昨天在重新构建服务时,遇到了一个非常"底层"的问题。最开始看日志,还以为是业务代码、依赖或者容器环境的问题,结果一路排查下去,最后发现问题根本不在 Python,而在虚拟机 CPU 指令集。
这篇文章就完整记录一下这次排查过程。
一、问题描述
1.1 部署失败
重新构建后,其中一个节点启动失败。日志如下:
bash
+ python main.py log.yml 5000
/usr/local/lib/python3.10/site-packages/polars/_cpu_check.py:259: RuntimeWarning: Missing required CPU features.
The following required CPU features were not detected:
avx, avx2, fma, bmi1, bmi2, lzcnt, pclmulqdq, movbe
Continuing to use this version of Polars on this processor will likely result in a crash.
Install the `polars-lts-cpu` package instead of `polars` to run Polars with better compatibility.
./web_entrypoint.sh: line 4: 39 Illegal instruction (core dumped) python main.py log.yml 5000 可以看到其中的关键错误:
bash
Illegal instruction (core dumped) 以及:
bash
Missing required CPU features:
avx, avx2, fma ...1.2 排查第一步:是不是 polars 崩了?
因为日志已经给了非常明显的提示:
bash
Install the `polars-lts-cpu` package instead of `polars` 因为 polars 默认会使用 AVX / AVX2 等现代 CPU 指令集优化 ,如果 CPU 不支持这些指令,在加载动态库时就可能直接触发:
bash
SIGILL(Illegal Instruction) 也就是说,Python 代码甚至还没真正开始执行,进程就已经被 CPU 杀掉了。
1.3 为什么只有一个节点出问题?
这里有个关键现象:不是所有节点都失败,只有其中一个节点失败。
这说明镜像本身没问题,requirements 没问题 ,代码没问题 ,只有某一台机器环境特殊。
于是我开始怀疑是不是这个节点的 CPU 指令集不对?
二、检查 CPU 指令集
先登录到失败的节点:
ssh xxx@xxx.xxx.xxx.xxx2.1 通过/proc/cpuinfo查看指令集
/proc/cpuinfo是 Linux 下的一个虚拟文件,可以使用cat查看:
bash
cat /proc/cpuinfo 里面包含CPU型号、核心数、cache、flags(支持的CPU指令集)。
这里的flags非常重要,例如:
flags : fpu vme de pse tsc ... avx avx2 fma bmi1 bmi2 因为很多深度学习框架:PyTorch、TensorFlow、ONNX Runtime 、llama.cpp 、vLLM都会检测这些 CPU 指令集。
2.2 通过正则提取目标指令集
从 Linux 的 CPU 信息中,提取当前 CPU 支持的一些关键指令集特性(如 AVX、FMA 等),并去重输出。主要用于检查 CPU 是否支持 AVX:
bash
grep -m1 -oE 'avx[0-9]*|fma|bmi[0-9]*|lzcnt|pclmulqdq|movbe' /proc/cpuinfo | sort -u 正常情况下应该看到:
bash
avx
avx2
fma
bmi1
bmi2
... 结果我运行后得到了一个空输出,这就非常异常了。
三、继续排查:CPU 型号是什么?
通过model name查看当前系统识别的CPU型号信息:
bash
grep -m1 "model name" /proc/cpuinfo3.1 正常输出
正常情况下,如果是在物理机器上,通常会看到类似:
bash
model name : Intel(R) Xeon(R) Gold 6230R CPU @ 2.10GHz| 字段 | 含义 |
|---|---|
| Intel® | Intel 处理器 |
| Xeon | Intel 服务器级 CPU 产品线 |
| Gold | Xeon 的中高端等级 |
| 6230R | 具体型号 |
| 2.10GHz | 基础主频 |
3.2 问题输出
QEMU Virtual CPU version 2.5+ 说明当前环境并不是真实物理 CPU,而是运行在 QEMU 虚拟化环境中。
(1) QEMU是什么
QEMU 是一个开源的虚拟机 、硬件模拟器 、CPU 模拟器。
它可以模拟不同 CPU 架构、创建虚拟机、提供隔离运行环境。
很多场景都会使用 QEMU: 云服务器、Docker底层虚拟化、KVM、CI/CD环境、模型沙箱、安全隔离环境。
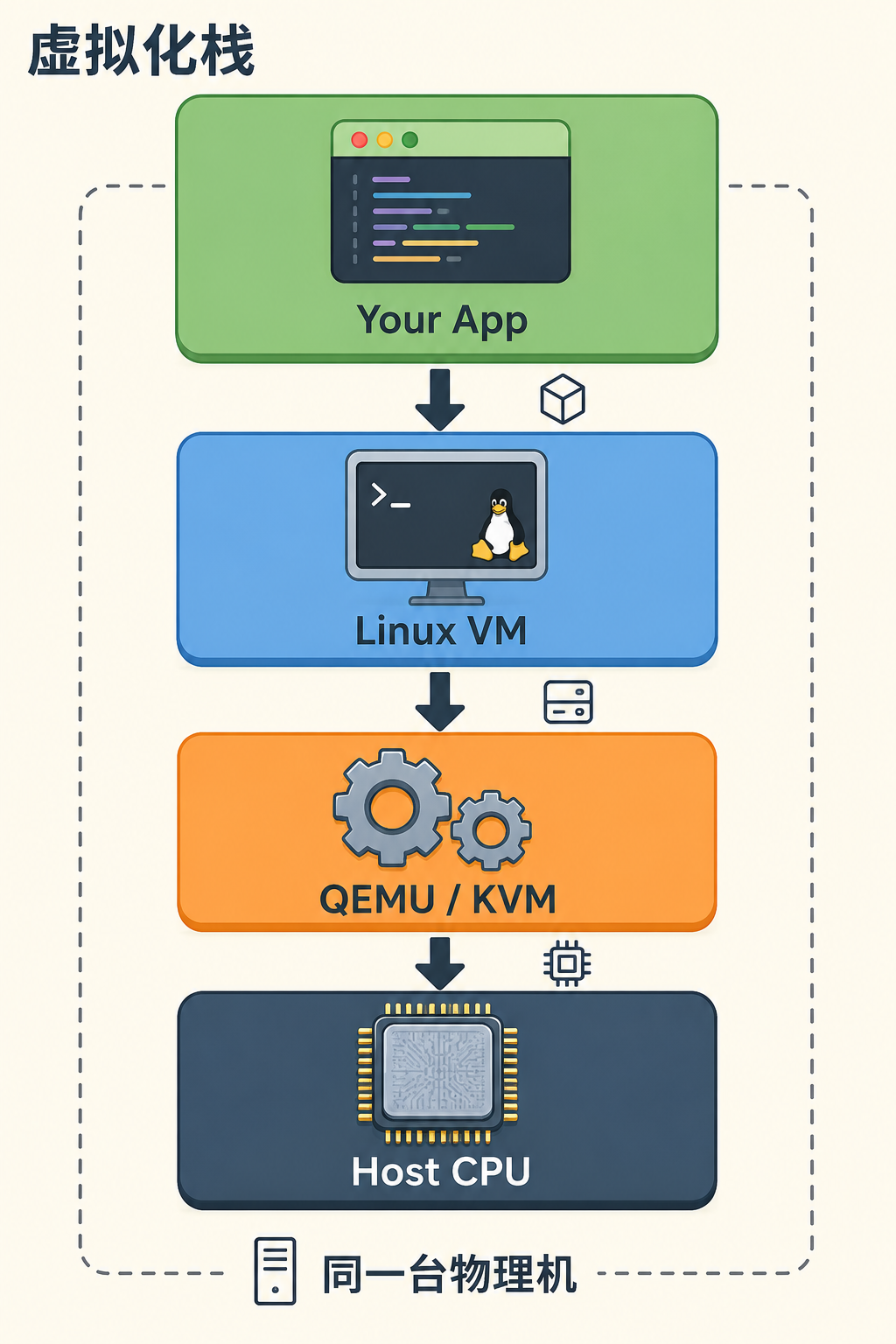
这张图用堆叠的方式呈现了从硬件到应用的四层抽象:底层物理 CPU 是唯一真实的算力来源,QEMU/KVM 在其上构造出"假装是CPU"的虚拟硬件,Linux 虚拟机把这套假硬件当真硬件来跑内核,最上层你的程序则完全感知不到自己其实活在第三层之上。层与层之间的箭头方向也提示了一个关键事实,上层的每条指令最终都要落到最底层的物理 CPU 上执行。
四、问题根源:QEMU 使用了通用 CPU 模型
通过上述CPU型号的输出说明当前虚拟机并没有直接暴露宿主机 CPU。而是使用了qemu64。
这种模式的特点是兼容性高、迁移方便、但会屏蔽 AVX / AVX2 等高级指令集。
因此,即使物理机实际上支持 AVX,虚拟机里也完全看不到。
4.1 为什么会突然这样?
后来同事提到这台机器之前做过一次迁移,这就完全对上了。
因为很多虚拟化平台在 VM 迁移时,会默认把 CPU 模型降级成qemu64,目的就是保证 VM 可以迁移到不同 CPU 型号的宿主机上。
代价则是AVX / AVX2 / FMA 等高级指令全部被隐藏。
4.2 为什么 polars 会直接崩?
