目录
[1. 图的定义](#1. 图的定义)
[2. 有向图和无向图](#2. 有向图和无向图)
[3. 简单图与多重图](#3. 简单图与多重图)
[4. 稠密图和稀疏图](#4. 稠密图和稀疏图)
[5. 顶点的度](#5. 顶点的度)
[6. 路径](#6. 路径)
[7. 简单路径与回路](#7. 简单路径与回路)
[8. 路径长度和带权路径长度](#8. 路径长度和带权路径长度)
[9. 子图与生成子图](#9. 子图与生成子图)
[10. 连通图与连通分量](#10. 连通图与连通分量)
[11. 生成树](#11. 生成树)
[1. 邻接矩阵](#1. 邻接矩阵)
[2. 邻接表](#2. 邻接表)
[1. DFS](#1. DFS)
[2. BFS](#2. BFS)
前言
图论很难,但是其实我们一步步掌握关于图论的各个知识,其实理解它并不难。下面,我们将从零开始介绍一些关于图论的知识。本章我们主要介绍关于图的一些基本概念术语以及通过C++代码实现图的存储。
一、图的基本概念
在图中,有许多概念,下面我们就来一步步认识。
1. 图的定义
什么是图?
在以前我们学习过线性表和树,那么和现在我们将要学习的图,到底有什么区别,我们来比较一下:
- 对于线性表,除了首尾两个元素之外,其余元素都只有一个前驱和一个后继,它们元素和元素之前是1对1的关系。
- 而对于树,除根节点外,每个元素都有唯一的双亲,数据之间是一种层次结构,它们的元素与元素之间是1对多的关系。
- 而在图中,任意两个节点之间都有可能有关系,是一种多对多的关系。
我们可以来;类比一下: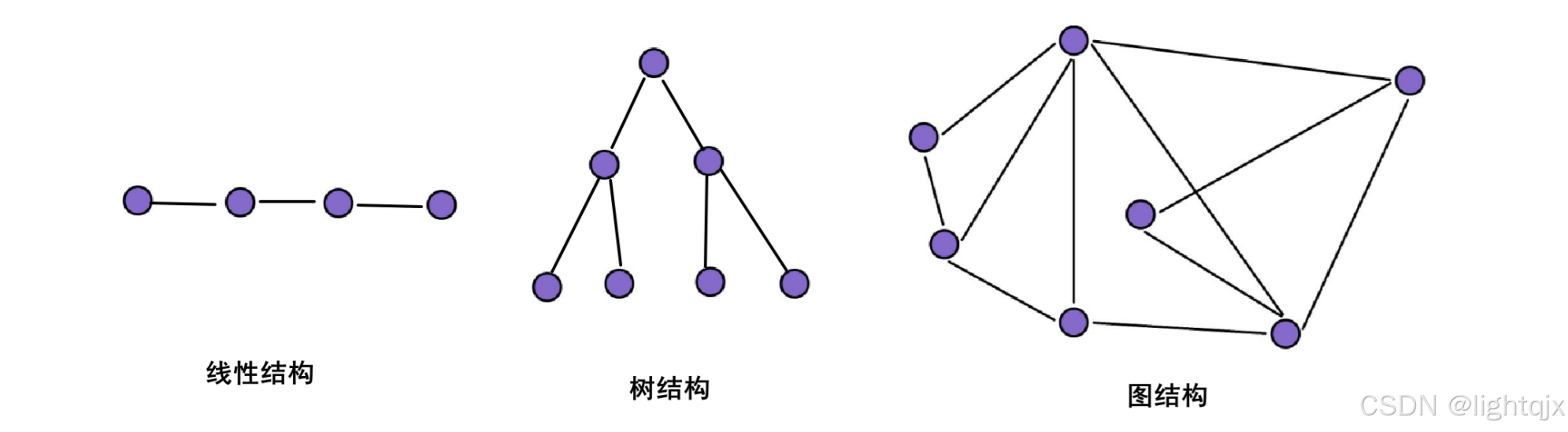
其中第三个图就是图的结构,任意两个点之间都有可能会有一条边。
当然,对于图,也有比较官方的解释(但看起来会比较抽象):
反正,我们只需要知道,图就是有一些点和一些边组成的就行了。其中还需要注意的是知道图的阶就是图中所有顶点的个数。
下面我们来看看,在图中我们会遇到哪些术语和概念。
2. 有向图和无向图
因为我们知道在图中各个点都是通过边连接成的。而对于边我们也可以分成两种:一种是有方向的,一种是没有方向的。
- 在有向图 中,所有的边都是有方向的。
- 在无向图 中,所有的边都是没有方向的。
如图所示:
一般,为了简化代码,在图相关的算法中,我们常常会将无序图的边看成两条方向相反的有向边。
3. 简单图与多重图
认识简单图与多重图之前,我们先来认识一下自环 和重边。
- 自环 就是一条边的两个端点是同一个顶点,其实就是自己指向自己有一边。
- 重边 是指连接同一对顶点的边有多条 ,通俗讲就是两点之间有多条路。注意,这里是指点与点之间的一条边。
如图所示: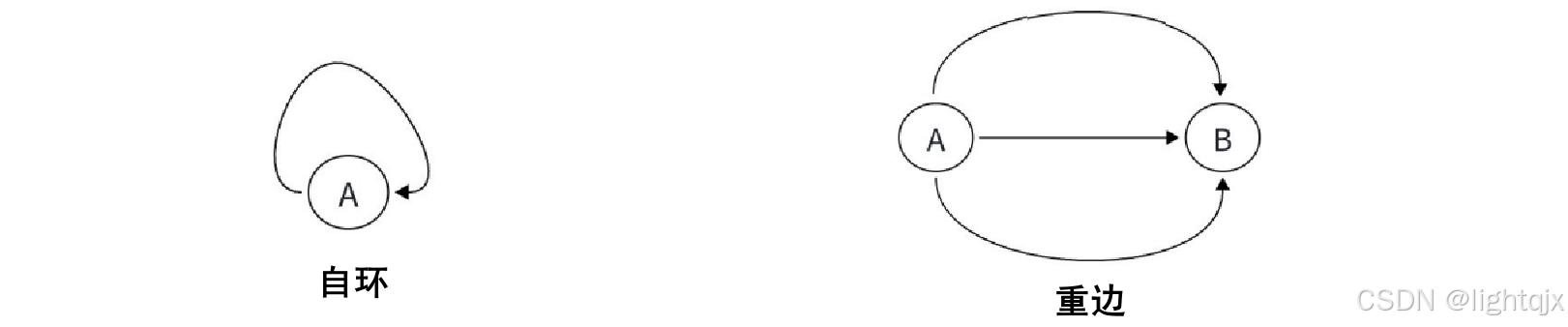
那么现在就可以来理解简单图与多重图了。
- 简单图:没有重边和自环的图。
- 多重图:存在重边或自环的图,其中自环和重边可以只存在一个,也可以同时存在。
示例: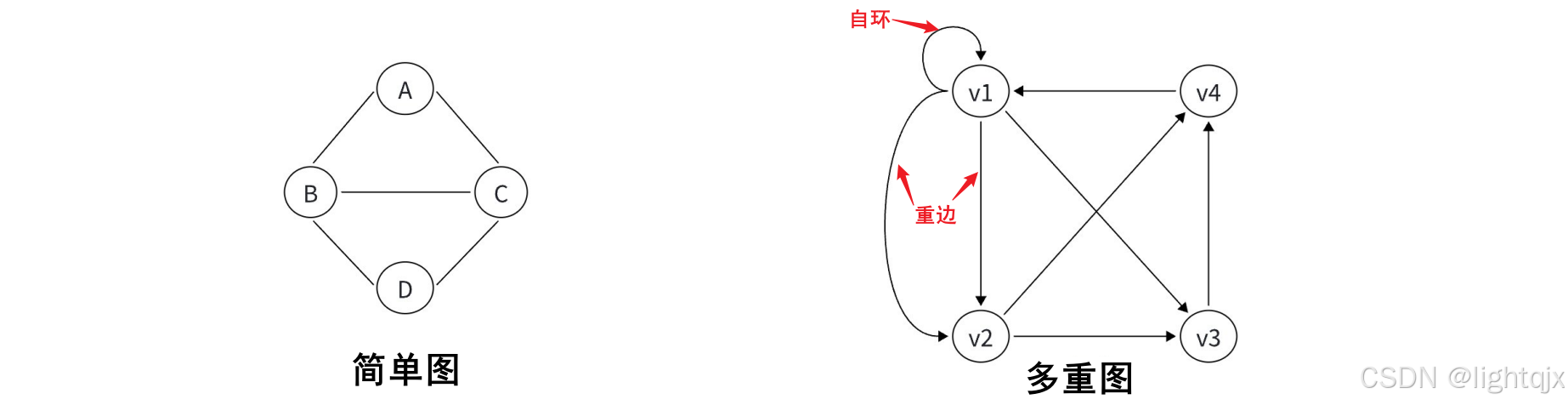
4. 稠密图和稀疏图
如果图中任意两个顶点之间都有一条边相连,则我们可以称其为完全图。
- 稠密图:指边的数量接近于完全图的边数,完全图也是稠密图。
