作者:汤祯捷 · 阿里云智能集团计算平台事业部 AI 搜索产品负责人 ,Elastic 中国 AI 搜索大会演讲实录 · 2026.4.18
导读: 2026 年的 AI 搜索,早已不是"接个 Embedding 模型 + RAG 框架就能交付"的时代。当我们真正面对千亿级知识库、百亿级日查询、真金白银的成本约束时,才发现每一个百分点的优化,都是几十万上百万的差距。本文基于阿里云 Elasticsearch 服务数十家头部客户的实战经验,从搜索融合、效能实践、AI 搜索演进三个维度,分享这条踩坑、迭代、再升级的路。

一、被三句客户原话敲醒的 2026
2026 年了。AI 搜索这个赛道,从 2023 年 RAG 爆火到现在,已经走过了快三年。
这三年里,我们服务了数十家头部客户------互联网大厂、金融机构、政企部门、电商平台、制造企业。大家来自不同行业,但坐下来聊痛点的时候,说的话越来越像。
浓缩成三句。
第一句:"我能不能就搜一次,你别让我来回切。"
先试关键词,搜不到转向量,再不行换 Embedding 模型------这个体验太差了。
第一个挑战:搜索融合,一步搜到。 关键词检索和向量检索不该让用户手动切换。
第二句:"架构要升级,但预算不能涨。"
每个客户都希望用最好的架构、最新的模型、最炫的方案------但看到报价的时候,反应一模一样:这个成本,CEO 不会批的。
第二个挑战:极致效能,规模成本。 不是有无限算力,而是在有限预算里榨出最大性能。
第三句:"搜出来的东西,得能用,不能只是看看。"
很多客户说:"你们 RAG 跑通了,答案也生成出来了,但我要的不是文字,是可执行的决策。"
第三个挑战:全局洞察,精准执行。 语义检索必须精准,消除幻觉,知识要能融汇贯通到自主执行。
三句话归结为一个核心命题:企业级 AI 搜索,不能只是 Demo,不能只是 POC,它要能在生产环境、千亿级规模、真金白银的成本约束下,稳定跑起来。
二、搜索融合:从手动拼凑到原生智能
2.1 为什么向量检索不是万能药
2023 年,Embedding 模型开始普及。text-embedding-ada-002、BGE、m3e,一波又一波好模型出来。行业的气氛是:BM25 可以退休了,向量检索是未来。
但真实场景给了沉重的一击。
