
摘要
虽然深度神经网络中神经元的激活值通常无法被人类简单直观地解释,但稀疏自编码器(SAE)可以将这些激活值转换到更高维的隐空间中,从而变得更易于解释。然而,SAE 可能包含数百万个独立特征,使得人工逐一解释变得不可行。在本文中,我们构建了一套开源的自动化流程,利用大语言模型(LLM)为 SAE 特征生成并评估自然语言解释 。我们在不同规模、激活函数与损失函数的 SAE 上进行了测试,这些 SAE 分别在两个开源权重的大语言模型上训练。我们提出五种新的评价指标 来衡量解释质量,其运行成本低于现有最优方法。其中一种技术 ------干预评分(intervention scoring),用于评估对特征进行干预所产生效果的可解释性,我们发现它能够解释现有方法无法覆盖的特征。我们给出了生成更优质解释的指导原则,使其在更广泛的激活上下文下依然有效,并讨论了现有评分方法的缺陷。我们的代码已开源。
1. 引言
大语言模型(LLM)已在众多领域达到人类水平的性能(OpenAI, 2023),甚至可用于构建智能体(Wang et al., 2023),使其能够制定策略(Bakhtin et al., 2022)、开展协作并产生新观点(Lu et al., 2024; Shaham et al., 2024)。与此同时,我们对驱动模型行为的内部表征仍知之甚少。
早期机械可解释性研究主要关注单个神经元的激活模式分析(Olah et al., 2020; Gurnee et al., 2023; 2024)。由于需要解释的神经元数量庞大,研究者提出了自动化方法(Bills et al., 2023):利用另一个大语言模型,根据神经元的激活情况及其激活的文本片段生成解释,流程近似于人工标注。但研究发现,多数神经元具有多义性,会在差异显著的不同场景中激活(Arora et al., 2018; Elhage et al., 2022)。线性表征假设(Park et al., 2023)认为,人类可理解的概念编码在神经元的线性组合中。当前可解释性研究的一个重要方向正是提取并解耦这类特征(Bereska & Gavves, 2024)。
稀疏自编码器(SAE)被提出用于解决神经元多义性问题(Cunningham et al., 2023)。SAE 包含两部分:编码器将激活向量映射到稀疏、高维的隐空间,解码器则将特征投射回原始空间;两者联合训练以最小化重构误差。研究发现,SAE 特征具备可解释性,且比神经元更接近单义性 (Bricken et al., 2023; Cunningham et al., 2023)。近期,研究者将 SAE 训练扩展到更大规模模型,如 GPT-4(Gao et al., 2024)与 Claude 3 Sonnet(Templeton et al., 2024),使其成为大语言模型可解释性的重要工具。训练 SAE 会得到大量稀疏特征,每个特征都需要对应的自然语言解释。本文提出一套自动化框架,借助大语言模型为 SAE 中的每个特征生成解释。我们利用该框架对多个模型、多层、不同 SAE 结构的数百万特征进行解释,并提出新的解释质量评估方式,同时分析现有方法存在的问题。我们希望这些结论能为已有的 SAE 特征解释库(Lin & Bloom, 2023)提供参考,并助力不同 SAE 结构之间的对比。