- 稀疏图:指边的数量远小于完全图的边数。
一般为了区分,我们可以将满足 (其中e为图中的边数,n为图中顶点个数)的图称为稀疏图,反之称为稠密图。这个定义其实是一个算法复杂度分析中的一个"经验阈值",主要是方便确定使用什么方法来存储图(邻接表存储稀疏图,邻接矩阵存储稠密图,后面说)。
比如图所示:
5. 顶点的度
顶点的度,就是与该顶点关联的边的条数。
在有向图中 ,边是有方向的。一个顶点 v 的度被分成了两部分: 入度( 以该顶点为箭头终点的边的数目)和出度(以该顶点为箭头起点的边的数目)。所以,在有向图中顶点v的度( deg(v))等于该顶点的入度( indeg(v))与出度( outdeg(v))之和,即:deg(v) = indeg(v) + outdeg(v)。
在无向图中, 边是没有方向的,其顶点的度就是指依附于该顶点的边的数目。 注:无向图中没有入度和出度的概念,或者可以认为入度,出度,顶点的度三者相等,即:deg(v) = indeg(v) + outdeg(v)。
示例: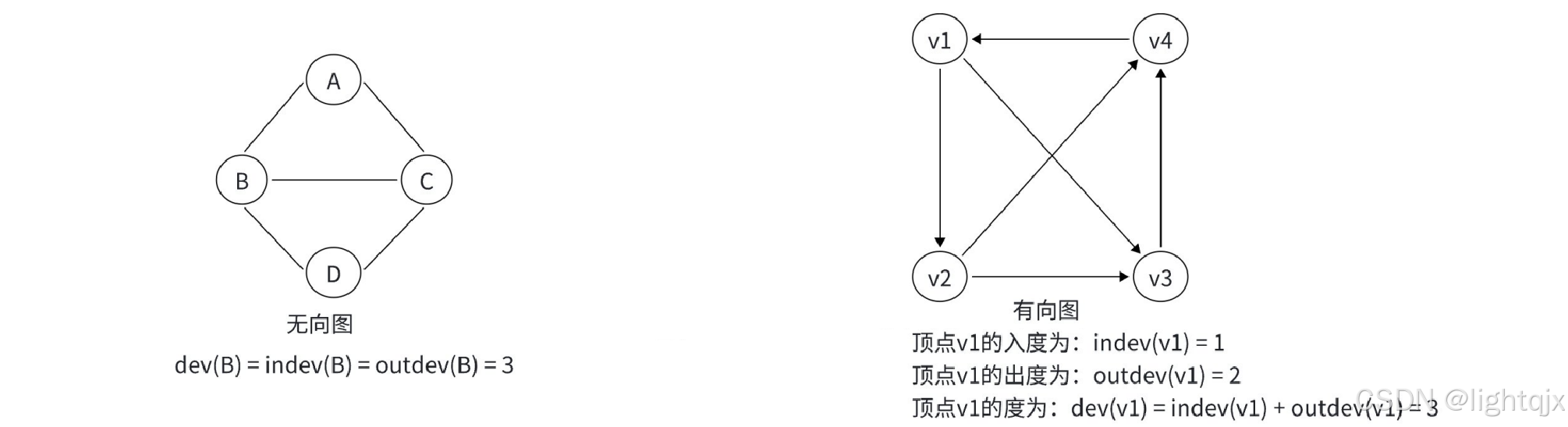
小性质:在无向图中所有顶点的度之和为总边数的2倍。
6. 路径
在一个图中,从一个点出发,会经过一些顶点
,到达
,则这些顶点序列:
就是从顶点
到顶点
的路径。
注意:在无向图中,路径可以沿任意方向遍历边,是一种双向通道;在有向图中,路径必须严格遵循边的箭头方向,是单向通道。
示例: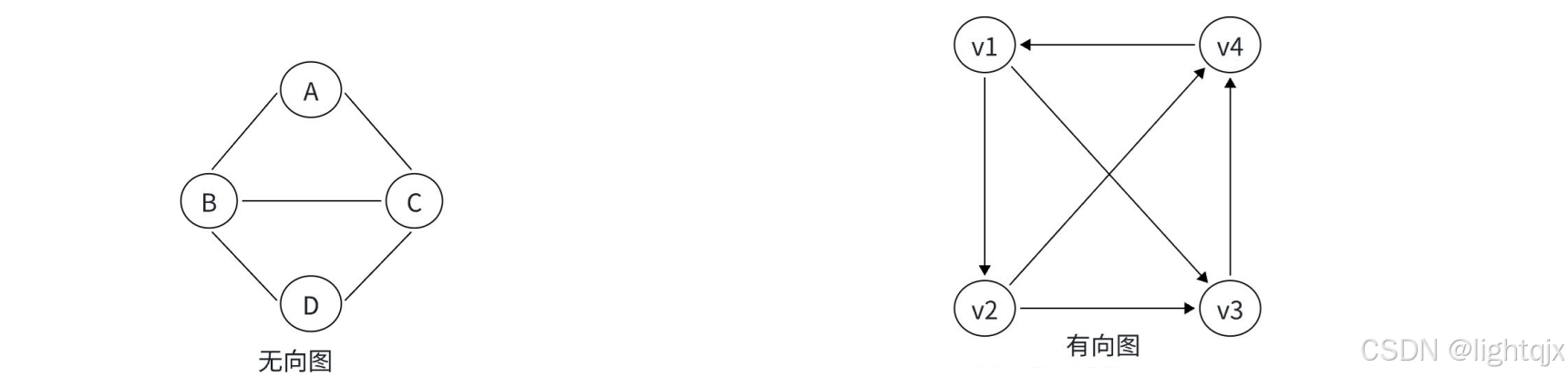
- 在该无向图中,从A到D的路可以是A,B,D,也可以是A,B,C,D,甚至也可以绕一个圈即A,B,D,C,B,D;
- 在有向图中,从v1到到v4的路径,可以是v1,v2,v3,v4,也可以是,v1,v3,v4。这里的路径必须沿着箭头方向的,不能逆着箭头方向,比如路径v1,v4就不行。
7. 简单路径与回路
- 简单路径:在一条路径的顶点序列中,如果没有重复的顶点,则就是简单路径
- 回路:在一条路径的顶点序列中,路径上第⼀个顶点和最后一个顶点相同,这样的路径就是回路或环
示例: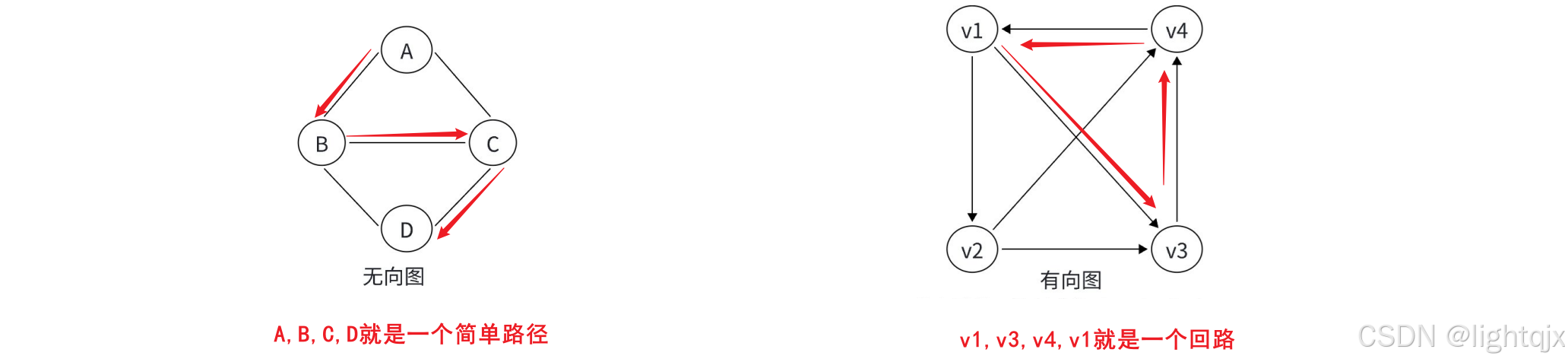
简单来说,对于一个路径,如果路径中出现了一个环,那它就是一个回路,如果没有环,那它就是一个简单路径。
8. 路径长度和带权路径长度
在某些图(比如带权图)的边具有与它相关的数值,称其为该边的权值 。在一个图中,边的权值代表的就是从一个顶点到另一个相邻顶点之间需要耗费的代价。
- 路径长度 :指一条路径上经过的边的数量。适用于不带权图中,因为无向图中我们不关心边的权重,或者可以认为所有边的权重默认为 1。
- 带权路径长度 :指一条路径上所有边的权重之和。适用于带权图,即边上有数值(权重)的图。
示例;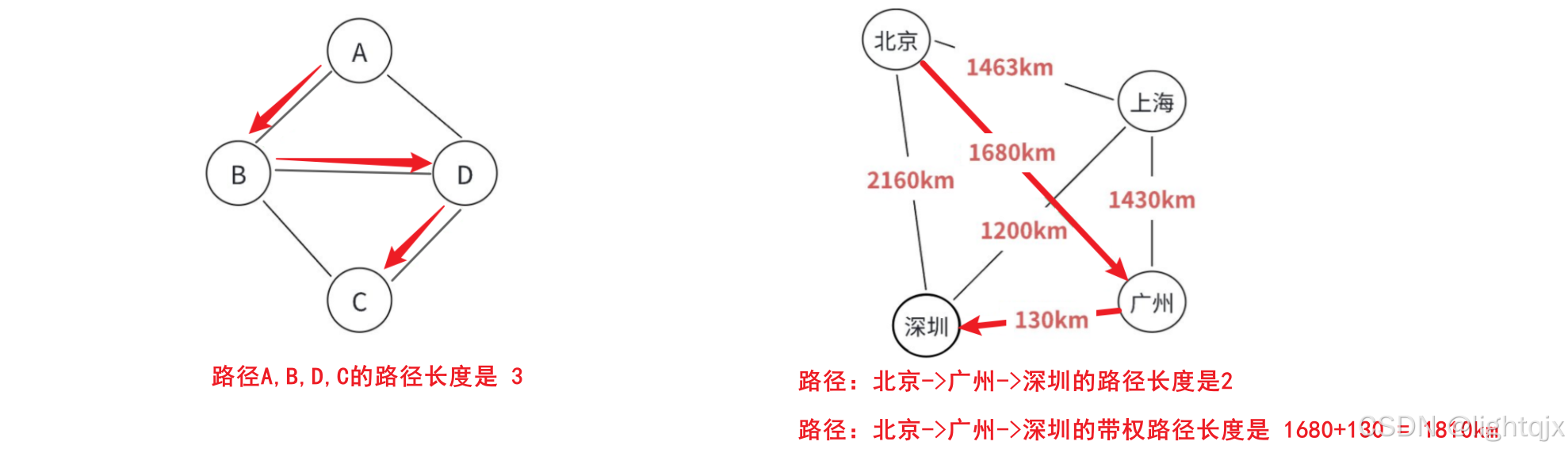
9. 子图与生成子图
子图就是在原来图的基础上,拿出来一些顶点和边,组成一个新的图。但是要注意,拿出来的点和 边要能构成一个图才行。
如果子图的顶点等于原图的顶点,而不需要和原图一样,这样的子图,称为生成子图。
