NameNode HA 背景
在Hadoop1中NameNode存在一个单点故障问题,如果NameNode所在的机器发生故障,整个集群就将不可用(Hadoop1中虽然有个SecorndaryNameNode,但是它并不是NameNode的备份,它只是NameNode的一个助理,协助NameNode工作,SecorndaryNameNode会对fsimage和edits文件进行合并,并推送给NameNode,防止因edits文件过大,导致NameNode重启变慢),这是Hadoop1的不可靠实现。
在Hadoop2中这个问题得以解决,Hadoop2中的高可靠性是指同时启动NameNode,其中一个处于active工作状态,另外一个处于随时待命standby状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode提供服务。这些NameNode之间通过共享数据,保证数据的状态一致。多个NameNode之间共享数据,可以通过Network File System或者Quorum Journal Node。前者是通过Linux共享的文件系统,属于操作系统的配置,后者是Hadoop自身的东西,属于软件的配置。
注意:
NameNode HA 与HDFS Federation都有多个NameNode,当NameNode作用不同,在HDFS Federation联邦机制中多个NameNode解决了内存受限问题,而在NameNode HA中多个NameNode解决了NameNode单点故障问题。
在Hadoop2.x版本中,NameNode HA 支持2个节点,在Hadoop3.x版本中,NameNode高可用可以支持多台节点。
NameNode HA实现原理
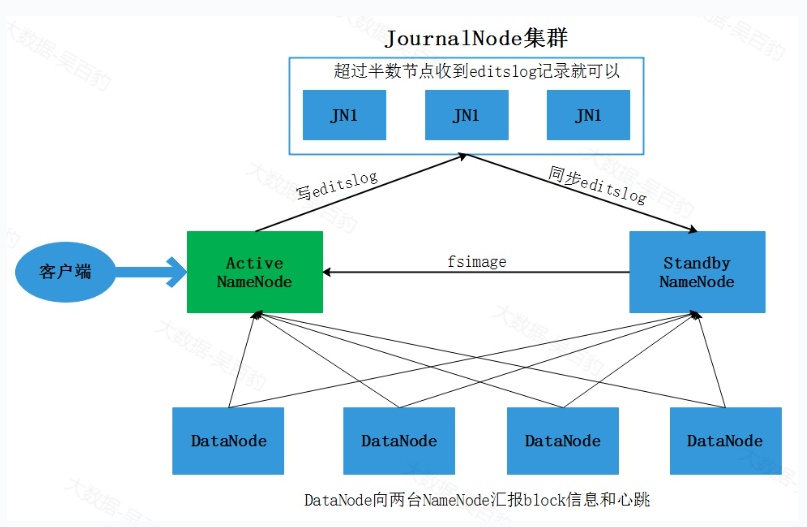
NameNode中存储了HDFS中所有元数据信息(包括用户操作元数据和block元数据),在NameNode HA中,当Active NameNode(ANN)挂掉后,StandbyNameNode(SNN)要及时顶上,这就需要将所有的元数据同步到SNN节点。如向HDFS中写入一个文件时,如果元数据同步写入ANN和SNN,那么当SNN挂掉势必会影响ANN,所以元数据需要异步写入ANN和SNN中。如果某时刻ANN刚好挂掉,但却没有及时将元数据异步写入到SNN也会引起数据丢失,所以向SNN同步元数据需要引入第三方存储,在HA方案中叫做"共享存储"。每次向HDFS中写入文件时,需要将edits log同步写入共享存储,这个步骤成功才能认定写文件成功,然后SNN定期从共享存储中同步editslog,以便拥有完整元数据便于ANN挂掉后进行主备切换。
HDFS将Cloudera公司实现的QJM(Quorum Journal Manager)方案作为默认的共享存储实现。在QJM方案中注意如下几点:
基于QJM的共享存储系统主要用于保存Editslog,并不保存FSImage文件,FSImage文件还是在NameNode本地磁盘中。
QJM共享存储采用多个称为JournalNode的节点组成的JournalNode集群来存储EditsLog。每个JournalNode保存同样的EditsLog副本。
每次NameNode写EditsLog时,除了向本地磁盘写入EditsLog外,也会并行的向JournalNode集群中每个JournalNode发送写请求,只要大多数的JournalNode节点返回成功就认为向JournalNode集群中写入EditsLog成功。
如果有2N+1台JournalNode,那么根据大多数的原则,最多可以容忍有N台JournalNode节点挂掉。
