在构建智能体与 RAG 系统时,用户自然语言输入和系统底层执行逻辑之间,天然存在巨大语义鸿沟。
进入 2026 年,行业早已抛弃「单一大模型全权兜底」的粗放式意图识别方案,业界统一落地分层漏斗路由 架构:遵循先快后慢、先低成本后高智能的设计原则,将 80% 的高频标准化请求,在零延迟的轻量化层级直接拦截消化,极致兼顾响应速度、推理成本与识别准确率。
这种设计彻底重塑了意图识别的定位:把传统意图分类问题,升级为全局流量路由问题 ,最终形成以向量检索 + Function Calling 为核心的现代智能体意图路由标准方案。
一、历史演进:三层漏斗 → 两层快慢路径
早期(2023--2025):关键词 + 向量 + 小模型三层漏斗(传统NLU)
由于当时大模型 function calling 不稳定、成本高、延迟大,业界采用三层结构:
一. L1 关键词/正则 :处理固定指令(代表公司 :Cursor、Claude Code、钉钉、飞书、Linux),仅用于绝对固定命令(如 /help、exit、yes);所有正则有单元测试
实际使用场景举例 :
- Cursor :用户按
Cmd+K触发内联编辑,检测到关键词edit、change直接唤起编辑器。 - 钉钉机器人 :以
/开头的指令(/todo、/remind)命中正则后直接执行。 - Claude Code :用户输入
git status等 shell 命令,正则匹配后直接执行,不调用 LLM。 - 飞书审批机器人:用户回复"同意"、"批准"等固定词,正则匹配后直接流转审批状态。
- GitLab CI :根据 commit message 是否包含
[skip ci]正则决定是否跳过流水线。
二. L2 向量语义 :处理同义改写(为每个意图写 3~20 条示例,生成向量;用户请求向量化后余弦相似度匹配。) 实际使用例子(≥3个) :
- Zendesk 智能客服:用户说"我忘记密码"、"无法登录",向量匹配到"账号恢复"意图,回复密码重置链接。
- Salesforce Einstein:客户发邮件"我想修改发货地址",匹配示例"更改地址"、"换送货地点",自动路由到订单修改机器人。
- 美团商家后台:商家说"今日流水"、"营收多少",向量匹配后展示营收仪表盘。
- 飞书智能助手(企业版) :员工说"请假三天"、"申请年假",匹配到请假流程。
- Notion AI(企业版) :用户问"上季度销售数据",匹配"季度报表"、"销售业绩"示例,拉取数据库。 三. L3 小模型分类(如 gpt-3.5-turbo、Claude Instant):对未命中请求做意图分类,再交给主模型执行;用小模型(gpt-3.5-turbo、Claude Instant、Gemini Flash)纯做意图分类,输出意图 ID,主模型再执行。
小模型的定位:作为兜底,比大模型快且便宜,能处理语义但无法提取槽位。
现在(2026):关键词 + 向量 + 大模型 FC 两层路径
随着大模型 FC 成熟(准确率 >95%、延迟 1--2s、成本下降 80%+),小模型变得尴尬:
- 比向量慢(500ms+ vs 100ms)
- 比大模型 FC 不准(分类漂移 + 无法提取槽位 + 不能反问澄清)
- 维护成本高(需要训练数据、模型更新、部署)
- 总成本并不低(小模型 + 主模型两次调用 ≥ 单次大模型 FC)
因此,新架构直接移除小模型层,由大模型 FC 接管长尾:
- L1 关键词/正则(<1ms,60--80% 请求)
- L2 向量语义(30--100ms,15--25% 请求)
- L3 大模型 FC(1--2s,5--15% 请求)------ 一次调用完成意图+槽位+执行
二、意图识别具体实现过程
1.原生写法-源码包含关键注释
python
# ===================== 【1. 安装依赖(新手第一步!必须做)】 =====================
# 终端执行命令:pip install sentence-transformers requests
# 【新手坑⚠️】不安装依赖直接运行,会报 ModuleNotFoundError 找不到模块
# 【新手坑⚠️】国内网络慢,下载向量模型失败 → 换手机热点运行
# ===================== 【2. 导入工具包】 =====================
import re # 正则表达式:用于关键词模糊匹配
import requests # 网络请求:调用Minimax官方API接口
from sentence_transformers import SentenceTransformer, util # 文本转向量+计算语义相似度
import json # 解析API返回的JSON数据,防止报错
# ===================== 【3. Minimax Coding Plan 核心配置】 =====================
# 【必填】替换成你的 Minimax API Key(Coding Plan 专用密钥)
# 【新手坑⚠️】密钥填错/漏填/前后多空格 → 报401无权限错误
MINIMAX_API_KEY = "你的Minimax-CodingPlan-API-KEY"