可以说:所有的生成子图都是子图,但不是所有的子图都是生成子图,子图包含了生成子图。
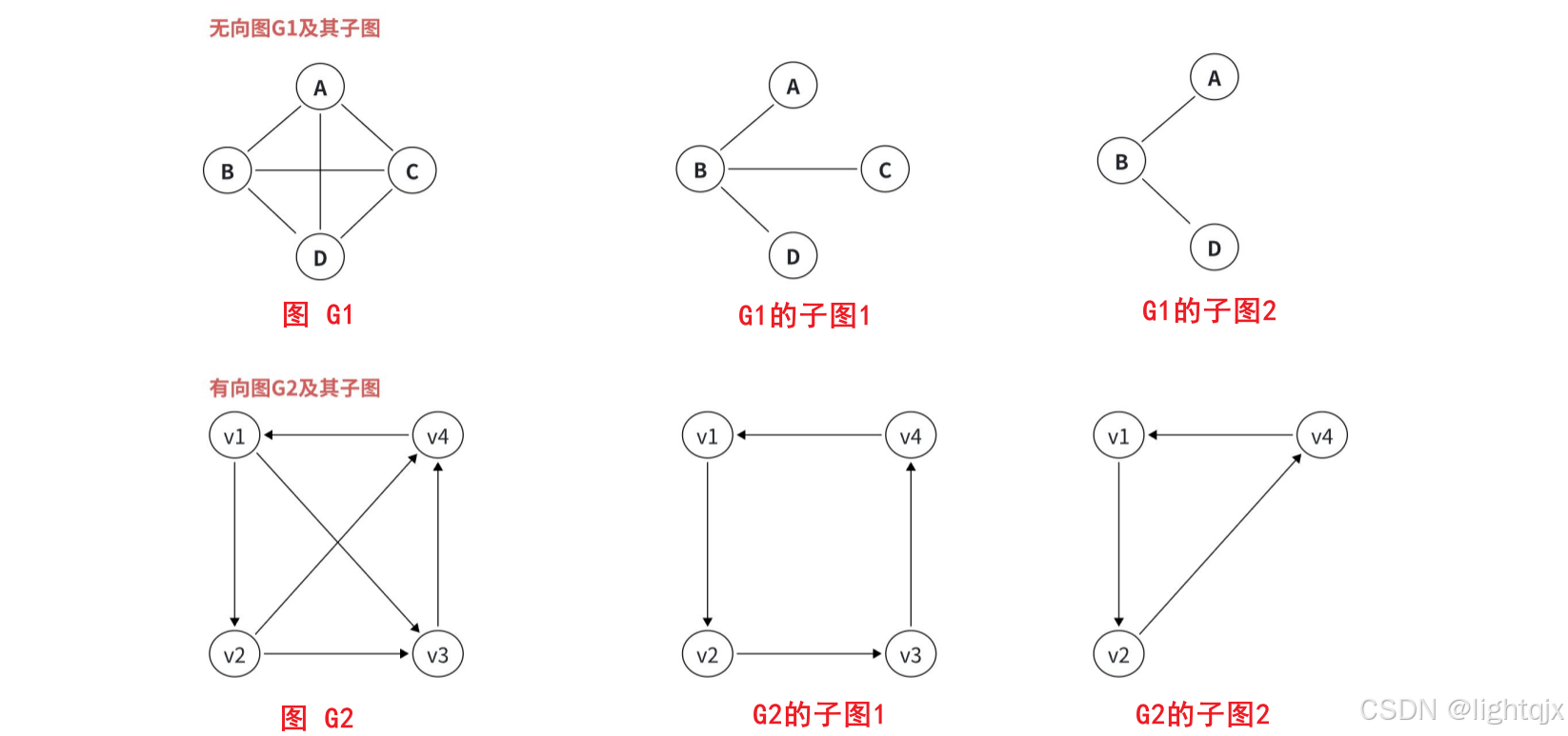
其中G1的子图1表示的就是G1的生成子图,G2的子图1表示的就是G2的生成子图。
10. 连通图与连通分量
在一个无向图 中,如果任意 两个顶点之间都存在路径 ,那么这个图就被称为连通图 ,否则就是非连通图。
理解连通分量,我们首先需要理解一下极大联通子图 ,极大联通子图,就是在一个无向图中,拿出一个子图,这个子图包含尽可能多的点和边, 并且保证这个子图内部,每个顶点是连通的(任意两点可达)。示例:
其实就是把由很多个连通图组成的无向图,将各个连通图原封不动的拿出来,这就是极大联通子图。
而连通分量 的概念就是无向图中极大联通子图的个数。
示例: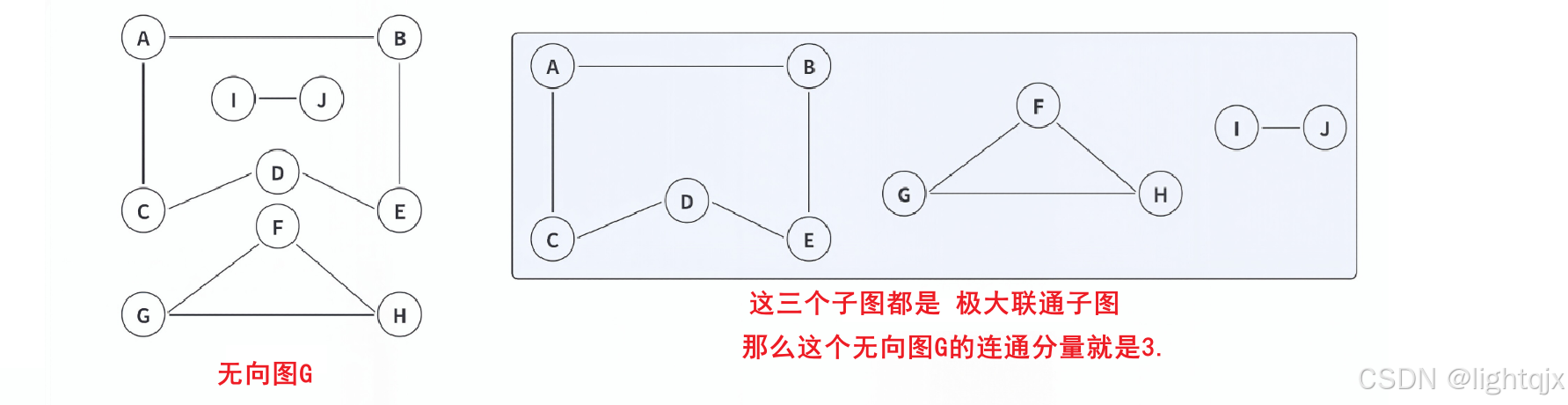
11. 生成树
生成树的概念:如果一个图是连通图 ,我们保留它的所有顶点,但去掉所有的环(回路),只保留能让图保持连通的最少边数。这样得到的子图就是一棵生成树。
极小连通子图
极小连通子图就是在一个连通图 G 中,如果一个子图 G ′ 满足: 包含 G 的全部顶点,且 G ′ 依然是连通的。 如果在这个子图中再少一条边,图就会变得不连通,若加上⼀条边则会形成一个回路。它就是极小连通子图。
而生成树可以认为就是包含图中全部顶点的一个极小连通子图。
示例: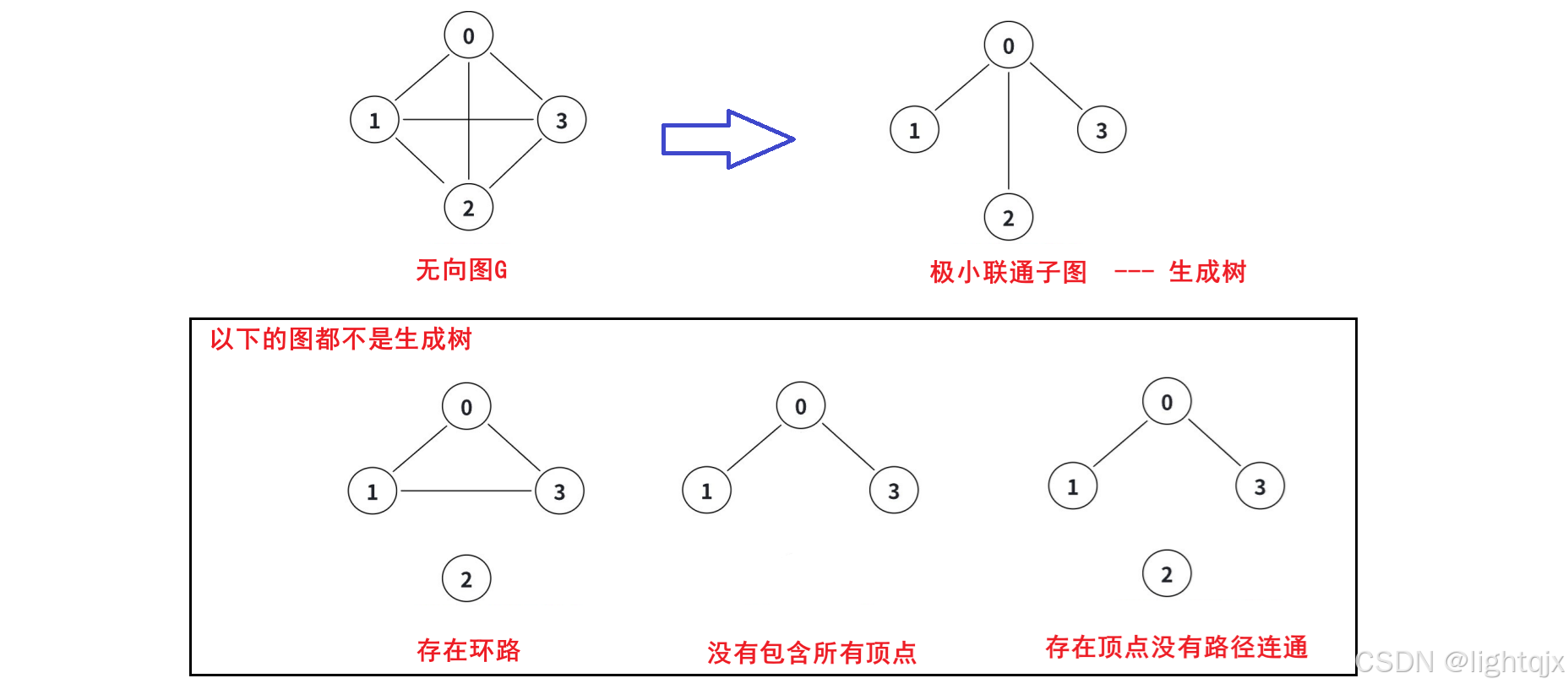
二、图的存储
图的存储有两种:邻接矩阵和邻接表。
1. 邻接矩阵
(1)理解原理
邻接矩阵存储方式的核心思想是使用一个二维数组来表示图中顶点之间的关系。
结构说明
如果有一个有n个顶点的图,则我们就需要创建一个 n * n 大小的二维数组 edges。然后我们就可以通过下标来表示顶点,比如 edges i j 就表示顶点 i 到顶点 j 之间的边(i指向j的边,即i -> j) 。所以
- 如果顶点 i 到顶点 j 之间存在一条边,如果它的权值为 w,则可以edges i j 的值设为 w(如果不带权图,则值可以设为 1) 。
- 如果如果顶点 i 到顶点 j 之间没有边,则edges i j 的值可以设为 ∞ 无穷大(有时常常设为 -1),表示这条边不存在。
关于无向图与有向图的存储区别
- 对于无向图,邻接矩阵是一个对称矩阵,因为边 i -> j 意味着 j -> i 也存在。
- 对于有向图,矩阵不一定对称,edges i j 则表示从 i 指向 j 的边。
存储结构如图所示: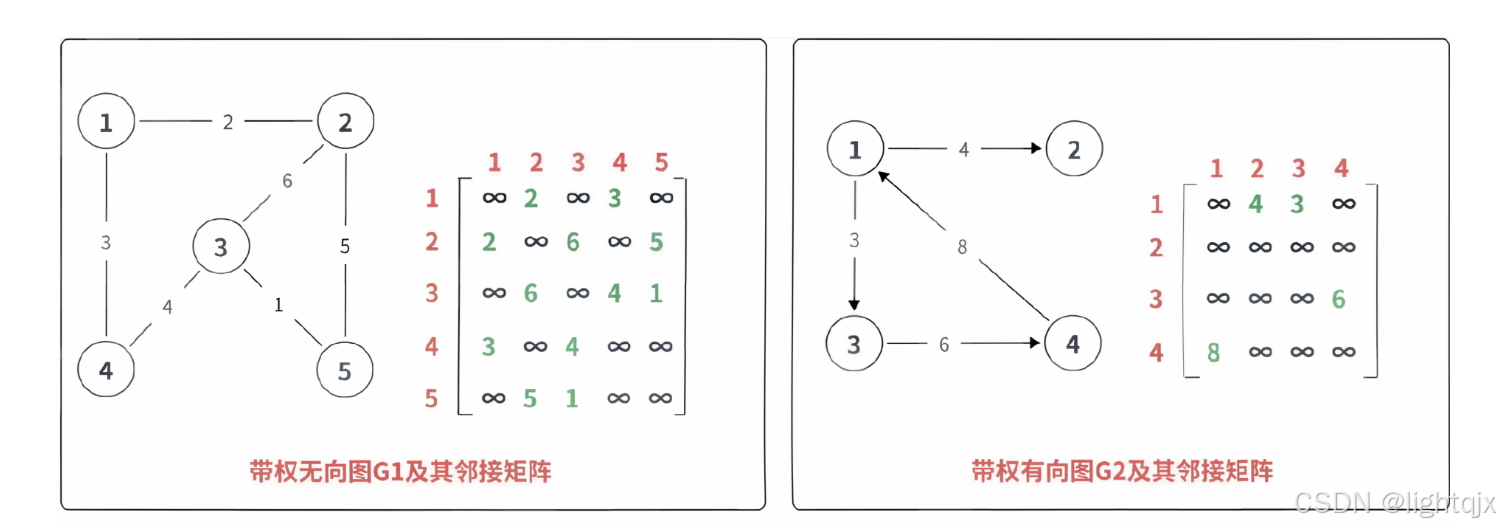
缺陷及适用情况
这种存储方法的时间复杂度和空间复杂度都是 ,但是它的缺陷就是空间上,因为无论图中有多少条边,都需要
的存储空间,对于稀疏图 (边数远小于
),则矩阵中会包含大量没有使用到的数据,造成严重的空间浪费 。所以当图中的边非常多,接近
时(即遇到稠密图),使用邻接矩阵就非常好。
(2)代码实现
C++实现代码:
cpp
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1e3 + 10;
int edges[N][N]; // 邻接矩阵存储
