Large Ontology Models for Enterprise Knowledge Management
摘要
本文提出大型本体模型(LOM),这是一个统一的"构建---对齐---推理"框架,旨在解决企业级知识管理中多源异构数据整合与复杂语义推理的难题。通过双层本体构建、文本-本体对齐以及三阶段指令微调流水线,4B参数的LOM在89.47%准确率上优于DeepSeek-V3.2等主流模型,展现了本体结构与自然语言融合的优势。
阅读原文或https://t.zsxq.com/BL2Ur获取原文pdf

正文
企业知识管理的时代挑战
在数字化转型的浪潮中,企业知识管理面临着前所未有的挑战。传统系统通常依赖关系型数据库或基本的文档管理系统来存储和管理企业知识。尽管这些方法能够有效存储结构化数据,但在处理复杂的非结构化知识和实体间关系方面存在困难。
近年来,知识图谱作为一种强大的表示方式应运而生,它将企业知识建模为图结构,利用结点和边来捕捉实体及其关系,从而实现更智能的查询与推理。然而,传统的知识图谱方法在隐式关系发现方面通常表现不佳,对于复杂问答系统的语义理解能力也不足。
企业本体构建与推理的现有方法面临显著局限。在构建方面,方法通常将结构化数据库与非结构化文本孤立处理。传统的模式映射工具难以识别遗留数据库中的隐式关系(例如缺失的外键),而标准的信息提取模型缺乏领域适应性,无法将这些结构化骨架与丰富的文本知识融合。在推理方面,图神经网络(GNNs)捕捉拓扑结构但缺乏对复杂业务问题的推理深度,而大模型(LLMs)拥有语义知识却常常无法遵循严格的图结构。这种脱节阻碍了对异构企业数据进行可靠、多跳推理的能力。
大型本体模型的核心创新
为解决这些局限性,研究团队提出了一种统一的大型本体模型(LOM)框架。这个框架集成了多源本体构建、文本-本体对齐以及指令对齐推理,有效弥合了数据集成与语义推理之间的鸿沟。
第一大创新:双层本体构建体系
构建企业本体是一项非平凡的任务,LOM采用分层方法,从结构化数据库和非结构化文本中构建本体。
对于结构化数据库,由于显式的外键经常缺失,LOM提出了一种多因子关系发现算法,该算法分析模式元数据与数据内容重叠,以揭示隐式连接。这使得能够构建包含抽象模式层和具体实例层的双层本体。
对于非结构化文本,LOM采用基于LLM与本体的流水线,通过符号规则与语义嵌入的混合方法,执行实体-关系抽取、链接预测以及鲁棒的实体消歧。最后,系统通过基于标签-描述匹配的跨模态对齐,将这些异构源融合为统一的企业本体。
第二大创新:三阶段指令对齐训练流水线
第二个创新在于训练一个能够深入理解并推理异构企业本体的大型语言模型。为解决图结构与文本知识之间的语义鸿沟,LOM设计了一套统一的三阶段训练流水线:
首先,采用本体指令微调,使大语言模型具备基础的本体结构理解能力。其次,引入文本-本体对齐阶段,通过类型内与类型间对齐训练一个对齐投影器,实现文本语义与本体特征的融合。最后,基于课程学习,在本体-语言配对数据上进行多任务指令微调,引导模型从简单的预测任务逐步过渡到复杂的生成式推理。
第三大创新:思维链增强数据集
为支持该训练流水线,研究团队构建了一个增强思维链(CoT)的综合性数据集,捕捉算法推理路径,使模型能够学习以本体为中心的操作逻辑,而非仅依赖简单的答案映射。
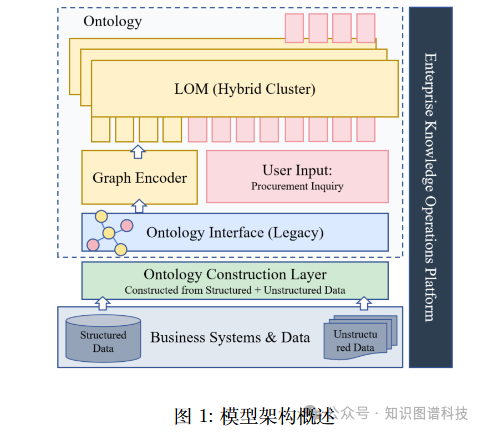
模型架构的系统性设计