2. 相关工作
最具代表性的自动化可解释性方法之一,是使用 GPT-4 解释 GPT-2 的神经元(Bills et al., 2023)。研究者向 GPT-4 展示某个神经元的激活场景示例,让其生成简短解释以描述激活模式;为评估解释效果,再让 GPT-4 依据该解释预测神经元在对应场景的激活情况,以预测激活与真实激活的相关度作为解释得分。Templeton 等人(2024)采用类似思路,对 Claude 3 Sonnet 的 SAE 特征进行解释。总体而言,现有方法聚焦于收集待解释模型的特征激活与对应场景,利用更大模型挖掘激活场景中的规律。延续这类工作,研究者提出了更多解释评估方法,包括让模型生成激活样本并测量模块激活程度(Singh et al., 2023; Kopf et al., 2024)。近期,研究者还构建了可解释性智能体,通过迭代实验得到视觉神经元的最优解释(Shaham et al., 2024)。
更高效的自动化可解释性方案也被提出:直接让待解释模型自身兼任解释生成模型(Kharlapenko et al., 2024)。将查询单个占位符 token 含义的提示输入模型,并在执行过程中将特征激活嵌入到占位符位置的残差流中,生成与该特征相关的续文。该技术受早期工作 Patchscopes(Ghandeharioun et al., 2024)与 SelfIE(Chen et al., 2024)启发。
3. 自动化可解释性流程
本节将分步阐述用于**生成特征解释并评估其质量**的核心流程。整个流程大致分为三个连续步骤:首先,在大规模数据集上收集待解释 SAE 的激活值;其次,针对每个特征筛选相关上下文并输入大语言模型,由模型为观测到的激活模式生成对应解释;最后,将这些解释与不同上下文配对,交由大语言模型通过相关任务评估解释在预测激活/非激活上下文时的效果,具体细节见下文。图1展示了该流程在真实特征上的示例。
3.1 激活值收集
稀疏自编码器(SAE)是单隐藏层前馈网络,训练目标是用**稀疏的少量神经元**重构输入。这意味着其神经元数量远多于输入维度,但仅有很小一部分神经元(本文中少于60个)会产生非零激活并参与输出。在本流程中,我们将 SAE 隐藏层神经元的非零激活称为**特征**,并对其进行解释。 我们在 RedPajama-v2(RPJv2)数据集的 1000 万令牌样本上收集了 SAE 的特征激活,该数据集与训练 Llama 3.1 8B 模型所用数据分布一致,构成近似于 Llama 1 预训练语料。 我们以句首令牌(BOS)开头,按批次截取长度为256的文本片段用于激活收集。用于激活收集的上下文长度短于 SAE 训练时的上下文长度。