# Minimax 官方固定接口地址(Coding Plan 通用,绝对不能修改!)
# 【新手坑⚠️】手动拼写接口地址错误 → 报404找不到服务器
MINIMAX_API_URL = "https://api.minimax.chat/v1/text/chatcompletion"
# 向量相似度阈值:分数≥0.7 判定为「意思匹配成功」
SIMILARITY_THRESHOLD = 0.7
# ===================== 【4. 第一层:关键词路由(办公场景 日常口语版)】 =====================
# AI规则小本本:{ 意图名称 : [用户日常会说的话] }
# 【新手致命坑⚠️】意图名称 必须和后面 INTENT_EXAMPLES/模型提示词 一字不差!
# 【新手致命坑⚠️】全程办公场景,禁止混入代码相关话术
INTENT_RULES = {
"问好": ["你好", "哈喽", "在吗", "嗨", "早上好", "晚上好", "有人吗"],
"查询身份": ["你是谁", "你是干嘛的", "你是什么助手", "你能做什么", "介绍一下你自己"],
"查询薪资": ["帮我查薪资", "查一下我的工资", "本月工资多少", "查工资条", "薪资明细"],
"查询考勤": ["帮我查考勤", "我的打卡记录", "今天迟到了吗", "查加班记录", "考勤情况"],
"请假申请": ["我要请假", "帮我提请假", "请假流程是什么", "怎么请假", "我想请年假"],
"查询公司政策": ["公司报销政策", "加班规则", "年假规定", "公司制度", "上下班时间"]
}
# ===================== 【函数1:关键词匹配函数】 =====================
# 作用:拿着规则本扫描用户输入,快速匹配意图(优先级最高)
# 参数:user_input = 用户输入的一句话
# 返回值:匹配到的意图 / None(未匹配)
def keyword_intent_route(user_input: str) -> str | None:
# 遍历规则本中 所有意图 + 对应的关键词列表
for intent, keyword_list in INTENT_RULES.items():
# 遍历当前意图下的每一个口语关键词
for keyword in keyword_list:
# 匹配用户输入中是否包含关键词
# 【新手坑⚠️】默认区分大小写,如需不区分 → 加参数 re.IGNORECASE
if re.search(keyword, user_input):
print(f"✅【第一层-关键词命中】意图:{intent}")