int n, m;
int main()
{
memset(edges, -1, sizeof edges); // -1表示没有边
cin >> n >> m; // 输入图的结点个数和边的个数
for(int i = 1; i <= m; i++)
{
int a, b , c; cin >> a >> b >> c;
// a->b有一条边,权值为c
edges[a][b] = c; // a->b有边
// 如果是无向图,则b->a也有边
edges[b][a] = c;
}
return 0;
} 2. 邻接表
(1)理解原理
邻接表存储的方法就是采用数组和链表相结合的方式,只为实际存在的边分配空间。
结构说明
如果有一个有n个顶点的图。
- 那么我们就需要使用一个大小为 n 的数组edges,数组的每个元素代表一个顶点。
- 该每个数组元素都指向一个链表(或列表),这个链表中存储了所有与该顶点直接相连的邻居顶点所包含的信息。比如,如果顶点 i 到顶点 j 之间有一条边,权值为 w ,则我们就需要在edgesi指向的链表后面添加一个存储 j 的节点信息(结点值为 j ,权值为 w),这样就表示出了 i - > j 之间存在一条权值为 w 的边。
对于无向图,对于一条边 i - j ,需要存储 i -> j,也需要存储 j -> i ;而对于有向图,对于有方向的边 i -> j ,则只需要存储 i -> j 即可。
如图所示:
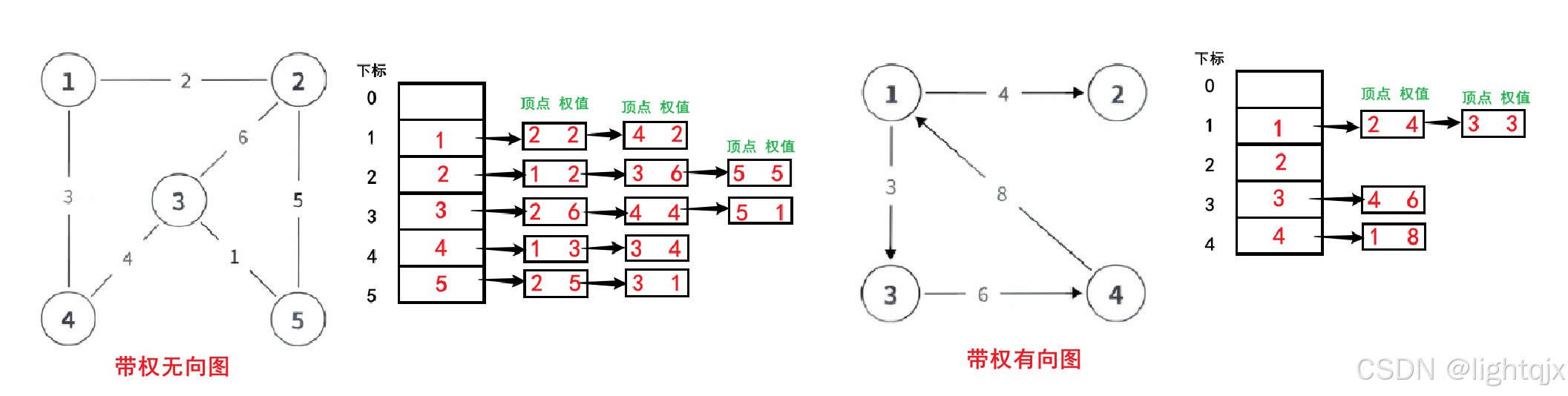
关于邻接表存储的代码,我们有两种方法:vector数组模拟存储和链式前向星(静态链表,数组模拟)实现。
(2)vector数组实现
通过一个vector<vector<int>> 来模拟实现。
如果有一个有n个顶点(顶点编号为1~n)的图。
- 如果不考虑边权,我们可以创建一个大小为 n + 1 的vector<vector<int>> 数组edges(这里开n+1是为了方便和顶点编号对应)。其中 edges i 中就保存着 i 号结点所连接的结点编号。
- 如果考虑边权 ,则还需要存储边权,那么就可以通过一个pair来存储顶点编号和边权。所以我们可以创建一个大小为 n + 1 的vector<vector<pair<int,int>>> 数组edges。其中 edges i 中就保存着 i 号结点所连接的结点编号和边权的结构。如图所示:
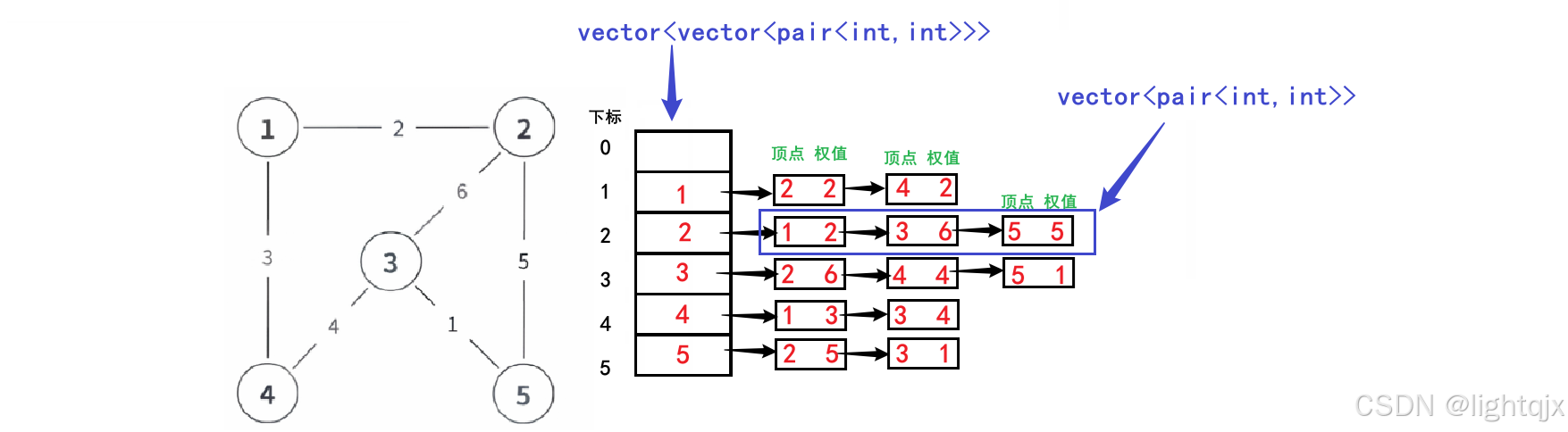
实现代码:
cpp
#include <iostream>
#include <vector>
using namespace std;
const int N = 1e3 + 10;
typedef pair<int, int> PII;
vector<PII> edges[N]; // 邻接表存储_vector数组
int n, m;
int main()
{
cin >> n >> m; // 输入图的结点个数和边的个数
for(int i = 1; i <= m; i++)
{
int a, b , c; cin >> a >> b >> c;
// a->b有一条边,权值为c