实验发现,在 1000 万令牌上,131k 特征的 Gemma 2 9B 模型中,每层平均有 30% 的特征激活次数少于200次,15% 的特征完全不激活;若按训练长度 1024 计算,仅 5% 的特征不激活。 当使用更接近训练数据的"无版权"Pile 数据集时,即使截取长度为256,激活少于200次的特征比例降至15%,完全不激活的仅占1%。有趣的是,在16k 特征的 Gemma 2 9B 模型中,仅有约10%的特征在 RPJv2 上激活少于200次,说明**更大规模(131k)的 SAE 会学到更多与数据集相关的特定特征**。
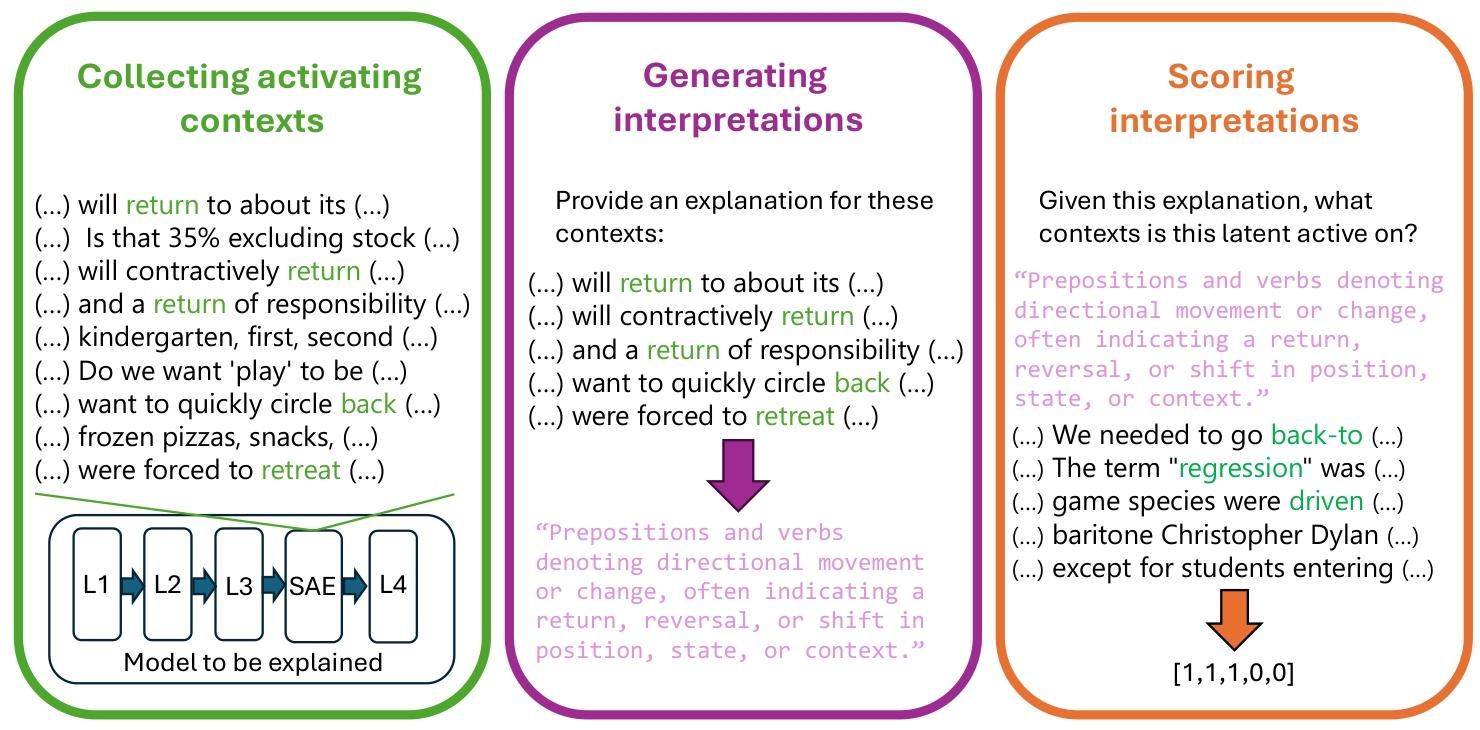
3.2 生成解释
本文生成解释的方法参考 Bricken 等人(2023),向解释模型展示从不同分位数采样的激活示例,但采用更自然的提示模板:完整呈现激活片段,高亮激活令牌并在句末标注激活强度,完整提示见附录B,整体设计与 Lee 等人(2023)相似。部分解释及对应得分示例如图A1所示。 我们向解释模型 Llama 3.1 70B Instruct 输入**40个不同的激活示例**,每个示例长度为32令牌,激活令牌可出现在任意位置。虽然大部分特征可以被32令牌长度的上下文较好解释,但长上下文激活的特征难以被当前流程充分表示。使用更长上下文生成解释要么需要减少示例数量,要么需要更强(也更昂贵)的解释模型。 由于本文提出的评估方法成本显著更低,劣质解释可以被轻松过滤,长距离特征的解释留待未来工作。按照该解释配置,**解释100万个特征仅需约200美元**。 实验发现,从更广泛的示例中随机采样生成的解释能覆盖更多样的激活情况,但有时会降低对最高激活样本的描述精度(见图2)。仅使用最高激活示例通常能得到更简洁、更具体的解释,精准描述这些样本,但无法覆盖整体分布。反之,从激活分布的十分位区间**分层采样**可能导致解释过于宽泛,无法表达有效语义。这类失效模式的例子见图A2及附录C的讨论。
3.2.1 干预的自动化解释
包括本文探索的大多数方法在内,现有的自动化可解释性方法,通常关注特征激活与输入的某种自然语言属性之间的相关性。然而,部分特征与模型**输出**的关系更为密切。例如,我们发现了一个特征:其激活会使模型输出与"声誉"相关的词汇,但从输入角度无法对其进行简单解释。 我们将**输出特征**定义为:能引发模型输出某种可通过自然语言轻易解释的属性的特征。关于评分时使用的定义,详见第3.3.5节。 输出特征也可以通过其与输入的相关性来描述。例如,上述"声誉"特征会在后续可能出现声誉相关词汇的上下文里激活。然而,从对输出的因果影响角度解释输出特征有两大优势:
-
**可扩展性**:从对输出的影响来描述输出特征更为简单,因为解释模型只需识别输出中的简单模式;而该特征与输入相关的模式则更复杂。通过与输入相关来解释特征,需要近似还原被解释模型在产生该特征前的计算过程,当被解释模型能力极强、处理复杂任务时,这会变得极具挑战。但部分特征对输出的影响,依然很容易解释。
-