return intent # 匹配成功直接返回,不继续执行
# 所有关键词都未匹配,返回空
return None
# ===================== 【5. 第二层:向量语义匹配(✅ 严格使用你的办公场景例句)】 =====================
# 作用:匹配「说法不同、意思相同」的提问(核心能力)
# 【新手致命坑⚠️】意图名称 必须和 INTENT_RULES 完全一致!!
# 【新手致命坑⚠️】这是你指定的办公场景例句,全程保持统一
embedding_model = SentenceTransformer("all-MiniLM-L6-v2")
# 你指定的 办公场景向量匹配例句库(完全保留,不修改)
INTENT_EXAMPLES = {
"问好": ["你好呀", "在不在", "哈喽助手", "早上好"],
"查询身份": ["你是什么软件", "你能帮我做什么", "介绍下自己"],
"查询薪资": ["我想看下工资条", "这个月收入多少", "查我的薪资"],
"查询考勤": ["我这个月打卡情况", "有没有迟到", "考勤记录"],
"请假申请": ["我想申请休假", "请假怎么操作", "提请假流程"],
"查询公司政策": ["公司加班怎么算", "报销流程", "年假天数"]
}
# 预计算:把所有例句转为向量,存储为意图标准特征(启动时计算1次)
intent_vector_map = {}
for intent, examples in INTENT_EXAMPLES.items():
# 将文本例句转换为向量数据
example_vectors = embedding_model.encode(examples, convert_to_tensor=True)
# 计算向量平均值,作为该意图的「标准语义特征」
intent_vector_map[intent] = example_vectors.mean(dim=0)
# ===================== 【函数2:向量语义匹配函数】 =====================
# 作用:计算用户输入和意图的语义相似度,实现模糊匹配
def embedding_intent_route(user_input: str) -> str | None:
# 将用户输入的文本转换为向量
user_vector = embedding_model.encode(user_input, convert_to_tensor=True)
# 初始化最高相似度分数
max_score = 0.0
# 初始化最匹配的意图
best_intent = None
# 遍历所有意图的标准向量,计算相似度
for intent, intent_vector in intent_vector_map.items():
score = util.cos_sim(user_vector, intent_vector).item()
# 更新最高分和最匹配意图
if score > max_score:
max_score = score
best_intent = intent
# 相似度达标,返回匹配意图
if max_score >= SIMILARITY_THRESHOLD:
print(f"✅【第二层-向量匹配】意图:{best_intent},相似度:{max_score:.2f}")
return best_intent
# 相似度不足,返回空
return None
# ===================== 【6. 第三层:Minimax 小模型兜底(办公场景意图识别)】 =====================
# 作用:前两层识别失败时,用Minimax小模型AI理解复杂意图
def minimax_small_intent_recognize(user_input: str) -> str:
# 请求头:Minimax 官方固定格式,禁止修改
# 【新手坑⚠️】Bearer 后面必须加1个空格 → 否则401认证失败
headers = {
"Authorization": f"Bearer {MINIMAX_API_KEY}",
"Content-Type": "application/json"
}
# 办公场景专属提示词:强制输出固定意图,不允许乱回答
prompt = f"""你是企业智能办公助手,仅输出标准意图:
问好、查询身份、查询薪资、查询考勤、请假申请、查询公司政策、其他
用户输入:{user_input}"""
# Minimax Coding Plan 官方请求参数
data = {
# 【新手坑⚠️】意图识别必须用轻量小模型:minimax-chat-lite
"model": "minimax-chat-lite",
"messages": [{"role": "user", "content": prompt}],
# 【新手坑⚠️】temperature=0 → 输出结果固定,不随机
"temperature": 0.0,
# 【新手坑⚠️】新手关闭流式输出,避免处理复杂逻辑
"stream": False
}
# 异常捕获:API报错不会让程序崩溃(新手必备)
try:
response = requests.post(MINIMAX_API_URL, headers=headers, json=data, timeout=10)
response.raise_for_status() # 主动抛出HTTP错误
result = response.json()
return result["choices"][0]["message"]["content"].strip()
except Exception as e:
print(f"❌ 小模型调用失败:{str(e)}")
return "其他"
# ===================== 【核心:Minimax 大模型生成办公回复(Coding Plan 适配)】 =====================
# 作用:识别意图后,调用大模型生成专业、友好的回复
def minimax_office_reply(user_input: str, intent: str) -> str:
headers = {
"Authorization": f"Bearer {MINIMAX_API_KEY}",
"Content-Type": "application/json"
}
# 办公助手专属提示词(适配Coding Plan生成逻辑)
prompt = f"""你是企业智能办公助手,根据用户意图友好、简洁、专业回复:
用户意图:{intent}
用户问题:{user_input}
要求:语气亲切、回答准确、符合办公场景"""
# Minimax 官方请求体(Coding Plan 专用)
data = {
# 【新手坑⚠️】生成回复必须用专业大模型:minimax-chat-pro
"model": "minimax-chat-pro",
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.3,
"stream": False
}
# 异常捕获,防止程序崩溃
try:
response = requests.post(MINIMAX_API_URL, headers=headers, json=data, timeout=30)
response.raise_for_status()
return response.json()["choices"][0]["message"]["content"]
except Exception as e:
return f"❌ 回复生成失败:{str(e)}"
# ===================== 【总路由:三层意图识别自动流转】 =====================
# 执行优先级:关键词匹配 → 向量匹配 → 小模型兜底
def agent_intent_router(user_input: str) -> str:
# 第一层
intent = keyword_intent_route(user_input)
if intent: return intent
# 第二层
intent = embedding_intent_route(user_input)
if intent: return intent
# 第三层
return minimax_small_intent_recognize(user_input)
# ===================== 【最终运行入口】 =====================
# 对外总接口:用户输入一句话,自动完成全流程
def run_office_agent(user_input: str):
# 打印分割线,方便查看结果
print("-" * 60)
# 打印用户输入内容
print(f"🗣️ 用户输入:{user_input}")
# 调用总路由,识别最终意图
final_intent = agent_intent_router(user_input)
# 打印最终识别结果
print(f"🎯 最终识别意图:{final_intent}")
# 定义办公场景支持的所有合法意图
valid_intents = ["问好","查询身份","查询薪资","查询考勤","请假申请","查询公司政策"]
# 合法意图 → 调用大模型生成回复
if final_intent in valid_intents:
print("\n🚀 助手正在生成回复...")
