系列文章目录
学习系列文章:
【初识C语言】选择结构(if语句和switch语句)详细解答
【初识C语言】循环结构(while语句、do...while语句和for语句)详细解答
【初识C语言】数组(一维数组和二维数组)详细解答+避坑
【初识C语言】C语言指针从入门到进阶详细解答
【初识C语言】字符 / 字符串函数 + 内存函数(详解+模拟实现+避坑)
【初识C语言】探究数据在内存中的存储(整型、浮点型)
【初识C语言】拆解函数:从基础用法到递归精髓
【初识C语言】自定义类型全解析:结构体、联合体、枚举
【初识C语言】动态内存管理超详解(malloc/calloc/realloc/ 柔性数组+ 常见错误 + 内存区域划分说明)
【初识C语言】文件操作超详细讲解
【初识C语言】C 语言编译与链接 详细解析笔记
理解函数文章:
【初识C语言】include头文件双引号""和尖括号<>的区别以及使用顺序
【初识C语言】qsort 函数保姆级教程,搞定各种数据类型的排序
实战项目文章:
【初识C语言】经典扫雷C语言实战(原码+解析),看完就能上手拆解与修改
文章目录
- 系列文章目录
- 前言
- 一、预处理概述
-
- [1. 什么是预处理?](#1. 什么是预处理?)
- [2. 预处理的核心特点](#2. 预处理的核心特点)
- [3. 程序编译完整流程](#3. 程序编译完整流程)
- [二、C 语言预定义符号](#二、C 语言预定义符号)
- 三、预处理核心指令总览
- [四、#define 宏定义(重点)](#define 宏定义(重点))
-
- [1. 定义宏常量](#1. 定义宏常量)
-
- [1.1 常用场景:](#1.1 常用场景:)
- [1.2 长文本续行符](#1.2 长文本续行符)
- [1.3 重点:宏常量末尾不要加分号;](#1.3 重点:宏常量末尾不要加分号;)
- [2. 定义带参宏(函数式宏)](#2. 定义带参宏(函数式宏))
- [3. 带副作用的宏参数](#3. 带副作用的宏参数)
- [4. 宏替换规则](#4. 宏替换规则)
- [五、宏 VS 函数 全方位对比](#五、宏 VS 函数 全方位对比)
- 六、预处理特殊运算符
-
- [1. # 运算符:字符串化](# 运算符:字符串化)
- [2 ## 运算符:记号粘合](## 运算符:记号粘合)
- [3. defined() 运算符](#3. defined() 运算符)
- 七、#undef:取消宏定义
- 八、条件编译:按需编译代码
-
- [1. 常用条件编译指令](#1. 常用条件编译指令)
-
- [1.1 单分支](#1.1 单分支)
- [1.2 多分支](#1.2 多分支)
- [1.3 判断宏是否定义](#1.3 判断宏是否定义)
- [2 实战示例:调试代码开关](#2 实战示例:调试代码开关)
- [3 实战示例:跨平台编译](#3 实战示例:跨平台编译)
- 九、头文件包含
-
- [1. 两种包含方式与查找规则](#1. 两种包含方式与查找规则)
- [2. 解决头文件重复包含](#2. 解决头文件重复包含)
- 十、其他预处理指令
- 总结
前言
C 语言预处理 是程序编译流程的第一个阶段 ,由预处理器独立完成,核心是纯文本替换与代码裁剪,不涉及语法分析、语义检查,也不生成机器码。
一、预处理概述
1. 什么是预处理?