**因果证据**:若我们希望通过调控特征来引导模型行为,就需要知道该特征确实会导致模型输出的某种属性。已有研究表明,现有的自动化可解释性评分方法,无法准确捕捉解释对神经元干预效果的预测能力(Huang et al., 2023)。此外,也有研究指出,因果证据对分布偏移的鲁棒性更强(Bühlmann, 2018; Schölkopf et al., 2012)。
3.3 解释质量评分
解释的生成过程需要高效,其质量评估同样需要高效。研究者希望了解每一条解释对网络实际行为的忠实度。部分特征可能无法用简单方式解释,此时自动化解释流程应输出评估指标较差的解释。其次,评估结果可作为反馈信号,用于解释模型的训练与流程中超参数的调优。最后,部分SAE本身质量不佳,可通过其所有解释的聚合评估指标来检测。 目前,SAE解释的质量主要通过**模拟评分(simulation scoring)**衡量,该方法由Bills等人(2023)提出,最初用于神经元解释的评估。其流程为:让解释模型在一组上下文里"模拟"特征行为,即根据给定的解释,预测该特征在上下文每个token上的激活强度;再计算模拟激活与真实激活之间的皮尔逊相关系数,作为模拟得分。 现有文献的标准做法是从"top-and-random"分布中采样上下文:混合最高激活的上下文,以及从激活语料中均匀随机采样的上下文。尽管过采样最高激活上下文会引入偏差,但考虑到对每个特征的数百个示例进行模拟评分成本极高,该方法被用作低成本的方差降低技术(Cunningham et al., 2023)。
在本文中,我们对"优质解释"的定义略有不同:解释应能作为**二分类器**,区分激活上下文与非激活上下文。其背后的逻辑很简单:鉴于SAE特征高度稀疏,其大部分方差可被一个二值预测器捕捉------当特征预期激活时,预测其非零激活均值;否则预测为零。在统计学中,零膨胀现象通常被建模为两部分的混合分布:零值处的狄拉克δ分布,以及非零值对应的另一种分布(如泊松分布)。 这与模拟评分的普遍做法相悖:后者仅关注激活样本,尽管这类样本在SAE每个特征的相关上下文中占比不足0.01%,但区分非激活上下文与激活上下文的能力,似乎更为重要。 作为模拟评分的替代方案,我们提出了四种新的评估方法,聚焦于解释在多大程度上能帮助评分器区分激活与非激活上下文。额外的好处是,所有这些方法的计算效率都高于模拟评分(见表1)。我们还提出了一种评分方法,评估针对特定特征进行干预时的可解释性。
3.3.1 检测评分(Detection)
对解释进行评分的一种简单方法是:让语言模型根据给定解释,判断**一整段文本序列**是否会激活某个 SAE 特征。检测评分在每个样本上只需生成少量输出token,这意味着可以在相近开销下,使用**更广泛激活强度分布**的样本来评分。通过纳入**非激活上下文**,该方法可以同时衡量解释的精确率(Precision)和召回率(Recall)。 相比模拟评分,检测评分更加"宽松",因为评分器**不需要将特征定位到特定token**。这意味着检测评分评估的是:解释能否正确识别特征会激活的**上下文类型**,即使解释没有精确定位到具体token。 该方法与下文的模糊评分(Fuzzing)都可以利用token概率,来评估评分模型对分类结果的置信度。我们认为这一机制有助于改进评分方法。提示词细节见附录D.1。