result = minimax_office_reply(user_input, final_intent)
print(f"\n📄 回复结果:\n{result}")
# 不支持的意图
else:
print("❌ 暂不支持该办公需求")
# ===================== 【测试代码】 =====================
if __name__ == "__main__":
# 【新手坑⚠️】每次只运行1个测试用例,禁止同时开启多个
run_office_agent("你好")
# run_office_agent("你是谁呀")
# run_office_agent("帮我查一下我的工资")
# run_office_agent("我要请假")
# run_office_agent("公司加班规则是什么")2.🔥 LangChain 0.3+ 办公助手
langchain
python
# ===================== LangChain 0.3+ 办公助手(Minimax Coding Plan 适配) =====================
# 【新手坑⚠️】必须安装依赖:pip install "langchain>=0.3.0" langchain-community langchain-minimax sentence-transformers numpy
# 【新手坑⚠️】LangChain <0.3 版本无invoke方法,会直接报错!
# 1. 导入LangChain 0.3 核心组件(官方最新标准)
from langchain_core.runnables import RunnableLambda # 把普通函数包装成LangChain可执行组件
from langchain_core.prompts import PromptTemplate # 提示词模板:固定AI的提问格式
from langchain_core.output_parsers import StrOutputParser # 把AI返回的结果转成纯文字
from langchain_community.embeddings import SentenceTransformerEmbeddings # 文字转向量工具
from langchain_minimax import ChatMinimax # LangChain0.3官方对接Minimax模型
# 基础工具
import re
import numpy as np
# ===================== 全局核心配置 =====================
# 【必填】替换为你的 Minimax Coding Plan API Key
MINIMAX_API_KEY = "你的Minimax-CodingPlan-API-KEY"
# 向量相似度阈值(≥0.7判定意思匹配)
SIMILARITY_THRESHOLD = 0.7
# 合法意图列表(全程统一,禁止修改)
VALID_INTENTS = [
"问好", "查询身份", "查询薪资", "查询考勤",
"请假申请", "查询公司政策", "其他"
]
# ===================== 第一层:关键词路由规则(办公场景口语) =====================
INTENT_RULES = {
"问好": ["你好", "哈喽", "在吗", "嗨", "早上好", "晚上好", "有人吗"],
"查询身份": ["你是谁", "你是干嘛的", "你是什么助手", "你能做什么", "介绍一下你自己"],
"查询薪资": ["帮我查薪资", "查一下我的工资", "本月工资多少", "查工资条", "薪资明细"],
"查询考勤": ["帮我查考勤", "我的打卡记录", "今天迟到了吗", "查加班记录", "考勤情况"],
"请假申请": ["我要请假", "帮我提请假", "请假流程是什么", "怎么请假", "我想请年假"],
"查询公司政策": ["公司报销政策", "加班规则", "年假规定", "公司制度", "上下班时间"]
}
# ===================== 1. LangChain 关键词路由组件 =====================
def keyword_router(query: str) -> str:
for intent, keywords in INTENT_RULES.items():
for kw in keywords:
if re.search(kw, query):
return intent
return "vector_router"
# 把普通函数变成LangChain可执行的组件
keyword_runnable = RunnableLambda(keyword_router)
# ===================== 第二层:向量语义匹配(你的原版例句100%保留) =====================
# 加载开源向量模型:将人类语言文字 转换成 计算机能计算的数字向量
embedding = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# 你指定的办公场景例句(完全不动)
INTENT_EXAMPLES = {
"问好": ["你好呀", "在不在", "哈喽助手", "早上好"],
"查询身份": ["你是什么软件", "你能帮我做什么", "介绍下自己"],
"查询薪资": ["我想看下工资条", "这个月收入多少", "查我的薪资"],
"查询考勤": ["我这个月打卡情况", "有没有迟到", "考勤记录"],
"请假申请": ["我想申请休假", "请假怎么操作", "提请假流程"],
"查询公司政策": ["公司加班怎么算", "报销流程", "年假天数"]
}
# 预计算所有意图的标准向量:启动程序时计算1次,后续直接使用,提升运行速度
intent_vectors = {}
for intent, examples in INTENT_EXAMPLES.items():
# 将例句文本批量转换为向量数组
vecs = embedding.embed_documents(examples)
# 计算同一意图下所有例句向量的平均值,作为该意图的【标准特征向量】
intent_vectors[intent] = np.mean(vecs, axis=0)
# ===================== 2. LangChain 向量路由组件(✅ 逐行超详细注释) =====================
def vector_router(query: str) -> str:
"""
【向量语义匹配函数】第二层意图识别核心
作用:解决「文字不同、意思相同」的匹配(比如:我想看下工资 = 帮我查薪资)
:param query: 用户输入的问题/对话
:return: 匹配到的意图 / 默认跳转到小模型识别
"""
# 1. 将用户输入的文字 转换为 计算机可计算的向量
query_vec = embedding.embed_query(query)
# 2. 初始化变量:记录最高的相似度分数(初始为0)
max_score = 0.0
# 3. 初始化默认意图:如果没匹配到,就跳转到第三层小模型识别
best_intent = "llm_router"
# 4. 遍历所有【标准意图向量】,逐一计算相似度
for intent, vec in intent_vectors.items():
# 5. 【核心公式】计算余弦相似度:值越接近1,代表两句话意思越像
# 公式:向量点积 / (向量1长度 * 向量2长度)
score = np.dot(query_vec, vec) / (np.linalg.norm(query_vec) * np.linalg.norm(vec))
# 6. 判断:当前分数 > 历史最高分 + 分数达标(≥0.7)
if score > max_score and score >= SIMILARITY_THRESHOLD:
# 7. 更新:最高分数 + 最匹配的意图
max_score = score
best_intent = intent
# 8. 返回最终匹配结果(匹配到的意图 / 跳转到小模型)
return best_intent
# 【LangChain0.3 强制规范】
# 把普通的Python函数 vector_router 包装成 LangChain 可识别、可执行的组件
# 只有包装后,才能用 .invoke() 方法执行,否则会报错
vector_runnable = RunnableLambda(vector_router)