因为 polars 的默认构建会开启 AVX 优化,动态库内部直接使用 AVX 指令。而当前 VM根本不支持 AVX,于是 CPU 在执行指令时直接触发:
SIGILL
Illegal instruction 进程被系统杀掉。
五、解决方案---修改虚拟机 CPU 模式(推荐)
这是根治方案。
5.1 KVM / libvirt
修改 VM 配置:
<cpu mode='host-passthrough' check='none'/> 或者:
<cpu mode='host-model'/> 让 VM 直接透传宿主机 CPU 指令集。
5.2 QEMU
启动参数改成:
-cpu host 而不是:
-cpu qemu645.3 修改后一定要:
power-cycle(关机再开) 不能只是 reboot,因为 CPU 特性是在 VM 启动时协商的。
六、这类问题为什么容易误判?
因为表面现象非常像:Python 崩溃 /Docker 问题/依赖问题/C 扩展问题 。但实际上是 CPU 指令集问题。
尤其是Illegal instruction这个错误。很多人第一反应是代码有 bug。实际上确是CPU 不认识这个指令。
七、以后再遇到 Illegal instruction 怎么排查?
7.1 Step1:先确认 CPU 支持哪些指令集
第一件事,不是重装环境。而是先确认当前机器到底有没有 AVX / AVX2 / FMA?
cat /proc/cpuinfo 或者:
lscpu 重点看flags部分,例如:
bash
flags : ... sse4_2 avx avx2 fma ... 这里 avx、 avx2 、 fma 代表 CPU 支持对应 SIMD 指令。
如果没有avx但你的程序用了 AVX 指令,那么一定会发生这个问题。
7.2 Step2:确认是不是运行在虚拟机里
有时候物理机支持 AVX2,但虚拟机不支持。
继续查看:
grep -m1 "model name" /proc/cpuinfo 如果看到:
QEMU Virtual CPU 或者:
Common KVM processor
Virtual CPU 基本说明你运行在虚拟化环境中。
这里要开始思考一个关键问题:虚拟机暴露的CPU kennel不是宿主机真实的CPU。也就是说宿主机可能是 Xeon Gold,但 VM 里看到的是"精简版 CPU" 。
虚拟化平台为了做热迁移、保证兼容、统一集群,通常不会把全部 CPU 指令暴露给 Guest。于是就会出现这个问题,这也是很多线上问题最容易忽略的一点。
7.3 Step3:思考"是不是迁移导致的"
如果以前能跑、迁移后跑不动,或者换了节点之后偶发失败,第一反应应该是怀疑 CPU model 被悄悄降级了。
很多虚拟化平台和云厂商,为了让虚拟机能在不同物理机之间自由迁移,会统一各台宿主机暴露给 VM 的 CPU能力取交集,砍掉高级指令集。 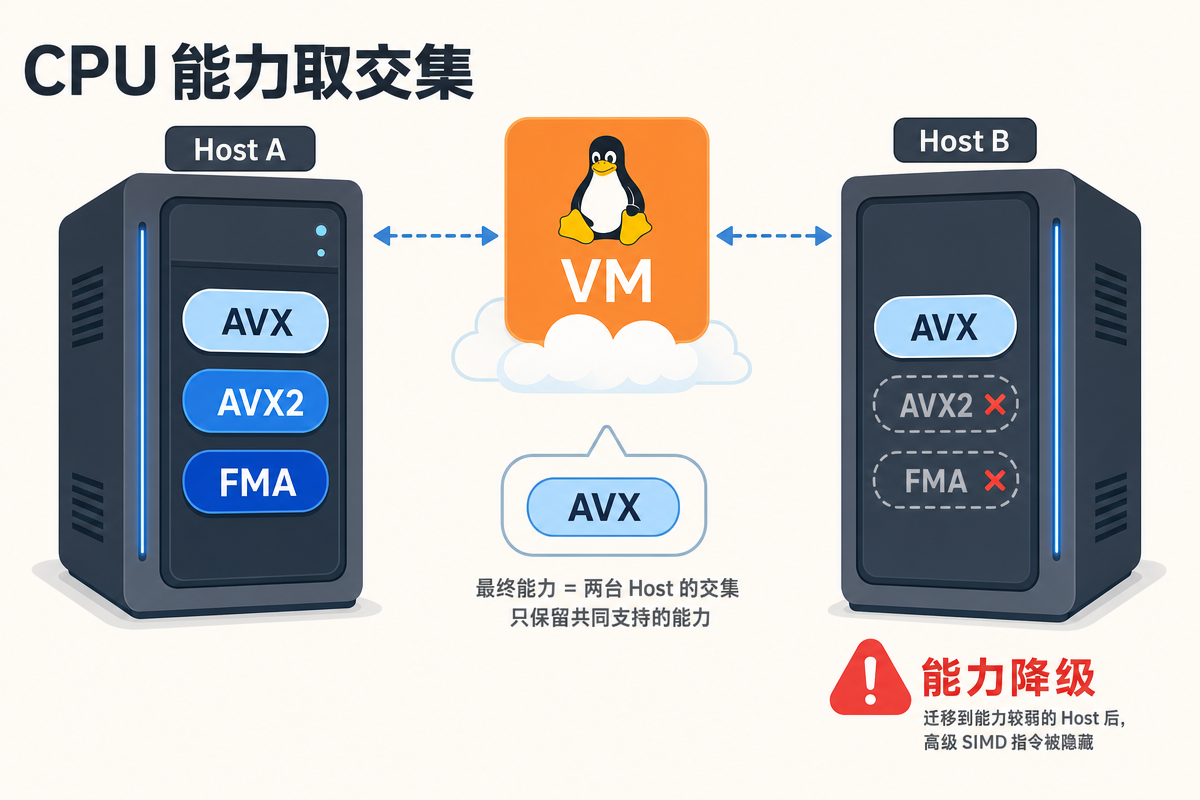
- 举个最常见的场景:
-
Host A: AVX2 + FMA
-
Host B: 仅 AVX
