
导读
无人机电力线巡检中,轻量化分割模型部署后可能因天气、光照等环境变化导致输出质量不可预测地下降,而传统精度指标需要真值标注,无法在线使用。
来自美国的研究团队提出了一种 LLM-as-Judge方案:将分割掩膜与原始图像叠加后送入多模态大语言模型(GPT-4o),让其输出质量评分、置信度和文字解释。通过严格的可重复性和敏感性实验,发现 GPT-4o 在相同输入下能保持稳定的离散评分(一致性 78--91%),并在雾、雨、雪等退化下置信度合理下降,表现出 "谨慎的评判者"特性,为无真值场景下的安全监控提供了新思路。
论文信息
-
标题:LLM-as-Judge for Semantic Judging of Powerline Segmentation in UAV Inspection
-
作者:Akram Hossain, Rabab Abdelfattah, Xiaofeng Wang, Kareem Abdelfatah
-
机构:美国多校联合
一、电力线分割的安全监控难题
无人机自主巡检电力线时,通常使用轻量化分割模型(如U‑Net)在机载端实时生成电力线像素掩膜。然而,真实环境下雾、雨、雪、阴影、反光等因素会使分割质量无声下降,而传统指标(IoU、像素准确率)均依赖真实标注,一旦部署便无法获知当前结果的可靠性。
目前主要依赖人工回放检查,但这严重削弱了自动化价值。因此,如何在没有真值时实时监控分割模型的可信度成为安全关键难题。
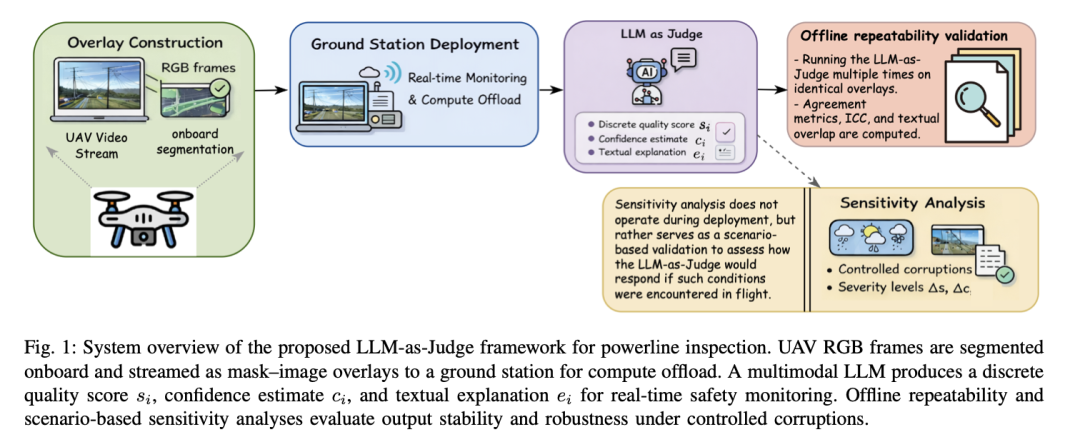
本文提出将 LLM-as-Judge作为独立评判器:机载模型输出分割掩膜,与原始RGB图像叠加后发送至地面站的GPT-4o,由大模型给出质量评分(1--5分)、置信度(0--1)和文字解释,从而实时判断当前分割是否可靠。
一、电力线分割的安全监控难题
无人机自主巡检电力线时,通常使用轻量化分割模型(如U‑Net)在机载端实时生成电力线像素掩膜。然而,真实环境下雾、雨、雪、阴影、反光等因素会使分割质量无声下降,而传统指标(IoU、像素准确率)均依赖真实标注,一旦部署便无法获知当前结果的可靠性。
目前主要依赖人工回放检查,但这严重削弱了自动化价值。因此,如何在没有真值时实时监控分割模型的可信度成为安全关键难题。
本文提出将 LLM-as-Judge作为独立评判器:机载模型输出分割掩膜,与原始RGB图像叠加后发送至地面站的GPT-4o,由大模型给出质量评分(1--5分)、置信度(0--1)和文字解释,从而实时判断当前分割是否可靠。
二、评判器的可靠性评估方法
为了验证GPT-4o能否担当此任,作者定义了可重复性 (相同输入输出是否稳定)和敏感性(对视觉退化是否产生合理响应)两个维度的评估。
图片来源于原论文
2.1 可重复性指标
设对于同一输入 x_i 重复运行 R=5 次,每次输出评分 s_i^(r) 和置信度 c_i^(r)。定义:
- 评分一致性(A_s):5次评分完全相同的图像占比
其中 (P) 表示当命题 (P) 为真时取 1,否则取 0(艾弗森括号)。
- 置信度一致性(A_c):5次置信度最大差值 ≤ 1e-6 的图像占比
- 组内相关系数ICC(1,1):衡量图像间差异与随机波动的比例,越高表示越稳定。
其中 σ_b^2 为不同图像间评分的方差,σ_w^2 为同一图像多次重复评分的方差。
2.2 敏感性指标
对每种退化类型 t 和严重等级 k(1--3级),计算相对干净图像的平均评分下降 Δs_{t,k} 和平均置信度下降 Δc_{t,k}:
同时计算配对效应量 (d_z)(标准化平均差值),用于判断响应是否显著(|d_z| > 0.8视为大效应)。
三、实验设置
-
数据集:TTPLA(约1100张航拍图像,电力线为细长目标)
-
分割模型:U‑Net(在TTPLA训练集上训练25轮)