3.3.2 模糊评分(Fuzzing)
模糊评分与检测评分类似,但作用于**单个token级别**。它会在每个样本中标记出可能激活的token,然后让语言模型判断哪些句子的标记是正确的。 模糊评分**最接近传统的模拟评分**。因为SAE激活非常稀疏,模拟评分本质上就是正确识别哪些token具有非零激活。因此,模糊评分与模拟评分的相关性最高。 如果解释只关注特征激活哪些token,**不关注上下文**,它仍可能在模糊评分上得高分,但在检测评分上较低(尤其是当这些token是常见词时)。因此,**同时使用检测评分和模糊评分**,可以判断模型是否基于正确的原因进行分类。提示词细节见附录D.2。
3.3.3 困惑度评分(Surprisal)
困惑度评分的核心思想是:**好的解释应该能让基础语言模型(评分器)在激活上下文的交叉熵损失更低**。 具体来说,对于每个激活或非激活上下文 \(x\),我们计算解释 \(z\) 的信息价值: 其中
是固定的伪解释。好的解释在**激活样本**上的信息价值应显著高于非激活样本。 解释的最终困惑度得分,是将信息价值作为分类器,区分激活/非激活上下文的 **AUROC值**。提示词与计算细节见附录D.3。 困惑度评分依赖模型根据解释调整预测的能力,同时衡量解释中上下文的相关性与token特异性。但它与其他评分的相关性最低,我们认为当前设置仍有改进空间。
3.3.4 嵌入评分(Embedding)
给定解释来分类激活/非激活上下文,可以看作:**将特征解释作为查询(query),从大量文本中检索出相关的文档(激活上下文)**。 我们将一批激活与非激活上下文用编码Transformer提取嵌入,再计算**解释查询**与**上下文文本**的相似度,用这个相似度做分类并计算AUROC,即为嵌入得分。 如果编码模型足够小(本文使用400M参数),该方法**速度最快**,并能评估更大范围的激活分布。实验表明,使用更大的7B参数嵌入模型不会显著提升分数(见图A3)。提示词、模型与计算细节见附录D.4。
3.3.5 干预评分(Intervention Scoring)
与前四种基于上下文的评分不同,**干预评分从因果反事实角度**解释特征对模型输出的影响。 我们量化:在提示分布 上,对特征施加干预
并使用解释
时,评分器在**干预生成文本**上关于解释
的困惑度的平均下降。
:
原始模型在提示 x 下的生成分布 - :施加干预后的生成分布 实际计算时,对每个prompt采样一次干净输出、一次干预输出。 过强的干预会让解释变得平庸(模型确定性输出)。因此,**必须在固定干预强度下比较分数**。 我们将干预强度
定义为:干预后模型输出分布与原始输出的**平均KL散度**:
干预实验的解释与评分流程见附录G。
4. 实验结果
4.1 评分方法对比
若要在更多样本上评估解释效果,必须使用比模拟评分更简便的方法(Templeton 等人,2024)。传统模拟评分**只在激活样本上计算**,忽略解释能否正确处理非激活样本。同时,由于计算成本高昂,每个特征通常只能用少量样本评分,这一显著缺陷促使我们探索更高效的评分方法。 在表 1 中,我们基于 100 个不同上下文,对比了 Fuzzing、Detection 与两种模拟评分方法对单个特征评分的 token 消耗量。
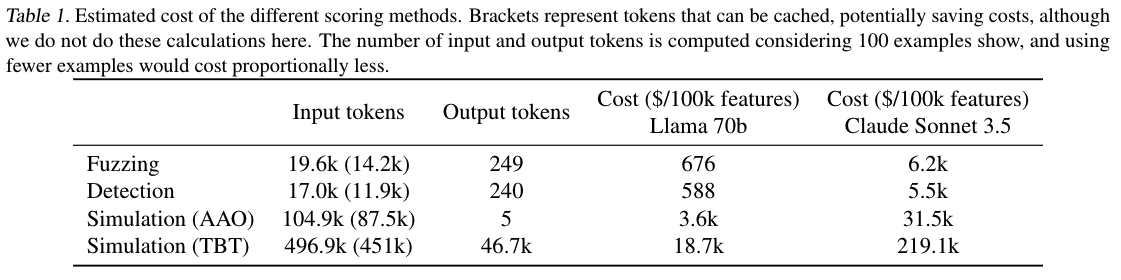 结果显示,使用 Bills 等人(2023)提出的一次性(AAO)方式时,Fuzzing 与 Detection 的成本比模拟评分**低至少 5 倍**;但该方法需要访问提示 token 的对数概率,而顶尖闭源模型通常不提供这一能力。 若研究者无法使用本地模型,需要在线生成模拟分数,则只能采用逐 token(TBT)方式,其成本比 Fuzzing 和 Detection **高出近 30 倍**。在同一组解释上,Llama 70B 与 Claude Sonnet 3.5 给出的 Fuzzing 和 Detection 分数分布相近;但 Claude Sonnet 3.5 的模拟分数整体高于 Llama 70B(见表 A9),这意味着需要将 Llama 70B 上 Fuzzing、Detection 的成本与 Claude Sonnet 3.5 上模拟评分的成本做对应比较。 **嵌入评分(Embedding)成本更低**:100 个上下文仅需 4000 个输入 token,按平均每百万 token 0.13 美元计算,每 10 万特征仅需 50 美元。 我们建议尽可能**组合多种方法**评估解释,因为每种方法都有不同失效模式(见 3.3 节),更丰富的评分体系能弥补缺陷。在同一 800 条解释上计算各方法分数的相关性后发现:各指标存在明显正相关,但也存在分歧(见附录 D.6 与表 A1、A2)。 其中,**Fuzzing 与模拟评分的相关性最高**,因为它主要衡量解释能否帮助模型预测哪些 token 非零激活;而 SAE 激活本身高度稀疏,模拟评分本质上做的是相近检验。与之相对,模拟评分与 Detection、Embedding、Surprisal 的相关性明显更低,后三者更准确地衡量上下文是否激活特征,而非具体哪个 token 激活。使用 Claude 3.5 Sonnet 计算模拟分数时,各类相关系数略有上升(见附录 D.6)。 我们还对比了各评分方法与**人工评分**的相关性。参照 Templeton 等人(2024)的方式,人类评估者从 4 个等级打分: 1. 解释与文本无关 2. 解释与文本模糊相关 3. 解释不完整但相关 4. 解释准确描述 token 激活 每个特征至少在 5 个上下文中评分,共包含 700 个上下文与 81 条特征解释。