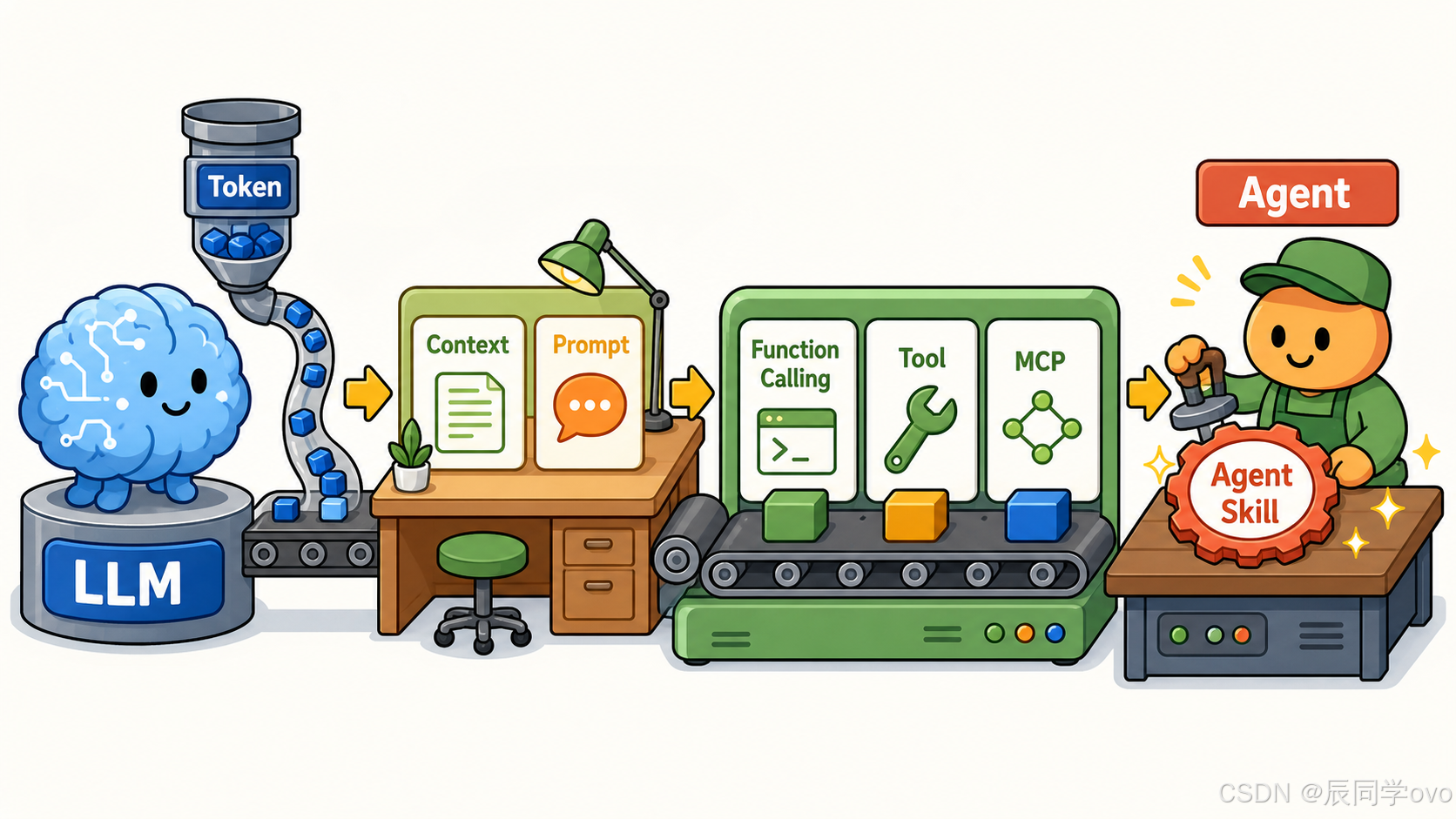
你可能已经听过 Agent,也可能已经用过一些 AI 编程工具,比如 Cursor、Claude Code 或 Codex。
但很多时候,我们对 Agent 的理解会停在一句话上:它能自己规划任务、调用工具、完成工作。
这句话没错,但还不够。因为一旦继续追问,问题就会变多:Agent 调用工具时到底发生了什么?Function Calling 和 Tool 是一回事吗?MCP 为什么突然变得重要?Agent Skill 又和普通 Prompt 有什么区别?