一个金融客户,知识库里有大量专业术语、产品代码、监管条文。上线向量检索后,用户搜"K8s 部署失败",返回的 Top 1 是一篇关于"容器化改造"的通用文章------语义上确实相关,但不是用户想要的那篇具体故障排查文档。真正的文档排在第七位。
原因:Embedding 模型对"K8s"和"Kubernetes"的语义对齐不够好,对"部署失败"和具体错误码之间的关联也理解不精准。
我们遇到的 第一个问题,叫语义漂移。向量模型对某些专业术语、缩写、专有名词的理解并不准确。
第二个问题更普遍:精确匹配丢失。
搜一个订单号"DD2026041800001",一个 SKU 编码,一个错误码"ERROR_CODE_500_INTERNAL"------这些查询的本质是精确匹配。向量检索会把它们和一堆"语义相近但不相关"的结果混在一起。
第三个问题是冷启动。新知识库建好,文档上传了,Embedding 还没全部生成,用户就开始搜了。纯向量检索怎么办?直接返回空。
第四个问题是调优成本 。换一个新 Embedding 模型,整个向量索引要重新生成。百万级数据量只要几小时,千亿级数据量是以天为单位。
结论:向量检索和 BM25 不是替代关系,是互补关系。
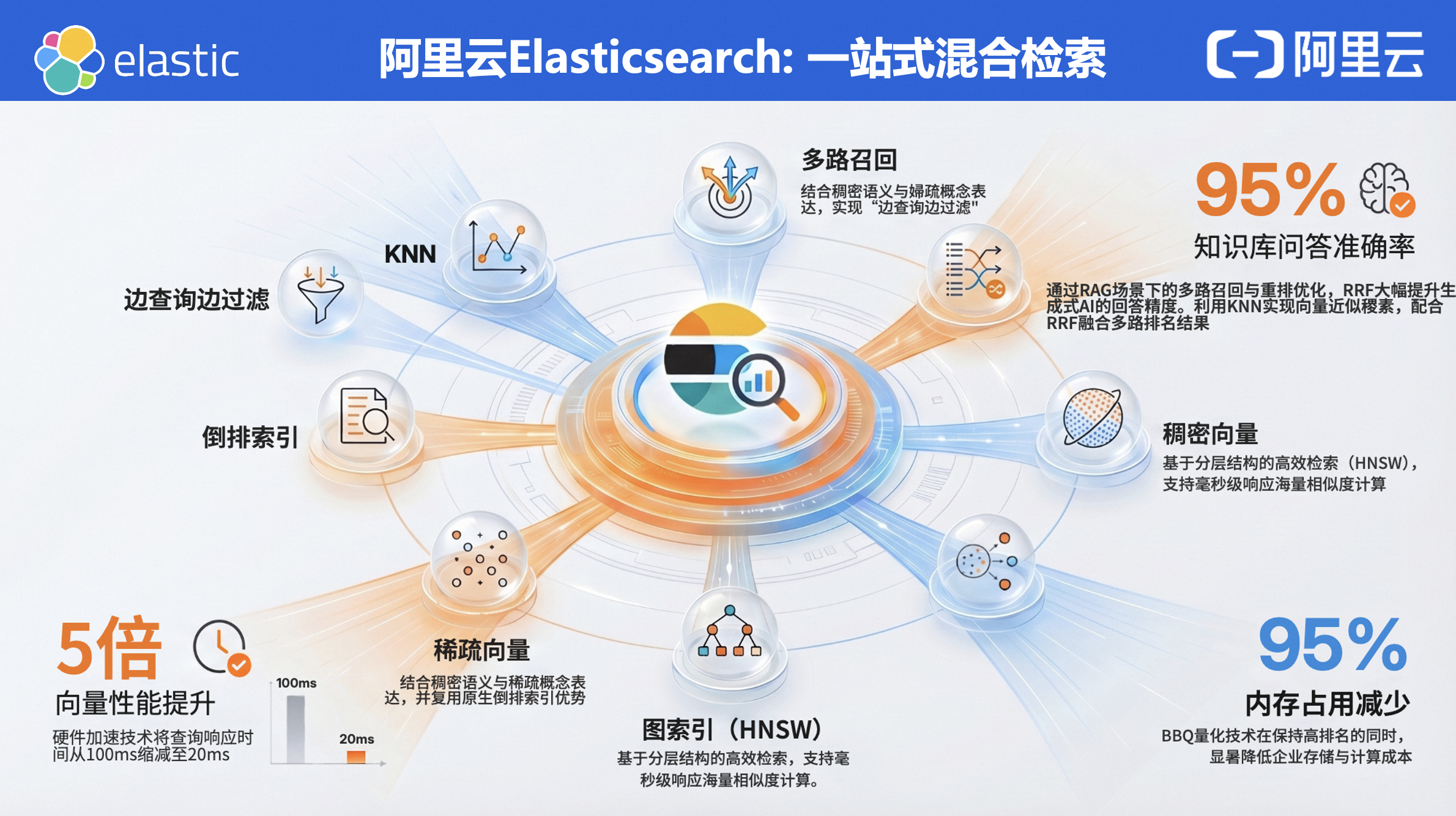
向量检索的长板是语义泛化,短板是精确匹配;BM25 的长板是精确匹配和冷启动,短板是语义理解。把两个长板拼在一起,才是正解。基于这个认知,阿里云 Elasticsearch 做了一件事:一站式混合检索
2.2 RRF 的优雅之处
一站式混合检索 首先实现------多路召回 + RRF 融合的统一架构。
RRF(Reciprocal Rank Fusion,倒数排名融合)的核心思想非常优雅:不比较不同检索通道的绝对分数,而是比较它们的排名。
BM25 给了文档 A 分数 0.95、文档 B 分数 0.87;向量检索给了文档 A 分数 0.72、文档 B 分数 0.91。两套分数体系完全不同,直接相加没有意义。
RRF 的做法是:用 1/(60+排名) 来做融合,60 是平滑参数。不同检索通道的分数天然归一化,不需要任何人工调权重。
具体从四个通道同时召回:
-
传统倒排索引:基于词汇的精确匹配,搜订单号、错误码、专有名词最靠谱