edges[a].push_back({b, c}); // a->b有边
// 如果是无向图,则b->a也有边
edges[b].push_back({a, c});
}
return 0;
} (3)静态链表存储(链式前向星)
核心思想是用数组模拟链表。
通过几个数组来实现,数组 h 表示所有顶点的边的哨兵位,hi 后面链接着编号为 i 的顶点的所有边的一个链表。
而我们的数据存储则是通过三个数组来维护的,如果有一条有向边 i -> j ,数组e则存储终点顶点的编号,w 存储权值,而ne表示的就是链接在它后面的节点下标 。存好之后,我们可以进行头插,将id对应的e和w的的位置插入到 h i 中。
如图所示:

看起来使用到的数组比较多,但是本质仍然是一个头数组,数组中每一个元素后都链接着一个以数组模拟的静态链表,链表中的元素都是以 i 为起点的终点顶点的节点。每次存一条边,都是通过id来分配空间的。所以 h 就是头数组,ej,wj,nej 三个一起就是一个节点。
实现代码为:
cpp
#include <iostream>
using namespace std;
const int N = 1e3 + 10;
// 邻接表存储_链式前向星(静态链表)
int h[N], e[N * 2], ne[N * 2], w[N * 2], id;
// h表示所有节点的哨兵位
// e和ne,表示数据域和指针域(配套使用);w表示权值
// id 标记新来结点的存储位置
int n, m;
// 把b头插到a所在的链表后面
void add(int a, int b, int c)
{
id++;
e[id] = b;
w[id] = c; // 存储权值
// 头插
ne[id] = h[a];
h[a] = id;
}
int main()
{
cin >> n >> m; // 输入图的结点个数和边的个数
for(int i = 1; i <= m; i++)
{
int a, b , c; cin >> a >> b >> c;
// a->b有一条边,权值为c
add(a, b, c); // a->b有边
// 如果是无向图,则b->a也有边
add(b, a, c);
}
return 0;
} 上述代码需要开2*N是因为对于无向图,我们需要存两次,所以需要两倍的空间。
三、图的遍历
图的遍历一般有两种方法: 深度优先搜索 (DFS) 和 广度优先搜索 (BFS)。
1. DFS
DFS的思路也很简单,对于一个图,就是:从起始顶点开始,沿着一条路径尽可能深地探索下去,直到无法继续前进,然后回溯到上一个顶点,继续探索其他未访问的分支,直到所有顶点都被访问。
如图所示: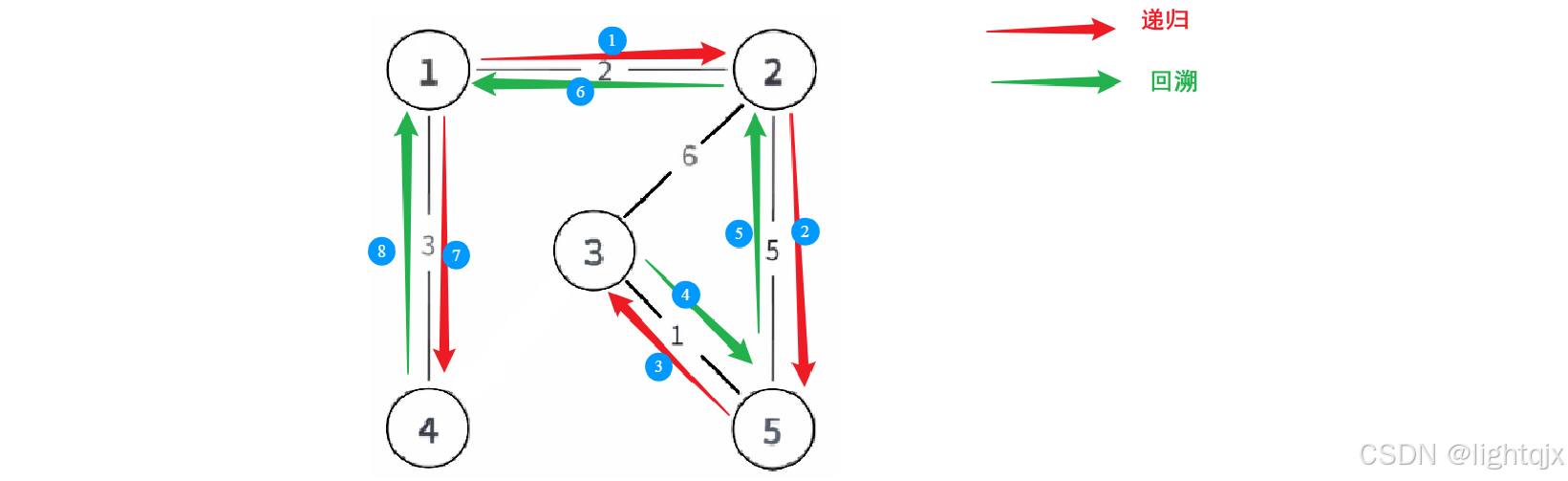
解释:从 节点 1 出发,依次访问 节点 2、节点 5,最终到达 节点 3。 在 节点 3 发现所有邻居都已被访问(无路可走),于是沿原路回退至 节点 5,再回退至 节点 2。在 节点 2 确认无新路径后,继续回退至 节点 1。 回到 节点 1 后,发现还有未访问的邻居 节点 4,于是前往访问,完成遍历。
代码实现有三种方法,对应与上面三种存储方法。代码如下(都是从编号为1的顶点喀什遍历的代码):
