引言
在上一篇 B 树文章中,我们学习了一种为磁盘而生的多路搜索树。B 树能大幅降低树的高度,减少磁盘 I/O 次数。然而,真正在 MySQL、Oracle、SQLite 等数据库中广泛使用的,是 B 树的经典变体------B+ 树。
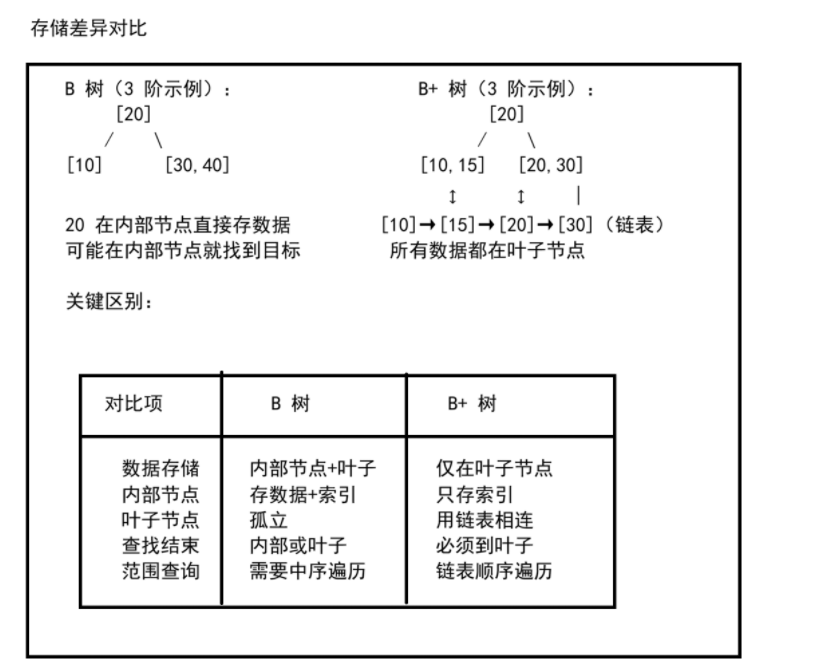
B+ 树在 B 树的基础上做了几个关键改进:所有数据只存储在叶子节点、叶子节点之间用链表连接、内部节点只存索引不存数据。这些改进让 B+ 树在范围查询和磁盘 I/O 效率上全面超越 B 树

第一部分:B+ 树的定义与结构
一、m 阶 B+ 树的五条性质

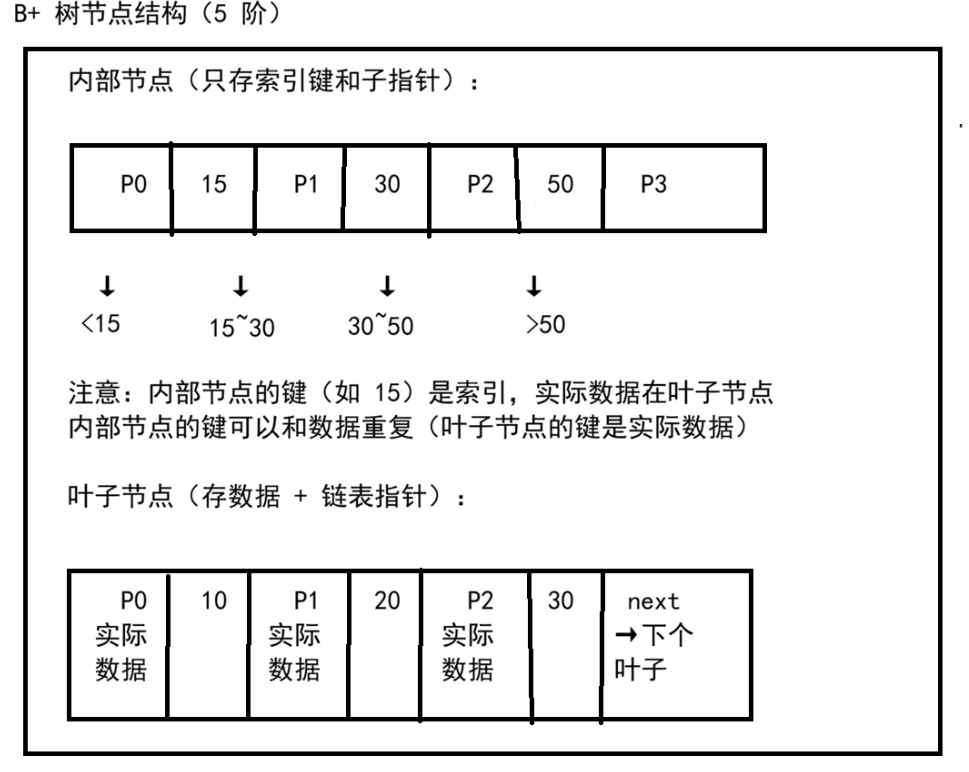
二、B+ 树的节点结构
第二部分:B+ 树 vs B 树深度对比
一、数据结构差异
二、同一棵树的容量差异

