参考笔记:
1.问题提出
商业项目通常都会有订单表,当用户查看个人订单时,会返回订单信息(包括订单号)给用户,订单表如果使用数据库 自增ID策略 就会存在一些问题:
**① id的规律性太明显:**用户或商业对手很容猜测出敏感信息,比如商城在一天的时间内,产出了多少个订单
② 随着项目规模越来越大**,Mysql** 的单表容量不宜超过 500W ,数据量过大则必须进行分表存储。但 Mysql 每张表都是计算自己的自增长,多张表情况下自增的ID一定会出现重复,但ID是需要具有唯一性的,以区分不同的订单
2. 生成全局唯一ID的要求
2.1 id生成规则的硬性要求
**① 全局唯一:**分布式多服务、多节点、多线程并发下永不重复
② 递增性: 生成的 ID 通常会作为主键存储到数据库中,有顺序的 ID 可以保证 Mysql 的写入性能
③ 安全性: 生成的 ID 规律性不能太明显,不能是简单的递增
④ 含时间戳: 通过 ID 的时间戳可以分析出生成该 ID 的时间,帮助定位排查问题
2.2 id生成系统的可用性要求
**① 高可用:**单点故障不影响服务
② 低延迟: 生成 ID 的速度要足够快
③ 高QPS: 数万个生成 ID 的请求同时过来,仍能生成不重复的 ID
3. 利用Redis生成全局唯一ID
3.1 介绍
生成全局唯一ID的方案很多,Redis是最优解之一,主要原因如下:
-
单线程串行执行模型 :所有命令按到达顺序排队执行,天然无并发冲突
-
原子自增命令: INCR/INCRBY 是 Redis 原生原子操作,执行过程不中断
-
高性能:纯内存操作,单节点每秒可处理 10万+ 次自增请求
Redis 的 INCR key 命令执行过程:
查找 key 对应的内存地址
将值加 1
返回新值
整个过程是原子的:即使 1000 个客户端同时对同一个 key 执行 INCR,Redis 也会将它们排成队列,一个接一个执行,绝不会出现 "两个线程同时读到同一个值,同时加 1,返回相同结果" 的情况
这是 Redis 实现全局唯一 ID 的根本保障
3.2 原理 + 代码实现
为了增加 ID的安全性,我们不直接使用 Redis 自增的数值,而是拼接一些其它信息,采用结构化 ID方案,这也是很多全局ID生成器采用的方案
Redis 构造的 ID 组成部分如下:
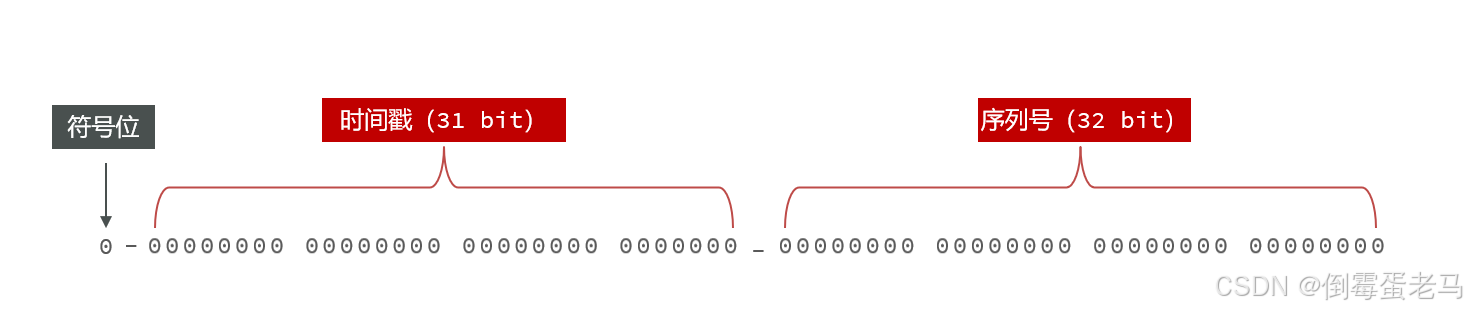
符号位: 1bit,永远为0,因为 ID 一定是正数
时间戳: 31bit,以秒为单位,支持使用69年
序列号: 32bit,每秒内的计数器,也就是每秒支持产生 个不同 ID 。作用:当时间戳部分重复时,可以通过序列号来区分;
代码实现(来自《黑马点评》):
java
/**
* 使用Redis生成全局唯一ID
*/
@Component
public class RedisIdWorker {
/**
* 自定义一个开始时间(以秒为单位)
*/
private static final long BEGIN_TIMESTAMP = 1640995200L;
/**
* 序列号的位数(支持每秒内生成2^32个不同的ID)
*/
private static final int COUNT_BITS = 32;
@Resource
private StringRedisTemplate stringRedisTemplate;
// keyPrefix:相关业务前缀
public long nextId(String keyPrefix) {
// 1.生成时间戳
LocalDateTime now = LocalDateTime.now(); // 获取当前时间
long nowSecond = now.toEpochSecond(ZoneOffset.UTC); // 转换为秒
long timestamp = nowSecond - BEGIN_TIMESTAMP; // 时间戳 = 当前时间 - 开始时间
// 2.生成序列号
// 2.1.获取当前日期(具体到天),按日期拆分Key,每天生成一个新的Key
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
// 2.2.自增长
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
// 3.拼接并返回
return timestamp << COUNT_BITS | count;
}
}3.3 代码分析
(1)获取当前时间
java
LocalDateTime now = LocalDateTime.now();这里获取当前时间。例如当前可能是:2026-05-05 12:34:40
java
2026-05-05T12:34:40.434878500(2)转换为秒级
java
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);这一步是先将时间转换成世界统一时间(UTC 0 时区),再将其转换为秒
也就是从 1970-01-01 00:00:00 到现在经过的总秒数
(3)减去自定义的开始时间
java
long timestamp = nowSecond - BEGIN_TIMESTAMP;时间戳 = 现在时间 - 自定义开始时间,有了时间戳我们可以分析出生成该ID的具体时间
(4)生成日期字符串
java
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));得到类似这样的结果:
java
2026:05:06为什么要这样做?