这些概念如果分开看,很容易越看越乱;但如果把它们放到同一条链路里,就会清楚很多:
LLM 大语言模型
Token 信息单位
Context 上下文
Prompt 提示词
Function Calling 结构化调用
Tool 外部工具
MCP 工具接入标准
Agent 多步执行
Agent Skill 可复用能力
理解这条链路之后,再看Agent,很多概念就不会显得那么碎片化。
1. LLM:AI 应用的基础大脑
LLM,也就是大语言模型,是整个 AI 应用的基础。它的核心能力是理解和生成自然语言。
表面上,我们是在和模型聊天;但从底层看,模型其实是在根据已有输入预测下一个最可能出现的 Token。也就是说,它并不是像数据库一样"查询答案",而是基于训练中学到的语言模式、知识结构和上下文信息进行生成。
所以,LLM 很强,但它不是万能的。它可以推理、总结、改写、生成代码,但它本身并不会主动访问网页、读取本地文件、查询数据库或执行真实操作。
这样的弊端促使了后面 Tool、Function Calling、Agent 等概念出现。
2. Token:模型处理信息的基本单位
模型并不是直接理解人类看到的"字"或"词",而是通过 Tokenizer 把文本切分成 Token,再转换成数字进行处理。
Token 可以理解为模型眼里的最小信息单位。它可能是一个字、一个词,也可能是半个词或一段符号。不同模型的 Tokenizer 规则也不完全一样。
Token 之所以重要,是因为它直接影响三个问题:
第一,输入和输出的成本通常按 Token 计算。
第二,模型一次能处理的信息量有上限。
第三,长文本任务、代码分析、文档问答等场景都绕不开 Token 管理。
所以,所谓"上下文太长""模型忘了前面内容""文档塞不进去",很多时候本质上都是 Token 和容纳Token的上下文窗口的容量的问题。
3. Context:模型当前能看到的一切
Context,中文常说"上下文",指的是模型在当前这次推理中能够看到的全部信息。
它不只是用户刚刚输入的一句话,还可能包括:
历史对话
系统提示词
当前用户问题
工具说明
函数定义
...
所以说,大模型并没有真正意义上的长期记忆。它能不能"记得",取决于相关信息有没有被放进当前 Context 里。
Context Window 则是模型一次最多能容纳多少 Token 的上限。窗口越大,模型能看到的信息越多,但成本也越高,处理难度也越大。
这也是为什么 RAG、摘要压缩、记忆管理、上下文工程会变得重要。它们的目标都是:在有限的上下文窗口里,放入最有价值的信息。
4. Prompt:控制模型行为的入口
Prompt 不只是用户输入的问题,而是模型执行任务的指令集合。
通常可以分成两类:
text
User Prompt:用户当前输入的问题或任务
System Prompt:系统层面对模型角色、规则、边界和输出格式的约束比如用户输入"帮我写一篇博客",这是 User Prompt。
而系统要求模型"用中文回答、保持简洁、不要编造信息",这就是 System Prompt 的作用。
Prompt 的价值在于,它把人的意图转化为模型可以执行的任务描述。一个好的 Prompt 不一定要很长,但应该清楚说明目标、背景、限制和输出格式。
不过,Prompt 只能告诉模型"怎么想、怎么说"。如果任务需要真实执行,比如查天气、读文件、调用数据库,就需要进入下一层:Function Calling 和 Tool。
5. Function Calling:让模型结构化地表达工具调用意图
Function Calling 是我认为这条链路里非常关键、但经常被忽略的一环。
大模型本身不会真正执行函数。它能做的是:根据当前上下文判断是否需要调用某个函数,并以结构化格式告诉外部系统"我要调用哪个函数、参数是什么"。
举个例子,如果用户问:
text
明天杭州会下雨吗?模型可能判断自己需要查询天气,于是输出类似这样的结构化调用:
json
{
"name": "get_weather",
"arguments": {
"city": "杭州",
"date": "tomorrow"
}
}真正去调用天气 API 的不是模型,而是宿主程序。宿主程序执行函数后,再把结果返回给模型,模型最后把结果整理成人能读懂的回答。
Tool/API 宿主程序 LLM 用户 Tool/API 宿主程序 LLM 用户 提出问题 输出 Function Call JSON 执行真实工具调用 返回工具结果 把结果放回上下文 生成最终回答
