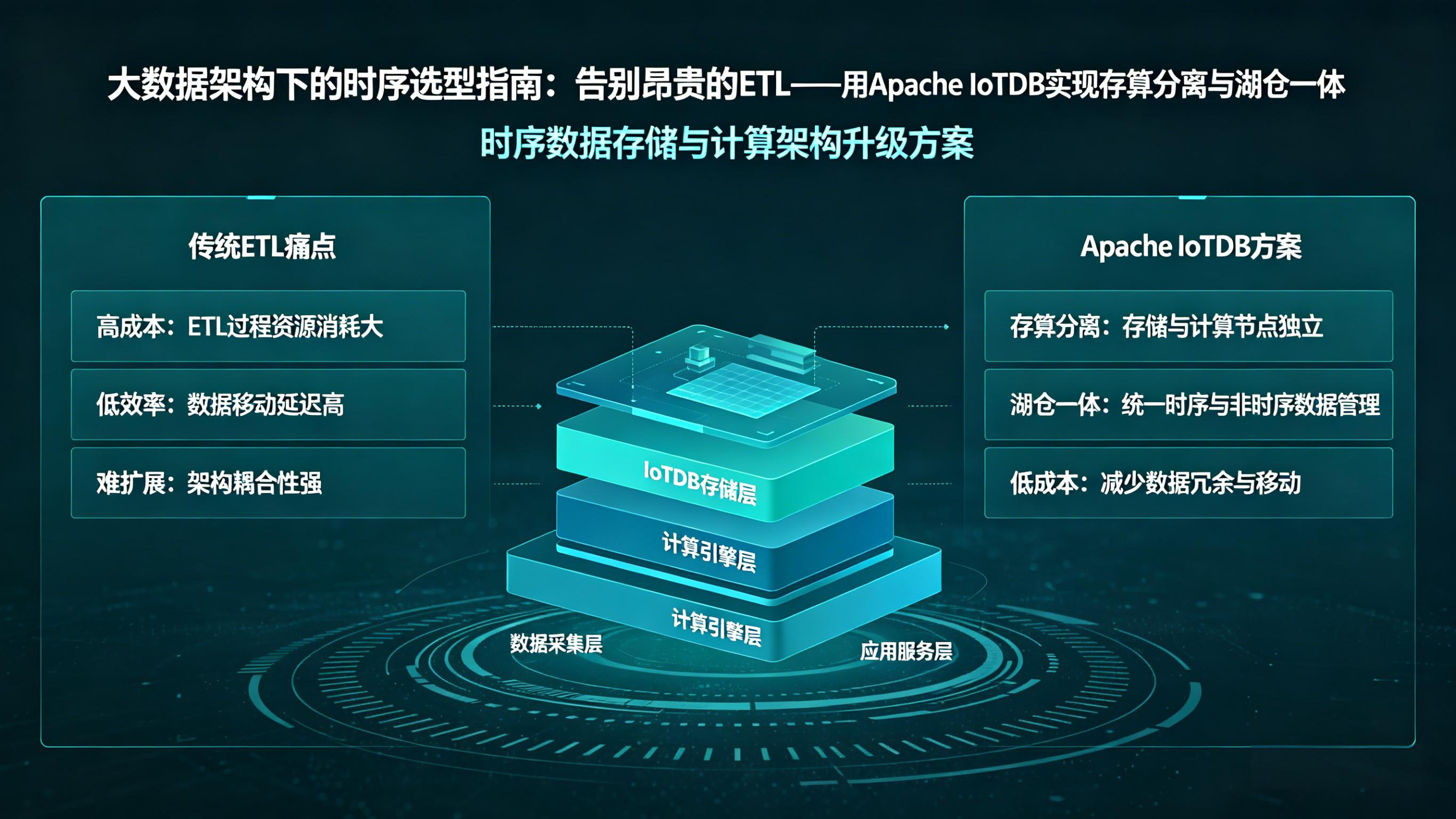
传统架构下,时序数据在 TSDB 中只能满足实时查询和看板需求,如果要做长期的大数据分析、模型训练,往往需要把数据通过 Kafka/Flink 或者定期 ETL 导出到 Hadoop/Spark 生态,这带来了高昂的存储冗余与传输成本。本文将从"大数据生态融合"与"存算分离"的角度探讨时序数据库的选型思路,并看看 Apache IoTDB 是如何破局的。
文章目录
-
- [1. 大数据架构下,为什么时序选型的关键是"文件格式"?](#1. 大数据架构下,为什么时序选型的关键是“文件格式”?)