结果显示: - Fuzzing 与人工评分的斯皮尔曼相关系数最高(0.69) - 其次是模拟评分(0.60) - Detection(0.59) - Surprisal(0.34) - Embedding(0.32) 综合成本与效果,我们建议: - 使用 **Fuzzing 与 Detection** 评估解释能否定位激活 token 与对应上下文 - 使用 **Embedding** 等低成本方法快速迭代,初步筛选优质/劣质解释
结果显示,使用 Bills 等人(2023)提出的一次性(AAO)方式时,Fuzzing 与 Detection 的成本比模拟评分**低至少 5 倍**;但该方法需要访问提示 token 的对数概率,而顶尖闭源模型通常不提供这一能力。 若研究者无法使用本地模型,需要在线生成模拟分数,则只能采用逐 token(TBT)方式,其成本比 Fuzzing 和 Detection **高出近 30 倍**。在同一组解释上,Llama 70B 与 Claude Sonnet 3.5 给出的 Fuzzing 和 Detection 分数分布相近;但 Claude Sonnet 3.5 的模拟分数整体高于 Llama 70B(见表 A9),这意味着需要将 Llama 70B 上 Fuzzing、Detection 的成本与 Claude Sonnet 3.5 上模拟评分的成本做对应比较。 **嵌入评分(Embedding)成本更低**:100 个上下文仅需 4000 个输入 token,按平均每百万 token 0.13 美元计算,每 10 万特征仅需 50 美元。 我们建议尽可能**组合多种方法**评估解释,因为每种方法都有不同失效模式(见 3.3 节),更丰富的评分体系能弥补缺陷。在同一 800 条解释上计算各方法分数的相关性后发现:各指标存在明显正相关,但也存在分歧(见附录 D.6 与表 A1、A2)。 其中,**Fuzzing 与模拟评分的相关性最高**,因为它主要衡量解释能否帮助模型预测哪些 token 非零激活;而 SAE 激活本身高度稀疏,模拟评分本质上做的是相近检验。与之相对,模拟评分与 Detection、Embedding、Surprisal 的相关性明显更低,后三者更准确地衡量上下文是否激活特征,而非具体哪个 token 激活。使用 Claude 3.5 Sonnet 计算模拟分数时,各类相关系数略有上升(见附录 D.6)。 我们还对比了各评分方法与**人工评分**的相关性。参照 Templeton 等人(2024)的方式,人类评估者从 4 个等级打分: 1. 解释与文本无关 2. 解释与文本模糊相关 3. 解释不完整但相关 4. 解释准确描述 token 激活 每个特征至少在 5 个上下文中评分,共包含 700 个上下文与 81 条特征解释。结果显示: - Fuzzing 与人工评分的斯皮尔曼相关系数最高(0.69) - 其次是模拟评分(0.60) - Detection(0.59) - Surprisal(0.34) - Embedding(0.32) 综合成本与效果,我们建议: - 使用 **Fuzzing 与 Detection** 评估解释能否定位激活 token 与对应上下文 - 使用 **Embedding** 等低成本方法快速迭代,初步筛选优质/劣质解释