-
稠密 Embedding 向量:捕获深层语义,"怎么优化数据库性能"能找到"SQL 调优最佳实践"
-
稀疏 Embedding 向量:类似 SPLADE 的语义关键词提取,介于 BM25 和稠密向量之间
-
原生倒排索引兜底:确保即使前三路都没结果,用户也能看到相关内容
实际效果:在多个客户的 A/B 测试中,混合检索的 NDCG@10 比单一向量检索平均提升了 15% 到 25% 。在专业术语和精确匹配场景下,提升达到 40% 以上。
NDCG 提升 10%,用户满意度就有明显的感知提升。
2.3 混合检索的相关性优化
RRF 只是起点。只做到 RRF,只能说跑通了,还没跑好。
优化一:Pre-filtering KNN,边查询边过滤
传统做法是先做全量向量相似度计算,再在结果上做过滤。千亿级数据量下,算了数百万向量的相似度,过滤条件一卡------99% 的结果被过滤掉,白算了。
Pre-filtering KNN 在向量检索的同时就考虑过滤条件,利用过滤条件剪枝。延迟降低 40% 到 60%。
优化二:动态相似度阈值
不同查询适合的阈值不同。搜"阿里云 Elasticsearch 怎么开通"------意图清晰,阈值应收紧;搜"搜索优化"------意图模糊,阈值应放宽。系统根据查询分布特征自动调整阈值。
2.4 从 1.0 到 2.0 的四次进化
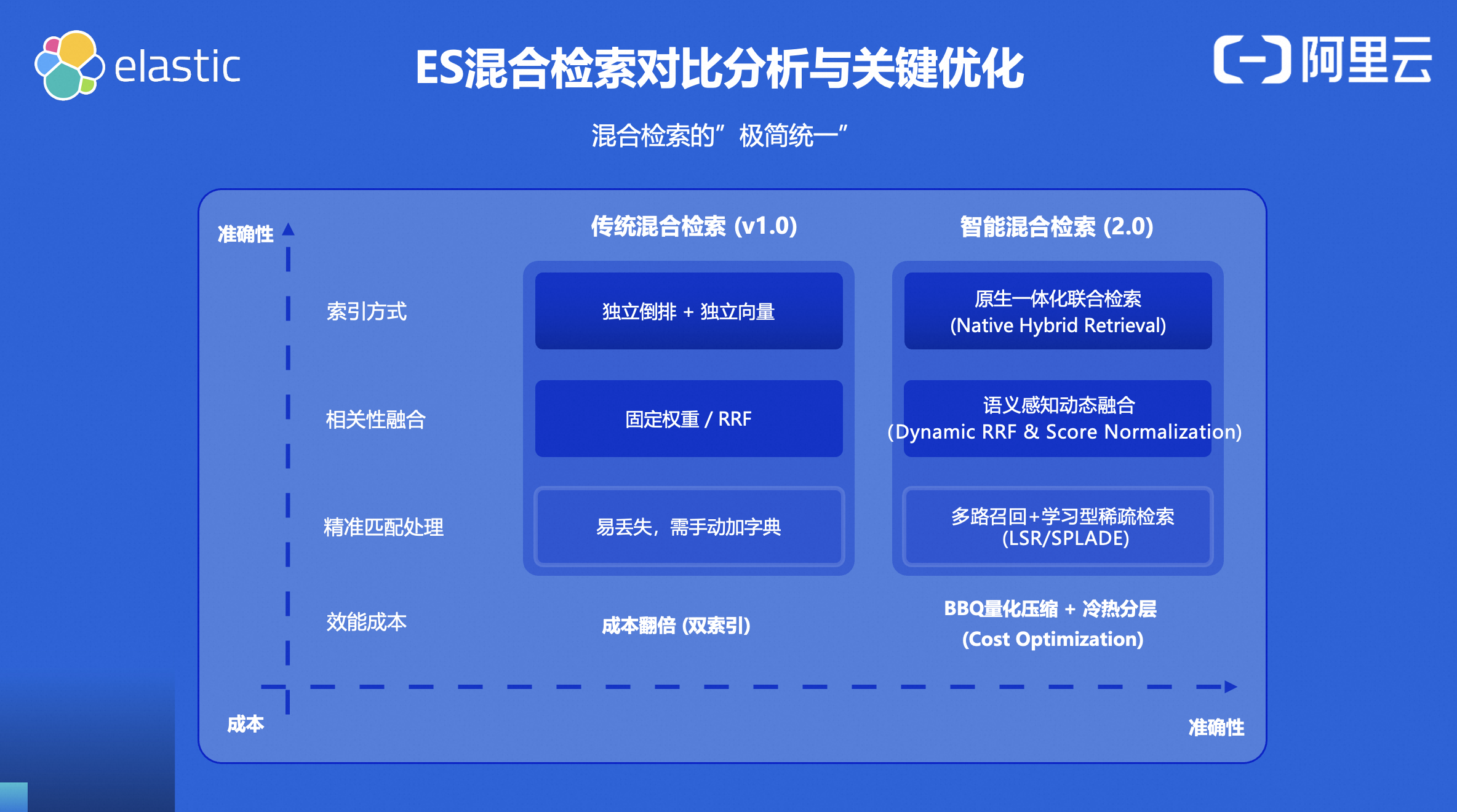
混合检索 1.0 版本:独立倒排索引 + 独立向量索引,两套系统各干各的,最后用 RRF 拼一下,固定权重融合,成本高------双索引,存储和计算都翻倍。
2.0 版本实现了四个关键进化:
| 维度 | 1.0 | 2.0 |
|---|---|---|
| 检索架构 | 独立引擎拼接 | 原生一体化联合检索,索引层面融合 |
| 权重策略 | 固定权重 RRF | 语义感知动态融合,查询特征自动调权 |
| 稀疏检索 | BM25 | 学习型稀疏检索(LSR + SPLADE) |
| 成本优化 | 双索引存储 | BBQ 量化压缩 + 冷热分层 |
从"手动拼凑混合检索"进化到"原生一体的智能检索"。
三、效能实践:千亿级背后的五管齐下