所以,Function Calling 的定位可以这样理解:
text
Function Calling 是模型调用工具时的结构化表达方式。
Tool 是真正被调用的外部能力。没有 Function Calling,模型可能只能用自然语言说"我需要查天气"。
有了 Function Calling,系统就能稳定解析模型意图,并执行对应函数。
这让大模型从"会说"进一步走向"会用工具"。
6. Tool:让模型连接外部世界
Tool,也就是工具,是外部能力的封装。
它可以是一个 API、一个数据库查询函数、一个文件读取器、一个搜索接口,也可以是代码执行器、浏览器、邮件发送器、表格处理器等。
LLM 本身的局限在于,它无法直接感知实时世界,也无法自己完成真实操作。Tool 弥补了这个缺口。
可以这样理解:
text
LLM 负责判断和生成
Function Calling 负责表达调用意图
Tool 负责执行真实动作例如,一个 AI 助手要完成"帮我整理最近一周的销售数据并生成图表",它可能需要调用文件读取工具、数据分析工具、图表生成工具,最后再由模型总结结果。
Tool 让 AI 从单纯的文本生成器,变成可以参与真实工作流的系统。
7. MCP:统一工具接入方式
当工具越来越多,新的问题出现了:不同模型、不同平台、不同 Agent 如果都要单独适配工具,开发成本会非常高。
MCP,也就是 Model Context Protocol,解决的是工具接入标准化的问题。
可以把 MCP 类比成一种统一接口。过去你要给不同 AI 平台分别写不同的工具接入代码;有了 MCP,就可以用统一协议描述工具,让支持 MCP 的客户端或 Agent 更容易调用这些工具。
它解决的不是"模型会不会调用工具",而是"工具如何以标准方式暴露给模型或 Agent"。
所以 MCP 在链路中的位置大致是:
text
Function Calling 解决调用表达
Tool 提供具体能力
MCP 解决工具接入标准化这也是为什么 MCP 会成为 Agent 生态里的重要基础设施。
8. Agent:从回答问题到完成任务
Agent 和普通聊天机器人的区别在于,它不只是回答一次问题,而是能围绕目标进行多步行动。
一个 Agent 通常具备这样的能力:
否
是
理解目标
制定计划
调用工具
观察结果
是否完成?
输出结果
举个例子:
比如用户说:"帮我调研三个竞品,并整理成一份对比报告。"
普通 LLM 可能直接根据已有知识生成一份回答。
Agent 则可能先搜索资料,再读取网页,再提取信息,再对比维度,最后生成报告。
也就是说,Agent 的关键不只是"调用工具",而是能围绕任务持续决策和执行。
9. Agent Skill:把经验沉淀成可复用能力
Agent Skill 是在 Agent 之上的进一步封装。
如果说 Tool 解决的是"能做什么",那么 Skill 解决的是"怎么把某类事情做好"。
例如,写博客变成一种 Skill的话,它里面可以规定:
text
如何理解素材
如何提炼主题
如何组织结构
如何控制语气
如何生成标题
如何输出 Markdown这样每次用户要求写博客时,Agent 不需要重新从零理解流程,而是可以加载对应 Skill,按照预先定义好的方法执行。
Agent Skill 的意义在于,它把经验、流程、规范和输出格式沉淀下来,让 Agent 在特定场景下表现得更稳定、更专业。
这也是 AI 应用从"通用助手"走向"专业工作流"的关键一步。
10. 总结:真正重要的是系统设计
LLM 当然重要,但一个真正可用的 AI 应用,不只是一个模型,而是一套系统:
text
LLM 提供基础智能
Token 决定信息处理方式
Context 决定模型能看到什么
Prompt 决定模型如何行动
Function Calling 让模型结构化表达工具调用
Tool 让模型获得外部能力
MCP 让工具接入标准化
Agent 让系统具备多步执行能力
Agent Skill 让经验和流程可以复用从这个角度看,AI 应用开发的核心,已经不只是"选哪个模型",而是如何组织上下文、设计工具、定义协议、规划任务流程,并把高频场景沉淀为 Skill。
总结来说:聊天只是入口,工具是能力扩展,Agent 是执行框架,而 Skill 是专业化和规模化的关键。