预处理是编译器在正式编译前 ,对源代码进行的文本处理工作 ,只识别以#开头的预处理指令,完成宏展开、文件包含、条件编译、删除注释等操作。
2. 预处理的核心特点
仅做纯文本替换 / 插入 / 删除 ,不检查语法对错;
处理结果生成.i后缀的预处理文件,供后续编译使用;
所有预处理指令均以#开头,且#必须是该行第一个非空白字符。
3. 程序编译完整流程
.c 源文件 → 【预处理】→ .i 预处理文件 → 【编译】→ .s 汇编文件 → 【汇编】→ .o 目标文件 → 【链接】→ 可执行程序
二、C 语言预定义符号
ANSI C 标准内置了一些预定义符号,无需定义可直接使用,预处理阶段自动替换为对应值,常用于调试、日志打印:
| 预定义符号 | 功能说明 |
|---|---|
__FILE__ |
当前编译的源文件名(字符串常量) |
__LINE__ |
当前代码所在的行号(十进制常量) |
__DATE__ |
文件编译日期 (格式:MMM DD YYYY) |
__TIME__ |
文件编译时间 (格式:HH:MM:SS) |
__STDC__ |
编译器遵循 ANSI C 标准则为 1,否则未定义 |
代码示例:
c
#include <stdio.h>
int main() {
// 打印当前源文件名(字符串常量)
printf("当前文件: %s\n", __FILE__);
// 打印编译日期("MMM DD YYYY"格式)
printf("编译日期: %s\n", __DATE__);
// 打印编译时间("HH:MM:SS"格式)
printf("编译时间: %s\n", __TIME__);
// 打印当前行号(十进制整数)
printf("当前行号: %d\n", __LINE__);
// 检查是否符合ANSI/ISO标准(1表示符合)
printf("ANSI标准: %d\n", __STDC__); // 如果 __STDC__ 报错提示未定义,则表示编译器不遵循C标准
return 0;
}三、预处理核心指令总览
所有的预处理器命令都是以井号 # 开头。它必须是第一个非空字符。以下列出比较重要的指令:
| 指令 | 核心功能 |
|---|---|
| #define | 定义宏(符号常量或函数式宏) |
| #include | 包含头文件 |
| #undef | 取消已定义的宏 |
| #if / #elif / #else / #endif | 条件编译 |
| #ifdef / #ifndef | 判断宏是否定义 |
| #error | 产生编译错误并输出消息 |
| #error | 产生编译错误并输出消息 |
| #pragma | 编译器专属指令(非标准,各编译器不同) |
| #line | 重置行号与文件名 |
四、#define 宏定义(重点)
#define 是预处理最核心的指令,分为定义常量 和定义带参宏 两种用法,本质都是文本替换。
1. 定义宏常量
语法:
c
#define 名字 替换文本预处理器会将代码中所有名字,替换为指定的文本内容。
1.1 常用场景:
c
#define MAX 1000 // 定义数值常量
#define PI 3.14159 // 定义圆周率
#define reg register // 关键字别名
#define do_forever for(;;) // 替换循环语句1.2 长文本续行符
宏内容过长时,用反斜杠\ 换行(最后一行不加):
c
#define DEBUG_PRINT printf("file:%s line:%d\n", \
__FILE__, __LINE__)1.3 重点:宏常量末尾不要加分号;
c
// 错误写法
#define MAX 1000;
// 正确写法
#define MAX 1000因为定义宏常量的本质是文本替换 ,替换后容易会出现语法错误。
例子:
c
// 原代码
if(1) max = MAX;
else max = 0;
// 错误替换后(if后有两条语句,编译报错)
if(1) max = 1000;;
else max = 0;2. 定义带参宏(函数式宏)
带参宏是带参数的文本替换,语法:
c
#define 宏名(参数列表) 替换文本注意 :宏名与左括号(之间不能有空格,否则会被识别为宏常量。
宏的核心陷阱:运算符优先级(必须加括号)
宏是纯文本替换,不会自动处理运算优先级 ,必须遵循:每个参数加括号 + 整个宏体加括号
错误示例 1:参数不加括号
c
#include <stdio.h>
#define SQUARE(x) x*x
int main(){
int a = SQUARE(5+1); // 调用 SQUARE(5+1) → 替换为 5+1*5+1 = 11(预期36)
printf("%d\n",a); // 输出11
return 0;
}正确示例 1:参数加括号
c
#include <stdio.h>
#define SQUARE(x) (x)*(x) // 正确示例
int main(){
int a = SQUARE(5+1); // 调用 SQUARE(5+1) → 替换为 (5+1)*(5+1) = 36
printf("%d\n",a); // 输出36
return 0;
}错误示例 2:整体不加括号
c
#include <stdio.h>
#define DOUBLE(x) (x)+(x)
int main(){
int a = 10*DOUBLE(5); // 调用 10*DOUBLE(5) → 10*(5)+(5) = 55(预期100)
printf("%d\n",a); // 输出55
return 0;
}正确示例 2:整体加括号
c
#include <stdio.h>
#define DOUBLE(x) ((x)+(x)) // 正确示例
int main(){
int a = 10*DOUBLE(5); // 调用 10*DOUBLE(5) → 10*((5)+(5)) = 100
printf("%d\n",a); // 输出100
return 0;
}3. 带副作用的宏参数
当宏参数在宏体中出现多次 ,且参数带有副作用 (++/--),会产生不可预期的结果:
c
#define MAX(a,b) ((a)>(b)?(a):(b))
int main() {
int x=5, y=8;
int z = MAX(x++, y++);
// 替换后:z = ((x++)>(y++)?(x++):(y++));
// x++、y++ 被执行2次!