千亿级知识库检索,意味着数百 TB 文档数据、数百万到数千万文档切片、数亿次日查询请求、P99 延迟在几百毫秒以内。
在这样的规模下,每一个百分点的成本优化都是几十万上百万的真金白银。

3.1 硬件降级的反常识
第一个尝试很简单:把贵的存储硬件换成便宜的。
把磁盘从 PL1(高性能云盘)降级到 PL0(基础云盘)。
敢这么做的核心判断:向量检索的核心瓶颈在内存,不在磁盘。
向量先加载到内存,在内存中做相似度计算。磁盘主要做持久化存储和冷数据加载,IOPS 不是决定性因素。
结果:存储成本降低了 50%,吞吐量反而提升了。
因为 PL0 RAID 做了条带化,多盘并行读取,整体吞吐量反而上升。
但硬件降级到一定程度就会触及天花板------高并发写入场景下,PL0 的 IOPS 瓶颈暴露,写入延迟飙升。
需要第二把刀:逻辑层面的优化。
3.2 10% 热数据覆盖 80% 查询
这是投入精力最多、效果最显著的方案。
核心思想:把 10% 的热数据和 90% 的冷数据,分开对待。
搜索系统的查询分布是典型的幂律分布:约 10% 的文档,承担了 80% 以上的查询。
这意味着:给 100% 数据都构建同样高质量的索引,90% 的索引成本就是浪费的。
热索引(Hot Index): 为 10% 热点数据构建完整的 HNSW 图索引。HNSW 速度快、精度高,但吃内存------千亿级数据量全量构建,内存成本是天价。
冷索引(Cold Index): 90% 的冷数据降级为纯暴力检索(Flat 或 IVF)。冷数据查询频率低,对延迟要求不高------一个用户一个月只搜一次冷数据,P99 延迟 200ms 和 50ms,感知差异几乎为零。
效果:单节点内存需求暴降 70%,计算规格直接减半,整体成本砍了一半。
原来需要 128G 内存的节点,现在 64G 就够了。
| 维度 | 热索引 | 冷索引 |
|---|---|---|
| 索引结构 | HNSW 多层导航图 | Flat / IVF 暴力检索 |
| P99 延迟 | < 50ms | 200-300ms |
| 查询占比 | > 80% | < 20% |
| 内存占用 | 高 | 低 |
| 用户感知 | 快 | 无差异(因为查询少) |
3.3 Ingest Pipeline 智能流量路由
怎么判断一个查询走热索引还是冷索引?
