文章目录
- [1. 概述](#1. 概述)
- [2. 核心常量](#2. 核心常量)
- [3. 成员变量](#3. 成员变量)
-
- [3.1 name](#3.1 name)
- [3.2 Nodes](#3.2 Nodes)
- [3.3 Edges](#3.3 Edges)
- [3.4 KeyStrategyFactory](#3.4 KeyStrategyFactory)
- [3.5 StateSerializer](#3.5 StateSerializer)
- [4. 核心方法](#4. 核心方法)
-
- [4.1 添加节点](#4.1 添加节点)
- [4.2 添加边](#4.2 添加边)
- [4.3 图校验](#4.3 图校验)
- [4.4 编译为执行图](#4.4 编译为执行图)
- [4.5 可视化生成](#4.5 可视化生成)
1. 概述
StateGraph 是状态图(工作流)的定义层 ,核心职责:
- 声明工作流的节点、边、配置,不负责执行;
- 最终通过
compile()方法编译为可执行的CompiledGraph。
2. 核心常量
源码中定义了 5 个常量,表示工作流的固定入口/出口/钩子:
java
public static final String END = "__END__"; // 流程终止节点
public static final String START = "__START__";// 流程起始节点
public static final String ERROR = "__ERROR__";// 全局错误节点
public static final String NODE_BEFORE = "__NODE_BEFORE__"; // 节点前置钩子
public static final String NODE_AFTER = "__NODE_AFTER__"; // 节点后置钩子3. 成员变量
java
// 1. 节点容器:存储所有 Node 组件(核心)
final Nodes nodes = new Nodes();
// 2. 边容器:存储所有 Edge 组件(核心)
final Edges edges = new Edges();
// 3. 状态合并策略工厂:管理 OverAllState 的数据合并规则
private final KeyStrategyFactory keyStrategyFactory;
// 4. 状态序列化器:负责 OverAllState 的序列化/持久化
private final StateSerializer stateSerializer;
// 5. 图名称
private final String name;3.1 name
状态图的名称。
java
/**
* Name of the graph.
*/
private final String name;3.2 Nodes
Nodes 是 StateGraph 中的静态内部类,本质是节点容器 ,内部维护了一个 LinkedHashSet 负责统一封装、存储和操作图中的所有 Node 。
核心方法:
| 方法 | 核心用途 | 调用时机 |
|---|---|---|
anyMatchById(String id) |
校验节点 ID 是否重复 |
StateGraph.addNode() 添加节点时 |
onlySubStateGraphNodes() |
获取所有嵌套子图节点 | 图编译时,递归编译子图 |
exceptSubStateGraphNodes() |
获取所有普通业务节点 | 图执行时,调度节点运行 |
完整源码:
java
public static class Nodes {
/**
* 节点集合:使用 LinkedHashSet 存储(有序 + 唯一)
* final 保证集合引用不可变,只能增删元素,不能替换集合
*/
public final Set<Node> elements;
/**
* 带参构造:传入已有节点集合,初始化 LinkedHashSet
* 保证节点【去重 + 保持插入顺序】
*/
public Nodes(Collection<Node> elements) {
this.elements = new LinkedHashSet<>(elements);
}
/**
* 无参构造:初始化空的 LinkedHashSet
*/
public Nodes() {
this.elements = new LinkedHashSet<>();
}
/**
* 根据节点 ID,判断容器中是否已存在该节点
* 用于:添加节点时的【重复校验】
*/
public boolean anyMatchById(String id) {
return elements.stream().anyMatch(n -> Objects.equals(n.id(), id));
}
/**
* 过滤出所有【子图节点】(SubStateGraphNode)
* 用于:编译时处理嵌套子图
*/
public List<SubStateGraphNode> onlySubStateGraphNodes() {
return elements.stream()
.filter(n -> n instanceof SubStateGraphNode) // 筛选子图节点
.map(n -> (SubStateGraphNode) n) // 类型强转
.toList(); // 转为不可变 List
}
/**
* 过滤出所有【普通节点】(排除子图节点)
* 用于:执行时调度普通业务节点
*/
public List<Node> exceptSubStateGraphNodes() {
return elements.stream().filter(n -> !(n instanceof SubStateGraphNode)).toList();
}
}Node 表示图中的一个节点,该节点具备唯一标识,同时拥有一个动作工厂方法(ActionFactory ),用于创建当前节点待执行的动作。
核心成员/方法:
| 成员/方法 | 核心作用 | 使用场景 |
|---|---|---|
PRIVATE_PREFIX = "__" |
系统保留前缀 | 禁止用户自定义节点占用 |
ActionFactory |
延迟创建执行动作 | 编译时生成节点逻辑 |
id |
节点唯一标识 | 路由、去重、校验 |
validate() |
节点合法性校验 | StateGraph 编译前调用 |
isParallel() |
是否并行节点 | 执行器判断是否并行调度 |
equals/hashCode |
节点唯一性判断 | Nodes 容器自动去重 |
Node 和 NodeAction 的核心区别:
| 对比维度 | Node(图节点) | NodeAction(节点动作) |
|---|---|---|
| 本质定位 | 流程结构载体、状态图中的点位 | 节点业务逻辑、可执行异步行为 |
| 核心职责 | 持有唯一ID、参与构图、流程跳转、容纳动作 | 定义节点具体要做的异步任务逻辑 |
| 是否含业务 | 无业务逻辑,只做结构定义 | 承载具体业务:接口调用、计算、流程判断等 |
| 生命周期 | 被注册挂载到 StateGraph 中 | 被 Node 触发执行 |
| 依赖关系 | 内部持有/关联 AsyncNodeAction | 被 Node 持有,依附节点运行 |
| 作用层级 | 图静态结构层 | 业务动态执行层 |
| 形象类比 | 工位/站点(占位、标识位置) | 工位上要完成的工作任务 |
完整源码:
java
/**
* 图中的【节点】:工作流的最小执行单元
* 包含唯一ID + 执行动作工厂,所有自定义节点、子图节点都继承/基于此类
*/
public class Node {
/**
* 私有前缀:系统保留节点ID前缀(__开头)
* 用户自定义节点禁止使用此前缀
*/
public static final String PRIVATE_PREFIX = "__";