-
退化生成:用Albumentations库添加 fog、rain、snow、shadow、sunflare 各3种严重等级。
-
评判器:GPT-4o(OpenAI API),固定 prompt 要求输出 {评分, 置信度, 解释}。
-
重复性实验:在干净图像和所有退化图像上各运行5次推理。
-
敏感性实验:对比干净与各退化等级下的输出变化。

图片来源于原论文
四、实验结果
4.1 可重复性
| 条件 | 评分一致性 (%) | 置信度一致性 (%) | ICC(1,1) | 联合数值稳定性 (%) |
|---|---|---|---|---|
| 原始(clean) | 81.11 | 70.05 | 0.858 | 69.59 |
| 太阳耀斑 | 82.49 | 60.83 | 0.901 | 60.37 |
| 阴影 | 80.18 | 54.38 | 0.880 | 53.46 |
| 雪 | 78.80 | 43.78 | 0.898 | 42.86 |
| 雾 | 90.78 | 33.18 | 0.917 | 33.18 |
雾天评分一致性反而最高(90.78%),因为雾导致分割几乎完全失效,所有掩膜接近空白,评判任务变得简单;而干净图像需精细判断多根电力线的局部质量,容易产生微小波动。ICC值始终≥0.858,说明图像质量相对排序稳定。
4.2 敏感性
| 退化 | 严重度 | 评分平均下降 | 置信度平均下降 | 评分效应量 (d_z) | 置信度效应量 (d_z) |
|---|---|---|---|---|---|
| 雾 | 1 | 3.124 | 0.736 | 3.426 | 3.453 |
| 雾 | 2 | 3.143 | 0.741 | 3.311 | 3.509 |
| 雾 | 3 | 3.115 | 0.732 | 3.393 | 3.419 |
| 雨 | 1 | 0.465 | 0.052 | 0.562 | 0.346 |
| 雨 | 2 | 0.581 | 0.067 | 0.764 | 0.558 |
| 雨 | 3 | 0.806 | 0.109 | 0.926 | 0.654 |
| 雪 | 1 | 0.700 | 0.101 | 0.718 | 0.489 |
| 雪 | 2 | 0.853 | 0.130 | 0.831 | 0.586 |
| 雪 | 3 | 0.963 | 0.147 | 0.959 | 0.647 |
| 阴影 | 1 | 0.631 | 0.071 | 0.852 | 0.604 |
| 太阳耀斑 | 2 | 0.558 | 0.067 | 0.699 | 0.457 |
-
雾天:评分和置信度均急剧下降(效应量>3.3),评判器明确警告分割不可靠。
-
雨/雪:随严重度增加,评分和置信度单调递减,效应量逐渐增大,显示合理的趋势响应。
-
阴影/太阳耀斑:影响较小且非严格单调,符合局部光照扰动不破坏几何结构的特点。
-
置信度变化更保守:非雾条件下置信度下降幅度显著小于评分下降,避免过度警告;而雾天置信度与评分同步大幅下降,体现"谨慎且区分性"的设计。
五、总结与展望
本文首次系统研究了LLM-as-Judge在电力线(细长目标)分割安全性监控中的可行性。实验证明:
-
可重复性:相同输入下离散评分高度一致(78--91%),ICC≥0.858,满足安全监控的基础稳定性要求;
-
敏感性:对雾、雨、雪等退化产生合理且统计显著的评分/置信度变化,且在严重退化时置信度谨慎下降。
该框架将分割模型的在线可靠性评估从"需要真值"转化为"语义可解释的评判",为大模型在无人机巡检等安全关键场景中作为"第三方看门狗"提供了实证支持。未来可进一步研究实时自适应阈值、多模型协作以及低延迟本地部署。