(1)邻接矩阵存储的遍历:
cpp
#include <iostream>
#include <cstring>
using namespace std;
const int N = 1e3 + 10;
int edges[N][N]; // 邻接矩阵存储
int n, m;
bool st[N]; // 用来标记哪些点以及访问过了
void dfs(int u)
{
cout << u << endl;
st[u] = true; // 标记访问过
// 遍历u结点的所有孩子
for(int v = 1; v <= n; v++)
{
// 如果存在边u->v,且没有遍历过
if(edges[u][v] != -1 && !st[v])
{
dfs(v); // 访问v
}
}
}
int main()
{
memset(edges, -1, sizeof edges); // -1表示没有边
cin >> n >> m; // 输入图的结点个数和边的个数
for(int i = 1; i <= m; i++)
{
int a, b , c; cin >> a >> b >> c;
// a->b有一条边,权值为c
edges[a][b] = c; // a->b有边
// 如果是无向图,则b->a也有边
edges[b][a] = c;
}
dfs(1); // 遍历
return 0;
} (2)邻接表,vector数组模拟存储的遍历:
cpp
#include <iostream>
#include <vector>
using namespace std;
const int N = 1e3 + 10;
typedef pair<int, int> PII;
vector<PII> edges[N]; // 邻接表存储_vector数组
int n, m;
bool st[N]; // 用来标记哪些点以及访问过了
void dfs(int u)
{
cout << u << endl;
st[u] = true;
// 遍历u后面的点
for(auto& t : edges[u])
{
// u->v有一条边,权值为w
int v = t.first, w = t.second;
if(!st[v])
{
dfs(v);
}
}
}
int main()
{
cin >> n >> m; // 输入图的结点个数和边的个数
for(int i = 1; i <= m; i++)
{
int a, b , c; cin >> a >> b >> c;
// a->b有一条边,权值为c
edges[a].push_back({b, c}); // a->b有边
// 如果是无向图,则b->a也有边
edges[b].push_back({a, c});
}
dfs(1);
return 0;
} (3)邻接表,链式前向星(即静态数组模拟实现)存储方式的遍历:
cpp
#include <iostream>
#include <vector>
using namespace std;
const int N = 1e3 + 10;
// 邻接表存储_链式前向星(静态链表)
int h[N], e[N * 2], ne[N * 2], w[N * 2], id;