/**
* 【节点动作工厂】:核心接口
* 作用:延迟创建节点的异步执行动作,编译时根据配置生成动作
* 入参:编译配置 CompileConfig
* 返回值:带配置的异步节点动作 AsyncNodeActionWithConfig
*/
public interface ActionFactory {
AsyncNodeActionWithConfig apply(CompileConfig config) throws GraphStateException;
}
/**
* 节点唯一ID(不可变)
*/
private final String id;
/**
* 节点执行动作工厂(不可变)
*/
private final ActionFactory actionFactory;
/**
* 全参构造:ID + 动作工厂
*/
public Node(String id, ActionFactory actionFactory) {
this.id = id;
this.actionFactory = actionFactory;
}
/**
* 仅ID构造:无执行动作(虚拟节点/路由节点专用)
*/
public Node(String id) {
this(id, null);
}
/**
* 【节点合法性校验】:编译前强制调用
* 校验规则:
* 1. START/END 节点直接放行
* 2. 禁止空ID/空白ID
* 3. 禁止用户节点使用 __ 前缀
*/
public void validate() throws GraphStateException {
// 系统保留节点(START/END)无需校验
if (Objects.equals(id, StateGraph.END) || Objects.equals(id, StateGraph.START)) {
return;
}
// 禁止空白ID
if (id.isBlank()) {
throw Errors.invalidNodeIdentifier.exception("blank node id");
}
// 禁止使用系统保留前缀 __
if (id.startsWith(PRIVATE_PREFIX)) {
throw Errors.invalidNodeIdentifier.exception("id that start with %s", PRIVATE_PREFIX);
}
}
/**
* 获取节点ID(不可变)
*/
public String id() {
return id;
}
/**
* 获取动作工厂
*/
public ActionFactory actionFactory() {
return actionFactory;
}
/**
* 是否为并行节点:默认false
* 子类(并行节点)可重写此方法
*/
public boolean isParallel() {
return false;
}
/**
* 生成新节点:修改ID,复用原有动作工厂
* 用于子图嵌套、节点重命名场景
*/
public Node withIdUpdated(Function<String, String> newId) {
return new Node(newId.apply(id), actionFactory);
}
/**
* 【核心:相等性判断】
* 节点是否相等 -> 只判断 ID!
* 这是 Nodes 容器自动去重的核心依据
*/
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null)
return false;
if (o instanceof Node node) {
return Objects.equals(id, node.id);
}
return false;
}
/**
* 哈希码:只基于 ID 生成
* 与 equals 保持一致,保证 Set 集合正确去重
*/
@Override
public int hashCode() {
return Objects.hash(id);
}
/**
* 打印节点信息:ID + 是否有执行动作
*/
@Override
public String toString() {
return format("Node(%s,%s)", id, actionFactory != null ? "action" : "null");
}
}默认实现类:
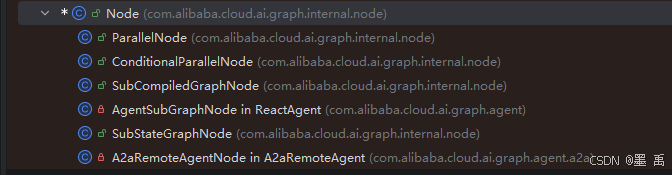
3.3 Edges
Edges 的本质是【边的容器】,统一存储(LinkedList)、查询所有边(Edge)。
完整源码:
java
public static class Edges {
/**
* 边集合:使用 LinkedList 存储
* final 保证容器引用不可变,仅支持增删元素
*/
public final List<Edge> elements;
/**
* 带参构造:初始化已有边集合
*/
public Edges(Collection<Edge> elements) {
this.elements = new LinkedList<>(elements);
}
/**
* 无参构造:空边集合
*/
public Edges() {
this.elements = new LinkedList<>();
}
/**
* 【核心查询】根据【源节点ID】查找边
* 设计:一个源节点 → 只能有一条边(StateGraph 核心规则)
*/
public Optional<Edge> edgeBySourceId(String sourceId) {
return elements.stream()
.filter(e -> Objects.equals(e.sourceId(), sourceId))
.findFirst();
}
/**
* 【反向查询】根据【目标节点ID】查找所有指向它的入边
* 用于:流程溯源、可视化、校验
*/
public List<Edge> edgesByTargetId(String targetId) {
return elements.stream()
.filter(e -> e.anyMatchByTargetId(targetId))
.toList();
}
}Edge 是一个 Record 类,表示图中的【边】,定义节点之间的连接关系,是工作流「怎么走」的核心载体。
属性列表:
| 属性名 | 类型 | 说明 |
|---|---|---|
| sourceId | String | 源节点ID(边的起点) |
| targets | List<EdgeValue> | 目标节点列表,支持多个目标(并行边) |
方法列表:
| 方法签名 | 返回值类型 | 访问修饰符 | 作用说明 |
|---|---|---|---|
| Edge(String sourceId, List<EdgeValue> targets) | - | public | Record 主构造方法 |
| Edge(String sourceId, EdgeValue target) | - | public | 简化构造:源节点 + 单个目标(普通边) |
| Edge(String id) | - | public | 简化构造:仅源节点(空目标,临时边) |
| isParallel() | boolean | public | 判断是否为并行边(目标数量 > 1) |
| target() | EdgeValue | public | 获取单个目标;并行边调用直接抛异常 |
| anyMatchByTargetId(String targetId) | boolean | public | 判断是否包含指定目标节点ID(支持普通边/条件边) |
