向量检索技术与相似度算法:深度解析 ANN 索引
前言
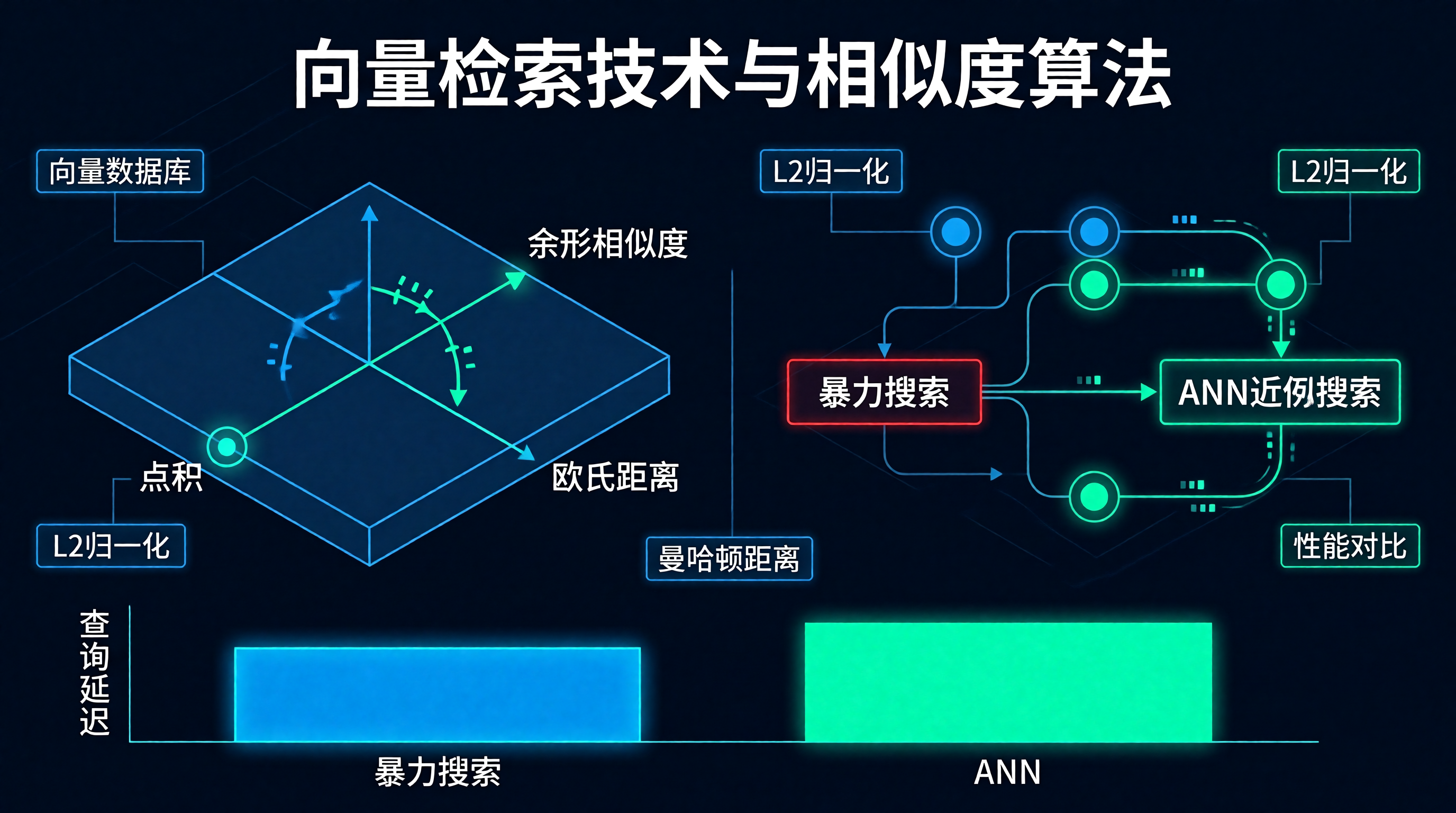
向量检索是 RAG系统和语义搜索的核心技术。当我们需要从海量向量中找到与查询最相似的结果时,精确的 KNN(K-Nearest Neighbors)搜索在数据量大时会变得极其缓慢。近似最近邻(ANN,Approximate Nearest Neighbors)算法通过允许一定的精度损失,换取了大幅的性能提升。
我之前在项目中对比测试了多种向量检索算法和向量数据库,对这些技术有了深入理解。今天分享一些核心原理和实战经验。
向量相似度度量
常用距离度量
python
import numpy as np
def cosine_similarity(a: np.ndarray, b: np.ndarray) -> float:
"""余弦相似度:[-1, 1],1 表示完全相同"""
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
def euclidean_distance(a: np.ndarray, b: np.ndarray) -> float:
"""欧氏距离:[0, +∞),0 表示完全相同"""
return np.linalg.norm(a - b)
def dot_product(a: np.ndarray, b: np.ndarray) -> float:
"""点积:未归一化,适用于已归一化的向量"""
return np.dot(a, b)
def manhattan_distance(a: np.ndarray, b: np.ndarray) -> float:
"""曼哈顿距离:[0, +∞)"""
return np.sum(np.abs(a - b))
# 选择建议
"""
- 余弦相似度:最常用,关注方向而非大小
- 欧氏距离:关注绝对差异,适合图像特征
- 点积:计算最快,但需要向量已归一化
"""内积与余弦的关系
python
# 对于 L2 归一化的向量:
# cosine_similarity(a, b) = dot_product(a, b)
def normalize_l2(x: np.ndarray) -> np.ndarray:
"""L2 归一化"""
norm = np.linalg.norm(x, axis=-1, keepdims=True)
return x / (norm + 1e-8) # 避免除零ANN 算法详解
1. 暴力搜索(Brute Force)
python
def brute_force_search(
query: np.ndarray,
database: np.ndarray,
k: int
) -> tuple:
"""暴力搜索(基准方法)"""
# 计算所有距离
distances = np.linalg.norm(database - query, axis=1)
# 找 top-k
top_k_idx = np.argsort(distances)[:k]
return top_k_idx, distances[top_k_idx]
# 时间复杂度:O(N * D),N 为向量数,D 为维度
# 优点:精确、无额外内存
# 缺点:慢2. LSH(Locality-Sensitive Hashing)
LSH 通过哈希函数将相似的向量映射到相同的"桶":
python
class LSH:
"""LSH 近似最近邻"""
def __init__(self, num_hash_tables: int = 8, hash_size: int = 12):
self.num_hash_tables = num_hash_tables
self.hash_size = hash_size
self.hash_tables = [defaultdict(list) for _ in range(num_hash_tables)]
self.random_planes = None
def _init_planes(self, dim: int):
"""初始化随机超平面"""
np.random.seed(42)
self.random_planes = [
np.random.randn(self.hash_size, dim)
for _ in range(self.num_hash_tables)
]
def _hash(self, vectors: np.ndarray, planes: np.ndarray) -> np.ndarray:
"""计算哈希值"""
projections = vectors @ planes.T # (N, hash_size)
return (projections > 0).astype(int)
def fit(self, vectors: np.ndarray):
"""构建索引"""
self._init_planes(vectors.shape[1])
for i, planes in enumerate(self.random_planes):
hashes = self._hash(vectors, planes)
for j, h in enumerate(hashes):
bucket_key = tuple(h)
self.hash_tables[i][bucket_key].append(j)
def search(self, query: np.ndarray, k: int = 10) -> list:
"""搜索"""
candidates = set()
for planes in self.random_planes:
h = tuple(self._hash(query, planes)[0])
candidates.update(self.hash_tables[planes.index(planes)][h])
# 在候选集中暴力搜索
return list(candidates)[:k]3. HNSW(Hierarchical Navigable Small World)
HNSW 是目前最流行的 ANN 算法:
python
class HNSWNode:
"""HNSW 节点"""
def __init__(self, vector: np.ndarray, id: int):
self.vector = vector
self.id = id
self.connections = {} # level -> [node_ids]
self.entry_point = None
class HNSW:
"""HNSW 实现"""
def __init__(
self,
m: int = 16, # 节点最大连接数
ef_construction: int = 200, # 构建时搜索范围
max_level: int = 16
):
self.m = m
self.ef_construction = ef_construction
self.max_level = max_level
self.nodes = {}
self.entry_point = None
self.top_level = 0
def _distance(self, a: np.ndarray, b: np.ndarray) -> float:
"""欧氏距离"""
return np.linalg.norm(a - b)
def _search_layer(
self,
query: np.ndarray,
ep: int,
ef: int,
level: int
) -> list:
"""单层搜索"""
visited = {ep}
candidates = [(self._distance(query, self.nodes[ep].vector), ep)]
result = [(self._distance(query, self.nodes[ep].vector), ep)]
while candidates:
dist, current = heapq.heappop(candidates)
# 获取结果中的最远距离
result_dist = result[0][0] if len(result) >= ef else float('inf')
if dist > result_dist:
break
# 遍历邻居
for neighbor_id in self.nodes[current].connections.get(level, []):
if neighbor_id in visited:
continue
visited.add(neighbor_id)
dist = self._distance(query, self.nodes[neighbor_id].vector)
if dist < result_dist or len(result) < ef:
heapq.heappush(candidates, (dist, neighbor_id))
heapq.heappushpop(result, (dist, neighbor_id))