- [2. 存算分离:两种常见的架构演进路线](#2. 存算分离:两种常见的架构演进路线)
-
- [2.1 路线 A:强耦合架构(常见于早期系统)](#2.1 路线 A:强耦合架构(常见于早期系统))
- [2.2 路线 B:湖仓一体与存算分离架构(现代化演进方向)](#2.2 路线 B:湖仓一体与存算分离架构(现代化演进方向))
- [3. Apache IoTDB 的解法:为时序而生的 TsFile 格式](#3. Apache IoTDB 的解法:为时序而生的 TsFile 格式)
- [4. 生态协同:让 Spark/Flink 无缝对接时序数据](#4. 生态协同:让 Spark/Flink 无缝对接时序数据)
-
- [4.1 Spark 读取 TsFile 的核心工程优势](#4.1 Spark 读取 TsFile 的核心工程优势)
- [4.2 场景代码示例:用 Spark 离线分析 TsFile 数据](#4.2 场景代码示例:用 Spark 离线分析 TsFile 数据)
- [5. 选型验收指南:如何用真实场景做对比测试?](#5. 选型验收指南:如何用真实场景做对比测试?)
- [6. 让时序数据库回归"数据资产"的本质](#6. 让时序数据库回归“数据资产”的本质)
- 资源链接
1. 大数据架构下,为什么时序选型的关键是"文件格式"?
在工业互联网和物联网蓬勃发展的今天,企业每天需要管理和接入的新增设备运行数据往往高达数十 TB。在这种海量数据规模下,数据库选型的痛点往往会从单纯的"写入吞吐量"向"整体架构的数据流转成本"转移。
传统架构下,企业往往会遇到以下三个无法回避的痛点:
- 痛点一:双份甚至多份存储成本极高。为了满足实时监控和设备看板的需求,企业通常会购买一套高配的时序数据库(TSDB);而为了做大数据的离线挖掘、报表生成或者训练机器学习模型,又必须把这部分数据清洗并存储到 HDFS 或 S3 上的 Parquet/ORC 文件中。同样的数据在业务流转中被存储了两份甚至多份,服务器的存储成本直接翻倍。
- 痛点二:ETL 链路脆弱且延迟高。从数据库通过 JDBC 批量拉取数据,或者通过 CDC(Change Data Capture)捕获数据变更,数据往往需要经过复杂的加工、降采样、时间戳对齐等操作。在工业场景中,设备网络可能不稳定,导致数据乱序到达,这让传统的 ETL 链路极易发生内存溢出(OOM)或者任务积压,运维人员每天都在处理报警和重跑任务。
- 痛点三:查询引擎不匹配导致分析极慢。传统大数据的列式存储格式(如 Parquet 或 ORC)主要针对关系型数据库的表结构设计,对时间序列特有的"时间+多测点"结构并不敏感。它们缺乏专门针对时间维度的编码和压缩机制,当 Spark/Flink 读取这类文件进行时序聚合时,需要耗费大量的 CPU 进行解压和过滤。
因此,站在整个大数据架构的顶层来看,能被大数据引擎原生识别、并支持高效压缩和处理的时序文件格式,才是降低整体架构成本的破局点。
2. 存算分离:两种常见的架构演进路线
在大数据时序场景下,企业通常会经历两种典型的架构演进路线,这也决定了他们在 TSDB 选型上的不同倾向。
2.1 路线 A:强耦合架构(常见于早期系统)
所有的读写、分析和计算都通过数据库的 API(如 HTTP 或 JDBC)进行。
- 优点:架构简单,适合起步阶段。
- 缺点:当离线的 Spark 任务发起大批量数据扫描时,会大量抢占数据库服务端的 CPU 和内存资源。这往往会导致线上的实时写入延迟急剧增加,Grafana 等实时看板加载缓慢甚至直接超时卡死。
2.2 路线 B:湖仓一体与存算分离架构(现代化演进方向)
底层数据以统一的标准文件格式落盘(如部署在 S3、HDFS 或 NAS 上),上层可以挂载多种异构的计算引擎。实时查询走轻量级的数据库进程,离线跑批走 Spark/Flink 直接读取底层的物理文件。
内存刷盘
对象存储/HDFS/本地盘
毫秒级实时查询
文件级高吞吐直读
流式读取