| withSourceAndTargetIdsUpdated(Node node, Function<String, String> newSourceId, Function<String, EdgeValue> newTarget) | Edge | public | 重命名源/目标ID,用于子图嵌套、节点重命名 |
| validate(StateGraph.Nodes nodes) | void | public | 【核心校验】编译前校验边的合法性(源节点/重复目标/目标节点存在性) |
| validate(EdgeValue target, StateGraph.Nodes nodes) | void | private | 校验单个目标节点的合法性 |
| equals(Object o) | boolean | public | 重写:仅根据 sourceId 判断相等性 |
| hashCode() | int | public | 重写:仅根据 sourceId 生成哈希码 |
完整源码:
java
/**
* 图中的【边】:定义节点的流转关系(源节点 → 目标节点)
* Record 类:属性不可变,自动生成 equals/hashCode/toString
*/
public record Edge(
String sourceId, // 源节点ID(起点)
List<EdgeValue> targets // 目标列表(终点,支持多个=并行)
) {
// 简化构造:源节点 + 单个目标(普通边)
public Edge(String sourceId, EdgeValue target) {
this(sourceId, List.of(target));
}
// 简化构造:仅源节点(空目标,临时边)
public Edge(String id) {
this(id, List.of());
}
/**
* 判断是否为【并行边】:目标数量 > 1 → 多个节点同时执行
*/
public boolean isParallel() {
return targets.size() > 1;
}
/**
* 获取【单个目标】
* 并行边调用直接抛异常,强制区分普通/并行逻辑
*/
public EdgeValue target() {
if (isParallel()) {
throw new IllegalStateException("Edge '%s' is parallel".formatted(sourceId));
}
return targets.get(0);
}
/**
* 判断是否包含指定目标节点(支持普通边+条件边)
*/
public boolean anyMatchByTargetId(String targetId) {
return targets().stream()
.anyMatch(v -> (v.id() != null) ?
Objects.equals(v.id(), targetId) // 普通目标:直接匹配ID
: v.value().mappings().containsValue(targetId) // 条件目标:匹配映射值
);
}
/**
* 重命名源/目标ID:用于子图嵌套、节点重命名
*/
public Edge withSourceAndTargetIdsUpdated(Node node, Function<String, String> newSourceId, Function<String, EdgeValue> newTarget) {
var newTargets = targets().stream().map(t -> t.withTargetIdsUpdated(newTarget)).toList();
return new Edge(newSourceId.apply(sourceId), newTargets);
}
/**
* 【核心校验】编译前校验边的合法性
* 1. 源节点必须存在
* 2. 并行边禁止重复目标
* 3. 所有目标节点必须存在
*/
public void validate(StateGraph.Nodes nodes) throws GraphStateException {
// 校验:源节点必须存在(除了START)
if (!Objects.equals(sourceId(), START) && !nodes.anyMatchById(sourceId())) {
throw Errors.missingNodeReferencedByEdge.exception(sourceId());
}
// 校验:并行边不能有重复目标节点
if (isParallel()) {
Set<String> duplicates = targets.stream()
.collect(Collectors.groupingBy(EdgeValue::id, Collectors.counting()))
.entrySet().stream()
.filter(entry -> entry.getValue() > 1)
.map(Map.Entry::getKey)
.collect(Collectors.toSet());
if (!duplicates.isEmpty()) {
throw Errors.duplicateEdgeTargetError.exception(sourceId(), duplicates);
}
}
// 递归校验所有目标
for (EdgeValue target : targets) {
validate(target, nodes);
}
}
/**
* 校验单个目标节点合法性
*/
private void validate(EdgeValue target, StateGraph.Nodes nodes) throws GraphStateException {
if (target.id() != null) {
// 普通目标:节点必须存在(END除外)
if (!Objects.equals(target.id(), StateGraph.END) && !nodes.anyMatchById(target.id())) {
throw Errors.missingNodeReferencedByEdge.exception(target.id());
}
}
else if (target.value() != null) {
// 条件边:所有映射的目标节点必须存在
for (String nodeId : target.value().mappings().values()) {
if (!Objects.equals(nodeId, StateGraph.END) && !nodes.anyMatchById(nodeId)) {
throw Errors.missingNodeInEdgeMapping.exception(sourceId(), nodeId);
}
}
}
else {
// 无效目标:无ID无条件
throw Errors.invalidEdgeTarget.exception(sourceId());
}
}
/**
* 相等性判断:仅根据 sourceId
* 设计:一个源节点只能有一条边
*/
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Edge node = (Edge) o;
return Objects.equals(sourceId, node.sourceId);
}
/**
* 哈希码:仅根据 sourceId
*/
@Override
public int hashCode() {
return Objects.hash(sourceId);
}
}3.4 KeyStrategyFactory
KeyStrategy 状态键策略接口继承自 BiFunction ,定义了基于输入参数和全局状态生成缓存键的策略。
java
public interface KeyStrategy extends BiFunction<Object, Object, Object> {