return result
def _select_neighbors(
self,
query: np.ndarray,
node_id: int,
level: int,
m: int
) -> list:
"""选择最近的 m 个邻居"""
neighbors = self.nodes[node_id].connections.get(level, [])
distances = [
(self._distance(query, self.nodes[n].vector), n)
for n in neighbors
]
return [n for _, n in heapq.nsmallest(m, distances)]
def insert(self, vector: np.ndarray, id: int):
"""插入向量"""
# 随机选择层级(指数衰减)
level = int(np.random.exponential(self.max_level - 1))
level = min(level, self.top_level + 1)
# 创建节点
self.nodes[id] = HNSWNode(vector, id)
# 如果是第一个节点
if self.entry_point is None:
self.nodes[id].level = level
self.entry_point = id
self.top_level = level
return
# 从顶层向下搜索
ep = self.entry_point
for l in range(self.top_level, level, -1):
ep = self._search_layer(
vector, ep, 1, l
)[0][1]
# 从 level 层开始插入
for l in range(level, -1, -1):
neighbors = self._search_layer(vector, ep, self.ef_construction, l)
ep = neighbors[0][1]
# 更新连接
selected = self._select_neighbors(vector, ep, l, self.m)
self.nodes[ep].connections.setdefault(l, []).extend(selected)
# 限制连接数
if len(self.nodes[ep].connections[l]) > self.m:
self.nodes[ep].connections[l] = self._select_neighbors(
vector, ep, l, self.m
)
def search(self, query: np.ndarray, k: int = 10) -> list:
"""搜索"""
ep = self.entry_point
# 从顶层向下找到入口点
for l in range(self.top_level, 0, -1):
ep = self._search_layer(query, ep, 1, l)[0][1]
# 最底层搜索
results = self._search_layer(query, ep, k, 0)
return [(id, dist) for dist, id in sorted(results, key=lambda x: x[0])[:k]]4. IVF(Inverted File Index)
IVF 通过聚类将向量空间划分:
python
class IVF:
"""倒排索引"""
def __init__(self, nlist: int = 100, nprobe: int = 10):
self.nlist = nlist
self.nprobe = nprobe
self.centroids = None
self.inverted_index = defaultdict(list)
def fit(self, vectors: np.ndarray):
"""构建索引"""
# K-Means 聚类
from sklearn.cluster import MiniBatchKMeans
kmeans = MiniBatchKMeans(n_clusters=self.nlist, random_state=42)
kmeans.fit(vectors)
self.centroids = kmeans.cluster_centers_
labels = kmeans.labels_