LOM的架构体现了"构建---对齐---推理"的完整闭环:
本体构建层:通过多因子算法发现隐式关系,从结构化和非结构化数据中提取企业知识,构建双层本体框架。
对齐融合层:利用文本-本体对齐机制,将自然语言表示与本体结构特征映射到统一的语义空间,消除异构数据之间的语义鸿沟。
推理生成层:通过三阶段微调流水线,赋予模型强大的复杂本体推理与生成能力,支持从简单的事实检索到复杂的多跳推理。
性能表现与基准验证
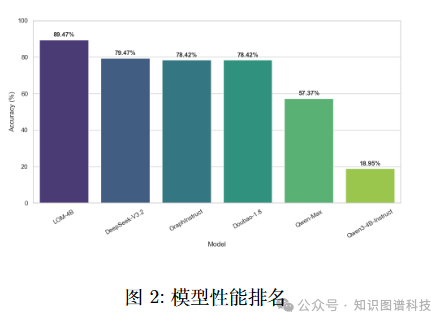
在自己构建的数据集上进行的系统性评估表明,4B参数的LOM达到了最先进的性能。具体来看,LOM-4B在该基准上的准确率达到89.47%,显著优于现有主流基准在复杂图推理任务中的表现,甚至优于DeepSeek-V3.2,表明本体结构与语言的有效融合。
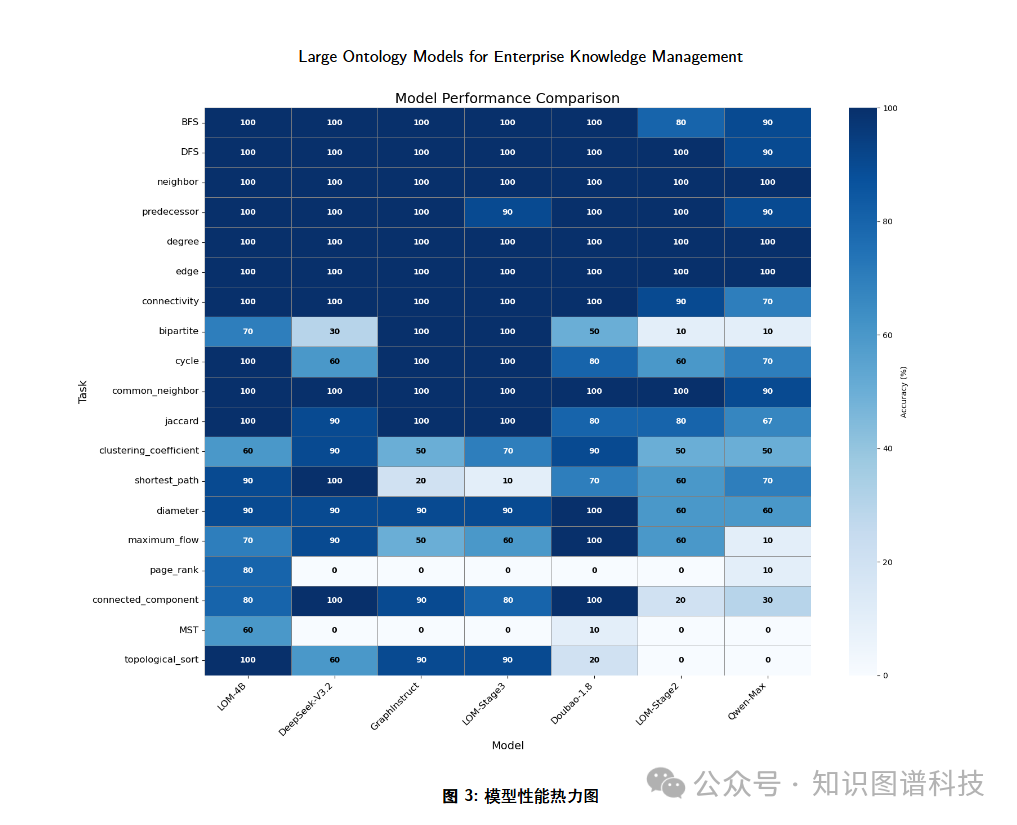
评估涵盖了19种多样的图推理任务,全面验证了模型在各类企业知识推理场景中的适应性和鲁棒性。
应用价值与前景展望
企业层面的应用价值:
-
知识整合:LOM能够有效整合企业内部分散的结构化数据和非结构化文档,构建统一的知识体系,支持企业知识的系统化管理和应用。
-
智能决策支持:通过强大的语义推理能力,LOM能够回答复杂的业务问题,支持多跳推理,为企业管理层提供数据驱动的决策支持。
-
自动化知识提取:减少人工模式工程的工作量,通过自动化流程发现隐式关系和提取隐藏知识,提高知识获取的效率。
-
跨域知识融合:支持将来自不同数据源、不同业务部门的知识进行融合,形成全局的企业知识视图。
科研与技术方向:
本研究在知识图谱、自然语言处理和本体论等领域进行了深度融合,为后续研究提供了新的思路。特别是"构建---对齐---推理"的统一框架,可以推广到其他领域的知识管理任务中。
投资与商业前景:
企业知识管理市场规模持续扩大,传统系统的升级需求迫切。LOM这类大型本体模型产品化的潜力巨大,可应用于金融风险管理、医疗知识库、法律智能等多个高价值行业。相关技术的商业化有望产生显著的经济效益。
与现有技术的对比优势
相比于传统知识图谱系统,LOM具有明显优势:
-
更强的语义理解:不仅理解图的拓扑结构,更能捕捉复杂的语义关系和隐式知识。
-
更好的异构数据处理:通过文本-本体对齐,有效处理结构化和非结构化数据的融合问题。
-
更高的推理深度:支持多跳推理和复杂问答,而不仅限于基于规则的简单推理。
-
更优的成本效益:4B参数规模相对轻量,但性能优于更大规模的通用模型,部署成本更低。
技术实现的创新亮点
-
多因子关系发现算法:突破了遗留数据库中外键缺失的技术难题,能够从元数据和数据内容的重叠中发现隐式连接。
-
混合方法的实体消歧:结合符号规则与语义嵌入,提高了非结构化文本中实体识别的准确性。
-
课程学习策略:循序渐进地引导模型学习,从简单任务到复杂推理,提高了训练效率和模型收敛性。
-
思维链数据集:通过显式记录推理路径,使模型学习到可解释的推理逻辑,增强了结果的可信度。
对企业决策者的启示
对于企业决策者而言,这项研究表明:
-
知识管理已成为竞争力的关键因素,投资于智能知识管理系统是必然选择。
-
异构数据的整合不再是难题,新技术使得企业能够真正打破信息孤岛。
-
AI与本体论的结合是未来方向,能够理解复杂知识结构的AI系统将成为企业的核心资产。
-
轻量化模型的崛起意味着更好的部署灵活性和成本效益。