/** 替换策略:使用新值直接替换旧缓存键 */
KeyStrategy REPLACE = new ReplaceStrategy();
/** 追加策略:将新内容追加到原有缓存键后 */
KeyStrategy APPEND = new AppendStrategy();
/** 合并策略:将多个缓存键/内容合并为一个最终键 */
KeyStrategy MERGE = new MergeStrategy();
/**
* 创建用于构建 KeyStrategy 配置的构建器实例
* @return 新的 KeyStrategyFactoryBuilder 构建器实例
*/
static KeyStrategyFactoryBuilder builder() {
return new KeyStrategyFactoryBuilder();
}
}默认提供了三种策略:
ReplaceStrategy:替换AppendStrategy:追加MergeStrategy:合并
KeyStrategyFactory 是一个用于提供缓存键策略实现的工厂接口。用于灵活创建不同的 KeyStrategy 实例,这些策略用于根据输入参数 和状态 生成缓存键,支持在需要时通过名称获取指定的缓存键策略。
java
@FunctionalInterface
public interface KeyStrategyFactory {
/**
* 创建并返回 KeyStrategy 实例的映射集合。
* 该方法的实现类需提供一个或多个带名称的缓存键策略实现。
*
* @return 以策略名称为键、对应 KeyStrategy 实例为值的 Map 集合
*/
Map<String, KeyStrategy> apply();
}3.5 StateSerializer
内置Jackson 序列化器 ,是 OverAllState 数据传输/持久化的默认实现:
java
public static final StateSerializer DEFAULT_JACKSON_SERIALIZER =
new SpringAIJacksonStateSerializer(OverAllState::new, new ObjectMapper());StateSerializer 是状态序列化器抽象基类,实现了标准的序列化接口,专门用于对状态图的全局状态(OverAllState)进行序列化/反序列化操作:
java
public abstract class StateSerializer implements Serializer<OverAllState> {
/**
* 状态工厂:用于将 Map 数据转换为 OverAllState 实例
*/
private final AgentStateFactory<OverAllState> stateFactory;
/**
* 构造方法
* @param stateFactory 状态工厂实例,不能为空
*/
protected StateSerializer(AgentStateFactory<OverAllState> stateFactory) {
this.stateFactory = Objects.requireNonNull(stateFactory, "stateFactory cannot be null");
}
/**
* 获取状态工厂实例
* @return AgentStateFactory<OverAllState>
*/
public final AgentStateFactory<OverAllState> stateFactory() {
return stateFactory;
}
/**
* 将 Map 格式数据转换为 OverAllState 实例
* @param data 状态数据 Map
* @return 构建好的全局状态对象
*/
public final OverAllState stateOf(Map<String, Object> data) {
Objects.requireNonNull(data, "data cannot be null");
return stateFactory.apply(data);
}
/**
* 克隆一个状态对象
* @param data 原始状态数据
* @return 克隆后的新状态对象
* @throws IOException 流操作异常
* @throws ClassNotFoundException 类未找到异常
*/
public final OverAllState cloneObject(Map<String, Object> data) throws IOException, ClassNotFoundException {
Objects.requireNonNull(data, "data cannot be null");
return cloneObject(stateFactory().apply(data));
}
/**
* 序列化 OverAllState 对象
* 实际只序列化内部的 data 数据
* @param object 待序列化的状态对象
* @param out 输出流
* @throws IOException 流写入异常
*/
@Override
public final void write(OverAllState object, ObjectOutput out) throws IOException {
writeData(object.data(), out);
}
/**
* 反序列化为 OverAllState 对象
* 读取数据后通过状态工厂构建实例
* @param in 输入流
* @return 反序列化后的全局状态对象
* @throws IOException 流读取异常
* @throws ClassNotFoundException 类未找到异常
*/
@Override
public final OverAllState read(ObjectInput in) throws IOException, ClassNotFoundException {
return stateFactory().apply(readData(in));
}
/**
* 抽象方法:序列化状态数据(子类实现)
* @param data 状态数据 Map
* @param out 输出流
* @throws IOException 写入异常
*/
public abstract void writeData(Map<String, Object> data, ObjectOutput out) throws IOException;
/**
* 抽象方法:反序列化状态数据(子类实现)
* @param in 输入流
* @return 读取到的状态数据 Map
* @throws IOException 读取异常
* @throws ClassNotFoundException 类未找到异常
*/
public abstract Map<String, Object> readData(ObjectInput in) throws IOException, ClassNotFoundException;
/**
* 将状态数据转换为字节数组
* @param data 状态数据 Map
* @return 序列化后的字节数组
* @throws IOException 流异常
*/
public final byte[] dataToBytes(Map<String, Object> data) throws IOException {
Objects.requireNonNull(data, "object cannot be null");
try (ByteArrayOutputStream stream = new ByteArrayOutputStream()) {
ObjectOutputStream oas = new ObjectOutputStream(stream);