第三部分:B+ 树的操作
一、查找
B+ 树的查找必须走到叶子节点(即使内部节点有相同的键值,那也只是索引,实际数据在叶子中)。

二、插入
B+ 树的插入和 B 树类似,分裂时内部节点和叶子节点处理不同:

B 树 vs B+ 树分裂的关键区别:
| 对比项 | B 树分裂 | B+ 树分裂 |
|---|---|---|
| 中间键在叶子 | 上移后从原节点删除 | 上移后保留在叶子 |
| 中间键在内部节点 | 成为新数据 | 只是索引,叶子仍有副本 |
三、删除
B+ 树的删除和 B 树逻辑相同(借兄弟或合并),区别在于:内部节点的键只是索引,删除数据时内部节点的索引可以保留(它仍然能正确指引查找方向)。
第四部分:范围查询------B+ 树的核心优势
B+ 树的叶子节点通过链表相连,这是它相比 B 树最大的性能优势。

第五部分:MySQL InnoDB 中的 B+ 树
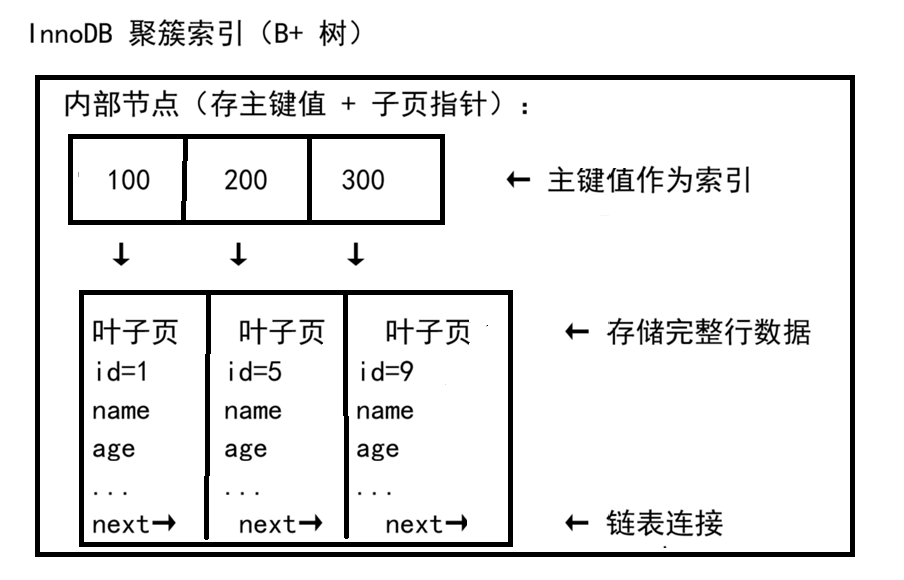
一、聚簇索引
MySQL InnoDB 的主键索引 就是一棵 B+ 树,叶子节点存储的是完整的行数据。
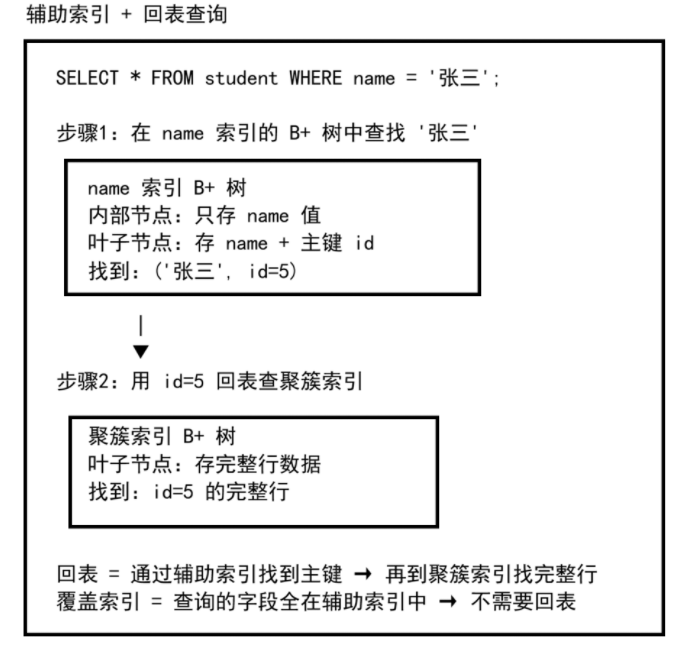
二、辅助索引与回表
辅助索引(非主键索引)也是一棵 B+ 树,但叶子节点只存索引列的值 + 主键值。
三、为什么 MySQL 选择 B+ 树而不是 B 树
| 原因 | 说明 |
|---|---|
| 范围查询更快 | 叶子链表直接顺序扫描,不需要中序遍历 |
| 内部节点更轻 | 只存索引不存数据 → 一页能存更多索引 → 树更矮 |
| 查询效率稳定 | 每次查询都必须走到叶子节点,时间稳定(B 树可能在内部节点就结束) |
| 磁盘 I/O 更少 | 树更矮 + 顺序扫描利用磁盘预读 |
第六部分:B+ 树完整代码实现
一、数据结构定义
cpp
#define MAX 4 // 每节点最多 4 个键(5 阶 B+ 树)
#define MIN 2 // 每节点最少 2 个键(除根)
typedef struct BPlusNode {
int keys[MAX]; // 键数组
struct BPlusNode* children[MAX + 1]; // 子指针(内部节点用)
struct BPlusNode* next; // 指向下一个叶子节点(叶子节点用)
int n; // 当前键的数量
int isLeaf; // 1=叶子,0=内部节点
} BPlusNode;
BPlusNode* root = NULL;二、查找
cpp
// 在 B+ 树中查找 key,返回叶子节点中的位置
BPlusNode* search(BPlusNode* node, int key) {
if (node == NULL) return NULL;
int i = 0;
while (i < node->n && key > node->keys[i]) i++;
if (node->isLeaf) {
// 叶子节点:直接判断是否找到
if (i < node->n && key == node->keys[i]) return node;
return NULL;
}
// 内部节点:继续向下查找
return search(node->children[i], key);
}三、分裂内部节点
cpp
void splitInternal(BPlusNode* parent, int idx, BPlusNode* child) {
BPlusNode* newChild = (BPlusNode*)malloc(sizeof(BPlusNode));
newChild->isLeaf = child->isLeaf;
newChild->next = NULL;
int mid = MAX / 2;
newChild->n = child->n - mid - 1;