NameNode HA 实现原理图如下:
上图中引入了zookeeper作为分布式协调器来完成NameNode自动选主,以上各个角色解释如下:
AcitveNameNode:主 NameNode,只有主NameNode才能对外提供读写服务。
Standby NameNode:备用NameNode,定时同步Journal集群中的editslog元数据。
ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换。
Zookeeper集群:分布式协调器,NameNode选主使用。
Journal集群:Journal集群作为共享存储系统保存HDFS运行过程中的元数据,ANN和SNN通过Journal集群实现元数据同步。
DataNode节点:除了通过共享存储系统共享 HDFS 的元数据信息之外,主 NameNode 和备 NameNode 还需要共享 HDFS 的数据块和 DataNode 之间的映射关系。DataNode 会同时向主 NameNode 和备 NameNode 上报数据块的位置信息。
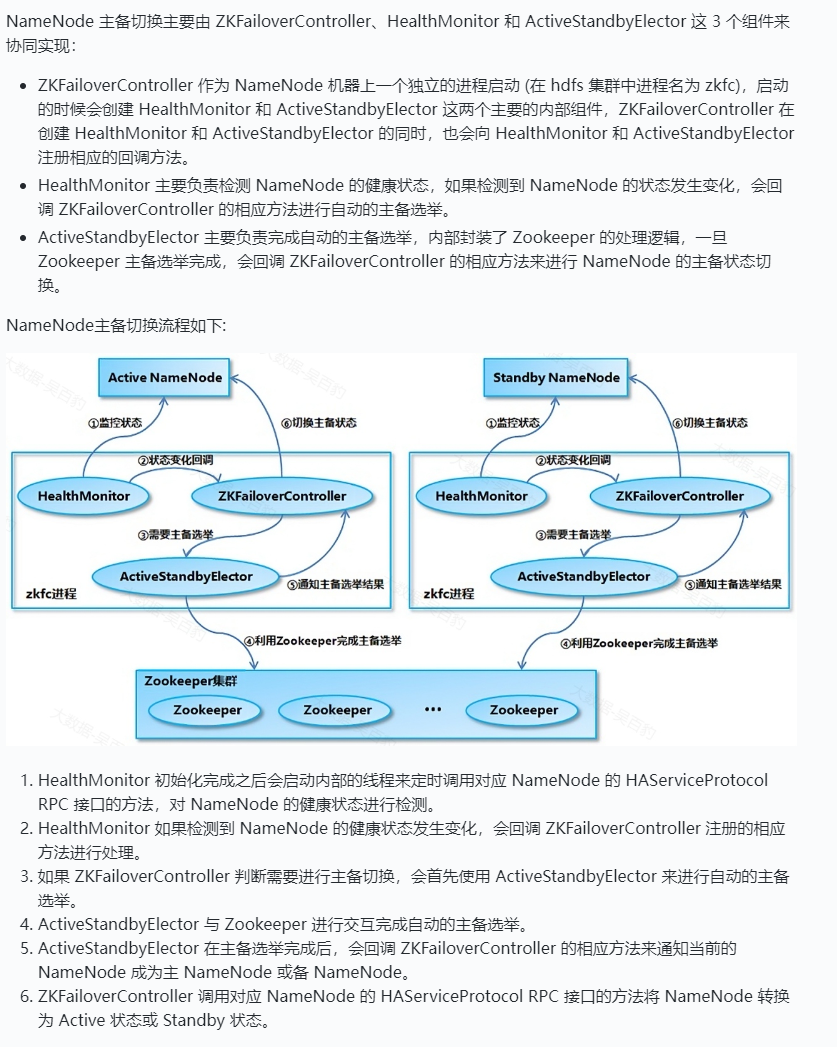
NameNode主备切换流程
脑裂问题
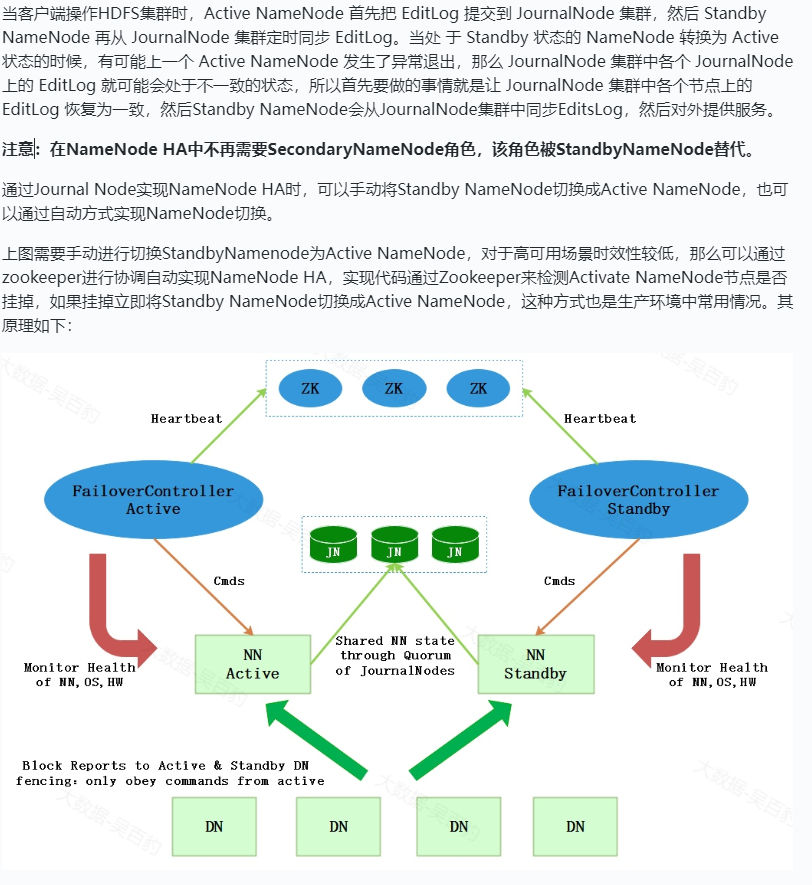
当网络抖动时,ZKFC检测不到Active NameNode,此时认为NameNode挂掉了,因此将Standby NameNode切换成Active NameNode,而旧的Active NameNode由于网络抖动,接收不到zkfc的切换命令,此时两个NameNode都是Active状态,这就是脑裂问题。那么HDFS HA中如何防止脑裂问题的呢?
HDFS集群初始启动时,Namenode的主备选举是通过 ActiveStandbyElector 来完成的,ActiveStandbyElector 主要是利用了 Zookeeper 的写一致性和临时节点机制,具体的主备选举实现如下:
- 创建锁节点
如果 HealthMonitor 检测到对应的 NameNode 的状态正常,那么表示这个 NameNode 有资格参加 Zookeeper 的主备选举。如果目前还没有进行过主备选举的话,那么相应的 ActiveStandbyElector 就会发起一次主备选举,尝试在 Zookeeper 上创建一个路径为/hadoop-ha/{dfs.nameservices}/ActiveStandbyElectorLock 的临时节点 ({dfs.nameservices} 为 Hadoop 的配置参数 dfs.nameservices 的值,下同),Zookeeper 的写一致性会保证最终只会有一个 ActiveStandbyElector 创建成功,那么创建成功的 ActiveStandbyElector 对应的 NameNode 就会成为主 NameNode,ActiveStandbyElector 会回调 ZKFailoverController 的方法进一步将对应的 NameNode 切换为 Active 状态。而创建失败的 ActiveStandbyElector 对应的NameNode成为备用NameNode,ActiveStandbyElector 会回调 ZKFailoverController 的方法进一步将对应的 NameNode 切换为 Standby 状态。
- 注册 Watcher 监听