writeData(data, oas);
oas.flush();
return stream.toByteArray();
}
}
/**
* 从字节数组中恢复状态数据
* @param bytes 序列化字节数组
* @return 恢复后的状态数据 Map
* @throws IOException 流异常
* @throws ClassNotFoundException 类未找到异常
*/
public final Map<String, Object> dataFromBytes(byte[] bytes) throws IOException, ClassNotFoundException {
Objects.requireNonNull(bytes, "bytes cannot be null");
if (bytes.length == 0) {
throw new IllegalArgumentException("bytes cannot be empty");
}
try (ByteArrayInputStream stream = new ByteArrayInputStream(bytes)) {
ObjectInputStream ois = new ObjectInputStream(stream);
return readData(ois);
}
}
}相关实现类:
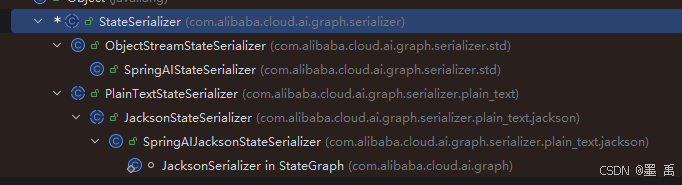
其中:
PlainTextStateSerializer:纯文本格式状态序列化器抽象类,专门用于将状态序列化为【纯文本】格式ObjectStreamStateSerializer:基于Java对象流的状态序列化器,使用Java原生序列化机制实现Map/List类型数据的序列化与反序列化
4. 核心方法
StateGraph 所有方法都是链式声明API,用于构建节点和边(声明式定义工作流),是开发者最常用的接口。
构造方法:
java
/**
* 通过指定名称、缓存键策略工厂构建 StateGraph(使用默认 Jackson 序列化器)
* @param name 状态图名称
* @param keyStrategyFactory 缓存键策略工厂
*/
public StateGraph(String name, KeyStrategyFactory keyStrategyFactory) {
this(name, keyStrategyFactory, DEFAULT_JACKSON_SERIALIZER);
}
/**
* 通过指定缓存键策略工厂构建 StateGraph(使用默认 Jackson 序列化器)
* @param keyStrategyFactory 缓存键策略工厂
*/
public StateGraph(KeyStrategyFactory keyStrategyFactory) {
this(null, keyStrategyFactory, DEFAULT_JACKSON_SERIALIZER);
}
/**
* 默认构造方法:使用基于 Jackson 的默认状态序列化器初始化 StateGraph
*/
public StateGraph() {
this(null, HashMap::new, DEFAULT_JACKSON_SERIALIZER);
}
/**
* 通过指定缓存键策略工厂、状态序列化器构建 StateGraph
* @param keyStrategyFactory 缓存键策略工厂
* @param stateSerializer 要使用的状态序列化器
*/
public StateGraph(KeyStrategyFactory keyStrategyFactory, StateSerializer stateSerializer) {
this(null, keyStrategyFactory, Objects.requireNonNull(stateSerializer, "stateSerializer cannot be null"));
}
/**
* 通过指定名称、缓存键策略工厂、状态序列化器构建 StateGraph(最终核心构造方法)
* @param name 状态图名称
* @param keyStrategyFactory 缓存键策略工厂
* @param stateSerializer 要使用的状态序列化器
*/
public StateGraph(String name, KeyStrategyFactory keyStrategyFactory, StateSerializer stateSerializer) {
this.name = name;
this.keyStrategyFactory = keyStrategyFactory;
this.stateSerializer = Objects.requireNonNull(stateSerializer, "stateSerializer cannot be null");
}4.1 添加节点
多个添加节点重载方法 ,支持以下类型作为 Node 添加到状态图中:
AsyncNodeAction:节点需要执行的异步节点动作AsyncNodeActionWithConfig:节点需要执行的动作(包含配置)Node:节点对象AsyncCommandAction:异步的执行命令动作AsyncMultiCommandAction:异步的多命令执行动作CompiledGraph:向状态图中添加子图(基于已编译的子图)StateGraph:向状态图中添加子图(基于未编译的状态图)
完整源码:
java
/**
* 向状态图中添加节点
* @param id 节点的唯一标识
* @param action 节点需要执行的异步节点动作
* @return 当前状态图实例
* @throws GraphStateException 当节点标识无效或节点已存在时抛出该异常
*/
public StateGraph addNode(String id, AsyncNodeAction action) throws GraphStateException {
// 封装动作与默认配置,调用重载方法
return addNode(id, AsyncNodeActionWithConfig.of(action));
}
/**
* 向状态图中添加节点(指定动作和配置)
* @param id 节点的唯一标识
* @param actionWithConfig 节点需要执行的动作(包含配置)
* @return 当前状态图实例
* @throws GraphStateException 当节点标识无效或节点已存在时抛出该异常
*/
public StateGraph addNode(String id, AsyncNodeActionWithConfig actionWithConfig) throws GraphStateException {
// 创建节点实例,使用工厂函数返回带配置的动作
Node node = new Node(id, (config) -> actionWithConfig);
// 调用最终的节点添加方法
return addNode(id, node);
}
/**
* 向状态图中添加节点(指定标识和节点实例)
* @param id 节点的唯一标识
* @param node 待添加的节点对象
* @return 当前状态图实例
* @throws GraphStateException 当节点标识无效、节点标识不匹配或节点已存在时抛出该异常
*/
public StateGraph addNode(String id, Node node) throws GraphStateException {
// 禁止将结束节点作为普通节点添加
if (Objects.equals(node.id(), END)) {
throw Errors.invalidNodeIdentifier.exception(END);