# 构建倒排索引
for i, label in enumerate(labels):
self.inverted_index[label].append(i)
def search(self, query: np.ndarray, k: int = 10) -> list:
"""搜索"""
# 1. 找到最近的 nprobe 个聚类中心
distances = np.linalg.norm(self.centroids - query, axis=1)
nearest_clusters = np.argsort(distances)[:self.nprobe]
# 2. 在这些聚类中搜索
all_candidates = []
for cluster_id in nearest_clusters:
all_candidates.extend(self.inverted_index[cluster_id])
# 3. 暴力搜索候选集
# (实际实现需要获取向量并计算距离)
results = [(id, 0.0) for id in all_candidates[:k]]
return results主流向量数据库对比
| 数据库 | 索引类型 | 优势 | 劣势 |
|---|---|---|---|
| Milvus | HNSW, IVF, PQ | 功能全面 | 资源占用大 |
| Qdrant | HNSW | 性能好 | 相对较新 |
| Weaviate | HNSW | 混合搜索 | 文档复杂 |
| Pinecone | 闭源 | 托管方便 | 成本高 |
| Chroma | HNSW (近似) | 轻量易用 | 不适合生产 |
索引参数调优
HNSW 参数
python
# HNSW 配置建议
hnsw_config = {
"M": 16, # 建议范围 8-64
# M 越大,召回率越高,但内存和构建时间也越大
"efConstruction": 200, # 建议范围 100-400
# 构建时的搜索范围,越大索引质量越好,但构建越慢
"efSearch": 100, # 建议范围 50-400
# 搜索时的搜索范围,越大召回率越高,但延迟也越高
"distance_type": "COSine" # 或 "EUCLIDEAN"
}
# 调优建议
"""
1. 召回率优先 → 提高 M 和 efSearch
2. 延迟优先 → 降低 M 和 efSearch
3. 内存受限 → 降低 M 或使用 PQ
"""PQ 参数
python
pq_config = {
"M": 64, # 子空间数,通常设为 64 或 96
"bits": 8, # 每子空间位数,通常为 8
# 参数影响
# - M * bits 越小,压缩率越高,精度越低
# - M 越大,精度越高,但索引越大
}实战建议
选择合适的索引
python
def select_index_type(data_size: int, dim: int, requirement: str) -> str:
"""根据需求选择索引类型"""
if requirement == "highest_recall":
return "HNSW"
if requirement == "low_memory":
return "PQ"
if requirement == "balanced":
return "HNSW + PQ"
if requirement == "fast_build":
return "IVF"
return "HNSW" # 默认选择性能优化技巧
python
class VectorSearchOptimizer:
"""向量搜索优化"""
@staticmethod
def batch_search_optimization():
"""批量搜索优化"""
# 1. 使用批量接口而非循环单次查询
# 2. 减少 Python GIL 影响
# 3. 使用异步 I/O
pass
@staticmethod
def memory_optimization():
"""内存优化"""
# 1. 使用内存映射文件
# 2. 量化向量
# 3. 及时清理不需要的数据
pass总结
向量检索的核心是 ANN 算法:
- HNSW:目前最流行,性能和召回率平衡好
- LSH:适合稀疏向量或需要精确哈希的场景
- IVF:基于聚类,适合大规模数据
- PQ:高压缩率,适合内存受限场景
关键要点:
- 相似度度量选余弦相似度最通用
- HNSW 是首选索引类型
- 参数调优需要在精度和性能间平衡
- 根据数据规模和硬件选择合适的方案