数据接入层(MQTT/Kafka/网关)
IoTDB(实时计算与服务引擎)
底层时序存储文件(TsFile)
数据湖底座
实时大屏/监控看板
Spark离线计算/模型训练
Flink流计算/实时告警
在这样的架构下,系统做到了真正的存算分离:数据库负责高频的数据写入和近线查询,大数据引擎负责海量的历史数据挖掘,双方共享同一份底层数据文件,互不干扰。
3. Apache IoTDB 的解法:为时序而生的 TsFile 格式
Apache IoTDB 的一个巨大工程价值,也是其区别于其他时序数据库的核心护城河,在于它不仅仅是一个运行在服务器上的数据库进程,更是包含了一套从底层从 0 到 1 自研的时序文件格式------TsFile 。
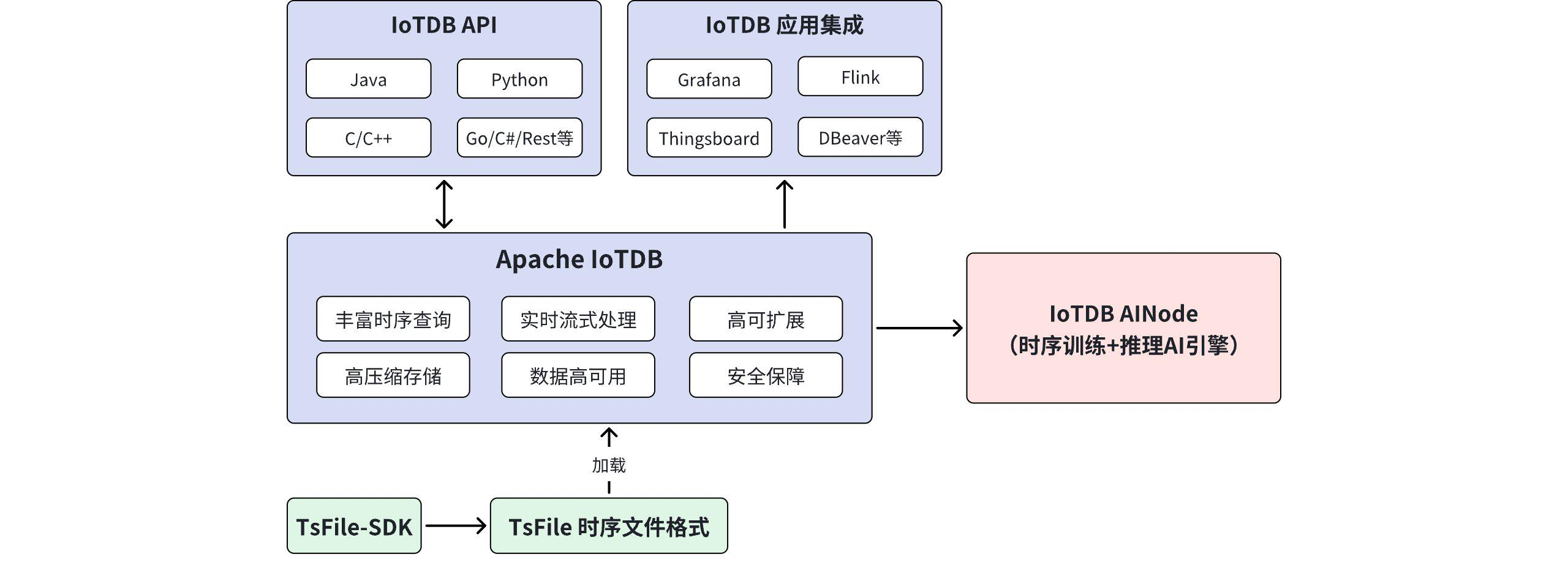
TsFile 可以被理解为"时序数据领域的 Parquet",它在选型和落地中具备以下无可比拟的优势:
- 极致的编码与高压缩比:根据官方资料,TsFile 针对时间序列数据的特性,采用了专有的压缩算法体系。例如,针对时间戳采用 Gorilla 编码或 RLE(游程编码),针对数值型采用二阶差分等算法,结合 Snappy、LZ4 等通用压缩技术,最高可以节省 90% 以上的存储成本。这不仅极大降低了磁盘采购费用,同时也成倍减少了大数据引擎读取时的 I/O 吞吐开销。
- 底层预计算机制(Pre-calculation) :TsFile 采用了"列式存储 + 分块机制"。在文件块(Chunk)和页面(Page)的头部,自带了丰富的元数据统计信息(如该块内数据的最大值、最小值、总和、数据条数等)。当执行类似于
SELECT MAX(temperature)的查询时,计算引擎可以直接读取块头部信息并返回,完全避免了去解压底层的原始明细数据,从而实现了接近 O(1) 时间复杂度的聚合查询。 - 独立性与跨引擎兼容:TsFile 格式是完全独立解耦的。它可以脱离 IoTDB 的服务端进程被独立读写。你可以用 Java、C++ 或 Python 的原生 API 在边缘端直接生成 TsFile,然后将其打包传输到云端;也可以在云端使用 Spark、Hive 等大数据组件直接挂载加载 TsFile,彻底绕开网络 RPC 瓶颈。
4. 生态协同:让 Spark/Flink 无缝对接时序数据
在企业进行时序数据库选型评审时,我们强烈建议将"大数据引擎的生态集成度"作为一个重要且必须验收的指标。IoTDB 官方通过其丰富的生态连接器(Connector),将时序数据与大数据体系完美融合。
4.1 Spark 读取 TsFile 的核心工程优势
在传统方式下,如果 Spark 要通过 JDBC 查询数据库,数据流转路径是:Spark -> Network RPC -> Database SQL Parser -> Database Disk I/O -> Network Return。这个过程极其漫长,且极易触发超时。
而使用 IoTDB 提供的 TsFile-Spark 连接器,数据流转路径变为:Spark Executor -> HDFS/S3 I/O -> 解析 TsFile 格式。Spark 的分布式 Executor 能够直接并行读取底层的物理文件块,吞吐量相较于 JDBC 方式提升了几个数量级,真正做到了"数据不搬家,计算就近执行"。
4.2 场景代码示例:用 Spark 离线分析 TsFile 数据
以下是一段演示如何在不启动 IoTDB 数据库进程的情况下,利用 Spark 直接对 TsFile 进行离线数据挖掘的代码片段:
scala
import org.apache.iotdb.spark.tsfile._
import org.apache.spark.sql.SparkSession
object TsFileAnalysis {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("TsFile Analytics")