}
// 校验传入的ID与节点自身ID一致
if (!Objects.equals(node.id(), id)) {
throw Errors.nodeIdNotMatchError.exception(node.id(), id);
}
// 校验节点是否已存在,避免重复添加
if (nodes.elements.contains(node)) {
throw Errors.duplicateNodeError.exception(id);
}
// 将节点添加到节点集合中
nodes.elements.add(node);
return this;
}
/**
* 添加作为条件边的节点(单命令条件路由)
* @param id 节点的唯一标识
* @param action 用于确定下一个目标节点的节点动作
* @param mappings 条件到目标节点的映射关系
* @throws GraphStateException 当节点标识无效、映射为空或节点已存在时抛出该异常
*/
public StateGraph addNode(String id, AsyncCommandAction action, Map<String, String> mappings)
throws GraphStateException {
// 简化实现:先添加空动作节点,再为节点绑定条件边
return addNode(id, (state, config) -> completedFuture(Map.of())).addConditionalEdges(id, action, mappings);
}
/**
* 添加作为并行条件边的节点(多命令并行路由)
* 该方法支持基于多命令动作并行路由到多个节点执行
* @param id 节点的唯一标识
* @param action 用于确定多个并行执行目标节点的多命令动作
* @param mappings 条件到目标节点的映射关系
* @return 当前状态图实例
* @throws GraphStateException 当节点标识无效、映射为空或节点已存在时抛出该异常
*/
public StateGraph addNode(String id, AsyncMultiCommandAction action, Map<String, String> mappings)
throws GraphStateException {
// 简化实现:先添加空动作节点,再为节点绑定并行条件边
return addNode(id, (state, config) -> completedFuture(Map.of())).addParallelConditionalEdges(id, action, mappings);
}
/**
* 向状态图中添加子图(基于已编译的子图)
* 通过创建指定标识的节点实现子图添加,子图与父图共享状态
* @param id 代表子图的节点唯一标识
* @param subGraph 待添加的已编译子图
* @return 当前状态图实例
* @throws GraphStateException 当节点标识无效或节点已存在时抛出该异常
*/
public StateGraph addNode(String id, CompiledGraph subGraph) throws GraphStateException {
// 禁止使用结束节点作为子图节点标识
if (Objects.equals(id, END)) {
throw Errors.invalidNodeIdentifier.exception(END);
}
// 创建子图节点实例
var node = new SubCompiledGraphNode(id, subGraph);
// 校验节点是否已存在
if (nodes.elements.contains(node)) {
throw Errors.duplicateNodeError.exception(id);
}
// 添加子图节点到集合
nodes.elements.add(node);
return this;
}
/**
* 向状态图中添加子图(基于未编译的状态图)
* 子图与父图共享状态,且会在父图编译时自动编译
* @param id 代表子图的节点唯一标识
* @param subGraph 待添加的状态图(父图编译时会自动编译该子图)
* @return 当前状态图实例
* @throws GraphStateException 当节点标识无效或节点已存在时抛出该异常
*/
public StateGraph addNode(String id, StateGraph subGraph) throws GraphStateException {
// 禁止使用结束节点作为子图节点标识
if (Objects.equals(id, END)) {
throw Errors.invalidNodeIdentifier.exception(END);
}
// 校验子图的合法性
subGraph.validateGraph();
// 创建子图状态节点实例
var node = new SubStateGraphNode(id, subGraph);
// 校验节点是否已存在
if (nodes.elements.contains(node)) {
throw Errors.duplicateNodeError.exception(id);
}
// 添加子图节点到集合
nodes.elements.add(node);
return this;
}4.2 添加边
多个添加边重载方法 ,支持以下类型作为 Edge 添加到状态图中:
- 直接使用节点名称(普通边):
- 【单源节点 → 单目标节点】(
String sourceId, String targetId) - 【多源节点 → 单目标节点】(
List<String> sourceIds, String targetId) - 【单源节点 → 多目标节点】(
String sourceId, List<String> targetIds)
- 【单源节点 → 单目标节点】(
- 使用
Action(条件边):AsyncCommandAction:用于判断目标节点的异步命令动作AsyncEdgeAction: 用于判断目标节点的异步边动作AsyncEdgeActionWithConfig:带配置的异步边动作
- 使用
Action(并行边):AsyncMultiCommandAction:用于判断多目标节点的异步多命令动作
完整源码:
java
// ==================== 普通边添加方法 ====================
/**
* 向状态图中添加【单源节点 → 单目标节点】的普通边
* @param sourceId 源节点ID
* @param targetId 目标节点ID
* @return 当前状态图实例(支持链式调用)
* @throws GraphStateException 边标识非法/边已存在时抛出异常
*/
public StateGraph addEdge(String sourceId, String targetId) throws GraphStateException {
// 校验:结束节点END不能作为源节点(无后续流转)
if (Objects.equals(sourceId, END)) {
throw Errors.invalidEdgeIdentifier.exception(END);
}
// 创建新的边对象(单目标普通边)
var newEdge = new Edge(sourceId, new EdgeValue(targetId));
// 检查当前源节点的边是否已存在(根据sourceId判断,Edge重写了equals)
int index = edges.elements.indexOf(newEdge);
if (index >= 0) {