通过 Ingest Pipeline 自动给文档打标签,三个维度:
-
更新时间:新文档默认为热文档
-
访问频率:被查询越多的文档,热等级越高
-
业务重要性:某些文档即使查询不多,但业务上重要,也标记为热
查询阶段,系统根据关键词的热度特征动态决定走热索引还是冷索引,或两者并行。
整个流程对用户透明。 用户不关心热和冷,只关心搜得快不快、准不准。
3.4 双效合一:FalconSeek引擎 + 存算分离架构
光有架构优化还不够,引擎本身也得跟上。
自研内核引擎 FalconSeek:
-
文本与向量检索性能比开源 ES 提升 2 到 6 倍
-
ES|QL 多维检索分析,SQL 算子覆盖 90% 使用场景
-
引入 GPU 加速,向量聚合场景性能提升一个数量级
-
云原生 DSL 查询加速 3 倍 以上,ANN 向量检索优化 1 倍以上
-
Lucene 10 支持,提升存储压缩率和倒排索引查找效率
-
针对高并发写入场景的 GC 停顿优化
云端存算分离架构:
-
智能混合存储:多级缓存 + 存储层预读,减少本地盘大小
-
自适应数据复制:根据数据重要性和访问模式动态选择复制策略
-
冷热共享计算资源:高峰期自动扩容,低峰期自动缩容
从日志到检索,成本降低 70% 到 40%。
五管齐下:存储介质降级、冷热索引分层、智能流量路由、内核引擎升级、存算分离架构。少一管,效果打折。
四、AI 搜索演进:RAG 三代到 Agentic RAG
4.1 RAG 三代各自踩了什么坑
第一代:Native RAG(2023 年)
流程:文档切片 → 向量化 → 相似度检索 → 注入 LLM → 生成答案。
问题:
-
Bad Chunking:知识边界不在 500 字整数倍上,一个知识点被切成两半,一半在 chunk 100,一半在 chunk 101
-
低秩检索:搜"怎么部署微服务",召回的可能是"什么是微服务"
-
幻觉率高:LLM 基于不完整或不准确的信息生成答案
第二代:Advanced RAG(2024 年)
引入 Query 改写、重排、多路召回。效果提升了,但新问题来了:
-
多路召回融合难
-
"什么是微服务"和"怎么部署微服务"语义相似度都很高,但一个是概念解释一个是操作指南
-
多跳查询、跨文档推理,搞不定
第三代:Modular RAG(2025 年至今)
模块化:实时搜索、离线处理、LLM、Agent 各司其职,灵活组合。新问题:
-
路由决策失效------系统不知道该走哪个模块,走错了整个链路就错了
-
模块越多,链路越长,出问题的概率越大
-
多轮对话中上下文状态怎么维护?
RAG 的下一个形态是什么?
