Federation背景介绍
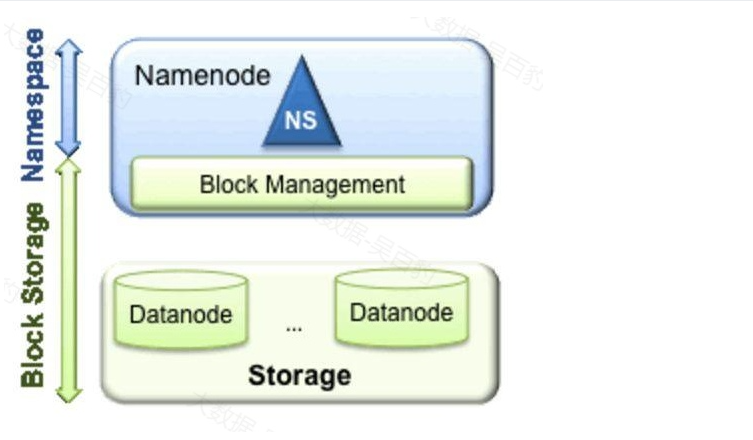
从上图中,我们可以很明显地看出现有的HDFS数据管理,数据存储2层分层的结构。也就是说,所有关于存储数据的信息和管理是放在NameNode这边,而真实数据的存储则是在各个DataNode下。而这些隶属于同一个NameNode,所管理的数据都是在同一个命名空间下的"NS",以上结构是一个NameNode管理集群中所有元数据信息。
举个例子,一般1GB内存放1,000,000 block元数据。200个节点的集群中每个节点有24TB存储空间,block大小为128MB,能存储大概4千万个block(200*24*1024*1024M/128 约为4千万或更多)。100万需要1G内存存储元数据,4千万大概需要40G内存存储元数据,假设节点数如果更多、存储数据更多的情况下,需要的内存也就越多。
通过以上例子可以看出,单NameNode的架构使得 HDFS 在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode进程使用的内存可能会达到上百G,NameNode 成为了性能的瓶颈。这时该怎么办?元数据空间依然还是在不断增大,一味调高NameNode的JVM大小绝对不是一个持久的办法,这时候就诞生了 HDFS Federation 的机制。