// 边已存在:获取原有目标列表,新增当前目标,合并为并行边
var newTargets = new ArrayList<>(edges.elements.get(index).targets());
newTargets.add(newEdge.target());
// 替换原有边为合并后的新边
edges.elements.set(index, new Edge(sourceId, newTargets));
} else {
// 边不存在:直接添加新边
edges.elements.add(newEdge);
}
return this;
}
/**
* 向状态图中添加【多源节点 → 单目标节点】的普通边
* 遍历所有源节点,分别添加到目标节点的边
* @param sourceIds 源节点ID集合
* @param targetId 目标节点ID
* @return 当前状态图实例(支持链式调用)
* @throws GraphStateException 源节点集合为空/边非法时抛出异常
*/
public StateGraph addEdge(List<String> sourceIds, String targetId) throws GraphStateException {
// 校验:源节点集合不能为空
if (sourceIds == null || sourceIds.isEmpty()) {
throw Errors.emptySourceNodeByEdge.exception(targetId);
}
// 遍历所有源节点,逐一添加单源单目标边
for (String sourceId : sourceIds) {
addEdge(sourceId, targetId);
}
return this;
}
/**
* 向状态图中添加【单源节点 → 多目标节点】的普通边
* 遍历所有目标节点,分别添加源节点到目标的边
* @param sourceId 源节点ID
* @param targetIds 目标节点ID集合
* @return 当前状态图实例(支持链式调用)
* @throws GraphStateException 目标节点集合为空/边非法时抛出异常
*/
public StateGraph addEdge(String sourceId, List<String> targetIds) throws GraphStateException {
// 校验:目标节点集合不能为空
if (targetIds == null || targetIds.isEmpty()) {
throw Errors.emptyTargetNodeByEdge.exception(sourceId);
}
// 遍历所有目标节点,逐一添加单源单目标边
for (String targetId : targetIds) {
addEdge(sourceId, targetId);
}
return this;
}
// ==================== 条件边添加方法 ====================
/**
* 向状态图中添加【单条件普通边】
* 根据条件和映射关系,动态路由到对应目标节点
* @param sourceId 源节点ID
* @param condition 用于判断目标节点的异步命令执行器
* @param mappings 条件结果 → 目标节点的映射关系
* @return 当前状态图实例(支持链式调用)
* @throws GraphStateException 边标识非法/映射为空/条件边已存在时抛出异常
*/
public StateGraph addConditionalEdges(String sourceId, AsyncCommandAction condition, Map<String, String> mappings)
throws GraphStateException {
// 校验:结束节点END不能作为源节点
if (Objects.equals(sourceId, END)) {
throw Errors.invalidEdgeIdentifier.exception(END);
}
// 校验:条件映射关系不能为空
if (mappings == null || mappings.isEmpty()) {
throw Errors.edgeMappingIsEmpty.exception(sourceId);
}
// 创建条件边对象(单路由条件)
var newEdge = new Edge(sourceId, new EdgeValue(EdgeCondition.single(condition, mappings)));
// 校验:同一源节点不能重复添加条件边
if (edges.elements.contains(newEdge)) {
throw Errors.duplicateConditionalEdgeError.exception(sourceId);
} else {
edges.elements.add(newEdge);
}
return this;
}
/**
* 向状态图中添加【单条件普通边】(适配异步边执行器)
* 包装AsyncEdgeAction为AsyncCommandAction,调用核心条件边方法
* @param sourceId 源节点ID
* @param condition 用于判断目标节点的异步边执行器
* @param mappings 条件结果 → 目标节点的映射关系
* @return 当前状态图实例(支持链式调用)
* @throws GraphStateException 边标识非法/映射为空/条件边已存在时抛出异常
*/
public StateGraph addConditionalEdges(String sourceId, AsyncEdgeAction condition, Map<String, String> mappings)
throws GraphStateException {
return addConditionalEdges(sourceId, AsyncCommandAction.of(condition), mappings);
}
/**
* 向状态图中添加【单条件普通边】(适配带配置的异步边执行器)
* 包装AsyncEdgeActionWithConfig为AsyncCommandAction,调用核心条件边方法
* @param sourceId 源节点ID
* @param asyncEdgeActionWithConfig 带配置的异步边执行器
* @param mappings 条件结果 → 目标节点的映射关系
* @return 当前状态图实例(支持链式调用)
* @throws GraphStateException 边标识非法/映射为空/条件边已存在时抛出异常
*/
public StateGraph addConditionalEdges(String sourceId, AsyncEdgeActionWithConfig asyncEdgeActionWithConfig, Map<String, String> mappings)
throws GraphStateException {
return addConditionalEdges(sourceId, AsyncCommandAction.of(asyncEdgeActionWithConfig), mappings);
}
// ==================== 并行条件边添加方法 ====================
/**
* 向状态图中添加【并行条件边】
* 条件执行后可路由到多个目标节点,支持并行执行
* @param sourceId 源节点ID
* @param condition 用于判断多目标节点的异步多命令执行器
* @param mappings 条件结果 → 目标节点的映射关系
* @return 当前状态图实例(支持链式调用)