因为后面 Redis 的自增 key 可以按天区分,也就是每天使用一个新的计数器
(5)使用 Redis 生成当天自增序列
java
long count = stringRedisTemplate.opsForValue()
.increment("icr:" + keyPrefix + ":" + date);这句是整个方案里最关键的一步。它本质上相当于执行了 Redis 命令:
java
INCR icr:order:2025:05:06如果 keyPrefix = "order",那么:
- 第一次调用返回1
- 第二次调用返回2
- ....
- 第n次调用返回n
这样就能在分布式环境下拿到一个全局唯一的递增序列号
3.4 为什么要加 KeyPrefix?
keyPrefix 可以用来区分业务类型
例如:
- 订单:order
- 用户:user
- 优惠券:voucher
最终 Redis key 可能长这样:
java
icr:order:2026:05:08
icr:user:2026:05:08
icr:voucher:2026:05:08这样可以使得不同业务之间的计数器互不影响
3.3 为什么要按天拆分Key?
如果 Redis key 不带日期,那么计数器会一直增长,长期运行后数值会越来越大
按天拆分的好处是:
- 每天生成一个新的 Redis key,例如 icr :order :20260506,即每天从一个新的计数器开始
- 避免序列号无限膨胀
- 更容易管理和排查问题
即新的一天,计数器又从 1 开始,不会与历史ID发生重复,因为高位的时间戳已经变化了
3.4 最终ID是如何拼接的?
java
return timestamp << COUNT_BITS | count;这句代码的含义是:
- 把时间戳左移 32 位,给低位留出 32 位的空间
- 此时低位是 32 位的 0000.....
- 使用按位或
|运算将序列号拼进去(0 | 1 = 1,0 | 0 = 0,所以低位的32位正好是序列号本身)
最终返回的是 long 类型数据, long 类型正好是 8字节 = 64bit
3.5 为什么这种方式能保证ID唯一?
唯一性来自两部分共同约束:
1. 不同时刻生成
只要时间戳不同,最终 ID 一定不同
2. 同一时刻生成多个 ID
哪怕时间戳相同,只要 Redis 自增得到的 count 不同,最终 ID 也不同。而且 Redis 的 INCR key 命令具有原子性
因此:
时间戳负责区分时间范围,Redis 自增负责区分同一时间内的并发请求
两者配合起来,就可以保证全局唯一
3.6 为什么它适合分布式系统?
因为 Redis 的 INCR 操作具有原子性
假设有两个服务实例同时生成订单 ID:
- 实例 A 执行一次 INCR,返回 1001
- 实例 B 执行一次 INCR,返回 1002
即使它们部署在不同机器上,也不会拿到重复值
这就是 Redis 在这个方案中的价值
3.7 该方案的优点和局限性
优点
① 实现简单
② 原子性强,无重复
③支付跨服务共享
局限性
① 单点故障问题:Redis 单点故障会导致 ID 生成不可用,必须部署主从集群 + 哨兵模式,确保Redis 宕机时自动切换
② 相比完全本地生成 ID 的算法,这种方式会多一次网络开销
③ 位数设计需要提前规划,这些都需要结合业务体量提前设计:
- 时间戳占多少位
- 序列号占多少位
- 能支撑多少年
- 每天最多支持多大量级的自增序列
4. 其他生成全局唯一ID方案
后续再补充...
4.1 UUID
UUID最大的问题是生成的ID是无序的,作为主键会导致索引分裂,大大降低索引的性能
补充.....
4.2 雪花算法
雪花算法和Redi实现全局唯一ID比较类
补充....
4.3 美团Leaf算法
....
4.4 数据库自增ID
...