// 复制右半部分的键
for (int j = 0; j < newChild->n; j++) {
newChild->keys[j] = child->keys[mid + 1 + j];
}
// 如果不是叶子,复制子指针
if (!child->isLeaf) {
for (int j = 0; j <= newChild->n; j++) {
newChild->children[j] = child->children[mid + 1 + j];
}
} else {
// 叶子节点:维护链表
newChild->next = child->next;
child->next = newChild;
}
int upKey = child->keys[mid]; // 上移到父节点的键
if (child->isLeaf) {
// ★ 叶子分裂:中间键保留在右叶子
newChild->keys[newChild->n] = upKey;
newChild->n++;
// 重新调整
for (int j = 0; j < newChild->n; j++) {
newChild->keys[j] = child->keys[mid + j];
}
child->n = mid;
} else {
child->n = mid;
}
// 父节点插入上移的键
for (int j = parent->n; j > idx; j--) {
parent->keys[j] = parent->keys[j - 1];
parent->children[j + 1] = parent->children[j];
}
parent->keys[idx] = upKey;
parent->children[idx + 1] = newChild;
parent->n++;
}四、插入
cpp
void insertNonFull(BPlusNode* node, int key) {
int i = node->n - 1;
if (node->isLeaf) {
// 叶子节点:找到位置直接插入
while (i >= 0 && key < node->keys[i]) {
node->keys[i + 1] = node->keys[i];
i--;
}
node->keys[i + 1] = key;
node->n++;
} else {
// 内部节点:找到子节点
while (i >= 0 && key < node->keys[i]) i--;
i++;
if (node->children[i]->n == MAX) {
splitInternal(node, i, node->children[i]);
if (key > node->keys[i]) i++;
}
insertNonFull(node->children[i], key);
}
}
BPlusNode* insert(int key) {
if (root == NULL) {
root = (BPlusNode*)malloc(sizeof(BPlusNode));
root->keys[0] = key;
root->n = 1;
root->isLeaf = 1;
root->next = NULL;
return root;
}
if (root->n == MAX) {
BPlusNode* newRoot = (BPlusNode*)malloc(sizeof(BPlusNode));
newRoot->isLeaf = 0;
newRoot->n = 0;
newRoot->children[0] = root;
splitInternal(newRoot, 0, root);
root = newRoot;
}
insertNonFull(root, key);