.master("local[*]")
.getOrCreate()
// 1. 在 Spark 中直接加载 HDFS 上的 TsFile,无需任何数据库连接
val df = spark.read.tsfile("hdfs://namenode:9000/iotdb/data/sequence/root.plant01/0/0/1-1-0.tsfile")
// 2. 将时序数据注册为 Spark 临时视图
df.createOrReplaceTempView("sensor_data")
// 3. 结合 Spark 的强大算力,执行复杂的大数据分析(例如:关联外部的设备主数据表)
val result = spark.sql("""
SELECT
device_id,
AVG(temperature) as avg_temp,
MAX(vibration) as max_vib
FROM sensor_data
WHERE time > 1700000000000
GROUP BY device_id
""")
result.show()
spark.stop()
}
}在这种创新的湖仓一体架构下,IoTDB 数据库进程负责"热数据的高频实时写入与大屏监控查询",而 Spark/Flink 负责"冷数据的重度离线分析与流式处理",两者在系统资源上互不干扰,但底层却物理共用着同一套 TsFile 存储基座。这彻底告别了传统架构中昂贵、冗余且脆弱的 ETL 数据同步链路。
5. 选型验收指南:如何用真实场景做对比测试?
如果你或你的团队正准备用 Apache IoTDB 替代旧有的大数据时序存储方案,建议在选型的 PoC(概念验证)阶段,设计并实施以下测试:
- 准备真实数据集:提取至少 100GB 的真实工业场景时序数据(需包含典型的浮点数、整型、布尔值及状态枚举类型数据)。
- 多格式落盘对比:将同一份数据分别写入基于 Snappy 压缩的 Parquet 文件体系,以及原生的 IoTDB 集群(即 TsFile 格式)。
- 体积与性能量化 :
- 深度对比两种方案落盘后的实际物理文件大小。
- 在 Spark 中分别挂载这两种文件,对比执行全表扫描(Full Scan)和带有时间窗口过滤条件的
COUNT()、AVG()聚合查询耗时。
在大量真实的工业验证场景中(如中车四方、大唐先一等知名企业的实践),你会惊讶地发现:得益于 TsFile 专门针对时序数据的定制化编码体系,其文件体积往往只有通用列存文件(如 Parquet)的几分之一,且针对时间维度的查询和数据过滤速度具有压倒性的优势。
6. 让时序数据库回归"数据资产"的本质
优秀的系统架构应当遵循"数据不搬家"的原则。在评测和选型一款时序数据库时,除了关注表面的 QPS 写入吞吐等性能指标外,企业更应该将目光放得长远,去审视其底层文件格式的设计哲学与整个大数生态的开放性。
Apache IoTDB 凭借其从零自研的 TsFile 格式,彻底打通了实时时序监控与底层离线计算的壁垒。它既能以传统数据库的形态提供数千万点每秒的高并发写入与毫秒级低延迟查询,又能以数据湖核心组件的形态无缝融入 Hadoop/Spark 生态体系。对于那些亟需处理海量物联网、车联网、工业互联网数据的企业而言,选择 IoTDB 不仅仅是一次纯粹的技术框架升级,更是对企业整体 IT 基础设施存储成本与运维成本的一次成倍压缩。
资源链接
你可以先从开源版开始验证,重点观察它在你自己的数据模型和查询模式下是否顺手:
Apache IoTDB 下载链接:
https://iotdb.apache.org/zh/Download/
如果你所在的是企业项目,需要进一步了解企业级产品、服务和交付支持,可以再看:
企业版官网:
https://timecho.com
一个成熟的时序数据库,不应该只是"能存数据";
它更应该是你未来数年数据平台演进中的稳定底座。
从这个角度看,IoTDB 确实值得被认真评估,而不是只被当成一个"候选名字"。