# ===================== 第三层:Minimax 小模型兜底(意图识别) =====================
small_llm = ChatMinimax(
api_key=MINIMAX_API_KEY,
model="minimax-chat-lite",
temperature=0.0,
)
# 意图识别提示词
intent_prompt = PromptTemplate.from_template("""
你是企业智能办公助手,仅输出标准意图:
问好、查询身份、查询薪资、查询考勤、请假申请、查询公司政策、其他
用户输入:{query}
""")
# LangChain0.3标准链
intent_chain = intent_prompt | small_llm | StrOutputParser()
# ===================== 总路由编排(三层自动流转) =====================
def total_router(query: str) -> str:
# 第一层:关键词匹配
res = keyword_runnable.invoke(query)
if res in VALID_INTENTS:
print(f"✅【LangChain关键词】识别意图:{res}")
return res
# 第二层:向量匹配
res = vector_runnable.invoke(query)
if res in VALID_INTENTS:
print(f"✅【LangChain向量】识别意图:{res}")
return res
# 第三层:小模型兜底
res = intent_chain.invoke({"query": query})
print(f"✅【LangChain小模型】识别意图:{res}")
return res
# 总路由:包装成LangChain可执行组件
total_runnable = RunnableLambda(total_router)
# ===================== Minimax 大模型:办公回复生成 =====================
big_llm = ChatMinimax(
api_key=MINIMAX_API_KEY,
model="minimax-chat-pro",
temperature=0.3,
)
# 回复提示词
reply_prompt = PromptTemplate.from_template("""
你是企业智能办公助手,语气友好、简洁、专业:
用户意图:{intent}
用户问题:{query}
""")
# 回复执行链
reply_chain = reply_prompt | big_llm | StrOutputParser()
# ===================== 最终运行入口(核心!超详细注释) =====================
def run_langchain_office_agent(query: str):
"""
办公助手总执行函数(小白直接调用这个就行)
:param query: 用户输入的一句话(比如:你好、帮我查工资)
"""
print("-" * 60)
print(f"🗣️ 用户输入:{query}")
# ======================================
# 【核心调用1】
# total_runnable:总路由组件(负责三层意图识别)
# .invoke():LangChain0.3 唯一执行方法
# 执行逻辑:关键词→向量→小模型 自动识别
# 返回值:最终识别的意图
# ======================================
intent = total_runnable.invoke(query)
print(f"🎯 最终识别意图:{intent}")
# 判断意图是否合法,合法就生成回复
if intent in VALID_INTENTS[:-1]:
print("\n🚀 正在生成回复...")