HDFS Federation是解决namenode内存瓶颈问题的水平横向扩展方案。Federation中文意思为联邦、联盟,HDFS Federation是NameNode的Federation,也就是会有多个NameNode。这些 namenode之间是联合的,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有 namenode 发送心跳和块报告,并执行来自所有 namenode的命令。
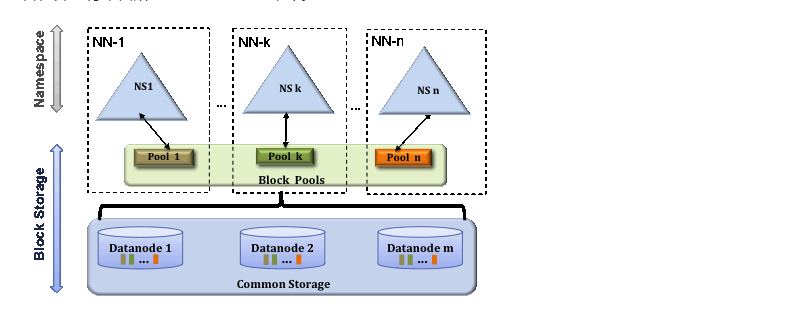
-
NameNode节点之间是相互独立的联邦的关系,即它们之间不需要协调服务。
-
DataNode向集群中所有的NameNode注册,发送心跳和block块列表报告,处理来自NameNode的指令。
-
用户可以使用ViewFs创建个性化的命名空间视图,ViewFs类似于在Unix/Linux系统中的客户端挂载表。
Federation搭建
Hadoop Federation机制可以看成将多个HDFS集群进行了统一管理,即:多个HDFS集群中,每个集群都有一个或者多个NameNode,每个NameNode只能属于一个集群且都有自己的NameSpace,集群间的NameSpace相互独立。通过Hadoop Federation机制可以将指定数据存储在不同的集群由不同的NS管理,且可以通过ViewFS进行统一访问。