不管创建/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点是否成功,ActiveStandbyElector 随后都会向 Zookeeper 注册一个 Watcher 来监听这个节点的状态变化事件,ActiveStandbyElector 主要关注这个节点的 NodeDeleted 事件。
- 自动触发主备选举
如果 Active NameNode 对应的 HealthMonitor 检测到 NameNode 的状态异常时, ZKFailoverController 会主动删除当前在 Zookeeper 上建立的临时节点/hadoop-ha/{dfs.nameservices}/ActiveStandbyElectorLock,这样处于 Standby 状态的 NameNode 的 ActiveStandbyElector 注册的监听器就会收到这个节点的 NodeDeleted 事件。收到这个事件之后,会马上再次进入到创建/hadoop-ha/{dfs.nameservices}/ActiveStandbyElectorLock 节点的流程,如果创建成功,这个本来处于 Standby 状态的 NameNode 就选举为主 NameNode 并随后开始切换为 Active 状态。
当然,如果是 Active 状态的 NameNode 所在的机器整个宕掉的话,那么根据 Zookeeper 的临时节点特性,/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock 节点会自动被删除,从而也会自动进行一次主备切换。
以上过程中,Standby NameNode成功创建 Zookeeper 节点/hadoop-ha/{dfs.nameservices}/ActiveStandbyElectorLock 成为Active NameNode之后,还会创建另外一个路径为/hadoop-ha/{dfs.nameservices}/ActiveBreadCrumb 的持久节点,这个节点里面保存了这个 Active NameNode 的地址信息。Active NameNode 的ActiveStandbyElector 在正常的状态下关闭 Zookeeper Session 的时候 (注意由于/hadoop-ha/{dfs.nameservices}/ActiveStandbyElectorLock 是临时节点,也会随之删除)会一起删除节点/hadoop-ha/{dfs.nameservices}/ActiveBreadCrumb。但是如果 ActiveStandbyElector 在异常的状态下 Zookeeper Session 关闭 (比如 Zookeeper 假死),那么由于/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 是持久节点,会一直保留下来。后面当另一个 NameNode 选主成功之后,会注意到上一个 Active NameNode 遗留下来的这个节点,从而会回调 ZKFailoverController 的方法对旧的 Active NameNode 进行隔离(fencing)操作以避免出现脑裂问题,fencing操作会通过SSH将旧的Active NameNode进程尝试转换成Standby状态,如果不能转换成Standby状态就直接将对应进程杀死。
NameNode自动HA集群搭建
zookeeper集群搭建


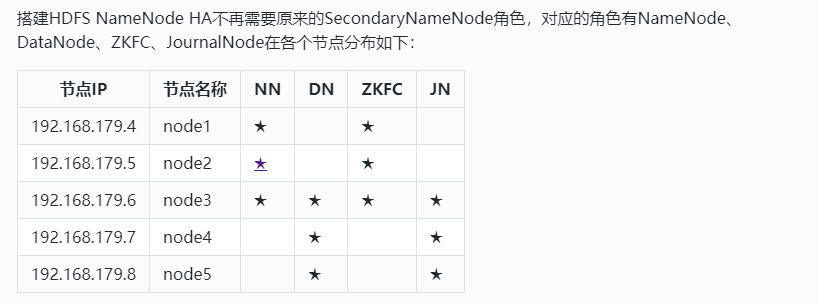
HDFS节点规划
安装JDK
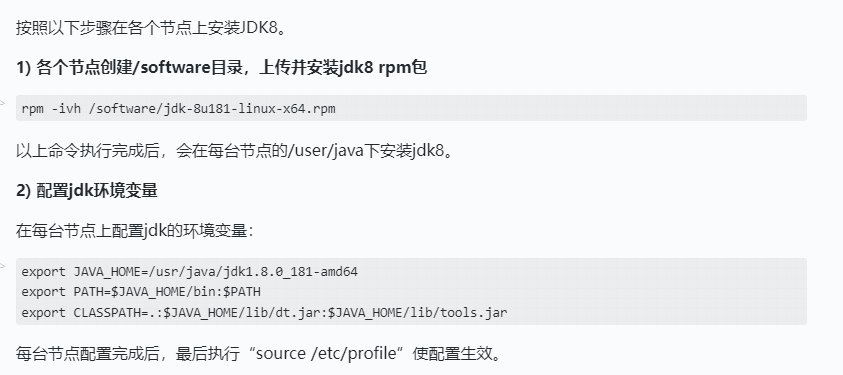
HDFS HA集群搭建


- 配置hdfs-site.xml