4.1.1 干预评分
前述评分方法都属于**相关性方法**,衡量解释能否预测特征激活值或区分激活/非激活样本。而**干预评分**用于衡量解释能否预测特征被干预后的输出效果。 我们将流水线生成、经 Fuzzing 评分的相关性解释,与经干预评分的因果性解释做对比。实验假设:部分特征相关性评分偏低,是因为它们更适合用**下游输出效果**解释,而非激活上下文。
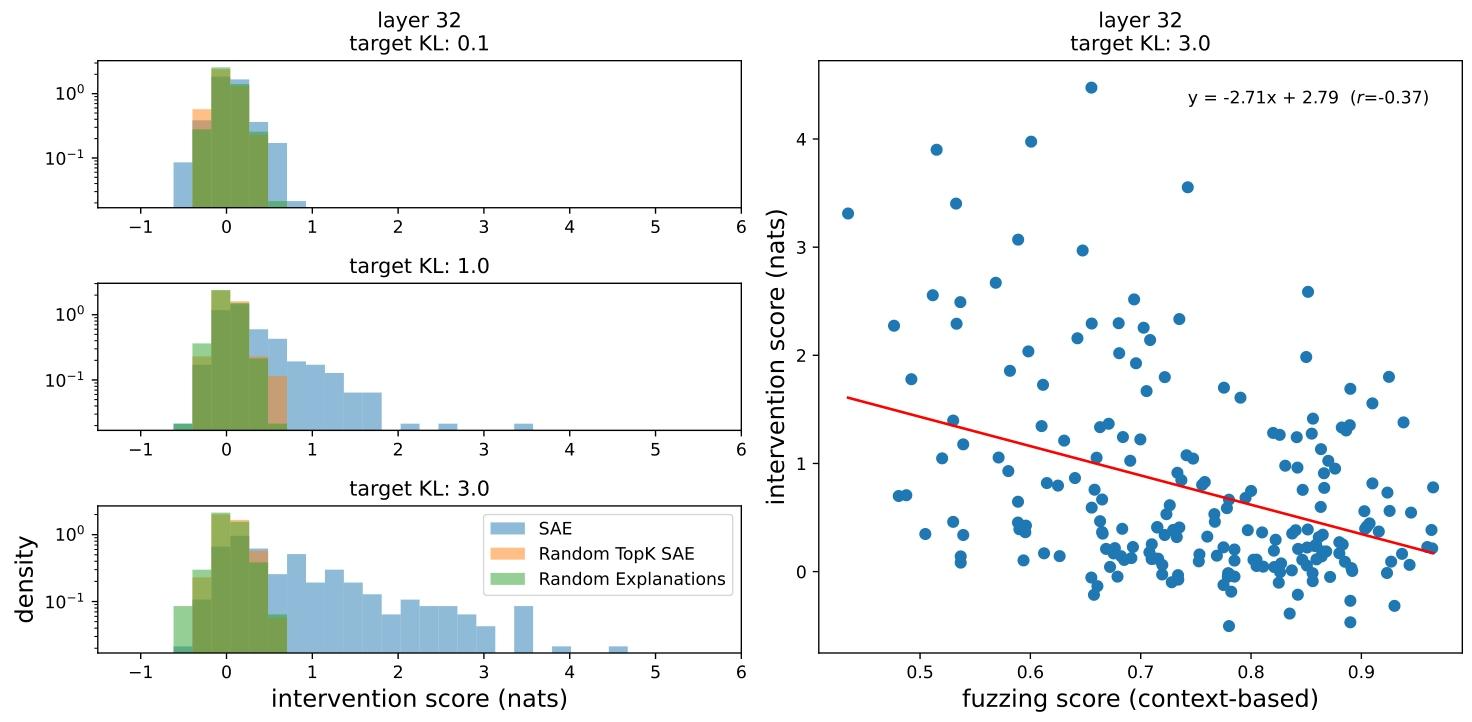
从图 3 可见,Fuzzing 分数与干预分数呈**弱负相关**:整体上,Fuzzing 分数低的特征,更适合用下游输出效果解释。同时,训练好的 SAE 解释的干预分数分布,与随机初始化 SAE、真实 SAE 配随机解释的分布差异显著,验证了该评分方法的有效性。
4.2 解释生成方法对比 我们以 500 多个特征为测试集,分析设计选择与超参数对解释质量的影响。每个特征使用 100 个激活样本与 100 个非激活样本评分;激活样本采用分层抽样,保证从激活分布的 10 个十分位区间各抽 10 个。我们选用**Fuzzing、Detection、Embedding** 评分,因其计算快且易于解释,能综合反映解释在激活与非激活样本上的有效性。 实验发现: - 只使用激活上下文生成的解释,与从全分布抽样生成的解释差异明显 - 基于**Top 激活样本**的解释**特异性更高、但召回更低**,无法覆盖整体分布 - 基于全分布抽样的解释容易**过于宽泛**,语义不明确 若只在高激活样本上评分,无法发现这一问题,凸显出现有自动化评估的缺陷:用高激活样本生成解释,却只在激活分布的一小部分子集上评测。 - 解释模型规模增大,分数略有提升,但 Claude Sonnet 3.5 生成的解释分数并未比 Llama 3.1 70B 高很多(见表 A9),二者都接近人类水平 - 评分模型越小,Fuzzing、Detection 等分数越低 - 给解释模型展示**更多样本**,分数小幅上升(见表 A7) - 是否使用与训练 SAE 相同的数据集、轻微调整上下文长度,影响不大(见表 A3、A5) - 使用**思维链(COT)** 不会显著提升 Llama 70B 的解释质量,但显著增加计算与时间开销,因此主流实验未使用 进一步发现: - **特征数量更多的 SAE 分数更高**,显著优于神经元 - 仅取 Top-K 最激活神经元能提升可解释性,但仍显著差于 SAE(见表 A10) - **位置影响**:残差流上训练的 SAE 优于在 MLP 输出上训练的 SAE - 模型**底层分数整体偏低**,但从前面几层之后,分数在深度上基本保持稳定(见图 A5)