# ======================================
# 【核心调用2】
# reply_chain:回复生成链
# 传参字典:必须和提示词的{intent}{query}完全一致
# 执行逻辑:调用Minimax大模型生成办公回复
# ======================================
result = reply_chain.invoke({"intent": intent, "query": query})
print(f"\n📄 助手回复:\n{result}")
else:
print("❌ 暂不支持该办公需求")
# ===================== 测试代码 =====================
if __name__ == "__main__":
# 新手每次只运行1个测试用例
run_langchain_office_agent("你好")
# run_langchain_office_agent("帮我查我的工资")
# run_langchain_office_agent("我要请假")三. 我的项目实现思路
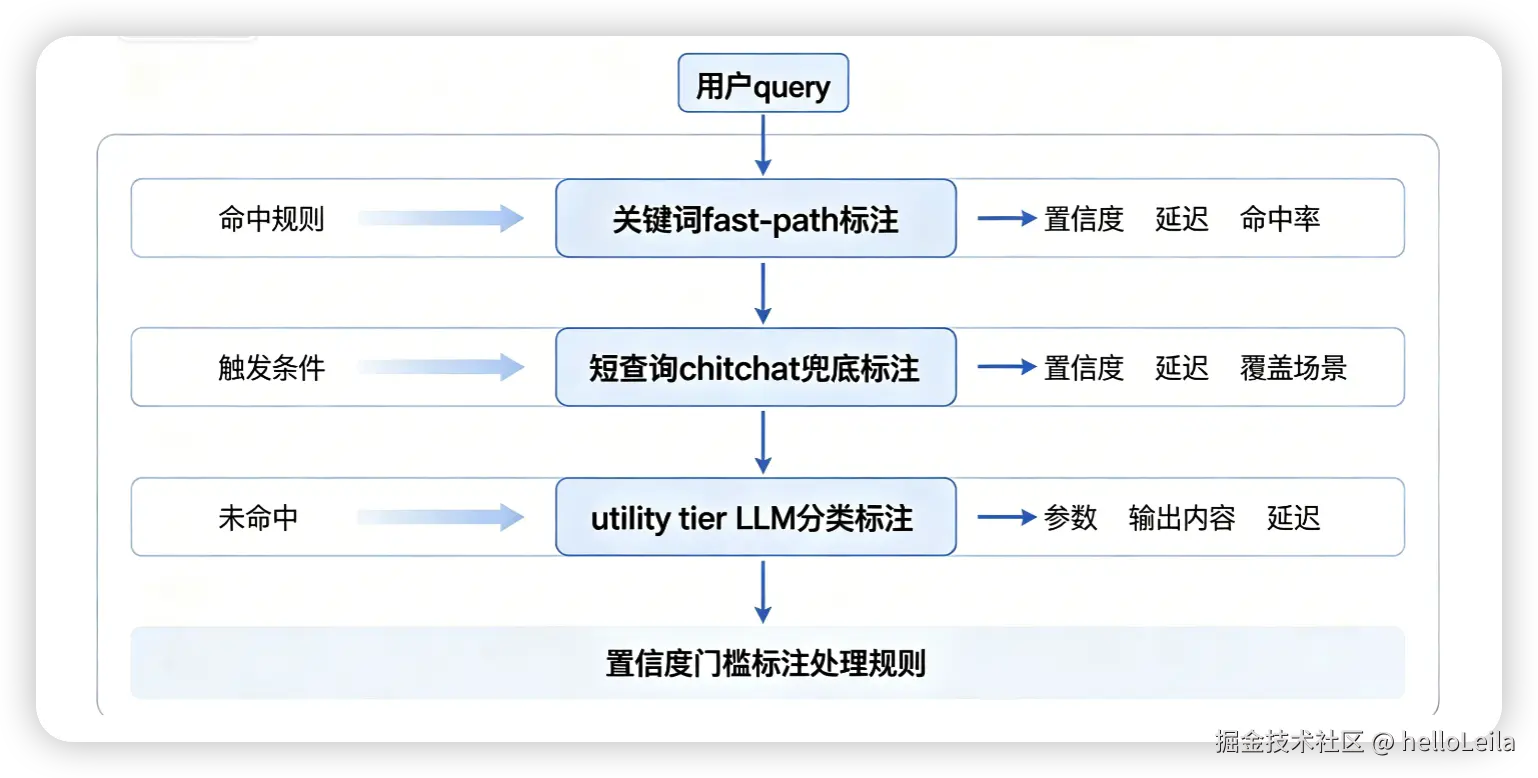
目前
- 关键词 fast-path 已经覆盖了 60-70% 的高频请求(0ms 0 调用,完全不碰任何模型)
- 短查询兜底覆盖了 10-15% 的零碎闲聊(同样 0 调用)
- 真到第 3 层 LLM 分类的请求只剩 15-25%,这部分目前还是 25s,但触发频率已经低很多
3.1 具体方案
第 1 层:关键词 fast-path
数据结构 :KEYWORD_RULES 元组表
(意图, 关键词列表, 候选意图列表)
5 条规则:
| 意图 | 关键词示例 |
|---|---|
| salary | 薪酬、工资、总包、奖金、薪资、个税、收入 |
| personal | 年假、合同、身份证、手机号、部门、入职 |
| travel | 机票、酒店、出差、预订、航班、舱位 |
| knowledge | 制度、报销、手册、规定、政策、流程、FAQ |
| chitchat | 生成/写/撰写/面试 + 你是谁/你好/hi/谢谢 |
决策规则:
- 子串匹配(lowercase)
- 平票(多个意图命中数相同)→ 放弃,进下一层
- 命中 →
confidence = 0.93,reason 写清命中词
第 2 层:短查询兜底
逻辑一行:
scss
if len(query.strip()) ≤ 15 字 and 第 1 层没命中:
return chitchat(confidence=0.85)覆盖:"在吗"、"嗯"、"ok"、"?" 这种没穷举进关键词的零碎闲聊。
为什么是 15 字:业务请求最短也在 "查一下本月薪酬"(8 字)和 "帮我预订明天的机票"(9 字)之间,但这些都已经被第 1 层关键词吃掉了,剩下没命中还短的基本只能是闲聊。阈值放 15 保险。
第 3 层:utility 模型分类
工厂:
get_utility_chat_model()
- temperature=0(分类要稳定)
- streaming=False(分类不流式)
- thinking=关闭(分类不需要思考)
- max_tokens=1024(短输出)
模型选择:
- OpenAI provider →
gpt-4o-mini - Anthropic provider →
anthropic_utility_model,留空回退到主模型(MiniMax Coding Plan 现况)
prompt:
- system:"你是意图分类器,只返回 JSON,意图只能是 5 类之一"
- human:few-shot 4 个示例 +
PydanticOutputParser生成的 JSON schema + 用户问题
输出强校验 :prompt | llm | parser,parser 用 Pydantic,校验失败自动重试。
后置:置信度门槛
ini
python
if result.intent != "chitchat" and result.confidence < 0.7:
result.intent = "clarify" # 让 generate_node 反问用户chitchat 没门槛(本来就不需要高置信度),其他业务意图必须 ≥0.7 才敢路由,否则问用户"你是想查工资还是查差旅?"