4.2 AgenticSearch 的两个关键组件
答案是:Agentic RAG------搜索即智能体。
传统 RAG:用户提问 → 系统检索 → LLM 生成答案。一条直线,从头到尾。
Agentic RAG:系统先理解意图 → 规划检索策略 → 多轮检索与推理 → 自主执行 → 知识迭代更新。
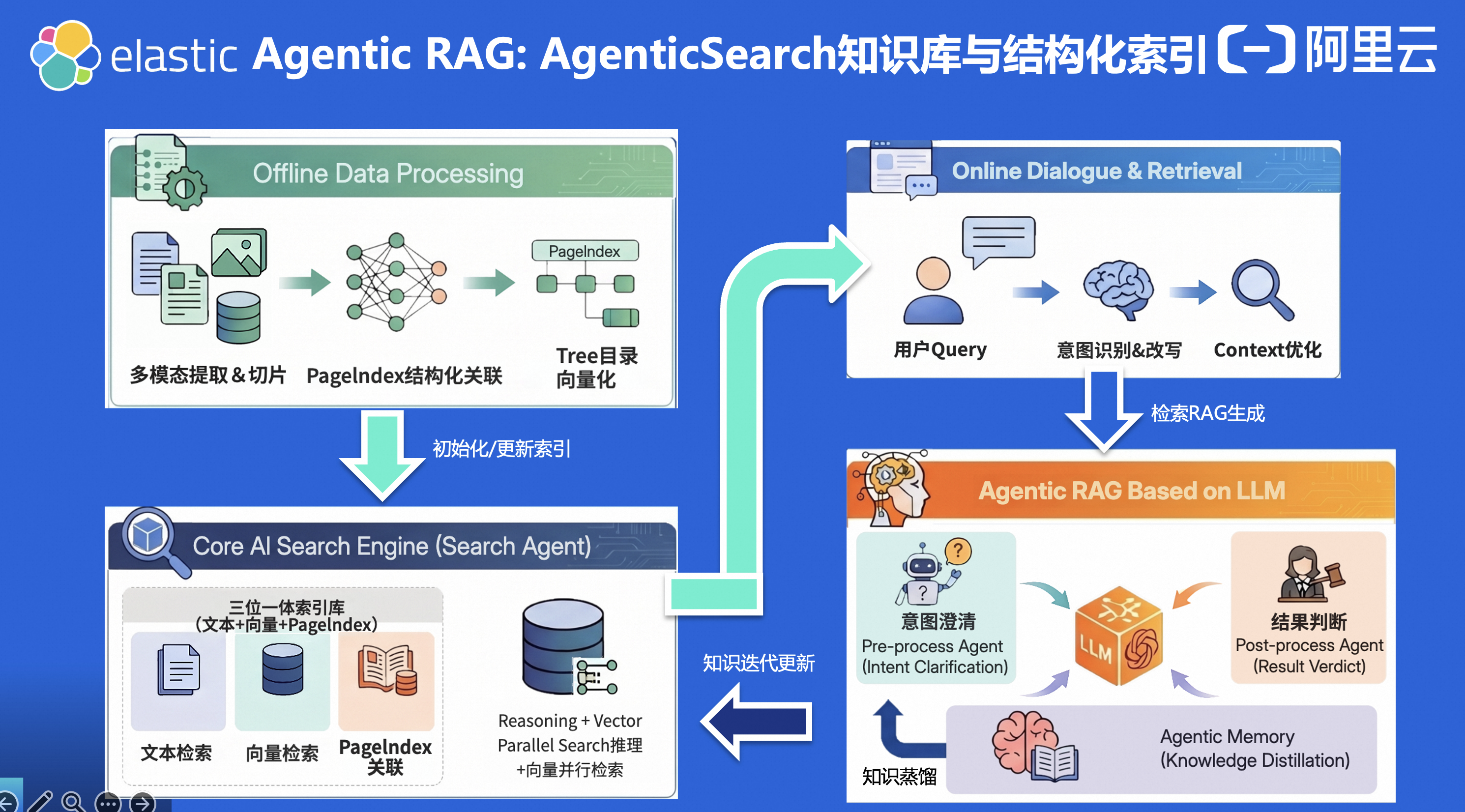
两个关键组件:
组件一:支持结构化索引的AgenticSearch 知识库
传统 RAG 的知识库是文档切片后的向量集合,flat 的、没有结构的。
AgenticSearch 的知识库是结构化知识图谱。系统不仅知道每个 chunk 的内容,还知道 chunk 之间的关系------这篇文档是那篇的前置知识,这个知识点属于那个知识域,这个操作步骤有三个前提条件。
有了结构化理解,就能进行多跳推理。
用户问:"我的数据库 CPU 飙高了,怎么办?"