return root;
}五、范围查询
cpp
// 从第一个 ≥ start 的叶子开始,遍历到 > end 停止
void rangeQuery(BPlusNode* node, int start, int end) {
if (node == NULL) return;
// 找到起始叶子
BPlusNode* cur = node;
while (!cur->isLeaf) {
int i = 0;
while (i < cur->n && start > cur->keys[i]) i++;
cur = cur->children[i];
}
// 顺着链表输出
printf("范围 [%d, %d]: ", start, end);
while (cur != NULL) {
for (int i = 0; i < cur->n; i++) {
if (cur->keys[i] > end) {
printf("\n");
return;
}
if (cur->keys[i] >= start) {
printf("%d ", cur->keys[i]);
}
}
cur = cur->next;
}
printf("\n");
}六、打印 B+ 树
cpp
void printTree(BPlusNode* node, int level) {
if (node == NULL) return;
printf("Level %d [", level);
for (int i = 0; i < node->n; i++) {
printf("%d", node->keys[i]);
if (i < node->n - 1) printf(" ");
}
if (node->isLeaf) {
printf("] (leaf, next→%s)\n", node->next ? "有" : "NULL");
} else {
printf("]\n");
for (int i = 0; i <= node->n; i++) {
printTree(node->children[i], level + 1);
}
}
}七、测试
cpp
int main() {
int arr[] = {10, 20, 5, 6, 12, 30, 7, 17, 25, 3, 8, 15};
int n = sizeof(arr) / sizeof(arr[0]);
printf("插入序列:");
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
root = insert(arr[i]);
}
printf("\n\n");
printf("B+ 树结构:\n");
printTree(root, 0);
printf("\n范围查询:\n");
rangeQuery(root, 8, 25);
return 0;
}第七部分:B 树 vs B+ 树 总结
| 对比项 | B 树 | B+ 树 |
|---|---|---|
| 数据存储位置 | 内部节点 + 叶子节点 | 仅叶子节点 |
| 内部节点内容 | 数据 + 索引 | 仅索引(更轻) |
| 叶子节点关系 | 相互独立 | 链表相连 |
| 查找结束位置 | 可能在内部节点 | 必须到叶子 |
| 范围查询 | 中序遍历 O(n log n) | 链表扫描 O(n) |
| 树高 | 较高 | 更矮(每页索引多) |
| 插入/删除 | 相同复杂度 | 分裂时中间键保留在叶子 |
| 实际应用 | 文件系统 | 数据库索引 |
总结
一、B+ 树的核心改进

二、一句话记忆
B+ 树是 B 树的经典变体,内部节点只做索引不存数据(更轻更矮),所有数据在叶子节点,叶子之间用链表连接(范围查询直接顺序扫描),是 MySQL InnoDB 聚簇索引和辅助索引的底层实现。