int n, m;
// 把b头插到a所在的链表后面
void add(int a, int b, int c)
{
id++;
e[id] = b;
w[id] = c; // 存储权值
// 头插
ne[id] = h[a];
h[a] = id;
}
bool st[N]; // 用来标记哪些点以及访问过了
void dfs(int u)
{
cout << u << endl;
st[u] = true;
// 遍历u后面的点
for(int i = h[u]; i; i = ne[i])
{
// u->v有一条边
int v = e[i];
if(!st[v])
{
dfs(v);
}
}
}
int main()
{
cin >> n >> m; // 输入图的结点个数和边的个数
for(int i = 1; i <= m; i++)
{
int a, b , c; cin >> a >> b >> c;
// a->b有一条边,权值为c
add(a, b, c); // a->b有边
// 如果是无向图,则b->a也有边
add(b, a, c);
}
dfs(1);
return 0;
} 2. BFS
BFS的核心思想是"层层递进",思路为:它从起始顶点开始,先访问其所有相邻的顶点,然后再依次访问这些相邻顶点的邻居,像水波纹一样一圈圈向外扩散。实现这种遍历方法需要使用队列来实现。
实现代码:
(1)邻接矩阵存储的遍历:
cpp
#include <iostream>
#include <cstring>
#include <queue>
using namespace std;
const int N = 1e3 + 10;
int edges[N][N]; // 邻接矩阵存储
int n, m;
bool st[N]; // 用来标记哪些点以及访问过了
void bfs(int u)
{
queue<int> q;
q.push(u);
st[u] = true;
while(q.size())
{
auto a = q.front(); q.pop();
cout << a << endl;
// 将与a连接的点入队
for(int b = 1; b <= n; b++)
{
if(edges[a][b] != -1 && !st[b])
{
q.push(b);
st[b] = true;
}
}
}
}
int main()
{
memset(edges, -1, sizeof edges); // -1表示没有边
cin >> n >> m; // 输入图的结点个数和边的个数
for(int i = 1; i <= m; i++)
{
int a, b , c; cin >> a >> b >> c;
// a->b有一条边,权值为c
edges[a][b] = c; // a->b有边
// 如果是无向图,则b->a也有边
edges[b][a] = c;
}
bfs(1); // 遍历
return 0;
} (2)邻接表,vector数组模拟存储的遍历:
cpp
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