AgenticSearch 先理解这是运维问题 → 检索数据库监控知识库找到 CPU 飙高的可能原因 → 检索对应的排查文档 → 检索解决方案。多跳检索,一步步来。
组件二:知识迭代更新机制
检索结果的质量反馈回来,用于优化索引。用户标记"没有帮助"的检索结果,系统记录下来,下次调整策略。索引更新反过来提升检索效果------这是一个闭环。
从"搜出来给模型"进化到"系统自己知道该怎么搜、搜什么、搜完之后怎么办"。
4.3 阿里云 AI 搜索开放平台全栈打通
这套 Agentic RAG 能力已经产品化:阿里云 AI 搜索开放平台 & 百炼 MaaS。
核心能力一览:
| 能力 | 说明 |
|---|---|
| 多模态搜索 RAG | 文本、图片、视频检索,上传故障截图自动理解内容 |
| AgenticSearch | 从被动检索升级到主动智能执行的搜索Agent |
| DeepResearch | 复杂分析型问题自动拆解子问题,多轮检索综合分析 |
| 百炼模型 API | Qwen3.5、Qwen3.5-Max、DeepSeek 等大模型一站式接入 |
| 向量排序模型 | Qwen-Embedding、Reranker 开箱即用 |
| 多模态解析 | 文档/图片解析、视频截帧、语音识别 |
| 智能助手 Agent | 集群监控运维、产品知识问答 |
从底层检索引擎到上层 AI 应用,全栈打通。
五、双线演进:LLM应用与AI搜索技术的同频
一张图,总结全部内容。两条线同步演进:

左侧:AI 大模型应用
| 时间 | 大模型应用 | 关注点 |
|---|---|---|
| 2023-2024 | Prompt Engineer | "如何问"------调整提示词结构、语气、少样本示例 |
| 2024-2025 | Context Engineer | "喂什么"------企业文档切片、召回、组装高质量 Context |
| 2026 | Harness Engineer | "如何度量、调度与提效"------多 Agent 协作、海量并发、动态工具调用 |
右侧:AI 搜索技术迭代
| 时间 | 阶段 | 关注点 |
|---|---|---|
| 2023-2024 | 语义向量检索 | 解决"词不达意"------传统 BM25 无法理解真实意图 |
| 2025 | 知识 RAG 与混合检索 | 解决"幻觉"------Advanced RAG + 混合检索,长尾知识精准定位 |
| 2026 | Agent 记忆检索 | AgenticSearch + 搜推问一体化,具备"规划与记忆"的基础设施 |
应用侧从"如何问"到"喂什么"到"如何度量",技术侧从"向量检索"到"知识RAG+混合检索"到"AgenticSearch+智能体记忆"。
LLM应用和AI搜索技术,在同一个时间线上,互相推动, 互相影响。
六、4.18 最新发布
借着今天的机会,同步阿里云 Elasticsearch 在 4.18 的最新发布:
-
阿里云Elasticsearch v9.3 全面发布:支持 Lucene 10,DiskBBQ 算法大规模降低内存占用,NVIDIA GPU 加速向量化
-
Elastic Inference Service 扩展:支持 Jina AI 模型
-
Agent Builder:引入辅助开发 AI Agent 功能,简化"数据对话"逻辑
-
ES|QL 高性能时序查询:监控和可观测性场景延迟降低 5 倍以上
-
集群运行状况健康事件体系:从告警到检测到事件,完整的运维闭环
-
全新 Skill:支持 Claude Code、Qcode、OpenClaw 等主流 Agent
-
Agentic Memory 智能记忆服务 API 体验版发布:Agentic RAG 能力产品化的重要一步
结语
AI 搜索的终局,不是更好的检索引擎,而是更聪明的智能体。
搜索不应该只是一个被动的工具------用户问、系统答。
搜索应该成为一个主动的伙伴------理解意图、规划策略、自主执行、持续进化。
这也是今天这篇文章主题的含义:搜索即智能体。
了解更多:
阿里云Elasticsearch:https://www.aliyun.com/product/bigdata/elasticsearch
阿里云AgenticSearch: https://help.aliyun.com/zh/open-search/search-platform/product-overview/agentic-search-ai-driven-next-generation-enterprise-search