进入 $HADOOP_HOME/etc/hadoop路径下,修改hdfs-site.xml文件,指定NameNode和JournalNode节点和端口。这里配置NameNode节点为3个。
#vim /software/hadoop-3.3.6/etc/hadoop/hdfs-site.xml
<configuration>
<!-- 指定副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 解析参数dfs.nameservices值hdfs://mycluster的地址 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster由以下三个namenode支撑 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.nameservice ID.name node ID namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.nameservice ID.name node ID namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.nameservice ID.name node ID namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>node3:8020</value>
</property>
<property>
<!-- dfs.namenode.http-address.nameservice ID.name node ID namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:9870</value>
</property>
<property>
<!-- dfs.namenode.http-address.nameservice ID.name node ID namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:9870</value>
</property>
<property>
<!-- dfs.namenode.http-address.nameservice ID.name node ID namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>node3:9870</value>
</property>
<!-- namenode高可用代理类 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 指定三台journal node服务器的地址 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value>
</property>
<!-- journalnode 存储数据的地方 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal/node/local/data</value>
</property>
<!--启动NN故障自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 当active nn出现故障时,ssh到对应的服务器,将namenode进程kill掉 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>

格式化并启动HDFS集群

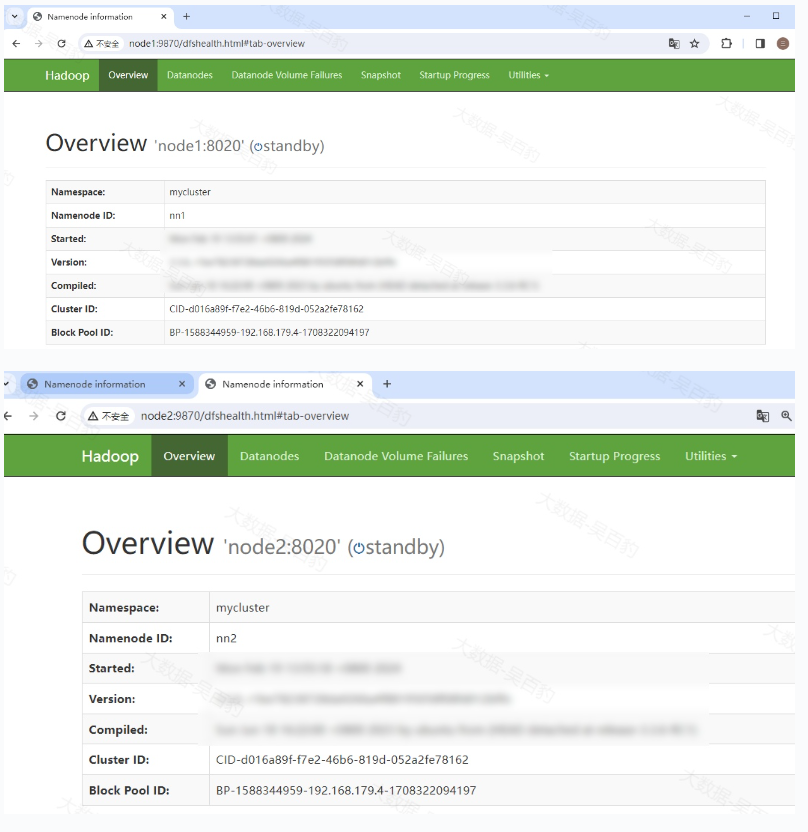
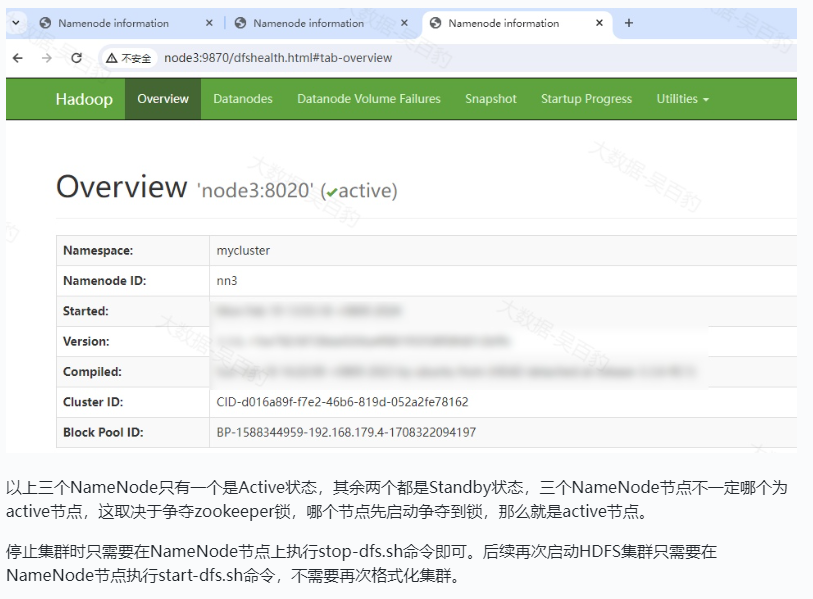
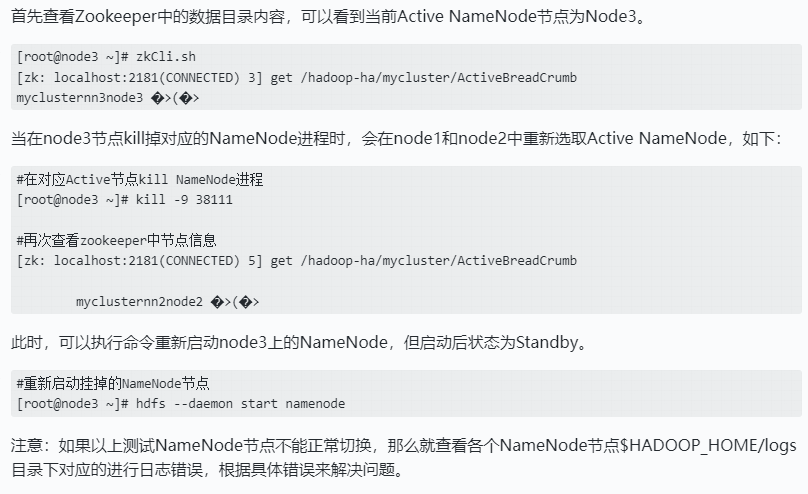
测试NameNode HA
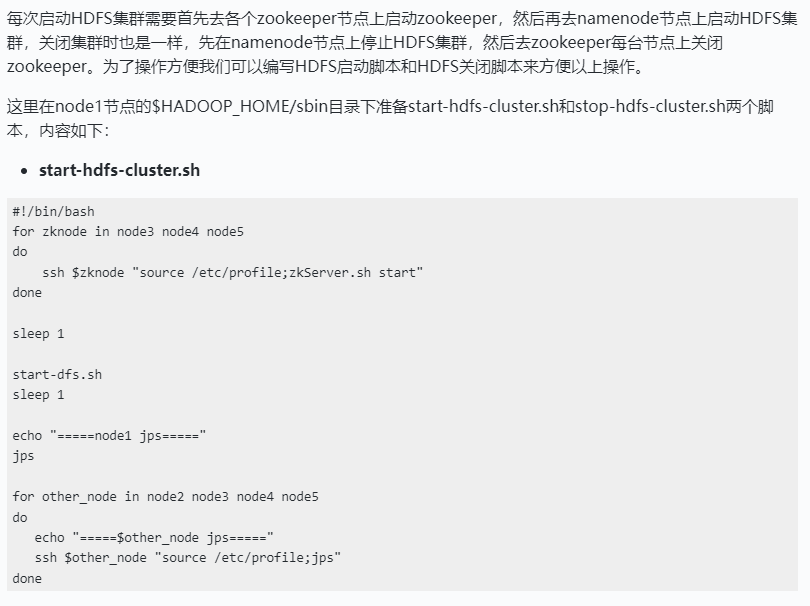
HDFS启动脚本和停止脚本编写

NameNode HA API操作

java
public class TestHAHDFS {
public static FileSystem fs = null;
public static void main(String[] args) throws IOException, InterruptedException {
Configuration conf = new Configuration();
//创建FileSystem对象
fs = FileSystem.get(URI.create("hdfs://mycluster/"),conf,"root");
//查看HDFS路径文件
listHDFSPathDir("/");
System.out.println("=====================================");
//创建目录
mkdirOnHDFS("/laowu/testdir");
System.out.println("=====================================");
//向HDFS 中上传数据
writeFileToHDFS("./data/test.txt","/laowu/testdir/test.txt");
System.out.println("=====================================");
//重命名HDFS文件
renameHDFSFile("/laowu/testdir/test.txt","/laowu/testdir/new_test.txt");
System.out.println("=====================================");
//查看文件详细信息
getHDFSFileInfos("/laowu/testdir/new_test.txt");
System.out.println("=====================================");
//读取HDFS中的数据
readFileFromHDFS("/laowu/testdir/new_test.txt");
System.out.println("=====================================");
//删除HDFS中的目录或者文件
deleteFileOrDirFromHDFS("/laowu/testdir");
System.out.println("=====================================");
//关闭fs对象
fs.close();
}
private static void listHDFSPathDir(String hdfsPath) throws IOException {
FileStatus[] fileStatuses = fs.listStatus(new Path(hdfsPath));
for (FileStatus fileStatus : fileStatuses) {
if(fileStatus.isDirectory()){