// 结果:x=6,y=10,z=9
return 0;
}结论 :带++/--的参数禁止传给宏。
4. 宏替换规则
- 先检查宏参数,若包含其他宏,先替换参数;
- 将参数值替换到宏体中,插入到代码原位置;
- 再次扫描结果,重复替换**(宏不能递归)**;
- 字符串常量中的宏名不被替换。
五、宏 VS 函数 全方位对比
宏适用于简单、高频、无类型 的运算,函数适用于复杂、可调试的逻辑:
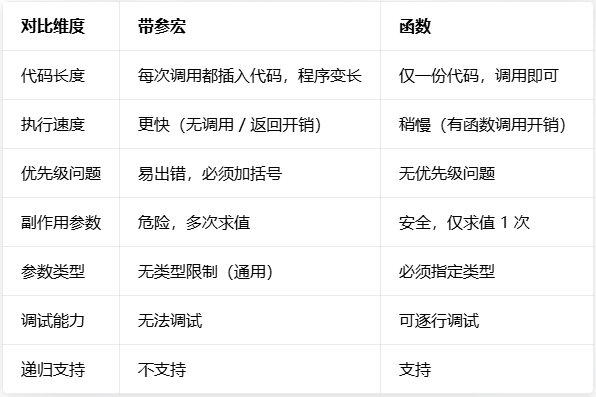
宏的独特能力:参数可传类型
函数无法实现,宏可以将数据类型作为参数:
c
#define MALLOC(num, type) (type*)malloc(num * sizeof(type))
// 使用
int* p = MALLOC(10, int);
// 替换后:int* p = (int*)malloc(10 * sizeof(int));六、预处理特殊运算符
1. # 运算符:字符串化
将宏参数转换为字符串字面量,仅用于带参宏:
c
#define PRINT(n) printf("the value of "#n" is %d\n", n)
int main() {
int a = 10;
PRINT(a);
// 替换后:printf("the value of ""a"" is %d\n", a);
// 输出:the value of a is 10
return 0;
}2 ## 运算符:记号粘合
将两边的符号拼接成一个合法标识符:
c
#define GENERIC_MAX(type) \
type type##_max(type x, type y) {\
return x>y ? x : y;\
}
// 自动生成int_max、float_max函数
GENERIC_MAX(int)
GENERIC_MAX(float)
int main() {
printf("%d\n", int_max(2,3)); // 3
printf("%f\n", float_max(3.5,4.5));// 4.500000
return 0;
}3. defined() 运算符
判断宏是否被定义,用于条件编译:
c
#if defined(DEBUG)
// 宏已定义,编译这段代码
#endif七、#undef:取消宏定义
用于移除已定义的宏,重定义宏前必须先取消:
c
#define MAX 100
#undef MAX // 取消MAX宏
#define MAX 200 // 重定义八、条件编译:按需编译代码
条件编译可以选择性保留 / 删除代码 ,常用于调试、跨平台、功能裁剪。
1. 常用条件编译指令
1.1 单分支
c
#if 常量表达式
// 满足条件则编译
#endif1.2 多分支
c
#if 表达式1
#elif 表达式2
#else
#endif1.3 判断宏是否定义
c
#ifdef MACRO // 已定义则编译
#ifndef MACRO // 未定义则编译2 实战示例:调试代码开关
c
#include <stdio.h>
#define __DEBUG__ 1
int main() {
int arr[10] = {0};
for(int i=0; i<10; i++) {
arr[i] = i;
#ifdef __DEBUG__
printf("%d ", arr[i]); // 仅调试模式编译
#endif
}
return 0;
}3 实战示例:跨平台编译
c
#if defined(_WIN32)
printf("Windows系统\n");
#elif defined(__linux__)
printf("Linux系统\n");
#elif defined(__APPLE__)
printf("macOS系统\n");
#endif九、头文件包含
1. 两种包含方式与查找规则
| 包含方式 | 查找规则 | 适用场景 |
|---|---|---|
| #include "add.h" | 先查当前目录,再查标准库路径 | 自定义头文件 |
| <include "add.h> | 直接查标准库路径 | 系统库头文件 |
2. 解决头文件重复包含
头文件被多次包含会导致重复定义错误,两种解决方案:
方法 1:条件编译(通用,跨平台)
c
#ifndef __TEST_H__
#define __TEST_H__
// 头文件内容
#endif方法 2:#pragma once(简洁,编译器支持)
c
#pragma once
// 头文件内容优点:写法简单,避免宏名冲突
十、其他预处理指令
1. #error:产生编译错误并输出消息
c
#if !defined(C99)
#error "当前编译器不支持C99标准"
#endif2. #pragma:编译器特定指令
c
#pragma once // 头文件保护
#pragma pack(1) // 结构体1字节对齐3. #line:重置行号与文件名
c
#line 100 "test.c" // 下一行行号为100,文件名为test.c总结
本文重点还是以宏定义为主,其他预处理指令仅仅只是做个记录,如果有兴趣的,可以参考《C语⾔深度解剖》这本书