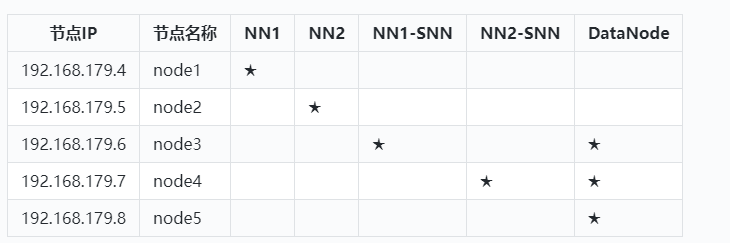
在node1~node5节点中进行Hadoop Federation集群搭建节点规划如下:


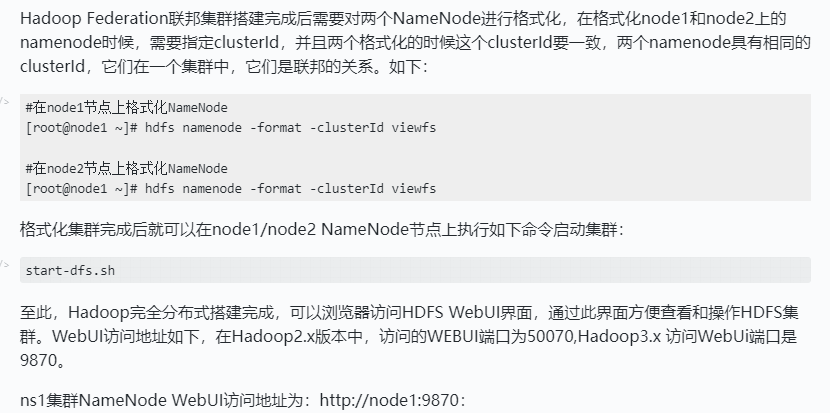
- 配置hdfs-site.xml


格式化并启动HDFS集群
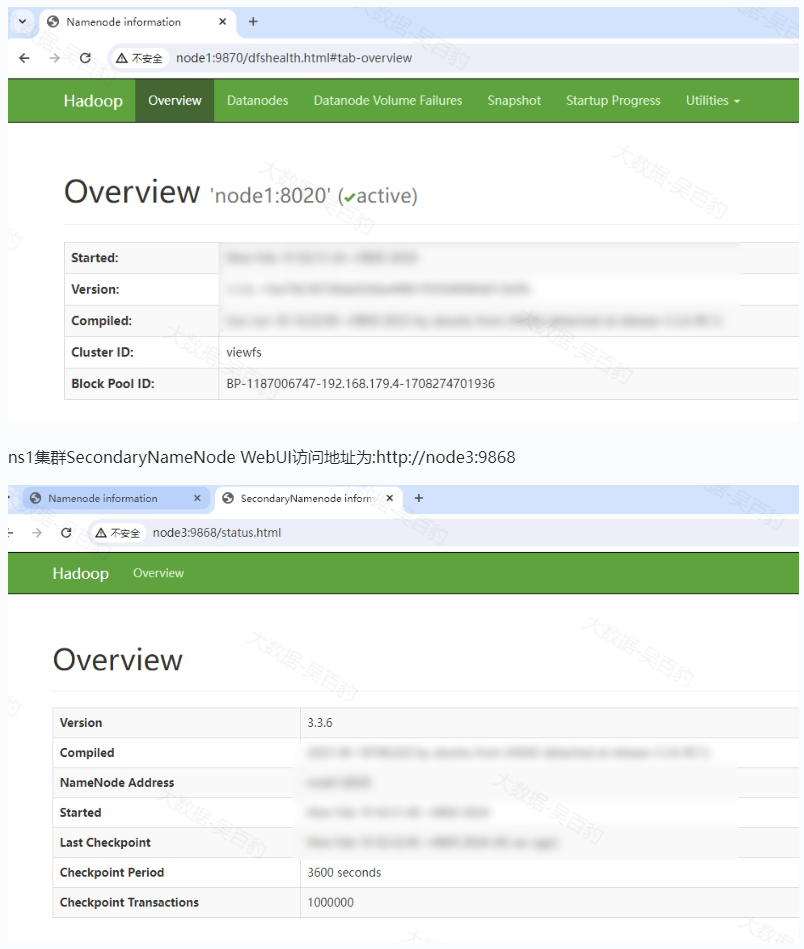
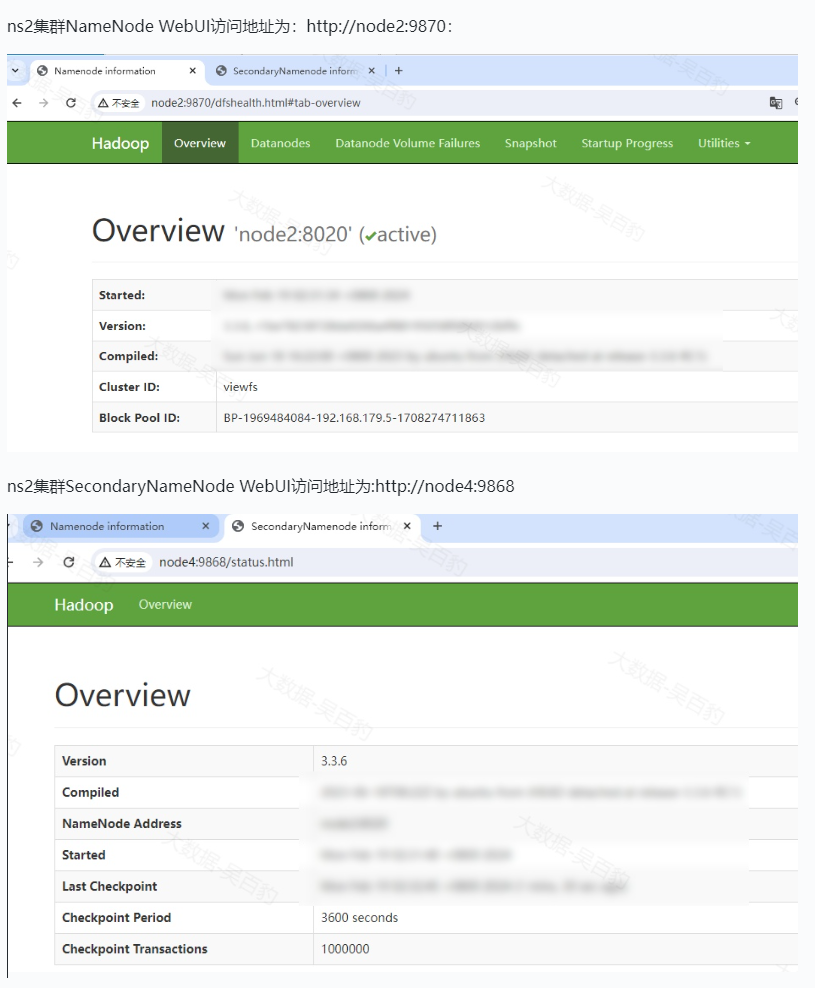

Federation问题
HDFS Federation 并没有完全解决单点故障问题。虽然 namenode/namespace 存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个 namenode 挂掉了,其管理的相应的文件便不可以访问。当然Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主namenode 挂掉重启后,用于还原元数据信息,需要手动将挂掉的namenode重新启动。
所以一般集群规模真的很大的时候,会采用HA+Federation 的部署方案。也就是每个联合的namenodes都是HA(High Availablity - 高可用)的。