listHDFSPathDir(fileStatus.getPath().toString());
}
System.out.println(fileStatus.getPath());
}
}
private static void mkdirOnHDFS(String dirpath) throws IOException {
Path path = new Path(dirpath);
//判断目录是否存在
if(fs.exists(path)) {
System.out.println("目录" + dirpath + "已经存在");
return;
}
//创建HDFS目录
boolean result = fs.mkdirs(path);
if(result) {
System.out.println("创建目录" + dirpath + "成功");
} else {
System.out.println("创建目录" + dirpath + "失败");
}
}
private static void writeFileToHDFS(String localFilePath, String hdfsFilePath) throws IOException {
//判断HDFS文件是否存在,存在则删除
Path hdfsPath = new Path(hdfsFilePath);
if(fs.exists(hdfsPath)) {
fs.delete(hdfsPath, true);
}
//创建HDFS文件路径
Path path = new Path(hdfsFilePath);
FSDataOutputStream out = fs.create(path);
//读取本地文件写入HDFS路径中
FileReader fr = new FileReader(localFilePath);
BufferedReader br = new BufferedReader(fr);
String newLine = "";
while ((newLine = br.readLine()) != null) {
out.write(newLine.getBytes());
out.write("\n".getBytes());
}
//关闭流对象
out.close();
br.close();
fr.close();
//以上代码也可以调用copyFromLocalFile方法完成
//参数解释如下:上传完成是否删除原数据;是否覆盖写入;本地文件路径;写入HDFS文件路径
fs.copyFromLocalFile(false,true,new Path(localFilePath),new Path(hdfsFilePath));
System.out.println("本地文件 ./data/test.txt 写入了HDFS中的"+hdfsFilePath+"文件中");
}
private static void renameHDFSFile(String hdfsOldFilePath,String hdfsNewFilePath) throws IOException {
fs.rename(new Path(hdfsOldFilePath),new Path(hdfsNewFilePath));
System.out.println("成功将"+hdfsOldFilePath+"命名为:"+hdfsNewFilePath);
}
private static void getHDFSFileInfos(String hdfsFilePath) throws IOException {
