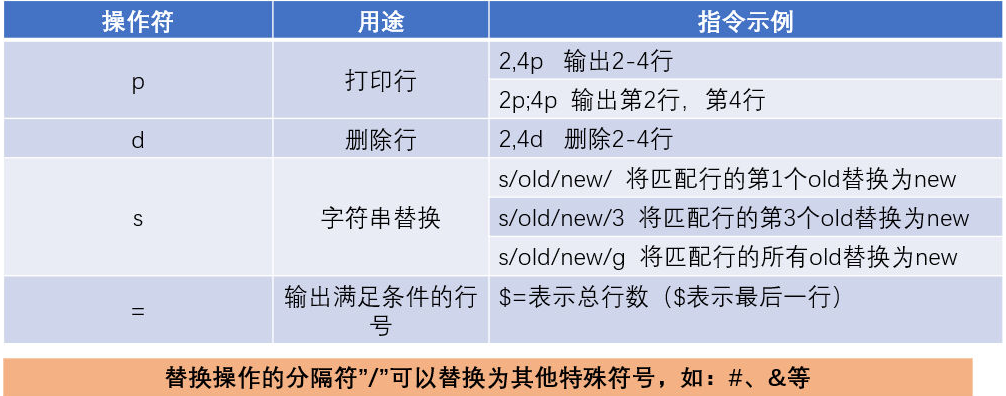
- 替换分隔符
/可换成#、&等任意特殊符号,但需保持一致,如s#old#new#等
表示最后一行,所有 =意思是最后一行的行号
2.3 常见处理操作示例
2.3.1 输出操作
shell
sed -n '4p' /opt/test.txt # 输出第4行
sed -n '2,4p' /opt/test.txt # 输出2~4行
sed -n '2p;4p' /opt/test.txt # 输出第2行和第4行
sed -n '/^C/p' /opt/test.txt # 输出以大写C开头的行
sed -rn '/o{2}/p' /opt/test.txt # 输出o连续出现2次的行
sed -n '$=' /opt/test.txt # 输出文件总行数2.3.2 删除操作
shell
sed '2d' /opt/test.txt # 删除第2行
sed '/linux$/d' /opt/test.txt # 删除以linux结尾的行
sed '3,4d' /opt/test.txt # 删除3~4行
sed '$d' /opt/test.txt # 删除最后一行2.3.3 修改操作
shell
sed '3s/Beijing/Shanghai/' /opt/test.txt # 第3行替换一次
sed 's/o/a/3' /opt/test.txt # 每行第3个o替换
sed 's/o/a/g' /opt/test.txt # 全局替换
sed '3,4s/^/#/' /opt/test.txt # 3~4行首加#
sed '$s/^/#/' /opt/test.txt # 最后一行首加#
sed -r '/^C/ s/^/#/' /opt/test.txt # 以C开头的行行首加#- s默认替换匹配行第一个关键字
- s/old/new/g意思是替换每行匹配到的所有old元素;
- s/old/new/3意思是替换每行的第3个元素;
- 最前面加数字指定第几行),' 2 s/old/new/'意思是替换第二行的元素
2.4 sed 应用案例:vsftpd 一键部署脚本
shell
[root@server ~]# vim /root/shell/day04/sed_vsftpd.sh #编写脚本
#!/bin/bash
#此脚本为ftp服务一键部署脚本,包括:装包、配置、启动服务
#如果已经安装,那么直接修改配置文件并重启服务
if rpm -q vsftpd &> /dev/null;then
sed -i '12s/NO/YES/' /etc/vsftpd/vsftpd.conf
systemctl restart vsftpd
ss -nutlp | grep :21
#如果没有安装,那么安装完软件再修改配置文件并重启服务
else
dnf -y install vsftpd
sed -i '12s/NO/YES/' /etc/vsftpd/vsftpd.conf
systemctl restart vsftpd
ss -nutlp | grep :21
fi
[root@server ~]# chmod +x /root/shell/day04/sed_vsftpd.sh #为脚本增加执行权限
[root@server ~]# /root/shell/day04/sed_vsftpd.sh #执行脚本验证三、sed 文本块处理
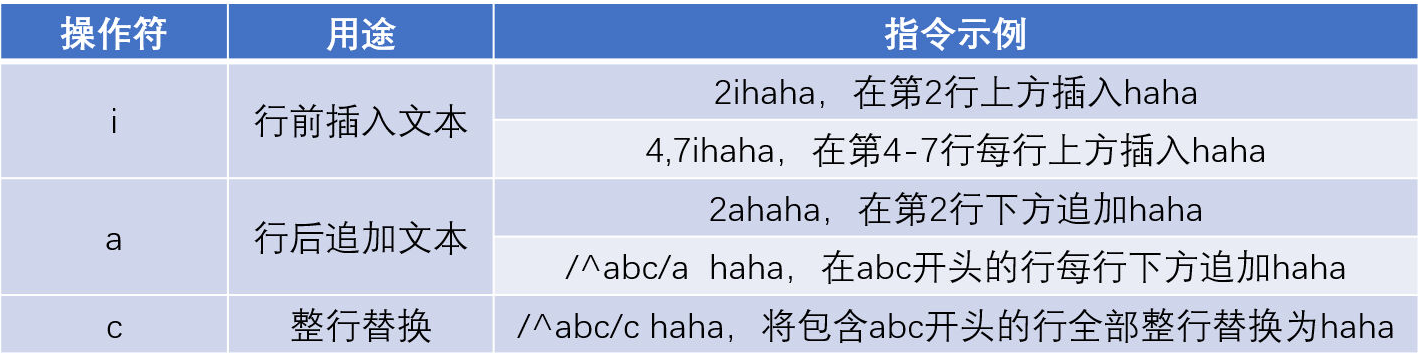
3.2 文本块处理动作
-
i行前:此处行前指的是行上方
-
a行后:指的是行下方
-
\n:相当于回车 , '1a AAA\nBBB'意思是在第一行下面插入AAA+回车+BBB
3.2 应用实例
3.2.1 单行处理
shell
[root@server ~]# vim /opt/file.txt #编写测试文件
Today is a beautiful day
Happy newyear
Happy birthday to you
[root@server ~]# sed '/newyear/i AAA' /opt/file.txt #在包含newyear的行上方增加AA
[root@server ~]# sed '2a AAA' /opt/file.txt #在第二行下方追加AAA
[root@server ~]# sed '/is/c AAA' /opt/file.txt #将包含is的行整行替换为AAA3.2.2 多行处理
\n表示换行- 加
-i才会真正修改文件
shell
[root@server ~]# sed '/newyear/i AAA' /opt/file.txt #在包含newyear的行上方增加AA
[root@server ~]# sed '2a AAA' /opt/file.txt #在第二行下方追加AAA
[root@server ~]# sed '/is/c AAA' /opt/file.txt #将包含is的行整行替换为AAA
[root@server ~]# sed '2a AAA\nBBB' /opt/file.txt #在第2行下方追加两行
[root@server ~]# sed '2i AAA\nBBB' /opt/file.txt #在第2行上方插入两行四、Day04 完整总结
- 理解正则表达式的作用与模糊匹配思想
- 掌握行首/行尾、次数、范围、边界等正则元字符
- 熟练使用
egrep过滤文本 - 掌握
sed基本用法:输出、删除、替换、修改文件 - 掌握
sed文本块处理:插入、追加、整行替换 - 能完成正则过滤 + sed 自动化配置修改脚本