为了让虚拟机能在 A、B 之间随便漂移,平台干脆只对 VM 暴露 AVX。于是同一份程序、同一套环境、同一个镜像,昨天在 A上跑得好好的,今天到 B 上就 illegal instruction 了。
-
本质上,变的不是你的代码,而是 VM 看到的 CPU 能力。 这一步特别值得强调,是因为大多数人遇到这种问题的第一反应都是去折腾用户态------重装 Python、重装 CUDA、重新编译PyTorch、换镜像版本,折腾一圈发现毫无效果。因为问题根本不在那一层:上面所有东西一个字节都没变,是底下那块"虚拟CPU"被换了。
所以排查顺序应该反过来:先用 cat /proc/cpuinfo | grep flags 对比迁移前后的指令集差异,确认 CPU 能力是否一致,再去怀疑用户态。
7.4 Step4:确认是不是 SIMD 优化库触发的
很多现代科学计算库为了性能,会默认启用SIMD、向量化、CPU 特化优化 。常见的"重灾区"包括:
- numpy(尤其是带 MKL 的版本)
- polars、pyarrow
- pytorch、tensorflow、jax
这些库的典型行为是运行时动态探测 CPU 能力,再挑一份最快的 kernel。检测到 AVX2 就走 AVX2 内核,检测到 AVX-512 就走AVX-512 内核。这套机制在裸机上工作得很好,但一旦放进虚拟机,就有几个地方会出岔子:
-
检测逻辑误判:库读到的 CPU flags 和 VM 实际能执行的指令对不上
-
Guest 和 Host 信息不一致:VM 宣称支持 AVX2,但底下的 vCPU 模型其实砍掉了
-
wheel 编译目标过高:预编译包是在带 AVX-512 的机器上用 -mavx2 -mfma 打的,强制要求运行环境也具备这些指令
程序加载 AVX2 指令
↓
CPU 实际不支持
↓
Illegal instruction
这类问题最容易在一个场景下中招:pip install 装预编译 wheel。 因为PyPI 上很多包提供的是别人在高配机器上用 -mavx2 -mfma 甚至 -mavx512f 编出来的 wheel,整段二进制里都是硬编码的高级指令,它不做运行时探测,也没有降级路径,假设你的 CPU一定支持。一旦运行环境是个砍过指令集的 VM,程序连 import 都过不去就直接崩。
排查思路也很直接:
- 用
python -c "import numpy; numpy.show_config()"看看链接的是哪份后端 - 怀疑是 wheel 问题时,加
--no-binary :all:强制从源码本地编译,让编译器以当前 CPU为目标 - 或者直接装"通用版本"(如 numpy 不带 MKL 的纯 OpenBLAS 构建),牺牲一点性能换可移植性
八、总结
这次问题本质上不是Python问题,也不是Docker问题,而是VM 迁移后,CPU 模型退化成了 qemu64,导致 AVX 指令集被隐藏。最终导致polars 加载动态库时触发 SIGILL。
这种问题非常"底层",但在 AI / 数据处理场景里会越来越常见。因为现在很多高性能库默认都假设 CPU 至少支持 AVX,所以以后看到:
Illegal instruction (core dumped) 不要只盯着代码,也要记得看看/proc/cpuinfo。