Path file = new Path(hdfsFilePath);
RemoteIterator<LocatedFileStatus> listFilesIterator = fs.listFiles(file, true);//是否递归
while(listFilesIterator.hasNext()){
LocatedFileStatus fileStatus = listFilesIterator.next();
System.out.println("文件详细信息如下:");
System.out.println("权限:" + fileStatus.getPermission());
System.out.println("所有者:" + fileStatus.getOwner());
System.out.println("组:" + fileStatus.getGroup());
System.out.println("大小:" + fileStatus.getLen());
System.out.println("修改时间:" + fileStatus.getModificationTime());
System.out.println("副本数:" + fileStatus.getReplication());
System.out.println("块大小:" + fileStatus.getBlockSize());
System.out.println("文件名:" + fileStatus.getPath().getName());
//获取当前文件block所在节点信息
BlockLocation[] blks = fileStatus.getBlockLocations();
for (BlockLocation nd : blks) {
System.out.println("block信息:"+nd);
}
}
}
private static void readFileFromHDFS(String hdfsFilePath) throws IOException {
//读取HDFS文件
Path path= new Path(hdfsFilePath);
FSDataInputStream in = fs.open(path);
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String newLine = "";
while((newLine = br.readLine()) != null) {
System.out.println(newLine);
}
//关闭流对象
br.close();
in.close();
}
private static void deleteFileOrDirFromHDFS(String hdfsFileOrDirPath) throws IOException {
//判断HDFS目录或者文件是否存在
Path path = new Path(hdfsFileOrDirPath);
if(!fs.exists(path)) {
System.out.println("HDFS目录或者文件不存在");
return;
}
//第二个参数表示是否递归删除
boolean result = fs.delete(path, true);
if(result){
System.out.println("HDFS目录或者文件 "+path+" 删除成功");
} else {
System.out.println("HDFS目录或者文件 "+path+" 删除成功");
}
}
}