* @throws GraphStateException 边标识非法/映射为空/条件边已存在时抛出异常
*/
public StateGraph addParallelConditionalEdges(String sourceId, AsyncMultiCommandAction condition, Map<String, String> mappings)
throws GraphStateException {
// 校验:结束节点END不能作为源节点
if (Objects.equals(sourceId, END)) {
throw Errors.invalidEdgeIdentifier.exception(END);
}
// 校验:条件映射关系不能为空
if (mappings == null || mappings.isEmpty()) {
throw Errors.edgeMappingIsEmpty.exception(sourceId);
}
// 创建并行条件边对象(多路由并行执行)
var newEdge = new Edge(sourceId, new EdgeValue(EdgeCondition.multi(condition, mappings)));
// 校验:同一源节点不能重复添加并行条件边
if (edges.elements.contains(newEdge)) {
throw Errors.duplicateConditionalEdgeError.exception(sourceId);
} else {
edges.elements.add(newEdge);
}
return this;
}4.3 图校验
编译前强制校验,避免无效工作流:
- 校验所有节点合法性
- 强制要求必须有
START入口边 - 校验所有边的目标节点存在
完整源码:
java
/**
* 校验状态图的整体结构合法性
* 确保图中所有节点、边、节点连接关系均符合规则,无非法配置
* @throws GraphStateException 图结构存在非法状态时抛出异常(如缺少入口、节点/边非法)
*/
void validateGraph() throws GraphStateException {
// 1. 遍历图中所有节点,执行【节点自身】的合法性校验
for (var node : nodes.elements) {
node.validate();
}
// 2. 获取【起始节点(START)】对应的边,无入口边则直接抛出【缺少入口点】异常
var edgeStart = edges.edgeBySourceId(START).orElseThrow(Errors.missingEntryPoint::exception);
// 3. 单独校验【起始边】的合法性(入口是图的核心,优先校验)
edgeStart.validate(nodes);
// 4. 遍历图中所有边,执行【所有边】的完整合法性校验(源节点、目标节点、并行规则等)
for (Edge edge : edges.elements) {
edge.validate(nodes);
}
}4.4 编译为执行图
StateGraph → CompiledGraph 编译状态图的核心方法:
- 使用【默认配置】编译
- 使用指定的配置编译
完整源码:
java
/**
* 使用指定的编译配置,将状态图编译为可执行的编译后图形
* 编译前会先执行全图结构校验,确保图形合法后再编译
* @param config 编译配置参数(包含持久化、执行策略等配置)
* @return 编译完成的可执行图形实例
* @throws GraphStateException 图结构非法、配置异常时抛出异常
*/
public CompiledGraph compile(CompileConfig config) throws GraphStateException {
// 校验编译配置不能为空,为空则直接抛出空指针异常
Objects.requireNonNull(config, "config cannot be null");
// 执行【全局图结构校验】:校验所有节点、边、入口点的合法性
validateGraph();
// 基于当前状态图和编译配置,创建并返回最终的编译后图形
return new CompiledGraph(this, config);
}
/**
* 使用【默认配置】编译状态图(内置内存持久化策略)
* 默认配置会自动注册内存存储器,适用于无需持久化的临时/内存运行场景
* @return 编译完成的可执行图形实例
* @throws GraphStateException 图结构非法时抛出异常
*/
public CompiledGraph compile() throws GraphStateException {
// 构建内存持久化配置:注册 MemorySaver(内存存储,数据仅保存在运行内存中)
SaverConfig saverConfig = SaverConfig.builder()
.register(new MemorySaver())
.build();
// 构建默认编译配置(仅配置内存持久化),并调用带参编译方法完成编译
return compile(CompileConfig.builder().saverConfig(saverConfig).build());
}4.5 可视化生成
内置工作流可视化能力 ,生成 Mermaid/PlantUML 流程图:
java
/**
* 生成状态图的可绘制图表表示
* @param type 要生成的图表表示类型(如 Mermaid、PlantUML 等)
* @param title 图表标题
* @param printConditionalEdges 是否在输出中包含条件边
* @return 封装后的状态图图表代码对象
*/
public GraphRepresentation getGraph(GraphRepresentation.Type type, String title, boolean printConditionalEdges) {
// 根据指定类型生成器,渲染节点、边、标题、条件边为图表文本
String content = type.generator.generate(nodes, edges, title, printConditionalEdges);
// 封装类型与内容并返回
return new GraphRepresentation(type, content);
}
/**
* 生成状态图的可绘制图表表示(默认包含条件边)
* @param type 要生成的图表表示类型
* @param title 图表标题
* @return 封装后的状态图图表代码对象
*/
public GraphRepresentation getGraph(GraphRepresentation.Type type, String title) {
// 调用重载方法,默认开启条件边打印
String content = type.generator.generate(nodes, edges, title, true);
return new GraphRepresentation(type, content);
}
/**
* 生成状态图的可绘制图表表示(使用状态图名称作为标题,默认包含条件边)
* @param type 要生成的图表表示类型
* @return 封装后的状态图图表代码对象
*/
public GraphRepresentation getGraph(GraphRepresentation.Type type) {
// 使用状态图自身 name 作为标题,默认开启条件边打印
String content = type.generator.generate(nodes, edges, name, true);
return new GraphRepresentation(type, content);
}