3.2、关键设计权衡
| 选择 | 另一种做法 | 为什么这么选 |
|---|---|---|
| 规则优先、模型兜底 | 全靠模型 | 模型贵且慢,高频 query 别浪费 |
| 关键词放第 1 层 | 关键词放最后(作"模型没把握时的补丁") | 从延迟角度考虑:能 0ms 就别花 1-2s |
| 平票放弃 | 强制选分最高 | "差旅报销制度"同时命中 2 个意图,应该让模型决定而不是按顺序取第一个 |
| confidence 分三档0.93 / 0.85 / 模型给 | 统一给 1.0 或不给 | 前端/澄清逻辑可以根据置信度决定要不要反问 |
| chitchat 不设置信度门槛 | 全部 intent 都卡 0.7 | 闲聊本来就模糊,强行要求高置信只会让"你好"这种被路到 clarify |
| reason 字段保留路径标识 | 统一用模型给的 reason | 便于日后 grep 日志统计每层命中率,运维友好 |
| 第 3 层用 utility 工厂(而不是主工厂) | 都用 get_chat_model() | 分类是高频小活儿,应该走小模型;MiniMax 回退到主模型保持向后兼容 |
| 第 2 层用"长度"而不是 embedding | 上 embedding 路由器 | 现阶段 YAGNI,长度启发式已经覆盖大部分情况 |
3.3、每层覆盖率(经验估算)
| 层 | 覆盖率 | 延迟 | LLM 调用 |
|---|---|---|---|
| 1 关键词 | 60-70% | ~0 ms | 0 |
| 2 短查询 | +10-15% | ~0 ms | 0 |
| 3 utility 模型 | +15-25% | 1-25s (看模型) | 1 |
累计:75-85% 的请求在前两层就处理完了,彻底跳过 LLM。
3.4、可观测性
每层命中路径都写到 IntentClassification.reason 里:
| 路径 | reason 值 |
|---|---|
| 第 1 层 | 本地快速路径命中关键词:{词} |
| 第 2 层 | 本地快速路径:短查询(≤15 字)默认 chitchat |
| 第 3 层 | 模型生成的自然语言原因 |
加个中间件 grep 这个字段就能算出真实分布。
3.5、向后兼容与可演进性
| 场景 | 做法 |
|---|---|
| 加新意图 | 在 KEYWORD_RULES 加一行 + 在 FEW_SHOTS 加一个示例 |
| 新意图太模糊没法列关键词 | 只加 few-shot,让第 3 层处理 |
| 想接 embedding 路由 | 在第 2、3 层之间插一层,不动现有代码 |
| MiniMax 换成 Claude 官方 | 改 .env 里 ANTHROPIC_UTILITY_MODEL=claude-3-5-haiku-latest,立即享受小模型加速 |
| 改置信度门槛 | INTENT_CONFIDENCE_THRESHOLD 环境变量 |
3.6、测试覆盖
test_intent_chain.py 5 条单测:
- 业务关键词命中 → fast-path,LLM 不被触发
- 写作类关键词命中 → chitchat,LLM 不被触发
- 问候类(你是谁/hi/谢谢) → chitchat,LLM 不被触发
- 短查询兜底(在吗/嗯/ok) → chitchat,LLM 不被触发
- 长查询 + 无关键词 → 必须进到第 3 层
测法:monkeypatch
get_utility_chat_model,让它一旦被调就抛 AssertionError。验证"该走快速路径的决不触达 LLM"。
3.7、关联文件清单
| 文件 | 角色 |
|---|---|
| intent_chain.py | 三层编排主体 |
| intent_router_node.py | 套成 LangGraph 节点 |
| llm.py:122-173 | get_utility_chat_model 工厂 |
| config.py:53-68 | 大/小模型配置 |
| domain.py | IntentClassification 结构 |
| test_intent_chain.py | 单测 |
| 02-routing-and-model-tiers.md | 设计文档 |