const int N = 1e3 + 10;
typedef pair<int, int> PII;
vector<PII> edges[N]; // 邻接表存储_vector数组
int n, m;
bool st[N]; // 用来标记哪些点以及访问过了
void bfs(int u)
{
queue<int> q;
q.push(u);
st[u] = true;
while(q.size())
{
auto a = q.front(); q.pop();
cout << a << endl;
for(auto& t : edges[a])
{
int b = t.first;
if(!st[b])
{
q.push(b);
st[b] = true;
}
}
}
}
int main()
{
cin >> n >> m; // 输入图的结点个数和边的个数
for(int i = 1; i <= m; i++)
{
int a, b , c; cin >> a >> b >> c;
// a->b有一条边,权值为c
edges[a].push_back({b, c}); // a->b有边
// 如果是无向图,则b->a也有边
edges[b].push_back({a, c});
}
bfs(1);
return 0;
}(3)邻接表,链式前向星(即静态数组模拟实现)存储方式的遍历:
cpp
#include <iostream>
#include <queue>
using namespace std;
const int N = 1e3 + 10;
// 邻接表存储_链式前向星(静态链表)
int h[N], e[N * 2], ne[N * 2], w[N * 2], id;
int n, m;
// 把b头插到a所在的链表后面
void add(int a, int b, int c)
{
id++;
e[id] = b;
w[id] = c; // 存储权值
// 头插
ne[id] = h[a];
h[a] = id;
}
bool st[N]; // 用来标记哪些点以及访问过了
void bfs(int u)
{
queue<int> q;
q.push(u);
st[u] = true;
while(q.size())
{
auto a = q.front(); q.pop();
cout << a << endl;
// 将与a连接的点入队
for(int i = h[a]; i; i = ne[i])
{
int b = e[i];
if(!st[b])
{
q.push(b);
st[b] = true;
}
}
}
}
int main()
{
cin >> n >> m; // 输入图的结点个数和边的个数
for(int i = 1; i <= m; i++)
{
int a, b , c; cin >> a >> b >> c;
// a->b有一条边,权值为c
add(a, b, c); // a->b有边
// 如果是无向图,则b->a也有边
add(b, a, c);
}
bfs(1);
return 0;
} 本文主要做认识图的初步理解。
最后感谢各位观看!希望能多多支持!